Kopieren von Daten aus oder nach MongoDB mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- oder Azure Synapse Analytics-Pipelines verwenden, um Daten aus einer MongoDB-Datenbank oder in eine MongoDB-Datenbank zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Wichtig
Der neue MongoDB-Connector umfasst eine bessere native MongoDB-Unterstützung. Wenn Sie den älteren MongoDB-Connector in Ihrer Lösung verwenden, der lediglich aus Gründen der Abwärtskompatibilität unverändert unterstützt wird, finden Sie entsprechende Informationen im Artikel MongoDB-Connector (Legacy).
Unterstützte Funktionen
Für den MongoDB-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen/Senken unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Dieser MongoDB-Connector unterstützt insbesondere die Versionen bis 4.2. Wenn Ihre Arbeit eine höhere Version als 4.2 erfordert, sollten Sie MongoDB Atlas mit dem MongoDB Atlas-Connector verwenden, der umfassendere Unterstützung und Funktionen bietet.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts für MongoDB über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen verknüpften Dienst für MongoDB in der Benutzeroberfläche des Azure-Portals zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach MongoDB, und wählen Sie den MongoDB-Connector aus.
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
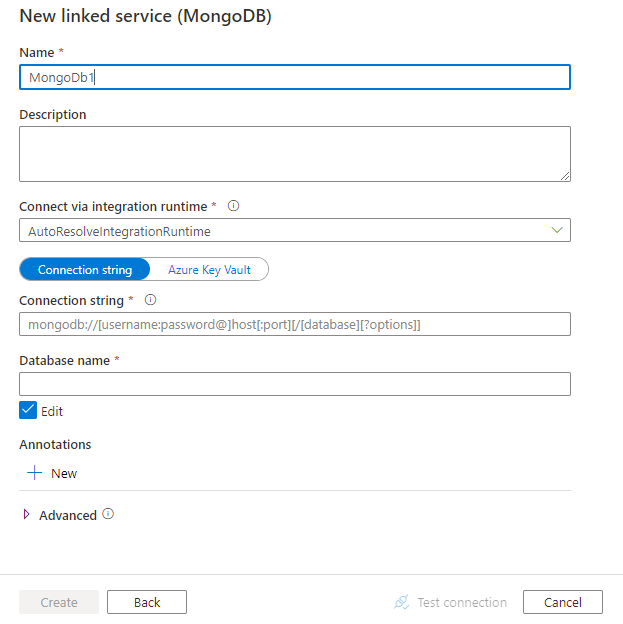
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den MongoDB-Connector verwendet werden:
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit MongoDB verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Folgendes festgelegt werden: MongoDbV2 | Ja |
| connectionString | Geben Sie die MongoDB-Verbindungszeichenfolge an, z.B. mongodb://[username:password@]host[:port][/[database][?options]]. Weitere Informationen finden Sie im MongoDB-Handbuch zur Verbindungszeichenfolge. Sie können eine Verbindungszeichenfolge auch in Azure Key Vault speichern. Ausführlichere Informationen finden Sie unter Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| database | Der Name der Datenbank, auf die Sie zugreifen möchten. | Ja |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDbV2",
"typeProperties": {
"connectionString": "mongodb://[username:password@]host[:port][/[database][?options]]",
"database": "myDatabase"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie unter Datasets und verknüpfte Dienste. Folgende Eigenschaften werden für das MongoDB-Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf folgenden Wert festgelegt werden: MongoDbV2Collection | Ja |
| collectionName | Der Name der Sammlung in der MongoDB-Datenbank | Ja |
Beispiel:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbV2Collection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der MongoDB-Quelle und -Senke unterstützt werden.
MongoDB als Quelle
Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: MongoDbV2Source | Ja |
| filter | Gibt den Auswahlfilter mit Abfrageoperatoren an. Um alle Dokumente in einer Sammlung zurückzugeben, lassen Sie diesen Parameter aus oder übergeben Sie ein leeres Dokument ({}). | Nein |
| cursorMethods.project | Gibt die Felder an, die in den Dokumenten für die Projektion zurückgegeben werden sollen. Um alle Felder in den entsprechenden Dokumenten zurückzugeben, lassen Sie diesen Parameter aus. | Nein |
| cursorMethods.sort | Gibt die Reihenfolge an, in der übereinstimmende Dokumente von der Abfrage zurückgegeben werden. Siehe cursor.sort(). | Nein |
| cursorMethods.limit | Gibt die maximale Anzahl von Dokumenten an, die vom Server zurückgegeben werden. Siehe cursor.limit(). | Nein |
| cursorMethods.skip | Gibt die Anzahl von Dokumenten an, die übersprungen werden sollen und ab denen MongoDB mit der Rückgabe von Ergebnissen beginnt. Siehe cursor.skip(). | Nein |
| batchSize | Gibt die Anzahl von Dokumenten an, die in jedem Batch der Antwort von der MongoDB-Instanz zurückgegeben werden sollen. In den meisten Fällen wirkt sich eine Änderung der Batchgröße nicht auf den Benutzer oder die Anwendung aus. In Azure Cosmos DB ist die maximale Größe von Batches auf 40 MB begrenzt. Dies entspricht der Summe des batchSize-Werts für die Dokumentengröße. Verringern Sie deshalb diesen Wert, falls Ihre Dokumente groß sind. | Nein (der Standardwert ist 100) |
Tipp
Der Dienst unterstützt die Nutzung eines BSON-Dokuments im Strict-Modus. Stellen Sie sicher, dass die Filterabfrage den Strict-Modus und nicht den Shell-Modus aufweist. Eine weitere Beschreibung finden Sie im MongoDB-Handbuch.
Beispiel:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbV2Source",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
MongoDB als Senke
Die folgenden Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Kopieraktivität muss auf MongoDbV2Sink festgelegt werden. | Ja |
| writeBehavior | Beschreibt, wie Daten in MongoDB geschrieben werden. Zulässige Werte: insert und upsert. Das Verhalten von upsert besteht darin, das Dokument zu ersetzen, wenn ein Dokument mit dem gleichen _id-Typ bereits vorhanden ist. Andernfalls wird das Dokument eingefügt.Hinweis: Der Dienst generiert automatisch eine _id für ein Dokument, wenn eine _id weder im Originaldokument noch durch eine Spaltenzuordnung angegeben wird. Dies bedeutet, dass Sie sicherstellen müssen, dass Ihr Dokument eine ID besitzt, damit upsert wie erwartet funktioniert. |
Nein (der Standardwert ist insert) |
| writeBatchSize | Die writeBatchSize-Eigenschaft steuert die Größe der in jeden Batch zu schreibenden Dokumente. Sie können versuchen, den Wert für writeBatchSize zu erhöhen, um die Leistung zu verbessern, oder den Wert verringern, falls Ihre Dokumente groß sind. | Nein (der Standardwert ist 10.000) |
| writeBatchTimeout | Die Wartezeit, bis der Batch-Einfügevorgang beendet ist, bevor er eine Zeitüberschreitung verursacht. Der zulässige Wert ist timespan. | Nein (der Standardwert ist 00:30:00 – 30 Minuten) |
Tipp
Informationen zum Importieren von JSON-Dokumenten in unveränderter Form finden Sie im Abschnitt Importieren oder Exportieren von JSON-Dokumenten. Informationen zum Kopieren aus tabellarisch strukturierten Daten finden Sie unter Schemazuordnung.
Beispiel
"activities":[
{
"name": "CopyToMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbV2Sink",
"writeBehavior": "upsert"
}
}
}
]
Importieren und Exportieren von JSON-Dokumenten
Sie können diesen MongoDB-Connector verwenden, um die folgenden Aufgaben auf einfache Weise zu erledigen:
- Dokumente zwischen zwei MongoDB-Sammlungen unverändert kopieren.
- Importieren von JSON-Dokumenten aus verschiedenen Quellen in MongoDB, z. B. aus Azure Cosmos DB, Azure Blob Storage, Azure Data Lake Store und anderen unterstützten dateibasierten Speichern.
- Exportieren von JSON-Dokumenten aus einer MongoDB-Sammlung in verschiedene dateibasierte Speicher.
Um eine solche vom Schema unabhängige Kopie zu erzielen, überspringen Sie den Abschnitt „structure“ (auch schema genannt) im Dataset und die Schemazuordnung in der Kopieraktivität.
Schemazuordnung
Informationen zum Kopieren von Daten aus MongoDB in eine tabellarische Senke oder umgekehrt finden Sie unter Schemazuordnung.
Upgrade des verknüpften MongoDB-Diensts
Die folgenden Schritte unterstützen Sie beim Upgrade Ihres verknüpften Diensts und der zugehörigen Abfragen:
Erstellen Sie einen neuen verknüpften MongoDB-Dienst, und konfigurieren Sie ihn anhand der Informationen unter Eigenschaften des verknüpften Diensts.
Wenn Sie in Ihren Pipelines SQL-Abfragen verwenden, die auf den alten verknüpften MongoDB-Dienst verweisen, ersetzen Sie sie durch die entsprechenden MongoDB-Abfragen. In der folgenden Tabelle finden Sie Beispiele für die Ersetzung:
SQL-Abfrage (SQL query) Äquivalente MongoDB-Abfrage SELECT * FROM usersdb.users.find({})SELECT username, age FROM usersdb.users.find({}, {username: 1, age: 1})SELECT username AS User, age AS Age, statusNumber AS Status, CASE WHEN Status = 0 THEN "Pending" CASE WHEN Status = 1 THEN "Finished" ELSE "Unknown" END AS statusEnum LastUpdatedTime + interval '2' hour AS NewLastUpdatedTime FROM usersdb.users.aggregate([{ $project: { _id: 0, User: "$username", Age: "$age", Status: "$statusNumber", statusEnum: { $switch: { branches: [ { case: { $eq: ["$Status", 0] }, then: "Pending" }, { case: { $eq: ["$Status", 1] }, then: "Finished" } ], default: "Unknown" } }, NewLastUpdatedTime: { $add: ["$LastUpdatedTime", 2 * 60 * 60 * 1000] } } }])SELECT employees.name, departments.name AS department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;db.employees.aggregate([ { $lookup: { from: "departments", localField: "department_id", foreignField: "_id", as: "department" } }, { $unwind: "$department" }, { $project: { _id: 0, name: 1, department_name: "$department.name" } } ])
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.