Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Verwenden Sie die Datenfluss Aktivität, um Daten über Zuordnungsdatenflüsse zu transformieren und zu verschieben. Wenn Sie neu bei Datenflüssen sind, lesen Sie Übersicht über das Datenfluss Mapping
Erstellen Sie eine Datenfluss Aktivität mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine Datenfluss Aktivität in einer Pipeline zu verwenden:
Suchen Sie im Bereich "Pipelineaktivitäten" nach Datenfluss, und ziehen Sie eine Datenfluss Aktivität in den Pipelinebereich.
Wählen Sie die neue Datenfluss-Aktivität auf dem Zeichenbereich aus, wenn sie noch nicht ausgewählt ist, und die Registerkarte Settings, um die Details zu bearbeiten.
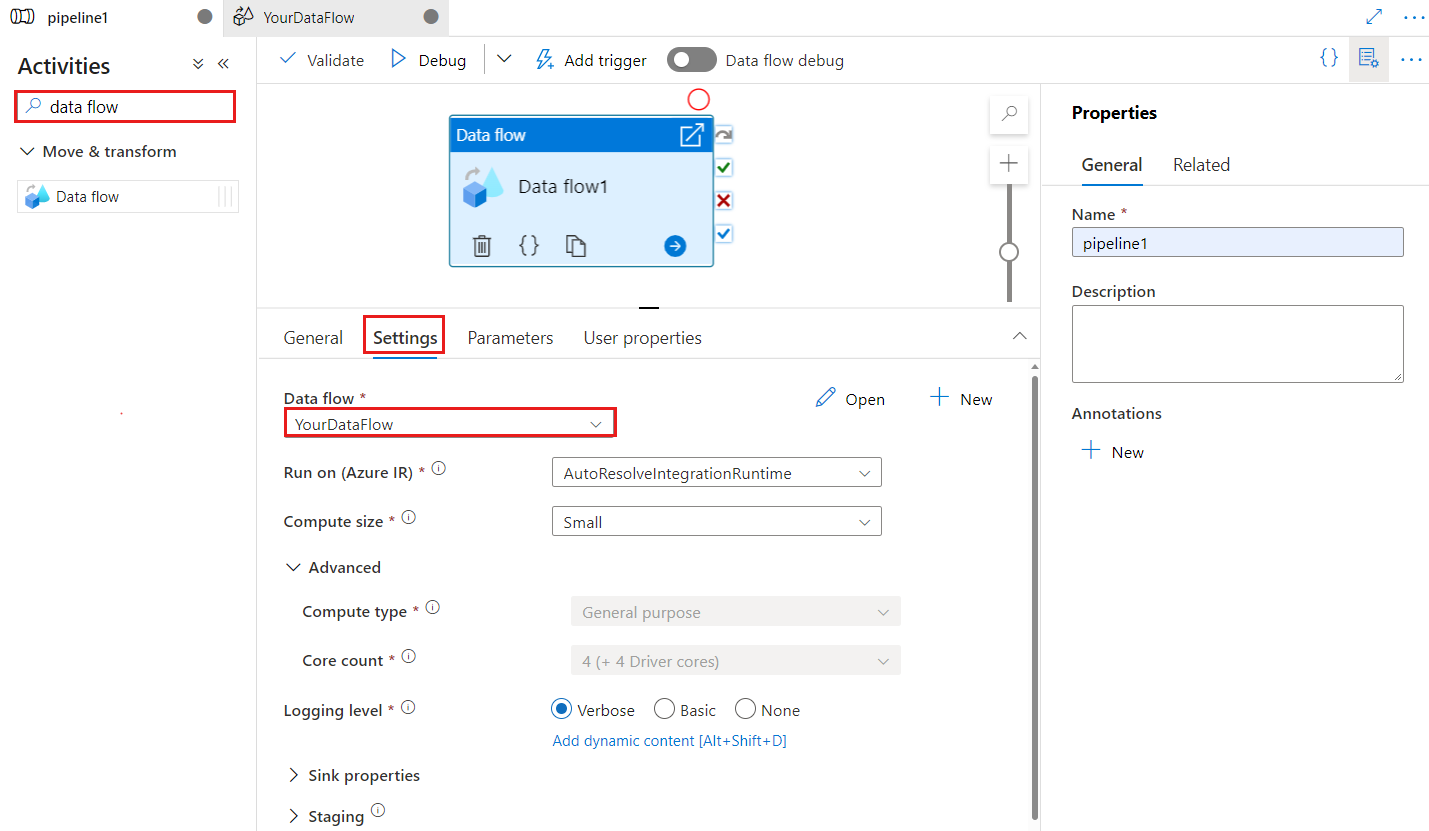
Mit dem Prüfpunktschlüssel wird der Prüfpunkt festgelegt, wenn der Datenfluss für die geänderte Datenerfassung verwendet wird. Sie können ihn überschreiben. Datenflussaktivitäten verwenden einen GUID-Wert als Prüfpunktschlüssel anstelle von „Pipelinename + Aktivitätsname“, damit der CDC-Status (Change Data Capture) des Kunden auch dann nachverfolgt werden kann, wenn Umbenennungsaktionen durchgeführt werden. Alle vorhandenen Datenflussaktivitäten verwenden aus Gründen der Abwärtskompatibilität den Schlüssel mit dem alten Muster. Die Option für Prüfpunktschlüssel nach der Veröffentlichung einer neuen Datenflussaktivität mit aktivierter Change Data Capture-Datenflussressource ist nachfolgend dargestellt:
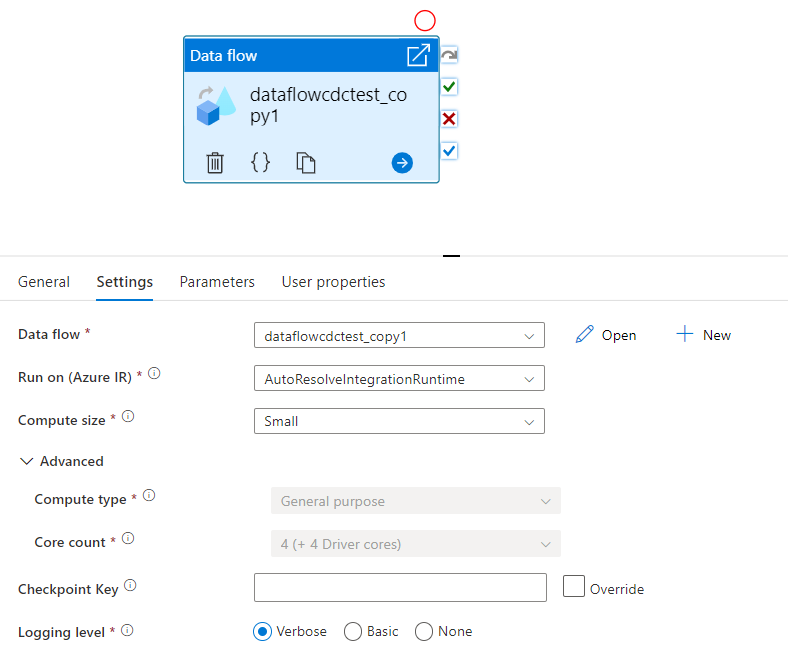
Wählen Sie einen vorhandenen Datenfluss aus, oder erstellen Sie mithilfe der Schaltfläche „Neu“ einen neuen. Wählen Sie nach Bedarf weitere Optionen aus, um Ihre Konfiguration abzuschließen.
Syntax
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Typeigenschaften
| Eigenschaft | BESCHREIBUNG | Zulässige Werte | Erforderlich |
|---|---|---|---|
| Datenfluss | Der Verweis auf den ausgeführten Datenfluss | DataFlowReference | Ja |
| Integrationslaufzeit | Die Computeumgebung, in der der Datenfluss ausgeführt wird. Wenn nicht angegeben, wird die autoresolve Azure Integrationslaufzeit verwendet. | IntegrationRuntimeReference | Nein |
| compute.coreCount | Die Anzahl von Kernen, die im Spark-Cluster verwendet werden. Kann nur angegeben werden, wenn die autoresolve Azure Integrationslaufzeit verwendet wird. | 8, 16, 32, 48, 80, 144, 272 | Nein |
| compute.computeType | Die Art der Berechnung, die im Spark-Cluster verwendet wird. Kann nur angegeben werden, wenn die autoresolve Azure Integrationslaufzeit verwendet wird. | „Allgemein“ | Nein |
| Staging.VerknüpfterDienst | Geben Sie das für PolyBase-Staging verwendete Speicherkonto an, wenn Sie eine Azure Synapse Analytics-Quelle oder -Senke verwenden. Wenn Ihr Azure Storage mit einem VNet-Dienstendpunkt konfiguriert ist, müssen Sie die verwaltete Identitätsauthentifizierung verwenden, wobei "vertrauenswürdigen Microsoft-Dienst zulassen" im Speicherkonto aktiviert ist. Weitere Informationen finden Sie unter Auswirkungen der Verwendung von VNet-Dienstendpunkten mit Azure-Speicher. Außerdem lernen Sie die erforderlichen Konfigurationen für Azure Blob bzw. Azure Data Lake Storage Gen2 kennen. |
LinkedServiceReference | Nur wenn der Datenfluss Daten in Azure Synapse Analytics liest oder schreibt |
| staging.folderPath | Der für das PolyBase-Staging verwendete Ordnerpfad im Blobspeicherkonto, wenn Sie eine Azure Synapse Analytics-Quelle oder -Senke verwenden. | String | Nur wenn der Datenfluss Daten in Azure Synapse Analytics liest oder schreibt |
| traceLevel | Festlegen des Protokollierungsniveaus bei der Ausführung Ihrer Datenflussaktivität | Fein, Grob, Keine | Nein |
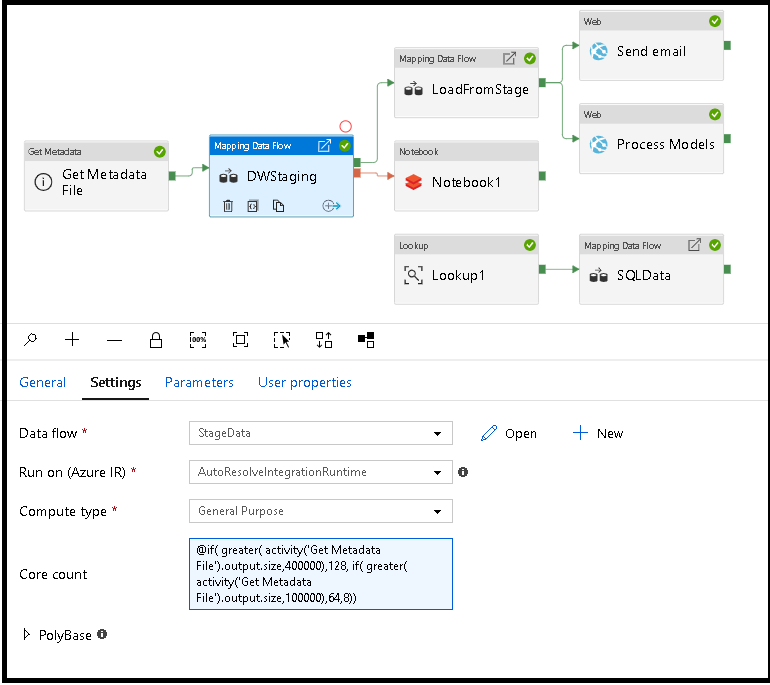
Dynamisches Bestimmen der Größe der Computekapazität für den Datenfluss zur Laufzeit
Die Eigenschaften „Anzahl Kerne“ und „Computetyp“ können dynamisch festgelegt werden, um die Größe der eingehenden Quelldaten zur Laufzeit anzupassen. Verwenden Sie Pipelineaktivitäten wie „Nachschlagen“ oder „Metadaten abrufen“, um die Größe der Daten im Quelldatenset zu bestimmen. Verwenden Sie dann "Dynamischen Inhalt hinzufügen" in den Datenfluss Aktivitätseigenschaften. Sie können kleine, mittlere oder große Computegrößen auswählen. Wählen Sie optional "Benutzerdefiniert" aus, und konfigurieren Sie die Berechnungstypen und die Anzahl der Kerne manuell.
Hier finden Sie ein kurzes Videotutorial, das diese Technik erläutert.
Datenfluss Integrationslaufzeit
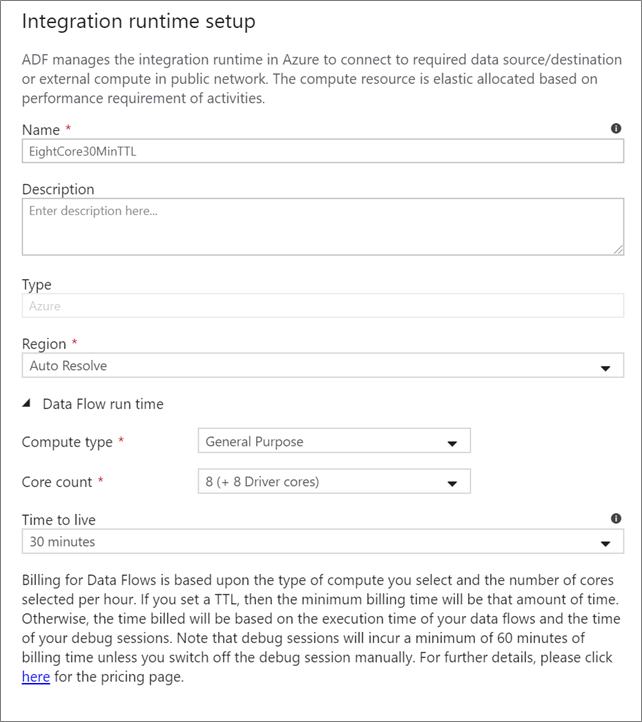
Wählen Sie aus, welche Integration Runtime für die Ausführung Ihrer Datenfluss Aktivität verwendet werden soll. Standardmäßig verwendet der Dienst die Autoresolve Azure Integrationslaufzeit mit vier Arbeitskernen. Diese Integration Runtime weist einen allgemeinen Computetyp auf und wird in derselben Region wie Ihre Dienstinstanz ausgeführt. Für operationalisierte Pipelines wird dringend empfohlen, eigene Azure Integrationslaufzeiten zu erstellen, die bestimmte Regionen, Computetyp, Kernanzahl und TTL für die Ausführung ihrer Datenflussaktivität definieren.
Für die meisten Produktionsworkloads wird mindestens ein Computetyp „Allgemeiner Zweck“ mit einer Konfiguration von 8+8 (insgesamt 16 virtuellen Kernen) und einer Lebensdauer (Time to live, TTL) von zehn Minuten empfohlen. Durch Festlegen einer kurzen TTL kann die Azure IR einen warmen Cluster aufrechterhalten, der die mehrminütige Startzeit eines kalten Clusters vermeidet. Weitere Informationen finden Sie unter Azure Integration runtime.
Wichtig
Die Integration-Runtime-Auswahl in der Datenfluss-Aktivität gilt nur für triggerierte Ausführungen Ihrer Pipeline. Das Debuggen Ihrer Pipeline mit Datenflüssen wird auf dem in der Debugsitzung angegebenen Cluster ausgeführt.
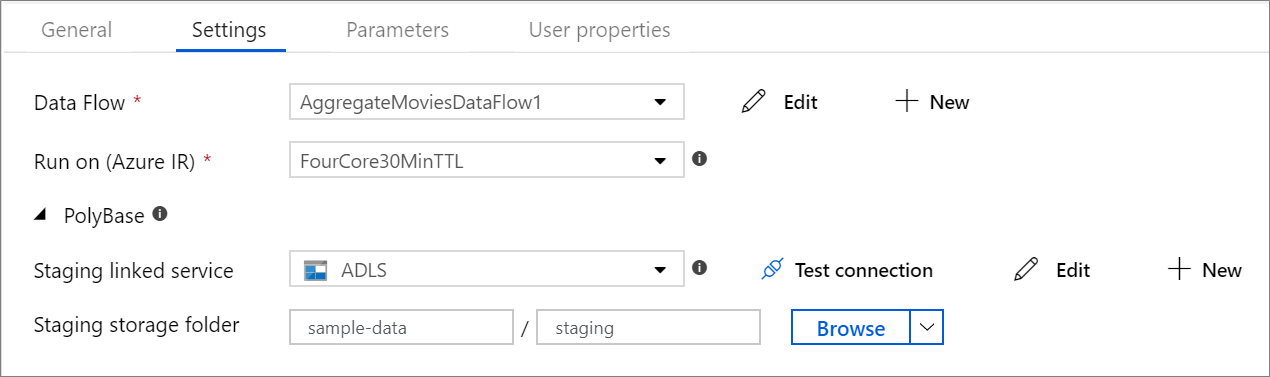
PolyBase
Wenn Sie Azure Synapse Analytics als Senke oder Quelle verwenden, müssen Sie einen Stagingspeicherort für Ihren PolyBase-Batchladevorgang auswählen. PolyBase ermöglicht das Batchladen per Massenvorgang, anstatt die Daten zeilenweise zu laden. PolyBase reduziert die Ladezeit drastisch in Azure Synapse Analytics.
Prüfpunktschlüssel
Wenn Sie die Änderungserfassungsoption für Datenflussquellen verwenden, verwaltet ADF den Prüfpunkt automatisch für Sie. Der Standardprüfpunktschlüssel ist ein Hash des Datenflussnamens und des Pipelinenamens. Wenn Sie ein dynamisches Muster für Ihre Quelltabellen oder -ordner verwenden, können Sie hier diesen Hash überschreiben und selbst einen Wert für den Prüfpunktschlüssel festlegen.
Protokollierungsgrad
Wenn es nicht erforderlich ist, dass jede Pipelineausführung Ihrer Datenflussaktivitäten alle ausführlichen Telemetrieprotokolle vollständig protokolliert, können Sie den Protokolliergrad optional auf „Standard“ oder „Kein“ festlegen. Wenn Sie Ihre Datenflüsse im Modus „Ausführlich“ (Standard) ausführen, fordern Sie vom Dienst, dass die Aktivität während der Datentransformation auf den einzelnen Partitionsebenen vollständig protokolliert wird. Da dies ein kostspieliger Vorgang sein kann, kann nur die ausschließliche Aktivierung von „Ausführlich“ bei der Problembehandlung den gesamten Datenfluss und die Pipelineleistung verbessern. Im Modus „Standard“ wird nur die Dauer der Transformation protokolliert, während der Modus „Kein“ lediglich eine Zusammenfassung der Werte für die Dauer bereitstellt.

Sink-Eigenschaften
Mit der Gruppierungsfunktion in Datenflüssen können Sie sowohl die Ausführungsreihenfolge der Senken festlegen als auch Senken unter Verwendung derselben Gruppennummer gruppieren. Um die Verwaltung von Gruppen zu erleichtern, können Sie den Dienst anweisen, Senken aus der gleichen Gruppe parallel auszuführen. Sie können die Senkengruppe auch so festlegen, dass sie selbst dann fortgesetzt wird, wenn bei einer der Senken ein Fehler auftritt.
Beim Standardverhalten einer Datenflusssenke wird jede Senke sequenziell ausgeführt, und der Datenfluss wird abgebrochen, wenn ein Fehler in der Senke auftritt. Außerdem werden alle Senken standardmäßig der gleichen Gruppe zugeordnet, es sei denn, Sie ändern die Datenflusseigenschaften und legen unterschiedliche Prioritäten für die Senken fest.

Nur erste Zeile
Diese Option ist nur für Datenflüsse verfügbar, für die Cachesenken für "Ausgabe an Aktivität" aktiviert sind. Die Ausgabe des Datenflusses, der direkt in Ihre Pipeline eingefügt wird, ist auf 2 MB beschränkt. Wenn Sie "Nur erste Zeile" festlegen, können Sie die Datenausgabe des Datenflusses einschränken, wenn Sie die Ausgabe der Datenflussaktivität direkt in Ihre Pipeline einfügen.
Parametrisieren von Datenflüssen
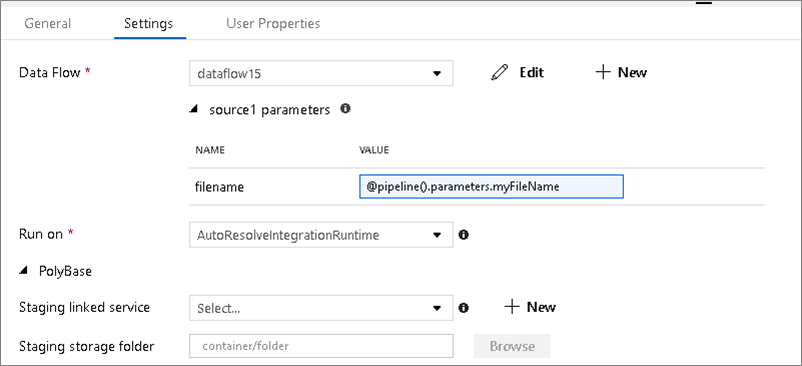
Parametrisierte Datasets
Wenn im Datenfluss parametrisierte Datasets verwendet werden, legen Sie die Parameterwerte auf der Registerkarte Einstellungen fest.
Parametrisierte Datenflüsse
Wenn Ihr Datenfluss parametrisiert ist, legen Sie die dynamischen Werte der Datenflussparameter auf der Registerkarte Parameter fest. Sie können entweder die Pipelineausdruckssprache oder die Datenflussausdruckssprache verwenden, um dynamische oder literale Parameterwerte zuzuweisen. Weitere Informationen finden Sie unter Datenfluss Parameters.
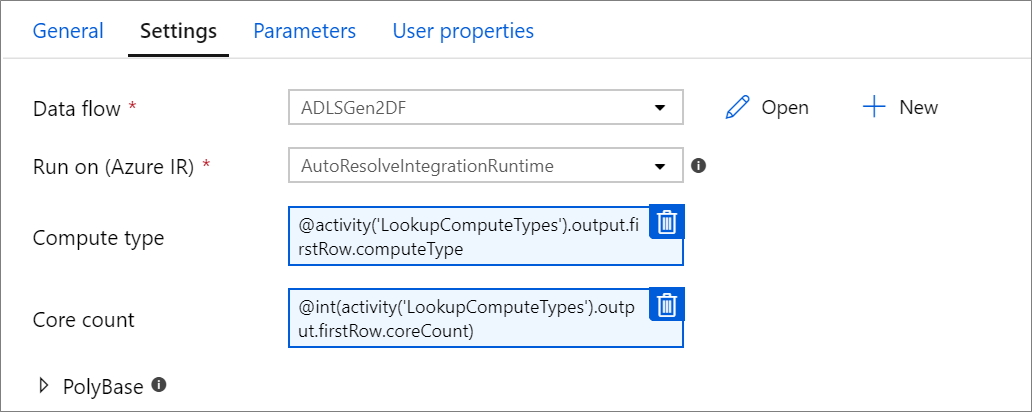
Parametrisierte Rechen-Eigenschaften.
Sie können die Kernanzahl oder den Computetyp parametrisieren, wenn Sie die autoesolve Azure Integrationslaufzeit verwenden und Werte für compute.coreCount und compute.computeType angeben.
Debuggen der Pipeline der Datenflussaktivität
Um eine Debugpipeline mit einer Datenfluss-Aktivität auszuführen, müssen Sie data flow Debugmodus über den Datenfluss DebugSchieberegler auf der oberen Leiste aktivieren. Im Debugmodus können Sie den Datenfluss für einen aktiven Spark-Cluster ausführen. Weitere Informationen finden Sie unter Debugmodus.

Die Debugpipeline wird für den aktiven Debugcluster ausgeführt, nicht die Integrationslaufzeitumgebung, die in den Datenfluss Aktivitätseinstellungen angegeben ist. Beim Starten des Debugmodus können Sie die Computeumgebung für das Debuggen auswählen.
Überwachen der Datenfluss-Aktivität
Die Datenfluss-Aktivität verfügt über eine spezielle Überwachungserfahrung, in der Sie Partitionierungs-, Phasen- und Datenlinieninformationen anzeigen können. Sie öffnen den Überwachungsbereich über das Brillensymbol unter Aktionen. Weitere Informationen finden Sie unter Überwachen von Datenflüssen.
Verwenden Sie die Ergebnisse der Datenflussaktivität in einer nachfolgenden Aktivität.
Die Datenflussaktivität gibt Metriken bezüglich der Anzahl der Zeilen aus, die in jeder Senke geschrieben werden und die in jeder Quelle gelesen werden. Diese Ergebnisse werden im Abschnitt output des Ergebnisses der Aktivitätsausführung zurückgegeben. Die zurückgegebenen Metriken weisen das Format des folgenden JSON auf.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Verwenden Sie beispielsweise @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten, um die Anzahl der in eine Senke namens „sink1“ in einer Aktivität namens „dataflowActivity“ geschriebenen Zeile zu erhalten.
Verwenden Sie @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead, um die Anzahl der von einer Quelle namens „source1“ gelesenen Zeile abzurufen, die in dieser Senke verwendet wurde.
Hinweis
Wenn für eine Senke keine Zeilen geschrieben wurden, wird sie in Metriken nicht angezeigt. Die Existenz kann mit der contains-Funktion überprüft werden. Beispielsweise überprüft contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1'), ob in „sink1“ Zeilen geschrieben wurden.
Zugehöriger Inhalt
Siehe unterstützte Ablaufsteuerungsaktivitäten: