Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Führen Sie Ihre Azure Machine Learning Pipelines als Schritt in Ihren Azure Data Factory- und Synapse Analytics-Pipelines aus. Die Machine Learning Ausführungspipelineaktivität ermöglicht Batchvorhersageszenarien, z. B. das Identifizieren möglicher Kreditausfälle, die Bestimmung der Stimmung und die Analyse von Kundenverhaltensmustern.
Das folgende Video enthält eine sechsminütige Einführung und Demonstration dieses Features.
Erstellen Sie eine Aktivität zum Ausführen einer Machine Learning-Pipeline mit Benutzeroberfläche.
Führen Sie die folgenden Schritte aus, um eine Machine-Learning-Pipeline-Ausführungsaktivität in einer Pipeline zu verwenden:
Suchen Sie im Bereich für Pipelineaktivitäten nach maschinelles Lernen, und ziehen Sie eine Execute Pipeline-Aktivität für maschinelles Lernen in die Pipeline-Canvas.
Wählen Sie auf der Canvas die Execute Pipeline-Aktivität für maschinelles Lernen aus, sofern sie noch nicht ausgewählt ist, und wählen Sie anschließend die Registerkarte Einstellungen aus, um die Details zu bearbeiten.
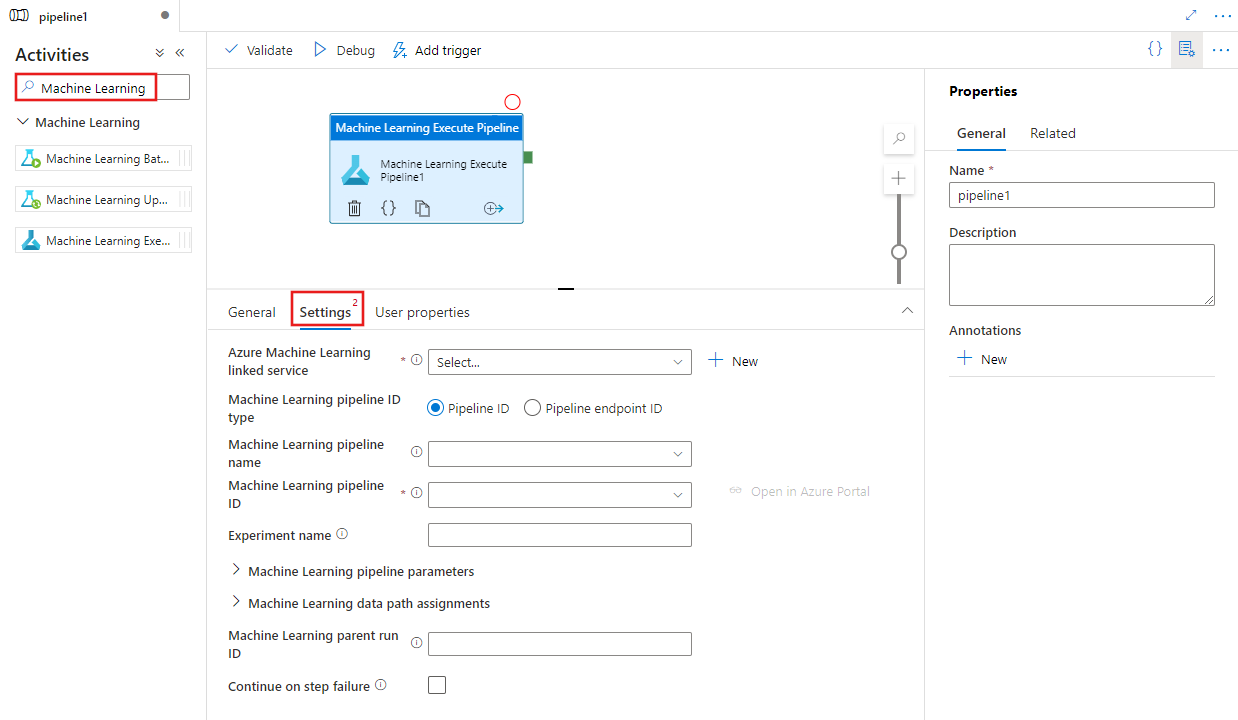
Wählen Sie einen vorhandenen oder erstellen Sie einen neuen Azure Machine Learning verknüpften Dienst, und geben Sie Details der Pipeline und des Experiments sowie alle Pipelineparameter oder Datenpfadzuordnungen an, die für die Pipeline erforderlich sind.
Syntax
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Typeigenschaften
| Eigenschaft | BESCHREIBUNG | Zulässige Werte | Erforderlich |
|---|---|---|---|
| Name | Name der Aktivität in der Pipeline | String | Ja |
| Typ | Die Art der Aktivität lautet „AzureMLExecutePipeline“. | String | Ja |
| verknüpfterDienstname | Verknüpfter Dienst mit Azure Machine Learning | Verweis auf den verknüpften Dienst | Ja |
| mlPipelineId | ID der veröffentlichten Azure Machine Learning Pipeline | Zeichenfolge (oder ein Ausdruck mit resultType der Zeichenfolge) | Ja |
| ExperimentName | Name des Ausführungsverlaufexperiments der Machine Learning-Pipelineausführung | Zeichenfolge (oder ein Ausdruck mit resultType der Zeichenfolge) | Nein |
| mlPipelineParameters | Schlüssel, Wertpaare, die an den veröffentlichten Azure Machine Learning Pipelineendpunkt übergeben werden sollen. Schlüssel müssen den Namen der pipelineparameter entsprechen, die in der veröffentlichten Machine Learning Pipeline definiert sind. | Objekt mit Schlüssel-Wert-Paaren (oder Ausdruck mit resultType-Objekt) | Nein |
| mlParentRunId | Die übergeordnete Azure Machine Learning Pipeline-Ausführungs-ID | Zeichenfolge (oder ein Ausdruck mit resultType der Zeichenfolge) | Nein |
| Datenpfadzuteilungen | Wörterbuch, das zum Ändern von Datenpfaden in Azure Machine Learning verwendet wird. Ermöglicht das Wechseln von Datenpfaden. | Objekt mit Schlüssel-Wert-Paaren | Nein |
| continueOnStepFailure | Gibt an, ob die Ausführung anderer Schritte in der Machine Learning Pipeline fortgesetzt werden soll, wenn ein Schritt fehlschlägt. | boolean | Nein |
Hinweis
Um die Dropdownelemente in Machine Learning Pipelinenamen und -ID aufzufüllen, muss der Benutzer über die Berechtigung zum Auflisten von ML-Pipelines verfügen. Die Benutzeroberfläche ruft AzureMLService-APIs mithilfe der Anmeldeinformationen des angemeldeten Benutzers direkt auf. Die Ermittlungszeit für die Dropdownelemente wäre bei Verwendung von privaten Endpunkten viel länger.
Zugehöriger Inhalt
In den folgenden Artikeln erfahren Sie, wie Daten auf andere Weisen transformiert werden: