Pipelineausführung und Trigger in Azure Data Factory oder Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Eine Pipelineausführung in Azure Data Factory und Azure Synapse Analytics definiert eine Instanz einer Pipelineausführung. Beispiel: Angenommen, Sie verfügen über eine Pipeline, die um 8:00, 9:00 und 10:00 Uhr ausgeführt wird. In diesem Fall erfolgen drei separate Ausführungen der Pipeline (oder Pipelineausführungen). Jede Pipelineausführung besitzt eine eindeutige Pipelineausführungs-ID. Eine Ausführungs-ID ist eine GUID, die die jeweilige Pipelineausführung eindeutig definiert.
Zur Instanziierung von Pipelineausführungen werden in der Regel Argumente an in der Pipeline definierte Parameter übergeben. Sie können eine Pipeline entweder manuell oder mithilfe eines Triggers ausführen. Dieser Artikel enthält Informationen zu beiden Möglichkeiten der Ausführung einer Pipeline.
Erstellen von Triggern über die Benutzeroberfläche
Wählen Sie oben im Pipeline-Editor „Trigger hinzufügen“ aus, um eine Pipeline manuell auszulösen oder ein neues geplantes rollierendes Fenster, ein Speicherereignis oder einen benutzerdefinierten Ereignistrigger zu konfigurieren.
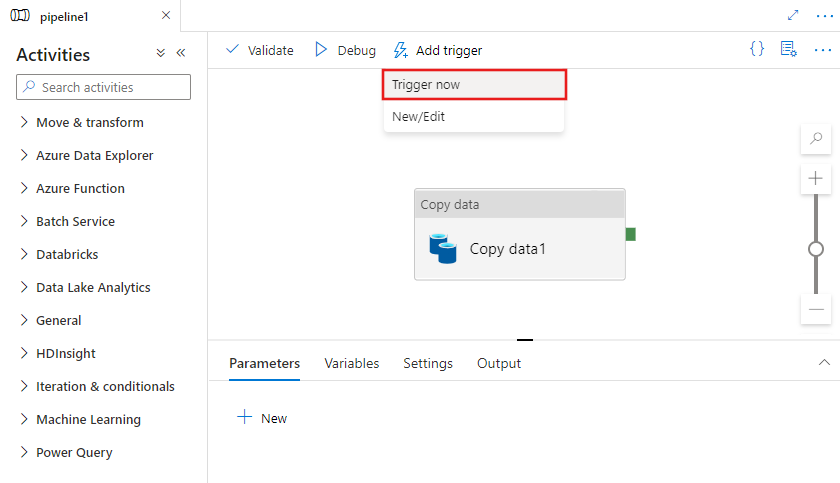
Wenn Sie die Pipeline manuell auslösen möchten, wird sie sofort ausgeführt. Andernfalls werden Sie bei Auswahl von „Neu/Bearbeiten“ mit dem Fenster „Trigger hinzufügen“ aufgefordert, entweder einen vorhandenen zu bearbeitenden Trigger auszuwählen oder einen neuen Trigger zu erstellen.
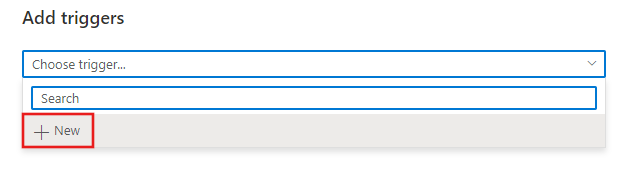
Daraufhin wird das Triggerkonfigurationsfenster angezeigt, in dem Sie den Triggertyp auswählen können.
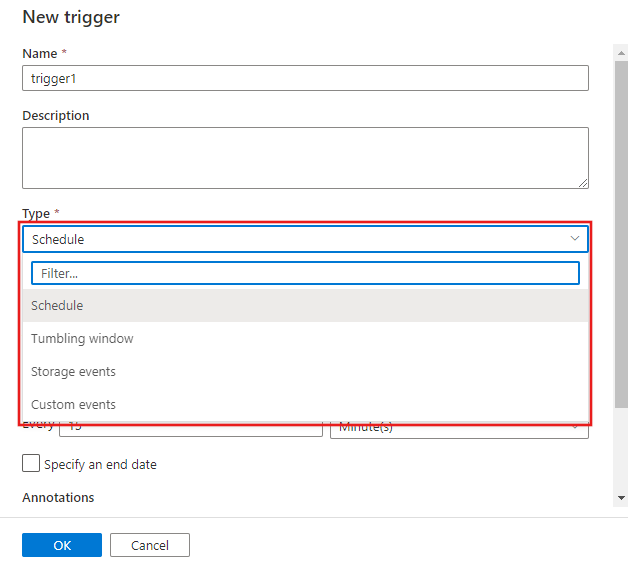
Weitere Informationen zu geplanten, rollierendes Fenster-, Speicherereignis- und benutzerdefiniertes Ereignis-Trigger erfahren Sie weiter unten.
Manuelle Ausführung mit JSON
Die manuelle Ausführung einer Pipeline wird auch als bedarfsgesteuerte Ausführung bezeichnet.
Beispiel: Angenommen, Sie haben eine allgemeine Pipeline mit dem Namen copyPipeline, die Sie ausführen möchten. Dabei handelt es sich um eine Pipeline mit einer einzelnen Aktivität, die Daten aus einem Azure Blob Storage-Quellordner in einen Zielordner im selben Speicher kopiert. Die folgende JSON-Definition zeigt diese Beispielpipeline:
{
"name": "copyPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
},
"name": "CopyBlobtoBlob",
"inputs": [
{
"referenceName": "sourceBlobDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "sinkBlobDataset",
"type": "DatasetReference"
}
]
}
],
"parameters": {
"sourceBlobContainer": {
"type": "String"
},
"sinkBlobContainer": {
"type": "String"
}
}
}
}
In der JSON-Definition nutzt die Pipeline nutzt zwei Parameter: sourceBlobContainer und sinkBlobContainer. Sie können Werte an diese Parameter zur Laufzeit übergeben.
Manuelle Ausführung mit anderen APIs/SDKs
Sie können Ihre Pipeline manuell mit einer der folgenden Methoden ausführen:
- .NET SDK
- Azure PowerShell-Modul
- REST-API
- Python SDK
.NET SDK
Der folgende Beispielaufruf zeigt, wie Ihre Pipeline mithilfe des .NET SDK manuell ausgeführt wird:
client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, parameters)
Ein vollständiges Beispiel finden Sie unter Schnellstart: Erstellen einer Data Factory mit dem .NET SDK.
Hinweis
Mit dem .NET SDK können Sie Pipelines aus Azure Functions, Ihren Webdiensten usw. aufrufen.
Azure PowerShell
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Der folgende Befehl zeigt, wie Ihre Pipeline manuell mithilfe von Azure PowerShell ausgeführt wird:
Invoke-AzDataFactoryV2Pipeline -DataFactory $df -PipelineName "Adfv2QuickStartPipeline" -ParameterFile .\PipelineParameters.json -ResourceGroupName "myResourceGroup"
Sie übergeben Parameter im Text in der Anforderungsnutzlast. Im .NET SDK, in Azure PowerShell und im Python SDK werden Werte in einem Wörterbuch übergeben, das als Argument an den Aufruf übergeben wird:
{
"sourceBlobContainer": "MySourceFolder",
"sinkBlobContainer": "MySinkFolder"
}
Die Antwortnutzlast ist eine eindeutige ID der Pipelineausführung:
{
"runId": "0448d45a-a0bd-23f3-90a5-bfeea9264aed"
}
Ein vollständiges Beispiel finden Sie unter Schnellstart: Erstellen einer Data Factory mit Azure PowerShell.
Python SDK
Ein vollständiges Beispiel finden Sie unter Schnellstart: Erstellen einer Datenfactory und Pipeline mit Python.
REST-API
Der folgende Befehl zeigt, wie Ihre Pipeline mithilfe der REST-API manuell ausgeführt wird:
POST
https://management.azure.com/subscriptions/mySubId/resourceGroups/myResourceGroup/providers/Microsoft.DataFactory/factories/myDataFactory/pipelines/copyPipeline/createRun?api-version=2017-03-01-preview
Ein vollständiges Beispiel finden Sie unter Schnellstart: Erstellen einer Data Factory mit der REST-API.
Triggerausführung mit JSON
Eine Pipelineausführung kann auch mithilfe von Triggern erfolgen. Trigger stellen eine Verarbeitungseinheit dar, die bestimmt, wann eine Pipelineausführung initiiert werden soll. Derzeit unterstützt der Dienst drei Arten von Triggern:
Zeitplantrigger: Ein Trigger, der eine Pipeline nach einem Realzeitplan aufruft.
Trigger für ein rollierendes Fenster: Ein Trigger, der in einem regelmäßigen Intervall ausgeführt wird, während der Zustand beibehalten wird.
Ereignisbasierter Trigger: Ein Trigger, der auf ein Ereignis reagiert.
Pipelines und Trigger haben eine m:m-Beziehung (außer beim Trigger mit rollierendem Fenster). Mehrere Trigger können eine einzelne Pipeline starten, oder ein einzelner Trigger kann mehrere Pipelines starten. In der folgenden Triggerdefinition bezieht sich die Pipelines-Eigenschaft auf eine Liste von Pipelines, die vom jeweiligen Trigger ausgelöst werden. Die Eigenschaftendefinition enthält Werte für die Pipelineparameter.
Grundlegende Triggerdefinition
{
"properties": {
"name": "MyTrigger",
"type": "<type of trigger>",
"typeProperties": {...},
"pipelines": [
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "<Name of your pipeline>"
},
"parameters": {
"<parameter 1 Name>": {
"type": "Expression",
"value": "<parameter 1 Value>"
},
"<parameter 2 Name>": "<parameter 2 Value>"
}
}
]
}
}
Zeitplantrigger mit JSON
Ein Zeitplantrigger führt Pipelines nach einem Realzeitplan aus. Dieser Trigger unterstützt regelmäßige und erweiterte Kalenderoptionen. Der Auslöser unterstützt zum Beispiel Intervalle wie "wöchentlich" oder "Montag um 17:00 Uhr und Donnerstag um 21:00 Uhr". Der Zeitplan-Trigger ist flexibel, da das Datensatzmuster unabhängig ist und der Trigger nicht zwischen Zeitseriendaten und Nicht-Zeitseriendaten unterscheidet.
Weitere Informationen zu Zeitplantriggern und Beispiele finden Sie unter Erstellen eines Triggers zum Ausführen einer Pipeline gemäß einem Zeitplan.
Definition für Zeitplantrigger
Wenn Sie einen Zeitplantrigger erstellen, geben den Zeitplan und die Wiederholung mithilfe einer JSON-Definition an.
Damit der Zeitplantrigger die Ausführung der Pipeline startet, verwenden Sie in der Triggerdefinition einen Pipelineverweis auf die jeweilige Pipeline. Pipelines und Trigger haben eine m:m-Beziehung. Mehrere Trigger können eine einzelne Pipeline starten. Ein einzelnder Trigger kann mehrere Pipelines starten.
{
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": <<Minute, Hour, Day, Week, Year>>,
"interval": <<int>>, // How often to fire
"startTime": <<datetime>>,
"endTime": <<datetime>>,
"timeZone": "UTC",
"schedule": { // Optional (advanced scheduling specifics)
"hours": [<<0-24>>],
"weekDays": [<<Monday-Sunday>>],
"minutes": [<<0-60>>],
"monthDays": [<<1-31>>],
"monthlyOccurrences": [
{
"day": <<Monday-Sunday>>,
"occurrence": <<1-5>>
}
]
}
}
},
"pipelines": [
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "<Name of your pipeline>"
},
"parameters": {
"<parameter 1 Name>": {
"type": "Expression",
"value": "<parameter 1 Value>"
},
"<parameter 2 Name>": "<parameter 2 Value>"
}
}
]}
}
Wichtig
Die parameters-Eigenschaft ist eine erforderliche Eigenschaft des pipelines-Elements. Wenn für Ihre Pipeline keine Parameter verwendet werden, müssen Sie eine leere JSON-Definition für die parameters-Eigenschaft einfügen.
Schemaübersicht
Die folgende Tabelle enthält eine allgemeine Übersicht über die wichtigsten Schemaelemente im Zusammenhang mit der Wiederholung und Zeitplanung eines Triggers:
| JSON-Eigenschaft | BESCHREIBUNG |
|---|---|
| startTime | Ein Datums-/Uhrzeitwert. Bei allgemeinen Zeitplänen gilt der Wert der startTime-Eigenschaft für das erste Vorkommen. Bei komplexen Zeitplänen wird der Trigger frühestens beim festgelegten startTime-Wert gestartet. |
| endTime | Enddatum und -uhrzeit für den Trigger. Der Trigger wird am angegebenen Enddatum und der Enduhrzeit beendet. Der Wert für die Eigenschaft darf nicht in der Vergangenheit liegen. |
| timeZone | Die Zeitzone. Eine Liste der unterstützten Zeitzonen finden Sie unter Erstellen eines Triggers zum Ausführen einer Pipeline gemäß einem Zeitplan. |
| recurrence | Ein recurrence-Objekt, das die Wiederholungsregeln für den Trigger angibt. Das recurrence-Objekt unterstützt die Elemente frequency, interval, endTime, count und schedule. Wenn ein recurrence-Objekt definiert ist, ist das frequency-Element erforderlich. Die anderen Elemente des recurrence-Objekts sind optional. |
| frequency | Die Einheit der Häufigkeit, mit welcher der Trigger wiederholt wird. Zu den unterstützten Werten gehören „minute“, „hour“, „day“, „week“ und „month“. |
| interval | Eine positive ganze Zahl, die das Intervall für den frequency-Wert angibt. Der frequency-Wert bestimmt, wie oft der Trigger ausgeführt wird. Ist interval also beispielsweise auf „3“ und frequency auf „week“ festgelegt, wird der Trigger alle drei Wochen ausgeführt. |
| schedule | Der Wiederholungszeitplan für den Trigger. Die Wiederholung eines Triggers mit einem festgelegten frequency-Wert wird auf der Grundlage eines Wiederholungszeitplans angepasst. Die schedule-Eigenschaft enthält Anpassungen für die Wiederholung auf der Grundlage von Minuten, Stunden, Wochentagen, Monatstagen und Wochennummer. |
Beispiel für Zeitplantrigger
{
"properties": {
"name": "MyTrigger",
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": "Hour",
"interval": 1,
"startTime": "2017-11-01T09:00:00-08:00",
"endTime": "2017-11-02T22:00:00-08:00"
}
},
"pipelines": [{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "SQLServerToBlobPipeline"
},
"parameters": {}
},
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "SQLServerToAzureSQLPipeline"
},
"parameters": {}
}
]
}
}
Schemastandards, Einschränkungen und Beispiele
| JSON-Eigenschaft | type | Erforderlich | Standardwert | Gültige Werte | Beispiel |
|---|---|---|---|---|---|
| startTime | Zeichenfolge | Ja | Keine | Datum/Uhrzeit (nach ISO 8601) | "startTime" : "2013-01-09T09:30:00-08:00" |
| recurrence | Objekt (object) | Ja | Keine | Wiederholungsobjekt | "recurrence" : { "frequency" : "monthly", "interval" : 1 } |
| interval | number | Nein | 1 | 1 bis 1.000 | "interval":10 |
| endTime | Zeichenfolge | Ja | Keine | Ein Datums-/Uhrzeitwert, der eine Zeit in der Zukunft darstellt | "endTime" : "2013-02-09T09:30:00-08:00" |
| schedule | Objekt (object) | Nein | Keine | Zeitplanobjekt | "schedule" : { "minute" : [30], "hour" : [8,17] } |
startTime-Eigenschaft
Die folgende Tabelle zeigt, wie die startTime-Eigenschaft eine Triggerausführung steuert:
| startTime-Wert | Wiederholung ohne Zeitplan | Wiederholung mit Zeitplan |
|---|---|---|
| Startuhrzeit in der Vergangenheit | Berechnet die erste zukünftige Ausführungszeit nach der Startzeit und nimmt die Ausführung zu diesem Zeitpunkt vor. Führt weitere Ausführungen aus, die auf der Grundlage der letzten Ausführungszeit berechnet wurden. Betrachten Sie das Beispiel nach dieser Tabelle. |
Der Trigger startet frühestens zur angegebenen Startzeit. Das erste Vorkommen basiert auf dem Zeitplan, der auf der Grundlage der Startzeit berechnet wird. Berechnet weitere Ausführungen auf Grundlage des Wiederholungszeitplans. |
| Startzeit in der Zukunft oder aktuelle Uhrzeit | Wird einmalig zur angegebenen Startzeit ausgeführt. Führt weitere Ausführungen aus, die auf der Grundlage der letzten Ausführungszeit berechnet wurden. |
Der Trigger startet frühestens zur angegebenen Startzeit. Das erste Vorkommen basiert auf dem Zeitplan, der auf der Grundlage der Startzeit berechnet wird. Berechnet weitere Ausführungen auf Grundlage des Wiederholungszeitplans. |
Das folgende Beispiel veranschaulicht, was passiert, wenn die Startzeit in der Vergangenheit liegt und nur eine Wiederholung, aber kein Zeitplan angegeben ist. Nehmen Sie beispielsweise an, dass die aktuelle Uhrzeit „2017-04-08 13:00“ und die Startzeit „2017-04-07 14:00“ ist und die Wiederholung alle zwei Tage erfolgt. (Der recurrence-Wert wird definiert, indem die frequency-Eigenschaft auf „day“ und die interval-Eigenschaft auf „2“ festgelegt wird.) Beachten Sie, dass der startTime-Wert in der Vergangenheit liegt.
Unter diesen Umständen erfolgt die erste Ausführung am 09.04.2017 um 14:00 Uhr. Die Scheduler-Engine berechnet die Ausführungen auf Grundlage der Startzeit. In der Vergangenheit liegende Instanzen werden verworfen. Die Engine verwendet die nächste in der Zukunft liegende Instanz. In diesem Szenario ist die Startzeit der 07.04.2017 um 14 Uhr. Die nächste Instanz folgt zwei Tage nach diesem Zeitpunkt, also um am 09.04.2017 um 14 Uhr.
Die erste Ausführungszeit ist auch dieselbe, wenn „2017-04-05 14:00“ oder „2017-04-01 14:00“ für startTime angegeben ist. Nach der ersten Ausführung werden nachfolgende Ausführungen anhand des Zeitplans berechnet. Daher erfolgen die weiteren Ausführungen am 11.04.2017 um 14 Uhr, am 13.04.2017 um 14 Uhr, am 15.04.2017 um 14 Uhr usw.
Wenn die Stunden oder Minuten im Zeitplan für einen Trigger nicht festgelegt sind, werden die Stunden oder Minuten der ersten Ausführung als Standardwerte verwendet.
schedule-Eigenschaft
Mithilfe von schedule lässt sich die Anzahl von Triggerausführungen begrenzen. Beispiel: Wenn für einen Trigger mit einer monatlichen Häufigkeit nur die Ausführung am 31. Tag geplant ist, wird der Trigger nur in Monaten mit 31 Tagen ausgeführt.
Mithilfe von schedule lässt sich die Anzahl von Triggerausführungen auch erweitern. Beispiel: Ein Trigger mit einem monatlichen Intervall, dessen Ausführung für die Monatstage 1 und 2 geplant ist, wird an den 1. und 2. Tagen des Monats anstatt einmal im Monat ausgeführt.
Bei Angabe mehrerer schedule-Elemente werden die Zeitplaneinstellungen in absteigender Reihenfolge ausgewertet – also von der Wochennummer über Monatstag und Wochentag bis hin zu Stunde und Minute.
Die folgende Tabelle enthält eine ausführliche Beschreibung der schedule-Elemente:
| JSON-Element | BESCHREIBUNG | Gültige Werte |
|---|---|---|
| minutes | Minuten der Stunde, zu denen der Trigger ausgeführt wird | – Integer – Array mit ganzen Zahlen |
| hours | Stunden des Tages, zu denen der Trigger ausgeführt wird | – Integer – Array mit ganzen Zahlen |
| weekDays | Tage der Woche, an denen der Trigger ausgeführt wird Der Wert kann nur bei wöchentlicher Häufigkeit angegeben werden. | – „Monday“ – „Tuesday“ – „Wednesday“ – „Thursday“ – „Friday“ – „Saturday“ – „Sunday“ – Array von Tageswerten (die maximale Arraygröße ist 7) Bei Tageswerten wird nicht zwischen Groß- und Kleinschreibung unterschieden. |
| monthlyOccurrences | Tage des Monats, an denen der Trigger ausgeführt wird. Der Wert kann nur bei monatlicher Häufigkeit angegeben werden. | Array mit monthlyOccurrence-Objekten: { "day": day, "occurrence": occurrence }– Das day-Attribut ist der Tag der Woche, an dem der Trigger ausgeführt wird. Beispiel: Eine monthlyOccurrences-Eigenschaft mit dem day-Wert {Sunday} bedeutet jeden Sonntag des Monats. Das day-Attribut ist erforderlich.– Das occurrence-Attribut ist das Vorkommen des angegebenen day-Attributs innerhalb des Monats. Beispiel: Eine monthlyOccurrences-Eigenschaft mit dem day- und occurrence-Wert {Sunday, -1} bedeutet den letzten Sonntag des Monats. Das occurrence-Attribut ist optional. |
| monthDays | Tag des Monats, an dem der Trigger ausgeführt wird. Der Wert kann nur bei monatlicher Häufigkeit angegeben werden. | – Beliebiger Wert, für den Folgendes gilt: <= -1 and >= -31 – Beliebiger Wert, für den Folgendes gilt: >= 1 und <= 31 – Array von Werten |
Trigger für ein rollierendes Fenster
Trigger für ein rollierendes Fenster werden ab einem angegebenen Startzeitpunkt in regelmäßigen Zeitintervallen ausgelöst, während der Zustand beibehalten wird. Bei rollierenden Fenstern handelt es sich um eine Reihe von nicht überlappenden, aneinandergrenzenden Zeitintervallen mit einer festen Größe.
Weitere Informationen zu Triggern für ein rollierendes Fenster und Beispiele finden Sie unter Erstellen eines Triggers zum Ausführen einer Pipeline für ein rollierendes Fenster.
Beispiele für Wiederholungszeitpläne von Triggern
Dieser Abschnitt enthält Beispiele für Wiederholungszeitpläne. Der Schwerpunkt liegt auf dem schedule-Objekt und seinen Elementen.
In den Beispielen wird angenommen, dass der interval-Wert „1“ festgelegt ist, und der frequency-Wert gemäß der Zeitplandefinition richtig ist. Beispielsweise können nicht gleichzeitig der frequency-Wert „day“ und die Änderung monthDays im schedule-Objekt angegeben werden. Diese Arten von Beschränkungen sind in der Tabelle im vorherigen Abschnitt beschrieben.
| Beispiel | BESCHREIBUNG |
|---|---|
{"hours":[5]} |
Ausführung täglich um 05:00 Uhr. |
{"minutes":[15], "hours":[5]} |
Ausführung täglich um 05:15 Uhr. |
{"minutes":[15], "hours":[5,17]} |
Ausführung täglich um 05:15 und 17:15 Uhr. |
{"minutes":[15,45], "hours":[5,17]} |
Ausführung täglich um 05:15 Uhr, 05:45 Uhr, 17:15 Uhr und 17:45 Uhr. |
{"minutes":[0,15,30,45]} |
Ausführung alle 15 Minuten. |
{hours":[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]} |
Stündliche Ausführung. Dieser Trigger wird stündlich ausgeführt. Die Minuten werden vom startTime-Wert gesteuert, wenn ein Wert angegeben ist. Wenn kein Wert angegeben ist, werden die Minuten von der Erstellungszeit gesteuert. Lautet die Start- oder Erstellungszeit also beispielsweise 12:25 Uhr, wird der Trigger um 00:25 Uhr, 01:25 Uhr, 02:25 Uhr etc. und um 23:25 Uhr ausgeführt. Dieser Zeitplan entspricht einem Trigger mit dem frequency-Wert „hour“, dem interval-Wert „1“ und ohne schedule-Wert. Dieser Zeitplan kann mit anderen Werten für frequency und interval auch zur Erstellung anderer Trigger verwendet werden. Beispiel: Mit dem frequency-Wert „month“ wird der Zeitplan nur einmal im Monat ausgeführt statt wie beim frequency-Wert „day“ jeden Tag. |
{"minutes":[0]} |
Ausführung jeweils zur vollen Stunde. Dieser Trigger wird immer zur vollen Stunde ab 00:00 Uhr (dann 01:00 Uhr, 02:00 Uhr und so weiter) ausgeführt. Dieser Zeitplan entspricht einem Trigger mit dem frequency-Wert „hour“ und einem startTime-Wert von null Minuten und ohne schedule-Wert, aber mit dem frequency-Wert „day“. Wenn der frequency-Wert „week“ oder „month“ ist, wird der Zeitplan nur an einem Tag in der Woche bzw. im Monat ausgeführt. |
{"minutes":[15]} |
Stündliche Ausführung jeweils 15 Minuten nach der vollen Stunde. Dieser Trigger wird stündlich immer 15 Minuten nach der vollen Stunde ab 00:15 Uhr, dann 01:15 Uhr, 02:15 Uhr und so weiter ausgeführt und endet um 23:15 Uhr. |
{"hours":[17], "weekDays":["saturday"]} |
Wöchentliche Ausführung, immer samstags um 17:00 Uhr. |
{"hours":[17], "weekDays":["monday", "wednesday", "friday"]} |
Wöchentliche Ausführung am Montag, Mittwoch und Freitag, jeweils um 17:00 Uhr. |
{"minutes":[15,45], "hours":[17], "weekDays":["monday", "wednesday", "friday"]} |
Wöchentliche Ausführung am Montag, Mittwoch und Freitag, jeweils um 17:15 und 17:45 Uhr. |
{"minutes":[0,15,30,45], "weekDays":["monday", "tuesday", "wednesday", "thursday", "friday"]} |
Ausführung an Wochentagen im 15-Minuten-Takt. |
{"minutes":[0,15,30,45], "hours": [9, 10, 11, 12, 13, 14, 15, 16] "weekDays":["monday", "tuesday", "wednesday", "thursday", "friday"]} |
Ausführung an Wochentagen zwischen 09:00 Uhr und 16:45 Uhr im 15-Minuten-Takt. |
{"weekDays":["tuesday", "thursday"]} |
Ausführung jeweils dienstags und donnerstags zur festgelegten Startzeit. |
{"minutes":[0], "hours":[6], "monthDays":[28]} |
Ausführung um 06:00 Uhr am 28. Tag des Monats (bei einem frequency-Wert von „month“) |
{"minutes":[0], "hours":[6], "monthDays":[-1]} |
Ausführung um 06:00 Uhr am letzten Tag des Monats. Zur Ausführung eines Triggers am letzten Tag eines Monats verwenden Sie „-1“ anstatt Tag 28, 29, 30 oder 31. |
{"minutes":[0], "hours":[6], "monthDays":[1,-1]} |
Ausführung jeweils am ersten und letzten Tag jedes Monats um 06:00 Uhr. |
{monthDays":[1,14]} |
Ausführung jeweils am ersten und 14. Tag jedes Monats zur festgelegten Startzeit |
{"minutes":[0], "hours":[5], "monthlyOccurrences":[{"day":"friday", "occurrence":1}]} |
Ausführung am ersten Freitag jedes Monats um 05:00 Uhr. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":1}]} |
Ausführung am ersten Freitag jedes Monats zur festgelegten Startzeit. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":-3}]} |
Monatliche Ausführung am dritten Freitag ab Monatsende zur festgelegten Startzeit. |
{"minutes":[15], "hours":[5], "monthlyOccurrences":[{"day":"friday", "occurrence":1},{"day":"friday", "occurrence":-1}]} |
Ausführung am ersten und letzten Freitag jedes Monats um 05:15 Uhr. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":1},{"day":"friday", "occurrence":-1}]} |
Ausführung am ersten und letzten Freitag jedes Monats zur festgelegten Startzeit. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":5}]} |
Ausführung am fünften Freitag jedes Monats zur festgelegten Startzeit. Wenn kein fünfter Freitag im Monat vorhanden ist, wird die Pipeline nicht ausgeführt. Zur Ausführung des Triggers am letzten Freitag des Monats empfiehlt sich u.U. die Verwendung von „-1“ anstelle von „5“ als occurrence-Wert. |
{"minutes":[0,15,30,45], "monthlyOccurrences":[{"day":"friday", "occurrence":-1}]} |
Ausführung im 15-Minuten-Takt am letzten Freitag des Monats. |
{"minutes":[15,45], "hours":[5,17], "monthlyOccurrences":[{"day":"wednesday", "occurrence":3}]} |
Ausführung um 05:15, 05:45, 17:15 und 17:45 Uhr am dritten Mittwoch jedes Monats. |
Vergleich von Triggertypen
Der Trigger für ein rollierendes Fenster und der Zeitplantrigger basieren jeweils auf Zeit-Heartbeats. Inwiefern unterscheiden sie sich?
Hinweis
Mit der Ausführung des Triggers für ein rollierendes Fenster wird gewartet, bis die ausgelöste Pipelineausführung beendet ist. Der Ausführungszustand gibt den Status der ausgelösten Pipelineausführung wieder. Wenn beispielsweise eine ausgelöste Pipelineausführung abgebrochen wird, wird die entsprechende Ausführung des Triggers für ein rollierendes Fenster als abgebrochen gekennzeichnet. Dies unterscheidet sich vom „Fire-and-Forget“-Verhalten (Auslösen und Vergessen) des Zeitplantriggers, das als erfolgreich gekennzeichnet wird, sofern eine Pipelineausführung gestartet wurde.
In der folgenden Tabelle werden der Trigger für ein rollierendes Fenster und der Zeitplantrigger verglichen:
| Element | Trigger für ein rollierendes Fenster | Zeitplantrigger |
|---|---|---|
| Abgleichsszenarien | Unterstützt. Pipelineausführungen können für Fenster in der Vergangenheit geplant werden. | Wird nicht unterstützt. Pipelineausführungen können nur in Zeiträumen ab der aktuellen Zeit und der Zukunft ausgeführt werden. |
| Zuverlässigkeit | 100 % zuverlässig. Pipelineausführungen können für alle Fenster ab einem festgelegten Datum ohne Lücken geplant werden. | Weniger zuverlässig. |
| Wiederholungsfunktion | Unterstützt. Für fehlgeschlagene Pipelineausführungen gilt standardmäßig eine Wiederholungsrichtlinie mit dem Wert 0 oder eine vom Benutzer in der Triggerdefinition angegebene Richtlinie. Eine Wiederholung erfolgt automatisch, wenn Pipelineausführungen aufgrund von Parallelitäts-/Server-/Einschränkungsgrenzwerten (d. h. mit den Statuscodes „400: Benutzerfehler“, „429: Zu viele Anforderungen“ und „500: Interner Serverfehler“) fehlschlagen. | Wird nicht unterstützt. |
| Concurrency | Unterstützt. Benutzer können Parallelitätsgrenzwerte für den Trigger explizit festlegen. Zwischen 1 und 50 parallele ausgelöste Pipelineausführungen sind zulässig. | Wird nicht unterstützt. |
| Systemvariablen | Neben @trigger().scheduledTime und @trigger().startTime unterstützt es auch die Verwendung der Systemvariablen WindowStart und WindowEnd. Benutzer haben Zugriff auf trigger().outputs.windowStartTime und trigger().outputs.windowEndTime als Systemvariablen in der Triggerdefinition. Die Werte werden jeweils als Start- und Endzeit des Fensters verwendet. Beispiel: Die Definition eines stündlich ausgeführten Triggers für ein rollierendes Fenster lautet für das Fenster von 1:00 Uhr bis 2:00 Uhr trigger().outputs.windowStartTime = 2017-09-01T01:00:00Z und trigger().outputs.windowEndTime = 2017-09-01T02:00:00Z. |
Unterstützt nur @trigger().scheduledTime@trigger().startTime Standardvariablen und Variablen. |
| Beziehung zwischen Pipeline und Trigger | Unterstützt eine 1:1-Beziehung. Nur eine Pipeline kann ausgelöst werden. | Unterstützt m:m-Beziehungen. Mehrere Trigger können eine einzelne Pipeline starten. Ein einzelnder Trigger kann mehrere Pipelines starten. |
Ereignisbasierter Trigger
Ein ereignisbasierter Auslöser führt Pipelines als Reaktion auf ein Ereignis aus. Es gibt zwei Arten von ereignisbasierten Triggern.
- Ein Speicherereignisauslöser führt eine Pipeline bei Ereignissen aus, die in einem Speicherkonto auftreten, z. B. das Eintreffen einer Datei oder das Löschen einer Datei im Azure Blob Storage-Konto.
- Ein Auslöser für benutzerdefinierte Ereignisse verarbeitet und behandelt benutzerdefinierte Artikel in Event Grid.
Weitere Informationen zu ereignisbasierten Auslösern finden Sie unter Speicherereignis auslöser und Auslöser für benutzerdefinierte Ereignisse.
Zugehöriger Inhalt
Arbeiten Sie die folgenden Tutorials durch: