Kopieren von Daten aus SAP HANA mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Azure Synapse Analytics-Pipelines verwenden, um Daten aus einer SAP HANA-Datenbank zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Tipp
Informationen zur allgemeinen Unterstützung des SAP-Datenintegrationsszenarios finden Sie im Whitepaper zur SAP-Datenintegration. Dieses Whitepaper bietet eine detaillierte Einführung in die einzelnen SAP-Connectors, einen Vergleich und Leitfäden.
Unterstützte Funktionen
Für den SAP HANA-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/Senke) | ② |
| Lookup-Aktivität | ② |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Dieser SAP HANA-Connector unterstützt insbesondere Folgendes:
- Kopieren von Daten von einer SAP HANA-Datenbank mit einer beliebigen Version
- Kopieren von Daten aus HANA-Informationsmodellen (z.B. Analyse- und Berechnungsansichten) und aus Zeile/Spalte-Tabellen.
- Kopieren von Dateien unter Verwendung der Standard- oder Windows-Authentifizierung
- Paralleles Kopieren von einer SAP HANA-Quelle. Weitere Informationen finden Sie im Abschnitt Paralleles Kopieren von SAP HANA.
Tipp
Verwenden Sie zum Kopieren von Daten in SAP HANA-Datenspeicher einen generischen ODBC-Connector. Ausführliche Informationen hierzu finden Sie im Abschnitt SAP HANA-Senke. Beachten Sie, dass die verknüpften Dienste für SAP HANA-Connectors und ODBC-Connectors unterschiedlichen Typs sind und daher nicht wiederverwendet werden können.
Voraussetzungen
Zum Verwenden dieses SAP HANA-Connectors müssen Sie folgende Schritte durchführen:
- Richten Sie eine selbstgehostete Integration Runtime ein. Im Artikel Selbstgehostete Integration Runtime finden Sie Details.
- Installieren des SAP HANA-ODBC-Treibers auf dem Computer mit der Integrationslaufzeit. Sie können den SAP HANA-ODBC-Treiber aus dem SAP Software Download Center herunterladen. Suche Sie mit dem Schlüsselwort SAP HANA CLIENT for Windows.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts mit SAP HANA über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst mit SAP HANA auf der Azure-Portal-Benutzeroberfläche zu erstellen.
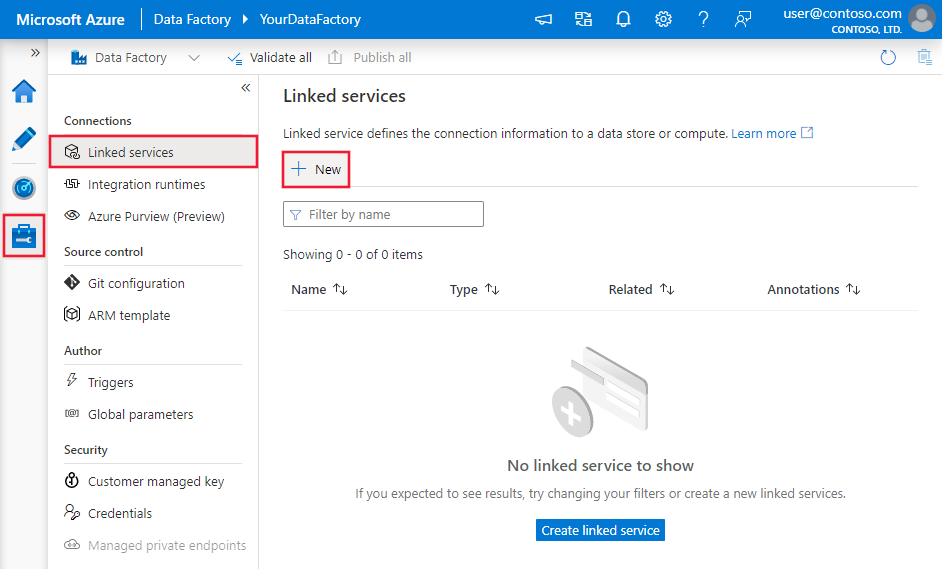
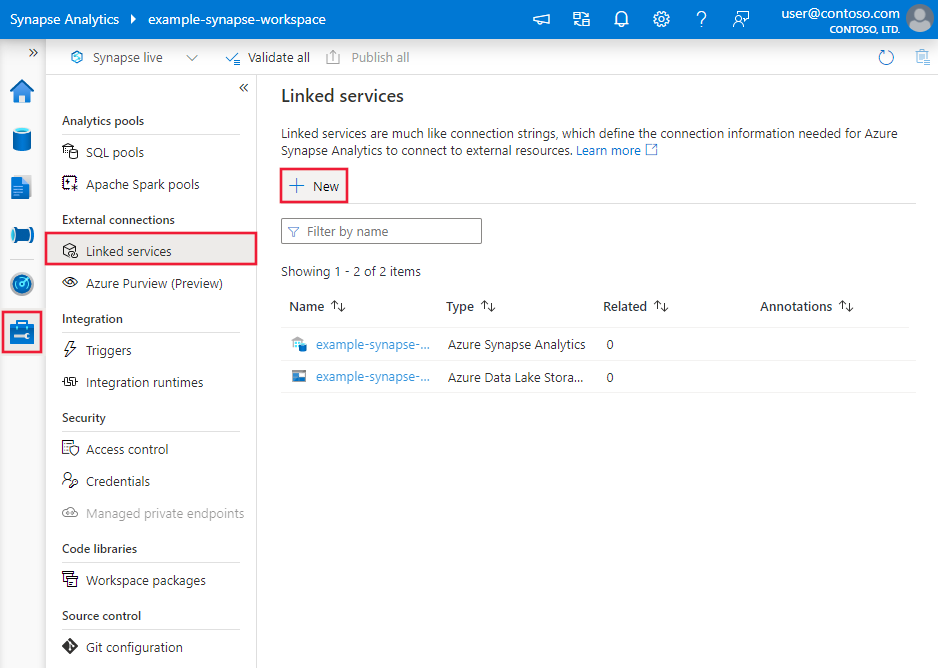
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach SAP, und wählen Sie die SAP HANA-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.

Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den SAP HANA-Connector verwendet werden:
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit SAP HANA verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Folgendes festgelegt werden: SapHana | Ja |
| connectionString | Geben Sie die Informationen an, die zum Herstellen einer Verbindung mit SAP HANA mithilfe der Standardauthentifizierung oder Windows-Authentifizierung benötigt werden. Sehen Sie sich die folgenden Beispiele an. In der Verbindungszeichenfolge ist Server/Port obligatorisch (der Standardport ist 30015), und Benutzername und Kennwort sind bei der Verwendung von Standardauthentifizierung obligatorisch. Weitere erweiterte Einstellungen finden Sie unter Eigenschaften der SAP Hana ODBC-Verbindung. Sie können das Kennwort auch in Azure Key Vault speichern und die Kennwortkonfiguration aus der Verbindungszeichenfolge pullen. Ausführlichere Informationen finden Sie im Artikel Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| userName | Geben Sie den Benutzernamen an, wenn Sie Windows-Authentifizierung verwenden. Beispiel: user@domain.com |
Nein |
| password | Geben Sie ein Kennwort für das Benutzerkonto an. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Eine selbstgehostete Integrationslaufzeit ist erforderlich, wie unter Voraussetzungen erwähnt wird. | Ja |
Beispiel: Verwenden von Standardauthentifizierung
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Verwenden von Windows-Authentifizierung
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Wenn Sie den verknüpften SAP HANA-Dienst mit der folgenden Nutzlast verwendet haben, wird er weiterhin unverändert unterstützt. Es wird jedoch empfohlen, zukünftig die neue Version zu verwenden.
Beispiel:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom SAP HANA-Dataset unterstützt werden.
Beim Kopieren von Daten aus SAP HANA werden die folgenden Eigenschaften unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf folgenden Wert festgelegt werden: SapHanaTable | Ja |
| schema | Der Name des Schemas in der SAP HANA-Datenbank. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| table | Der Name der Tabelle in der SAP HANA-Datenbank. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Wenn Sie das Datenset vom Typ RelationalTable verwenden, wird es weiterhin unverändert unterstützt. Es wird jedoch empfohlen, zukünftig die neue Version zu verwenden.
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der SAP HANA-Quelle unterstützt werden.
SAP HANA als Quelle
Tipp
Weitere Informationen zum effizienten Erfassen von Daten von SAP HANA mithilfe der Datenpartitionierung finden Sie im Abschnitt Paralleles Kopieren von SAP HANA.
Wenn Sie Daten aus SAP HANA kopieren möchten, werden die folgenden Eigenschaften im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: SapHanaSource | Ja |
| Abfrage | Gibt die SQL-Abfrage an, mit der Daten aus der SAP HANA-Instanz gelesen werden. | Ja |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, mit denen Daten von SAP HANA erfasst werden. Weitere Informationen finden Sie im Abschnitt Paralleles Kopieren von SAP HANA. Zulässige Werte sind: None (Standard), PhysicalPartitionsOfTable, SapHanaDynamicRange. Weitere Informationen finden Sie im Abschnitt Paralleles Kopieren von SAP HANA. PhysicalPartitionsOfTable kann nur beim Kopieren von Daten aus einer Tabelle, jedoch nicht bei Abfragen verwendet werden. Wenn eine Partitionsoption aktiviert ist (nicht None), wird der Grad an Parallelität zum gleichzeitigen Laden von Daten von SAP HANA durch die Einstellung parallelCopies für die Kopieraktivität gesteuert. |
False |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie ihn, wenn die Partitionsoption SapHanaDynamicRange lautet. |
False |
| partitionColumnName | Geben Sie den Namen der Quellspalte an, die von der Partitionierung für den parallelen Kopiervorgang verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. Verwenden Sie diese Option, wenn die Partitionsoption SapHanaDynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfHanaDynamicRangePartitionCondition in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren von SAP HANA. |
Ja, wenn die Partitionierung SapHanaDynamicRange verwendet wird. |
| packetSize | Gibt die Netzwerkpaketgröße (in KB) an, mit der Daten auf mehrere Blöcke aufgeteilt werden. Wenn Sie über eine große Datenmenge verfügen, die kopiert werden soll, kann das Erhöhen der Paketgröße in den meisten Fällen die Lesegeschwindigkeit aus SAP Hana erhöhen. Leistungstests werden empfohlen, wenn die Paketgröße angepasst wird. | Nein. Der Standardwert ist 2.048 (2MB). |
Beispiel:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Wenn Sie die Kopierquelle vom Typ RelationalSource verwenden, wird sie weiterhin unverändert unterstützt. Es wird jedoch empfohlen, zukünftig die neue Version zu verwenden.
Paralleles Kopieren von SAP HANA
Der SAP HANA-Connector bietet eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten von SAP HANA. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.

Wenn Sie partitioniertes Kopieren aktivieren, führt Data Factory parallele Abfragen für Ihre SAP HANA-Quelle aus, um Daten anhand von Partitionen abzurufen. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier (4) festlegen, generiert der Dienst gleichzeitig vier Abfragen auf der Grundlage der von Ihnen angegebenen Partitionsoption und -einstellungen und führt sie aus. Dabei ruft jede Abfrage einen Teil der Daten aus Ihrer SAP HANA-Instanz ab.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung zu aktivieren. Das gilt insbesondere, wenn Sie große Datenmengen von Ihrer SAP HANA-Instanz erfassen. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus großer Tabelle | Partitionsoption: Physische Partitionen der Tabelle. Bei der Ausführung erkennt der Dienst automatisch den physischen Partitionstyp der angegebenen SAP HANA-Tabelle und wählt die entsprechende Partitionierungsstrategie aus: - Bereichspartitionierung: Ruft die für die Tabelle definierte Partitionsspalte und die Partitionsbereiche ab und kopiert dann die Daten nach Bereich. - Hashpartitionierung: Verwenden Sie den Hashpartitionsschlüssel als Partitionsspalte. Danach partitionieren und kopieren Sie die Daten auf der Grundlage der vom Dienst berechneten Bereiche. - Roundrobin-Partitionierung oder Keine Partitionierung: Verwenden Sie den Primärschlüssel als Partitionsspalt. Danach partitionieren und kopieren Sie die Daten auf der Grundlage der vom Dienst berechneten Bereiche. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage | Partitionsoption: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Gibt die Spalte an, die zum Anwenden der dynamischen Bereichspartitionierung verwendet wird. Bei der Ausführung berechnet der Dienst zuerst die Wertebereiche der angegebenen Partitionsspalte, indem die Zeilen in mehreren Buckets entsprechend der Anzahl der unterschiedlichen Partitionsspaltenwerte und der Einstellung für paralleles Kopieren gleichmäßig verteilt werden. Anschließend wird ?AdfHanaDynamicRangePartitionCondition ersetzt, indem der Wertebereich der Partitionsspalte für jede Partition gefiltert wird, und das Ergebnis wird an SAP HANA gesendet.Wenn Sie mehrere Spalten als Partitionsspalten verwenden möchten, können Sie die Werte jeder Spalte in der Abfrage in einer Spalte verketten und als Partitionsspalte angeben, z. B. SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Beispiel: Abfrage mit physischen Partitionen einer Tabelle
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Datentypzuordnung für SAP HANA
Beim Kopieren von Daten aus SAP HANA werden die folgenden Zuordnungen von SAP HANA-Datentypen zu den vom Dienst intern verwendeten Zwischendatentypen verwendet. Unter Schema- und Datentypzuordnungen erfahren Sie, wie Sie Aktivitätszuordnungen für Quellschema und Datentyp in die Senke kopieren.
| SAP HANA-Datentyp | Zwischendatentyp des Diensts |
|---|---|
| ALPHANUM | String |
| bigint | Int64 |
| BINARY | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | String |
| DATE | Datetime |
| DECIMAL | Decimal |
| Double | Double |
| GLEITKOMMAZAHL | Double |
| INTEGER | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| real | Single |
| SECONDDATE | Datetime |
| SHORTTEXT | String |
| SMALLDECIMAL | Decimal |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXT | String |
| TIME | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | Datetime |
| VARBINARY | Byte[] |
SAP HANA-Senke
Der SAP HANA-Connector wird zurzeit nicht als Senke unterstützt, aber Sie können den generischen ODBC-Connector mit dem SAP HANA-Treiber verwenden, um Daten in SAP HANA zu schreiben.
Beachten Sie die Voraussetzungen, um zuerst die selbstgehostete Integration Runtime einzurichten und den SAP HANA ODBC-Treiber zu installieren. Erstellen Sie einen verknüpften ODBC-Dienst, um eine Verbindung mit Ihrem SAP HANA-Datenspeicher herzustellen, wie im folgenden Beispiel gezeigt wird. Erstellen Sie dann entsprechend die Senke für die DataSet- und Kopieraktivität mit dem ODBC-Typ. Weitere Informationen finden Sie im Artikel ODBC-Connector.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.