Neuigkeiten bei der Datendeduplizierung
Gilt für Windows Server 2022, Windows Server 2019, Windows Server 2016, Azure Stack HCI (Version 21H2 und 20H2)
Die Datendeduplizierung in Windows Server wurde optimiert und bietet nun auch für private Clouds eine hohe Leistung und Flexibilität sowie erstklassige Verwaltbarkeit. Weitere Informationen zum softwaredefinierten Speicherstapel in Windows Server finden Sie unter Neuerungen beim Speicher in Windows Server.
Windows Server 2022
Bei der Datendeduplizierung in Windows Server 2022 gibt es keine zusätzlichen Verbesserungen.
Windows Server 2019
Die Datendeduplizierung wurde in Windows Server 2019 wie folgt verbessert:
| Funktionalität | Neu oder aktualisiert | BESCHREIBUNG |
|---|---|---|
| ReFS-Unterstützung | Neu | Speichern Sie bis zu 10-mal mehr Daten auf demselben Volume mit Deduplizierung und Komprimierung für das ReFS-Dateisystem. (In Windows Admin Center können Sie das Feature mit nur einem Klick aktivieren.) Der Blockspeicher variabler Größe mit optionaler Komprimierung maximiert die Einsparungsraten, während die Multithread-Nachverarbeitungsarchitektur minimale Auswirkungen auf die Leistung hat. Unterstützt Volumes mit einer Größe von bis zu 64 TB und dedupliziert die ersten 4 TB jeder Datei. |
Windows Server 2016
Die Datendeduplizierung wurde ab Windows Server 2016 wie folgt verbessert:
| Funktionalität | Neu oder aktualisiert | BESCHREIBUNG |
|---|---|---|
| Unterstützung für große Volumes | Aktualisiert | Vor Windows Server 2016 musste die Größe der Volumes speziell für die erwartete Änderung konfiguriert werden, wobei Volumes mit über 10 TB keine geeigneten Kandidaten für die Deduplizierung waren. In Windows Server 2016 unterstützt die Datendeduplizierung Volumegrößen von bis zu 64 TB. |
| Unterstützung für große Dateien) | Aktualisiert | Vor Windows Server 2016 waren Dateien mit einer Größe von knapp 1 TB keine geeigneten Kandidaten für die Deduplizierung. In Windows Server 2016 werden Dateien mit einer Größe von bis zu 1 TB vollständig unterstützt. |
| Unterstützung für Nano Server | Neu | Die Datendeduplizierung ist in der neuen Nano Server-Bereitstellungsoption für Windows Server 2016 verfügbar und wird von dieser Option vollständig unterstützt. |
| Vereinfachte Unterstützung von Sicherungen | Neu | In Windows Server 2012 R2 musste eine Reihe von manuellen Konfigurationsschritten ausgeführt werden, um virtualisierte Sicherungsanwendungen wie Microsoft Data Protection Manager zu unterstützen. In Windows Server 2016 wurde ein neuer Standardverwendungstyp (Sicherung) hinzugefügt, um eine nahtlose Bereitstellung der Datendeduplizierung für virtualisierte Sicherungsanwendungen zu ermöglichen. |
| Unterstützung für parallele Upgrades des Clusterbetriebssystems | Neu | Die Datendeduplizierung bietet vollständige Unterstützung für das neue Feature für parallele Upgrades des Clusterbetriebssystems von Windows Server 2016. |
Unterstützung für große Volumes
Welchen Nutzen bietet diese Änderung?
Um bei der Datendeduplizierung in Windows Server 2012 R2 die maximale Leistung zu erreichen, muss die Größe von Volumes richtig konfiguriert werden, damit der Optimierungsauftrag mit der Geschwindigkeit von Datenänderungen oder einer sonstigen Änderung Schritt halten kann. Das bedeutet, dass typischerweise nur bei Volumes mit einer Größe von maximal 10 TB eine gute Leistung bei der Datendeduplizierung erreicht wird (abhängig von den Schreibmustern der Workload).
Ab Windows Server 2016 bietet die Datendeduplizierung bei Volumes mit einer Größe von bis zu 64 TB eine hervorragende Leistung.
Worin bestehen die Unterschiede?
In Windows Server 2012 R2 verwendet die Datendeduplizierungs-Auftragspipeline eine Singlethread- und E/A-Warteschlange für jedes Volume. Um eine ausreichende Geschwindigkeit der Optimierungsaufträge sicherzustellen, damit die Speichergeschwindigkeit für das Volume insgesamt nicht sinkt, müssen große Datasets in kleinere Volumes unterteilt werden. Die geeignete Volumegröße hängt von dem erwarteten Änderungsumfang für dieses Volume ab. Der Höchstwert beträgt durchschnittlich etwa 6-7 TB für Volumes mit hohem Änderungsumfang und etwa 9-10 TB für Volumes mit niedrigem Änderungsumfang.
Ab Windows Server 2016 wurde die Deduplizierungs-Auftragspipeline überarbeitet, um mithilfe mehrerer E/A-Warteschlangen für jedes Volume mehrere Threads parallel ausführen zu können. Dies führt zu Leistung, die bisher nur durch Aufteilen der Daten auf mehrere kleinere Volumes möglich war. Diese Änderung wird in der folgenden Abbildung dargestellt:
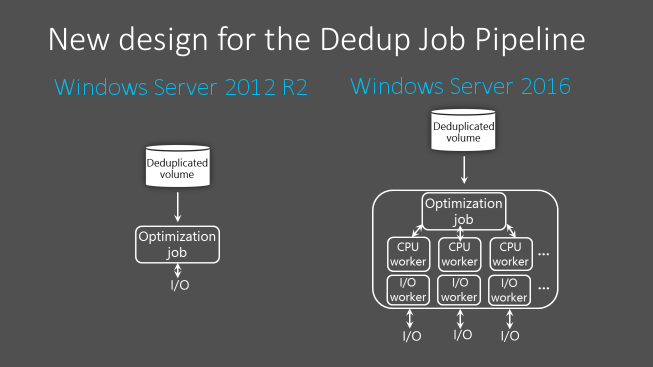
Diese Optimierungen gelten nicht nur für den Optimierungsauftrag, sondern für alle Datendeduplizierungsaufträge.
Unterstützung für große Dateien
Welchen Nutzen bietet diese Änderung?
In Windows Server 2012 R2 sind sehr große Dateien keine geeigneten Kandidaten für die Datendeduplizierung, da die Leistung der Deduplizierungs-Verarbeitungspipeline bei diesen Dateien sinkt. In Windows Server 2016 wird bei der Deduplizierung von Dateien mit einer Größe von bis zu 1 TB eine hervorragende Leistung erreicht, sodass Administratoren bei einer breiteren Palette von Workloads von der Deduplizierung profitieren können. Ein Beispiel ist die Deduplizierung von sehr großen Dateien, die normalerweise mit Sicherungsworkloads einhergehen.
Worin bestehen die Unterschiede?
Ab Windows Server 2016 werden bei der Datendeduplizierung neue Streamzuordnungsstrukturen und weitere „verdeckte“ Verbesserungen genutzt, um den Optimierungsdurchsatz und die Zugriffsleistung zu verbessern. Darüber hinaus kann die Deduplizierungs-Verarbeitungspipeline die Optimierung jetzt nach einem Failover fortsetzen (die Optimierung muss nicht neu gestartet werden). Durch diese Änderungen wird bei der Deduplizierung von Dateien mit einer Größe von bis zu 1 TB eine erstklassige Leistung erzielt.
Unterstützung für Nano Server
Welchen Nutzen bietet diese Änderung?
Nano Server ist eine neue monitorlose Bereitstellungsoption in Windows Server 2016 mit wesentlich geringerer Systemressourcennutzung und erheblich kürzerer Startzeit, für die weniger Updates und Neustarts erforderlich sind als bei der Windows Server Core-Bereitstellungsoption. Die Datendeduplizierung wird bei Nano Server vollständig unterstützt. Weitere Informationen zu Nano Server finden Sie unter Getting Started with Nano Server (Erste Schritte mit Nano Server).
Vereinfachte Konfigurationen für virtualisierte Sicherungsanwendungen
Welchen Nutzen bietet diese Änderung?
Die Datendeduplizierung für virtualisierte Sicherungsanwendungen wird in Windows Server 2012 R2 unterstützt, die Deduplizierungseinstellungen müssen aber bei dieser Windows Server-Version manuell angepasst und optimiert werden. Ab Windows Server 2016 wurde die Konfiguration der Deduplizierung für virtualisierte Sicherungsanwendungen stark vereinfacht. Beim Aktivieren der Deduplizierung für ein Volume wird eine vordefinierte Verwendungstypoption verwendet, vergleichbar mit den Optionen für allgemeine Dateiserver und VDI.
Unterstützung für parallele Upgrades des Clusterbetriebssystems
Welchen Nutzen bietet diese Änderung?
Windows Server-Failovercluster, auf denen die Datendeduplizierung ausgeführt wird, können über eine Kombination aus Knoten mit Windows Server 2012 R2-Versionen der Datendeduplizierung und Windows Server 2016-Versionen der Datendeduplizierung verfügen. Diese Verbesserung ermöglicht während eines parallelen Clusterupgrades vollen Datenzugriff auf alle deduplizierten Volumes, sodass der Rollout der neuen Datendeduplizierungsversion auf einem vorhandenen Windows Server 2012 R2-Cluster schrittweise erfolgen kann. Auf diese Weise lässt sich Downtime verhindern, da die Knoten nicht gleichzeitig, sondern nacheinander aktualisiert werden.
Worin bestehen die Unterschiede?
Bei früheren Versionen von Windows Server mussten alle Knoten eines Windows Server-Failoverclusters dieselbe Windows Server-Version aufweisen. Ab Windows Server 2016 ermöglicht das Feature für parallele Clusterupgrades die Ausführung des Clusters im gemischten Modus. Die Datendeduplizierung unterstützt diese neue Clusterkonfiguration im gemischten Modus, um während eines parallelen Clusterupgrades vollen Datenzugriff zu ermöglichen.