Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server unter Linux
SQL Server unter Linux
In diesem Artikel wird beschrieben, wie Sie die folgenden Aufgaben für SQL Server auf einem freigegebenen Datenträger-Failovercluster mit Red Hat Enterprise Linux ausführen.
- Durchführen eines manuellen Clusterfailovers
- Überwachen eines SQL Server-Diensts für Failovercluster
- Hinzufügen eines Clusterknotens
- Entfernen eines Clusterknotens
- Ändern der Häufigkeit der SQL Server-Ressourcenüberwachung
Beschreibung der Architektur
Die Clusteringebene basiert auf einem Hochverfügbarkeits-Add-On für Red Hat Enterprise Linux (RHEL), das auf Pacemaker aufbaut. Corosync und Pacemaker koordinieren die Clusterkommunikation und die Ressourcenverwaltung. Die SQL Server-Instanz ist auf einem der beiden Knoten aktiv.
Das folgende Diagramm veranschaulicht die Komponenten in einem Linux-Cluster mit SQL Server.
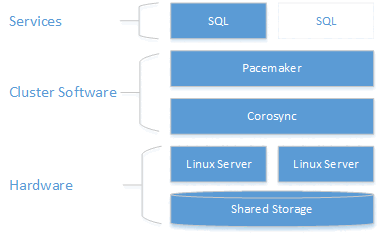
Weitere Informationen zur Clusterkonfiguration, den Optionen für Ressourcen-Agents und der Verwaltung finden Sie in der Referenzdokumentation von RHEL.
Failover des Clusters manuell ausführen
Der Befehl resource move erstellt eine Einschränkung, die die Ressource zwingt, auf dem Zielknoten zu starten. Nachdem der Befehl move ausgeführt wurde, entfernt die ausführende Ressource clear die Einschränkung, sodass die Ressource erneut verschoben oder ein automatisches Failover für die Ressource durchgeführt werden kann.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
Im folgenden Beispiel wird die Ressource mssqlha auf den Knoten sqlfcivm2 verschoben. Dann wird die Einschränkung entfernt, sodass die Ressource später auf einen anderen Knoten verschoben werden kann.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Überwachen eines SQL Server-Diensts für Failovercluster
Anzeigen des aktuellen Clusterstatus:
sudo pcs status
Anzeigen des aktuellen Status von Cluster und Ressourcen:
sudo crm_mon
Die Protokolle des Ressourcen-Agents können Sie unter /var/log/cluster/corosync.log anzeigen
Hinzufügen eines Knotens zu einem Cluster
Überprüfen Sie die IP-Adresse jedes Knotens. Das folgende Skript zeigt die IP-Adresse des aktuellen Knotens an.
ip addr showDer neue Knoten benötigt einen eindeutigen Namen, der höchstens 15 Zeichen lang ist. In Red Hat Enterprise Linux ist der Computername standardmäßig
localhost.localdomain. Dieser Standardname ist möglicherweise nicht eindeutig und außerdem zu lang. Legen Sie den Computernamen für den neuen Knoten fest. Legen Sie den Computernamen fest, indem Sie diesen zu/etc/hostshinzufügen. Mithilfe des folgenden Skripts können Sie/etc/hostsmitvibearbeiten.sudo vi /etc/hostsDas folgende Beispiel zeigt
/etc/hostsergänzungen für drei Knoten mit dem Namensqlfcivm1,sqlfcivm2undsqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3Die Datei sollte auf jedem Knoten dieselbe sein.
Beenden Sie den SQL Server-Dienst auf dem neuen Knoten.
Befolgen Sie die Anweisungen, um das Datenbankdatei-Verzeichnis am freigegebenen Speicherort einzubinden:
Vom NFS-Server aus installieren Sie
nfs-utils:sudo yum -y install nfs-utilsÖffnen Sie die Firewall auf Clients und NFS-Server:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadBearbeiten Sie die Datei
/etc/fstabso, dass sie den Einbindungsbefehl enthält:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrFühren Sie
mount -aaus, damit die Änderungen wirksam werden.Erstellen Sie auf dem neuen Knoten eine Datei zum Speichern von Benutzername und Kennwort für SQL Server für die Pacemaker-Anmeldung. Der folgende Code erstellt und füllt diese Tabelle:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdAchtung
Ihr Kennwort sollte der standardmäßigen Kennwortrichtlinie von SQL Server folgen. Ein Standardkennwort enthält mindestens acht Zeichen, die aus drei der folgenden vier Kategorien stammen müssen: Großbuchstaben, Kleinbuchstaben, Grundzahlen (0–9) und Symbole. Kennwörter können bis zu 128 Zeichen lang sein. Verwenden Sie möglichst lange und komplexe Kennwörter.
Öffnen Sie auf dem neuen Knoten die Pacemaker-Firewallports. Führen Sie zum Öffnen dieser Ports mit
firewalldfolgenden Befehl aus:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadWenn Sie eine andere Firewall verwenden, in die keine Konfiguration mit Hochverfügbarkeit integriert ist, müssen die folgenden Ports geöffnet werden, damit Pacemaker mit anderen Knoten im Cluster kommunizieren kann:
- TCP: Ports 2224, 3121, 21064
- UDP: Port 5405
Installieren Sie Pacemaker-Pakete auf dem neuen Knoten.
sudo yum install pacemaker pcs fence-agents-all resource-agentsLegen Sie das Kennwort für den Standardbenutzer fest, der beim Installieren von Pacemaker und Corosync-Paketen erstellt wird. Verwenden Sie dasselbe Kennwort wie bei den vorhandenen Knoten.
sudo passwd haclusterAktivieren und starten Sie den
pcsd-Dienst und Pacemaker. So kann der neue Knoten dem Cluster nach dem Neustart erneut beitreten. Führen Sie den folgenden Befehl auf dem neuen Knoten aus.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstallieren Sie den FCI-Ressourcenagent für SQL Server. Führen Sie die folgenden Befehle auf dem neuen Knoten aus.
sudo yum install mssql-server-haAuthentifizieren Sie den neuen Knoten vom Cluster aus auf einem vorhandenen Knoten, und fügen Sie ihn dem Cluster hinzu.
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>Im folgenden Beispiel wird der Knoten vm3 dem Cluster hinzugefügt.
sudo pcs cluster auth sudo pcs cluster start
Entfernen von Knoten aus einem Cluster
Führen Sie den folgenden Befehl aus, um einen Knoten aus einem Cluster zu entfernen:
sudo pcs cluster node remove <nodeName>
Ändern der Häufigkeit der SQL Server-Ressourcenüberwachung
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
Im folgenden Beispiel wird das Überwachungsintervall für die Ressource „mssql“ auf 2 Sekunden festgelegt:
sudo pcs resource op monitor interval=2s mssqlha
Problembehandlung für einen freigegebenen Datenträgercluster mit Red Hat Enterprise Linux für SQL Server
Bei der Fehlersuche im Cluster ist es hilfreich zu verstehen, wie die drei Daemons bei der Verwaltung der Clusterressourcen zusammenarbeiten.
| Dämon | BESCHREIBUNG |
|---|---|
| Corosync | Ermöglicht Quorum-Mitgliedschaft und Messaging zwischen Clusterknoten |
| Schrittmacher | Baut auf Corosync auf und bietet Zustandsautomaten für Ressourcen |
| PCSD | Verwaltet Pacemaker und Corosync über die pcs-Tools. |
PCSD muss ausgeführt werden, damit die pcs-Tools verwendet werden können.
Aktueller Clusterstatus
sudo pcs status gibt grundlegende Informationen zu Cluster, Quorum, Knoten, Ressourcen und Daemonstatus für jeden Knoten zurück.
Eine fehlerfreie Pacemaker-Quorumausgabe könnte wie folgt aussehen:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
Im Beispiel bedeutet partition with quorum, dass ein Mehrheitsquorum von Knoten online ist. Wenn der Cluster ein Mehrheitsquorum von Knoten verliert, gibt pcs statuspartition WITHOUT quorum zurück, und alle Ressourcen werden angehalten.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] gibt die Namen aller Knoten zurück, die aktuell am Cluster beteiligt sind. Wenn ein oder mehrere Knoten nicht beteiligt sind, gibt pcs statusOFFLINE: [<nodename>] zurück.
PCSD Status zeigt den Clusterstatus für jeden Knoten an.
Gründe, warum ein Knoten offline sein kann
Überprüfen Sie Folgendes, wenn ein Knoten offline ist:
Firewall
Die folgenden Ports müssen auf allen Knoten geöffnet sein, damit Pacemaker kommunizieren kann:
- **TCP: 2224, 3121, 21064
Ausführung von Pacemaker oder Corosync
Knotenkommunikation
Zuordnungen von Knotennamen