Kopieren und Transformieren von Daten mithilfe von Azure Data Factory- oder Azure Synapse Analytics-Pipelines in Microsoft Fabric Lakehouse
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Microsoft Fabric Lakehouse ist eine Datenarchitekturplattform zum Speichern, Verwalten und Analysieren strukturierter und unstrukturierter Daten an einem einzigen Standort. Weitere Informationen zum nahtlosen Datenzugriff über alle Compute-Engines in Microsoft Fabric hinweg finden Sie unter Lakehouse- und Deltatabellen. Standardmäßig werden die Daten in die Lakehouse-Tabelle in der V-Reihenfolge geschrieben. Weitere Informationen finden Sie unter Optimierung der Delta-Lake-Tabelle und V-Reihenfolge.
In diesem Artikel wird beschrieben, wie Sie mithilfe der Copy-Aktivität Daten aus und in Microsoft Fabric Lakehouse kopieren und einen Datenfluss verwenden, um Daten in Microsoft Fabric Lakehouse zu transformieren. Um mehr zu lernen, lesen Sie den Einführungsartikel für Azure Data Factory oder Azure Synapse Analytics.
Unterstützte Funktionen
Dieser Microsoft Fabric Lakehouse-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② |
| Zuordnungsdatenfluss (Quelle/Senke) | ① |
| Lookup-Aktivität | ① ② |
| GetMetadata-Aktivität | ① ② |
| Delete-Aktivität | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Microsoft Fabric Lakehouse-Diensts mithilfe der Benutzeroberfläche
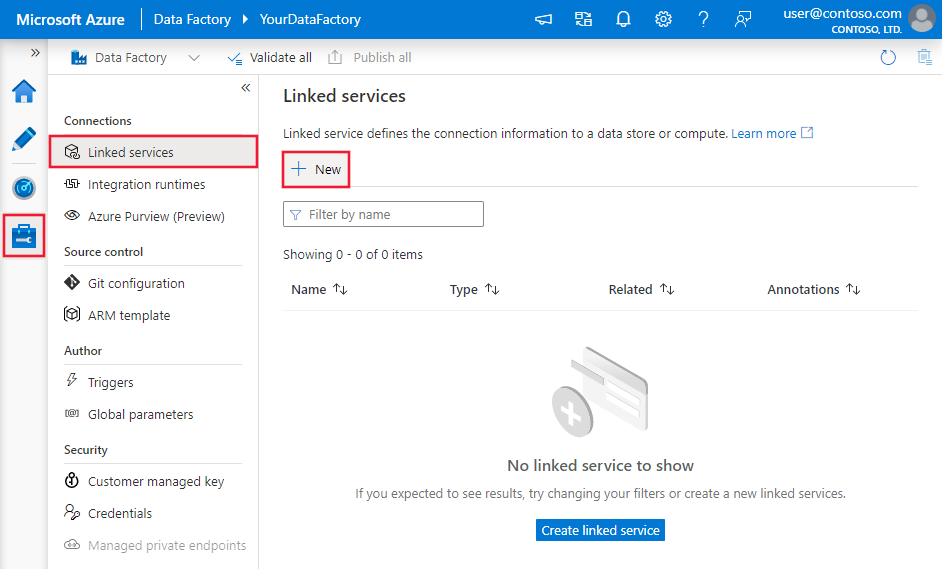
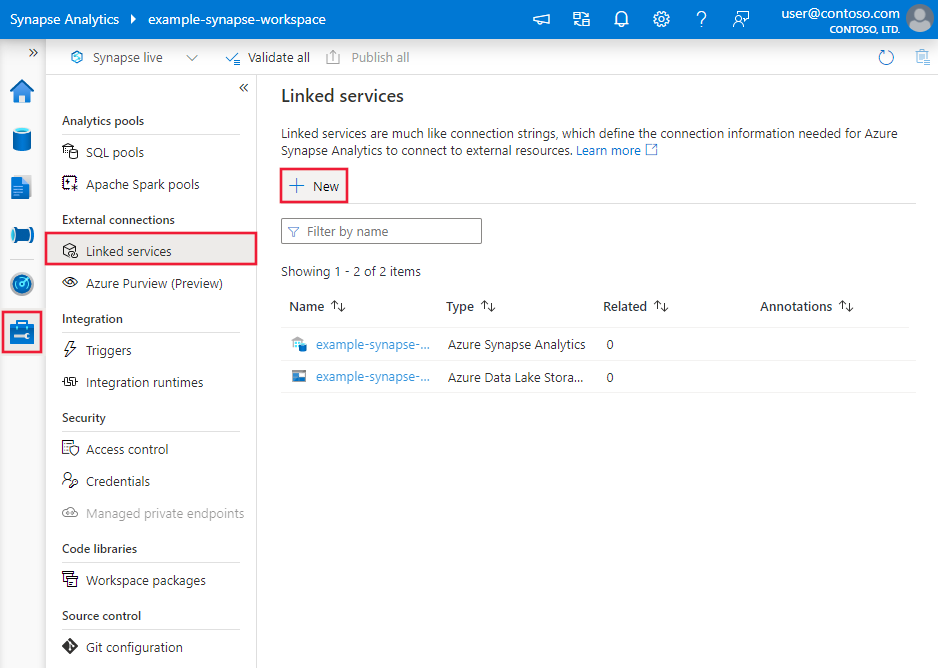
Führen Sie die folgenden Schritte aus, um einen verknüpften Microsoft Fabric Lakehouse-Dienst über die Benutzeroberfläche des Azure-Portals zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte Verwalten, und wählen Sie „Verknüpfte Dienste“ und anschließend „Neu“ aus:
Suchen Sie nach Microsoft Fabric Lakehouse, und wählen Sie den Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für Microsoft Fabric Lakehouse verwendet werden.
Eigenschaften des verknüpften Diensts
Der Microsoft Fabric Lakehouse-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten:
Dienstprinzipalauthentifizierung
Zum Verwenden der Dienstprinzipalauthentifizierung führen Sie die folgenden Schritte aus.
Registrieren einer Anwendung bei der Microsoft Identity Platform und Hinzufügen eines geheimen Clientschlüssels. Notieren Sie sich anschließend die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden können:
- Anwendungs-ID (Client), d. h. die Dienstprinzipal-ID im verknüpften Dienst.
- Wert des geheimen Clientschlüssels, d. h. der Dienstprinzipalschlüssel im verknüpften Dienst.
- Mandanten-ID
Weisen Sie dem Dienstprinzipal mindestens die Rolle Mitwirkender im Microsoft Fabric-Arbeitsbereich zu. Führen Sie folgende Schritte aus:
Wechseln Sie zu Ihrem Microsoft Fabric-Arbeitsbereich, und wählen Sie auf der oberen Leiste Zugriff verwalten aus. Wählen Sie anschließend Personen oder Gruppen hinzufügen aus.


Geben Sie im Bereich Personen hinzufügen den Namen Ihres Dienstprinzipals ein, und wählen Sie Ihren Dienstprinzipal aus der Dropdownliste aus.
Hinweis
Der Dienstprinzipal wird nicht in der Liste Personen hinzufügen angezeigt, es sei denn, die Power BI-Mandanteneinstellungen ermöglichen Dienstprinzipalen den Zugriff auf Fabric-APIs.
Geben Sie als Rolle Mitwirkender oder höher (Administrator, Mitglied) an, und wählen Sie dann Hinzufügen aus.

Ihr Dienstprinzipal wird im Bereich Zugriff verwalten angezeigt.
Diese Eigenschaften werden im verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft „Typ“ muss auf Lakehouse festgelegt werden. | Ja |
| workspaceId | Die ID des Microsoft Fabric-Arbeitsbereichs | Ja |
| artifactId | Die Microsoft Fabric Lakehouse-Objekt-ID | Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalCredentialType | Die Art von Anmeldeinformationen, die für die Authentifizierung beim Dienstprinzipal verwendet werden. Gültige Werte sind ServicePrincipalKey und ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Die Anmeldeinformationen für den Dienstprinzipal. Wenn Sie ServicePrincipalKey als Anmeldeinformationstyp verwenden, geben Sie den Wert des geheimen Clientschlüssels der Anwendung an. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. Wenn Sie ServicePrincipalCert als Anmeldeinformationen verwenden, verweisen Sie auf ein Zertifikat in Azure Key Vault, und stellen Sie sicher, dass der Zertifikatsinhaltstyp PKCS #12 lautet. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Dienstprinzipal-Schlüsselauthentifizierung
Sie können den Dienstprinzipalschlüssel auch in Azure Key Vault speichern.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Der Microsoft Fabric Lakehouse-Connector unterstützt zwei Typen von Datasets: Microsoft Fabric Lakehouse-Dateidatasets und Microsoft Fabric Lakehouse-Tabellendatasets. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Microsoft Fabric Lakehouse-Dateidataset
Der Microsoft Fabric Lakehouse-Connector unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
Folgende Eigenschaften werden unter den location-Einstellungen in formatbasierten Microsoft Fabric Lakehouse-Dateidatasets unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter location im Dataset muss auf LakehouseLocation festgelegt werden. |
Ja |
| folderPath | Der Pfad zu einem Ordner. Wenn Sie einen Platzhalter verwenden möchten, um Ordner zu filtern, überspringen Sie diese Einstellung, und geben Sie entsprechende Aktivitätsquelleneinstellungen an. | Nein |
| fileName | Der Name der Datei unter dem angegebenen „folderPath“. Wenn Sie einen Platzhalter verwenden möchten, um Dateien zu filtern, überspringen Sie diese Einstellung, und geben Sie ihn in den entsprechenden Aktivitätsquelleneinstellungen an. | Nein |
Beispiel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Microsoft Fabric Lakehouse-Tabellendataset
Die folgenden Eigenschaften werden bei dem Microsoft Fabric Lakehouse Table-Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft Typ des Datasets muss auf LakehouseTable festgelegt werden. | Ja |
| schema | Name des Schemas. Wenn Sie hier nichts angeben, lautet der Standardwert dbo. |
No |
| table | Der Name Ihrer Tabelle. | Ja |
Beispiel:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Eigenschaften der Kopieraktivität
Die Eigenschaften der Copy-Aktivität für Microsoft Fabric Lakehouse-Dateidatasets und Microsoft Fabric Lakehouse-Tabellendatasets unterscheiden sich. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
- Microsoft Fabric Lakehouse-Dateien in der Copy-Aktivität
- Microsoft Fabric Lakehouse-Tabellen in der Copy-Aktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Konfigurationen für die Kopieraktivität und Pipelines und Aktivitäten.
Microsoft Fabric Lakehouse-Dateien in der Copy-Aktivität
Wenn Sie den Datasettyp Microsoft Fabric Lakehouse-Dateien als Quelle oder Senke der Copy-Aktivität verwenden möchten, finden Sie in den folgenden Abschnitten detaillierte Informationen zur Konfiguration.
Microsoft Fabric Lakehouse-Dateien als Quelltyp
Der Microsoft Fabric Lakehouse-Connector unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
Sie haben mehrere Möglichkeiten, Daten aus Microsoft Fabric Lakehouse mithilfe von Microsoft Fabric Lakehouse-Dateidatasets zu kopieren:
- Kopieren Sie aus dem im Dataset angegebenen Pfad.
- Den Platzhalterfilter für Ordnerpfad oder Dateiname finden Sie unter
wildcardFolderPathundwildcardFileName. - Kopieren Sie die in einer bestimmten Textdatei definierten Dateien als Dateigruppe (siehe
fileListPath).
Folgende Eigenschaften werden für Microsoft Fabric Lakehouse-Dateidatasets unter den storeSettings-Einstellungen in der formatbasierten Kopierquelle unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter storeSettings muss auf LakehouseReadSettings festgelegt werden. |
Ja |
| Suchen Sie die zu kopierenden Dateien: | ||
| OPTION 1: statischer Pfad |
Kopieren Sie aus dem im Dataset angegebenen Ordner/Dateipfad. Wenn Sie alle Dateien aus einem Ordner kopieren möchten, geben Sie zusätzlich für wildcardFileName den Wert * an. |
|
| OPTION 2: Platzhalter – wildcardFolderPath |
Der Ordnerpfad mit Platzhalterzeichen, um Quellordner zu filtern. Zulässige Platzhalter sind: * (entspricht null oder mehr Zeichen) und ? (entspricht null oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Nein |
| OPTION 2: Platzhalter – wildcardFileName |
Der Dateiname mit Platzhalterzeichen unter dem angegebenen „folderPath/wildcardFolderPath“ für das Filtern von Quelldateien. Zulässige Platzhalter sind: * (entspricht null oder mehr Zeichen) und ? (entspricht null oder einem einzelnen Zeichen). Verwenden Sie ^ als Escapezeichen, wenn Ihr tatsächlicher Dateiname einen Platzhalter oder dieses Escapezeichen enthält. Weitere Beispiele finden Sie unter Beispiele für Ordner- und Dateifilter. |
Ja |
| OPTION 3: eine Liste von Dateien – fileListPath |
Gibt an, dass eine bestimmte Dateigruppe kopiert werden soll. Verweisen Sie auf eine Textdatei, die eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Dies ist der relative Pfad zu dem im Dataset konfigurierten Pfad. Geben Sie bei Verwendung dieser Option keinen Dateinamen im Dataset an. Weitere Beispiele finden Sie unter Beispiele für Dateilisten. |
Nein |
| Zusätzliche Einstellungen: | ||
| recursive | Gibt an, ob die Daten rekursiv aus den Unterordnern oder nur aus dem angegebenen Ordner gelesen werden. Wenn „recursive“ auf „true“ festgelegt ist und es sich bei der Senke um einen dateibasierten Speicher handelt, wird ein leerer Ordner oder Unterordner nicht in die Senke kopiert oder dort erstellt. Zulässige Werte sind true (Standard) und false. Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| deleteFilesAfterCompletion | Gibt an, ob die Binärdateien nach dem erfolgreichen Verschieben in den Zielspeicher aus dem Quellspeicher gelöscht werden. Die Dateien werden einzeln gelöscht, sodass Sie bei einem Fehler der Copy-Aktivität feststellen werden, dass einige Dateien bereits ins Ziel kopiert und aus der Quelle gelöscht wurden, während sich andere weiter im Quellspeicher befinden. Diese Eigenschaft ist nur im Szenario zum Kopieren von Binärdateien gültig. Standardwert: FALSE. |
Nein |
| modifiedDatetimeStart | Dateifilterung basierend auf dem Attribut: Letzte Änderung. Die Dateien werden ausgewählt, wenn der Zeitpunkt ihrer letzten Änderung größer als oder gleich modifiedDatetimeStart und kleiner als modifiedDatetimeEnd ist. Die Zeit wird auf die UTC-Zeitzone im Format „2018-12-01T05:00:00Z“ angewandt. Die Eigenschaften können NULL sein, was bedeutet, dass kein Dateiattributfilter auf das Dataset angewandt wird. Wenn modifiedDatetimeStart den datetime-Wert aufweist, aber modifiedDatetimeEnd NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung größer oder gleich dem datetime-Wert ist. Wenn modifiedDatetimeEnd den datetime-Wert aufweist, aber modifiedDatetimeStart NULL ist, bedeutet dies, dass die Dateien ausgewählt werden, deren Attribut für die letzte Änderung kleiner als der datetime-Wert ist.Diese Eigenschaft gilt nicht, wenn Sie fileListPath konfigurieren. |
Nein |
| modifiedDatetimeEnd | Wie oben. | Nein |
| enablePartitionDiscovery | Geben Sie bei partitionierten Dateien an, ob die Partitionen anhand des Dateipfads analysiert und als zusätzliche Quellspalten hinzugefügt werden sollen. Zulässige Werte sind false (Standard) und true. |
Nein |
| partitionRootPath | Wenn die Partitionsermittlung aktiviert ist, geben Sie den absoluten Stammpfad an, um partitionierte Ordner als Datenspalten zu lesen. Wenn dieser Wert nicht angegeben ist, gilt standardmäßig Folgendes: - Wenn Sie den Dateipfad im Dataset oder die Liste der Dateien in der Quelle verwenden, ist der Partitionsstammpfad der im Dataset konfigurierte Pfad. – Wenn Sie einen Platzhalterordnerfilter verwenden, ist der Stammpfad der Partition der Unterpfad vor dem ersten Platzhalter. Angenommen, Sie konfigurieren den Pfad im Dataset als „root/folder/year=2020/month=08/day=27“: – Wenn Sie den Stammpfad der Partition als „root/folder/year=2020“ angeben, generiert die Kopieraktivität zusätzlich zu den Spalten in den Dateien zwei weitere Spalten month und day mit den Werten „08“ bzw. „27“.– Wenn kein Stammpfad für die Partition angegeben ist, wird keine zusätzliche Spalte generiert. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
Beispiel:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse-Dateien als Senkentyp
Der Microsoft Fabric Lakehouse-Connector unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
Folgende Eigenschaften werden für Microsoft Fabric Lakehouse-Dateidatasets unter den storeSettings-Einstellungen in der formatbasierten Kopiersenke unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft unter storeSettings muss auf LakehouseWriteSettings festgelegt werden. |
Ja |
| copyBehavior | Definiert das Kopierverhalten, wenn es sich bei der Quelle um Dateien aus einem dateibasierten Datenspeicher handelt. Zulässige Werte sind: - PreserveHierarchy (Standard): Behält die Dateihierarchie im Zielordner bei. Der relative Pfad der Quelldatei zum Quellordner ist mit dem relativen Pfad der Zieldatei zum Zielordner identisch. - FlattenHierarchy: Alle Dateien aus dem Quellordner befinden sich auf der ersten Ebene des Zielordners. Die Namen für die Zieldateien werden automatisch generiert. - MergeFiles: Alle Dateien aus dem Quellordner werden in einer Datei zusammengeführt. Wenn der Dateiname angegeben wurde, entspricht der zusammengeführte Dateiname dem angegebenen Namen. Andernfalls wird der Dateiname automatisch generiert. |
Nein |
| blockSizeInMB | Geben Sie die Blockgröße, die zum Schreiben von Daten in Microsoft Fabric Lakehouse verwendet wird, in MB an. Informieren Sie sich ausführlicher über Blockblobs. Der zulässige Wert liegt zwischen 4 und 100 MB. Standardmäßig bestimmt ADF automatisch die Blockgröße, basierend auf dem Quellspeichertyp und den Daten. Bei einer nicht binären Kopie in Microsoft Fabric Lakehouse beträgt die Standardblockgröße 100 MB, damit sie in maximal ca. 4,75 TB Daten passt. Dies ist möglicherweise nicht optimal, wenn Ihre Daten nicht groß sind – insbesondere, wenn Sie eine selbstgehostete Integration Runtime bei einem unzureichenden Netzwerk verwenden, was zu einem Timeout beim Vorgang oder einem Leistungsproblem führen kann. Sie können die Blockgröße explizit angeben und gleichzeitig sicherstellen, dass „blockSizeInMB*50000“ groß genug zum Speichern der Daten ist. Andernfalls tritt bei Ausführung der Copy-Aktivität ein Fehler auf. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| metadata | Hiermit werden beim Kopieren in die Senke benutzerdefinierte Metadaten festgelegt. Jedes Objekt unter dem Array metadata stellt eine zusätzliche Spalte dar. name definiert den Namen des Metadatenschlüssels, und value gibt den Datenwert dieses Schlüssels an. Wenn das Feature zum Beibehalten von Attributen verwendet wird, werden die angegebenen Metadaten mit den Metadaten der Quelldatei vereint/überschrieben.Zulässige Datenwerte sind: - $$LASTMODIFIED: Eine reservierte Variable gibt an, dass der Zeitpunkt der letzten Änderung der Quelldateien gespeichert werden soll. Gilt nur für dateibasierte Quellen im Binärformat.– Ausdruck - Statischer Wert |
Nein |
Beispiel:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Beispiele für Ordner- und Dateifilter
Dieser Abschnitt beschreibt das sich ergebende Verhalten für den Ordnerpfad und den Dateinamen mit Platzhalterfiltern.
| folderPath | fileName | recursive | Quellordnerstruktur und Filterergebnis (Dateien mit Fettformatierung werden abgerufen.) |
|---|---|---|---|
Folder* |
(Leer, Standardwert verwenden) | false | FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
(Leer, Standardwert verwenden) | true | FolderA Datei1.csv File2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
false | FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Folder* |
*.csv |
true | FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv AndererOrdnerB Datei6.csv |
Beispiele für Dateilisten
In diesem Abschnitt wird das resultierende Verhalten beschrieben, wenn der Dateilistenpfad in der Quelle der Kopieraktivität verwendet wird.
Angenommen, Sie haben die folgende Quellordnerstruktur und möchten die Dateien kopieren, deren Namen fett formatiert sind:
| Beispielquellstruktur | Inhalt in „FileListToCopy.txt“ | ADF-Konfiguration |
|---|---|---|
| filesystem FolderA Datei1.csv Datei2.json Unterordner1 File3.csv File4.json File5.csv Metadaten FileListToCopy.txt |
Datei1.csv Unterordner1/Datei3.csv Unterordner1/Datei5.csv |
Im Dataset: – Ordnerpfad: FolderAIn der Quelle der Kopieraktivität: – Dateilistenpfad: Metadata/FileListToCopy.txt Der Dateilistenpfad verweist auf eine Textdatei im selben Datenspeicher, der eine Liste der zu kopierenden Dateien enthält, und zwar eine Datei pro Zeile. Diese enthält den relativen Pfad zu dem im Dataset konfigurierten Pfad. |
Beispiele für „recursive“ und „copyBehavior“
Dieser Abschnitt beschreibt das resultierende Verhalten des Kopiervorgangs für verschiedene Kombinationen von „recursive“- und „copyBehavior“-Werten.
| recursive | copyBehavior | Struktur des Quellordners | Resultierendes Ziel |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der gleichen Struktur erstellt wie die Quelle: Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
| true | flattenHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Automatisch generierter Name für Datei1 Automatisch generierter Name für Datei2 Automatisch generierter Name für Datei3 Automatisch generierter Name für Datei4 Automatisch generierter Name für Datei5 |
| true | mergeFiles | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Die Inhalte von Datei1 + Datei2 + Datei3 + Datei4 + Datei5 werden in einer Datei mit einem automatisch generierten Dateinamen zusammengeführt. |
| false | preserveHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Datei1 Datei2 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
| false | flattenHierarchy | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Automatisch generierter Name für Datei1 Automatisch generierter Name für Datei2 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
| false | mergeFiles | Folder1 Datei1 Datei2 Unterordner1 Datei3 Datei4 Datei5 |
Der Zielordner „Ordner1“ wird mit der folgenden Struktur erstellt: Folder1 Die Inhalte von Datei1 + Datei2 werden in einer Datei mit einem automatisch generierten Dateinamen zusammengeführt. Automatisch generierter Name für Datei1 Unterordner1 mit Datei3, Datei4 und Datei5 wird nicht übernommen. |
Microsoft Fabric Lakehouse-Tabellen in der Copy-Aktivität
Wenn Sie ein Microsoft Fabric Lakehouse-Tabellendataset als Quell- oder Senkendataset der Copy-Aktivität verwenden möchten, finden Sie in den folgenden Abschnitten detaillierte Informationen zur Konfiguration.
Microsoft Fabric Lakehouse Table als Quelltyp
Wenn Sie Daten aus Microsoft Fabric Lakehouse mithilfe des Microsoft Fabric Lakehouse-Tabellendatasets kopieren möchten, legen Sie die Typ-Eigenschaft der Quelle der Copy-Aktivität auf LakehouseTableSource fest. Die folgenden Eigenschaften werden im Abschnitt Quelle der Copy-Aktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft Typ der Quelle der Copy-Aktivität muss auf LakehouseTableSource festgelegt werden. | Ja |
| timestampAsOf | Der Zeitstempel zum Abfragen einer älteren Momentaufnahme. | Nein |
| versionAsOf | Die Version zum Abfragen einer älteren Momentaufnahme. | Nein |
Beispiel:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Table als Senkentyp
Wenn Sie Daten in Microsoft Fabric Lakehouse mithilfe des Microsoft Fabric Lakehouse-Tabellendatasets kopieren möchten, legen Sie die Typ-Eigenschaft der Senke der Copy-Aktivität auf LakehouseTableSink fest. Die folgenden Eigenschaften werden im Abschnitt Senke der Copy-Aktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Eigenschaft Typ der Quelle der Copy-Aktivität muss auf LakehouseTableSink festgelegt werden. | Ja |
Hinweis
Die Daten werden standardmäßig in den Lakehouse Table in V-Reihenfolge geschrieben. Weitere Informationen finden Sie unter Delta Lake-Tabellenoptimierung und V-Reihenfolge.
Beispiel:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Dateien oder Tabellen in Microsoft Fabric Lakehouse lesen und schreiben. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
- Microsoft Fabric Lakehouse-Dateien im Zuordnungsdatenfluss
- Microsoft Fabric Lakehouse-Tabellen im Zuordnungsdatenfluss
Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen.
Microsoft Fabric Lakehouse-Dateien im Zuordnungsdatenfluss
Wenn Sie ein Microsoft Fabric Lakehouse-Dateidataset als Quell- oder Senkendataset im Zuordnungsdatenfluss verwenden möchten, finden Sie in den folgenden Abschnitten detaillierte Informationen zur Konfiguration.
Microsoft Fabric Lakehouse-Dateien als Quell- oder Senkentyp
Der Microsoft Fabric Lakehouse-Connector unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
Um den dateibasierten Fabric Lakehouse-Connector im Inline-Datasettyp zu verwenden, müssen Sie den richtigen Inline-Datasettyp für Ihre Daten auswählen. Je nach Datenformat können Sie DelimitedText, Avro, JSON, ORC oder Parquet verwenden.
Microsoft Fabric Lakehouse-Tabellen im Zuordnungsdatenfluss
Wenn Sie ein Microsoft Fabric Lakehouse-Tabellendataset als Quell- oder Senkendataset im Zuordnungsdatenfluss verwenden möchten, finden Sie in den folgenden Abschnitten detaillierte Informationen zur Konfiguration.
Microsoft Fabric Lakehouse Table als Quelltyp
Es gibt unter den Quelloptionen keine konfigurierbaren Eigenschaften.
Hinweis
Eine CDC-Unterstützung ist für Lakehouse-Tabellenquellen derzeit nicht verfügbar.
Microsoft Fabric Lakehouse Table als Senkentyp
Die folgenden Eigenschaften werden im Abschnitt Senke des Zuordnungsdatenflusses unterstützt:
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Wenn Sie allein „Einfügen zulassen“ auswählen oder in eine neue Deltatabelle schreiben, empfängt das Ziel alle eingehenden Zeilen, und zwar unabhängig von den festgelegten Zeilenrichtlinien. Wenn Ihre Daten Zeilen mit anderen Zeilenrichtlinien enthalten, müssen diese mit einer vorhergehenden Filtertransformation ausgeschlossen werden. Wenn alle Update-Methoden ausgewählt sind, erfolgt eine Zusammenführung, bei der Zeilen gemäß den festgelegten Richtlinien für Zeilen eingefügt/gelöscht/aktualisiert und eingefügt/aktualisiert werden, und zwar mithilfe einer vorhergehenden Alter Row-Transformation. |
ja | true oder false |
insertable deletable upsertable updateable |
| Optimierter Schreibvorgang | Erzielen Sie einen höheren Durchsatz für den Schreibvorgang, indem Sie das interne Mischen in Spark-Executors optimieren. Dies führt möglicherweise zu weniger Partitionen und größeren Dateien. | Nein | true oder false |
optimizedWrite: true |
| Automatisches Komprimieren | Nach dem Abschluss der einzelnen Schreibvorgänge führt Spark automatisch den Befehl OPTIMIZE aus, um die Daten neu zu organisieren. Dies führt möglicherweise zu mehr Partitionen, um künftig eine bessere Leseleistung zu erzielen. |
Nein | true oder false |
autoCompact: true |
| Zusammenführen des Schemas | Die Option „Schema zusammenführen“ ermöglicht eine Schemaweiterentwicklung, d. h., alle Spalten, die im aktuellen eingehenden Datenstrom, aber nicht in der Deltazieltabelle vorhanden sind, werden automatisch dem Schema hinzugefügt. Diese Option wird für alle Updatemethoden unterstützt. | Nein | true oder false |
mergeSchema: true |
Beispiel: Microsoft Fabric Lakehouse Table-Senke
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
Für den tabellenbasierten Fabric Lakehouse-Connector im Inline-Datasettyp müssen Sie nur Delta als Datasettyp verwenden. Auf diese Weise können Sie Daten aus Fabric Lakehouse-Tabellen lesen und schreiben.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Eigenschaften der Delete-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Delete-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.