Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In dieser Schnellstartanleitung verwenden Sie den Assistenten zum Importieren und Vektorisieren von Daten im Azure-Portal, um mit der multimodalen Suche zu beginnen. Der Assistent vereinfacht den Prozess des Extrahierens, Segmentierens, Vektorisierens und Ladens von Texten und Bildern in einen durchsuchbaren Index.
Im Gegensatz zur Schnellstartanleitung: Vektorsuche im Azure-Portal, die einfache Text-enthaltende Bilder verarbeitet, unterstützt diese Schnellstartanleitung erweiterte Bildverarbeitung für multimodale RAG-Szenarien.
Diese Schnellstartanleitung verwendet ein multimodales PDF aus dem Azure-Search-Beispieldaten-Repository . Sie können jedoch verschiedene Dateien verwenden und diese Schnellstartanleitung trotzdem abschließen.
Voraussetzungen
Ein Azure-Konto mit einem aktiven Abonnement. Kostenlos ein Konto erstellen.
Ein Azure AI Search-Dienst. Wir empfehlen den Tarif „Basic“ oder höher.
Ein Azure Storage-Konto Verwenden Sie Azure Blob Storage oder Azure Data Lake Storage Gen2 (Speicherkonto mit einem hierarchischen Namespace) auf einem Standardleistungskonto (mit allgemeinem Zweck v2). Zugriffsebenen können heiß, kühl oder kalt sein.
Vertrautheit mit dem Assistenten. Siehe Importieren von Daten-Assistenten im Azure-Portal.
Unterstützte Extraktionsmethoden
Für die Inhaltsextraktion können Sie entweder die Standardextraktion über Azure AI Search oder eine erweiterte Extraktion über Azure AI Document Intelligence auswählen. In der folgenden Tabelle werden beide Extraktionsmethoden beschrieben.
| Methode | Beschreibung |
|---|---|
| Standardextraktion | Extrahiert nur Speicherortmetadaten aus PDF-Bildern. Erfordert keine weitere Azure AI-Ressource. |
| Erweiterte Extraktion | Extrahiert Positionsmetadaten aus Text und Bildern für mehrere Dokumenttypen. Erfordert eine Azure AI-Dienste-Multi-Service-Ressource1 in einer unterstützten Region. |
1 Für Abrechnungszwecke müssen Sie Ihre Azure AI Multi-Service-Ressource an das Skillset in Ihrem Azure AI Search-Dienst anfügen. Sofern Sie nicht eine schlüssellose Verbindung zum Erstellen des Skillsets verwenden, müssen sich beide Ressourcen in derselben Region befinden.
Unterstützte Einbettungsmethoden
Bei der Einbettung von Inhalten können Sie entweder die Bildverbalisierung (gefolgt von der Textvektorisierung) oder die multimodalen Einbettungen auswählen. Bereitstellungsanweisungen für die Modelle werden in einem späteren Abschnitt bereitgestellt. In der folgenden Tabelle werden beide Einbettungsmethoden beschrieben.
| Methode | Beschreibung | Unterstützte Modelle |
|---|---|---|
| Bildverbalisierung | Verwendet ein Sprachmodell (LLM), um natürliche Sprachbeschreibungen von Bildern zu generieren, und verwendet dann ein Einbettungsmodell, um Klartext und verbalisierte Bilder zu vektorisieren. Erfordert ein Azure OpenAI-Ressourcenprojekt1, 2 oder Azure AI Foundry. Für die Textvektorisierung können Sie auch eine Azure AI Services Multi-Service-Ressource3 in einer unterstützten Region verwenden. |
LLMs GPT-4o GPT-4o-mini phi-4 4 Einbettungsmodelle: text-embedding-ada-002 text-embedding-3-small text-embedding-3-large |
| Multimodale Einbettungen | Verwendet ein Einbettungsmodell zum direkten Vektorisieren von Text und Bildern. Erfordert ein Azure AI Foundry-Projekt oder azure AI Services Multi-Service-Ressource3 in einer unterstützten Region. |
Cohere-embed-v3-english Cohere-embed-v3-multilingual |
1 Der Endpunkt Ihrer Azure OpenAI-Ressource muss über eine benutzerdefinierte Unterdomäne verfügen, wie https://my-unique-name.openai.azure.com. Wenn Sie Ihre Ressource im Azure-Portal erstellt haben, wurde diese Unterdomäne während der Ressourceneinrichtung automatisch generiert.
2 Azure OpenAI-Ressourcen (mit Zugriff auf Einbettungsmodelle), die im Azure AI Foundry-Portal erstellt wurden, werden nicht unterstützt. Sie müssen eine Azure OpenAI-Ressource im Azure-Portal erstellen.
3 Zu Abrechnungszwecken müssen Sie Ihre Azure AI Multi-Service-Ressource an das Skillset in Ihrem Azure AI Search-Dienst anfügen. Sofern Sie keine schlüssellose Verbindung (Vorschau) zum Erstellen des Skillsets verwenden, müssen sich beide Ressourcen in derselben Region befinden.
4phi-4 ist nur für Azure AI Foundry-Projekte verfügbar.
Anforderungen an öffentliche Endpunkte
Für alle vorherigen Ressourcen muss der öffentliche Zugriff aktiviert sein, damit die Azure-Portal-Knoten darauf zugreifen können. Andernfalls tritt im Assistenten ein Fehler auf. Sobald der Assistent ausgeführt wird, können Sie Firewalls und private Endpunkte für die Integrationskomponenten für die Sicherheit aktivieren. Weitere Informationen finden Sie unter Sichere Verbindungen in den Import-Assistenten.
Wenn private Endpunkte bereits vorhanden sind und Sie sie nicht deaktivieren können, besteht die Alternative darin, den entsprechenden End-to-End-Fluss von einem Skript oder Programm auf einem virtuellen Computer auszuführen. Die VM muss sich im selben virtuellen Netzwerk wie der private Endpunkt befinden. Hier ist ein Python-Codebeispiel für die integrierte Vektorisierung. Im gleichen GitHub-Repository gibt es Beispiele in anderen Programmiersprachen.
Überprüfen des Speicherplatzes
Wenn Sie mit dem kostenlosen Tarif beginnen, sind Sie auf drei Indizes, drei Datenquellen, drei Skillsets und drei Indexer beschränkt. Stellen Sie sicher, dass Sie über ausreichend Platz für zusätzliche Elemente verfügen, bevor Sie beginnen. In diesem Schnellstart wird jeweils eines dieser Objekte erstellt.
Konfigurieren des Zugriffs
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Berechtigungen für den Zugriff auf Inhalte und Vorgänge verfügen. Wir empfehlen die Microsoft Entra ID-Authentifizierung und rollenbasierten Zugriff für die Autorisierung. Sie müssen ein Besitzer oder Benutzerzugriffsadministrator sein, um Rollen zuzuweisen. Wenn Rollen nicht machbar sind, können Sie stattdessen die schlüsselbasierte Authentifizierung verwenden.
Konfigurieren Sie die erforderlichen Rollen und bedingten Rollen , die in diesem Abschnitt identifiziert wurden.
Erforderliche Rollen
Azure AI Search und Azure Storage sind für alle multimodalen Suchszenarien erforderlich.
Azure AI Search stellt die multimodale Pipeline bereit. Konfigurieren Sie den Zugriff für sich selbst und Ihren Suchdienst, um Daten zu lesen, die Pipeline auszuführen und mit anderen Azure-Ressourcen zu interagieren.
Auf Ihrem Azure AI Search-Dienst:
Konfigurieren sie eine vom System zugewiesene verwaltete Identität.
Weisen Sie sich selbst die folgenden Rollen zu:
Mitwirkender von Suchdienst
Mitwirkender an Suchindexdaten
Suchindexdatenleser
Bedingte Rollen
Die folgenden Registerkarten umfassen alle assistentenkompatiblen Ressourcen für die multimodale Suche. Wählen Sie nur die Registerkarten aus, die für die ausgewählte Extraktionsmethode und die Einbettungsmethode gelten.
Azure OpenAI bietet LLMs für die Bildverbalisierung und Einbettung von Modellen für Text- und Bildvektorisierung. Ihr Suchdienst erfordert Zugriff, um die GenAI Prompt Skill und Azure OpenAI Embedding Skills aufzurufen.
Auf Ihrer Azure OpenAI-Ressource:
- Weisen Sie Ihrer Suchdienstidentität die Rolle Cognitive Services OpenAI-Benutzer zu.
Vorbereiten der Beispieldaten
In dieser Schnellstartanleitung wird eine multimodale PDF-Beispieldatei verwendet, Sie können aber auch eigene Dateien verwenden. Wenn Sie einen kostenlosen Suchdienst verwenden, verwenden Sie weniger als 20 Dateien, um innerhalb des kostenlosen Kontingents für die Anreicherungsverarbeitung zu bleiben.
So bereiten Sie die Beispieldaten für diese Schnellstartanleitung vor:
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihr Azure Storage-Konto aus.
Wählen Sie im linken Bereich "Datenspeichercontainer>" aus.
Erstellen Sie einen Container, und laden Sie dann die Beispiel-PDF in den Container hoch.
Erstellen Sie einen anderen Container zum Speichern von Bildern, die aus der PDF-Datei extrahiert wurden.
Bereitstellen von Modellen
Der Assistent bietet mehrere Optionen zum Einbetten von Inhalten. Die Bildverbalisierung erfordert eine LLM zum Beschreiben von Bildern und ein Einbettungsmodell zum Vektorisieren von Text- und Bildinhalten, während direkte multimodale Einbettungen nur ein Einbettungsmodell erfordern. Diese Modelle sind über Azure OpenAI und Azure AI Foundry verfügbar.
Hinweis
Wenn Sie Azure AI Vision verwenden, überspringen Sie diesen Schritt. Die multimodalen Einbettungen sind in Ihre Azure AI Multi-Service-Ressource integriert und erfordern keine Modellbereitstellung.
So stellen Sie die Modelle für diese Schnellstartanleitung bereit:
Melden Sie sich beim Azure AI Foundry-Portal an.
Wählen Sie Ihre Azure OpenAI-Ressource oder Ihr Azure AI Foundry-Projekt aus.
Wählen Sie im linken Bereich den Modellkatalog aus.
Stellen Sie die modelle bereit, die für die ausgewählte Einbettungsmethode erforderlich sind.
Starten des Assistenten
So starten Sie den Assistenten für die multimodale Suche:
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihren Azure AI Search-Dienst aus.
Wählen Sie auf der Seite Übersicht die Option Importieren und Vektorisieren von Daten aus.

Wählen Sie Ihre Datenquelle aus: Azure Blob Storage oder Azure Data Lake Storage Gen2.

Wählen Sie Multimodale RAG aus.



Herstellen einer Verbindung mit Ihren Daten
Azure AI Search erfordert eine Verbindung mit einer Datenquelle für die Erfassung und Indizierung von Inhalten. In diesem Fall ist die Datenquelle Ihr Azure Storage-Konto.
So stellen Sie eine Verbindung mit Ihren Daten her:
Geben Sie auf der Seite "Mit Ihren Daten verbinden" Ihr Azure-Abonnement an.
Wählen Sie das Speicherkonto und den Container aus, in das Sie die Beispieldaten hochgeladen haben.
Aktivieren Sie das Kontrollkästchen "Authentifizieren mit verwalteter Identität ". Lassen Sie den Identitätstyp als vom System zugewiesen.
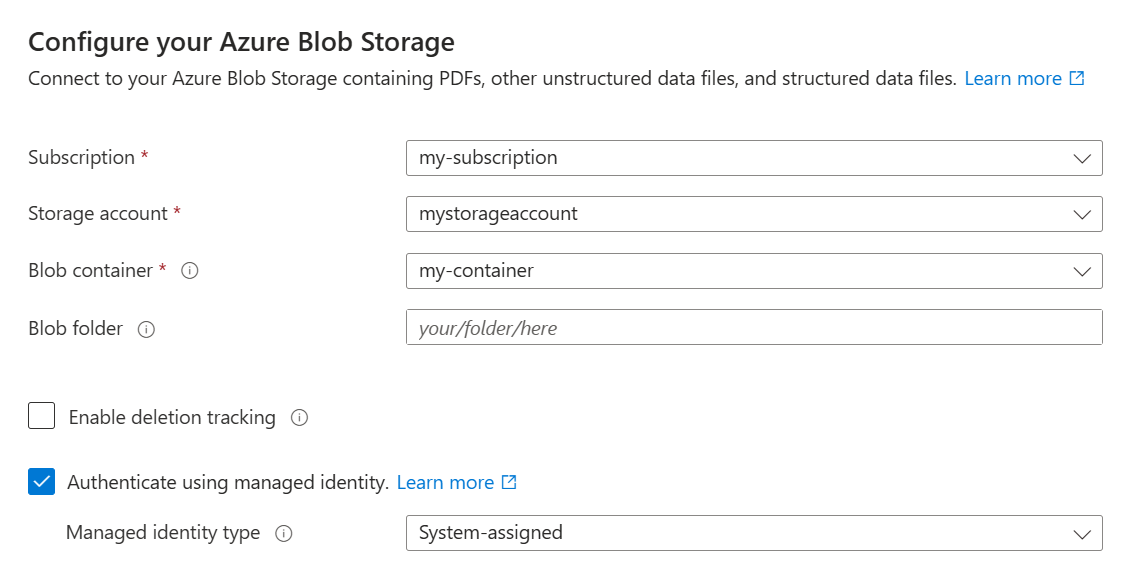
Wählen Sie Weiter aus.

Inhalte extrahieren
Je nach ausgewählter Extraktionsmethode bietet der Assistent Konfigurationsoptionen für das Knacken und Blöcken von Dokumenten.
Die Standardmethode ruft die Dokumentextraktionsfähigkeit auf, um Textinhalte zu extrahieren und normalisierte Bilder aus Ihren Dokumenten zu generieren. Die Fähigkeit "Textteilung " wird dann aufgerufen, um den extrahierten Textinhalt auf Seiten aufzuteilen.
So verwenden Sie die Dokumentextraktionsfähigkeit:
Wählen Sie auf der Seite "Inhaltsextraktion" die Option "Standard" aus.
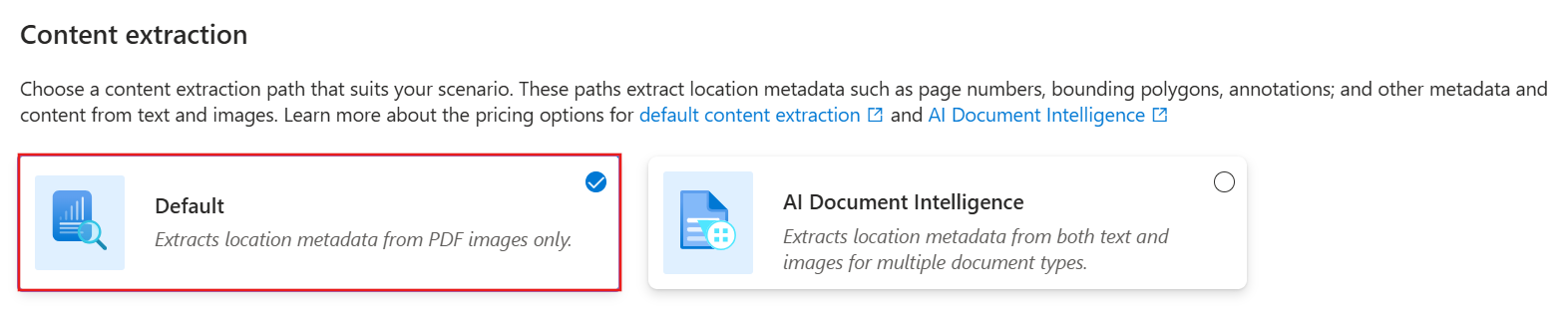
Wählen Sie Weiter aus.



Einbetten von Inhalten
Während dieses Schritts verwendet der Assistent die ausgewählte Einbettungsmethode , um Vektordarstellungen von Text und Bildern zu generieren.
Der Assistent ruft einen Skill auf, um beschreibenden Text für Bilder (Bildverbalisierung) zu erstellen, und einen anderen Skill, um Vektoreinbettungen für Text und Bilder zu erstellen.
Für die Bildverbalisierung verwendet die GenAI Prompt-Fähigkeit Ihr bereitgestelltes LLM, um jedes extrahierte Bild zu analysieren und eine Beschreibung in natürlicher Sprache zu erzeugen.
Bei Einbettungen verwendet der Azure OpenAI Embedding Skill, der AML Skill oder der Azure AI Vision multimodale Einbettungs-Skill Ihr bereitgestelltes Einbettungsmodell, um Textblöcke und verbalisierte Beschreibungen in hochdimensionale Vektoren zu konvertieren. Diese Vektoren ermöglichen Ähnlichkeit und Hybridabruf.
So verwenden Sie die Fähigkeiten für die Bildverbalisierung:
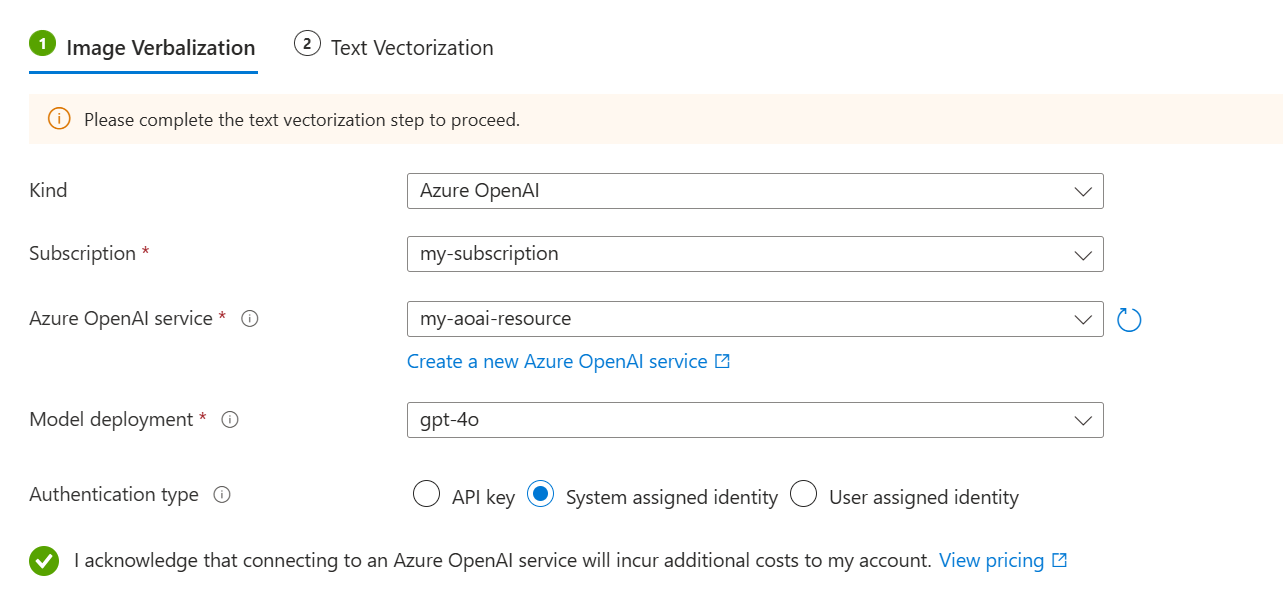
Wählen Sie auf der Seite "Inhalt einbetten " die Option "Bildverbalisierung" aus.

Auf der Registerkarte Bildverbalisierung:
Wählen Sie für den Typ Ihren LLM-Anbieter aus: Azure OpenAI oder AI Foundry Hub Katalogmodelle.
Geben Sie Ihr Azure-Abonnement, Ihre Ressource und die LLM-Bereitstellung an.
Wählen Sie für den Authentifizierungstyp die vom System zugewiesene Identität aus.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
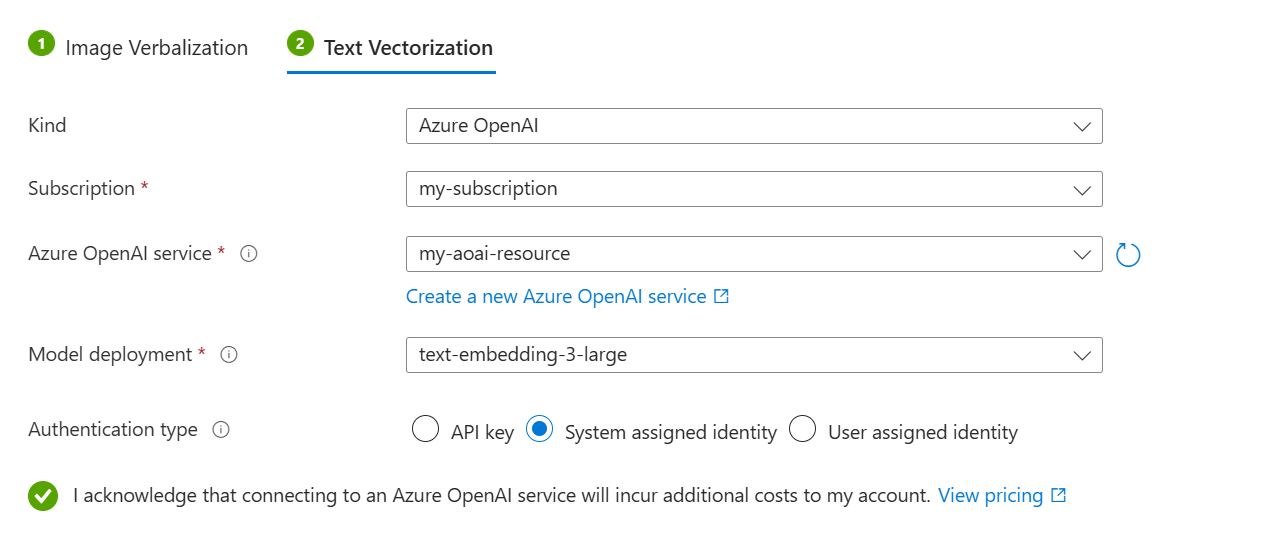
Auf der Registerkarte Textvektorisierung:
Wählen Sie für die Art Ihren Modellanbieter aus: Azure OpenAI, AI Foundry Hub-Katalogmodelle oder AI Vision-Vektorisierung.
Geben Sie Ihr Azure-Abonnement, Ihre Ressource und die Bereitstellung des Einbettungsmodells an.
Wählen Sie für den Authentifizierungstyp die vom System zugewiesene Identität aus.
Aktivieren Sie das Kontrollkästchen, das die Auswirkungen der Nutzung dieser Ressourcen auf die Abrechnung bestätigt.
Wählen Sie Weiter aus.





Speichern der extrahierten Bilder
Der nächste Schritt besteht darin, Bilder, die aus Ihren Dokumenten extrahiert wurden, an Azure Storage zu senden. In Azure AI Search wird dieser sekundäre Speicher als Wissensspeicher bezeichnet.
So speichern Sie die extrahierten Bilder:
Geben Sie auf der Seite "Bildausgabe " Ihr Azure-Abonnement an.
Wählen Sie das Speicherkonto und den blob-Container aus, den Sie erstellt haben, um die Bilder zu speichern.
Aktivieren Sie das Kontrollkästchen "Authentifizieren mit verwalteter Identität ". Lassen Sie den Identitätstyp als vom System zugewiesen.
Wählen Sie Weiter aus.

Neue Felder zuordnen
Auf der Seite "Erweiterte Einstellungen " können Sie dem Indexschema optional Felder hinzufügen. Standardmäßig generiert der Assistent die in der folgenden Tabelle beschriebenen Felder.
| Feld | Gilt für: | Beschreibung | Attribute |
|---|---|---|---|
| content_id | Text- und Bildvektoren | Zeichenfolgenfeld. Dokumentschlüssel für den Index. | Abrufbar, sortierbar und durchsuchbar. |
| Dokumententitel | Text- und Bildvektoren | Zeichenfolgenfeld. Lesbarer Dokumenttitel. | Abrufbar und durchsuchbar. |
| Textdokument-ID | Textvektoren | Zeichenfolgenfeld. Gibt das übergeordnete Dokument an, aus dem der Textabschnitt stammt. | Abrufbar und filterbar. |
| Bilddokument-ID | Bildvektoren | Zeichenfolgenfeld. Gibt das übergeordnete Dokument an, aus dem das Bild stammt. | Abrufbar und filterbar. |
| content_text | Textvektoren | Zeichenfolgenfeld. Lesbare Version des Textabschnitts. | Abrufbar und durchsuchbar. |
| content_embedding | Text- und Bildvektoren | Collection(Edm.Single). Vektordarstellung von Text und Bildern. | Abrufbar und durchsuchbar. |
| Inhaltspfad | Text- und Bildvektoren | Zeichenfolgenfeld. Pfad zum Inhalt im Speichercontainer. | Abrufbar und durchsuchbar. |
| Standortmetadaten | Bildvektoren | Edm.ComplexType. Enthält Metadaten zum Speicherort des Bilds in den Dokumenten. | Variiert je nach Feld. |
Sie können die generierten Felder oder deren Attribute nicht ändern, aber Sie können Felder hinzufügen, wenn ihre Datenquelle sie bereitstellt. Beispielsweise stellt Azure Blob Storage eine Sammlung von Metadatenfeldern bereit.
So fügen Sie dem Indexschema Felder hinzu:
Wählen Sie unter "Indexfelder"die Option "Vorschau" und "Bearbeiten" aus.
Wählen Sie Feld hinzufügen aus.
Wählen Sie ein Quellfeld aus den verfügbaren Feldern aus, geben Sie einen Feldnamen für den Index ein, und akzeptieren (oder überschreiben) Sie den Standarddatentyp.
Wenn Sie das Schema in seiner ursprünglichen Version wiederherstellen möchten, wählen Sie "Zurücksetzen" aus.
Planen der Indizierung
Für Datenquellen, in denen die zugrunde liegenden Daten veränderlich sind, können Sie die Indizierung planen , um Änderungen in bestimmten Intervallen oder bestimmten Datums- und Uhrzeitangaben zu erfassen.
Planen der Indizierung:
Geben Sie auf der Seite "Erweiterte Einstellungen " unter " Indizierung planen" einen Ausführungszeitplan für den Indexer an. Wir empfehlen Once für diesen Quickstart.

Wählen Sie Weiter aus.

Beenden Sie den Assistenten.
Der letzte Schritt besteht darin, Ihre Konfiguration zu überprüfen und die erforderlichen Objekte für die multimodale Suche zu erstellen. Kehren Sie bei Bedarf zu den vorherigen Seiten des Assistenten zurück, um Ihre Konfiguration anzupassen.
Beenden des Assistenten:
Geben Sie auf der Seite " Überprüfen und Erstellen " ein Präfix für die Objekte an, die der Assistent erstellt. Ein allgemeines Präfix hilft Ihnen, den Überblick zu behalten.

Klicken Sie auf Erstellen.

Wenn der Assistent die Konfiguration abschließt, erstellt er die folgenden Objekte:
Ein Indexer, der die Indizierungspipeline steuert
Eine Datenquellenverbindung mit Azure Blob Storage.
Ein Index mit Textfeldern, Vektorfeldern, Vektorisierern, Vektorprofilen und Vektoralgorithmen. Während des Assistentenworkflows können Sie den Standardindex nicht ändern. Indizes entsprechen der 2024-05-01-Preview-REST-API, sodass Sie Previewfunktionen verwenden können.
Ein Skillset mit den folgenden Fähigkeiten:
Die Dokumentextraktionsfertigkeit oder dokumentlayout-Fähigkeit extrahiert Text und Bilder aus Quelldokumenten. Die Textaufteilungsfunktion begleitet die Dokumentextraktionsfunktion für die Datenaufteilung, während die Dokumentlayout-Funktion integriertes Chunking aufweist.
Die GenAI Prompt-Fähigkeit verbalisiert Bilder in natürlicher Sprache. Wenn Sie direkte multimodale Einbettungen verwenden, fehlt diese Fähigkeit.
Die Azure OpenAI Embedding-Fähigkeit, AML-Fähigkeit oder Azure AI Vision multimodale Einbettungskompetenzen werden einmal für die Textvektorisierung und einmal für die Bildvektorisierung aufgerufen.
Die Shaper-Fähigkeit erweitert die Ausgabe mit Metadaten und erstellt neue Bilder mit Kontextinformationen.
Tipp
Vom Assistenten erstellte Objekte verfügen über konfigurierbare JSON-Definitionen. Um diese Definitionen anzuzeigen oder zu ändern, wählen Sie die Suchverwaltung im linken Bereich aus, in dem Sie Ihre Indizes, Indexer, Datenquellen und Skillsets anzeigen können.
Überprüfen der Ergebnisse
Diese Schnellstartanleitung erstellt einen multimodalen Index, der die Hybridsuche sowohl für Text als auch für Bilder unterstützt. Sofern Sie keine direkten multimodalen Einbettungen verwenden, akzeptiert der Index keine Bilder als Abfrageeingaben, was die AML-Fähigkeit oder die Azure AI Vision Multimodal-Einbettungs-Fähigkeit mit einem entsprechenden Vektorizer erfordert. Weitere Informationen finden Sie unter Konfigurieren eines Vektorizers in einem Suchindex.
Die Hybridsuche kombiniert Volltextabfragen und Vektorabfragen. Wenn Sie eine Hybridabfrage ausstellen, berechnet die Suchmaschine die semantische Ähnlichkeit zwischen Ihrer Abfrage und den indizierten Vektoren und bewertet die Ergebnisse entsprechend. Für den in dieser Schnellstartanleitung erstellten Index werden Ergebnisse angezeigt, deren Inhalt aus dem Feld content_text eng mit Ihrer Abfrage übereinstimmt.
So fragen Sie Ihren multimodalen Index ab:
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihren Azure AI Search-Dienst aus.
Wählen Sie im linken Bereich "Suchverwaltungsindizes>" aus.
Wählen Sie Ihren Index aus.
Wählen Sie "Abfrageoptionen" und dann " Vektorwerte in Suchergebnissen ausblenden" aus. Dieser Schritt macht die Ergebnisse besser lesbar.
Geben Sie Text ein, nach dem Sie suchen möchten. Unser Beispiel verwendet
energy.Um die Abfrage auszuführen, wählen Sie "Suchen" aus.

Die JSON-Ergebnisse sollten Text- und Bildinhalte, die mit
energyin Ihrem Index zusammenhängen, enthalten. Wenn Sie den semantischen Rangierer aktiviert haben, bietet das@search.answersArray präzise, vertrauenswürdige semantische Antworten , die Ihnen helfen, relevante Übereinstimmungen schnell zu identifizieren."@search.answers": [ { "key": "a71518188062_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_normalized_images_7", "text": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like energy distribution, resource allocation, and environmental monitoring. **Accelerate the development of sustainability solution...", "highlights": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like<em> energy distribution, </em>resource<em> allocation, </em>and environmental monitoring. **Accelerate the development of sustainability solution...", "score": 0.9950000047683716 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_5", "text": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim 10.5 gigawatts (GW) of renewable energy to the grid.910.5 GWof new renewable energy capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "highlights": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim <em> 10.5 gigawatts (GW) of renewable energy </em>to the<em> grid.910.5 </em>GWof new<em> renewable energy </em>capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "score": 0.9890000224113464 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_50", "text": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community Solar MicrogridsDeveloping energy transition programsWe are co-innovating with communities to develop energy transition programs that align their goals with broader s.", "highlights": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community<em> Solar MicrogridsDeveloping energy transition programsWe </em>are co-innovating with communities to develop<em> energy transition programs </em>that align their goals with broader s.", "score": 0.9869999885559082 } ]


Bereinigen von Ressourcen
Diese Schnellstartanleitung verwendet abgerechnete Azure-Ressourcen. Wenn Sie die Ressourcen nicht mehr benötigen, löschen Sie sie aus Ihrem Abonnement, um Gebühren zu vermeiden.
Nächste Schritte
In dieser Schnellstartanleitung haben Sie den Assistenten zum Importieren und Vektorisieren von Daten eingeführt, der alle erforderlichen Objekte für die multimodale Suche erstellt. Informationen zu den einzelnen Schritten finden Sie in den folgenden Lernprogrammen: