Indizieren von Daten aus OneLake-Dateien und -Verknüpfungen
In diesem Artikel erfahren Sie, wie Sie einen OneLake-Dateiindexer zum Extrahieren durchsuchbarer Daten und Metadatendaten aus einem Lakehouse in OneLake konfigurieren.
Verwenden Sie diesen Indexer für die folgenden Aufgaben:
- Datenindizierung und inkrementelle Indizierung: Der Indexer kann Dateien und zugehörige Metadaten aus Datenpfaden in einem Lakehouse indizieren. Es erkennt neue und aktualisierte Dateien und Metadaten durch die integrierte Änderungserkennung. Sie können eine planmäßige oder bedarfsorientierte Datenaktualisierung konfigurieren.
- Löscherkennung: Der Indexer kann Löschungen in den meisten Dateien und Verknüpfungen durch benutzerdefinierte Metadaten erkennen. Dies erfordert das Hinzufügen von Metadaten zu Dateien, um zu kennzeichnen, dass sie „vorläufig gelöscht“ wurden, wodurch die Entfernung aus dem Suchindex ermöglicht wird. Derzeit ist es nicht möglich, Löschungen in Google Cloud Storage- oder Amazon S3-Verknüpfungsdateien zu erkennen, da benutzerdefinierte Metadaten für diese Datenquellen nicht unterstützt werden.
- Angewandte KI durch Skillsets: Skillsets werden vom OneLake-Dateiindexer vollständig unterstützt. Dazu gehören wichtige Features wie die integrierte Vektorisierung, die Datenabschnitte und Einbettungsschritte hinzufügt.
- Parsing-Modi: Der Indexer unterstützt JSON-Parsing-Modi, wenn Sie JSON-Arrays oder -Zeilen in einzelne Suchdokumente parsen möchten.
- Kompatibilität mit anderen Features: Der OneLake-Indexer ist auf eine nahtlose Funktionsweise mit anderen Indexerfeatures wie Debugsitzungen, den Indexercache für inkrementelle Anreicherungenund Wissensspeicher ausgelegt.
Verwenden Sie die REST-API „2024-05-01-preview“, die Betaversion eines Azure SDK-Pakets oder Importieren und Vektorisieren von Daten im Azure-Portal, um aus OneLake zu indizieren.
In diesem Artikel werden die REST-APIs verwendet, um die einzelnen Schritte zu veranschaulichen.
Voraussetzungen
Ein Fabric-Arbeitsbereich. Folgen Sie diesem Tutorial, um einen Fabric-Arbeitsbereich zu erstellen.
Ein Lakehouse in einem Fabric-Arbeitsbereich. Folgen Sie diesem Tutorial, um ein Lakehouse zu erstellen.
Textdaten. Wenn Sie Binärdaten haben, können Sie eine Bildanalyse mit KI-Anreicherung verwenden, um Text zu extrahieren oder Beschreibungen von Bildern zu generieren. Dateiinhalte dürfen die Indexer-Limits für Ihre Suchdienstebene nicht überschreiten.
Inhalt im Speicherort Dateien Ihres Lakehouse. So fügen Sie Daten hinzu:
- Direktes Hochladen in ein Lakehouse
- Verwenden von Datenpipelines aus Microsoft Fabric
- Hinzufügen von Verknüpfungen aus externen Datenquellen wie Amazon S3 oder Google Cloud Storage
Ein KI-Suchdienst, der für eine systemseitig verwaltete Identität oder eine benutzerseitig zugewiesene verwaltete Identität konfiguriert ist. Der KI-Suchdienst muss sich innerhalb desselben Mandanten wie der Microsoft Fabric-Arbeitsbereich befinden.
Eine Rollenzuweisung des Typs „Mitwirkender“ in dem Microsoft Fabric-Arbeitsbereich, in dem sich das Lakehouse befindet. Die Schritte werden im Abschnitt Erteilen von Berechtigungen in diesem Artikel beschrieben.
Einen REST-Client, wenn Sie REST-Aufrufe formulieren möchten, die den in diesem Artikel gezeigten ähnlich sind.
Unterstützte Dokumentformate
Der OneLake-Dateiindexer kann Text aus den folgenden Dokumentformaten extrahieren:
- CSV (siehe Indizierung von CSV-Blobs)
- EML
- EPUB
- GZ
- HTML
- JSON (Siehe Indizierung von JSON-Blobs)
- KML (XML für geografische Darstellungen)
- Microsoft Office-Formate: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook-E-Mails), XML (WORD XML 2003 und 2006)
- Öffnen von Dokumentformaten: ODT, ODS, ODP
- Textdateien (Siehe auch Indizierung von Nur-Text)
- RTF
- XML
- ZIP
Unterstützte Verknüpfungen
Die folgenden OneLake-Verknüpfungen werden vom OneLake-Dateiindexer unterstützt:
OneLake-Verknüpfung (eine Verknüpfung zu einer anderen OneLake-Instanz)
Einschränkungen in dieser Vorschau
Parquet-Dateitypen (einschließlich Delta-Parquet-Dateien) werden derzeit nicht unterstützt.
Das Löschen von Dateien wird für Amazon S3- und Google Cloud Storage-Verknüpfungen nicht unterstützt.
Dieser Indexer unterstützt keine Inhalte zu Tabellenspeicherorten in OneLake-Arbeitsbereichen.
Dieser Indexer unterstützt keine SQL-Abfragen. Die in der Konfiguration der Datenquelle verwendete Abfrage dient ausschließlich dazu, optional den Ordner oder die Verknüpfung hinzuzufügen, auf den oder die zugegriffen werden soll.
Das Erfassen von Dateien aus einem My Workspace-Arbeitsbereich in OneLake wird nicht unterstützt, da dies ein persönliches Benutzerrepository ist.
Aufbereiten von Daten für die Indizierung
Überprüfen Sie vor dem Einrichten der Indizierung die Quelldaten, um zu ermitteln, ob Änderungen im Voraus vorgenommen werden sollten. Ein Indexer kann immer nur Inhalte aus einem Container gleichzeitig indizieren. Standardmäßig werden alle Dateien im Container verarbeitet. Sie haben mehrere Optionen für eine stärker selektive Verarbeitung:
Platzieren Sie Dateien in einen virtuellen Ordner. Die Datenquellendefinition eines Indexers enthält einen „query“-Parameter, der ein Lakehouse-Unterordner oder eine Lakehouse-Verknüpfung sein kann. Wenn dieser Wert angegeben ist, werden nur die Dateien im Unterordner oder der Verknüpfung innerhalb des Lakehouse indiziert.
Ein- oder Ausschließen von Dateien nach Dateityp. Mithilfe der Liste der unterstützten Dokumentformate können Sie bestimmen, welche Dateien ausgeschlossen werden sollen. Beispielsweise können Sie Bild- oder Audiodateien ausschließen, die keinen durchsuchbaren Text bereitstellen. Diese Funktion wird über Konfigurationseinstellungen im Indexer gesteuert.
Ein- oder Ausschließen beliebiger Dateien. Wenn Sie eine bestimmte Datei aus irgendeinem Grund überspringen möchten, können Sie Dateien in Ihrem OneLake-Lakehouse Metadateneigenschaften und -werte hinzufügen. Wenn der Indexer auf diese Eigenschaft stößt, überspringt er die Datei oder dessen Inhalt im Indizierungslauf.
Das Ein- und Ausschließen von Dateien ist im Schritt Konfiguration des Indexers behandelt. Wenn Sie keine Kriterien einrichten, meldet der Indexer eine nicht berechtigte Datei als Fehler und fährt fort. Wenn genügend Fehler auftreten, wird die Verarbeitung möglicherweise beendet. Sie können die Fehlertoleranz in den Konfigurationseinstellungen des Indexers angeben.
Ein Indexer erstellt in der Regel ein Suchdokument pro Datei, wobei der Textinhalt und die Metadaten als durchsuchbare Felder in einem Index erfasst werden. Wenn Dateien ganze Dateien sind, können Sie sie möglicherweise in mehrere Suchdokumente parsen. Beispielsweise können Sie Zeilen in einer CSV-Datei analysieren, um ein Suchdokument pro Zeile zu erstellen. Wenn Sie ein einzelnes Dokument in kleinere Passagen aufteilen müssen, um Daten zu vektorisieren, sollten Sie gegebenenfalls die integrierte Vektorisierung verwenden.
Indizieren von Dateimetadaten
Dateimetadaten können auch indiziert werden. Dies ist hilfreich, wenn Sie der Meinung sind, dass eine der Standard- oder benutzerdefinierten Metadateneigenschaften für Filter und Abfragen nützlich ist.
Vom Benutzer angegebene Metadateneigenschaften werden wortgetreu extrahiert. Um die Werte zu erhalten, müssen Sie im Suchindex ein Feld des Typs Edm.String definieren, das den gleichen Namen hat wie der Metadatenschlüssel des Blobs. Wenn ein Blob beispielsweise über den Metadatenschlüssel Priority mit dem Wert High verfügt, müssen Sie ein Feld mit dem Namen Priority in Ihrem Suchindex definieren, das dann mit dem Wert High aufgefüllt wird.
Standard-Dateimetadateneigenschaften können in ähnlich benannte und typisierte Felder extrahiert werden, wie unten aufgeführt. Der OneLake-Dateiindexer erstellt automatisch interne Feldzuordnungen für diese Metadateneigenschaften und konvertiert den ursprünglichen Bindestrichnamen ("metadata-storage-name") in einen entsprechenden Unterstrichnamen ("metadata_storage_name").
Sie müssen die Felder mit den Unterstrichnamen weiterhin zur Indexdefinition hinzufügen, aber Sie können Indexerfeldzuordnungen weglassen, da der Indexer die Zuordnung automatisch erstellt.
metadata_storage_name (
Edm.String): der Dateiname. Für eine Datei mit dem Namen „/mydatalake/my-folder/subfolder/resume.pdf“ lautet der Wert dieses Felds beispielsweiseresume.pdf.metadata_storage_path (
Edm.String): der vollständigen URI des Blobs, einschließlich Speicherkonto. Beispiel:https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String): Inhaltstyp, der mit dem Code angegeben wird, den Sie zum Hochladen des Blobs verwendet haben. Beispiel:application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset): Zeitstempel der letzten Änderung des Blobs. In Azure KI Search wird dieser Zeitstempel zum Identifizieren geänderter Blobs verwendet, um die erneute Indizierung aller Elemente nach der ersten Indizierung zu vermeiden.metadata_storage_size (
Edm.Int64): Blobgröße in Bytes.metadata_storage_content_md5 (
Edm.String): MD5-Hash des Blobinhalts, sofern vorhanden.
Schließlich können auch alle Metadateneigenschaften, die für das Dokumentformat der zu indizierenden Dateien spezifisch sind, im Indexschema dargestellt werden. Weitere Informationen zu inhaltsspezifischen Metadaten finden Sie unter Eigenschaften von Inhaltsmetadaten.
Wichtig ist der Hinweis, dass Sie nicht für alle der oben genannten Eigenschaften Felder in Ihrem Suchindex definieren müssen. Erfassen Sie lediglich die Eigenschaften, die Sie für Ihre Anwendung benötigen.
Erteilen von Berechtigungen
Der OneLake-Indexer verwendet die Tokenauthentifizierung und den rollenbasierten Zugriff für Verbindungen mit OneLake. Berechtigungen werden in OneLake zugewiesen. Es gibt keine Berechtigungsanforderungen für die physischen Datenspeicher hinter den Verknüpfungen. Wenn Sie z. B. Daten aus AWS indizieren, müssen Sie in AWS keine Suchdienstberechtigungen erteilen.
Die minimale Rollenzuweisung für Ihre Suchdienstidentität ist „Mitwirkender“.
Konfigurieren Sie eine system- oder benutzerseitig verwaltete Identität für Ihren KI-Suchdienst.
Der folgende Screenshot zeigt eine systemseitig verwaltete Identität für einen Suchdienst namens „onelake-demo“.

Dieser Screenshot zeigt eine benutzerseitig verwaltete Identität für denselben Suchdienst.
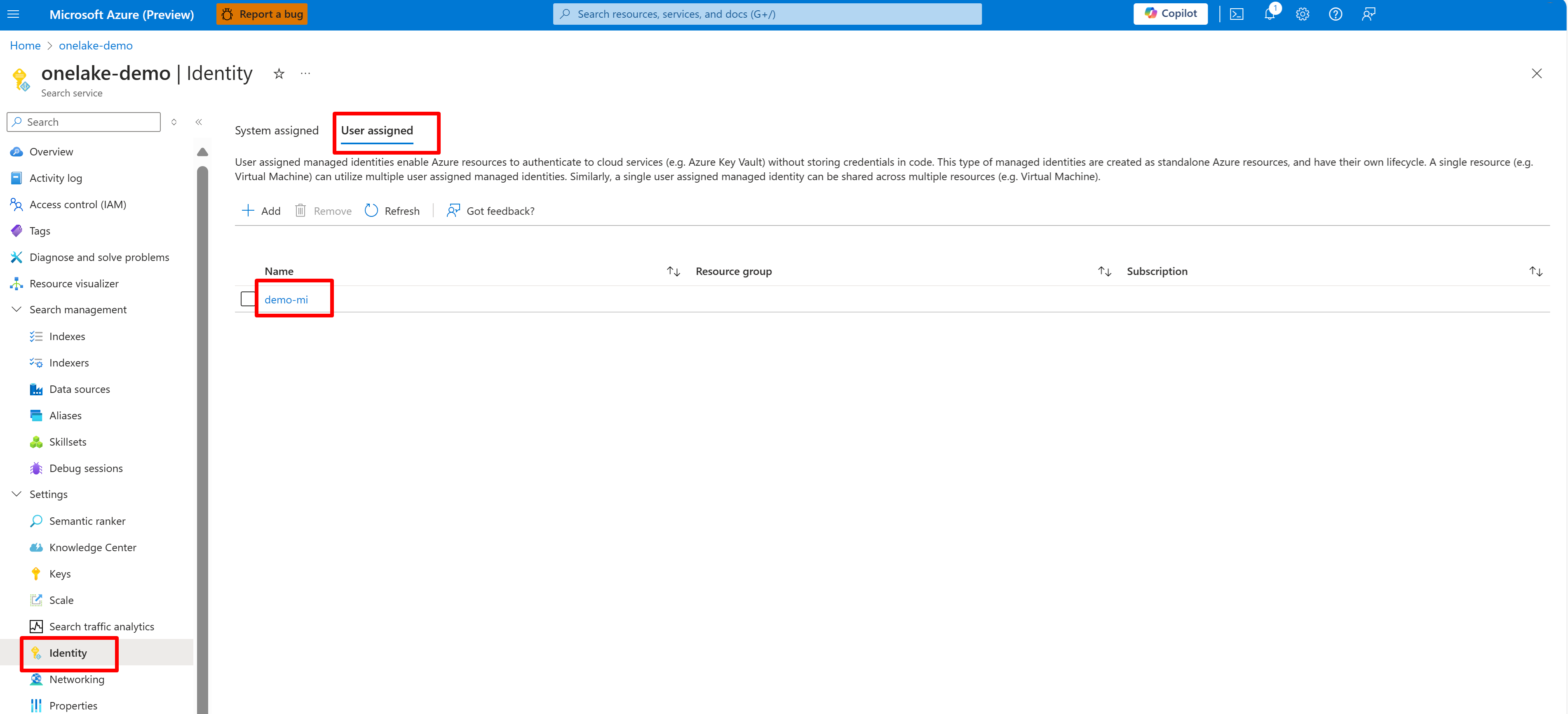
Erteilen Sie dem Suchdienst Zugriffsberechtigung für den Fabric-Arbeitsbereich. Der Suchdienst stellt die Verbindung im Namen des Indexers her.
Wenn Sie eine systemseitig zugewiesene verwaltete Identität verwenden, suchen Sie nach dem Namen des KI-Suchdiensts. Wenn Sie eine benutzerseitig zugewiesene verwaltete Identität verwenden, suchen Sie nach dem Namen der Identitätsressource.
Der folgende Screenshot zeigt eine Zuweisung der Rolle „Mitwirkender“ mithilfe einer systemseitig verwalteten Identität.

Dieser Screenshot zeigt eine Zuweisung der Rolle „Mitwirkender“ mithilfe einer systemseitig verwalteten Identität.





Definieren der Datenquelle
Eine Datenquelle wird als unabhängige Ressource definiert, sodass sie von mehreren Indexern verwendet werden kann. Sie müssen die REST-API „2024-05-01-preview“ verwenden, um die Datenquelle zu erstellen.
Verwenden Sie Erstellen oder Aktualisieren einer Datenquellen-REST-API, um die Definition festzulegen. Dies sind die wichtigsten Schritte der Definition.
Legen Sie
"type"auf"onelake"fest (erforderlich).Rufen Sie die GUID des Microsoft Fabric-Arbeitsbereichs und die Lakehouse-GUID ab:
Wechseln Sie zum Lakehouse, aus dessen URL Sie Daten importieren möchten. Die Seite sollte diesem Beispiel ähneln: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Kopieren Sie die folgenden Werte, die in der Datenquellendefinition verwendet werden:
Kopieren Sie die Arbeitsbereichs-GUID, die in diesem Artikel
{FabricWorkspaceGuid}genannt wird und in der URL direkt hinter "groups" steht. In diesem Beispiel ist dies 00000000-0000-0000-0000-000000000000.
Kopieren Sie die Lakehouse-GUID, die in diesem Artikel
{lakehouseGuid}genannt wird und in der URL direkt hinter "lakehouses" steht. In diesem Beispiel ist dies 11111111-1111-1111-1111-111111111111.
Legen Sie
"credentials"auf die GUID des Microsoft Fabric-Arbeitsbereichs fest, indem Sie{FabricWorkspaceGuid}durch den Wert ersetzen, den Sie im vorherigen Schritt kopiert haben. Dies ist die OneLake-Instanz, auf die mit der verwalteten Identität zugegriffen werden soll, die Sie später in diesem Leitfaden einrichten."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Legen Sie
"container.name"auf die Lakehouse-GUID fest, indem Sie{lakehouseGuid}durch den Wert ersetzen, den Sie im vorherigen Schritt kopiert haben. Verwenden Sie"query", um optional einen Lakehouse-Unterordner oder eine Verknüpfung anzugeben."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Legen Sie die Authentifizierungsmethode mithilfe der benutzerseitig zugewiesenen verwalteten Identität fest, oder fahren Sie mit dem nächsten Schritt für die systemseitig verwaltete Identität fort.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Der Wert
userAssignedIdentitykann in der Ressource{userAssignedManagedIdentity}unter „Eigenschaften“ gefunden werden und heißtId.
Beispiel:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Verwenden Sie stattdessen optional eine systemseitig zugewiesene verwaltete Identität. Die Identität ("identity") wird aus der Definition entfernt, wenn die systemseitig zugewiesene verwaltete Identität verwendet wird.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Beispiel:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Erkennen von Löschungen mithilfe benutzerdefinierter Metadaten
Eine Datenquellendefinition des OneLake-Dateiindexers kann eine Richtlinie für vorläufiges Löschen enthalten, falls der Indexer ein Suchdokument löschen soll, wenn das Quelldokument für den Löschvorgang gekennzeichnet ist.
Zum Aktivieren der automatischen Dateilöschung, verwenden Sie benutzerdefinierte Metadaten, um anzuzeigen, ob ein Suchdokument aus dem Index entfernt werden soll.
Dieser Workflow erfordert drei separate Aktionen:
- Vorläufiges Löschen der Datei in OneLake
- Indexer löscht das Suchdokument im Index
- Endgültiges Löschen der in OneLake
Das vorläufige Löschen teilt dem Indexer mit, was zu tun ist (Löschen des Suchdokuments). Wenn Sie die physische Datei zuerst in OneLake löschen, kann der Indexer sie nicht mehr lesen, und das entsprechende Suchdokument im Index ist verwaist.
Es müssen sowohl in OneLake als auch in Azure KI-Suche einige Schritte befolgt werden, aber es gibt keine weiteren Featureabhängigkeiten.
Fügen Sie der Datei in der Lakehouse-Datei ein benutzerdefiniertes Metadaten-Schlüssel-Wert-Paar hinzu, um anzugeben, dass die Datei zum Löschen gekennzeichnet ist. Sie können die Eigenschaft z. B. „IsDeleted“ nennen und auf FALSE festlegen. Wenn Sie die Datei löschen möchten, ändern Sie sie in TRUE.

Bearbeiten Sie in Azure AI Search die Datenquellendefinition, um eine Eigenschaft „dataDeletionDetectionPolicy“ einzufügen. Bei der folgenden Richtlinie wird eine Datei beispielsweise als gelöscht angesehen, wenn ihre Metadateneigenschaft "IsDeleted" den Wert TRUE aufweist:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Nachdem der Indexer das Dokument ausgeführt und aus dem Suchindex gelöscht hat, können Sie die physische Datei im Data Lake löschen.
Wichtige Hinweise sind u. a.:
Die Planung einer Indexerausführung hilft, diesen Prozess zu automatisieren. Es wird empfohlen, Zeitpläne für alle inkrementellen Indizierungsszenarios zu erstellen.
Wenn die Löscherkennungsrichtlinie nicht für die erste Indexerausführung festgelegt wurde, müssen Sie den Indexer zurücksetzen, damit die aktualisierte Konfiguration gelesen wird.
Beachten Sie, dass die Löschungserkennung, wie bereits erwähnt, aufgrund der Abhängigkeit von benutzerdefinierten Metadaten für Amazon S3- und Google Cloud Storage-Verknüpfungen nicht unterstützt wird.
Hinzufügen von Suchfeldern zu einem Index
Fügen Sie in einem Suchindex Felder hinzu, um den Inhalt und die Metadaten Ihrer Data Lake-Dateien in OneLake zu akzeptieren.
Erstellen oder aktualisieren Sie einen Index, um Suchfelder zu definieren, in denen Dateiinhalte und Metadaten gespeichert werden:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Erstellen Sie ein Dokumentschlüsselfeld („key“: true). Metadateneigenschaften sind die besten Kandidaten für Dateiinhalte.
metadata_storage_path(Standard) vollständiger Pfad zum Objekt oder zur Datei. Das Schlüsselfeld ("ID" in diesem Beispiel) wird mit Werten aus „metadata_storage_path“ aufgefüllt, da es sich um die Standardeinstellung handelt.metadata_storage_namekann nur verwendet werden, wenn Namen eindeutig sind. Wenn Sie dieses Feld als Schlüssel benötigen, verschieben Sie"key": truein diese Felddefinition.Eine benutzerdefinierte Metadateneigenschaft, die Sie Ihren Dateien hinzufügen. Für diese Option ist es erforderlich, dass diese Metadateneigenschaft beim Dateiupload allen Blobs hinzugefügt wird. Da der Schlüssel eine erforderliche Eigenschaft ist, schlägt die Indizierung aller Dateien fehl, denen ein Wert fehlt. Wenn Sie eine benutzerdefinierte Metadateneigenschaft als Schlüssel verwenden, vermeiden Sie es, Änderungen an dieser Eigenschaft vorzunehmen. Indexer fügen doppelte Dokumente für dieselbe Datei hinzu, wenn sich die Schlüsseleigenschaft ändert.
Metadateneigenschaften enthalten häufig Zeichen wie
/und-, die für Dokumentschlüssel ungültig sind. Da der Indexer über die Eigenschaft „base64EncodeKeys“ verfügt (standardmäßig „true“), wird die Metadateneigenschaft automatisch codiert, ohne dass eine Konfiguration oder Feldzuordnung erforderlich ist.Fügen Sie ein Feld "content" hinzu, um extrahierten Text aus jeder Datei über die Eigenschaft "content" der Datei zu speichern. Sie sind nicht verpflichtet, diesen Namen zu verwenden, aber Sie können so die Vorteile impliziter Zuordnungen von Feldern nutzen.
Fügen Sie Felder für Standardmetadateneigenschaften hinzu. Der Indexer kann Eigenschaften von benutzerdefinierten Metadaten, Standardmetadaten und inhaltsspezifischen Metadaten lesen.
Konfigurieren und Ausführen des OneLake-Dateiindexers
Nach der Erstellung von Index und Datenquelle können Sie den Indexer erstellen. Die Indexerkonfiguration gibt die Eingaben, Parameter und Eigenschaften an, die das Laufzeitverhalten steuern. Sie können auch angeben, welche Teile eines Blobs indiziert werden sollen.
Erstellen oder aktualisieren Sie den Indexer, indem Sie ihm einen Namen geben und einen Verweis auf die Datenquelle und den Zielindex hinzufügen:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Legen Sie „batchSize“ fest, wenn der Standardwert (10 Dokumente) die verfügbaren Ressourcen entweder nicht auslastet oder überlastet. Die Standardbatchgrößen sind datenquellenspezifisch. Bei der Dateiindizierung wird unter Berücksichtigung der größeren durchschnittlichen Dokumentgröße eine Batchgröße von 10 Dokumenten festgelegt.
Steuern Sie unter "configuration", welche Dateien basierend auf dem Dateityp indiziert werden, oder geben Sie dies nicht an, um alle Dateien abzurufen.
Geben Sie für
"indexedFileNameExtensions"eine durch Trennzeichen getrennte Liste der Dateierweiterungen an (mit vorangestelltem Punkt). Machen Sie dasselbe für"excludedFileNameExtensions", um anzugeben, welche Erweiterungen übersprungen werden sollen. Wenn die gleiche Erweiterung in beiden Listen vorhanden ist, wird sie von der Indizierung ausgeschlossen.Legen Sie unter "configuration" "dataToExtract" fest, um zu steuern, welche Teile der Dateien indiziert werden:
"contentAndMetadata" ist der Standardwert. Er gibt an, dass alle Metadaten und Textinhalte, die aus der Datei extrahiert wurden, indiziert werden
"storageMetadata" gibt an, dass nur die Standarddateieigenschaften und benutzerspezifischen Metadaten indiziert werden. Obwohl die Eigenschaften für Azure-Blobs dokumentiert sind, sind die Dateieigenschaften für OneLkae identisch, mit Ausnahme der SAS-bezogenen Metadaten.
"allMetadata" gibt an, dass Standarddateieigenschaften und alle Metadaten für gefundene Inhaltstypen aus dem Dateiinhalt extrahiert und indiziert werden.
Legen Sie unter "configuration" "parsingMode" fest, wenn Dateien mehreren Suchdokumenten zugeordnet werden sollen, oder wenn sie aus Nur-Text, JSON-Dokumenten oder CSV-Dateien bestehen.
Geben Sie Feldzuordnungen an, wenn es Unterschiede beim Feldnamen oder -typ gibt, oder wenn Sie mehrere Versionen eines Quellfelds im Suchindex benötigen.
Bei der Dateiindizierung können Sie häufig Feldzuordnungen weglassen, da der Indexer über integrierte Unterstützung für die Zuordnung der „content“- und Metadateneigenschaften zu ähnlich benannten und typisierten Feldern in einem Index verfügt. Bei Metadateneigenschaften ersetzt der Indexer im Suchindex automatisch Bindestriche
-durch Unterstriche.
Weitere Informationen zu anderen Eigenschaften finden Sie unter Erstellen eines Indexers. Die vollständige Liste der Parameterbeschreibungen finden Sie in der REST-API unter Erstellen eines Indexers (REST). Die Parameter sind für OneLake identisch.
Ein Indexer wird standardmäßig automatisch nach der Erstellung ausgeführt. Diese Verhalten kann geändert werden, indem Sie "disabled" auf TRUE festlegen. Um die Ausführung des Indexers zu steuern, führen Sie einen Indexer nach Bedarf aus, oder legen Sie für ihn einen Zeitplan fest.
Überprüfen des Indexerstatus
Weitere Informationen finden Sie im Artikel zum Überwachen des Indexerstatus und Ausführungsverlaufs.
Behandeln von Fehlern
Zu häufigen Fehlern bei der Indizierung gehören nicht unterstützte Inhaltstypen, fehlende Inhalte oder übergroße Dateien. Der OneLake-Dateiindexer wird standardmäßig beendet, sobald eine Datei mit einem nicht unterstützten Inhaltstyp gefunden wird. Möglicherweise möchten Sie jedoch, dass die Indizierung auch dann fortgesetzt wird, wenn Fehler auftreten, und dann später einzelne Dokumente debuggen.
Vorübergehende Fehler sind für Lösungen mit mehreren Plattformen und Produkten üblich. Wenn Sie den Indexer jedoch nach Zeitplan ausführen (z. B. alle 5 Minuten), sollte der Indexer bei der folgenden Ausführung trotzdem wieder problemlos ausgeführt werden können.
Es gibt fünf Indexereigenschaften, die die Reaktion des Indexers beim Auftreten von Fehlern steuern.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parameter | Gültige Werte | Beschreibung |
|---|---|---|
| „maxFailedItems“ | -1, NULL oder 0, positive ganze Zahl | Setzen Sie die Indizierung fort, wenn an einem beliebigen Punkt der Verarbeitung Fehler auftreten, entweder bei der Analyse von Blobs oder beim Hinzufügen von Dokumenten zu einem Index. Legen Sie diese Eigenschaften auf die Anzahl zulässiger Fehler fest. Der Wert -1 ermöglicht die Verarbeitung unabhängig davon, wie viele Fehler auftreten. Andernfalls ist der Wert eine positive ganze Zahl. |
| „maxFailedItemsPerBatch“ | -1, NULL oder 0, positive ganze Zahl | Wie oben, wird aber für die Batchindizierung verwendet. |
| „failOnUnsupportedContentType“ | true oder false | Wenn der Indexer den Inhaltstyp nicht bestimmen kann, geben Sie an, ob der Auftrag fortgesetzt wird oder als nicht gelungen gilt. |
| „failOnUnprocessableDocument“ | true oder false | Wenn der Indexer ein Dokument eines ansonsten unterstützten Inhaltstyps nicht verarbeiten kann, geben Sie an, ob der Auftrag fortgesetzt wird oder als nicht gelungen gilt. |
| „indexStorageMetadataOnlyForOversizedDocuments“ | true oder false | Zu große Blobs werden standardmäßig als Fehler behandelt. Wenn Sie diesen Parameter auf TRUE festlegen, versucht der Indexer, seine Metadaten zu indizieren, auch wenn der Inhalt nicht indiziert werden kann. Grenzwerte für die Blobgröße finden Sie unter Dienstgrenzwerte. |
Nächste Schritte
Überprüfen Sie, wie der -Assistent zum Importieren und Vektorisieren von Daten funktioniert, und probieren Sie ihn für diesen Indexer aus. Sie können die integrierte Vektorisierung zum Aufteilen und Erstellen von Einbettungen für die Vektor- oder Hybridsuche mithilfe eines Standardschemas zu erstellen.