Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit Hilfe von Power Fx, den Open-Source-Low-Code-Formeln, können Sie Ihrer Power App leistungsfähigere und flexiblere Integrationen von KI-Modellen hinzufügen. Formeln der KI-Modell-Vorhersage können in beliebige Steuerelemente in der Canvas-App integriert werden. Beispielsweise können Sie die Sprache des Texts in einem Texteingabesteuerelement erkennen und die Ergebnisse an ein Beschriftungssteuerelement ausgeben, wie im Abschnitt Ein Modell mit Steuerelementen verwenden unten zu sehen ist.
Anforderungen
Um Power Fx in AI Builder-Modellen zu verwenden, benötigen Sie:
Zugriff auf eine Microsoft Power Platform Umgebung mit einer Datenbank.
AI Builder-Lizenz (Testversion oder kostenpflichtig). Weitere Informationen finden Sie unter AI Builder-Lizenzierung.
Ein Modell in Canvas Apps auswählen
Um ein KI-Modell mit Power Fx zu konsumieren, müssen Sie eine Canvas-App erstellen, ein Steuerelement auswählen und den Steuerelementeigenschaften Ausdrücke zuweisen.
Notiz
Eine Liste der AI Builder-Modelle, die Sie verwenden können, finden Sie unter KI-Modelle und Geschäftsszenarien. Mit der Funktion Eigenes Modell verwenden können Sie auch Modelle verwenden, die in Microsoft Azure Machine Learning erstellt wurden.
App erstellen Mehr Informationen: Erstellen Sie eine Canvas App ohne Vorlage.
Wählen Sie Daten>Daten hinzufügen>KI-Modelle.
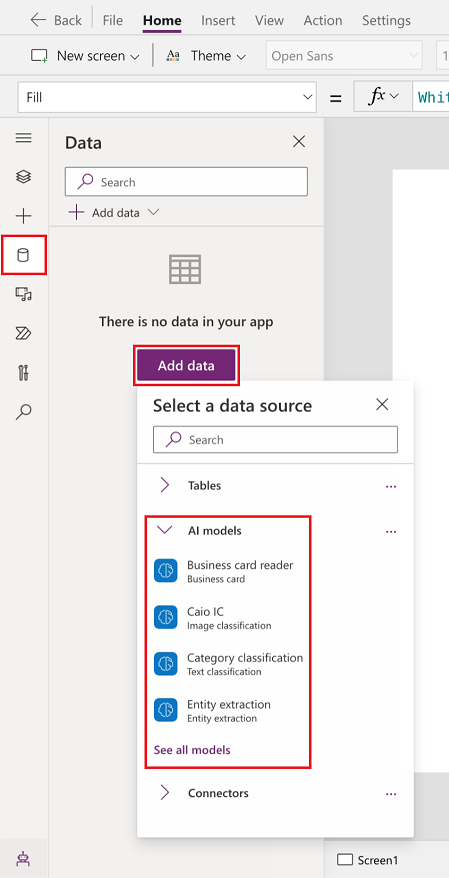
Wählen Sie ein oder mehrere Modelle aus, die Sie hinzufügen möchten.
Wenn Sie Ihr Modell nicht in der Liste sehen, haben Sie möglicherweise keine Berechtigung, es in Power Apps zu verwenden. Wenden Sie sich an Ihren Administrator, um dieses Problem zu lösen.
Ein Modell mit Steuerelementen verwenden
Nachdem Sie Ihrer Canvas-App nun das KI-Modell hinzugefügt haben, sehen wir uns an, wie Sie ein AI Builder-Modell über ein Steuerelement aufrufen.
Im folgenden Beispiel erstellen wir eine App, die die von einem Benutzer in der App eingegebene Sprache erkennen kann.
App erstellen Mehr Informationen: Erstellen Sie eine Canvas App ohne Vorlage.
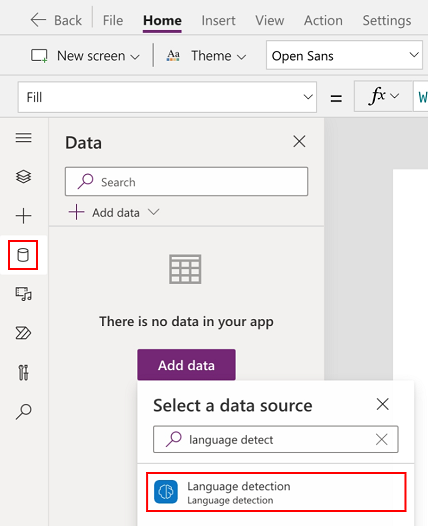
Wählen Sie Daten>Daten hinzufügen>KI-Modelle.
Suchen Sie das Spracherkennung-KI-Modell und wählen Sie es aus.
Notiz
Wenn Sie die App in Umgebungen verschieben, müssen Sie das Modell in der neuen Umgebung manuell wieder zur App hinzufügen.
Wählen Sie im linken Bereich + und dann das Steuerelement Texteingabe aus.
Wiederholen Sie den vorherigen Schritt, um ein Beschriftung-Steuerelement hinzufügen.
Benennen Sie das Text Label in Language um.
Fügen Sie neben der Beschriftung „Sprache“ eine weitere Beschriftung hinzu.
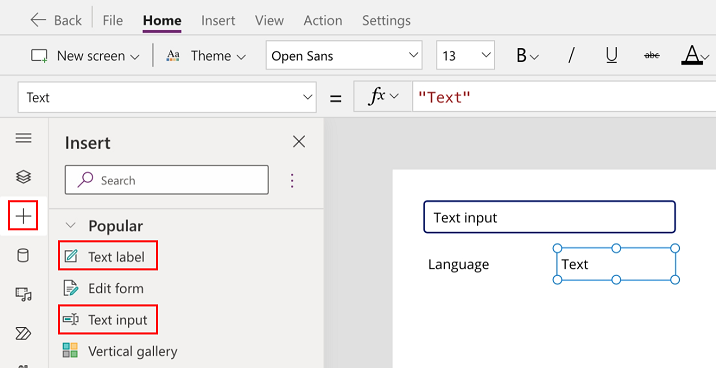
Wählen Sie die im vorherigen Schritt hinzugefügte Beschriftung aus.
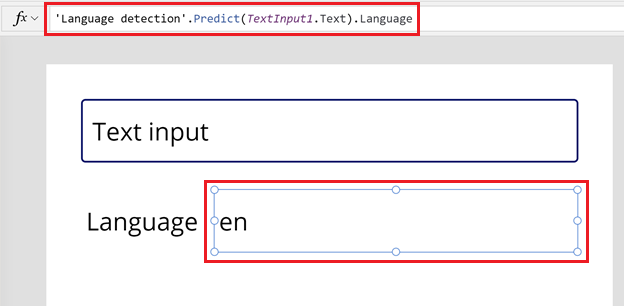
Geben Sie die folgende Formel in der Formelleiste für die Eigenschaft Text der Beschriftung ein.
'Language detection'.Predict(TextInput1.Text).LanguageDie Beschriftung ändert sich in den Sprachcode basierend auf Ihrem Gebietsschema. Für dieses Beispiel en (Englisch).
Wählen Sie die Schaltfläche Wiedergabe in der oberen rechten Ecke des Bildschirms aus, um eine Vorschau der App anzuzeigen.
Geben Sie im Textfeld
bonjourein. Beachten Sie, dass die Sprache für Frankreich (fr) unterhalb des Textfeldes erscheint.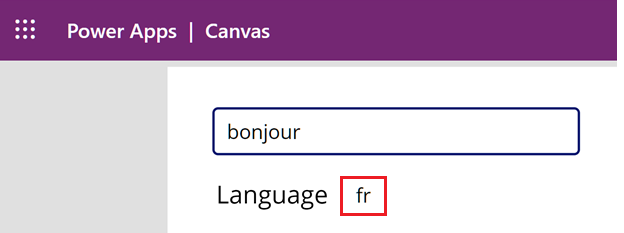
Probieren Sie in ähnlicher Weise Text in einer anderen Sprache aus. Wenn Sie zum Beispiel
guten tageingeben, wird die erkannte Sprache in de für deutsche Sprache geändert.
Best Practices
Versuchen Sie, die Modellvorhersage durch einzelne Aktionen auszulösen wie z. B. OnClick mit einer Schaltfläche statt der OnChange-Aktion auf eine Texteingabe, um eine effiziente Nutzung der AI Builder-Kredite zu gewährleisten.
Um Zeit und Ressourcen zu sparen, speichern Sie das Ergebnis eines Modellaufrufs, damit Sie es an mehreren Stellen verwenden können. Sie können eine Ausgabe in einer globalen Variablen speichern. Nachdem Sie das Modellergebnis gespeichert haben, können Sie die Sprache an anderer Stelle in Ihrer App verwenden, um die identifizierte Sprache und ihre Konfidenzbewertung in zwei verschiedenen Beschriftungen anzuzeigen.
Set(lang, 'Language detection'.Predict("bonjour").Language)
Eingabe und Ausgabe nach Modelltyp
Dieser Abschnitt enthält Eingaben und Ausgaben für angepasste und vorgefertigte Modelle nach Modelltyp.
Benutzerdefinierte Modelle
| Modelltyp | Syntax | Ausgabe |
|---|---|---|
| Klassifizierung von Kategorien | 'Custom text classification model name'.Predict(Text: String, Language?: Optional String) |
{AllClasses: {Name: String, Confidence: Number}[],TopClass: {Name: String,Confidence: Number}} |
| Extraktion von Entitäten | 'Custom entity extraction model name’.Predict(Text: String,Language?:String(Optional)) |
{Entities:[{Type: "name",Value: "Bill", StartIndex: 22, Length: 4, Confidence: .996, }, { Type: "name", Value: "Gwen", StartIndex: 6, Length: 4, Confidence: .821, }]} |
| Objekt-Erkennung | 'Custom object detection model name'.Predict(Image: Image) |
{ Objects: { Name: String, Confidence: Number, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }}[]} |
Vordefinierte Modelle
Anmerkung
Vordefinierte Modellnamen werden im Gebietsschema Ihrer Umgebung angezeigt. Die folgenden Beispiele zeigen die Modellnamen für die englische Sprache (en).
| Modelltyp | Syntax | Ausgabe |
|---|---|---|
| Visitenkartenleser | ‘Business card reader’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text", Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Klassifizierung von Kategorien | 'Category classification'.Predict( Text: String,Language?: Optional String, ) |
{ AllClasses: { Name: String, Confidence: Number }[], TopClass: { Name: String, Confidence: Number }} |
| Identitätsbeleg-Leser | ‘Identity document reader’.Predict( Document: Base64 encoded image ) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text", Confidence: Number, Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Verarbeitung von Rechnungen | ‘Invoice processing’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number,Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: { Items: { Rows: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } }} |
| Extraktion von Schlüsselwörtern | 'Key phrase extraction'.Predict(Text: String, Language?: Optional String)) |
{ Phrases: String[]} |
| Spracherkennung | 'Language Detection'.Predict(Text: String) |
{ Language: String, Confidence: Number} |
| Empfangsverarbeitung | ‘Receipt processing’.Predict( Document: Base64 encoded image) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: {Items: {Rows: {FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } } } |
| Sentiment-Analyse | 'Sentiment analysis'.Predict( Text: String, Language?: Optional String ) |
{ Document: { AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } } Sentences: { StartIndex: Number, Length: Number, AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } }[]} |
| Texterkennung | 'Text recognition'.Predict( Document: Base64 encoded image) |
{Pages: {Page: Number,Lines: { Text: String, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }, Confidence: Number }[] }[]} |
| Textübersetzung | 'Text translation'.Predict( Text: String, TranslateTo?: String, TranslateFrom?: String) |
{ Text: String, // Translated text DetectedLanguage?: String, DetectedLanguageConfidence: Number} } |
Beispiele
Jedes Modell wird mit dem Vorhersage-Verb aufgerufen. Ein Beispiel: Ein Spracherkennungsmodell nimmt einen Text als Eingabe und gibt eine Tabelle mit möglichen Sprachen zurück, geordnet nach der Bewertung dieser Sprache. Die Bewertung zeigt an, wie sicher das Modell mit seiner Vorhersage ist.
| Eingabe | Ausgabe |
|---|---|
'Language detection'.Predict("bonjour") |
{ Language: “fr”, Confidence: 1} |
‘Text Recognition’.Predict(Image1.Image) |
{ Pages: [ {Page: 1, Lines: [ { Text: "Contoso account", BoundingBox: { Left: .15, Top: .05, Width: .8, Height: .10 }, Confidence: .97 }, { Text: "Premium service", BoundingBox: { Left: .15, Top: .20, Width: .8, Height: .10 }, Confidence: .96 }, { Text: "Paid in full", BoundingBox: { Left: .15, Top: .35, Width: .8, Height: .10 }, Confidence: .99 } } ] } |