Sichern und Wiederherstellen benutzerdefinierter NER-Modelle
Wenn Sie eine Language-Ressource erstellen, geben Sie eine Region an, in der sie erstellt werden soll. Dann werden Ihre Ressource und alle damit verbundenen Vorgänge in der angegebenen Azure-Serverregion ausgeführt. Es ist selten, aber nicht unmöglich, dass ein Netzwerkproblem auftritt, das eine ganze Region betrifft. Wenn Ihre Lösung immer verfügbar sein muss, sollten Sie sie so entwerfen, dass ein Failover in eine andere Region erfolgt. Dies erfordert zwei Azure KI Language-Ressourcen in verschiedenen Regionen und die Synchronisierung benutzerdefinierter Modelle in diesen Regionen.
Wenn Ihre App oder Ihr Unternehmen von der Verwendung eines benutzerdefinierten NER-Modells abhängig ist, wird empfohlen, dass Sie ein Replikat Ihres Projekts in einer zusätzlichen unterstützten Region erstellen. Wenn ein regionaler Ausfall eintritt, können Sie auf Ihr Modell in der anderen Failoverregion zugreifen, in der Sie Ihr Projekt repliziert haben.
Das Replizieren eines Projekts bedeutet, dass Sie Ihre Projektmetadaten und -ressourcen exportieren und in ein neues Projekt importieren. Dadurch wird nur eine Kopie Ihrer Projekteinstellungen und gekennzeichneten Daten erstellt. Sie müssen die Modelle weiterhin trainieren und bereitstellen, damit sie für die Verwendung bei Vorhersage-APIs zur Verfügung stehen.
In diesem Artikel erfahren Sie, wie Sie Ihr Projekt mithilfe der Export- und Import-APIs von einer Ressource in eine andere replizieren können, die in verschiedenen unterstützten geografischen Regionen vorhanden ist. Außerdem wird erläutert, wie Sie Ihre Projekte synchron halten und Änderungen vornehmen, die für Ihren Laufzeitverbrauch erforderlich sind.
Voraussetzungen
- Zwei Azure KI Language-Ressourcen in verschiedenen Azure-Regionen. Erstellen Sie Ihre Ressourcen, und verbinden Sie sie mit einem Azure-Speicherkonto. Es wird empfohlen, jede Ihrer Sprachressourcen mit unterschiedlichen Speicherkonten zu verbinden. Jedes Speicherkonto sollte sich in den entsprechenden Regionen befinden, in denen sich Ihre separaten Sprachressourcen befinden. Sie können den Schnellstart durchführen, um eine zusätzliche Sprachressource und ein Speicherkonto zu erstellen.
Abrufen Ihrer Ressourcenschlüssel und des Endpunkts
Führen Sie die folgenden Schritte aus, um die Schlüssel und den Endpunkt Ihrer primären und sekundären Ressourcen abzurufen. Diese Elemente werden in den folgenden Schritten verwendet.
Navigieren Sie im Azure-Portal zur Übersichtsseite Ihrer Ressource.
Wählen Sie im Menü auf der linken Seite Schlüssel und Endpunkt aus. Sie verwenden den Endpunkt und Schlüssel für die API-Anforderungen.
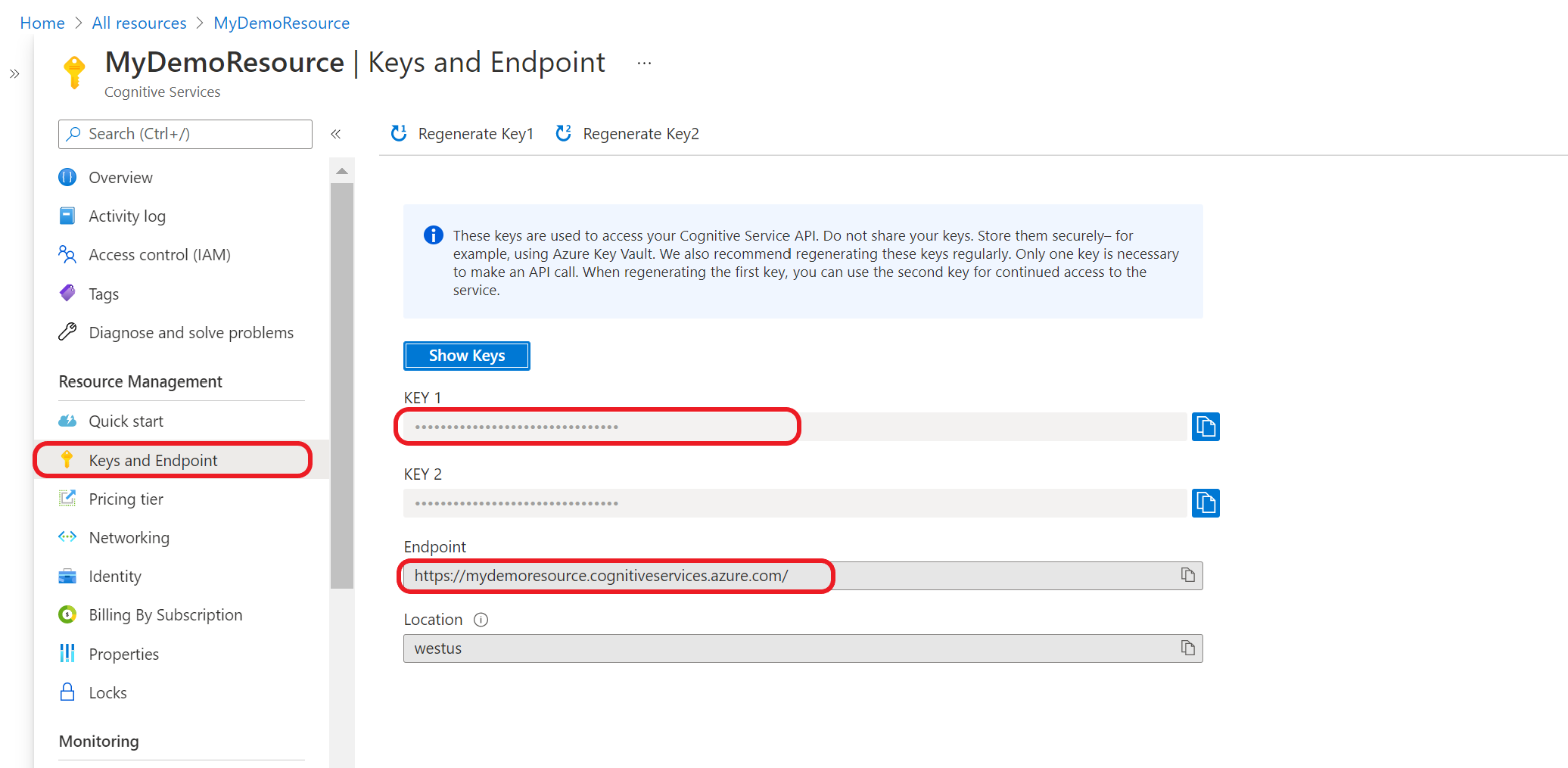

Tipp
Notieren Sie sich Schlüssel und Endpunkte für die primären und sekundären Ressourcen sowie die Namen des primären und sekundären Containers. Durch diese Werte ersetzen Sie die folgenden Platzhalter: {PRIMARY-ENDPOINT}, {PRIMARY-RESOURCE-KEY}, {PRIMARY-CONTAINER-NAME}, {SECONDARY-ENDPOINT}, {SECONDARY-RESOURCE-KEY} und {SECONDARY-CONTAINER-NAME}.
Notieren Sie sich außerdem Ihren Projektnamen, Ihren Modellnamen und Ihren Bereitstellungsnamen. Durch diese Werte ersetzen Sie die folgenden Platzhalter: {PROJECT-NAME}, {MODEL-NAME} und {DEPLOYMENT-NAME}.
Exportieren Ihrer primären Projektressourcen
Exportieren Sie zuerst die Projektressourcen aus dem Projekt in Ihrer primären Ressource.
Übermitteln des Exportauftrags
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {PRIMARY-ENDPOINT} und {PRIMARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Erstellen Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um Ihr Projekt zu exportieren.
Anfrage-URL
Verwenden Sie zum Erstellen Ihrer API-Anforderung die folgende URL. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:export?stringIndexType=Utf16CodeUnit&api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | MyProject |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert entspricht der neuesten veröffentlichten Modellversion. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Body
Verwenden Sie den folgenden JSON-Code in Ihrem Anforderungstext, um anzugeben, dass Sie alle Ressourcen exportieren möchten.
{
"assetsToExport": ["*"]
}
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/export/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie verwenden diese URL, um den Status des Exportauftrags abzurufen.
Abrufen des Exportauftragsstatus
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {PRIMARY-ENDPOINT} und {PRIMARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Verwenden Sie die folgende GET-Anforderung, um den Status beim Exportieren Ihrer Projektressourcen abzurufen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/export/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Diese befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
{
"resultUrl": "{RESULT-URL}",
"jobId": "string",
"createdDateTime": "2021-10-19T23:24:41.572Z",
"lastUpdatedDateTime": "2021-10-19T23:24:41.572Z",
"expirationDateTime": "2021-10-19T23:24:41.572Z",
"status": "unknown",
"errors": [
{
"code": "unknown",
"message": "string"
}
]
}
Verwenden Sie die URL aus dem Schlüssel resultUrl im Text, um die exportierten Ressourcen aus diesem Auftrag anzuzeigen.
Abrufen von Exportergebnissen
Übermitteln Sie eine GET-Anforderung mithilfe der aus dem vorherigen Schritt erhaltenen {RESULT-URL}, um die Ergebnisse des Exportauftrags anzuzeigen.
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Kopieren Sie den Antworttext, da Sie ihn als Text für den nächsten Importauftrag verwenden werden.
Importieren in ein neues Projekt
Importieren Sie jetzt die exportierten Projektressourcen in Ihr neues Projekt in der sekundären Region, damit Sie sie replizieren können.
Übermitteln des Importauftrags
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT}, {SECONDARY-RESOURCE-KEY} und {SECONDARY-CONTAINER-NAME}, die Sie im ersten Schritt abgerufen haben.
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um Ihre Bezeichnungsdatei zu importieren. Stellen Sie sicher, dass die Bezeichnungsdatei dem akzeptierten Format entspricht.
Wenn bereits ein Projekt mit demselben Namen existiert, werden die Daten dieses Projekts ersetzt.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Body
Verwenden Sie den folgenden JSON-Code in Ihrer Anforderung. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
api-version |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Die hier verwendete Version muss mit der API-Version in der URL identisch sein. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
projectKind |
CustomEntityRecognition |
Die Art Ihres Projekts | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
Eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode für die Sprache aus, die in den meisten der Dokumente verwendet wird. | en-us |
multilingual |
true |
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (nicht unbedingt in Ihren Trainingsdokumenten enthalten). Weitere Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung. | true |
storageInputContainerName |
{CONTAINER-NAME} | Der Name Ihres Azure-Speichercontainers, in den Sie Ihre Dokumente hochgeladen haben | myContainer |
entities |
Dies ist ein Array mit allen Entitätstypen, die im Projekt enthalten sind. Dies sind die Entitätstypen, die aus Ihren Dokumenten extrahiert werden. | ||
documents |
Dies ist ein Array mit allen Dokumenten in Ihrem Projekt und die Liste der Entitäten, die innerhalb jedes Dokuments gekennzeichnet sind. | [] | |
location |
{DOCUMENT-NAME} |
Dies ist der Speicherort der Dokumente im Speichercontainer. Da sich alle Dokumente im Stammverzeichnis des Containers befinden, sollte dies der Dokumentname sein. | doc1.txt |
dataset |
{DATASET} |
Dies ist der Testsatz, in den diese Datei bei der Aufteilung vor dem Training aufgenommen wird. Weitere Informationen darüber, wie Ihre Daten geteilt werden, finden Sie unter Trainieren eines Modells. Mögliche Werte für dieses Feld sind Train und Test. |
Train |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie verwenden diese URL, um den Status des Importauftrags abzurufen.
Mögliche Fehlerszenarios für diese Anforderung:
- Die ausgewählte Ressource verfügt nicht über die richtigen Berechtigungen für das Speicherkonto.
- Das angegebene
storageInputContainerName-Element ist nicht vorhanden. - Ein ungültiger Sprachcode wird verwendet, oder der Sprachcodetyp ist keine Zeichenfolge.
- Der Wert
multilingualist eine Zeichenfolge und kein boolescher Wert.
Abrufen des Importauftragsstatus
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Verwenden Sie die folgende GET-Anforderung, um den Status Ihres Importprojekts abzurufen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Trainieren Ihres Modells
Nachdem Sie Ihr Projekt importiert haben, haben Sie nur die Ressourcen, Metadaten und Objekte des Projekts kopiert. Sie müssen Ihr Modell weiterhin trainieren, was zu einer Nutzung bei Ihrem Konto führt.
Übermitteln des Trainingsauftrags
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Trainingsauftrag zu senden. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie den folgenden JSON-Code im Anforderungstext. Das Modell wird {MODEL-NAME} benannt, nachdem das Training abgeschlossen ist. Nur erfolgreiche Trainingsaufträge generieren Modelle.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Der Modellname, der Ihrem Modell nach dem erfolgreichen Training zugewiesen wird | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Dies ist die Modellversion, die zum Trainieren des Modells verwendet wird. | 2022-05-01 |
| evaluationOptions | Option zum Aufteilen Ihrer Daten zwischen Trainings- und Testsätzen | {} |
|
| kind | percentage |
Aufteilungsmethoden Mögliche Werte sind percentage oder manual. Weitere Informationen finden Sie unter Trainieren eines Modells. |
percentage |
| trainingSplitPercentage | 80 |
Prozentsatz der markierten Daten, die in den Trainingssatz einbezogen werden sollen. Der empfohlene Wert ist 80. |
80 |
| testingSplitPercentage | 20 |
Prozentsatz der markierten Daten, die in den Testsatz einbezogen werden sollen. Der empfohlene Wert ist 20. |
20 |
Hinweis
trainingSplitPercentage und testingSplitPercentage sind nur erforderlich, wenn Kind auf percentage festgelegt ist, und die Summe beider Prozentsätze sollte 100 ergeben.
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können diese URL zum Abrufen des Trainingsstatus verwenden.
Abrufen des Trainingsstatus
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Verwenden Sie die folgende GET-Anforderung, um den Trainingsstatus Ihres Modells abzufragen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Bereitstellen Ihres Modells
Dies ist der Schritt, in dem Sie Ihr trainiertes Modell aus dem Verbrauch über die Laufzeitvorhersage-API zur Verfügung stellen.
Tipp
Verwenden Sie denselben Bereitstellungsnamen wie für Ihr primäres Projekt, um die Wartung zu vereinfachen und nur minimale Änderungen an Ihrem System vornehmen zu müssen, damit Ihr Datenverkehr umgeleitet wird.
Übermitteln des Bereitstellungsauftrags
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Übermitteln Sie eine PUT-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Bereitstellungsauftrag zu senden. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie die folgende JSON-Datei im Textkörper Ihrer Anforderung. Verwenden Sie den Namen des Modells, das Sie der Bereitstellung zuweisen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Der Modellname, der Ihrer Bereitstellung zugewiesen wird. Sie können nur Modelle zuweisen, für die das Training erfolgreich war. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myModel |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können diese URL verwenden, um den Bereitstellungsstatus abzurufen.
Abrufen des Bereitstellungsstatus
Ersetzen Sie die Platzhalter in der folgenden Anforderung durch Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}, die Sie im ersten Schritt abgerufen haben.
Verwenden Sie die folgende GET-Anforderung, um den Status des Bereitstellungsauftrags abzurufen. Sie können die URL verwenden, die Sie im vorherigen Schritt erhalten haben, oder die Platzhalterwerte unten durch Ihre eigenen Werte ersetzen.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Diese befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt. Sie sollten einen 200-Code erhalten, der den Erfolg der Anforderung angibt.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Änderungen beim Aufrufen der Laufzeit
Überprüfen Sie in Ihrem System bei dem Schritt, in dem Sie die Laufzeitvorhersage-API aufrufen, den Antwortcode, der von der API für die Übermittlungsaufgabe zurückgegeben wurde. Wenn Sie bei der Übermittlung der Anforderung einen konsistenten Fehler feststellen, könnte dies auf einen Ausfall in Ihrer primären Region hinweisen. Ein einmaliger Fehler bedeutet keinen Ausfall, sondern kann ein vorübergehendes Problem sein. Wiederholen Sie die Übermittlung des Auftrags über die von Ihnen erstellte sekundäre Ressource. Verwenden Sie für die zweite Anforderung Ihre Werte für {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}. Wenn Sie die vorherigen Schritte befolgt haben, sind {PROJECT-NAME} und {DEPLOYMENT-NAME} identisch, sodass keine Änderungen am Anforderungstext erforderlich sind.
Falls Sie wieder Ihre sekundäre Ressource verwenden, werden Sie aufgrund des Unterschieds in den Regionen, in denen Ihr Modell bereitgestellt wird, einen geringfügigen Anstieg der Latenz feststellen.
Überprüfen, ob Ihre Projekte nicht synchron sind
Die Beibehaltung der Aktualität von beiden Projekten ist ein wichtiger Bestandteil des Prozesses. Sie müssen häufig überprüfen, ob Aktualisierungen an Ihrem primären Projekt vorgenommen wurden, damit Sie sie in Ihr sekundäres Projekt verschieben können. Wenn Ihre primäre Region ausfällt und Sie in die sekundäre Region wechseln, sollten Sie eine ähnliche Modellleistung erwarten können, da sie bereits die neuesten Updates enthält. Das Festlegen der Häufigkeit der Überprüfung, ob Ihre Projekte synchron sind, ist eine wichtige Wahl. Wir empfehlen, diese Überprüfung täglich durchzuführen, um die Aktualität der Daten in Ihrem sekundären Modell zu gewährleisten.
Abrufen von Projektdetails
Verwenden Sie die folgende URL, um Ihre Projektdetails abzurufen. Einer der Schlüssel, die im Textkörper zurückgegeben werden, gibt das Datum der letzten Änderung am Projekt an. Wiederholen Sie den folgenden Schritt zweimal: einmal für Ihr primäres Projekt und ein zweites Mal für Ihr sekundäres Projekt. Vergleichen Sie anschließend den Zeitstempel, der für beide zurückgegeben wird, um zu überprüfen, ob sie nicht synchron sind.
Verwenden Sie die folgende GET-Anforderung, um Ihre Projektdetails abzurufen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der hier referenzierte Wert gilt für die neueste veröffentlichte Version. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie unter Modelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
{
"createdDateTime": "2021-10-19T23:24:41.572Z",
"lastModifiedDateTime": "2021-10-19T23:24:41.572Z",
"lastTrainedDateTime": "2021-10-19T23:24:41.572Z",
"lastDeployedDateTime": "2021-10-19T23:24:41.572Z",
"projectKind": "CustomEntityRecognition",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project description",
"language": "{LANGUAGE-CODE}"
}
Wiederholen Sie die gleichen Schritte für Ihr repliziertes Projekt mit {SECONDARY-ENDPOINT} und {SECONDARY-RESOURCE-KEY}. Vergleichen Sie die aus beiden Projekten zurückgegebene lastModifiedDateTime. Wenn Ihr primäres Projekt früher als Ihr sekundäres Projekt geändert wurde, müssen Sie die Schritte zum Exportieren, Importieren, Trainieren und Bereitstellen wiederholen.
Nächste Schritte
In diesem Artikel haben Sie erfahren, wie Sie Ihr Projekt mithilfe der Export- und Import-APIs in eine sekundäre Sprachressource in einer anderen Region replizieren können. Sehen Sie sich als Nächstes die API-Referenzdokumentation an, um sich über weitere Möglichkeiten der Verwendung von Erstellungs-APIs zu informieren.