Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Artikel werden die Features zur Optimierung der Kopieraktivität beschrieben, die Sie in Azure Data Factory- und Synapse-Pipelines nutzen können.
Konfigurieren von Leistungsfunktionen mit der Benutzeroberfläche
Wenn Sie eine Kopier-Aktivität im Pipeline-Editor auf der Leinwand auswählen und die Registerkarte "Einstellungen" im Konfigurationsbereich der Aktivität unter der Leinwand öffnen, werden Ihnen Optionen zum Konfigurieren aller unten beschriebenen Leistungsmerkmale angezeigt.
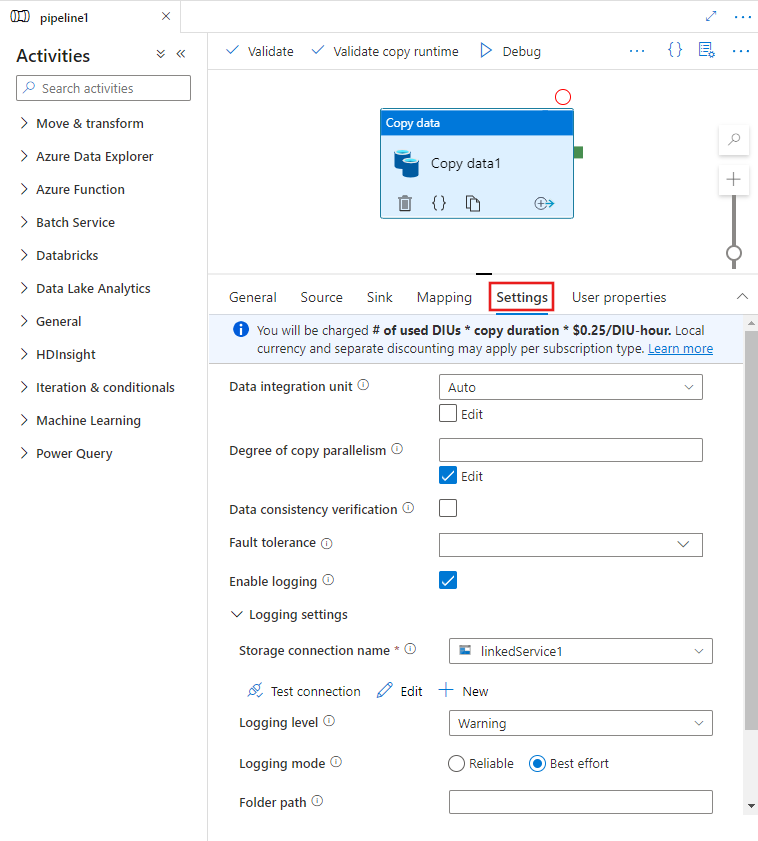
Datenintegrationseinheiten
Eine Datenintegrationseinheit ist eine Messgröße für die Leistungsfähigkeit (Kombination aus zugeteilten CPU-, Speicher- und Netzwerkressourcen) einer einzelnen Einheit innerhalb des Diensts. Die Datenintegrationseinheit gilt nur für Azure Laufzeitumgebung, jedoch nicht für selbst gehostete Integrationslaufzeitumgebung.
Die zulässige Anzahl von DIUs für die Ausführung einer Copy-Aktivität liegt zwischen 4 und 256. Wenn diese Option nicht angegeben ist oder Sie auf der Benutzeroberfläche „Auto“ auswählen, wendet der Dienst dynamisch die optimale DIU-Einstellung auf dem Quelle-Senke-Paar und dem Datenmuster basierend an. In der nachstehenden Tabelle sind die unterstützten DIU-Bereiche und das Standardverhalten in verschiedenen Kopierszenarien aufgeführt:
| Kopierszenario | Unterstützter DIU-Bereich | Standard-DIUs, die vom Dienst bestimmt werden |
|---|---|---|
| Zwischen Speicherorten |
-
Kopieren von/zu einer einzelnen Datei: 4 - Kopieren aus mehreren Dateien oder in mehrere Dateien: 4–256, je nach Anzahl und Größe der Dateien Wenn Sie beispielsweise Daten aus einem Ordner mit 4 großen Dateien kopieren und die Hierarchie beibehalten möchten, ist die maximale effektive DIU gleich 16. Wenn Sie sich für das Zusammenführen der Datei entscheiden, ist die maximale effektive DIU gleich 4. |
Zwischen 4 und 32, je nach Anzahl und Größe der Dateien |
| Aus Dateispeicher in Nicht-Dateispeicher |
-
Kopieren aus einer einzelnen Datei: 4 - Kopieren aus mehreren Dateien: 4–256, je nach Anzahl und Größe der Dateien Wenn Sie beispielsweise Daten aus einem Ordner mit 4 großen Dateien kopieren, ist die maximale effektive DIU gleich 16. |
-
Kopieren in Azure SQL-Datenbank oder Azure Cosmos DB: zwischen 4 und 16, je nach der Senkenebene (DTUs/RUs) und dem Quelldateimuster - Kopieren in Azure Synapse Analytics mithilfe von PolyBase oder COPY-Anweisungen: 2 – Anderes Szenario: 4 |
| Vom Nicht-Dateispeicher zum Dateispeicher |
-
Copy aus partitionsoptionsfähigen Datenspeichern (einschließlich Azure Database for PostgreSQL, Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server und Teradata): 4-256 beim Schreiben in einen Ordner und 4 beim Schreiben in eine einzelne Datei. Beachten Sie, dass pro Quelldatenpartition bis zu 4 DIUs verwendet werden können. - Andere Szenarien: 4 |
-
Kopieren aus REST oder HTTP: 1 - Kopieren aus Amazon Redshift mithilfe von UNLOAD: 4 - Anderes Szenario: 4 |
| Zwischen Nicht-Dateispeichern |
-
Copy aus partitionsoptionsfähigen Datenspeichern (einschließlich Azure Database for PostgreSQL, Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server und Teradata): 4-256 beim Schreiben in einen Ordner und 4 beim Schreiben in eine einzelne Datei. Beachten Sie, dass pro Quelldatenpartition bis zu 4 DIUs verwendet werden können. - Andere Szenarien: 4 |
-
Kopieren aus REST oder HTTP: 1 - Anderes Szenario: 4 |
Sie können die für die einzelnen Kopiervorgänge verwendeten DIUs in der Überwachungsansicht der Kopieraktivität oder der Aktivitätsausgabe anzeigen. Weitere Informationen finden Sie unter Überwachung der Kopieraktivität. Wenn Sie diese Standardeinstellung überschreiben möchten, geben Sie einen Wert für die Eigenschaft dataIntegrationUnits wie folgt an. Die tatsächliche Anzahl von DIUs, die der Kopiervorgang zur Laufzeit verwendet, entspricht maximal dem konfigurierten Wert. Dies ist abhängig von Ihrem Datenmuster.
Ihnen wird die Anzahl der verwendeten DIUs * Kopierdauer * Einheitenpreis/DIU-Stunde in Rechnung gestellt. Sehen Sie sich hier die aktuellen Preise an. Je nach Abonnementtyp können lokale Währungen und separate Rabatte gelten.
Beispiel:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Skalierbarkeit der selbstgehosteten Integration Runtime (IR)
Wenn Sie einen höheren Durchsatz erreichen möchten, können Sie die selbstgehostete IR zentral oder horizontal hochskalieren:
- Wenn die CPU und der verfügbare Arbeitsspeicher auf dem Knoten der selbstgehosteten IR nicht vollständig genutzt werden, bei der Ausführung paralleler Aufträge aber das Limit erreicht wird, sollten Sie eine Skalierung nach oben durchführen, indem Sie die Anzahl der gleichzeitig ausführbaren Aufträge erhöhen, die auf einem Knoten ausgeführt werden dürfen. Anweisungen dazu finden Sie hier.
- Wenn jedoch die CPU-Auslastung auf dem selbstgehosteten IR-Knoten hoch ist oder der verfügbare Arbeitsspeicher gering ist, können Sie einen neuen Knoten hinzufügen, um die Last auf mehrere Knoten zu verteilen. Anweisungen dazu finden Sie hier.
Beachten Sie in den folgenden Szenarien, dass bei der Ausführung einer einzelnen Kopieraktivität mehrere Knoten einer selbstgehosteten IR genutzt werden können:
- Kopieren Sie Daten aus dateibasierten Speichern, je nach Anzahl und Größe der Dateien.
- Kopieren von Daten aus partitionsoptionsfähigen Datenspeicher (einschließlich Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server und Teradata), abhängig von der Anzahl der Datenpartitionen.
Parallele Kopie
Sie können die parallele Kopie (die
Die parallele Kopie ist orthogonal zu Datenintegrationseinheiten oder Knoten der selbstgehosteten IR. Sie wird für alle DIUs oder Knoten der selbstgehosteten IR gezählt.
Bei jeder Ausführung einer Kopieraktivität wendet der Dienst standardmäßig die optimale Einstellung für parallele Kopien basierend auf Ihrem Quell-Senke-Paar und Datenmuster dynamisch an.
Tipp
Das Standardverhalten von parallelen Kopien bietet Ihnen normalerweise den besten Durchsatz, der vom Dienst automatisch festgelegt wird. Grundlage dafür ist das Quell-/Senkenpaar, das Datenmuster sowie die Anzahl der DIUs oder die CPU/der Arbeitsspeicher/die Anzahl der Knoten der selbstgehosteten IR. Unter Problembehandlung der Kopieraktivitätsleistung erfahren Sie, wann die Parallelkopie optimiert werden sollte.
In der folgenden Tabelle wird das parallele Kopierverhalten aufgeführt:
| Kopierszenario | Paralleles Kopierverhalten |
|---|---|
| Zwischen Speicherorten |
parallelCopies bestimmt die Parallelität auf Dateiebene. Die Chunk-Erstellung („Chunking“) innerhalb jeder Datei erfolgt im Hintergrund automatisch und transparent. Sie wurde so konzipiert, dass die am besten geeignete Blockgröße für einen bestimmten Datenspeichertyp zum parallelen Laden von Daten verwendet wird. Die tatsächliche Anzahl paralleler Kopien, die von der Kopieraktivität zur Laufzeit verwendet werden, ist nicht mehr als die Anzahl Ihrer verfügbaren Dateien. Bei Verwendung des Kopierverhaltens mergeFile in die Dateisenke kann die Kopieraktivität die Parallelität auf Dateiebene nicht nutzen. |
| Aus Dateispeicher in Nicht-Dateispeicher | – Beim Kopieren von Daten in Azure SQL-Datenbank oder Azure Cosmos DB ist die standardmäßige parallele Kopie auch abhängig von der Senkenebene (Anzahl von DTUs/RUs). - Beim Kopieren von Daten in Azure Tabelle ist die parallele Standardkopie 4. |
| Vom Nicht-Dateispeicher zum Dateispeicher | - Beim Kopieren von Daten aus dem partitionsoptionsfähigen Datenspeicher (einschließlich Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS für Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS für SQL Server und Teradata) ist die standardmäßige parallele Kopie 4. Die tatsächliche Anzahl paralleler Kopien, die von der Kopieraktivität zur Laufzeit verwendet werden, ist nicht mehr als die Anzahl Ihrer verfügbaren Datenpartitionen. Wenn Sie self-hosted Integration Runtime verwenden und in Azure Blob/ADLS Gen2 kopieren, beachten Sie, dass die maximale effektive parallele Kopie 4 oder 5 pro IR-Knoten ist. – Bei anderen Szenarien wird die parallele Kopie nicht wirksam. Selbst wenn Parallelität angegeben wurde, wird sie nicht angewendet. |
| Zwischen Nicht-Dateispeichern | – Beim Kopieren von Daten in Azure SQL-Datenbank oder Azure Cosmos DB ist die standardmäßige parallele Kopie auch abhängig von der Senkenebene (Anzahl von DTUs/RUs). - Beim Kopieren von Daten aus dem partitionsoptionsfähigen Datenspeicher (einschließlich Azure SQL-Datenbank, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS für Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS für SQL Server und Teradata) ist die standardmäßige parallele Kopie 4. - Beim Kopieren von Daten in Azure Tabelle ist die parallele Standardkopie 4. |
Sie können den Standardwert jedoch überschreiben und einen Wert für die Eigenschaft parallelCopies angeben, um die Last für die Computer zu steuern, auf denen Ihre Datenspeicher gehostet werden, oder um die Kopierleistung zu optimieren. Der Wert muss eine ganze Zahl größer als oder gleich 1 sein. Zur Laufzeit verwendet die Kopieraktivität einen Wert, der kleiner oder gleich dem von Ihnen festgelegten Wert ist, um die beste Leistung zu erzielen.
Berücksichtigen Sie bei der Angabe eines Werts für die Eigenschaft parallelCopies die höhere Auslastung Ihrer Quell- und Senkendatenspeicher. Berücksichtigen Sie auch den Lastanstieg zur selbstgehosteten Integration Runtime, wenn die Kopieraktivität davon abhängt. Dieser Lastanstieg tritt insbesondere auf, wenn Sie über mehrere Aktivitäten oder gleichzeitige Ausführungen der gleichen Aktivitäten verfügen, die für den gleichen Datenspeicher ausgeführt werden. Wenn Sie eine Überlastung des Datenspeichers oder der selbstgehosteten Integration Runtime feststellen, verringern Sie den Wert parallelCopies, um die Last zu verringern.
Beispiel:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
gestaffeltem Kopieren
Wenn Sie Daten aus einem Quelldatenspeicher in einen Sinkdatenspeicher kopieren, können Sie Azure Blob-Speicher oder Azure Data Lake Storage Gen2 als Zwischen-Staging-Speicher verwenden. Staging ist besonders in folgenden Fällen hilfreich:
- Sie möchten Daten aus verschiedenen Datenspeichern über PolyBase in Azure Synapse Analytics aufnehmen, Daten aus/nach Snowflake kopieren oder Daten von Amazon Redshift/HDFS performant aufnehmen. Ausführliche Informationen finden Sie unter:
- Aufgrund der IT-Richtlinien des Unternehmens sollten Sie mit Ausnahme der Ports 80 und 443 keine weiteren Ports in der Firewall öffnen. Wenn Sie beispielsweise Daten aus einem lokalen Datenspeicher in eine Azure SQL-Datenbank oder eine Azure Synapse Analytics kopieren, müssen Sie die ausgehende TCP-Kommunikation an Port 1433 sowohl für die Windows Firewall als auch für Ihre Unternehmensfirewall aktivieren. In diesem Szenario kann die gestaffelte Kopie die selbst gehostete Integrationslaufzeit nutzen, um Daten zuerst in einen Stagingspeicher über HTTP oder HTTPS auf Port 443 zu kopieren und anschließend die Daten aus dem Staging in eine SQL-Datenbank oder in Azure Synapse Analytics zu laden. In diesem Ablauf müssen Sie den Port 1433 nicht aktivieren.
- Hybriddatenverschiebungen (also das Kopieren aus einem lokalen Datenspeicher in einen Clouddatenspeicher) können bei einer langsamen Netzwerkverbindung eine Weile dauern. Zur Verbesserung der Leistung können Sie gestaffeltes Kopieren verwenden, um die Daten lokal zu komprimieren und dadurch die Verschiebung in den Stagingdatenspeicher in der Cloud zu beschleunigen. Anschließend können Sie die Daten im Stagingspeicher wieder dekomprimieren, bevor Sie sie in den Zieldatenspeicher laden.
Funktionsweise des gestaffelten Kopierens
Wenn Sie das Stagingfeature aktivieren, werden die Daten zuerst aus dem Quelldatenspeicher in den Stagingspeicher kopiert (bringen Sie Ihr eigenes Azure Blob oder Azure Data Lake Storage Gen2). Danach werden sie aus dem Staging- in den Senkendatenspeicher kopiert. Die Kopieraktivität verwaltet den zweistufigen Ablauf automatisch und löscht außerdem nach Abschluss der Datenverschiebung temporäre Daten aus dem Stagingspeicher.

Sie müssen Ihrem Azure Data Factory in Ihrem Stagingspeicher Löschberechtigungen erteilen, damit die temporären Daten nach ausführung der Kopieraktivität bereinigt werden können.
Wenn Sie die Datenverschiebung unter Verwendung eines Stagingspeichers aktivieren, können Sie angeben, ob die Daten vor dem Verschieben aus dem Quelldatenspeicher in den Stagingspeicher komprimiert und dann vor dem Verschieben aus einem Zwischen- oder Stagingdatenspeicher in den Senkendatenspeicher dekomprimiert werden sollen.
Derzeit können Sie keine Daten zwischen zwei Datenspeichern kopieren, die über verschiedene selbstgehostete IRs verbunden sind, weder mit noch ohne gestaffeltes Kopieren. Für ein solches Szenario können Sie zwei explizit verkettete Kopiervorgänge konfigurieren, um von der Quelle zum Stagingspeicher und aus dem Stagingspeicher zur Senke zu kopieren.
Konfiguration
Konfigurieren Sie für die Kopieraktivität die Einstellung enableStaging, um anzugeben, ob die Daten vor dem Laden in das Zieldatenspeicher zwischengespeichert werden sollen. Wenn Sie enableStaging auf TRUE festlegen, müssen Sie zusätzliche Eigenschaften angeben. Diese sind in der folgenden Tabelle aufgeführt.
| Eigenschaft | Beschreibung | Standardwert | Erforderlich |
|---|---|---|---|
| Staging aktivieren | Geben Sie an, ob Sie Daten über einen temporären Zwischenspeicher kopieren möchten. | Falsch | Nein |
| linkedServiceName | Geben Sie den Namen eines Azure Blob Storage oder Azure Data Lake Storage Gen2 verknüpften Diensts an, der sich auf die Instanz des Speichers bezieht, die Sie als Zwischen-Staging-Speicher verwenden. | – | Ja, wenn enableStaging auf „TRUE“ festgelegt ist. |
| Pfad | Geben Sie den gewünschten Pfad für die vorbereiteten Daten an. Wenn Sie keinen Pfad angeben, erstellt der Dienst einen Container zum Speichern der temporären Daten. | – | Nein (Ja, wenn storageIntegration im Snowflake-Connector angegeben ist) |
| enableCompression | Gibt an, ob die Daten komprimiert werden sollen, bevor sie an das Ziel kopiert werden. Durch diese Einstellung wird die Menge der übertragenen Daten reduziert. | Falsch | Nein |
Hinweis
Wenn Sie das gestaffelte Kopieren mit aktivierter Komprimierung verwenden, wird die Dienstprinzipal- oder MSI-Authentifizierung für das Staging eines verknüpften Blobdiensts nicht unterstützt.
Hier sehen Sie eine Beispieldefinition der Kopieraktivität mit den Eigenschaften aus der obigen Tabelle:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Auswirkungen auf die Abrechnung von gestaffeltem Kopieren
Die Abrechnung basiert auf zwei Aspekten: Dauer des Kopiervorgangs und Art der Kopie.
- Wenn Sie beim Kopieren von Daten zwischen Clouddatenspeichern mit Staging arbeiten, wobei beide Phasen durch die Azure-Integrationslaufzeit unterstützt werden, berechnen wir Ihnen die Gebühren als [Summe der Kopierdauer für Schritt 1 und Schritt 2] x [Preis pro Cloudkopieneinheit].
- Wenn Sie während eines Hybridkopiervorgangs (d. h. beim Kopieren von Daten aus einem lokalen Datenspeicher in einen Clouddatenspeicher) Staging verwenden, wobei eine Phase durch eine selbstgehostete Integration Runtime unterstützt wird, berechnet sich die Gebühr folgendermaßen: [Dauer des Hybridkopiervorgangs] x [Einheitspreis für Hybridkopien] + [Dauer des Cloudkopiervorgangs] x [Einheitspreis für Cloudkopien].
Zugehöriger Inhalt
Weitere Informationen finden Sie in den anderen Artikeln zur Kopieraktivität:
- Übersicht über die Kopieraktivität
- Leitfaden zur Leistung und Skalierbarkeit der Kopieraktivität
- Probleme bei der Leistung von Kopieraktivitäten beheben
Use Azure Data Factory, um Daten aus Ihrem Data Lake oder Data Warehouse zu Azure - Daten von Amazon S3 zu Azure Storage migrieren