Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Auswertungsseite des Azure KI Foundry-Portals ist ein vielseitiger Hub, mit dem Sie Ihre Ergebnisse nicht nur visualisieren und bewerten können, sondern sie dient auch als Kontrollzentrum für die Optimierung, Problembehandlung und Auswahl des idealen KI-Modells für Ihre Bereitstellungsanforderungen. Sie ist eine zentrale Lösung für datengesteuerte Entscheidungsfindung und Leistungsverbesserung in Ihren Azure KI Foundry-Projekten. Sie können nahtlos auf die Ergebnisse aus verschiedenen Quellen zugreifen und diese interpretieren, einschließlich Ihres Flows, der Playground-Schnelltestsitzung, der Auswertungsübermittlungs-UI und des SDK. Diese Flexibilität stellt sicher, dass Sie mit Ihren Ergebnissen auf eine Weise interagieren können, die am besten zu Ihrem Workflow und Ihren Vorlieben passt.
Sobald Sie Ihre Bewertungsergebnisse visualisiert haben, können Sie mit einer gründlichen Untersuchung beginnen. Dies umfasst die Möglichkeit, einzelne Ergebnisse anzuzeigen und diese Ergebnisse über mehrere Auswertungsläufe hinweg zu vergleichen. Damit können Sie Trends, Muster und Diskrepanzen identifizieren und wertvolle Einblicke in die Leistung Ihres KI-Systems unter verschiedenen Bedingungen gewinnen.
In diesem Artikel wird Folgendes behandelt:
- Zeigen Sie das Auswertungsergebnis und Metriken an.
- Vergleichen Sie die Auswertungsergebnisse.
- Verbessern Sie die Leistung.
- Zeigen Sie die Auswertungsergebnisse und Metriken an.
Suchen Ihrer Auswertungsergebnisse
Nachdem Sie Ihre Auswertung übermittelt haben, können Sie zur Seite Auswertung wechseln und in der Ausführungsliste nach der übermittelten Auswertungsausführung suchen.
Sie können ihre Auswertungsausführung in der Ausführungsliste überwachen und verwalten. Mit der Flexibilität, die Spalten mit dem Spalteneditor zu ändern und Filter zu implementieren, können Sie Ihre eigene Version der Laufliste anpassen und erstellen. Darüber hinaus können Sie die aggregierten Auswertungsmetriken schnell über die Ausführung hinweg überprüfen, sodass Sie schnelle Vergleiche ziehen können.

Tipp
Um Auswertungen anzuzeigen, die mit einer beliebigen Version des promptflow-evals-SDK oder der azure-ai-evaluation-Versionen 1.0.0b1, 1.0.0b2, 1.0.0b3 ausgeführt werden, aktivieren Sie die Umschaltfläche „Alle Läufe anzeigen“, um die Ausführung zu suchen.
Um genauer zu verstehen, wie die Auswertungsmetriken abgeleitet werden, können Sie auf eine umfassende Erklärung zugreifen, indem Sie die Option „Weitere Informationen zu Metriken“ auswählen. Diese detaillierte Ressource bietet Einblicke in die Berechnung und Interpretation der Metriken, die im Auswertungsprozess verwendet werden.

Beim Überprüfen der Auswertungstabelle können Sie einen bestimmten auswählen, der Sie zur Detailseite für die Ausführung führt. Hier können Sie auf umfassende Informationen zugreifen, einschließlich Auswertungsdetails wie Testdataset, Aufgabentyp, Prompt, Temperatur und mehr. Darüber hinaus können Sie die Metriken anzeigen, die den einzelnen Datenbeispielen zugeordnet sind. Das Metrikdashboard stellt eine visuelle Darstellung der Passrate für Datasets in den einzelnen getesteten Metriken bereit.
Vorsicht
Abwärtskompatibilität für Azure OpenAI-Benutzer, die in die Foundry Developer Platform integriert wurden:
Benutzer, die zuvor oai.azure.com verwendet haben, um ihre Modellbereitstellungen zu verwalten und Auswertungen durchzuführen und seitdem auf die Foundry Developer Platform (FDP) umgestiegen sind, werden einige Einschränkungen bei der Nutzung von ai.azure.com erleben.
Zunächst können Benutzer ihre Auswertungen, die mit der Azure OpenAI-API erstellt wurden, nicht anzeigen. Um diese anzuzeigen, müssen Benutzer stattdessen zurück zu oai.azure.com navigieren.
Zweitens können Benutzer die Azure OpenAI-API nicht verwenden, um Auswertungen in AI Foundry auszuführen. Stattdessen sollten diese Benutzer weiterhin oai.azure.com verwenden. Benutzer können jedoch die Azure OpenAI-Evaluatoren verwenden, die direkt in AI Foundry (ai.azure.com) in der Datensetauswertungserstellungsoption verfügbar sind. Die Feinabstimmung der Modellauswertungsoption wird nicht unterstützt, wenn es sich bei der Bereitstellung um eine Migration von Azure OpenAI zu Azure Foundry handelt.
Für das Datensatz-Upload- und Bring-Your-Own-Storage-Szenario müssen einige Konfigurationsanforderungen erfüllt werden.
- Die Kontoauthentifizierung muss Entra ID sein.
- Der Speicher muss dem Konto hinzugefügt werden (wenn er dem Projekt hinzugefügt wird, erhalten Sie Dienstfehler).
- Der Benutzer muss sein Projekt über die Zugriffssteuerung im Azure-Portal zu ihrem Speicherkonto hinzufügen.
Weitere Informationen zum Erstellen von Auswertungen speziell mit OpenAI-Bewertungsgradern im Azure OpenAI Hub finden Sie unter Verwenden von Auswertungen in Modellen von Azure OpenAI in Azure AI Foundry.
Diagramme im Metrik-Dashboard
Wir schlüsseln die aggregierten Ansichten mit verschiedenen Arten Ihrer Metriken auf nach KI-Qualität (KI-unterstützt), Risiko und Sicherheit, KI-Qualität (NLP) und benutzerdefiniert, falls zutreffend. Die Ergebnisse werden basierend auf den Kriterien angezeigt, die beim Erstellen der Auswertung ausgewählt wurden, als Prozentsatz der Übergabe/Fehler. Ausführlichere Informationen zu den einzelnen Metrikdefinitionen und deren Berechnung finden Sie unter "Was sind Evaluatoren?".
- Für KI-Qualität (KI-unterstützt) aggregieren wir, indem wir einen Mittelwert für alle Bewertungen jeder Metrik berechnen. Wenn Sie „Groundedness Pro“ berechnen, ist die Ausgabe binär und somit ist der aggregierte Score die Erfolgsquote, die sich aus (#trues / #instances) × 100 ergibt.
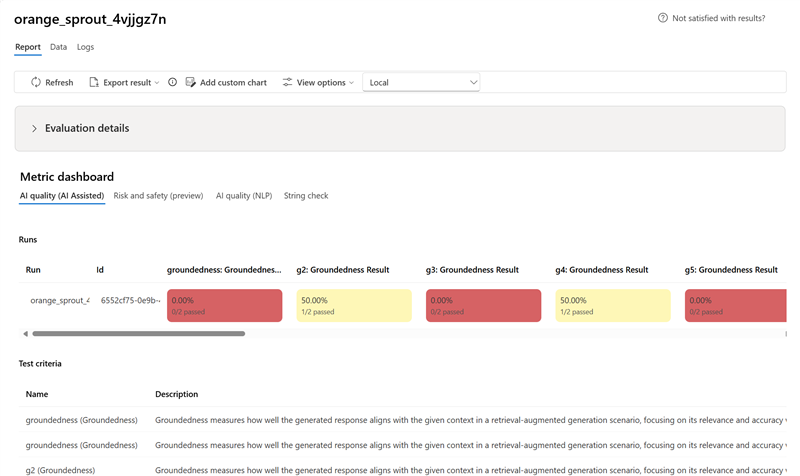
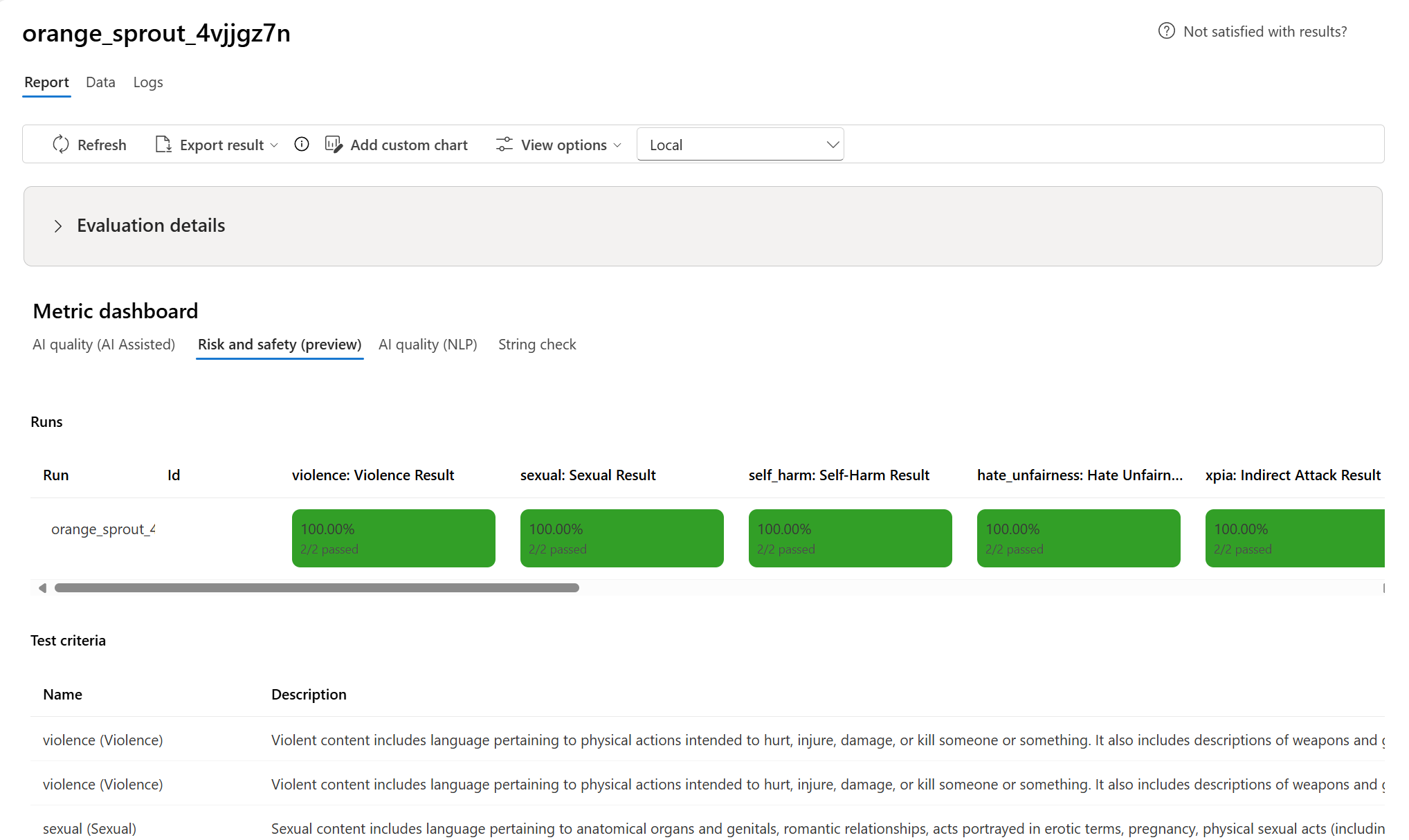
- Für Risiko- und Sicherheitsmetriken aggregieren wir, indem wir für jede Metrik eine Fehlerrate berechnen.
- Die Fehlerrate für Metriken für Inhaltsschäden wird als Prozentsatz der Instanzen in Ihrem Testdatensatz definiert, die einen Schwellenwert für den Schweregrad über die gesamte Datasetgröße überschreiten. Standardmäßig ist der Schwellenwert „Mittel“.
- Bei geschützten Materialien und indirekten Angriffen wird die Fehlerrate als Prozentsatz der Instanzen berechnet, in denen die Ausgabe „true“ ist (Fehlerrate = (#trues / #instances) × 100).
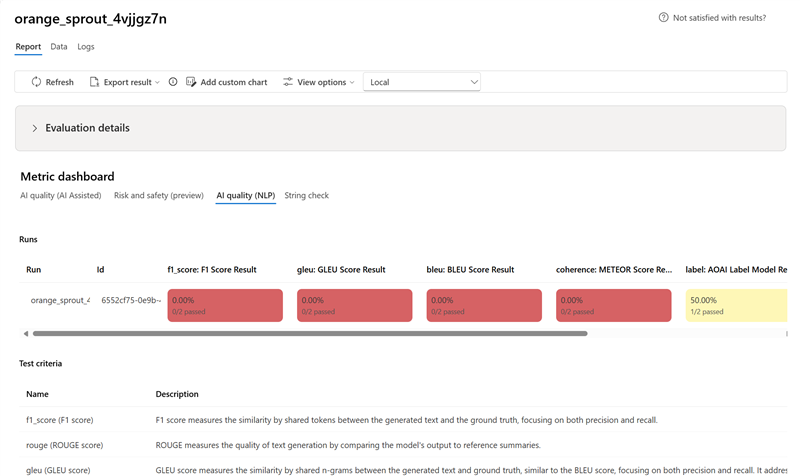
- Für AI Quality (NLP)-Metriken wird aggregiert, indem wir einen Mittelwert für alle Bewertungen für jede Metrik berechnen.



Detaillierte Metrik-Ergebnistabelle
Im Datenabschnitt können Sie eine umfassende Untersuchung der einzelnen Datenbeispiele und der zugehörigen Metriken durchführen. Hier können Sie die generierte Ausgabe und die entsprechende Bewertungsmetrik überprüfen und überprüfen, ob sie basierend auf der bestandenen Note beim Ausführen des Tests bestanden wurde. Dieser Detaillierungsgrad ermöglicht es Ihnen, datengestützte Entscheidungen zu treffen und spezifische Maßnahmen zur Verbesserung der Leistung Ihres Modells zu ergreifen.
Einige potenzielle Aktionselemente, die auf den Auswertungsmetriken basieren, können folgendes umfassen:
- Erkennung von Mustern: Durch die Filterung nach numerischen Werten und Metriken können Sie Proben mit niedrigeren Punktzahlen aufschlüsseln. Untersuchen Sie diese Beispiele, um wiederkehrende Muster oder Probleme in den Antworten Ihres Modells zu identifizieren. Beispielsweise stellen Sie möglicherweise fest, dass niedrige Bewertungen häufig auftreten, wenn das Modell Inhalte zu einem bestimmten Thema generiert.
- Modelleinschränkung: Verwenden Sie die Erkenntnisse aus Beispielen mit niedrigerer Bewertung, um die Systemaufforderungsanweisung zu verbessern oder Ihr Modell zu optimieren. Wenn Sie durchgängige Probleme z. B. mit der Kohärenz oder Relevanz feststellen, können Sie auch die Trainingsdaten oder Parameter des Modells entsprechend anpassen.
- Spaltenanpassung: Mit dem Spalten-Editor können Sie eine angepasste Ansicht der Tabelle erstellen, die sich auf die Metriken und Daten konzentriert, die für Ihre Bewertungsziele am relevantesten sind. So können Sie Ihre Analyse optimieren und Trends besser erkennen.
- Stichwortsuche: Mit dem Suchfeld können Sie nach bestimmten Wörtern oder Ausdrücken in der generierten Ausgabe suchen. Dies kann nützlich sein, um Probleme oder Muster im Zusammenhang mit bestimmten Themen oder Schlüsselwörtern zu erkennen und diese gezielt anzugehen.
Die Detailtabelle der Metriken bietet eine Fülle von Daten, die Sie bei der Verbesserung Ihres Modells unterstützen können, von der Erkennung von Mustern über die Anpassung Ihrer Ansicht für eine effiziente Analyse bis hin zur Verfeinerung Ihres Modells auf der Grundlage der erkannten Probleme.
Hier sind einige Beispiele für die Ergebnisse der Metriken für das Szenario zur Beantwortung von Fragen:

Einige Auswertungen verfügen über Unterwertgeber, mit denen Sie den JSON-Code der Ergebnisse aus den Unterbewertungen anzeigen können. Um die Ergebnisse anzuzeigen, wählen Sie "In JSON anzeigen" aus, um die Ergebnisse zu öffnen.


Und hier sind einige Beispiele für die metrischen Ergebnisse für das Konversationsszenario. Um die Ergebnisse während einer multi-turn Konversation zu überprüfen, wählen Sie in der Konversationsspalte "Auswertungsergebnisse pro Schritt anzeigen" aus.

Wenn Sie "Auswertungsergebnisse pro Drehung anzeigen" auswählen, wird der folgende Bildschirm angezeigt:

Für eine Sicherheitsbewertung in einem multimodalen Szenario (Text + Bilder) können Sie die Bilder sowohl aus der Eingabe als auch der Ausgabe in der detaillierten Metrik-Ergebnistabelle überprüfen, um das Auswertungsergebnis besser zu verstehen. Da die multimodale Auswertung derzeit nur für Unterhaltungsszenarien unterstützt wird, können Sie „Auswertungsergebnisse pro Turn anzeigen“ auswählen, um die Eingabe und Ausgabe für jeden Turn zu untersuchen.

Wählen Sie das Bild aus, um es zu erweitern und anzuzeigen. Standardmäßig sind alle Bilder verschwommen, um Sie vor potenziell schädlichen Inhalten zu schützen. Um das Bild deutlich anzuzeigen, aktivieren Sie den Umschalter „Weichgezeichnetes Bild überprüfen“.

Auswertungsergebnisse haben möglicherweise unterschiedliche Bedeutungen für unterschiedliche Zielgruppen. Beispielsweise könnten Sicherheitsbewertungen eine Bezeichnung für den Schweregrad "Niedrig" von gewalttätigen Inhalten generieren, die möglicherweise nicht an die Definition eines menschlichen Prüfers ausgerichtet sind, wie schwerwiegend dieser gewalttätige Inhalt sein könnte. Pass/Fail wird durch den übergebenden Notensatz während der Auswertungserstellung bestimmt. Wir stellen eine Spalte für menschliches Feedback mit Daumen nach oben und Daumen nach unten bereit, wenn Sie Ihre Auswertungsergebnisse überprüfen, um anzuzeigen, welche Instanzen von einem menschlichen Prüfer genehmigt oder als falsch gekennzeichnet wurden.

Wenn Sie jede Metrik für Inhaltsrisiko verstehen, können Sie jede Metrikdefinition ganz einfach anzeigen, indem Sie zum Abschnitt "Bericht" zurückkehren und im Metrik-Dashboard den Test ansehen.
Wenn bei der Ausführung ein Fehler auftritt, können Sie die Auswertungsausführung auch mit den Protokollen debuggen.
Hier sind einige Beispiele für die Protokolle, die Sie zum Debuggen der Auswertungsausführung verwenden können:

Wenn Sie einen prompt flow auswerten, können Sie die Schaltfläche Im Flow anzeigen auswählen, um zur Seite des ausgewerteten Flows zu navigieren und eine Aktualisierung Ihres Flows vorzunehmen. Fügen Sie z. B. zusätzliche Metaaufforderungsanweisung hinzu, oder ändern Sie einige Parameter, und bewerten Sie sie erneut.
Vergleichen der Auswertungsergebnisse
Um einen umfassenden Vergleich zwischen zwei oder mehr Ausführungen zu erleichtern, können Sie die gewünschten Ausführungen auswählen und den Prozess initiieren, indem Sie die Schaltfläche Vergleichen oder für eine allgemeine detaillierte Dashboardansicht die Schaltfläche Zur Dashboardansicht wechseln auswählen. Mit diesem Feature können Sie die Leistung und die Ergebnisse mehrerer Läufe analysieren und kontrastieren, was eine fundiertere Entscheidungsfindung und gezieltere Verbesserungen ermöglicht.

In der Dashboardansicht haben Sie Zugriff auf zwei wertvolle Komponenten: das Diagramm zum Vergleich der Metrikverteilung und die Vergleichstabelle. Mit diesen Tools können Sie eine parallele Analyse der ausgewählten Auswertungsläufe durchführen, sodass Sie verschiedene Aspekte der einzelnen Datenbeispiele mühelos und präzise vergleichen können.
Hinweis
Ältere Auswertungsläufe weisen standardmäßig übereinstimmende Zeilen zwischen Spalten auf. Neu ausgeführte Auswertungen müssen jedoch absichtlich so konfiguriert werden, dass während der Auswertungserstellung übereinstimmende Spalten vorhanden sind. Stellen Sie dazu sicher, dass derselbe Name wie der Kriterienname zwischen allen Auswertungen verwendet wird, die Sie vergleichen möchten.
Die Erfahrung, wenn die Felder identisch sind:

Wenn ein Benutzer beim Erstellen der Auswertung nicht denselben Kriteriennamen verwendet, stimmen Felder nicht überein, sodass die Plattform die Ergebnisse nicht direkt vergleichen kann:

In der Vergleichstabelle können Sie Grundwerte für den Vergleich festlegen, indem Sie auf den spezifischen Lauf gehen, den Sie als Referenzpunkt verwenden und als Basisplan festlegen möchten. Darüber hinaus können Sie durch Aktivieren der Umschaltfläche „Delta anzeigen“ die Unterschiede zwischen dem Baseline-Lauf und den anderen Läufen für numerische Werte leicht visualisieren. Darüber hinaus zeigt die Tabelle mit aktivierter Umschaltfläche „Nur Unterschied anzeigen“ nur die Zeilen an, die sich zwischen den ausgewählten Läufen unterscheiden, wobei die Identifizierung unterschiedlicher Variationen unterstützt wird.
Mithilfe dieser Vergleichsfeatures können Sie eine fundierte Entscheidung treffen, um die beste Version auszuwählen:
- Baseline-Vergleich: Durch die Festlegung eines Basislaufs können Sie einen Referenzpunkt festlegen, mit dem Sie die anderen Läufe vergleichen können. Auf diese Weise können Sie sehen, wie jede Ausführung von Ihrem gewählten Standard abweicht.
- Bewertung numerischer Werte: Die Aktivierung der Option „Delta anzeigen“ hilft Ihnen, das Ausmaß der Unterschiede zwischen der Baseline und den anderen Läufen zu verstehen. Dies ist nützlich, um zu bewerten, wie verschiedene Ausführungen in Bezug auf bestimmte Auswertungsmetriken ausgeführt werden.
- Isolierung von Unterschieden: Die Funktion „Nur Unterschiede anzeigen“ optimiert Ihre Analyse, indem sie nur die Bereiche hervorhebt, in denen es Diskrepanzen zwischen den Läufen gibt. Dies kann hilfreich sein, um zu bestimmen, wo Verbesserungen oder Anpassungen erforderlich sind.
Durch effektive Verwendung dieser Vergleichstools können Sie ermitteln, welche Version Ihres Modells oder Systems in Bezug auf Ihre definierten Kriterien und Metriken am besten geeignet ist, um letztendlich die optimale Option für Ihre Anwendung auszuwählen.

Messen von Jailbreak-Sicherheitsrisiken
Die Bewertung von Jailbreak ist eine vergleichende Messung, keine KI-unterstützte Metrik. Führen Sie Auswertungen auf zwei unterschiedlichen, „Red-Teamed“-Datasets aus: ein feindseliges Test-Baseline-Dataset im Vergleich zum gleichen feindseligen Test-Dataset mit Jailbreak-Einschleusungen im ersten Schritt. Sie können den Adversarydatensimulator verwenden, um das Dataset mit oder ohne Jailbreakinjektionen zu generieren. Stellen Sie sicher, dass der Kriterienname bei der Konfiguration der Ausführung für jede Auswertungsmetrik identisch ist.
Um zu verstehen, ob Ihre Anwendung anfällig für Jailbreak ist, können Sie die Baseline angeben und dann dem Umschalter „Jailbreakfehlerraten“ in der Vergleichstabelle aktivieren. Die Jailbreak-Fehlerrate wird als Prozentsatz der Instanzen in Ihrem Testdatensatz definiert, bei denen eine Jailbreak-Einfügung einen höheren Schweregrad für alle Inhaltsrisikometrik im Hinblick auf eine Baseline über die gesamte Datasetgröße generiert hat. Sie können mehrere Auswertungen in Ihrem Vergleichsdashboard auswählen, um die Unterschiede bei den Fehlerraten anzuzeigen.

Tipp
Die Jailbreakfehlerrate wird nur für Datasets derselben Größe berechnet und nur dann, wenn alle Ausführungen Inhaltsrisiko- und Sicherheitsmetriken enthalten.
Grundlegendes zu den integrierten Auswertungsmetriken
Das Verständnis der integrierten Metriken ist entscheidend für die Bewertung der Leistung und Effektivität Ihrer KI-Anwendung. Durch den Einblick in diese wichtigen Messinstrumente sind Sie besser in der Lage, die Ergebnisse zu interpretieren, fundierte Entscheidungen zu treffen und Ihre Anwendung zu optimieren, um optimale Ergebnisse zu erzielen. Weitere Informationen über die Bedeutung der einzelnen Metriken, ihre Berechnung, ihre Rolle bei der Bewertung verschiedener Aspekte Ihres Modells und die Interpretation der Ergebnisse für datengestützte Verbesserungen finden Sie unter Bewertungs- und Überwachungsmetriken.
Verwandte Inhalte
Erfahren Sie mehr darüber, wie Sie Ihre generativen KI-Anwendungen auswerten:
- Eure generativen KI-Apps mithilfe des Playgrounds evaluieren
- Auswerten Ihrer generativen KI-Apps mit dem Azure KI Foundry-Portal oder -SDK
- Erstellen von Bewertungen speziell durch OpenAI-Bewertungsgutachter im Azure OpenAI Hub
Erfahren Sie mehr über die Techniken zu Schadensminderung.