Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird der BM25-Relevanzbewertungsalgorithmus erläutert, der zum Berechnen von Suchergebnissen für die Volltextsuche verwendet wird. BM25-Relevanz ist exklusiv für die Volltextsuche. Filterabfragen, AutoVervollständigung und vorgeschlagene Abfragen, Platzhaltersuche und Fuzzysuchabfragen werden nicht bewertet oder nach Relevanz sortiert.
Bewertungsalgorithmen, die in der Volltextsuche verwendet werden
Azure AI Search bietet die folgenden Bewertungsalgorithmen für die Volltextsuche:
| Algorithmus | Verwendung | Bereich |
|---|---|---|
BM25Similarity |
Festgelegter Algorithmus für alle Suchdienste, die nach Juli 2020 erstellt wurden. Sie können diesen Algorithmus konfigurieren, aber Sie können nicht zu einem älteren (klassischen) wechseln. | Unbegrenzt. |
ClassicSimilarity |
Standardeinstellung für ältere Suchdienste, die aus einer Zeit vor Juli 2020 stammen. Bei älteren Diensten können Sie sich für BM25 entscheiden und den BM25-Algorithmus pro Index auswählen. | 0 < 1,00 |
BM25 und Classic sind beide TF-IDF-ähnliche Abruffunktionen, bei denen die Begriffshäufigkeit (Term Frequency, TF) und die inverse Dokumenthäufigkeit (Inverse Document Frequency, IDF) als Variablen verwendet werden, um die Relevanzbewertungen für jedes Dokument/Abfrage-Paar zu berechnen, die dann zur Priorisierung der Ergebnisse verwendet werden. BM25 ist konzeptionell dem älteren klassischen Ähnlichkeitsalgorithmus ähnlich, basiert aber auf dem Abruf probabilistischer Informationen, der intuitivere Übereinstimmungen erzeugt, wie von der Benutzerforschung gemessen.
BM25 bietet erweiterte Anpassungsoptionen. Beispielsweise kann der Benutzer entscheiden, wie weit die Relevanzbewertung von der Häufigkeit übereinstimmender Begriffe abhängt.
Funktionsweise der BM25-Bewertung
Die Relevanzbewertung bezieht sich auf die Berechnung einer Suchbewertung (@search.score), die als Indikator für die Relevanz eines Elements im Kontext der aktuellen Abfrage dient. Der Bereich ist ungebunden. Je höher die Bewertung, desto relevanter das Element.
Eine Suchbewertung wird auf Basis der statistischen Eigenschaften der Zeichenfolgeeingabe und der Abfrage selbst berechnet. Azure AI Search findet Dokumente, die Suchbegriffe enthalten (einige oder alle, in Abhängigkeit von searchMode), wobei Dokumente bevorzugt werden, in denen der Suchbegriff häufig vorkommt. Die Suchbewertung fällt sogar noch höher aus, wenn der Begriff nur selten im Datenindex, jedoch innerhalb des Dokuments häufig vorkommt. Die Grundlage für diesen Ansatz zur Berechnung der Relevanz wird als TF-IDF (Term Frequency – Inverse Document Frequency, Vorkommenshäufigkeit – Inverse Dokumenthäufigkeit) bezeichnet.
Suchbewertungen können in einem Resultset wiederholt vorkommen. Wenn mehrere Treffer die gleiche Suchbewertung aufweisen, ist die Sortierung von Elementen mit gleicher Bewertung nicht definiert und somit auch nicht stabil. Wenn Sie die Abfrage noch mal ausführen, sehen Sie möglicherweise, dass sich die Position von Elementen ändert. Dies ist insbesondere dann der Fall, wenn Sie den kostenlosen Dienst oder einen abrechenbaren Dienst mit vielen Replikaten verwenden. Wenn zwei Elemente mit identischer Bewertung vorliegen, kann nicht garantiert werden, welches Element zuerst angezeigt wird.
Um eine Reihenfolge für Elemente mit der gleichen Bewertung festzulegen, können Sie eine $orderby-Klausel hinzufügen, um erst nach Bewertung und dann nach einem anderen sortierbaren Feld zu sortieren (z. B. $orderby=search.score() desc,Rating desc).
Für die Bewertung werden nur Felder verwendet, die als searchable-Index oder searchFields in der Abfrage markiert sind. Es werden nur Felder zurückgegeben, die in der Abfrage als retrievable markiert oder als select angegeben sind, zusammen mit ihrer Suchbewertung.
Hinweis
@search.score = 1 bedeutet, dass es sich um ein nicht bewertetes oder unsortiertes Resultset handelt. Die Bewertung wird für alle Ergebnisse gleich durchgeführt. Nicht bewertete Ergebnisse treten auf, wenn das Abfrageformular eine Fuzzysuche, Platzhalter- oder RegEx-Abfragen oder eine leere Suche ist (search=*, manchmal gekoppelt mit Filtern, wobei der Filter das primäre Mittel zum Zurückgeben einer Übereinstimmung ist).
Das folgende Videosegment bietet eine schnelle Übersicht über die in Azure AI Search verwendeten allgemein verfügbaren Ähnlichkeitsalgorithmen. Sie können sich das vollständige Video ansehen, um weitere Hintergrundinformationen zu erhalten.
Ergebnisse in Textergebnissen
Wenn Ergebnisse bewertet werden, enthält die @search.score-Eigenschaft den Wert, der zum Sortieren der Ergebnisse verwendet wird.
In der folgenden Tabelle werden die Bewertungseigenschaft, der Algorithmus und der Bereich identifiziert.
| Suche | Parameter | Bewertungsalgorithmus | Bereich |
|---|---|---|---|
| Volltextsuche | @search.score |
BM25-Algorithmus unter Verwendung der im Index angegebenen Parameter. | Unbegrenzt. |
Bewertungsvariation
Suchergebnisse vermitteln einen allgemeinen Eindruck von Relevanz, der die Stärke der Übereinstimmung im Vergleich zu anderen Dokumenten im selben Resultset widerspiegelt. Bewertungen sind jedoch von einer Abfrage zur nächsten nicht immer konsistent, sodass Sie möglicherweise geringfügige Abweichungen in der Reihenfolge der Suchdokumente feststellen werden. Hierfür kann es verschiedene Ursachen geben.
| Ursache | Beschreibung |
|---|---|
| Identische Bewertungen | Wenn mehrere Dokumente dieselbe Bewertung aufweisen, wird eine davon zuerst angezeigt. |
| Datenvolatilität | Der Indexinhalt variiert, wenn Sie Dokumente hinzufügen, ändern oder löschen. Begriffshäufigkeiten ändern sich, wenn im Laufe der Zeit Indexaktualisierungen verarbeitet werden, die sich auf die Suchbewertungen für übereinstimmende Dokumente auswirken. |
| Mehrere Replikate | Bei Diensten, die mehrere Replikate verwenden, werden Abfragen parallel für jedes Replikat ausgegeben. Die zum Berechnen einer Suchbewertung verwendete Indexstatistik wird pro Replikat berechnet, wobei die Ergebnisse zusammengeführt und in der Abfrageantwort sortiert werden. Replikate sind größtenteils Spiegelungen. Statistiken können sich jedoch aufgrund geringfügiger Zustandsabweichungen voneinander unterscheiden. So könnten beispielsweise in einem Replikat Dokumente gelöscht worden sein, die aus anderen Replikaten zusammengeführt wurden, was zur jeweiligen Statistik beiträgt. Unterschiede in Statistiken, die pro Replikat berechnet werden, fallen in kleineren Indizes deutlicher auf. Der folgende Abschnitt enthält weitere Informationen zu dieser Situation. |
Auswirkungen von Sharding auf Abfrageergebnisse
Ein Shard ist ein Indexblock. Azure KI-Suche unterteilt jeden Index in Shards, um das Hinzufügen von Partitionen zu beschleunigen (durch Verschieben der Shards in neue Sucheinheiten). In einem Suchdienst ist die Shardverwaltung ein Implementierungsdetail und nicht konfigurierbar. Aber das Wissen, dass das Sharding für einen Index ausgeführt wird, hilft dabei, die gelegentlichen Anomalien bei der Erstellung der Rangfolge und beim Verhalten von AutoVervollständigen zu verstehen:
Rangfolgenanomalien: Suchbewertungen werden zunächst auf der Shard-Ebene berechnet und dann zu einem einzelnen Resultset aggregiert. Abhängig von den Merkmalen des Shardinhalts können Übereinstimmungen aus einem Shard höher eingestuft werden als Übereinstimmungen in einem anderen Shard. Wenn Sie in den Suchergebnissen intuitive Rangfolgen bemerken, ist dies höchstwahrscheinlich auf die Auswirkungen des Shardings zurückzuführen – insbesondere wenn die Indizes klein sind. Sie können diese Anomalien in der Rangfolge vermeiden, indem Sie die Option zum globalen Berechnen von Bewertungen über den gesamten Index auswählen. Dies ist jedoch mit Leistungseinbußen verbunden.
Anomalien bei der AutoVervollständigung: Abfragen mit AutoVervollständigen, bei denen Vergleiche anhand der ersten paar Zeichen eines teilweise eingegebenen Begriffs vorgenommen werden, akzeptieren einen Fuzzyparameter, der kleine Abweichungen in der Rechtschreibung verzeiht. Bei AutoVervollständigen ist die Fuzzyübereinstimmung auf Begriffe innerhalb des aktuellen Shards beschränkt. Wenn z. B. ein Shard „Microsoft“ enthält und ein Teilbegriff von „micor“ eingegeben wird, findet die Suchmaschine in diesem Shard eine Übereinstimmung mit „Microsoft“, aber nicht in anderen Shards, die die restlichen Teile des Indexes enthalten.
Das folgende Diagramm zeigt die Beziehung zwischen Replikaten, Partitionen, Shards und Sucheinheiten. Es zeigt ein Beispiel dafür, wie ein einzelner Index in einem Dienst mit zwei Replikaten und zwei Partitionen über vier Sucheinheiten verteilt ist. Jede der vier Sucheinheiten speichert nur die Hälfte der Shards des Indexes. Die Sucheinheiten in der linken Spalte speichern die erste Hälfte der Shards, bestehend aus der ersten Partition, während die in der rechten Spalte die zweite Hälfte der Shards, bestehend aus der zweiten Partition, speichern. Da es zwei Replikate gibt, sind zwei Kopien der einzelnen Indexshards vorhanden. Die Sucheinheiten in der oberen Zeile speichern eine aus dem ersten Replikat bestehende Kopie, während die Sucheinheiten in der unteren Zeile eine aus dem zweiten Replikat bestehende weitere Kopie speichern.
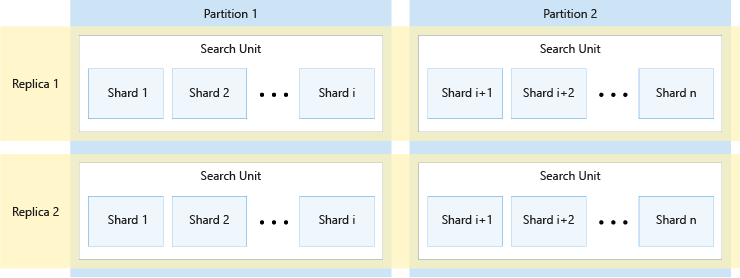
Das obige Diagramm ist nur ein Beispiel. Es sind viele Kombinationen von Partitionen und Replikaten möglich, bis zu einer Gesamtzahl von maximal 36 Sucheinheiten.
Hinweis
Die Anzahl der Replikate und Partitionen ist ein ganzzahliger Teiler von 12 (d.h. 1, 2, 3, 4, 6, 12). Bei Azure AI Search wird jeder Index vorab in zwölf Shards unterteilt, damit er gleichmäßig auf alle Partitionen verteilt werden kann. Wenn Ihr Dienst z.B. drei Partitionen aufweist und Sie einen Index erstellen, enthält jede Partition 4 Shards des Indexes. Azure AI Search erstellt Shards eines Index in Form von Implementierungsdetails, die sich bei zukünftigen Versionen ändern können. Auch wenn die Anzahl heute 12 beträgt, sollten Sie nicht davon ausgehen, das dies auch in Zukunft immer so ist.
Bewertungsstatistiken und persistente Sitzungen
Aus Gründen der Skalierbarkeit verteilt Azure AI Search jeden Index horizontal mithilfe eines Shardingprozesses. Dies bedeutet, dass Teile eines Index physisch voneinander getrennt sind.
Standardmäßig wird die Bewertung eines Dokuments basierend auf statistischen Eigenschaften der Daten innerhalb eines Shards berechnet. Diese Vorgehensweise stellt in der Regel bei einem großen Datenkorpus kein Problem dar und bietet eine bessere Leistung als die Berechnung der Bewertung auf Grundlage von Informationen in allen Shards. Allerdings kann die Verwendung dieser Leistungsoptimierung dazu führen, dass zwei sehr ähnliche (oder sogar identische) Dokumente unterschiedliche Relevanzbewertungen erhalten, wenn sie sich in verschiedenen Shards befinden.
Wenn Sie es vorziehen, die Bewertung basierend auf den statistischen Eigenschaften für alle Shards zu berechnen, können Sie dies tun, indem Sie scoringStatistics=global als Abfrageparameter hinzufügen (oder "scoringStatistics": "global" als Textparameter der Abfrageanforderung hinzufügen).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Durch die Verwendung von scoringStatistics wird sichergestellt, dass alle Shards in demselben Replikat die gleichen Ergebnisse liefern. Dennoch können sich unterschiedliche Replikate geringfügig voneinander unterscheiden, da sie immer mit den neuesten Änderungen am Index aktualisiert werden. In einigen Szenarien möchten Sie möglicherweise, dass die Benutzer während einer Abfragesitzung konsistentere Ergebnisse erhalten. In solchen Szenarien können Sie eine sessionId in den Abfragen bereitstellen. Die sessionId ist eine eindeutige Zeichenfolge, die Sie erstellen, um auf eine eindeutige Benutzersitzung zu verweisen.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Solange dieselbe sessionId verwendet wird, wird ein bestmöglicher Versuch unternommen, das gleiche Replikat als Ziel zu verwenden und die Konsistenz der Ergebnisse zu erhöhen, die den Benutzern angezeigt werden.
Hinweis
Wenn Sie wiederholt die gleichen sessionId-Werte verwenden, können der Lastenausgleich der Anforderungen über Replikate hinweg und die Leistung des Suchdiensts beeinträchtigt werden. Der als „sessionId“ verwendete Wert darf nicht mit einem Unterstrich (_) beginnen.
Relevanzoptimierung
In Azure KI-Suche können Sie für die Stichwortsuche und den Textteil einer Hybridabfrage BM25-Algorithmusparameter konfigurieren sowie die Suchrelevanz optimieren und die Suchergebnisse durch die folgenden Mechanismen verbessern:
| Vorgehensweise | Implementierung | Beschreibung |
|---|---|---|
| Konfiguration des BM25-Algorithmus | Suchindex | Konfigurieren Sie, wie sich Dokumentlänge und Begriffshäufigkeit auf die Relevanzbewertung auswirken. |
| Bewertungsprofile | Suchindex | Stellen Kriterien für eine höhere Gewichtung der Suchbewertung einer Übereinstimmung basierend auf Inhaltseigenschaften bereit. Mit dieser Logik können Sie Übereinstimmungen z. B. auf Grundlage des Umsatzpotentials, der Aktualität von Artikeln oder der Lagerzeit von Waren höher gewichten. Ein Bewertungsprofil ist Teil der Indexdefinition und besteht aus gewichteten Feldern, Funktionen und Parametern. Sie können einen vorhandenen Index mit Bewertungsprofiländerungen aktualisieren, ohne dass ein Index neu erstellt wird. |
| Semantische Rangfolge | Abfrageanforderung | Wendet maschinelles Leseverstehen auf Suchergebnisse an, um die semantischen relevanten Ergebnisse am Anfang zu fördern. |
| featuresMode-Parameter | Abfrageanforderung | Dieser Parameter wird hauptsächlich zum Entpacken eines Scores nach BM25 verwendet, kann aber für Code verwendet werden, der eine benutzerdefinierte Bewertungslösung bereitstellt. |
featuresMode-Parameter (Vorschau)
Anforderungen vom Typ Dokumente durchsuchen unterstützen einen featuresMode-Parameter, der weitere Details zum BM25-Relevanzscore auf Feldebene bereitstellt. Während @searchScore für das gesamte Dokument berechnet wird, um die Relevanz dieses Dokument im Kontext der Abfrage zu ermitteln, liefert „featuresMode“ Informationen zu einzelnen Feldern, wie in einer @search.features-Struktur ausgedrückt. Die Struktur enthält alle in der Abfrage verwendeten Felder (entweder spezifische Felder mithilfe von searchFields in einer Abfrage oder alle in einem Index als searchable gekennzeichneten Felder).
Für jedes Feld liefert @search.features die folgenden Werte:
- Anzahl der im Feld gefundenen eindeutigen Token
- Ähnlichkeitsbewertung oder eine Kennzahl für die Ähnlichkeit des Feldinhalts im Verhältnis zum Abfrageausdruck
- Ausdruckshäufigkeit oder Anzahl der Vorkommen des Ausdrucks im Feld
Für eine Abfrage, die auf die Felder „Beschreibung“ und „Titel“ abzielt, könnte eine Antwort, die @search.features beinhaltet, etwa so aussehen:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Sie können diese Datenpunkte in benutzerdefinierten Bewertungslösungen verbrauchen oder die Informationen zum Debuggen von Problemen bei der Suchrelevanz verwenden.
Der featuresMode-Parameter ist in den REST-APIs nicht dokumentiert, kann aber in einem Vorschau-REST-API-Aufruf zum Durchsuchen von Dokumenten nach Text (Schlüsselwort) gemäß BM25-Einstufung verwendet werden.
Anzahl der bewerteten Ergebnisse in einer Antwort auf Volltextabfragen
Wenn Sie die Paginierung nicht verwenden, gibt die Suchmaschine standardmäßig die höchsten 50 Übereinstimmungen für die Volltextsuche zurück. Sie können den top-Parameter verwenden, um eine kleinere oder größere Anzahl von Elementen (bis zu 1.000 in einer einzelnen Antwort) zurückzugeben. Sie können skip und next für das Einteilen von Ergebnissen in Seiten verwenden. Die Einteilung in Seiten bestimmt die Anzahl der Ergebnisse auf jeder logischen Seite und unterstützt die Inhaltsnavigation. Weitere Informationen finden Sie auf der Gestalten von Suchergebnissen.
Wenn Ihre Volltextabfrage Teil einer Hybridabfrage ist, können Sie maxTextRecallSize festlegen, um die Anzahl der Ergebnisse von der Textseite der Abfrage zu erhöhen oder zu verringern.
Die Volltextsuche unterliegt einem maximalen Grenzwert von 1.000 Übereinstimmungen (siehe API-Antwortgrenzwerte). Sobald 1.000 Übereinstimmungen gefunden wurden, sucht die Suchmaschine nicht mehr weiter.