Columnstore-Indizes: Übersicht
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Columnstore-Indizes stellen den Standard für das Speichern und Abfragen großer Data Warehousing-Faktentabellen dar. Dieser Index verwendet spaltenbasierte Datenspeicherung und Abfrageverarbeitung, um eine bis zu zehnmal höhere Abfrageleistung im Data Warehouse im Vergleich zur herkömmlichen zeilenorientierten Speicherung zu erzielen. Sie können im Vergleich zur unkomprimierten Datengröße außerdem eine bis zu 10-mal höhere Datenkomprimierung erzielen. Ab SQL Server 2016 (13.x) SP1 ermöglichen Columnstore-Indizes die operative Analyse und bieten damit die Möglichkeit, leistungsfähige Echtzeitanalysen von Transaktionsworkloads durchzuführen.
Erfahren Sie mehr über ähnliche Szenarien:
Was ist ein Columnstore-Index?
Ein Columnstore-Index ist eine Technologie zum Speichern, Abrufen und Verwalten von Daten mithilfe eines spaltenbasierten Datenformats, das als „Columnstore“ bezeichnet wird.
Hauptbegriffe und -Konzepte
Die folgenden Hauptbegriffe und -konzepte werden im Zusammenhang mit Columnstore-Indizes verwendet.
columnstore
Ein Columnstore enthält Daten, die logisch als Tabelle mit Zeilen und Spalten organisiert und physisch in einem Spaltendatenformat gespeichert sind.
Rowstore
Ein Rowstore enthält Daten, die logisch als Tabelle mit Zeilen und Spalten organisiert und physisch in einem Zeilendatenformat gespeichert sind. Dieses Format wird üblicherweise zum Speichern relationaler Tabellendaten verwendet. In SQL Server bezieht Rowstore sich auf die Tabelle, deren zugrunde liegendes Datenspeicherformat ein Heap, ein gruppierter Index oder eine speicheroptimierte Tabelle ist.
Hinweis
In Zusammenhang mit Columnstore-Indizes bezeichnen die Begriffe „Rowstore“ und „Columnstore“ das Format der Datenspeicherung.
Zeilengruppe
Eine Zeilengruppe ist eine Gruppe von Zeilen, die gleichzeitig im Columnstore-Format komprimiert werden. Eine Zeilengruppe enthält in der Regel die maximale Anzahl von Zeilen pro Zeilengruppe (d. h. 1.048.576 Zeilen).
Um eine hohe Leistung und hohe Komprimierungsraten zu erzielen, unterteilt der Columnstore-Index die Tabelle in Zeilengruppen und komprimiert dann jede Zeilengruppe nach Spalten. Die Anzahl der Zeilen in der Zeilengruppe muss groß genug sein, um die Komprimierungsraten zu verbessern, und klein genug, um von In-Memory-Vorgängen profitieren zu können.
Der Zustand einer Zeilengruppe, aus der alle Daten gelöscht wurden, ändert sich von COMPRESSED in TOMBSTONE. Später wird sie durch einen Hintergrundprozess entfernt, der auch Tupelverschiebungsvorgang genannt wird. Weitere Informationen zu Zeilengruppenzuständen finden Sie unter sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tipp
Zu viele kleine Zeilengruppen verschlechtern die Qualität des Columnstore-Index. Bis SQL Server 2017 (14.x) ist ein Neuorganisierungsvorgang erforderlich, um kleinere COMPRESSED-Zeilengruppen zusammenzuführen. Dabei wird eine interne Schwellenwertrichtlinie eingehalten, die bestimmt, wie gelöschte Zeilen entfernt und die komprimierten Zeilengruppen kombiniert werden.
Ab SQL Server 2019 (15.x) wird ebenfalls ein Hintergrundvorgang durchgeführt, um COMPRESSED-Zeilengruppen zusammenzuführen, aus denen viele Zeilen gelöscht wurden.
Nachdem kleinere Zeilengruppen zusammengeführt wurden, sollte sich die Indexqualität verbessern.
Hinweis
Seit SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance und den dedizierten SQL-Pools in Azure Synapse Analytics wird der Tupelverschiebungsvorgang von einem Zusammenführungstask im Hintergrund unterstützt. Dieser komprimiert automatisch kleinere OPEN-Deltazeilengruppen, die für einen bestimmten durch einen internen Schwellenwert definierten Zeitraum vorhanden waren, oder führt COMPRESSED-Zeilengruppen zusammen, aus denen eine große Anzahl von Zeilen gelöscht wurde. Dies verbessert die Qualität des Columnstore-Index im Lauf der Zeit.
Spaltensegment
Ein Spaltensegment ist eine Spalte mit Daten aus der Zeilengruppe.
- Jede Zeilengruppe enthält ein Spaltensegment für jede Spalte in der Tabelle.
- Jedes Spaltensegment wird zusammenhängend komprimiert und auf physischen Medien gespeichert.
- Es gibt Metadaten für jedes Segment, damit Segmente, ohne sie zu lesen, schnell eliminiert werden können.
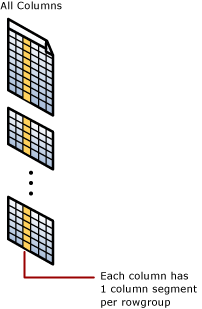
Gruppierter Columnstore-Index
Ein gruppierter Columnstore-Index ist der physische Speicher für die gesamte Tabelle.
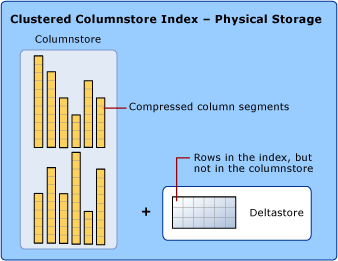
Um die Fragmentierung der Spaltensegmente zu verringern und die Leistung zu verbessern, können einige Daten im Columnstore-Index vorübergehend in einem gruppierten Index (Deltastore) und in einer B-Struktur mit IDs der gelöschten Zeilen gespeichert werden. Die Deltastore-Vorgänge werden im Hintergrund verarbeitet. Damit die richtigen Abfrageergebnisse zurückgegeben werden, kombiniert der gruppierte Columnstore-Index Abfrageergebnisse aus dem Columnstore und dem Deltastore.
Hinweis
In der Dokumentation wird der Begriff „B-Struktur“ im Allgemeinen in Bezug auf Indizes verwendet. In Zeilenspeicherindizes implementiert die Datenbank-Engine eine B+-Struktur. Das gilt nicht für Columnstore-Indizes oder Indizes in speicheroptimierten Tabellen. Weitere Informationen finden Sie im Leitfaden zur Architektur und zum Entwerfen von SQL Server- und Azure SQL-Indizes.
Deltazeilengruppe
Eine Deltazeilengruppe ist ein gruppierter B-Strukturindex, der nur mit Columnstore-Indizes verwendet wird. Sie verbessert die Columnstore-Komprimierung und -Leistung, indem sie Zeilen solange speichert, bis bei der Zeilenanzahl ein bestimmter Schwellenwert (1.048.576 Zeilen) erreicht wird und diese dann in den Columnstore verschoben werden.
Wenn eine Deltazeilengruppe die maximale Zeilenanzahl erreicht, ändert sich ihr Zustand von OPEN in CLOSED. Ein Hintergrundprozess namens Tupelverschiebungsvorgang überprüft auf geschlossene Zeilengruppen. Wenn der Prozess eine geschlossene Zeilengruppe findet, wird die Deltazeilengruppe komprimiert und im Columnstore als COMPRESSED-Zeilengruppe gespeichert.
Wenn eine Deltazeilengruppe komprimiert wurde, ändert sich der Zustand der vorhandenen Deltazeilengruppe in TOMBSTONE, damit sie später im Tupelverschiebungsvorgang entfernt wird, wenn nicht auf sie verwiesen wird.
Weitere Informationen zu Zeilengruppenzuständen finden Sie unter sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Hinweis
Ab SQL Server 2019 (15.x) wird der Tupelverschiebungsvorgang von einem Mergetask im Hintergrund unterstützt, der automatisch kleinere OPEN-Deltazeilengruppen komprimiert, die für einen bestimmten Zeitraum vorhanden waren (wie durch einen internen Schwellenwert festgelegt), oder COMPRESSED-Zeilengruppen zusammenführt, aus denen eine große Anzahl von Zeilen gelöscht wurde. Dies verbessert die Qualität des Columnstore-Index im Lauf der Zeit.
Deltastore
Ein Columnstore-Index kann mehr als eine Deltazeilengruppe haben. Alle Deltazeilengruppen zusammen werden als „Deltastore“ bezeichnet.
Während eines umfassenden Massenladevorgangs werden die meisten Zeilen ohne Umweg über den Deltastore direkt in den Columnstore verschoben. Einige Zeilen am Ende des Massenladevorgangs erreichen möglicherweise nicht die notwendige Anzahl für die minimale Größe einer Zeilengruppe von 102.400 Zeilen. In diesem Fall werden die letzten Zeilen in den Deltastore anstatt in den Columnstore verschoben. Bei kleinen Massenladevorgängen mit weniger als 102.400 Zeilen werden alle Zeilen direkt in den Deltastore verschoben.
Nicht gruppierter Columnstore-Index
Ein nicht gruppierter Columnstore-Index und ein gruppierter Columnstore-Index haben die gleiche Funktionsweise. Der Unterschied besteht darin, dass ein nicht gruppierter Index ein sekundärer Index ist, der für eine Rowstore-Tabelle erstellt wird. Ein gruppierter Columnstore-Index hingegen ist der primäre Speicher für die gesamte Tabelle.
Der nicht gruppierte Index enthält eine Kopie eines Teils oder aller Zeilen und Spalten der zugrundeliegenden Tabelle. Der Index ist als mindestens eine Spalte der Tabelle definiert und weist eine optionale Bedingung auf, die zum Filtern der Zeilen dient.
Ein nicht gruppierter Columnstore-Index ermöglicht operative Echtzeitanalyse, bei der der OLTP-Workload den zugrunde liegenden gruppierten Index verwendet, während die Analyse parallel auf dem Columnstore-Index ausgeführt wird. Weitere Informationen finden Sie unter Erste Schritte mit Columnstore für operative Echtzeitanalyse.
Batchmodusausführung
Die Batchmodusausführung ist eine Methode zur Abfrageverarbeitung, die zum gleichzeitigen Abfragen mehrerer Zeilen verwendet wird. Die Batchmodusausführung ist eng in das Columnstore-Speicherformat integriert und für dieses optimiert. Die Batchmodusausführung wird auch als vektorbasierte oder vektorisierte Ausführung bezeichnet. Abfragen von Columnstore-Indizes verwenden die Batchmodusausführung, die die Abfrageleistung in der Regel um das Zwei- bis Vierfache steigert. Weitere Informationen finden Sie im Handbuch zur Architektur der Abfrageverarbeitung.
Warum sollte ich einen Columnstore-Index verwenden?
Ein Columnstore-Index kann eine sehr hohe Datenkomprimierung bieten, normalerweise etwa zehnfach. Dadurch werden die Speicherkosten für ein Data Warehouse erheblich reduziert. Für Analysezwecke bietet der Columnstore-Index eine weitaus bessere Leistung als ein B-Strukturindex. Columnstore-Indizes stellen das bevorzugte Datenspeicherformat für Data Warehouse- und Analyseworkloads dar. Ab SQL Server 2016 (13.x) können Sie Columnstore-Indizes für Echtzeitanalysen Ihrer Betriebsarbeitsauslastung verwenden.
Gründe für die hohe Geschwindigkeit von Columnstore-Indizes:
Spalten speichern Werte aus der gleichen Domäne und weisen oft ähnliche Werte auf, was zu hohen Komprimierungsraten führt. E/A-Engpässe in Ihrem System werden minimiert oder beseitigt, und der Speicherbedarf wird deutlich reduziert.
Hohe Komprimierungsraten verbessern die Abfrageleistung, da der Arbeitsspeicherbedarf geringer ist. Auch die Abfrageleistung kann verbessert werden, da SQL Server eine größere Anzahl von speicherinternen Abfrage- und Datenvorgängen ausführen kann.
Die Batchausführung verbessert die Abfrageleistung, in der Regel um das Zwei- bis Vierfache, indem mehrere Zeilen zusammen verarbeitet werden.
Bei Abfragen werden häufig nur wenige Spalten aus einer Tabelle ausgewählt, wodurch das Gesamtaufkommen der E/A-Vorgänge für das physische Medium reduziert wird.
Wann sollte ein Columnstore-Index verwendet werden?
Empfohlene Einsatzgebiete:
Verwenden Sie einen gruppierten Columnstore-Index zum Speichern von Faktentabellen und umfangreichen Dimensionstabellen für Data Warehouse-Arbeitsauslastungen. Diese Methode verbessert die Abfrageleistung und die Datenkomprimierung um das bis zu Zehnfache. Weitere Informationen finden Sie unter Columnstore-Indizes: Data Warehouse.
Verwenden Sie einen nicht gruppierten Columnstore-Index, um Echtzeitanalysen für OLTP-Workloads auszuführen. Weitere Informationen finden Sie unter Erste Schritte mit Columnstore für operative Echtzeitanalyse.
Weitere Verwendungsszenarien für Columnstore-Indizes finden Sie unter Auswählen des besten Columnstore-Indizes für Ihre Anforderungen.
Wie treffe ich die Entscheidung zwischen einem Rowstore-Index und einem Columnstore-Index?
Rowstore-Indizes eignen sich am besten für Abfragen, die Daten bei der Suche nach einem bestimmten Wert oder mit einem kleinen Wertebereich durchsuchen. Verwenden Sie Rowstore-Indizes für Transaktionsworkloads, da sie tendenziell eher Suchvorgänge in Tabellen als Scans ganzer Tabellen erfordern.
Columnstore-Indizes ermöglichen große Leistungsvorteile bei Analyseabfragen, die große Mengen von Daten durchsuchen, insbesondere bei umfangreichen Tabellen. Verwenden Sie Columnstore-Indizes für Data Warehouse- und Analyseworkloads, insbesondere für Faktentabellen, da diese eher Scans ganzer Tabellen als Suchvorgänge in Tabellen erfordern.
Ab SQL Server 2022 (16.x) verbessern sortierte gruppierte Columnstore-Indizes die Leistung für Abfragen basierend auf sortierten Spalten-Prädikaten. Sortierte Columnstore-Indizes können die Eliminierung von Zeilengruppen verbessern, wodurch sich Leistungsverbesserungen erzielen lassen, indem Zeilengruppen vollständig übersprungen werden. Weitere Informationen finden Sie unter Leistungsoptimierung mit einem sortierten gruppierten Columnstore-Index.
Können Rowstore und Columnstore in der gleichen Tabelle kombiniert werden?
Ja. Ab SQL Server 2016 (13.x) können Sie einen aktualisierbaren, nicht gruppierten Columnstore-Index für eine Rowstore-Tabelle erstellen. Der Columnstore-Index speichert eine Kopie der ausgewählten Spalten, sodass zusätzlicher Speicherplatz benötigt wird. Allerdings werden die ausgewählten Daten im Durchschnitt um das Zehnfache komprimiert. So können Sie Analysen im Columnstore-Index und Transaktionen im Rowstore-Index zur gleichen Zeit ausführen. Der Columnstore wird aktualisiert, wenn sich Daten in der Rowstore-Tabelle ändern, daher arbeiten beide Indizes mit den gleichen Daten.
Ab SQL Server 2016 (13.x) können Sie mindestens einen nicht gruppierten Rowstore-Index auf einem Columnstore-Index haben und auf dem zugrunde liegenden Columnstore effiziente Suchen in Tabellen durchführen. Auch weitere Optionen werden dadurch verfügbar. Beispielsweise können Sie eine Primärschlüsseleinschränkung durchsetzen, indem Sie eine UNIQUE-Bedingung auf die Rowstore-Tabelle anwenden. Da ein nicht eindeutiger Wert nicht in die Rowstore-Tabelle eingefügt werden kann, kann SQL Server den Wert nicht in den Columnstore einfügen.
Metadaten
Alle Spalten in einem Columnstore-Index werden in den Metadaten als eingeschlossene Spalten gespeichert. Der Columnstore-Index hat keine Schlüsselspalten.
Zugehörige Aufgaben
Alle relationalen Tabellen, sofern Sie sie nicht als gruppierten Columnstore-Index festlegen, verwenden Rowstore als zugrundeliegendes Datenformat. CREATE TABLE erstellt eine Rowstore-Tabelle, es sei denn, Sie geben die Option WITH CLUSTERED COLUMNSTORE INDEX an.
Beim Erstellen einer Tabelle mit der CREATE TABLE-Anweisung können Sie die Tabelle als Columnstore erstellen, indem Sie die Option WITH CLUSTERED COLUMNSTORE INDEX angeben. Wenn Sie bereits über eine Rowstore-Tabelle verfügen, die Sie in einen Columnstore konvertieren möchten, können Sie die Anweisung CREATE COLUMNSTORE INDEX verwenden.
| Aufgabe | Referenzartikel | Hinweise |
|---|---|---|
| Erstellen einer Tabelle als Columnstore. | CREATE TABLE (Transact-SQL) | Ab SQL Server 2016 (13.x) können Sie die Tabelle als gruppierten Columnstore-Index erstellen. Sie müssen nicht zuerst eine Rowstore-Tabelle erstellen, die Sie dann in Columnstore konvertieren. |
| Erstellen Sie eine speicheroptimierte Tabelle mit einem Columnstore-Index. | CREATE TABLE (Transact-SQL) | Ab SQL Server 2016 (13.x) können Sie eine speicheroptimierte Tabelle mit einem Columnstore-Index erstellen. Der Columnstore-Index kann auch nach dem Erstellen der Tabelle mit der ALTER TABLE ADD INDEX-Syntax hinzugefügt werden. |
| Konvertieren einer Rowstore-Tabelle in eine Columnstore-Tabelle. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Konvertieren Sie eine vorhandene Heap- oder B-Struktur in einen Columnstore. Aus den Beispielen können Sie ersehen, wie vorhandene Indizes und der Name des Index beim Durchführen der Konvertierung behandelt werden. |
| Konvertieren einer Columnstore-Tabelle in einen Rowstore. | CREATE CLUSTERED INDEX (Transact-SQL) oder Konvertieren einer Columnstore-Tabelle in einen Rowstore-Heap | In der Regel müssen Sie nicht konvertieren, allerdings kann es vorkommen, dass Sie diese Aktion durchführen müssen. Aus den Beispielen ist zu ersehen, wie ein Columnstore in einen Heap oder einen gruppierten Index konvertiert werden kann. |
| Erstellen eines Columnstore-Index für eine Rowstore-Tabelle. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Eine Rowstore-Tabelle kann über einen Columnstore-Index verfügen. Ab SQL Server 2016 (13.x) kann der Columnstore-Index eine Filterbedingung aufweisen. In den Beispielen wird die grundlegende Syntax verwendet. |
| Erstellen leistungsfähiger Indizes für Betriebsanalysen. | Erste Schritte mit Columnstore für operative Echtzeitanalyse | Beschreibt, wie sich ergänzende Columnstore-Indizes und B-Strukturindizes erstellt werden, sodass OLTP-Abfragen B-Strukturindizes und Analyseabfragen Columnstore-Indizes verwenden. |
| Erstellen leistungsfähiger Columnstore-Indizes für Data Warehousing | Columnstore-Indizes: Data Warehouse | Beschreibt, wie B-Strukturindizes für Columnstore-Tabellen verwendet werden können, um leistungsstarke Data Warehousing-Abfragen zu erstellen. |
| Verwenden Sie einen B-Strukturindex, um eine Primärschlüsseleinschränkung für einen Columnstore-Index zu erzwingen. | Columnstore-Indizes: Data Warehouse | Zeigt, wie B-Struktur- und Columnstore-Indizes kombiniert werden können, um Primärschlüsseleinschränkungen für den Columnstore-Index zu erzwingen. |
| Löschen eines Columnstore-Indexes. | DROP INDEX (Transact-SQL) | Beim Löschen eines Columnstore-Indexes wird die standardmäßige DROP INDEX-Syntax verwendet, die auch B-Strukturindizes verwenden. Beim Löschen eines gruppierten Columnstore-Index wird die Columnstore-Tabelle in einen Heap konvertiert. |
| Löschen einer Zeile aus einem Columnstore-Index. | DELETE (Transact-SQL) | Verwenden Sie DELETE (Transact-SQL) zum Löschen einer Zeile. columnstore row: SQL Server markiert die Zeile als logisch gelöscht, der physische Speicherplatz für die Zeile wird jedoch erst wieder freigegeben, wenn der Index neu erstellt wurde. deltastore row: SQL Server löscht die Zeile logisch und physisch. |
| Aktualisieren einer Zeile im Columnstore-Index. | UPDATE (Transact-SQL) | Verwenden Sie UPDATE (Transact-SQL), um eine Zeile zu aktualisieren. columnstore row: SQL Server markiert die Zeile als logisch gelöscht und fügt die aktualisierte Zeile dann in den Deltastore ein. deltastore row: SQL Server aktualisiert die Zeile im Deltastore. |
| Laden von Daten in einen Columnstore-Index. | Columnstore-Indizes: Laden von Daten | |
| Durchsetzen, dass alle Zeilen im Deltastore in den Columnstore wechseln. | ALTER INDEX (Transact-SQL) ... REBUILDNeuorganisieren und Neuerstellen von Indizes |
ALTER INDEX mit der Option REBUILD erzwingt das Verschieben aller Zeilen in den Columnstore. |
| Defragmentieren eines Columnstore-Index. | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE defragmentiert Columnstore-Indizes online. |
| Zusammenführen von Tabellen mit Columnstore-Indizes. | MERGE (Transact-SQL) |
Zugehöriger Inhalt
- Neuerungen in Columnstore-Indizes
- Columnstore-Indizes: Leitfaden zum Datenladevorgang
- Columnstore-Indizes: Abfrageleistung
- Erste Schritte mit Columnstore für die operative Echtzeitanalyse
- Columnstore-Indizes: Data Warehouse
- Columnstore-Index-Defragmentierung
- Leitfaden zur Architektur und zum Design von SQL Server-Indizes
- Columnstore-Indizes: Architektur
- CREATE COLUMNSTORE INDEX (Transact-SQL)