Kopieren von Daten aus Google BigQuery mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Synapse Analytics-Pipelines verwenden, um Daten aus Google BigQuery zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Wichtig
Der neue Google BigQuery-Connector bietet verbesserte native Google BigQuery-Unterstützung. Wenn Sie den Legacyconnector von Google BigQuery in Ihrer Lösung verwenden, upgraden Sie Ihren Google BigQuery-Connector vor dem 31. Oktober 2024. Ausführliche Informationen zum Unterschied zwischen der Legacy- und der neuesten Version finden Sie in diesem Abschnitt .
Unterstützte Funktionen
Für den Google BigQuery-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | ① ② |
| Lookup-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Der Dienst enthält einen integrierten Treiber zum Herstellen der Konnektivität. Aus diesem Grund müssen Sie Treiber für die Verwendung dieses Connectors nicht manuell installieren.
Hinweis
Dieses Google BigQuery-Connector wird basierend auf den BigQuery-APIs erstellt. Beachten Sie, dass BigQuery die maximale Rate eingehender Anforderung begrenzt und entsprechende Kontingente projektbezogen durchsetzt, siehe Kontingente & Limits – API-Anfragen. Stellen Sie sicher, dass Sie nicht zu viele gleichzeitige Anforderungen für das Konto auslösen.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Dienstes mit Google BigQuery über die Benutzeroberfläche
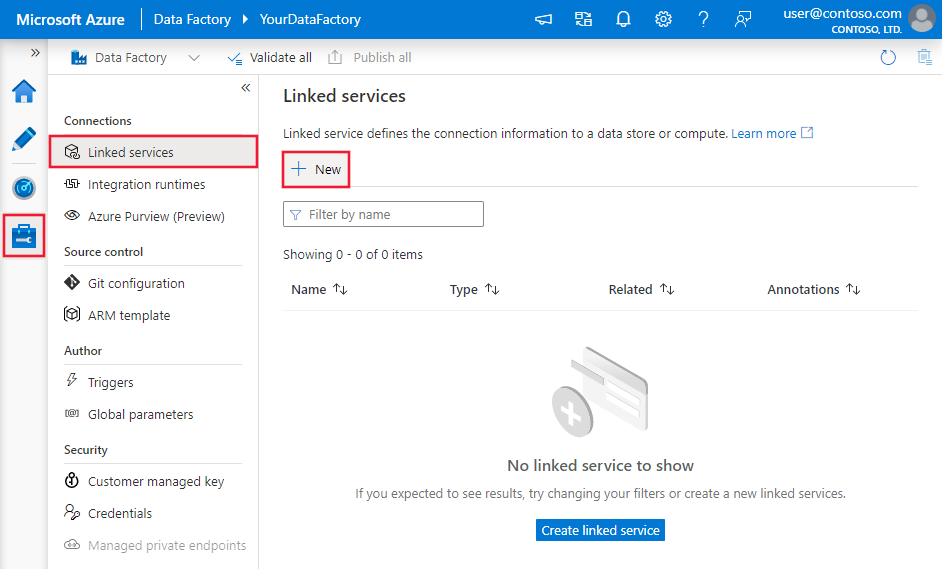
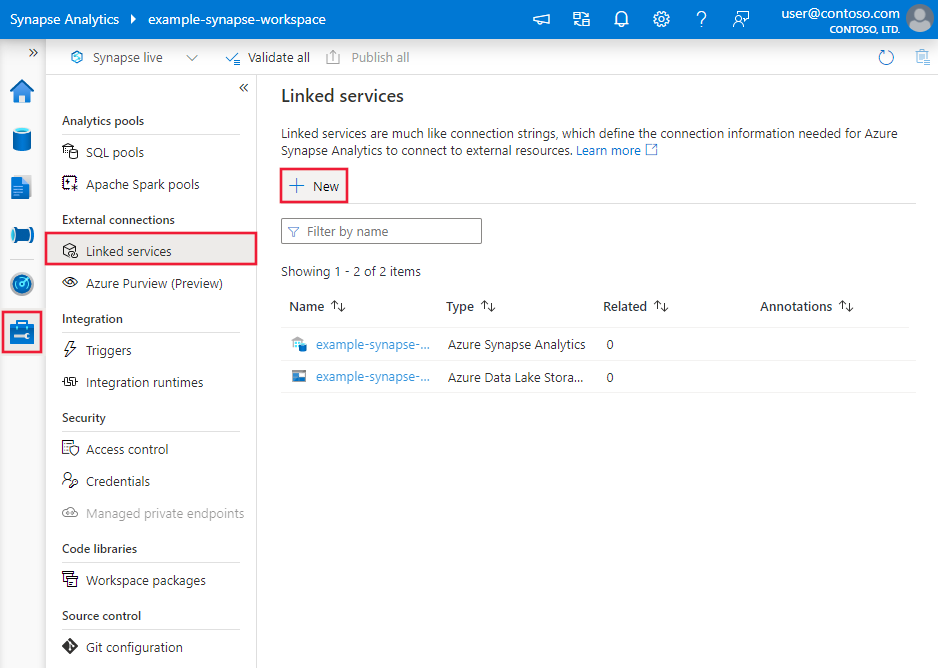
Gehen Sie wie folgt vor, um einen verknüpften Dienst mit Google BigQuery in der Benutzeroberfläche des Azure-Portals zu erstellen.
Navigieren Sie zur Registerkarte Verwalten in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich, wählen Sie Verknüpfte Dienste und klicken Sie dann auf Neu:
Suchen Sie nach Google BigQuery, und wählen Sie den Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Konfiguration des Connectors
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zur Definition von Entitäten verwendet werden, die für den Google BigQuery Connector spezifisch sind.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit Google BigQuery verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die „type“-Eigenschaft muss auf GoogleBigQueryV2 festgelegt werden. | Ja |
| projectId | Das Projekt-ID des BigQuery-Standardprojekts, das abgefragt werden soll. | Ja |
| authenticationType | Der für die Authentifizierung verwendete OAuth 2.0-Authentifizierungsmechanismus. Zulässige Werte sind UserAuthentication und ServiceAuthentication. Weitere Eigenschaften und JSON-Beispiele für diese Authentifizierungstypen finden Sie in den Abschnitten nach dieser Tabelle. |
Ja |
Verwenden der Benutzerauthentifizierung
Legen Sie die Eigenschaft „authenticationType“ auf UserAuthentication fest, und geben Sie zusammen mit den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| clientId | Die ID der Anwendung, die verwendet wird, um das Aktualisierungstoken zu generieren. | Ja |
| clientSecret | Das Geheimnis der Anwendung, das verwendet wird, um das Aktualisierungstoken zu generieren. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
| refreshToken | Das Aktualisierungstoken, das von Google für die Autorisierung des Zugriffs auf BigQuery abgerufen wird. Informationen dazu, wie Sie ein Token erhalten, finden Sie unter Abrufen von OAuth 2.0-Zugriffstoken und in diesem Communityblog. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
Beispiel:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"typeProperties": {
"projectId" : "<project ID>",
"authenticationType" : "UserAuthentication",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value":"<client secret>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Verwenden der Dienstauthentifizierung
Legen Sie die Eigenschaft „authenticationType“ auf ServiceAuthentication fest, und geben Sie zusammen mit den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| keyFileContent | Die Schlüsseldatei im JSON-Format, die zum Authentifizieren des Dienstkontos verwendet wird. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
Beispiel:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"typeProperties": {
"projectId": "<project ID>",
"authenticationType": "ServiceAuthentication",
"keyFileContent": {
"type": "SecureString",
"value": "<key file JSON string>"
}
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Google BigQuery-Dataset unterstützt werden.
Legen Sie zum Kopieren von Daten aus Google BigQuery die „type“-Eigenschaft des Datasets auf GoogleBigQueryV2Object fest. Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf GoogleBigQueryV2Object festgelegt sein. | Ja |
| dataset | Name des Google BigQuery-Datasets. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| table | Der Name der Tabelle. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryV2Object",
"linkedServiceName": {
"referenceName": "<Google BigQuery linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"dataset": "<dataset name>",
"table": "<table name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Google BigQuery-Quelltyp unterstützt werden.
GoogleBigQuerySource als Quelltyp
Legen Sie zum Kopieren von Daten aus Google BigQuery den Quelltyp in der Kopieraktivität auf GoogleBigQueryV2Source fest. Die folgenden Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die „type“-Eigenschaft der Quelle der Kopieraktivität muss auf GoogleBigQueryV2Source festgelegt werden. | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. z. B. "SELECT * FROM MyTable". Weitere Informationen finden Sie unter Abfragesyntax. |
Nein (wenn „dataset“ und „table“ im Dataset angegeben sind) |
Beispiel:
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<Google BigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQueryV2Source",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Upgrade des Google BigQuery-Connectors
Für das Upgrade des Google BigQuery-Connectors erstellen Sie einen neuen verknüpften Google BigQuery-Dienst und konfigurieren ihn anhand der Informationen unter Eigenschaften des verknüpften Diensts.
Unterschiede zwischen Google BigQuery und Google BigQuery (Legacy)
Der Google BigQuery-Connector bietet neue Funktionen und ist mit den meisten Features des Google BigQuery-Connector (Legacy) kompatibel. Die folgende Tabelle zeigt die Unterschiede der Features zwischen Google BigQuery und Google BigQuery (Legacy).
| Google BigQuery | Google BigQuery (Legacy) |
|---|---|
| Die Dienstauthentifizierung wird von der Azure Integration Runtime und der selbstgehosteten Integration Runtime unterstützt. Die Eigenschaften „trustedCertPath“, „useSystemTrustStore“, „email“ und „keyFilePath“ werden nicht unterstützt, da sie nur für die selbstgehostete Integration Runtime verfügbar sind. |
Die Dienstauthentifizierung wird nur von der selbstgehosteten Integration Runtime unterstützt. Unterstützt werden die trustedCertPath-, useSystemTrustStore-, email- und keyFilePath-Eigenschaften. |
| Die folgenden Zuordnungen werden von Google BigQuery-Datentypen zu Zwischendatentypen verwendet, die intern vom Dienst verwendet werden. Numeric -> Decimal Timestamp -> DateTimeOffset Datetime -> DatetimeOffset |
Die folgenden Zuordnungen werden von Google BigQuery-Datentypen zu Zwischendatentypen verwendet, die intern vom Dienst verwendet werden. Numeric -> String Timestamp -> DateTime Datetime -> DateTime |
| requestGoogleDriveScope wird nicht unterstützt. Sie müssen zusätzlich die Berechtigung im Google BigQuery-Dienst anwenden, indem Sie auf Google Drive API-Bereiche auswählen und Drive-Daten abfragen verweisen. | Unterstützung für requestGoogleDriveScope. |
| additionalProjects wird nicht unterstützt. Alternative: Öffentliches Dataset mit der Google Cloud Console abfragen. | Unterstützung für additionalProjects. |
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.