In diesem Artikel werden einige Strategien für die Partitionierung von Daten in verschiedenen Azure-Datenspeichern beschrieben. Allgemeine Informationen zur Verwendung der Datenpartitionierung sowie Best Practices finden Sie unter Datenpartitionierung.
Partitionieren von Azure SQL-Datenbank
Eine einzelne SQL-Datenbank kann jeweils nur eine bestimmte Datenmenge enthalten. Der Durchsatz wird durch architekturbezogene Faktoren sowie die Anzahl von gleichzeitigen Verbindungen eingeschränkt, die von der Datenbank unterstützt werden.
Pools für elastische Datenbanken unterstützen die horizontale Skalierung für eine SQL-Datenbank. Mithilfe von Pools für elastische Datenbanken können Sie Ihre Daten in Shards partitionieren, die über mehrere SQL-Datenbanken verteilt sind. Sie können Shards auch hinzufügen oder entfernen, wenn die zu verarbeitende Datenmenge wächst oder schrumpft. Pools für elastische Datenbanken können auch zur Verringerung von Konflikten beitragen, indem die Last auf mehrere Datenbanken verteilt wird.
Jedes Shard wird als SQL-Datenbank implementiert. Ein Shard kann mehrere Datasets (sogenannte Shardlets) enthalten. Jede Datenbank verwaltet Metadaten, die die darin enthaltenen Shardlets beschreiben. Ein Shardlet kann ein einzelnes Datenelement oder eine Gruppe von Elementen sein, die den gleichen Shardlet-Schlüssel verwenden. In einer mehrinstanzenfähigen Anwendung kann der Shardlet-Schlüssel beispielsweise die Mandanten-ID sein, und alle Daten für einen Mandanten können im gleichen Shardlet gespeichert werden.
Die Zuordnung von Dataset und Shardlet-Schlüssel erfolgt in Clientanwendungen. Eine separate SQL-Datenbank fungiert als globaler Shardzuordnungs-Manager. Diese Datenbank verfügt über eine Liste aller Shards und Shardlets im System. Die Anwendung stellt eine Verbindung mit der Shardzuordnungs-Manager-Datenbank her, um eine Kopie der Shardzuordnung zu erhalten. Die Shardzuordnung wird lokal zwischengespeichert und von der Anwendung verwendet, um Datenanforderungen an den entsprechenden Shard weiterzuleiten. Diese Funktion ist hinter einer Reihe von APIs aus der Clientbibliothek für elastische Datenbanken verborgen, die für Java und .NET zur Verfügung steht.
Weitere Informationen zu Pools für elastische Datenbanken finden Sie unter Horizontales Hochskalieren mit Azure SQL-Datenbank.
Sie können die globale Shardzuordnungs-Manager-Datenbank replizieren, um die Wartezeit zu verringern und die Verfügbarkeit zu verbessern. Mit den Premium-Tarifen können Sie die aktive Georeplikation konfigurieren, um kontinuierlich Daten in Datenbanken in verschiedenen Regionen zu kopieren.
Alternativ können Sie die Azure SQL-Datensynchronisierung oder Azure Data Factory verwenden, um die Shardzuordnungs-Manager-Datenbank regionsübergreifend zu replizieren. Diese Form der Replikation wird in regelmäßigen Abständen ausgeführt und eignet sich besser, wenn die Shardzuordnung unregelmäßig geändert wird. Außerdem benötigt sie keinen Premium-Tarif.
Elastische Datenbanken bieten zwei Schemas für das Zuordnen von Daten zu Shardlets und deren Speicherung in Shards:
Eine listenbasierte Shardzuordnung ordnet einen einzelnen Schlüssel einem Shardlet zu. In einem mehrinstanzenfähigen System können beispielsweise die Daten für jeden Mandanten einem eindeutigen Schlüssel zugeordnet und in einem eigenen Shardlet gespeichert werden. Zur Gewährleistung der Isolation kann jedes Shardlet innerhalb seines eigenen Shards gespeichert werden.

Laden Sie eine Visio-Datei mit dieser Architektur herunter.
Eine bereichsbasierte Shardzuordnung ordnet eine Reihe zusammenhängender Schlüsselwerte einem Shardlet zu. So können Sie beispielsweise die Daten für eine Reihe von Mandanten (die jeweils einen eigenen Schlüssel besitzen) innerhalb des gleichen Shardlets gruppieren. Dieses Schema ist kostengünstiger als das erste, da Mandanten Datenspeicher gemeinsam nutzen, dies geht jedoch zulasten der Isolation.

Laden Sie eine Visio-Datei mit diesem Diagramm herunter.
Ein einzelner Shard kann die Daten für mehrere Shardlets enthalten. Beispielsweise können Sie listenbasierte Shardlets verwenden, um Daten für verschiedene nicht zusammenhängende Mandanten im gleichen Shard zu speichern. Sie können auch bereichs- und listenbasierte Shardlets im gleichen Shard kombinieren. Für die Adressierung werden allerdings unterschiedliche Zuordnungen verwendet. Dieser Ansatz wird im folgenden Diagramm veranschaulicht:

Laden Sie eine Visio-Datei mit dieser Architektur herunter.
Pools für elastische Datenbanken ermöglichen das Hinzufügen und Entfernen von Shards, wenn sich das Datenvolumen verringert oder erhöht. Clientanwendungen können Shards dynamisch erstellen und löschen und den Shardzuordnungs-Manager transparent aktualisieren. Das Entfernen eines Shards ist jedoch ein destruktiver Vorgang, der auch das Löschen aller Daten in diesem Shard erfordert.
Wenn eine Anwendung einen Shard in zwei separate Shards aufteilen oder Shards miteinander kombinieren muss, verwenden Sie das Split-Merge-Tool. Dieses Tool wird als Azure-Webdienst ausgeführt und migriert Daten sicher zwischen Shards.
Das Partitionierungsschema kann sich erheblich auf die Leistung des Systems auswirken. Es kann sich auch darauf auswirken, wie häufig Shards hinzugefügt oder entfernt oder Daten über Shards hinweg neu partitioniert werden müssen. Beachten Sie die folgenden Punkte:
Gruppieren Sie Daten, die im gleichen Shard verwendet werden, und vermeiden Sie Vorgänge, die auf Daten aus mehreren Shards zugreifen. Ein Shard ist eine eigenständige SQL-Datenbank, und datenbankübergreifende Verknüpfungen müssen auf der Clientseite erfolgen.
SQL-Datenbank unterstützt zwar keine datenbankübergreifenden Verknüpfungen, Sie können jedoch die Tools für elastische Datenbanken verwenden, um Multishardabfragen auszuführen. Bei einer Multishardabfrage werden einzelne Abfragen an die individuellen Datenbanken gesendet und die Ergebnisse zusammengeführt.
Entwerfen Sie kein System, in dem Abhängigkeiten zwischen Shards bestehen. Einschränkungen für die referenzielle Integrität, Trigger und gespeicherte Prozeduren in einer einzelnen Datenbank dürfen nicht auf Objekte in einer anderen Datenbank verweisen.
Wenn Sie über Verweisdaten verfügen, die von Abfragen häufig verwendet werden, empfiehlt es sich unter Umständen, diese Daten shardübergreifend zu replizieren. Dadurch müssen Daten ggf. nicht datenbankübergreifend verknüpft werden. Im Idealfall sollten diese Daten statisch sein oder sich nur langsam verändern, um den Replikationsaufwand zu minimieren und eine Veraltung der Daten zu vermeiden.
Shardlets, die zur gleichen Shardzuordnung gehören, sollten das gleiche Schema besitzen. Diese Regel wird von SQL-Datenbank zwar nicht erzwungen, die Datenverwaltung und Abfragen werden jedoch sehr komplex, wenn jedes Shardlet ein anderes Schema hat. Erstellen Sie stattdessen separate Shardzuordnungen für jedes Schema. Denken Sie daran, dass Daten, die zu unterschiedlichen Shardlets gehören, im gleichen Shard gespeichert werden können.
Transaktionsvorgänge werden nur für Daten innerhalb eines Shards unterstützt, nicht über Shards hinweg. Transaktionen können sich über Shardlets erstrecken, solange sie dem gleichen Shard angehören. Wenn Ihre Geschäftslogik Transaktionen ausführen muss, sollten Sie die Daten daher in der gleichen Shard speichern oder letztendliche Konsistenz implementieren.
Platzieren Sie Shards in der Nähe der Benutzer, die auf die Daten in diesen Shards zugreifen. Diese Strategie hilft dabei, Latenzen zu reduzieren.
Vermeiden Sie eine Mischung aus sehr aktiven und relativ inaktiven Shards. Versuchen Sie, die Last gleichmäßig über Shards hinweg zu verteilen. Dies erfordert möglicherweise ein Hashing der Shardschlüssel. Stellen Sie bei der Geolokalisierung von Shards sicher, dass die Schlüssel mit Hash Shardlets zugeordnet sind, die in der Nähe der Benutzer gespeichert sind, die auf diese Daten zugreifen.
Partitionieren von Azure Table Storage
Azure Table Storage ist ein Schlüssel-Wert-Speicher, der mit Fokus auf Partitionierung konzipiert ist. Alle Entitäten werden in einer Partition gespeichert, und Partitionen werden intern von Azure Table Storage verwaltet. Jede in einer Tabelle gespeicherte Entität muss einen zweiteiligen Schlüssel bereitstellen, der Folgendes umfasst:
Partitionsschlüssel: Dieser Zeichenfolgenwert bestimmt, in welcher Partition Azure Table Storage die Entität platzieren soll. Alle Entitäten mit dem gleichen Partitionsschlüssel werden in der gleichen Partition gespeichert.
Zeilenschlüssel: Dieser Zeichenfolgewert gibt die Entität innerhalb der Partition an. Alle Entitäten innerhalb einer Partition werden durch diesen Schlüssel lexikalisch, in aufsteigender Reihenfolge sortiert. Die Kombination aus Partitions- und Zeilenschlüssel muss für jede Entität eindeutig sein und darf 1 KB Länge nicht überschreiten.
Wenn eine Entität einer Tabelle mit einem zuvor nicht verwendetem Partitionsschlüssel hinzugefügt wird, erstellt Azure Table Storage eine neue Partition für diese Entität. Andere Entitäten mit demselben Partitionsschlüssel werden in der gleichen Partition gespeichert.
Dieser Mechanismus implementiert effektiv eine Strategie für die automatische Skalierungsstrategie. Jede Partition wird auf dem gleichen Server in einem Azure-Datencenter gespeichert, um sicherzustellen, dass Abfragen, die Daten aus einer einzelnen Partition abrufen, schnell ausgeführt werden.
Microsoft hat Skalierbarkeitsziele für Azure Storage veröffentlicht. Wenn Ihr System diese Grenzwerte voraussichtlich überschreitet, empfiehlt es sich ggf., Entitäten auf mehrere Tabellen aufzuteilen. Verwenden Sie die vertikale Partitionierung, um die Felder in die Gruppen zu teilen, auf die höchstwahrscheinlich gemeinsam zugegriffen wird.
Das folgende Diagramm zeigt die logische Struktur eines Beispielspeicherkontos. Das Speicherkonto enthält drei Tabellen: eine mit Kundeninformationen, eine mit Produktinformationen und eine mit Bestellinformationen.
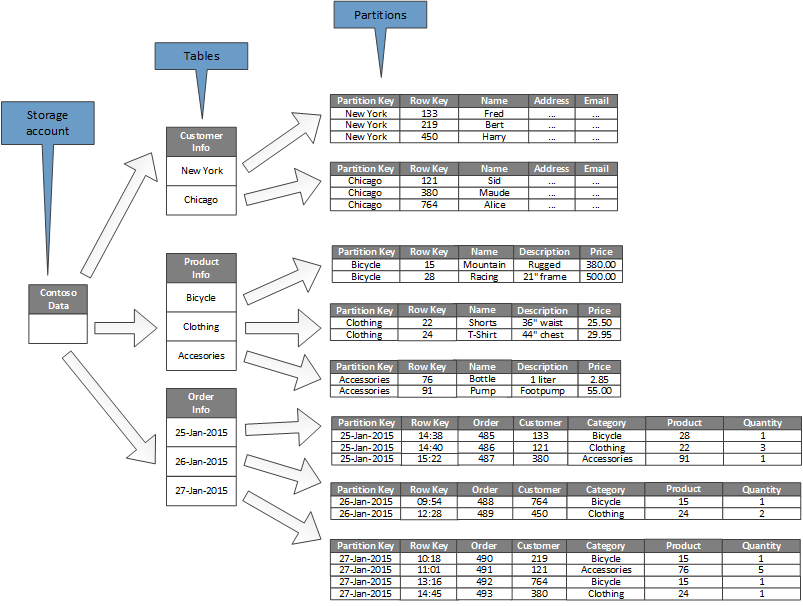
Jede Tabelle verfügt über mehrere Partitionen.
- In der Tabelle mit den Kundeninformationen sind die Daten nach der Stadt partitioniert, in der sich der Kunde befindet. Der Zeilenschlüssel enthält die Kunden-ID.
- In der Tabelle mit den Produktinformationen sind die Produkte nach Kategorie partitioniert, und der Zeilenschlüssel enthält die Produktnummer.
- In der Tabelle mit den Bestellinformationen sind die Bestellungen nach dem Bestelldatum partitioniert, und der Zeilenschlüssel gibt die Zeit an, zu der die Bestellung eingegangen ist. Alle Daten sind anhand der Zeilenschlüssel in jeder Partition sortiert.
Berücksichtigen Sie die folgenden Punkte beim Entwerfen der Entitäten für Azure Table Storage:
Berücksichtigen Sie bei der Wahl des Partitions- und Zeilenschlüssels, wie auf die Daten zugegriffen wird. Wählen Sie eine Kombination aus Partitions- und Zeilenschlüssel, die den Großteil Ihrer Abfragen unterstützt. Die effizientesten Abfragen rufen Daten durch Angeben des Partitions- und des Zeilenschlüssels ab. Abfragen, die einen Partitionsschlüssel und einen Zeilenschlüsselbereich angeben, können durch Durchsuchen einer einzigen Partition ausgeführt werden. Dies ist ein relativ schneller Vorgang, da die Daten in der Reihenfolge der Zeilenschlüssel gespeichert sind. Bei Abfragen ohne Angabe der zu überprüfenden Partition muss jede Partition überprüft werden.
Wenn eine Entität einen natürlichen Schlüssel hat, dann verwenden Sie diesen als Partitionsschlüssel und geben Sie eine leere Zeichenfolge als Zeilenschlüssel an. Wenn eine Entität über einen zusammengesetzten Schlüssel aus zwei Eigenschaften verfügt, verwenden Sie die Eigenschaft, die sich am langsamsten ändert, als Partitionsschlüssel und die andere als Zeilenschlüssel. Wenn eine Entität über mehr als zwei Schlüsseleigenschaften verfügt, verwenden Sie eine Verkettung der Eigenschaften, um die Partitions- und Zeilenschlüssel bereitzustellen.
Wenn Sie regelmäßig Abfragen ausführen, die Daten nicht anhand von Partitions- und Zeilenschlüssel, sondern unter Verwendung anderer Felder suchen, sollten Sie das Indextabellenmuster implementieren oder einen anderen Datenspeicher mit Indizierungsunterstützung verwenden (beispielsweise Azure Cosmos DB).
Wenn Sie Partitionsschlüssel mit einer monotonen Sequenz generieren (etwa „0001“, „0002“, „0003“) und jede Partition nur eine begrenzte Datenmenge enthält, kann Azure Table Storage diese Partitionen physisch auf dem gleichen Server gruppieren. Azure Storage geht davon aus, dass die Anwendung am ehesten Abfragen für einen zusammenhängenden Bereich von Partitionen (Bereichsabfragen) ausführt, und ist für diesen Fall optimiert. Dieser Ansatz kann jedoch zu Hotspots führen, da sich alle neu eingefügten Entitäten wahrscheinlich an einem Ende des zusammenhängenden Bereichs konzentrieren. Er kann auch die Skalierbarkeit verringern. Eine gleichmäßigere Lastenverteilung lässt sich ggf. mittels Hashing des Partitionsschlüssels erreichen.
Azure Table Storage unterstützt Transaktionsvorgänge für Entitäten, die zur selben Partition gehören. Eine Anwendung kann mehrere Einfüge-, Aktualisierungs-, Lösch-, Ersetzungs- oder Zusammenführungsvorgänge als atomische Einheit ausführen, sofern die Transaktion nicht mehr als 100 Entitäten umfasst und die Nutzlast der Anforderung 4 MB nicht übersteigt. Vorgänge, die sich über mehrere Partitionen erstrecken, sind nicht transaktional und erfordern möglicherweise die Implementierung von letztlicher Konsistenz. Weitere Informationen zu Tabellenspeicher und Transaktionen finden Sie unter Ausführen von Entitätsgruppentransaktionen.
Berücksichtigen Sie die Granularität des Partitionsschlüssels:
Die Verwendung des gleichen Partitionsschlüssels für jede Entität führt zu einer einzelnen Partition auf einem einzelnen Server. Dies verhindert das horizontale Hochskalieren der Partition und konzentriert die Last auf einen einzelnen Server. Folglich eignet sich dieser Ansatz nur zur Speicherung einer geringen Anzahl von Entitäten. Andererseits können bei diesem Ansatz alle Entitäten in Entitätsgruppentransaktionen einbezogen werden.
Die Verwendung eines eindeutigen Partitionsschlüssels für jede Entität führt dazu, dass der Tabellenspeicherdienst eine separate Partition für jede Entität erstellt, was möglicherweise zu einer großen Anzahl von kleinen Partitionen führt. Dieser Ansatz bietet mehr Skalierbarkeit als ein einzelner Partitionsschlüssel, Gruppentransaktionen für Entitäten sind jedoch nicht möglich. Auch erfordern Abfragen, die mehr als eine Entität abrufen, möglicherweise Lesevorgänge auf mehr als einem Server. Wenn die Anwendung jedoch Bereichsabfragen ausführt, kann die Verwendung einer monotonen Sequenz für die Partitionsschlüssel zur Optimierung dieser Abfragen beitragen.
Die gemeinsame Verwendung eines einzelnen Partitionsschlüssels innerhalb einer Teilmenge von Entitäten ermöglicht es, verwandte Entitäten in der gleichen Partition zu gruppieren. Vorgänge mit verknüpften Entitäten lassen sich mithilfe von Gruppentransaktionen für Entitäten durchführen, und Abfragen, die einen Satz verknüpfter Entitäten abrufen, können durch Zugriff auf einen einzigen Server durchgeführt werden.
Weitere Informationen finden Sie unter Azure Storage-Tabelle – Entwurfshandbuch und Strategie für die skalierbare Partitionierung.
Partitionieren von Azure Blob Storage
Azure Blob Storage ermöglicht die Speicherung großer binärer Objekte. Verwenden Sie Blockblobs in Szenarien, in denen Sie schnell große Datenmengen hoch- oder herunterladen müssen. Verwenden Sie Seitenblobs für Anwendungen, die eher zufälligen als seriellen Zugriff auf Teile der Daten erfordern.
Jedes Blob (Block oder Seite), wird in einem Container in einem Azure Storage-Konto aufrechterhalten. Sie können Container verwenden, um verwandte Blobs zu gruppieren, für die die gleichen Sicherheitsanforderungen gelten. Diese Gruppierung ist nicht physischer, sondern logischer Art. In einem Container hat jedes Blob einen eindeutigen Namen.
Der Partitionsschlüssel für ein Blob setzt sich aus dem Kontonamen, Containernamen und Blobnamen zusammen. Der Partitionsschlüssel wird zur Partitionierung von Daten in Bereiche verwendet, und diese Bereiche werden im Lastausgleich über das System verteilt. Blobs können über mehrere Server verteilt werden, um den Zugriff darauf aufzuskalieren, aber ein einzelnes Blob kann nur von einem einzelnen Server bedient werden.
Wenn Ihr Benennungsschema Zeitstempel oder numerische Bezeichner umfasst, kann dies zu übermäßigem Datenverkehr für eine Partition führen und einen effektiven Lastenausgleich verhindern. Wenn Sie beispielsweise über täglich ausgeführte Vorgänge verfügen, die ein Blobobjekt mit einem Zeitstempel (etwa JJJJ-MM-TT) verwenden, wird der gesamte Datenverkehr für diesen Vorgang an einen einzelnen Partitionsserver gesendet. Es empfiehlt sich daher unter Umständen, den Namen mit einem dreistelligen Hashpräfix zu versehen. Weitere Informationen finden Sie unter Partitionsbenennungskonvention.
Die Aktionen zum Schreiben eines einzelnen Blocks oder einer einzelnen Seite sind atomar. Vorgänge, die mehrere Blöcke, Seiten oder Blobs umfassen, dagegen nicht. Wenn Sie bei der Ausführung von Schreibvorgängen Konsistenz zwischen Blöcken, Seiten und Blobs gewährleisten müssen, richten Sie mithilfe einer Bloblease eine Schreibsperre ein.
Partitionierung von Azure Storage-Warteschlangen
Azure Storage-Warteschlangen ermöglichen Ihnen asynchrones Messaging zwischen Prozessen. Ein Azure Storage-Konto kann eine beliebige Anzahl an Warteschlangen enthalten und jede Warteschlange kann eine beliebige Anzahl an Nachrichten enthalten. Die einzige Beschränkung ist der im Speicherkonto verfügbare Platz. Die maximale Größe einer einzelnen Nachricht beträgt 64 KB. Falls Sie größere Nachrichten erfordern, dann sollten Sie in Betracht ziehen, stattdessen Azure Service Bus-Warteschlangen zu verwenden.
Jede Speicherwarteschlange verfügt über einen eindeutigen Namen innerhalb des Speicherkontos, in dem sie enthalten ist. Azure partitioniert Warteschlangen basierend auf dem Namen. Alle Nachrichten für dieselbe Warteschlange werden in derselben Partition gespeichert, die von einem einzigen Server kontrolliert wird. Verschiedene Warteschlangen können von verschiedenen Servern verwaltet werden, um beim Lastausgleich zu helfen. Die Zuordnung der Warteschlangen zu Servern ist für Anwendungen und Benutzer transparent.
Verwenden Sie in einer umfangreichen Anwendung nicht die gleiche Speicherwarteschlange für alle Instanzen der Anwendung, da bei diesem Ansatz der Server, der die Warteschlange hostet, zum Hotspot werden kann. Verwenden Sie stattdessen verschiedene Warteschlangen für verschiedene Funktionsbereiche der Anwendung. Azure Storage-Warteschlangen unterstützen keine Transaktionen. Das Weiterleiten von Nachrichten an verschiedene Warteschlangen sollte daher nur geringe Auswirkungen auf die Messagingkonsistenz haben.
Eine Azure Storage-Warteschlange kann bis zu 2.000 Nachrichten pro Sekunde verarbeiten. Wenn Sie Nachrichten schneller verarbeiten müssen, sollten Sie das Erstellen mehrerer Warteschlangen in Betracht ziehen. Erstellen Sie z. B. in einer globalen Anwendung separate Speicherwarteschlangen in separaten Speicherkonten, um Anwendungsinstanzen zu verarbeiten, die in jeder Region ausgeführt werden.
Partitionieren von Azure Service Bus
Azure Service Bus verwendet einen Nachrichtenbroker, um Nachrichten zu verarbeiten, die an eine Service Bus-Warteschlange oder ein Topic gesendet wurden. Standardmäßig werden alle an eine Warteschlange oder ein Topic gesendeten Nachrichten vom gleichen Nachrichtenbrokerprozess verarbeitet. Diese Architektur kann den Gesamtdurchsatz der Nachrichten-Warteschlange eingrenzen. Sie können eine Warteschlange oder ein Topic jedoch auch während der Erstellung partitionieren. Legen Sie dazu die EnablePartitioning-Eigenschaft der Warteschlange oder des Themas true fest.
Eine partitionierte Warteschlange oder ein partitioniertes Topic ist in mehrere Fragmente unterteilt, von denen jedes durch einen separaten Nachrichtenspeicher und Nachrichtenbroker gesichert ist. Service Bus übernimmt die Verantwortung zum Erstellen und Verwalten dieser Fragmente. Wenn eine Anwendung eine Nachricht an eine partitionierte Warteschlange oder ein partitioniertes Thema postet, ordnet Service Bus die Nachricht einem Fragment für diese Warteschlange oder dieses Thema zu. Wenn eine Anwendung eine Nachricht von einer Warteschlange oder einem Abonnement empfängt, überprüft Service Bus jedes Fragment auf die nächste verfügbare Nachricht und leitet diese dann an die Anwendung zur Verarbeitung weiter.
Mit dieser Struktur kann die Last auf die Nachrichtenbroker und Nachrichtenspeicher verteilt werden, um die Skalierbarkeit und Verfügbarkeit zu verbessern. Wenn der Nachrichtenbroker oder der Nachrichtenspeicher für ein Fragment vorübergehend nicht verfügbar ist, kann Service Bus Nachrichten aus einem der anderen verfügbaren Fragmente abrufen.
Service Bus ordnet jeder Nachricht folgendermaßen ein Fragment zu:
Wenn die Nachricht zu einer Sitzung gehört, werden alle Nachrichten mit dem gleichen Wert für die Eigenschaft SessionId an das gleiche Fragment gesendet.
Wenn die Nachricht nicht zu einer Sitzung gehört, aber der Absender einen Wert für die PartitionKey-Eigenschaft angegeben hat, werden alle Nachrichten mit demselben PartitionKey-Wert an dasselbe Fragment gesendet.
Hinweis
Wenn die Eigenschaften SessionId und PartitionKey angegeben werden, müssen sie auf denselben Wert festgelegt werden. Andernfalls wird die Nachricht abgelehnt.
Wenn die Eigenschaften SessionID und PartitionKey für eine Nachricht nicht angegeben sind, aber Duplikaterkennung aktiviert ist, wird die MessageID-Eigenschaft verwendet. Alle Nachrichten mit derselben MessageID werden an dasselbe Fragment geleitet.
Wenn Nachrichten keine SessionId-, PartitionKey- oder MessageId-Eigenschaft enthalten, ordnet Service Bus die Nachrichten den Fragmenten sequenziell zu. Wenn ein Fragment nicht verfügbar ist, geht Service Bus zum nächsten über. Dies bedeutet, dass ein vorübergehender Fehler in der Nachrichteninfrastruktur nicht dazu führt, dass der Nachrichtensendevorgang nicht ausgeführt werden kann.
Beachten Sie die folgende Punkte, wenn Sie entscheiden, ob und wie Sie eine Service Bus-Nachrichtenwarteschlange oder ein Service Bus-Topic partitionieren:
Service Bus-Warteschlangen und -Themen werden im Umfang des Service Bus-Namespace erstellt. Service Bus erlaubt derzeit bis zu 100 partitionierte Warteschlangen oder Themen pro Namespace.
Jeder Service Bus-Namespace setzt Kontingente für die verfügbaren Ressourcen fest, wie z. B. die Anzahl der Abonnements pro Topic, die Anzahl gleichzeitiger Sende- und Empfangsanforderungen und die maximale Anzahl gleichzeitiger Verbindungen, die aufgebaut werden können. Diese Kontingente sind unter Service Bus-Kontingente dokumentiert. Wenn Sie diese Werte überschreiten möchten, dann erstellen Sie zusätzliche Namespaces mit ihren eigenen Warteschlangen und Themen und verteilen Sie die Arbeit auf diese Namespaces. Erstellen Sie z. B. in einer globalen Anwendung separate Namespaces in jeder Region und konfigurieren Sie die Anwendungsinstanzen so, dass sie die Warteschlangen und Themen in nächstliegendem Namespace verwenden.
Nachrichten, die als Teil einer Transaktion gesendet werden, müssen einen Partitionsschlüssel angeben. Dies kann eine SessionId-, PartitionKey- oder MessageId-Eigenschaft sein. Alle Nachrichten, die als Teil derselben Transaktion gesendet werden, müssen denselben Partitionsschlüssel angeben, da sie vom selben Nachrichtenbroker-Prozess verarbeitet werden müssen. Sie können keine Nachrichten an verschiedene Warteschlangen oder Themen innerhalb der gleichen Transaktion senden.
Partitionierte Warteschlangen und Topics können nicht so konfiguriert werden, dass sie im Leerlauf automatisch gelöscht werden.
Partitionierte Warteschlangen und Topics können zurzeit nicht mit dem Advanced Message Queuing Protocol (AMQP) verwendet werden, wenn Sie plattformübergreifende oder hybride Lösungen erstellen.
Partitionieren in Azure Cosmos DB
Azure Cosmos DB for NoSQL ist eine NoSQL-Datenbank zum Speichern von JSON-Dokumenten. Ein Dokument in einer Azure Cosmos DB-Datenbank ist eine JSON-serialisierte Darstellung eines Objekts oder sonstigen Datensegments. Es werden keine festgelegten Schemen erzwungen, außer dass jedes Dokument über eine eindeutige ID verfügen muss.
Dokumente werden in Auflistungen organisiert. In einer Sammlung können Sie verwandte Dokumente gruppieren. Beispielsweise könnten Sie in einem System, das Blogbeiträge verwaltet, den Inhalt jedes Blogbeitrags als Dokument in einer Sammlung speichern. Sie können auch Sammlungen für jeden Thementyp erstellen. Alternativ dazu könnten Sie in einer mehrinstanzenfähigen Anwendung, wie beispielsweise einem System, in dem verschiedene Autoren ihre eigenen Blogbeiträge kontrollieren und verwalten können, Blogs nach Autor partitionieren und für jeden Autor eine separate Sammlung erstellen. Der Speicherplatz, der Sammlungen zugeordnet ist, ist elastisch und kann je nach Bedarf schrumpfen oder wachsen.
Azure Cosmos DB unterstützt die automatische Partitionierung von Daten basierend auf einem anwendungsdefinierten Partitionsschlüssel. Eine logische Partition ist eine Partition, die alle Daten für einen einzelnen Partitionsschlüsselwert speichert. Alle Dokumente, die den gleichen Wert für den Partitionsschlüssel besitzen, werden in der gleichen logischen Partition platziert. Azure Cosmos DB verteilt Werte anhand des Hashes des Partitionsschlüssels. Eine logische Partition hat eine maximale Größe von 20 GB. Daher ist die Auswahl des Partitionsschlüssels eine wichtige Entscheidung, die zur Entwurfszeit getroffen wird. Wählen Sie eine Eigenschaft mit einer Vielzahl von Werten und gleichmäßigen Zugriffsmustern. Weitere Informationen finden Sie unter Partitionieren und Skalieren in Azure Cosmos DB.
Hinweis
Jede Azure Cosmos DB-Datenbank weist eine bestimmte Leistungsebene auf, mit der der Umfang der Ressourcen festgelegt wird, die von der Datenbank genutzt werden können. Jeder Leistungsstufe ist eine Ratenbegrenzung für Anforderungseinheiten (Request Unit, RU) zugeordnet. Die RU-Ratenbegrenzung gibt die Menge der Ressourcen an, die für diese Sammlung reserviert sind und für die ausschließliche Verwendung durch diese Sammlung zur Verfügung stehen. Die Kosten einer Sammlung richten sich nach der Leistungsstufe, die für diese Sammlung gewählt wurde. Je höher die Leistungsstufe (und die RU-Ratenbegrenzung), desto höher die Kosten. Sie können die Leistungsstufe einer Sammlung über das Azure-Portal anpassen. Weitere Informationen finden Sie unter Anforderungseinheiten in Azure Cosmos DB.
Falls der Partitionierungsmechanismus von Azure Cosmos DB nicht ausreicht, müssen die Daten unter Umständen auf der Anwendungsebene horizontal partitioniert werden (Sharding). Dokumentsammlungen bieten einen natürlichen Mechanismus zum Partitionieren von Daten innerhalb einer Einzeldatenbank. Der einfachste Weg Sharding zu implementieren, ist für jedes Shard eine Auflistung zu erstellen. Container sind logische Ressourcen und können einen oder mehrere Server umfassen. Container mit fester Größe weisen eine Obergrenze von 20 GB und einen Durchsatz von 10.000 RUs/Sek. (Request Units, Anforderungseinheiten) auf. Für unbegrenzte Container gilt keine maximale Speichergröße, sie müssen aber einen Partitionsschlüssel angeben. Bei Anwendungs-Sharding muss die Clientanwendung Anforderungen an den geeigneten Shard leiten. Für gewöhnlich erfolgt dies durch Implementieren ihres eigenen Zuordnungsmechanismus, basierend auf einigen Attributen der Daten, die den Shardschlüssel definieren.
Alle Datenbanken werden im Kontext eines Azure Cosmos DB-Datenbankkontos erstellt. Ein einzelnes Konto kann mehrere Datenbanken enthalten und gibt an, in welcher Region die Datenbanken erstellt werden. Jedes Konto erzwingt auch seine eigene Zugriffssteuerung. Sie können Azure Cosmos DB-Konten verwenden, um Shards (Sammlungen in Datenbanken) geografisch in der Nähe der Benutzer zu platzieren, die darauf zugreifen müssen, und Einschränkungen erzwingen, sodass nur diese Benutzer eine Verbindung damit herstellen können.
Berücksichtigen Sie folgende Punkte bei der Entscheidung, wie Daten mit Azure Cosmos DB for NoSQL partitioniert werden sollen:
Die für eine Azure Cosmos DB-Datenbank verfügbaren Ressourcen unterliegen den Kontingentgrenzen für das Konto. Jede Datenbank kann eine Reihe von Sammlungen enthalten, und jeder Sammlung ist eine Leistungsebene zugeordnet, die die RU-Ratenbegrenzung (reservierter Durchsatz) für diese Sammlung regelt. Weitere Informationen finden Sie unter Grenzwerte für Azure-Abonnements, -Dienste und -Kontingente sowie allgemeine Beschränkungen.
Jedes Dokument muss über ein Attribut verfügen, das verwendet werden kann, um das Dokument in der Sammlung, in der es enthalten ist, eindeutig zu identifizieren. Dieses Attribut unterscheidet sich vom Shardschlüssel, der die Sammlung definiert, in der das Dokument enthalten ist. Eine Sammlung kann eine große Anzahl von Dokumenten enthalten. Theoretisch besteht die einzige Einschränkung in der maximalen Länge der Dokument-ID. Die Dokument-ID kann bis zu 255 Zeichen lang sein.
Alle Vorgänge für ein Dokument werden im Kontext einer Transaktion ausgeführt. Transaktionen sind auf die Sammlung begrenzt, in der das Dokument enthalten ist. Wenn ein Vorgang fehlschlägt, wird die Arbeit, die durch ihn ausgeführt wurde, zurückgesetzt. Während ein Vorgang für ein Dokument ausgeführt wird, unterliegen alle vorgenommenen Änderungen einer Isolierung auf Snapshotebene. Wenn z. B. eine Anforderung zum Erstellen eines neuen Dokuments fehlschlägt, stellt dieser Mechanismus sicher, dass einem anderen Benutzer, der die Datenbank gleichzeitig abfragt, kein Teildokument angezeigt wird, das dann entfernt wird.
Datenbankabfragen sind ebenfalls auf die Sammlungsebene begrenzt. Eine einzelne Abfrage kann nur Daten aus einer Sammlung abrufen. Wenn Sie Daten aus mehreren Sammlungen abrufen müssen, müssen Sie jede Sammlung einzeln abfragen und die Ergebnisse in Ihrem Anwendungscode zusammenführen.
Azure Cosmos DB-Datenbanken unterstützen programmierbare Elemente, die alle zusammen mit Dokumenten in einer Sammlung gespeichert werden können. Hierzu gehören gespeicherte Prozeduren, benutzerdefinierte Funktionen und Trigger (geschrieben in JavaScript). Diese Elemente können auf alle Dokumente in der gleichen Auflistung zugreifen. Außerdem werden diese Elemente entweder im Rahmen der Ambient-Transaktion ausgeführt (im Fall eines Triggers, der als Ergebnis eines für ein Dokument ausgeführten Erstellungs-, Lösch- oder Ersetzungsvorgangs ausgelöst wird) oder durch Starten einer neuen Transaktion (im Fall einer gespeicherten Prozedur, die als Ergebnis einer expliziten Clientanforderung ausgeführt wird). Wenn der Code in einem programmierbaren Element eine Ausnahme auslöst, wird für die Transaktion ein Rollback ausgeführt. Sie können gespeicherte Prozeduren und Trigger verwenden, um die Integrität und Konsistenz zwischen den Dokumenten zu verwalten, aber diese Dokumente müssen alle derselben Auflistung angehören.
Die Sammlungen, die Sie in den Datenbanken speichern möchten, sollten die von den Leistungsstufen der Sammlungen definierten Durchsatzgrenzen nicht überschreiten. Weitere Informationen finden Sie unter Anforderungseinheiten in Azure Cosmos DB. Wenn diese Grenzwerte bei Ihnen voraussichtlich erreicht werden, sollten Sie erwägen, die Sammlungen auf Datenbanken in verschiedenen Konten zu verteilen, um die Last pro Sammlung zu verringern.
Partitionieren von Azure Search
Die Fähigkeit, nach Daten zu suchen, ist häufig die primäre Navigations- und Untersuchungsmethode, die von vielen Webanwendungen bereitgestellt wird. Damit können Benutzer Ressourcen anhand einer Kombination verschiedener Suchkriterien schnell finden (beispielsweise Produkte in einer E-Commerce-Anwendung). Azure Search bietet Volltext-Suchfunktionen über Web-Inhalte und umfasst Funktionen wie z. B. Type-ahead, vorgeschlagene Abfragen basierend auf Übereinstimmungen und Facettennavigation. Weitere Informationen finden Sie unter Was ist Azure Search?.
Azure Search speichert durchsuchbare Inhalte in Form von JSON-Dokumenten in einer Datenbank. Sie definieren Indizes, um die durchsuchbaren Felder in diesen Dokumenten anzugeben, und stellen diese Definitionen Azure Search zur Verfügung. Wenn ein Benutzer eine Suchanforderung sendet, verwendet Azure Search die entsprechenden Indizes, um übereinstimmende Elemente zu finden.
Um Konflikte zu reduzieren, kann der von Azure Search verwendete Speicher in 1, 2, 3, 4, 6 oder 12 Partitionen unterteilt werden, von denen jede bis zu 6-mal repliziert werden kann. Das Produkt der Multiplikation aus Anzahl von Partitionen und Anzahl von Replikaten wird Sucheinheit (Search Unit, SU) genannt. Eine einzelne Instanz von Azure Search kann maximal 36 SUs enthalten (eine Datenbank mit 12 Partitionen unterstützt nur maximal 3 Replikate).
Jede SU, die Ihrem Dienst zugeordnet wird, wird Ihnen berechnet. Wenn die Menge an durchsuchbaren Inhalten oder die Rate der Suchanforderungen wächst, können Sie einer vorhandenen Azure Search-Instanz SUs hinzufügen, um die zusätzliche Last zu verarbeiten. Azure Search selbst verteilt die Dokumente gleichmäßig über die Partitionen. Zurzeit werden keine manuellen Partitionierungsstrategien unterstützt.
Jede Partition kann maximal 15 Millionen Dokumente enthalten oder 300 GB Speicherplatz belegen (je nachdem, welche Menge geringer ist). Sie können bis zu 50 Indizes generieren. Die Leistung des Diensts variiert und ist abhängig von der Komplexität der Dokumente, den verfügbaren Indizes und den Auswirkungen von Netzwerklatenz. Im Durchschnitt sollte ein einzelnes Replikat (1 SU) 15 Abfragen pro Sekunde (Queries Per Second, QPS) verarbeiten können. Es empfiehlt sich allerdings, ein Benchmarking mit Ihren eigenen Daten durchzuführen, um ein genaueres Maß für den Durchsatz zu erhalten. Weitere Informationen finden Sie unter Grenzwerte für den Azure Search-Dienst.
Hinweis
Sie können eine begrenzte Anzahl von Datentypen in durchsuchbaren Dokumenten speichern, z. B. Zeichenfolgen, boolesche Werte, numerische Daten, Datums-/Uhrzeitdaten und einige geografische Daten. Weitere Informationen finden Sie auf der Microsoft-Website im Artikel Unterstützte Datentypen (Azure Search).
Sie können die Art und Weise, in der Azure Search Daten für jede Instanz des Diensts partitioniert, nur in begrenztem Umfang steuern. In einer globalen Umgebung können Sie jedoch möglicherweise die Leistung verbessern sowie Latenz und Konflikte verringern, indem Sie den Dienst selbst mithilfe einer der folgenden Strategien partitionieren:
Erstellen Sie eine Instanz von Azure Search in jeder geografischen Region, und stellen Sie sicher, dass Clientanwendungen an die nächste verfügbare Instanz geleitet werden. Diese Strategie erfordert, dass alle Aktualisierungen von durchsuchbarem Inhalt für alle Instanzen des Dienstes rechtzeitig repliziert werden.
Erstellen Sie zwei Ebenen von Azure Search:
- Einen lokalen Dienst in jeder Region, der die Daten enthält, auf die Benutzer in dieser Region am häufigsten zugreifen. Benutzer können auf dieser Ebene suchen, um schnelle, aber eingeschränkte Ergebnisse zu erhalten.
- Einen globalen Dienst, der alle Daten enthält. Benutzer können auf dieser Ebene suchen, um langsamere, aber vollständigere Ergebnisse zu erhalten.
Dieser Ansatz ist besonders geeignet, wenn erhebliche regionale Unterschiede in Bezug auf die gesuchten Daten vorhanden sind.
Partitionieren von Azure Cache for Redis
Azure Cache for Redis bietet einen Shared Caching Service in der Cloud, der auf dem Redis-Schlüssel-Wert-Datenspeicher basiert. Wie der Name schon sagt, ist Azure Cache for Redis als Cachinglösung konzipiert. Verwenden Sie den Cache nur zur vorübergehenden Speicherung, nicht als permanenten Datenspeicher. Anwendungen, die Azure Cache for Redis verwenden, sollten weiterhin funktionieren, auch wenn der Cache nicht verfügbar ist. Azure Cache for Redis unterstützt die primäre/sekundäre Replikation zur Gewährleistung von Hochverfügbarkeit, derzeit ist die maximale Cachegröße jedoch auf 53 GB beschränkt. Wenn mehr Speicherplatz benötigt wird, müssen Sie zusätzliche Caches erstellen. Weitere Informationen finden Sie unter Azure Cache for Redis.
Die Partitionierung eines Redis-Datenspeichers umfasst das Aufteilen von Daten über Instanzen des Redis-Diensts hinweg. Jede Instanz stellt eine einzelne Partition dar. Azure Cache for Redis abstrahiert die Redis-Dienste hinter einer Fassade und macht sie nicht direkt verfügbar. Die einfachste Methode zum Implementieren der Partitionierung ist es, mehrere Azure Cache for Redis-Instanzen zu erstellen und die Daten auf diese Instanzen zu verteilen.
Sie können jedem Datenelement einen Bezeichner (Partitionsschlüssel) zuordnen, der angibt, in welchem Cache es gespeichert ist. Die Logik der Clientanwendung kann diesen Bezeichner dann zum Weiterleiten von Anforderungen an die entsprechende Partition verwenden. Dieses Schema ist sehr einfach, aber wenn sich das Partitionierungsschema ändert (z. B. durch Erstellen zusätzlicher Azure Cache for Redis-Instanzen), müssen Clientanwendungen möglicherweise neu konfiguriert werden.
Natives Redis (nicht Azure Cache for Redis) unterstützt die serverseitige Partitionierung basierend auf Redis-Clustering. Bei diesem Ansatz können Sie die Daten mit einem Hashmechanismus gleichmäßig auf die Server verteilen. Jeder Redis-Server speichert Metadaten, die den Bereich der Hash-Schlüssel beschreiben, die die Partition enthält, und enthält außerdem Informationen dazu, welche Hash-Schlüssel sich in den Partitionen auf anderen Servern befinden.
Clientanwendungen senden Anforderungen einfach an einen der teilnehmenden Redis-Server (wahrscheinlich an den nächstgelegenen). Der Redis-Server überprüft die Clientanforderung. Wenn die Anforderung lokal aufgelöst werden kann, führt der Redis-Server den angeforderten Vorgang aus. Andernfalls leitet er die Anforderung an den geeigneten Server weiter.
Dieses Modell wird mithilfe von Redis-Clustering implementiert und wird ausführlicher im Redis-Cluster-Lernprogramm auf der Redis-Website beschrieben. Redis-Clustering ist für Clientanwendungen transparent. Dem Cluster können zusätzliche Redis-Server hinzugefügt (und die Daten neu partitioniert) werden, ohne dass die Clients neu konfiguriert werden müssen.
Wichtig
Azure Cache for Redis unterstützt das Redis-Clustering derzeit nur im Tarif Premium.
Weitere Informationen zur Implementierung der Partitionierung mit Redis finden Sie auf der Redis-Website unter Partitioning: how to split data among multiple Redis instances (Partitionierung: Aufteilen von Daten auf mehrere Redis-Instanzen). Im restlichen Abschnitt wird davon ausgegangen, dass Sie clientseitige oder Proxy-unterstützte Partitionierung implementieren.
Berücksichtigen Sie folgende Punkte bei der Entscheidung, wie Daten mit Azure Cache for Redis partitioniert werden sollen:
Azure Cache for Redis ist nicht als dauerhafter Datenspeicher gedacht, d. h., unabhängig vom Partitionierungsschema, das Sie implementieren, muss Ihr Anwendungscode Daten von anderen Speicherorten als dem Cache abrufen können.
Daten, auf die häufig zugegriffen wird, sollten in derselben Partition gespeichert werden. Redis ist ein leistungsfähiger Schlüssel-Wert-Speicher, der mehrere in hohem Maß optimierte Mechanismen zum Strukturieren von Daten bereitstellt. Bei diesen Mechanismen kann es sich um folgende handeln:
- Einfache Zeichenfolgen (binäre Daten mit einer Länge von bis zu 512 MB)
- Aggregierte Datentypen wie beispielsweise Listen (die als Warteschlangen und Stapel fungieren können)
- Sätze (sortiert und nicht sortiert)
- Hashes (die verwandte Felder gruppieren können, wie z. B. die Elemente, die die Felder in einem Objekt repräsentieren)
Mithilfe der aggregierten Datentypen können Sie viele ähnliche Werte mit dem gleichen Schlüssel verknüpfen. Ein Redis-Schlüssel identifiziert eine Liste, einen Satz oder einen Hash anstatt der darin enthaltenen Datenelemente. Alle diese Datentypen sind mit Azure Cache for Redis verfügbar und werden auf der Redis-Website unter Datentypen beschrieben. Beispielsweise können in dem Teil eines E-Commerce-Systems, in dem die Bestellungen von Kunden verfolgt werden, die Details der einzelnen Kunden in einem Redis-Hash gespeichert werden, der mithilfe der Kunden-ID verschlüsselt wurde. Jeder Hash kann eine Sammlung von Bestellnummern für den jeweiligen Kunden enthalten. Ein separater Redis-Satz kann die Bestellungen enthalten, die wieder als Hashes strukturiert sind und mithilfe der Bestellnummer verschlüsselt wurden. Abbildung 8 zeigt eine solche Struktur. Beachten Sie, dass Redis keine Form der referenziellen Integrität implementiert, daher ist es die Verantwortung des Entwicklers, die Beziehungen zwischen Kunden und Bestellungen zu verwalten.
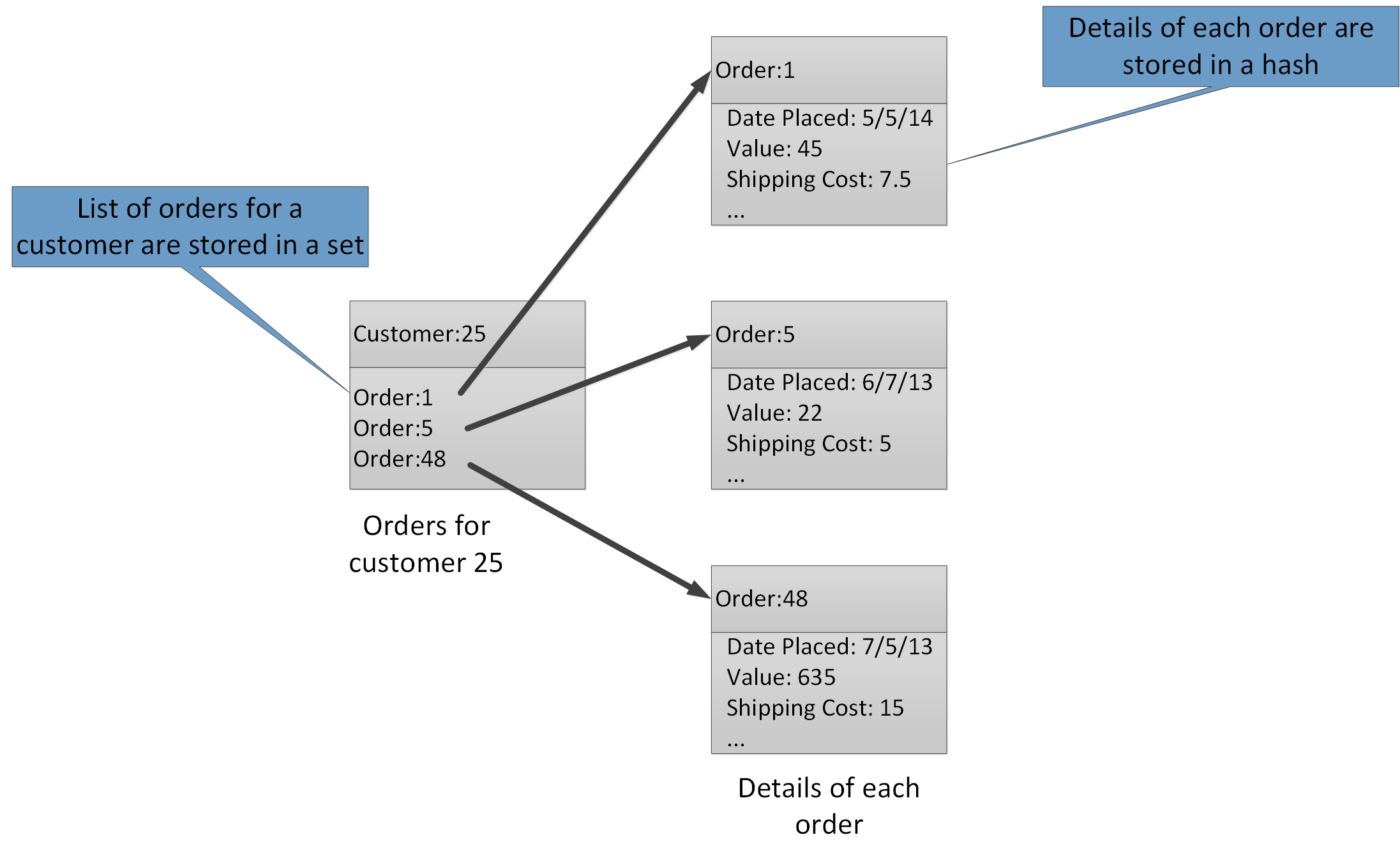
Abbildung 8. Vorgeschlagene Struktur im Redis-Speicher zur Erfassung von Kundenbestellungen und -informationen.
Hinweis
In Redis sind alle Schlüssel binäre Datenwerte (wie Redis-Zeichenfolgen) und können bis zu 512 MB Daten enthalten. Theoretisch kann ein Schlüssel nahezu jegliche Informationen enthalten. Es empfiehlt sich jedoch, eine konsistente Benennungskonvention für Schlüssel anzuwenden, die den Datentyp beschreibt und die Entität identifiziert, aber nicht übermäßig lang ist. Eine gängige Methode ist die Verwendung von Schlüsseln im Format „Entitätstyp:ID“. Beispielsweise können Sie „Kunde:99“ verwenden, um den Schlüssel für einen Kunden mit der ID 99 anzugeben.
Sie können die vertikale Partitionierung durch das Speichern von verwandten Informationen in anderen Aggregationen in derselben Datenbank implementieren. Sie können z. B. in einer E-Commerce-Anwendung häufig abgerufene Informationen zu Produkten in einem Redis-Hash speichern und weniger häufig verwendete Detailinformationen in einem anderen. Beide Hashes können die gleiche Produkt-ID als Teil des Schlüssels verwenden. Sie können z. B. „Produkt: nn“ für die allgemeinen Produktinformationen (wobei nn die Produkt-ID ist) und „Produktdetails: nn“ für die Detailinformationen verwenden. Mit dieser Strategie lässt sich die Datenmenge reduzieren, die bei den meisten Abfragen wahrscheinlich abgerufen werden.
Sie können einen Redis-Datenspeicher neu partitionieren, denken Sie jedoch daran, dass dies eine komplexe und zeitaufwendige Aufgabe ist. Redis-Clustering kann Daten automatisch neu partitionieren, diese Funktion ist allerdings in Azure Cache for Redis nicht verfügbar. Daher sollten Sie beim Entwerfen Ihres Partitionierungsschemas für ausreichend freien Speicherplatz in jeder Partition sorgen, um den langfristig zu erwartenden Datenzuwachs zu ermöglichen. Denken Sie jedoch daran, dass Azure Cache for Redis zur vorübergehenden Zwischenspeicherung von Daten vorgesehen ist, und dass im Cache gehaltene Daten eine begrenzte Lebensdauer haben, die als Gültigkeitsdauer (Time-to-live, TTL) angegeben wird. Für relativ flüchtige Daten sollte der TTL-Wert klein, für statische Daten kann er jedoch wesentlich größer sein. Vermeiden Sie die Speicherung großer Mengen langlebiger Daten im Cache, wenn die Datenmenge wahrscheinlich den kompletten Cache belegen wird. Sie können eine Entfernungsrichtlinie angeben, die bewirkt, dass Azure Cache for Redis die Daten entfernt, wenn der Speicherplatz knapp bemessen ist.
Hinweis
Wenn Sie Azure Cache for Redis verwenden, können Sie durch Auswahl des entsprechenden Tarifs die maximale Größe des Caches (von 250 MB bis 53 GB) angeben. Sie können eine Azure Cache for Redis-Instanz jedoch nach dem Erstellen nicht mehr vergrößern (oder verkleinern).
Redis-Batches und -Transaktionen können sich nicht über mehrere Verbindungen erstrecken, d. h. alle Daten, die von einem Batch- oder Transaktionsvorgang betroffen sind, sollten in der gleichen Datenbank (Shard) gespeichert werden.
Hinweis
Eine Abfolge von Operationen in einer Redis-Transaktion ist nicht unbedingt atomar. Die Befehle, die eine Transaktion bilden, werden vor der Ausführung überprüft und in eine Warteschlange eingereiht. Wenn während dieser Phase ein Fehler auftritt, wird die gesamte Warteschlange verworfen. Nachdem die Transaktion jedoch erfolgreich übermittelt wurde, werden die Befehle in der Warteschlange der Reihenfolge nach ausgeführt. Wenn bei einem Befehl ein Fehler auftritt, wird nur die Ausführung dieses Befehls beendet. Alle vorherigen und nachfolgenden Befehle in der Warteschlange werden ausgeführt. Weitere Informationen finden Sie auf der Redis-Website unter Transaktionen.
Redis unterstützt eine begrenzte Anzahl von atomischen Vorgängen. Die einzige Vorgänge dieser Art, die mehrere Schlüssel und Werte unterstützen, sind MGET und MSET. MGET-Vorgänge geben eine Auflistung von Werten für eine angegebene Liste von Schlüsseln zurück, und MSET-Vorgänge speichern eine Auflistung von Werten für eine angegebene Liste von Schlüsseln. Wenn Sie diese Vorgänge verwenden müssen, müssen die Schlüssel-Wert-Paare, auf die durch die MSET- und MGET-Befehle verwiesen wird, in derselben Datenbank gespeichert sein.
Partitionieren von Azure Service Fabric
Azure Service Fabric ist eine Microservice-Plattform, die eine Laufzeit für verteilte Anwendungen in der Cloud bereitstellt. Service Fabric unterstützt ausführbare .NET-Gastanwendungsdateien, zustandsbehaftete und zustandslose Dienste sowie Container. Für zustandsbehaftete Dienste wird eine zuverlässige Sammlung bereitgestellt, um Daten im Service Fabric-Cluster in einer Schlüssel-Wert-Sammlung dauerhaft zu speichern. Weitere Informationen zu Strategien für die Partitionierung von Schlüsseln in einer zuverlässigen Sammlung finden Sie unter Richtlinien und Empfehlungen für zuverlässige Sammlungen in Azure Service Fabric.
Nächste Schritte
Der Artikel Übersicht über Azure Service Fabric enthält eine Einführung in Azure Service Fabric.
Partitionieren von Service Fabric Reliable Services enthält weitere Informationen zu Reliable Services in Azure Service Fabric.
Partitionieren von Azure Event Hubs
Azure Event Hubs ist für das Datenstreaming in großem Umfang ausgelegt, und die Partitionierung ist in den Dienst integriert, um die horizontale Skalierung zu ermöglichen. Jeder Consumer liest nur eine bestimmte Partition des Nachrichtendatenstroms.
Dem Ereignisherausgeber ist nur der Partitionsschlüssel bekannt, nicht die Partition, auf der die Ereignisse veröffentlicht werden. Dieses Entkoppeln von Schlüssel und Partition entbindet den Absender davon, zu viel über die Downstreamverarbeitung wissen zu müssen. (Es ist auch möglich, Ereignisse direkt an eine bestimmte Partition zu senden, aber normalerweise ist dies nicht zu empfehlen.)
Berücksichtigen Sie bei der Wahl der Anzahl von Partitionen die langfristigen Skalierungsanforderungen. Nach der Erstellung eines Event Hub können Sie die Anzahl von Partitionen nicht mehr ändern.
Nächste Schritte
Weitere Informationen zur Verwendung von Partitionen in Event Hubs finden Sie unter Was ist Event Hubs?.
Informationen zu den Kompromissen, die in Bezug auf die Verfügbarkeit und die Konsistenz gemacht werden müssen, finden Sie unter Verfügbarkeit und Konsistenz in Event Hubs.