Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory-Pipelines als auch in Azure Synapse Analytics-Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Die Aggregattransformation definiert Aggregationen von Spalten in Ihren Datenströmen. Mithilfe des Ausdrucks-Generators können Sie verschiedene Arten von Aggregationen wie SUM, MIN, MAX und COUNT gruppiert nach vorhandenen oder berechneten Spalten definieren.
Gruppieren nach
Wählen Sie eine bereits vorhandene Spalte aus, oder erstellen Sie eine neue berechnete Spalte, um diese als GROUP BY-Klausel für Ihre Aggregation zu verwenden. Wenn Sie eine vorhandene Spalte verwenden möchten, wählen Sie sie aus der Dropdownliste aus. Zum Erstellen einer neuen berechneten Spalte zeigen Sie mit dem Mauszeiger auf die Klausel, und klicken Sie auf Berechnete Spalte. Dadurch öffnet sich der Datenfluss-Ausdrucks-Generator. Sobald Sie die berechnete Spalte erstellt haben, geben Sie den Namen der Ausgabespalte in das Feld Benennen als ein. Wenn Sie eine zusätzliche GROUP BY-Klausel hinzufügen möchten, zeigen Sie mit dem Mauszeiger auf eine bereits vorhandene Klausel, und klicken Sie auf das Pluszeichen.
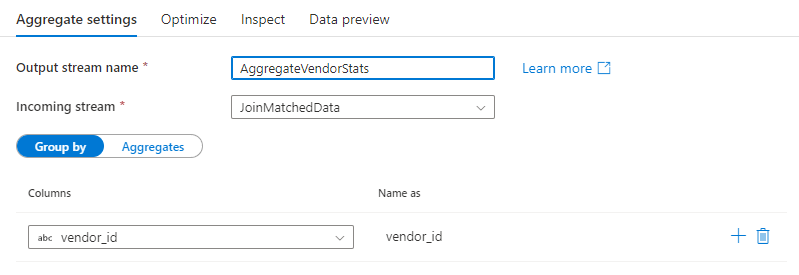
Die Verwendung einer GROUP BY-Klausel in einer Aggregattransformation ist optional.
Aggregatspalten
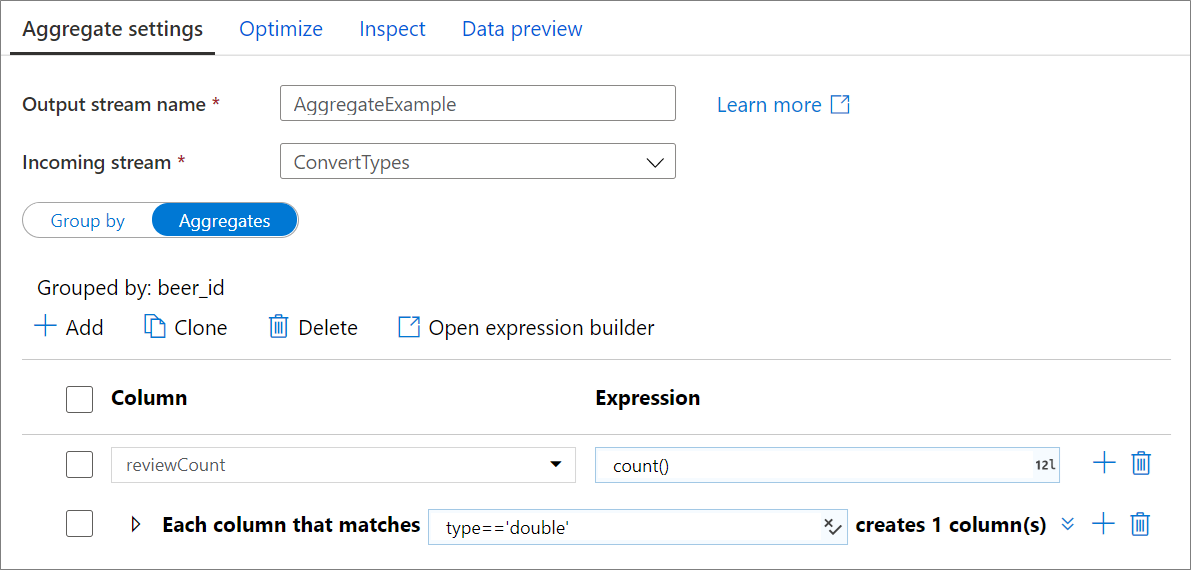
Wechseln Sie zur Registerkarte Aggregate, um Aggregationsausdrücke zu erstellen. Sie können entweder eine bereits vorhandene Spalte mit einer Aggregation überschreiben oder ein neues Feld mit einem neuen Namen erstellen. Der Aggregationsausdruck wird in das Feld auf der rechten Seite neben dem Selektor für den Spaltennamen eingegeben. Klicken Sie auf das Textfeld, und öffnen Sie den Ausdrucks-Generator, um den Ausdruck zu bearbeiten. Wenn Sie weitere Aggregatspalten hinzufügen möchten, klicken Sie oberhalb der Spaltenliste auf Hinzufügen, oder klicken Sie auf das Pluszeichen („+“) neben einer vorhandenen Aggregatspalte. Klicken Sie entweder auf Spalte hinzufügen oder auf Spaltenmuster hinzufügen. Jeder Aggregationsausdruck muss mindestens eine Aggregatfunktion enthalten.
Hinweis
Im Debugmodus kann der Ausdrucks-Generator keine Datenvorschau mit Aggregatfunktionen generieren. Wenn Sie die Datenvorschau für eine Aggregattransformation abrufen möchten, schließen Sie den Ausdrucks-Generator, und rufen Sie die Daten über die Registerkarte „Datenvorschau“ ab.
Spaltenmuster
Verwenden Sie Spaltenmuster, um dieselbe Aggregation auf eine Gruppe von Spalten anzuwenden. Dies ist nützlich, wenn Sie viele Spalten aus dem Eingabeschema beibehalten möchten, weil sie standardmäßig gelöscht werden. Verwenden Sie eine Heuristik wie first(), um Eingabespalten über die Aggregation hinaus beizubehalten.
Neuverbinden von Zeilen und Spalten
Aggregattransformationen ähneln SQL-Abfragen für die Aggregatauswahl. Spalten, die nicht in der GROUP BY-Klausel oder in den Aggregatfunktionen enthalten sind, fließen nicht in die Ausgabe der Aggregattransformation. Wenn Sie andere Spalten in die aggregierte Ausgabe einschließen möchten, führen Sie eine der folgenden Methoden aus:
- Verwenden Sie eine Aggregatfunktion, z.B.
last()oderfirst(), um die zusätzliche Spalte einzuschließen. - Verknüpfen Sie die Spalten mithilfe des Self-Join-Musters erneut mit dem Ausgabedatenstrom.
Entfernen doppelter Zeilen
Aggregattransformationen werden häufig für das Entfernen oder Identifizieren doppelter Einträge in Quelldaten verwendet. Dieser Prozess wird als Deduplizierung bezeichnet. Verwenden Sie basierend auf einem Satz von Gruppierungsschlüsseln eine Heuristik Ihrer Wahl, um zu ermitteln, welche der doppelten Zeilen Sie behalten möchten. Häufige Heuristiken sind first(), last(), max() und min(). Verwenden Sie Spaltenmuster, um die Regel auf alle Spalten mit Ausnahme der Group by-Spalten anzuwenden.
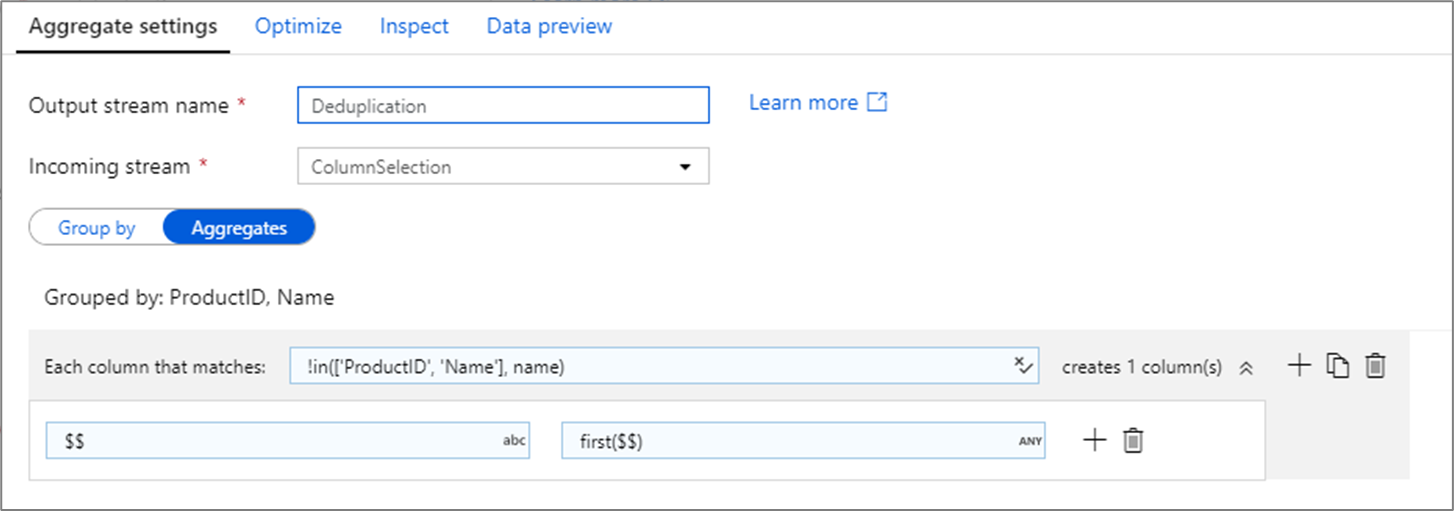
Im obigen Beispiel werden die Spalten ProductID und Name für die Gruppierung verwendet. Wenn zwei Zeilen identische Werte für diese beiden Spalten aufweisen, werden sie als Duplikate angesehen. In dieser Aggregattransformation werden die Werte der ersten übereinstimmenden Zeile beibehalten, und alle anderen werden entfernt. Mithilfe der Syntax von Spaltenmustern werden alle Spalten, deren Namen nicht ProductID und Name sind, dem vorhandenen Spaltennamen zugeordnet. Außerdem erhalten sie den Wert der ersten übereinstimmenden Zeile. Das Ausgabeschema ist mit dem Eingabeschema identisch.
Bei Datenüberprüfungsszenarien können Sie mithilfe der count()-Funktion zählen, wie viele Duplikate vorhanden sind.
Datenflussskript
Syntax
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Beispiel
Im folgenden Beispiel werden bei einem eingehenden Datenstrom MoviesYear die Zeilen nach der Spalte year gruppiert. Die Transformation erstellt eine Aggregatspalte avgrating, die den Durchschnitt der Spalte Rating ergibt. Diese Aggregattransformation hat den Namen AvgComedyRatingsByYear.
In der Benutzeroberfläche sieht diese Transformation wie in der folgenden Abbildung aus:
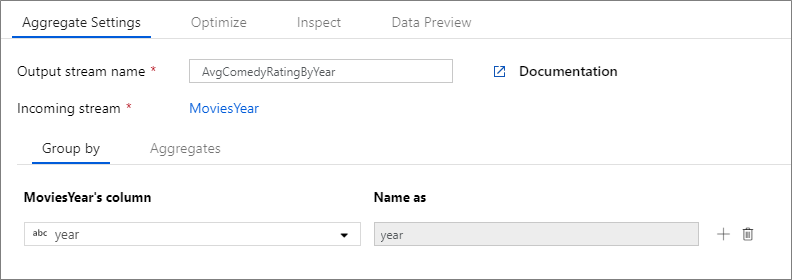
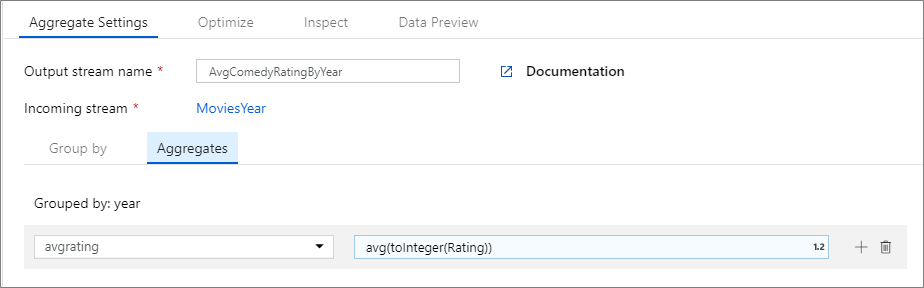
Das Datenflussskript für diese Transformation befindet sich im folgenden Codeausschnitt.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
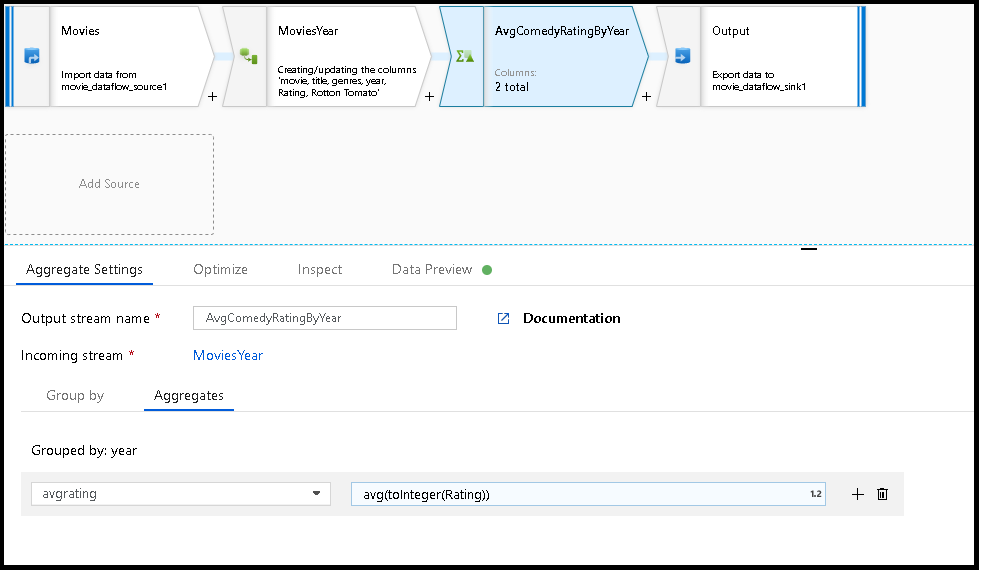
MoviesYear: Abgeleitete Spalte, die das Jahr und die Titelspalten definiert: AvgComedyRatingByYear Aggregattransformation für die durchschnittliche Bewertung von Komödien gruppiert nach Jahr: avgrating Name der neuen Spalte, die erstellt wird, um den aggregierten Wert aufzunehmen
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Zugehöriger Inhalt
- Definieren Sie eine fensterbasierte Aggregation mithilfe der Fenstertransformation.