Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für die Zuordnung von Datenflüssen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
In der Fenstertransformation definieren Sie fensterbasierte Aggregationen von Spalten in Ihren Datenströmen. Im Ausdrucks-Generator können Sie verschiedene Typen von Aggregationen definieren, die auf Daten- oder Zeitfenstern (SQL OVER-Klausel) basieren, wie z.B. LEAD, LAG, NTILE, CUMEDIST und RANK. Ein neues Feld wird in Ihrer Ausgabe generiert, das diese Aggregationen enthält. Sie können auch optionale „Group by“-Felder einschließen.
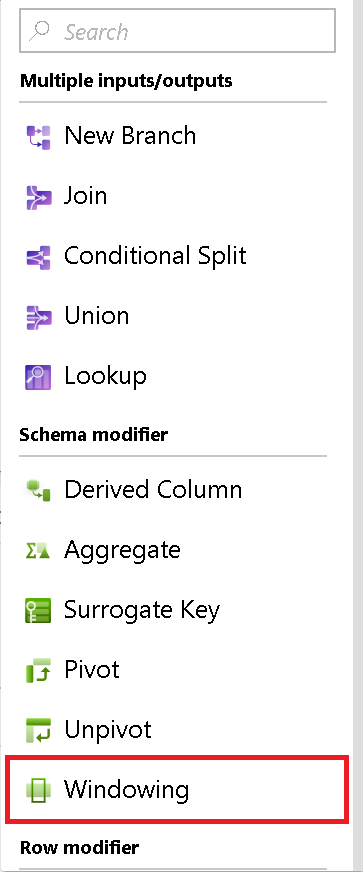
Über
Legen Sie die Partitionierung von Spaltendaten für Ihre Fenstertransformation fest. Die SQL-Entsprechung ist Partition By in der Over-Klausel in SQL. Wenn Sie eine Berechnung erstellen möchten, oder einen für die Partitionierung zu verwendenden Ausdruck, können Sie hierzu den Mauszeiger auf den Namen der Spalte setzen und Berechnete Spalte auswählen.
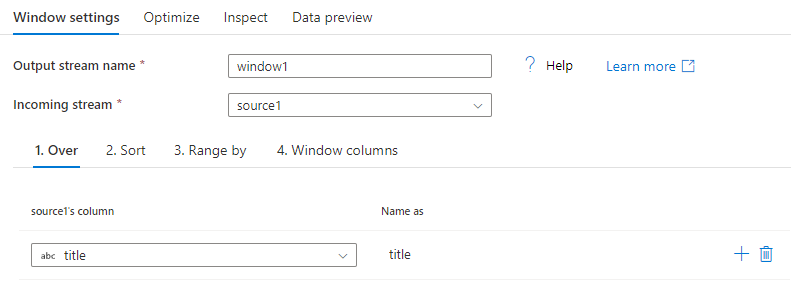
Sortieren
Ein anderer Teil der Over-Klausel ist das Festlegen von Order By. Diese Klausel legt die Sortierreihenfolge der Daten fest. Sie können auch einen Ausdruck für einen berechneten Wert in diesem Spaltenfeld für die Sortierung erstellen.
Sortieren nach
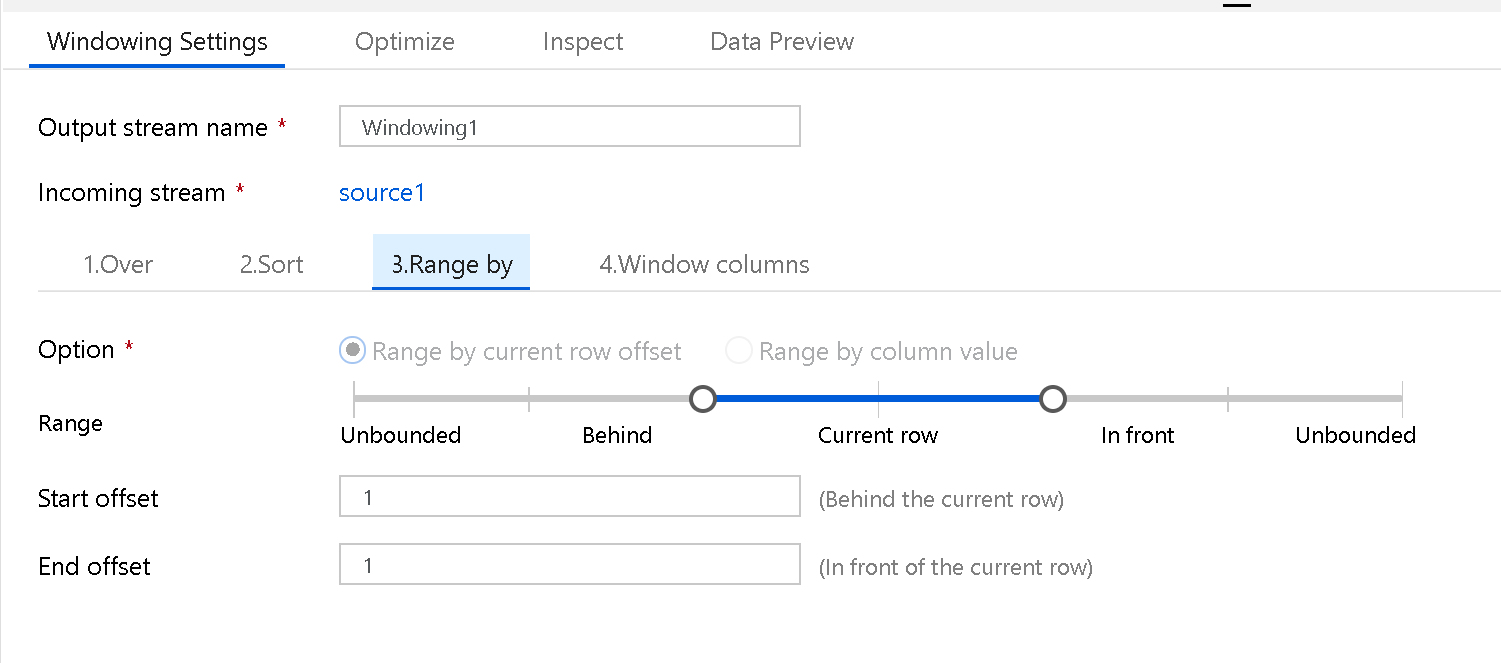
Legen Sie als Nächstes den Fensterrahmen als „Unbounded“ oder „Bounded“ fest. Um einen unbegrenzten Fensterrahmen festzulegen, positionieren Sie den Schieberegler an beiden Enden auf „Unbounded“. Wenn Sie eine Einstellung zwischen „Unbounded“ und „Current Row“ auswählen, müssen Sie den Offset-Start- und Endwert festlegen. Beide Werte sind positive ganze Zahlen. Sie können entweder relativen Zahlen oder Werte aus Ihren Daten verwenden.
Der Fensterschieberegler muss zwei Werte festlegen: die Werte vor der aktuellen Zeile und die Werte nach der aktuellen Zeile. Der Abstand zwischen Start- und Endwert entspricht den beiden Schaltern auf dem Schieberegler.
Fensterspalten
Verwenden Sie den Ausdrucks-Generator schließlich, um die Aggregationen zu definieren, die Sie mit Datenfenstern wie RANK, COUNT, MIN, MAX, DENSE RANK, LEAD, LAG usw. verwenden möchten.
Die vollständige Liste der Aggregations- und Analysefunktionen, die Sie in der Data-Flow-Ausdruckssprache über den Ausdrucksgenerator verwenden können, wird in Datentransformationsausdrücke im Zuordnungs-Datenfluss aufgeführt.
Zugehöriger Inhalt
Wenn Sie eine einfache Gruppen-Aggregation suchen, verwenden Sie die Aggregat-Transformation.