Dieses Architekturmuster veranschaulicht, wie Sie MDM in das Ökosystem der Azure-Datendienste integrieren, um die Qualität der Daten zu verbessern, die für die Analyse und betriebliche Entscheidungsfindung verwendet werden. MDM löst mehrere gängige Herausforderungen, z. B.:
- Identifizieren und Verwalten doppelter Daten (Abgleich und Zusammenführung)
- Kennzeichnen und Beheben von Problemen mit der Datenqualität
- Standardisieren und Anreichern von Daten
- Proaktives Verwalten und Verbessern der Daten durch Data Steward
Dieses Muster stellt einen modernen Ansatz für MDM dar. Sämtliche Technologien können nativ in Azure bereitgestellt werden, einschließlich Profisee, das Sie über Container bereitstellen und mit Azure Kubernetes Service verwalten können.
Aufbau

Laden Sie eine Visio-Datei mit allen Diagrammen herunter, die in dieser Architektur verwendet werden.
Datenfluss
Der folgende Dataflow entspricht dem vorherigen Diagramm:
Laden der Quelldaten: Die Quelldaten aus Geschäftsanwendungen werden in Azure Data Lake kopiert und für die weitere Transformation und Verwendung in Downstreamanalysen gespeichert. Quelldaten fallen in der Regel in eine von drei Kategorien:
- Strukturierte Masterdaten: Die Informationen, mit denen Kunden, Produkte, Standorte usw. beschrieben werden. Masterdaten sind klein, komplex und ändern sich im Lauf nur geringfügig. Dies sind häufig die Daten, auf deren Qualität die meisten Organisationen am stärksten achten.
- Strukturierte Transaktionsdaten: Geschäftsereignisse, die zu einem bestimmten Zeitpunkt auftreten, z. B. eine Bestellung, eine Rechnung oder eine Interaktion. Transaktionen umfassen die Metriken für diese Transaktion (z. B. Verkaufspreis) und Verweise auf Masterdaten (z. B. das Produkt und die Kundschaft, die an einem Kauf beteiligt ist). Transaktionsdaten haben in der Regel einen großen Umfang, sind von geringer Komplexität und unterliegen kaum Änderungen.
- Unstrukturierte Daten: Zu diesen Daten gehören Dokumente, Bilder, Videos, Social Media-Inhalte und Audioinhalte. Moderne Analyseplattformen können in zunehmendem Maße unstrukturierte Daten verwenden, um neue Erkenntnisse zu gewinnen. Unstrukturierte Daten gehören häufig zu den Masterdaten, z. B. die Kund*innen, denen Social Media-Konten gehören, oder das Produkt, das einem Bild zugeordnet ist.
Laden von Quellmasterdaten: Masterdaten aus Quellgeschäftsanwendungen werden „wie besehen“ in die MDM-Anwendung geladen, mit vollständigen Herkunftsinformationen und minimalen Transformationen.
Automatisierte MDM-Verarbeitung: Die MDM-Lösung verwendet automatisierte Prozesse zum Standardisieren, Überprüfen und Anreichern von Daten, z. B. Adressdaten. Außerdem ermittelt die Lösung Probleme mit der Datenqualität, gruppiert doppelte Datensätze (z. B. doppelte Kund*innen) und generiert Masterdatensätze, die auch als „goldene Datensätze“ bezeichnet werden.
Datenverwaltung: Bei Bedarf können Data Stewards folgende Aktionen ausführen:
- Überprüfen und Verwalten von Gruppen übereinstimmender Datensätze
- Erstellen und Verwalten von Datenbeziehungen
- Ausfüllen fehlender Informationen
- Lösen von Problemen mit der Datenqualität
Data Stewards können bei Bedarf mehrere alternative hierarchische Rollups verwalten (z. B. Produkthierarchien).
Verwaltete Masterdaten laden: Hochwertige Masterdaten fließen in Downstreamanalyselösungen. Dieser Prozess vereinfacht wiederum die Datenintegration, da dafür dann keine Datenqualitätstransformationen mehr notwendig sind.
Laden von Transaktions- und unstrukturierten Daten: Transaktions- und unstrukturierte Daten werden in die Downstream-Analyselösung geladen, wo sie mit hochwertigen Masterdaten kombiniert werden.
Visualisierung und Analyse: Daten werden modelliert und für Geschäftsbenutzer zur Analyse bereitgestellt. Hochwertige Masterdaten beseitigen häufige Probleme mit der Datenqualität und ermöglichen so bessere Erkenntnisse.
Komponenten
Azure Data Factory ist ein Hybriddienst für die Datenintegration, mit dem Sie Ihre Workflows für Extrahieren, Transformieren und Laden (ETL) sowie Extrahieren, Laden und Transformieren (ELT) erstellen, planen und orchestrieren können.
Azure Data Lake bietet unbegrenzten Speicher für Analysedaten.
Profisee ist eine skalierbare MDM-Plattform, die für die einfache Integration in das Microsoft-Ökosystem konzipiert ist.
Azure Synapse Analytics ist das schnelle, flexible und vertrauenswürdige Data Warehouse in der Cloud, mit dem Sie flexibel und unabhängig mit einer leistungsstarken Parallelverarbeitungsarchitektur Daten skalieren, berechnen und speichern können.
Power BI ist eine Suite mit Business-Analytics-Tools, die für Ihre gesamte Organisation Erkenntnisse liefern. Stellen Sie eine Verbindung mit Hunderten von Datenquellen her, vereinfachen Sie die Datenvorbereitung, und führen Sie improvisierte Analysen durch. Erzeugen Sie hochwertige Berichte, und veröffentlichen Sie sie dann für Ihre Organisation zur Nutzung im Web und auf mobilen Geräten.
Alternativen
Wenn keine speziell erstellte MDM-Anwendung vorhanden ist, finden Sie einige der technischen Funktionen, die zum Erstellen einer MDM-Lösung erforderlich sind, im Azure-Ökosystem.
- Datenqualität: Sie können beim Laden auf eine Analyseplattform die Datenqualität in Ihre Integrationsprozesse integrieren. Beispielsweise können Sie hartcodierte Skripts nutzen, um Datenqualitätstransformationen in einer Azure Data Factory-Pipeline anzuwenden.
- Datenstandardisierung und -anreicherung: Mit Azure Maps können Sie Datenüberprüfung und -standardisierung für Adressdaten bereitstellen, die in Azure Functions und Azure Data Factory verwendet werden können. Die Standardisierung anderer Daten erfordert möglicherweise die Entwicklung hartcodierter Skripts.
- Verwalten doppelter Daten: Sie können Azure Data Factory verwenden, um Zeilen zu deduplizieren, wenn genügend Bezeichner für eine exakte Übereinstimmung verfügbar sind. In diesem Fall würde die mit der entsprechenden Survivorship gepaarte Logik zum Zusammenführen wahrscheinlich benutzerdefinierte, hart codierte Skripts erfordern.
- Datenverwaltung: Mit Power Apps können Sie schnell einfache Datenverwaltungslösungen in Azure zu entwickeln, zusammen mit den entsprechenden Benutzeroberflächen, die Data Stewards für die Überprüfung sowie für Workflows, Warnungen und Validierungen nutzen können.
Szenariodetails
Viele digitale Transformationsprogramme verwenden als Basis Azure. Dies hängt jedoch bei Daten aus mehreren Quellen, z. B. Geschäftsanwendungen, Datenbanken, Datenfeeds usw., von ihrer Qualität und Konsistenz ab. Ein Mehrwert entsteht durch Business Intelligence, Analysen, maschinelles Lernen u. v. m. Die MDM-Lösung (Master Data Management, Masterdatenverwaltung) von Profisee vervollständigt die Datenressourcen von Azure mit einer praktischen Methode zum „Abgleichen und Kombinieren“ von Daten aus mehreren Quellen. Dazu werden konsistente Datenstandards für Quelldaten erzwungen, z. B. Abgleich, Zusammenführung, Standardisierung, Überprüfung, Korrektur. Durch die native Integration in Azure Data Factory und andere Azure Data Services wird dieser Prozess noch weiter optimiert, um die Bereitstellung von Azure-Geschäftsvorteilen zu beschleunigen.
Ein Kernaspekt der Funktionsweise von MDM-Lösungen besteht darin, dass sie Daten aus mehreren Quellen kombinieren, um einen „Golden Record Master“ (goldener Datensatzmaster) zu erstellen, der die am besten bekannten und vertrauenswürdigsten Daten für jeden Datensatz enthält. Diese Struktur wird gemäß den Anforderungen domänenweise ausgebaut, erfordert jedoch fast immer mehrere Domänen. Gängige Domänen sind Kundschaft, Produkt und Standort. Domänen können aber auch beliebige Elemente von Verweisdaten bis hin zu Verträgen und Medikamentennamen darstellen. Generell gilt: Je besser die Domänenabdeckung in Bezug auf die allgemeinen Azure-Datenanforderungen ausgebaut werden kann, desto besser.
MDM-Integrationspipeline

Laden Sie eine Visio-Datei dieser Architektur herunter.
Die vorherige Abbildung zeigt die Details der Integration in die MDM-Lösung von Profisee. Beachten Sie, dass Azure Data Factory und Profisee native Unterstützung für die REST-Integration bieten und so eine schlanke und moderne Integration ermöglichen.
Laden von Quelldaten in MDM: Mit Azure Data Factory können Sie Daten aus Data Lakes extrahieren, sie so transformieren, dass sie dem Masterdatenmodell entsprechen, und sie über eine REST-Senke in das MDM-Repository streamen.
MDM-Verarbeitung: Die MDM-Plattform verarbeitet Quellmasterdaten durch eine Abfolge von Aktivitäten, um die Daten zu überprüfen, zu standardisieren und anzureichern sowie um Datenqualitätsprozesse auszuführen. Schließlich werden im MDM Abgleich und Survivorship (Überleben) ausgeführt, um doppelte Datensätze zu identifizieren und zu gruppieren und um Masterdatensätze zu erstellen. Optional können Data Stewards Aufgaben ausführen, die zu Masterdaten für die Verwendung bei nachfolgenden Analysen führen.
Masterdaten für die Analyse laden: Azure Data Factory verwendet seine REST-Quelle, um Masterdaten aus Profisee in Azure Synapse Analytics zu streamen.
Azure Data Factory-Vorlagen für Profisee
In Zusammenarbeit mit Microsoft hat Profisee eine Gruppe von Azure Data Factory-Vorlagen entwickelt, die die Integration von Profisee in das Azure Data Services-Ökosystem beschleunigen und vereinfachen. Diese Vorlagen verwenden die REST-Datenquelle und -Datensenke von Azure Data Factory, um Daten aus der REST-Gateway-API von Profisee zu lesen und zu schreiben. Sie umfassen Vorlagen sowohl zum Lesen aus als auch zum Schreiben in Profisee.
Data Factory-Beispielvorlage: JSON an Profisee über REST
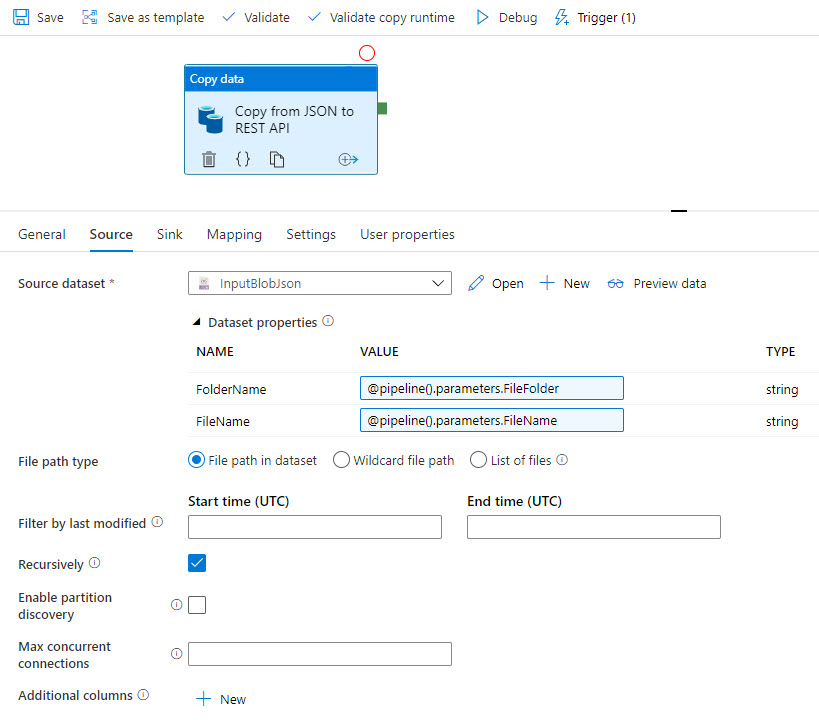
Die folgenden Screenshots veranschaulichen eine Azure Data Factory-Vorlage, mit der Daten aus einer JSON-Datei in Azure Data Lake über REST zu Profisee kopiert werden.
Die Vorlage kopiert die JSON-Quelldaten:
Anschließend werden die Daten per REST mit Profisee synchronisiert:
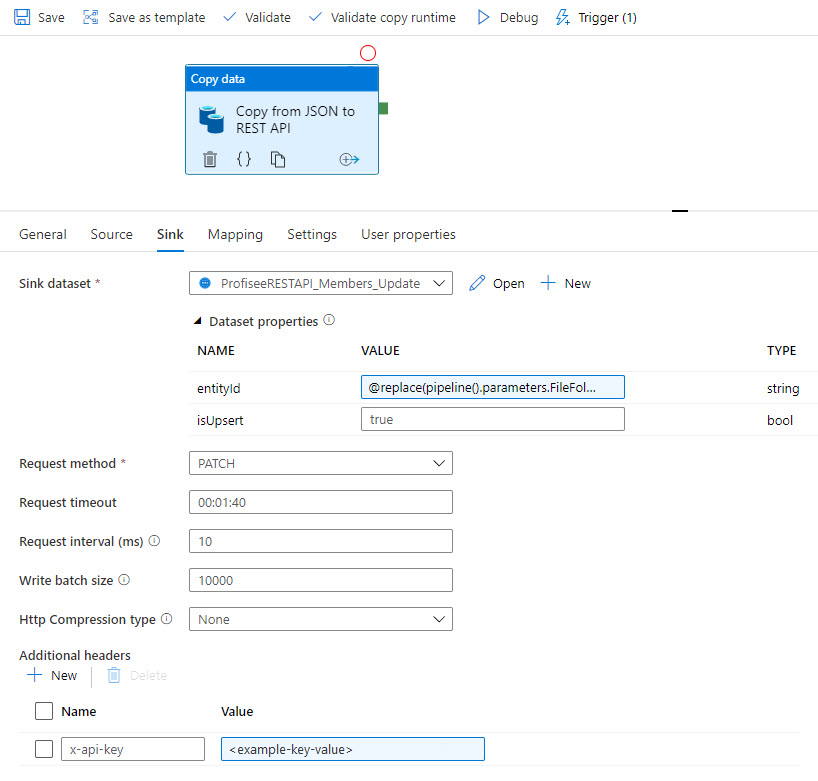
Weitere Informationen finden Sie unter Azure Data Factory-Vorlagen für Profisee.
MDM-Verarbeitung
In einem analytischen MDM-Anwendungsfall werden Daten häufig durch die MDM-Lösung automatisiert zum Laden von Daten für die Analyse verarbeitet. In den folgenden Abschnitten wird ein typischer Prozess für Kundendaten in diesem Kontext veranschaulicht.
1. Quelldaten laden
Die Quelldaten werden aus Quellsystemen mit ihren Herkunftsinformationen in die MDM-Lösung geladen. In diesem Fall haben wir zwei Quelldatensätze: einen aus der CRM- und einen aus der ERP-Anwendung. Bei der visuellen Überprüfung scheinen die beiden Datensätze die gleiche Person zu repräsentieren.
| Quellname | Adresse (Quelle) | Bundesland (Quelle) | Telefon (Quelle) | Quell-ID | Adresse (Standard) | Bundesland (Standard) | Name (Standard) | Telefon (Standard) | Ähnlichkeit |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Allgemein verfügbar | 7708434125 | CRM-100 | |||||
| Bosch, Alana | Hauptst. 123 | Georgien | 404-854-7736 | CRM-121 | |||||
| Alana Bosch | (404) 854-7736 | ERP-988 |
2. Datenüberprüfung und -standardisierung
Regeln und Dienste zur Überprüfung und Standardisierung helfen dabei, Informationen zu Adresse, Name und Telefonnummer zu standardisieren und zu überprüfen.
| Quellname | Adresse (Quelle) | Bundesland (Quelle) | Telefon (Quelle) | Quell-ID | Adresse (Standard) | Bundesland (Standard) | Name (Standard) | Telefon (Standard) | Ähnlichkeit |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Allgemein verfügbar | 7708434125 | CRM-100 | Hauptst. 123 | Allgemein verfügbar | Alana Bosh | 770 843 4125 | |
| Bosch, Alana | Hauptst. 123 | Georgien | 404-854-7736 | CRM-121 | Hauptst. 123 | Allgemein verfügbar | Alana Bosch | 404 854 7736 | |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 |
3. Abgleich
Mit den standardisierten Daten wird der Abgleich durchführt, bei dem Ähnlichkeiten zwischen Datensätzen in der Gruppe identifiziert werden. In diesem Szenario stimmen zwei Datensätze bei Name und Telefonnummer exakt überein, und bei den anderen liegen unscharfe Übereinstimmungen bei Name und Adresse vor.
| Quellname | Adresse (Quelle) | Bundesland (Quelle) | Telefon (Quelle) | Quell-ID | Adresse (Standard) | Bundesland (Standard) | Name (Standard) | Telefon (Standard) | Ähnlichkeit |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Allgemein verfügbar | 7708434125 | CRM-100 | Hauptst. 123 | Allgemein verfügbar | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | Hauptst. 123 | Georgien | 404-854-7736 | CRM-121 | Hauptst. 123 | Allgemein verfügbar | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 |
4. Survivorship
Mit einer gebildeten Gruppe erstellt Survivorship einen Masterdatensatz (auch als „Golden Record“ bezeichnet), um die Gruppe darzustellen, und füllt diesen auf.
| Quellname | Adresse (Quelle) | Bundesland (Quelle) | Telefon (Quelle) | Quell-ID | Adresse (Standard) | Bundesland (Standard) | Name (Standard) | Telefon (Standard) | Ähnlichkeit |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Allgemein verfügbar | 7708434125 | CRM-100 | Hauptst. 123 | Allgemein verfügbar | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | Hauptst. 123 | Georgien | 404-854-7736 | CRM-121 | Hauptst. 123 | Allgemein verfügbar | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 | ||||
| Masterdatensatz: | 123 Main St. | GA | Alana Bosch | 404 854 7736 |
Dieser Masterdatensatz wird zusammen mit verbesserten Quelldaten und Herkunftsinformationen in die Downstream-Analyselösung geladen, wo er wieder mit Transaktionsdaten verknüpft werden kann.
Dieses Beispiel zeigt die grundlegende automatisierte MDM-Verarbeitung. Datenqualitätsregeln können auch verwendet werden, um Werte automatisch zu berechnen und zu aktualisieren und um fehlende oder ungültige Werte zu kennzeichnen, damit Data Stewards diese auflösen können. Data Stewards verwalten die Daten, einschließlich der Verwaltung hierarchischer Rollups von Daten.
Die Auswirkungen der Masterdatenverwaltung (MDM) auf die Komplexität der Integration
Wie oben gezeigt, unterstützt MDM bei verschiedenen häufigen Herausforderungen, die bei der Integration von Daten in eine Analyselösung auftreten können. Dazu gehören die Behebung von Problemen mit der Datenqualität, das Standardisieren und Anreichern von Daten sowie das Rationalisieren doppelter Daten. Die Integration von MDM in Ihre Analysearchitektur ändert den Datenfluss grundlegend, indem die hartcodierte Logik des Integrationsprozesses beseitigt und auf die MDM-Lösung abgeladen wird, was Integrationen erheblich vereinfacht. In der folgenden Tabelle werden einige allgemeine Unterschiede im Integrationsprozess mit und ohne MDM beschrieben.
| Funktion | Ohne MDM | Mit MDM |
|---|---|---|
| Datenqualität | Die Integrationsprozesse umfassen Qualitätsregeln und Transformationen, um Daten beim Verschieben zu korrigieren. Hierfür sind technische Ressourcen sowohl für die anfängliche Implementierung als auch die fortlaufende Wartung dieser Regeln erforderlich, was die Entwicklung und Pflege von Datenintegrationsprozessen kompliziert und teuer gestaltet. | Die MDM-Lösung konfiguriert und erzwingt Logik und Regeln zur Datenqualität. Integrationsprozesse führen keine Datenqualitätstransformationen durch, sondern verschieben die Daten unverändert („wie besehen“) in die MDM-Lösung. Datenintegrationsprozesse lassen sich einfach und kostengünstig entwickeln und pflegen. |
| Datenstandardisierung und -anreicherung | Die Integrationsprozesse umfassen Logik zum Standardisieren und Abgleichen von Verweis- und Masterdaten. Entwickeln Sie Integrationen mit Drittanbieterdiensten, um die Standardisierung von Adressen, Namen, E-Mail-Adressen und Telefondaten vorzunehmen. | Mithilfe integrierter Regeln und vorgefertigter Integrationen mit Drittanbieter-Datendiensten können Sie Daten innerhalb der MDM-Lösung standardisieren, was die Integration vereinfacht. |
| Verwaltung doppelter Daten | Beim Integrationsprozess werden auf Grundlage vorhandener eindeutiger Bezeichner doppelte Datensätze identifiziert und gruppiert, die innerhalb von Anwendungen sowie anwendungsübergreifend vorhanden sind. Bei diesem Prozess werden Bezeichner systemübergreifend (z. B. SSN oder E-Mail-Adresse) gemeinsam verwendet, und sie werden nur abgeglichen und gruppiert, wenn sie identisch sind. Anspruchsvollere Ansätze erfordern signifikante Investitionen in das Integrations-Engineering. | Integrierte Machine Learning-Funktionen für Abgleiche identifizieren doppelte Datensätze innerhalb von Systemen sowie systemübergreifend und erzeugen so einen goldenen Datensatz zur Darstellung der Gruppe. Dadurch können Datensätze unscharf (fuzzy) abgeglichen werden, wobei ähnliche Datensätze gruppiert werden, um nachvollziehbare Ergebnisse zu liefern. Gruppen werden in Szenarien verwaltet, in denen die ML-Engine keine Gruppe mit hoher Zuverlässigkeit (Konfidenz) bilden kann. |
| Data Stewards | Bei den Aktivitäten zur Datenverwaltung werden nur Daten in den Quellanwendungen aktualisiert, z. B. in ERP- oder CRM-Lösungen. In der Regel werden beim Durchführen von Analysen Probleme wie fehlende, unvollständige oder falsche Daten erkannt. Die Probleme werden in der Quellanwendung korrigiert und dann bei der nächsten Aktualisierung in der Analyselösung auf den neuesten Stand gebracht. Alle neuen, zu verwaltenden Informationen werden den Quellanwendungen hinzugefügt, was zeitaufwendig und kostspielig sein kann. | MDM-Lösungen verfügen über integrierte Funktionen zur Datenverwaltung, die es Benutzer*innen ermöglichen, auf Daten zuzugreifen und diese zu verwalten. Idealerweise kennzeichnet das System Probleme und fordert Data Stewards auf, diese zu korrigieren. Konfigurieren Sie schnell neue Informationen oder Hierarchien in der Lösung, damit Data Stewards sie verwalten können. |
MDM-Anwendungsfälle
Zwar gibt es viele Anwendungsfälle für MDM, doch es gibt nur wenige Anwendungsfälle, die die meisten realen MDM-Implementierungen abdecken. Diese Anwendungsfälle sind zwar auf eine einzelne Domäne fokussiert, es ist aber unwahrscheinlich, dass sie nur auf dieser Domäne basieren. Das heißt also, dass selbst diese fokussierten Anwendungsfälle höchstwahrscheinlich mehrere Masterdatendomänen umfassen.
Customer 360
Das Konsolidieren von Kundendaten für Analysen ist der häufigste MDM-Anwendungsfall. Organisationen erfassen Kundendaten mit einer wachsenden Anzahl von Anwendungen, wobei sie doppelte Kundendaten innerhalb von Anwendungen sowie anwendungsübergreifend mit Inkonsistenzen und Abweichungen erzeugen. Diese Kundendaten von schlechter Qualität machen es schwierig, den Mehrwert moderner Analyselösungen zu realisieren. Zu den Symptomen gehören:
- Schwierig zu beantwortende, grundlegende geschäftliche Fragen wie „Wer sind unsere wichtigsten Kund*innen?“ und „Wie viele neue Kund*innen hatten wir?“, die beträchtlichen manuellen Aufwand erfordern
- Fehlende und ungenaue Kundeninformationen, die ein Rollup oder Drilldown in die Daten erschweren.
- Die Unmöglichkeit, Kundendaten system- oder geschäftseinheitenübergreifend zu analysieren, da Kund*innen nicht über Organisations- und Systemgrenzen hinweg eindeutig identifiziert werden können
- Erkenntnisse von schlechter Qualität aus KI und Machine Learning wegen schlechter Qualität der Eingabedaten.
Rund um Produkte
Produktdaten sind häufig auf mehrere Unternehmensanwendungen verteilt, z. B. ERP, PLM oder E-Commerce. Hieraus resultiert die Herausforderung, den gesamten Katalog von Produkten zu verstehen, die inkonsistente Definitionen für Eigenschaften besitzen wie den Namen, die Beschreibung und die Eigenschaften des Produkts. Unterschiedliche Definitionen von Verweisdaten erschweren diese Situation zusätzlich. Zu den Symptomen gehören:
- Die Unmöglichkeit, verschiedene alternative hierarchische Rollup- und Drilldownpfade für die Produktanalyse zu unterstützen.
- Egal ob Endprodukte oder Materialbestand, Schwierigkeiten beim Verständnis, welche Produkte genau Sie vorrätig haben, von welchen Lieferant*innen Ihre Produkte gekauft werden sowie doppelte Produkte – dies alles führt zu einem übermäßigen Bestand.
- Es ist schwierig, Produkte aufgrund von widersprüchlichen Definitionen zu rationalisieren. Dies kann zu fehlenden oder ungenauen Informationen in Analysen führen.
Rund um Verweisdaten
Im Kontext der Analyse liegen Verweisdaten als zahlreiche Listen von Daten vor, die helfen, andere Gruppen von Masterdaten näher zu beschreiben. Zu den Verweisdaten gehören z. B. Listen von Ländern und Regionen, Währungen, Farben, Größen und Maßeinheiten. Inkonsistente Verweisdaten führen zu offensichtlichen Fehlern in der Downstreamanalyse. Zu den Symptomen gehören:
- Mehrfache Darstellungen desselben Objekts. Beispielsweise wird der Bundesstaat „Georgia“ in der Form „GA“ und „Georgia“ aufgeführt, was es schwierig macht, Daten konsistent zu aggregieren und einen Drilldown auszuführen.
- Schwierigkeiten beim Aggregieren von Daten aus mehreren Anwendungen aufgrund der Unfähigkeit, die Verweisdatenwerte zwischen Systemen miteinander verknüpfen zu können. Beispielsweise wird die Farbe Rot im ERP-System als „R“ und im PLM-System als „Rot“ dargestellt.
- Schwierigkeiten beim Abgleichen von Werten zwischen Organisationen aufgrund von Unterschieden bei vereinbarten Verweisdatenwerten für die Kategorisierung von Daten
Rund um Finanzen
Finanzorganisationen verlassen sich bei kritischen Aktivitäten sehr stark auf Daten, z. B. Monats-, Quartals- und Jahresberichte. Organisationen mit mehreren Finanz- und Buchhaltungssystemen haben häufig Finanzdaten über mehrere allgemeine Hauptbücher verteilt, die zur Erstellung von Finanzberichten konsolidiert werden müssen. MDM kann einen zentralisierten Ort zum Zuordnen und Verwalten von Konten, Kostenstellen, Geschäftseinheiten und anderen Finanzdatasets zu einer konsolidierten Ansicht bereitstellen. Zu den Symptomen gehören:
- Schwierigkeiten beim Aggregieren von Finanzdaten über mehrere Systeme hinweg in einer konsolidierten Ansicht.
- Fehlende Prozesse zum Hinzufügen und Zuordnen neuer Datenelemente in den Finanzsystemen.
- Verzögerungen bei der Erstellung von Finanzberichten zu Abschlusszeiträumen
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Zuverlässigkeit
Zuverlässigkeit stellt sicher, dass Ihre Anwendung Ihre Verpflichtungen gegenüber den Kunden erfüllen kann. Weitere Informationen finden Sie in der Überblick über die Säule „Zuverlässigkeit“.
Profisee läuft nativ in Azure Kubernetes Service und Azure SQL-Datenbank. Beide Dienste bieten vordefinierte Funktionen zur Unterstützung von Hochverfügbarkeit.
Effiziente Leistung
Leistungseffizienz ist die Fähigkeit Ihrer Workload, auf effiziente Weise eine den Anforderungen der Benutzer entsprechende Skalierung auszuführen. Weitere Informationen finden Sie unter Übersicht über die Säule „Leistungseffizienz“.
Profisee läuft nativ in Azure Kubernetes Service und Azure SQL-Datenbank. Sie können Azure Kubernetes Service für die bedarfsgesteuerte Hoch- und Aufskalierung von Profisee konfiguriert werden. Sie können Azure SQL-Datenbank in vielen verschiedenen Konfigurationen bereitstellen, um Leistung, Skalierbarkeit und Kosten auszugleichen.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Profisee authentifiziert Benutzer*innen mithilfe von OpenID Connect, das einen OAuth 2.0-Authentifizierungsflow implementiert. Die meisten Organisationen konfigurieren Profisee für die Benutzerauthentifizierung mit Microsoft Entra ID. Durch diesen Prozess wird sichergestellt, dass Unternehmensrichtlinien für die Authentifizierung angewandt und erzwungen werden.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Die Ausführungskosten bestehen aus einer Softwarelizenz und dem Azure-Verbrauch. Um weitere Informationen zu erhalten, wenden Sie sich an Profisee.
Bereitstellen dieses Szenarios
So stellen Sie dieses Szenario bereit:
- Bereitstellen von Profisee in Azure mit einer ARM-Vorlage.
- Erstellen einer Azure Data Factory-Instanz.
- Konfigurieren Ihrer Azure Data Factory-Instanz für das Verbinden mit einem Git-Repository.
- Fügen Sie die Azure Data Factory-Vorlagen von Profisee Ihrem Azure Data Factory-Git-Repository hinzu.
- Erstellen Sie eine neue Azure Data Factory-Pipeline mithilfe einer Vorlage.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Sunil Sabat | Principal Program Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Verstehen der Funktionen des REST-Kopierconnectors in Azure Data Factory.
- Weitere Informationen zum nativ in Azure ausgeführtem Profisee.
- Informationen zum Bereitstellen von Profisee in Azure mit einer ARM-Vorlage.
- Anzeigen der Azure Data Factory-Vorlagen von Profisee.
Zugehörige Ressourcen
Handbücher zur Architektur
- Extrahieren, Transformieren und Laden (ETL)
- Integrationslaufzeit in Azure Data Factory
- Auswählen einer Technologie für die Datenpipelineorchestrierung in Azure