Kopieren und Transformieren von Daten in Azure Database for MySQL mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe der Copy-Aktivität in Azure Data Factory- oder Synapse Analytics-Pipelines aus und in Azure Database for MySQL kopieren sowie Daten mit einem Datenfluss in Azure Database for MySQL transformieren. Weitere Informationen finden Sie in den Einführungsartikeln zu Azure Data Factory und Synapse Analytics.
Dieser Connector ist spezialisiert auf
Verwenden Sie MySQL-Connector, um Daten aus der generischen MySQL-Datenbank zu kopieren, die lokal oder in der Cloud angeordnet ist.
Voraussetzungen
Dieser Schnellstart erfordert die folgenden Ressourcen und Konfigurationen, die unten als Ausgangspunkt genannt sind:
- Eine vorhandene Azure-Datenbank für MySQL-Einzelserver oder MySQL Flexibler Server mit öffentlichem Zugriff oder privatem Endpunkt.
- Aktivieren Sie Öffentlichen Zugriff auf diesen Server über beliebigen Azure-Dienst in Azure gestatten auf der Netzwerkseite des MySQL-Servers. Dadurch können Sie Data Factory Studio verwenden.
Unterstützte Funktionen
Dieser Azure Database for MySQL-Connector wird für folgende Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② | ✓ |
| Zuordnungsdatenfluss (Quelle/Senke) | ① | ✓ |
| Lookup-Aktivität | ① ② | ✓ |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
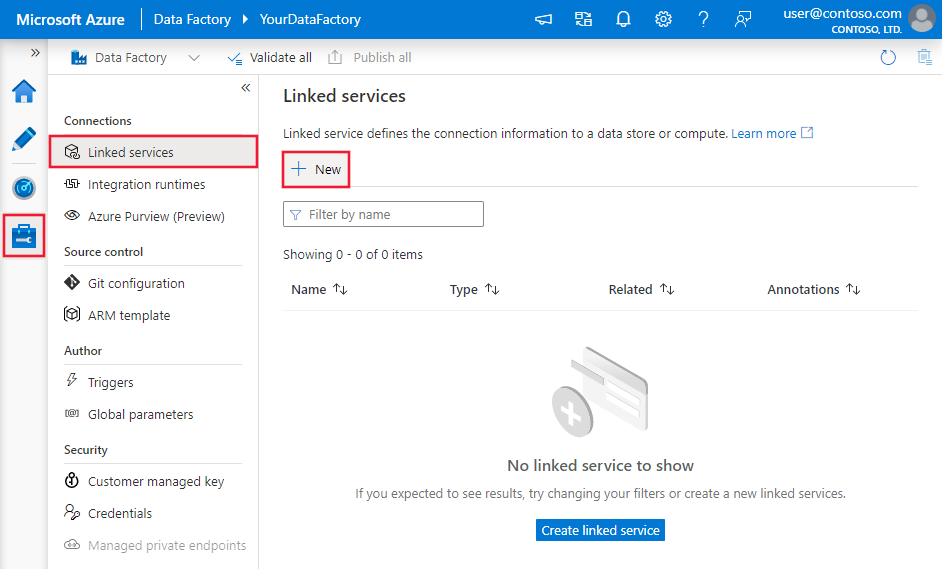
Erstellen eines mit Azure Database for MySQL verknüpften Dienstes über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen mit Azure Database for MySQL verknüpften Dienst in der Azure-Portal-Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie auf „Neu“:
Suchen Sie nach „MySQL“, und wählen Sie den Azure Database for MySQL-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den Azure Database for MySQL-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den verknüpften Azure Database for MySQL-Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Folgendes festgelegt werden: AzureMySql | Ja |
| connectionString | Geben Sie Informationen an, die zum Herstellen einer Verbindung mit der Azure Database for MySQL-Instanz erforderlich sind. Sie können auch das Kennwort in Azure Key Vault speichern und die password-Konfiguration aus der Verbindungszeichenfolge pullen. Ausführlichere Informationen finden Sie in den folgenden Beispielen und im Artikel Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Sie können die Azure-Integrationslaufzeit oder selbstgehostete Integrationslaufzeit verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Eine typische Verbindungszeichenfolge ist Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Weitere Eigenschaften, die Sie für Ihren Fall festlegen können:
| Eigenschaft | BESCHREIBUNG | Tastatur | Erforderlich |
|---|---|---|---|
| SSLMode | Diese Option gibt an, ob der Treiber beim Herstellen der Verbindung mit MySQL die TLS-Verschlüsselung und -Überprüfung verwendet. Beispiel: SSLMode=<0/1/2/3/4> |
DISABLED (0) / PREFERRED (1) (Standard) / REQUIRED (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | Nein |
| UseSystemTrustStore | Diese Option gibt an, ob ein Zertifizierungsstellenzertifikat aus dem Vertrauensspeicher des Systems oder aus einer angegebenen PEM-Datei verwendet werden soll. Beispiel: UseSystemTrustStore=<0/1>; |
Enabled (1) / Disabled (0) (Standard) | Nein |
Beispiel:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Speichern des Kennworts in Azure Key Vault
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste mit den Eigenschaften, die vom Azure Database for MySQL-Dataset unterstützt werden.
Legen Sie die „type“-Eigenschaft des Datasets auf AzureMySqlTable fest, um Daten von Azure Database for MySQL zu kopieren. Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf folgenden Wert festgelegt werden: AzureMySqlTable | Ja |
| tableName | Name der Tabelle in der MySQL-Datenbank. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste mit den Eigenschaften, die von der Azure Database for MySQL-Quelle und -Senke unterstützt werden.
Azure Database for MySQL als Quelle
Beim Kopieren von Daten aus Azure Database for MySQL werden die folgenden Eigenschaften im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: AzureMySqlSource | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Beispiel: "SELECT * FROM MyTable". |
Nein (wenn „tableName“ im Dataset angegeben ist) |
| queryCommandTimeout | Die Wartezeit vor dem Timeout der Abfrageanforderung. Die Standardeinstellung ist 120 Minuten (02:00:00). | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for MySQL als Senke
Beim Kopieren von Daten nach Azure Database for MySQL werden die folgenden Eigenschaften im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Senke der Kopieraktivität muss auf Folgendes festgelegt sein: AzureMySqlSink | Ja |
| preCopyScript | Geben Sie eine SQL-Abfrage für die Kopieraktivität an, die ausgeführt werden soll, bevor bei jeder Ausführung Daten in Azure Database for MySQL geschrieben werden. Sie können diese Eigenschaft nutzen, um die vorab geladenen Daten zu bereinigen. | Nein |
| writeBatchSize | Fügt Daten in die Azure Database for MySQL-Tabelle ein, wenn die Puffergröße „writeBatchSize“ erreicht. Als Wert ist eine ganze Zahl (Integer) zulässig, mit der die Anzahl von Zeilen angegeben wird. |
Nein (Standardwert ist 10.000) |
| writeBatchTimeout | Die Wartezeit für den Abschluss der Batcheinfügung, bis das Timeout wirksam wird. Zulässige Werte sind Timespan-Werte. Beispiel: 00:30:00 (30 Minuten). |
Nein (Standardwert ist 00:00:30) |
Beispiel:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten in einen Zuordnungsdatenfluss können Sie über Azure Database for MySQL Tabellen lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen. Sie können ein Azure Database for MySQL-Dataset oder ein Inlinedataset als Quell- und Senkentyp verwenden.
Quellentransformation
In der folgenden Tabelle werden die von der Azure Database for PostgreSQL-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Tabelle | Wenn Sie „Tabelle“ als Eingabe auswählen, ruft der Datenfluss alle Daten aus der im Dataset angegebenen Tabelle ab. | Nein | - | (nur für Inlinedataset) tableName |
| Abfrage | Wenn Sie „Abfrage“ als Eingabe auswählen, geben Sie eine SQL-Abfrage zum Abrufen von Daten aus der Quelle an, die Vorrang vor jeder im Dataset angegebenen Tabelle hat. Die Verwendung von Abfragen stellt eine gute Möglichkeit dar, um die Zeilen für Tests oder Suchvorgänge zu verringern. Die Order By-Klausel wird nicht unterstützt. Sie können aber eine vollständige SELECT FROM-Anweisung festlegen. Sie können auch benutzerdefinierte Tabellenfunktionen verwenden. select * from udfGetData() ist eine benutzerdefinierte Funktion in SQL, mit der eine Tabelle zurückgegeben wird, die Sie im Datenfluss verwenden können. Abfragebeispiel: select * from mytable where customerId > 1000 and customerId < 2000 oder select * from "MyTable". |
Nein | String | Abfrage |
| Gespeicherte Prozedur | Wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen, geben Sie einen Namen der gespeicherten Prozedur an, um Daten aus der Quelltabelle zu lesen, oder wählen Sie „Aktualisieren“ aus, um den Dienst aufzufordern, die Prozedurnamen zu ermitteln. | Ja (wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen) | String | procedureName |
| Prozedurparameter | Wenn Sie „Gespeicherte Prozedur als Eingabe“ auswählen, geben Sie alle Eingabeparameter für die gespeicherte Prozedur in der in der Prozedur festgelegten Reihenfolge an, oder wählen Sie „Importieren“ aus, um alle Prozedurparameter mithilfe des Formulars @paraNamezu importieren. |
Nein | Array | inputs |
| Batchgröße | Geben Sie eine Batchgröße an, um große Datenmengen in Batches zu segmentieren. | Nein | Integer | batchSize |
| Isolationsstufe | Wählen Sie eine der folgenden Isolationsstufen aus: – Lesen zugesichert – Lesen nicht zugesichert (Standard) – Wiederholbarer Lesevorgang – Serialisierbar – Keine (Isolationsstufe ignorieren) |
Nein | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Beispielskript für die Azure DB for MySQL-Quelle
Wenn Sie Azure Database for MySQL als Quelltyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Senkentransformation
In der folgenden Tabelle werden die Eigenschaften aufgeführt, die von der Azure Database for MySQL-Senke unterstützt werden. Sie können diese Eigenschaften auf der Registerkarte Senkenoptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Geben Sie an, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Um Aktualisierungs-, Upsert- oder Löschaktionen auf Zeilen anzuwenden, muss eine Zeilenänderungstransformation zum Kennzeichnen von Zeilen für diese Aktionen erfolgen. |
Ja | true oder false |
deletable insertable updateable upsertable |
| Schlüsselspalten | Für Update-, Upsert- und Löschvorgänge müssen Schlüsselspalten festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll. Der Spaltenname, den Sie als Schlüssel auswählen, wird als Teil der nachfolgenden Update-, Upsert- und Löschvorgänge verwendet. Daher müssen Sie eine Spalte auswählen, die in der Senkenzuordnung vorhanden ist. |
Nein | Array | keys |
| Schreiben von Schlüsselspalten überspringen | Wenn Sie den Wert nicht in die Schlüsselspalte schreiben möchten, wählen Sie „Schreiben von Schlüsselspalten überspringen“ aus. | Nein | true oder false |
skipKeyWrites |
| Aktion table | Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen. - Keine: Es wird keine Aktion an der Tabelle vorgenommen. - Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird. - Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt. |
Nein | true oder false |
Neu erstellen truncate |
| Batchgröße | Geben Sie an, wie viele Zeilen in die einzelnen Batches geschrieben werden. Durch größere Batches werden zwar Komprimierung und Arbeitsspeicheroptimierung verbessert, beim Zwischenspeichern von Daten besteht aber die Gefahr, dass Ausnahmen wegen unzureichenden Arbeitsspeichers auftreten. | Nein | Integer | batchSize |
| Pre- und Post-SQL-Skripts | Geben Sie mehrzeilige SQL-Skripts an, die ausgeführt werden, bevor Daten in die Senkendatenbank geschrieben werden (Vorverarbeitung) und danach (Nachbearbeitung). | Nein | String | preSQLs postSQLs |
Tipp
- Es wird empfohlen, einzelne Batchskripts mit mehreren Befehlen in mehrere Batches aufzuteilen.
- In einem Batch können nur DDL- (Data Definition Language) und DML-Anweisungen (Data Manipulation Language) ausgeführt werden, die eine einfache Updatezählung zurückgeben. Weitere Informationen finden Sie unter Ausführen von Batchvorgängen.
Inkrementelles Extrahieren aktivieren: Verwenden Sie diese Option, um ADF mitzuteilen, nur Zeilen zu verarbeiten, die seit der letzten Ausführung der Pipeline geändert wurden.
Inkrementelle Spalte: Wenn Sie die inkrementelle Extraktfunktion verwenden, müssen Sie die Datums-/Uhrzeitspalte oder numerische Spalte auswählen, die Sie als Wasserzeichen in der Quelltabelle verwenden möchten.
Beginnen Sie mit dem Lesen von Anfang: Wenn Sie diese Option mit inkrementellen Extrakt festlegen, wird ADF angewiesen, alle Zeilen bei der ersten Ausführung einer Pipeline zu lesen, wobei der inkrementelle Extrakt aktiviert ist.
Beispielskript für die Azure DB for MySQL-Senke
Wenn Sie Azure Database for MySQL als Senkentyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Datentypzuordnung für Azure Database for MySQL
Beim Kopieren von Daten aus Azure Database for MySQL werden die folgenden Zuordnungen von MySQL-Datentypen zu den vom Dienst intern verwendeten Zwischendatentypen verwendet. Unter Schema- und Datentypzuordnungen erfahren Sie, wie Sie Aktivitätszuordnungen für Quellschema und Datentyp in die Senke kopieren.
| Azure Database for MySQL-Datentyp | Zwischendatentyp des Diensts |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.