Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Um die Leistung Ihrer generativen KI-Modelle und -Apps beim Anwenden auf einen umfangreichen Datensatz gründlich zu bewerten, können Sie einen Auswertungsprozess einleiten. Während dieser Auswertung wird Ihr Modell bzw. Ihre Anwendung mit dem angegebenen Dataset getestet und die Leistung quantitativ mit sowohl auf Mathematik basierten als auch mit KI-gestützten Metriken gemessen. Dieser Auswertungslauf bietet Ihnen umfassende Einblicke in die Funktionen und Einschränkungen der Anwendung.
Um diese Auswertung durchzuführen, können Sie die Auswertungsfunktionalität im Azure KI Foundry-Portal nutzen, eine umfassende Plattform, die Tools und Features zum Bewerten der Leistung und Sicherheit für Ihr generatives KI-Modell bietet. Im Azure KI Foundry-Portal können Sie detaillierte Auswertungsmetriken protokollieren, anzeigen und analysieren.
In diesem Artikel erfahren Sie, wie Sie eine Auswertungsausführung anhand eines Modells oder eines Testdatensatzes mit integrierten Auswertungsmetriken aus der Azure AI Foundry-Benutzeroberfläche erstellen. Für eine größere Flexibilität können Sie einen benutzerdefinierten Auswertungsflow einrichten und das benutzerdefinierte Auswertungsfeature verwenden. Wenn Ihr Ziel darin besteht, einen Batchlauf ohne Auswertung durchzuführen, können Sie auch das benutzerdefinierte Auswertungsfeature nutzen.
Voraussetzungen
Um eine Auswertung mit KI-unterstützten Metriken auszuführen, müssen Sie Folgendes bereithalten:
- Ein Test-Dataset in einem der folgenden Formate:
csvoderjsonl. - Eine Azure OpenAI-Verbindung. Eine Bereitstellung eines dieser Modelle: GPT 3.5-Modelle, GPT 4-Modelle oder Davinci-Modelle. Dies ist nur erforderlich, wenn Sie KI-gestützte Qualitätsauswertungen ausführen.
Erstellen einer Auswertung mit integrierten Auswertungsmetriken
Mit einem Auswertungslauf können Sie Metrikausgaben für jede Datenzeile in Ihrem Testdatensatz generieren. Sie können eine oder mehrere Auswertungsmetriken auswählen, um die Ausgabe aus verschiedenen Aspekten zu bewerten. Sie können eine Auswertung auf den Auswertungs- oder Modellkatalogseiten im Azure AI Foundry-Portal erstellen. Anschließend wird ein Auswertungserstellungs-Assistent angezeigt, der Sie durch den Prozess der Einrichtung eines Auswertungslaufs führt.
Von der Seite Auswerten
Wählen Sie im reduzierbaren linken Menü Auswertung>+ Neue Auswertung erstellen aus.

Auf der Modellkatalogseite
Wählen Sie im reduzierbaren linken Menü Folgendes aus: Modellkatalog> Zu einem bestimmten Modell wechseln > Zur Registerkarte „Benchmark“ navigieren > Mit eigenen Daten testen. Dadurch wird der Modellauswertungspanel geöffnet, in dem Sie eine Auswertungsausführung für Ihr ausgewähltes Modell erstellen können.

Auswertungsziel
Wenn Sie eine Auswertung von der Seite "Auswerten" starten, müssen Sie entscheiden, was das Auswertungsziel zuerst ist. Durch die Angabe des geeigneten Auswertungsziels können wir die Auswertung auf die spezifische Art Ihrer Anwendung anpassen und dabei genaue und relevante Metriken sicherstellen. Wir unterstützen zwei Arten von Auswertungszielen:
- Fein abgestimmtes Modell: Sie möchten die ausgabe auswerten, die von Ihrem ausgewählten Modell und einer benutzerdefinierten Eingabeaufforderung generiert wurde.
- Dataset: Sie haben bereits über das Modell generierte Ausgaben in einem Test-Dataset.

Testdaten konfigurieren
Wenn Sie den Assistenten zur Erstellung von Auswertungen aufrufen, können Sie aus bestehenden Datensätzen auswählen oder einen neuen Datensatz hochladen, der speziell ausgewertet werden soll. Um für die Auswertung verwendet zu werden, muss das Test-Dataset vom Modell generierte Ausgaben enthalten. Eine Vorschau Ihrer Testdaten wird im rechten Bereich angezeigt.
Wählen Sie ein vorhandenes Dataset aus: Sie können das Test-Dataset aus Ihrer etablierten Dataset-Sammlung auswählen.
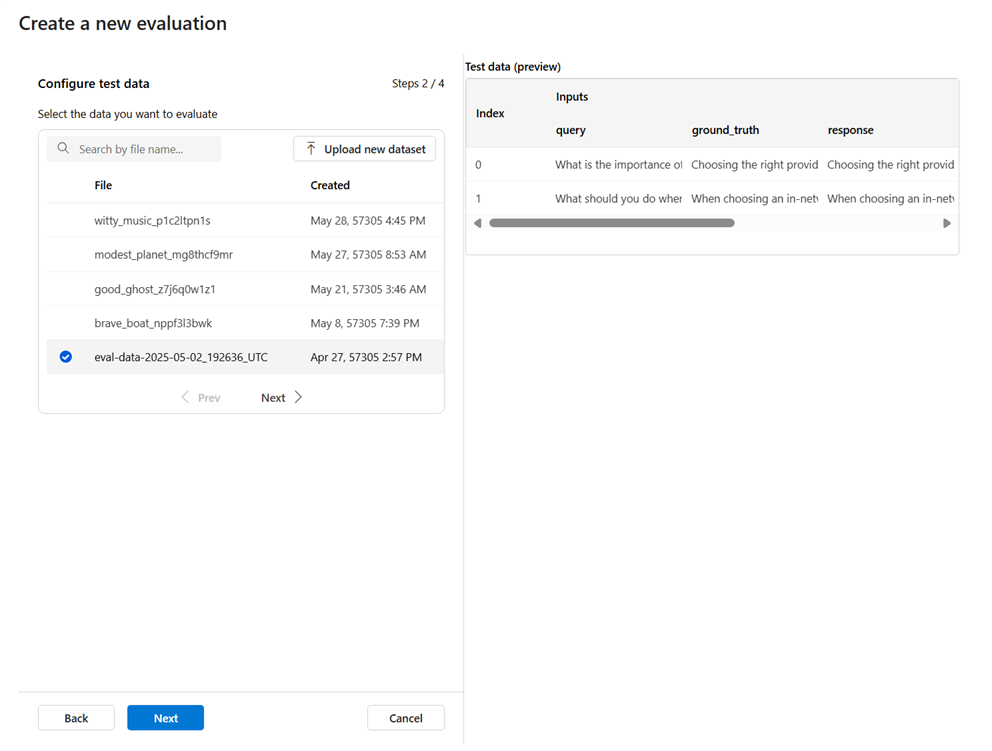
Hinzufügen eines neuen Datasets: Sie können Dateien aus Ihrem lokalen Speicher hochladen. Es werden nur die Dateiformate
.csvund.jsonlunterstützt. Eine Vorschau Ihrer Testdaten wird im rechten Bereich angezeigt.


Konfigurieren von Testkriterien
Es werden drei von Microsoft kuratierte Arten von Metriken unterstützt, um eine umfassende Auswertung Ihrer Anwendung zu ermöglichen:
- KI-Qualität (KI-gestützt): Mit diesen Metriken wird die allgemeine Qualität und Kohärenz des generierten Inhalts auswertet. Um diese Metriken zu nutzen, muss eine Modellimplementierung als Richter fungieren.
- KI-Qualität (NLP): Diese NLP-Metriken basieren auf Mathematik. Mit ihnen wird auch die allgemeine Qualität des generierten Inhalts ausgewertet. Sie erfordern häufig Ground Truth, aber keine Modellimplementierung als Richter.
- Risiko- und Sicherheitsmetriken: Diese Metriken konzentrieren sich auf die Identifizierung potenzieller Inhaltrisiken und die Gewährleistung der Sicherheit der generierten Inhalte.

Wenn Sie Ihre Testkriterien hinzufügen, werden verschiedene Metriken als Teil der Auswertung verwendet. In der Tabelle finden Sie die vollständige Liste der Metriken, die für jedes Szenario unterstützt werden. Ausführlichere Informationen zu den einzelnen Metrikdefinitionen und deren Berechnung finden Sie unter "Was sind Evaluatoren?".
| KI-Qualität (KI-gestützt) | KI-Qualität (NLP) | Risiko- und Sicherheitsmetriken |
|---|---|---|
| Groundedness, Relevanz, Kohärenz, Fluss, GPT-Ähnlichkeit | F1-Score, ROUGE-Score, BLEU-Score, GLEU-Score, METEOR-Score | Selbstverletzte Inhalte, Hass und unfaire Inhalte, gewalttätige Inhalte, sexuelle Inhalte, geschütztes Material, indirekte Angriffe |
Bei der Ausführung der KI-unterstützten Qualitätsbewertung müssen Sie ein GPT-Modell für den Berechnungs-/Bewertungsprozess angeben.

KI-Qualität-Metriken (NLP) sind auf Mathematik basierende Messungen, mit denen die Leistung Ihrer Anwendung bewertet wird. Sie benötigen oft Ground Truth für die Berechnung. ROUGE ist eine Metrikfamilie. Sie können den ROUGE-Typ auswählen, um die Scores zu berechnen. Verschiedene Arten von ROUGE-Metriken bieten Möglichkeiten, die Qualität der Textgenerierung auszuwerten. ROUGE-N misst die Überlappung von N-Grammen zwischen Kandidat- und Referenztext.

Für Risiko- und Sicherheitsmetriken müssen Sie keine Bereitstellung bereitstellen. Der Back-End-Dienst für Sicherheitsbewertungen im Azure KI Foundry-Portal stellt ein GPT-4-Modell bereit, das Scores für den Schweregrad des Inhaltsrisikos und Argumente generieren kann, die es Ihnen ermöglichen, Ihre Anwendung auf Inhaltsschäden zu überprüfen.

Hinweis
KI-unterstützte Risiko- und Sicherheitsmetriken werden vom Back-End-Dienst für Sicherheitsbewertungen von Azure KI Foundry gehostet und sind nur in den folgenden Regionen verfügbar: USA, Osten 2, Frankreich, Mitte, Vereinigtes Königreich, Süden, Schweden, Mitte
Vorsicht
Abwärtskompatibilität für Azure OpenAI-Benutzer, die in die Foundry Developer Platform integriert wurden:
Benutzer, die zuvor oai.azure.com verwendet haben, um ihre Modellbereitstellungen zu verwalten und Auswertungen durchzuführen und seitdem auf die Foundry Developer Platform (FDP) umgestiegen sind, werden einige Einschränkungen bei der Nutzung von ai.azure.com erleben.
Zunächst können Benutzer ihre Auswertungen, die mit der Azure OpenAI-API erstellt wurden, nicht anzeigen. Um diese anzuzeigen, müssen Benutzer stattdessen zurück zu oai.azure.com navigieren.
Zweitens können Benutzer die Azure OpenAI-API nicht verwenden, um Auswertungen in AI Foundry auszuführen. Stattdessen sollten diese Benutzer weiterhin oai.azure.com verwenden. Benutzer können jedoch die Azure OpenAI-Evaluatoren verwenden, die direkt in AI Foundry (ai.azure.com) in der Datensetauswertungserstellungsoption verfügbar sind. Die Feinabstimmung der Modellauswertungsoption wird nicht unterstützt, wenn es sich bei der Bereitstellung um eine Migration von Azure OpenAI zu Azure Foundry handelt.
Für das Datensatz-Upload- und Bring-Your-Own-Storage-Szenario müssen einige Konfigurationsanforderungen erfüllt werden.
- Die Kontoauthentifizierung muss Entra ID sein.
- Der Speicher muss dem Konto hinzugefügt werden (wenn er dem Projekt hinzugefügt wird, erhalten Sie Dienstfehler).
- Der Benutzer muss sein Projekt über die Zugriffssteuerung im Azure-Portal zu ihrem Speicherkonto hinzufügen.
Weitere Informationen zum Erstellen von Auswertungen speziell mit OpenAI-Bewertungsgradern im Azure OpenAI Hub finden Sie unter Verwenden von Auswertungen in Modellen von Azure OpenAI in Azure AI Foundry.
Datenabbildung
Datenzuordnung für die Auswertung: Für jede hinzugefügte Metrik müssen Sie angeben, welche Datenspalten in Ihrem Dataset den eingaben entsprechen, die in der Auswertung erforderlich sind. Verschiedene Auswertungsmetriken erfordern unterschiedliche Arten von Dateneingaben für genaue Berechnungen.
Während der Auswertung wird die Antwort des Modells anhand von Schlüsseleingaben bewertet, z. B.:
- Abfrage: für alle Metriken erforderlich
- Kontext: optional
- Ground Truth: optional, erforderlich für KI-Qualitätsmetriken (NLP)
Diese Zuordnungen stellen eine genaue Harmonisierung zwischen Ihren Daten und den Auswertungskriterien sicher.

Einen Leitfaden zu den spezifischen Datenzuordnungsanforderungen für jede Metrik finden Sie in den Informationen in der Tabelle:
Anforderungen an die Abfrage- und Antwortmetriken
| Maßeinheit | Abfrage | Antwort | Kontext | Grundwahrheit |
|---|---|---|---|---|
| Verankerung | Erforderlich: Str | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar |
| Kohärenz | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Geläufigkeit | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Relevanz | Erforderlich: Str | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar |
| GPT-Ähnlichkeit | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| F1-Bewertung | Nicht verfügbar | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| BLEU-Bewertung | Nicht verfügbar | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| GLEU-Score | Nicht verfügbar | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| METEOR Score | Nicht verfügbar | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| ROUGE-Score | Nicht verfügbar | Erforderlich: Str | Nicht verfügbar | Erforderlich: Str |
| Inhalte mit Bezug auf Selbstverletzung | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Hasserfüllte und unfaire Inhalte | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Gewalttätige Inhalte | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Sexuelle Inhalte | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Geschütztes Material | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
| Indirekter Angriff | Erforderlich: Str | Erforderlich: Str | Nicht verfügbar | Nicht verfügbar |
- Abfrage: eine Frage nach bestimmten Informationen
- Antwort: die vom Modell generierte Antwort auf die Frage
- Kontext: die Quelle, in Bezug auf die die Antwort generiert wird, d. h. die Grounding-Dokumente
- Ground Truth: die Antwort auf die Abfrage, die vom Benutzer/Menschen als die tatsächliche Antwort generiert wurde
Prüfen und fertigstellen
Nachdem Sie alle erforderlichen Konfigurationen abgeschlossen haben, können Sie einen optionalen Namen für Ihre Auswertung angeben. Anschließend können Sie die Option "Absenden" überprüfen und fortfahren, um die Auswertungsausführung zu übermitteln.

Feinabstimmung der Modellauswertung
Um eine neue Auswertung für die ausgewählte Modellbereitstellung zu erstellen, können Sie ein GPT-Modell verwenden, um Beispielfragen zu generieren, oder Sie können aus ihrer etablierten Datasetsammlung auswählen.

Konfigurieren von Testdaten für fein abgestimmtes Modell
Richten Sie das Testdatenset ein, das für die Auswertung verwendet wird. Dieses Dataset wird an das Modell gesendet, um Antworten für die Bewertung zu generieren. Sie haben zwei Optionen zum Konfigurieren Ihrer Testdaten:
- Generieren von Beispielfragen
- Verwenden eines vorhandenen Datasets (oder Hochladen eines neuen Datasets)
Generieren von Beispielfragen
Wenn Sie kein Dataset direkt zur Verfügung haben und eine Auswertung mit einer kleinen Stichprobe ausführen möchten, wählen Sie das Modell-Deployment aus, das Sie nach einem gewählten Thema bewerten möchten. Wir unterstützen sowohl Azure OpenAI-Modelle als auch andere offene Modelle, die mit der Standardbereitstellung kompatibel sind, z. B. Meta LIama- und Phi-3-Familienmodelle. Das Thema hilft dabei, die generierten Inhalte an Ihren Interessenbereich anzupassen. Die Abfragen und Antworten werden in Echtzeit generiert, und Sie haben die Möglichkeit, sie nach Bedarf neu zu generieren.

Verwendung Ihres Datensatzes
Sie können auch aus Ihrer etablierten Datasetsammlung auswählen oder ein neues Dataset hochladen.

Auswählen von Auswertungsmetriken
Danach können Sie auf "Weiter" klicken, um Ihre Testkriterien zu konfigurieren. Während Sie Ihre Kriterien auswählen, werden Metriken hinzugefügt, und Sie müssen die Spalten Ihres Datasets den erforderlichen Feldern für die Auswertung zuordnen. Diese Zuordnungen stellen eine genaue Harmonisierung zwischen Ihren Daten und den Auswertungskriterien sicher. Nachdem Sie die gewünschten Testkriterien ausgewählt haben, können Sie die Auswertung überprüfen, optional den Namen der Auswertung ändern und dann " Absenden " auswählen, um den Auswertungslauf zu übermitteln, und zur Auswertungsseite wechseln, um die Ergebnisse anzuzeigen.

Hinweis
Das generierte Dataset wird im BLOB-Speicher des Projekts gespeichert, nachdem die Auswertungsausführung erstellt wurde.
Anzeigen und Verwalten der Auswertungen in der Auswertungsbibliothek
Die Auswertungsbibliothek ist ein zentraler Ort, an dem Sie die Details und den Status Ihrer Auswertungen anzeigen können. Sie können von Microsoft kuratierte Auswertungen anzeigen und verwalten.
Die Auswertungsbibliothek ermöglicht auch die Versionsverwaltung. Sie können unterschiedliche Versionen Ihrer Arbeit vergleichen, bei Bedarf frühere Versionen wiederherstellen und einfacher mit anderen Personen zusammenarbeiten.
Um die Auswertungsbibliothek im Azure KI Foundry-Portal zu verwenden, wechseln Sie zur Seite Auswertung Ihres Projekts, und wählen Sie die Registerkarte Auswertungsbibliothek aus.

Sie können den Namen der Auswertung auswählen, um weitere Details anzuzeigen. Sie können den Namen, die Beschreibung und Parameter anzeigen und die der Auswertung zugeordneten Dateien überprüfen. Im Anschluss folgen einige Beispiele für von Microsoft kuratierte Ressourcen:
- Für von Microsoft kuratierte Leistungs- und Qualitätsauswertungen können Sie den Prompt für Anmerkungen auf der Detailseite anzeigen. Sie können diese Eingabeaufforderungen an Ihren eigenen Anwendungsfall anpassen, indem Sie die Parameter oder Kriterien entsprechend Ihren Daten und Zielen im Azure AI Evaluation SDK ändern. Sie können z. B. Groundedness-Evaluator auswählen und die Prompt-Datei überprüfen, die zeigt, wie die Metrik berechnet wird.
- Für von Microsoft kuratierte Risiko- und Sicherheitsauswertungen können Sie die Definition der Metriken anzeigen. Sie können z. B. Self-Harm-Related-Content-Evaluator auswählen und erfahren, was dies bedeutet und wie Microsoft die verschiedenen Schweregrade für diese Sicherheitsmetrik festlegt.
Verwandte Inhalte
Erfahren Sie mehr darüber, wie Sie Ihre generativen KI-Anwendungen auswerten: