Behandeln von Leistungsengpässen in Azure Databricks
Hinweis
In diesem Artikel wird auf eine Open-Source-Bibliothek zurückgegriffen, die auf GitHub unter https://github.com/mspnp/spark-monitoring gehostet wird.
Die ursprüngliche Bibliothek unterstützt Azure Databricks Runtime-Versionen bis Version 10.x (Spark 3.2.x).
Databricks hat eine aktualisierte Version zur Unterstützung von Azure Databricks Runtime-Versionen ab Version 11.0 (Spark 3.3.x) für den Branch l4jv2 unter https://github.com/mspnp/spark-monitoring/tree/l4jv2 bereitgestellt.
Beachten Sie, dass das Release 11.0 aufgrund der unterschiedlichen Protokollierungssysteme, die in Databricks Runtime-Instanzen verwendet werden, nicht abwärtskompatibel ist. Achten Sie darauf, den richtigen Build für Ihre Databricks Runtime-Instanz zu verwenden. Die Bibliothek und das GitHub-Repository befinden sich im Wartungsmodus. Es gibt keine Pläne für weitere Releases, und der Support bei Problemen wird nur bestmöglich bereitgestellt. Wenn Sie weitere Fragen zu der Bibliothek oder zur Roadmap für die Überwachung und Protokollierung Ihrer Azure Databricks-Umgebungen haben, wenden Sie sich an azure-spark-monitoring-help@databricks.com.
Dieser Artikel beschreibt, wie Überwachungsdashboards verwendet werden, um Leistungsengpässe in Spark-Aufträgen unter Azure Databricks aufzuspüren.
Azure Databricks ist ein Analysedienst, der auf Apache Spark basiert und eine zügige Entwicklung und Bereitstellung von Analyselösungen für Big Data ermöglicht. Überwachung und Behandlung von Leistungsproblemen sind im Umgang mit Azure Databricks-Produktionsworkloads entscheidend. Um häufig auftretende Leistungsprobleme identifizieren zu können, ist es hilfreich, Überwachungsvisualisierungen auf der Grundlage von Telemetriedaten zu verwenden.
Voraussetzungen
So richten Sie die in diesem Artikel gezeigten Grafana-Dashboards ein:
Konfigurieren Sie den Databricks-Cluster mit der Azure Databricks-Überwachungsbibliothek zum Senden von Telemetriedaten an einen Log Analytics-Arbeitsbereich. Weitere Informationen finden Sie in der GitHub-Infodatei.
Stellen Sie Grafana auf einem virtuellen Computer bereit. Weitere Informationen finden Sie unter Visualisieren von Azure Databricks-Metriken mithilfe von Dashboards.
Das bereitgestellte Grafana-Dashboard enthält einen Satz von Zeitreihenvisualisierungen. Jedes Diagramm ist ein Zeitreihenplot von Metriken, die sich auf einen Apache Spark-Auftrag, die Phasen des Auftrags und die Aufgaben, aus denen jede Phase besteht, beziehen.
Übersicht zur Azure Databricks-Leistung
Azure Databricks basiert auf Apache Spark, einem verteilten Computersystem für allgemeine Zwecke. Der als Auftrag bezeichnete Anwendungscode wird vom Cluster-Manager koordiniert in einem Apache Spark-Cluster ausgeführt. Im Allgemeinen stellt ein Auftrag die höchste Berechnungseinheitenebene dar. Ein Auftrag stellt den vollständigen Vorgang dar, den die Spark-Anwendung ausführt. Ein normaler Vorgang umfasst das Lesen von Daten aus einer Quelle, Anwenden von Datentransformationen und Schreiben der Ergebnisse in einen Speicher oder ein anderes Ziel.
Aufträge werden in Phasen aufgeschlüsselt. Der Auftrag durchläuft die Phasen sequenziell, was bedeutet, dass spätere Phasen erst ausgeführt werden können, wenn frühere Phasen abgeschlossen sind. Phasen enthalten Gruppen von identischen Aufgaben, die auf mehreren Knoten des Spark-Clusters parallel ausgeführt werden können. Aufgaben sind die detailliertesten Ausführungseinheiten, die für eine Teilmenge der Daten ausgeführt werden.
Die nächsten Abschnitte beschreiben einige Dashboardvisualisierungen, die zur Behebung von Leistungsproblemen hilfreich sind.
Auftrags- und Phasenlatenz
Die Auftragslatenz ist die Dauer der Auftragsausführung vom Zeitpunkt des Beginns bis zum Zeitpunkt des Abschlusses. Sie wird in Quantilen einer Auftragsausführung pro Cluster und Anwendungs-ID angezeigt, um die Visualisierung von Ausreißern zu ermöglichen. Das folgende Diagramm zeigt einen Auftragsverlauf, in dem das 90. Quantil 50 Sekunden erreichte, obwohl das 50. Quantil konsistent bei ca. 10 Sekunden lag.
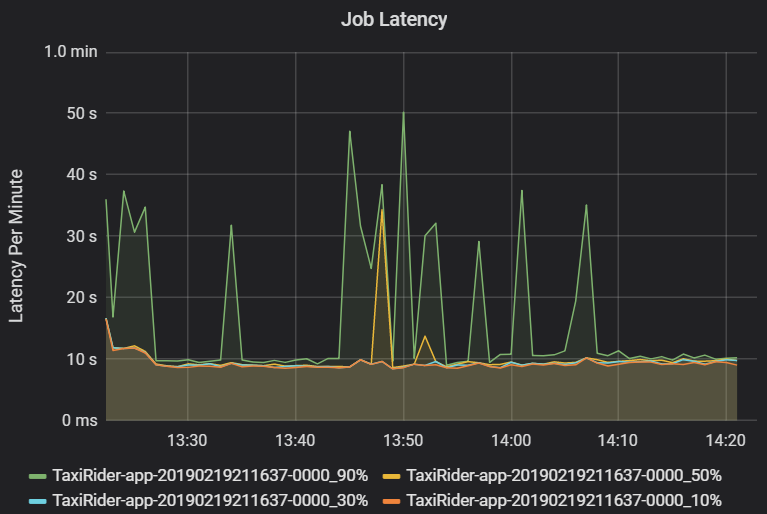
Untersuchen Sie die Ausführung des Auftrags nach Cluster und Anwendung, und achten Sie auf Latenzspitzen. Sobald Cluster und Anwendungen mit hoher Latenz identifiziert sind, fahren Sie mit der Untersuchung der Phasenlatenz fort.
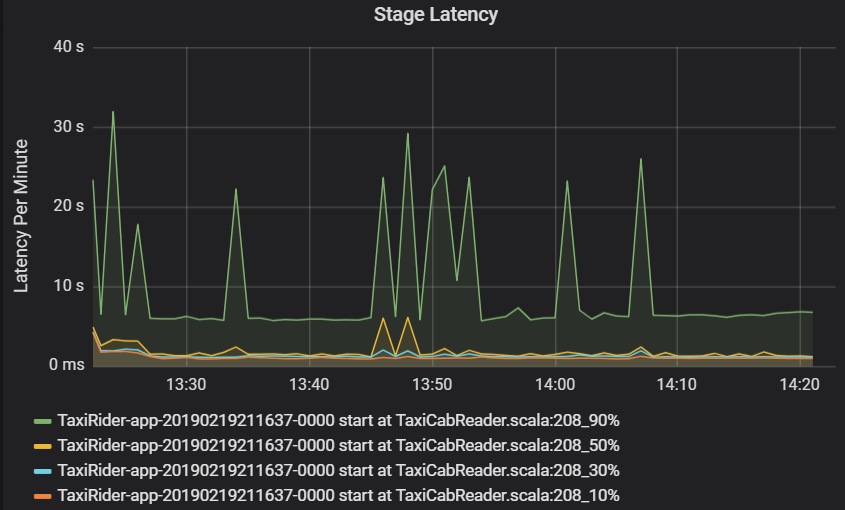
Die Phasenlatenz wird ebenfalls in Quantilen angezeigt, um die Visualisierung von Ausreißern zu ermöglichen. Die Phasenlatenz wird nach Cluster, Anwendung und Phasenname aufgeschlüsselt. Identifizieren Sie Spitzen der Aufgabenlatenz im Diagramm, um zu bestimmen, welche Aufgaben den Abschluss der Phase aufhalten.
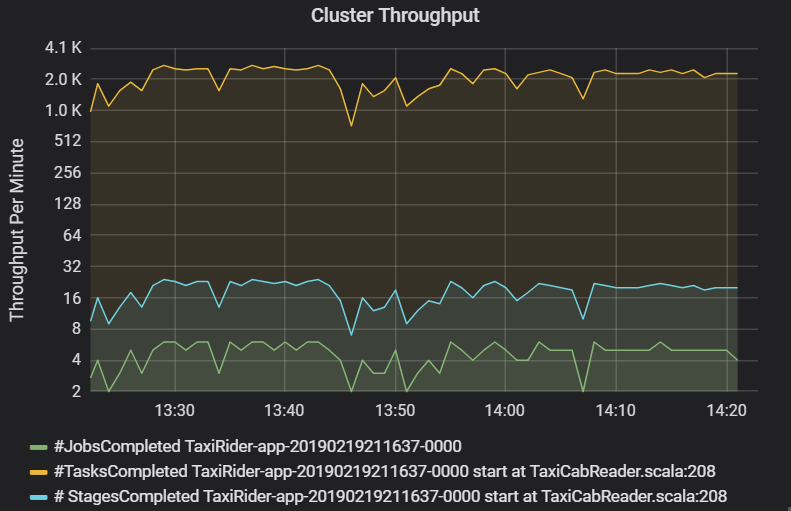
Das Diagramm des Clusterdurchsatzes zeigt die Anzahl der Aufträge, Phasen und Aufgaben, die pro Minute abgeschlossen werden. So können Sie die Workload im Hinblick auf die relative Anzahl von Phasen und Aufgaben pro Auftrag besser verstehen. Hier sehen Sie, dass die Anzahl der Aufträge pro Minute im Bereich zwischen 2 und 6 liegt, während die Anzahl der Phasen ungefähr 12 bis 24 pro Minute beträgt.
Summe der Aufgabenausführungslatenz
Diese Visualisierung zeigt die Summe der Aufgabenausführungslatenz pro Host in einem Cluster an. Verwenden Sie dieses Diagramm, um Aufgaben zu erkennen, die aufgrund der Verlangsamung des Hosts auf einem Cluster oder der Fehlzuordnung von Aufgaben pro Executor langsam ausgeführt werden. Im folgenden Diagramm haben die meisten Hosts eine Summe von ungefähr 30 Sekunden. Allerdings haben zwei Hosts Summen von etwa 10 Minuten. Entweder werden die Hosts langsam ausgeführt, oder die Anzahl der Aufgaben pro Executor ist falsch zugeordnet.
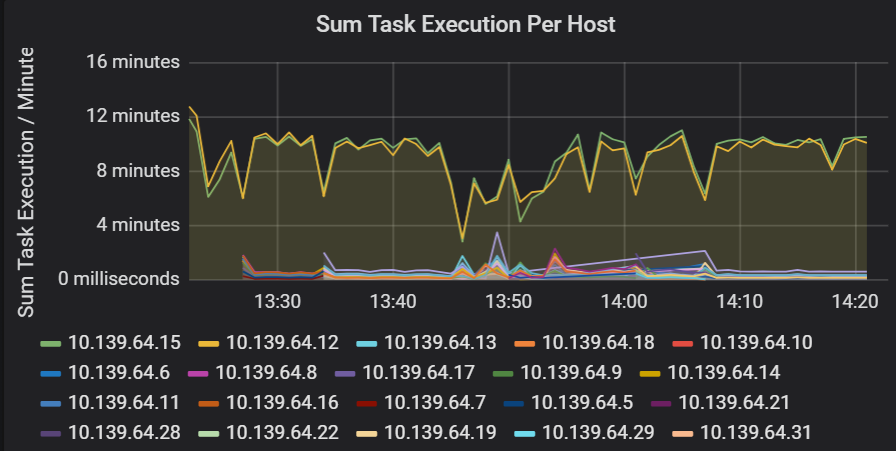
Die Anzahl der Aufgaben pro Executor zeigt, dass zwei Executor eine unverhältnismäßig hohe Anzahl von Aufgaben zugewiesen ist, was einen Engpass verursacht.
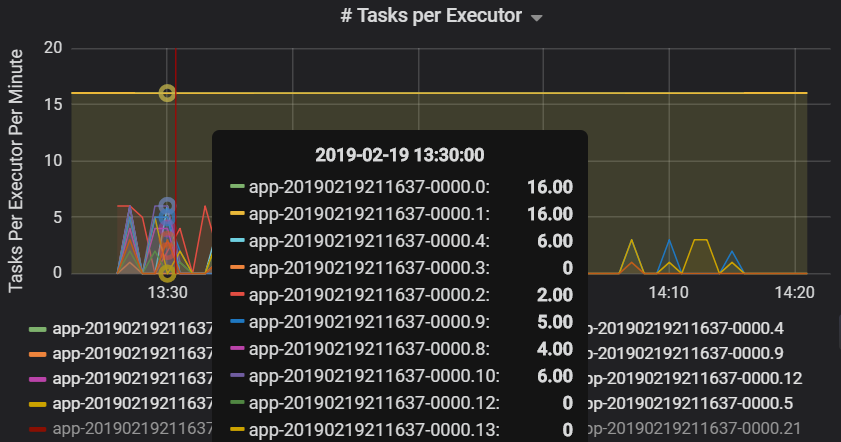
Aufgabenmetriken pro Phase
Die Visualisierung der Aufgabenmetriken zeigt die Aufschlüsselung der Kosten für eine Aufgabenausführung. Sie können damit die für Aufgaben wie Serialisierung und Deserialisierung aufgewendete relative Zeit erkennen. Diese Daten könnten auf Möglichkeiten zur Optimierung hinweisen, etwa durch Verwendung von Broadcastvariablen, um Datenversand zu vermeiden. Die Aufgabenmetriken zeigen auch die Menge der Shuffledaten für eine Aufgabe an sowie die Shufflelese- und Shuffleschreibzeiten. Wenn diese Werte hoch sind, bedeutet dies, dass große Datenmengen über das Netzwerk verschoben werden.
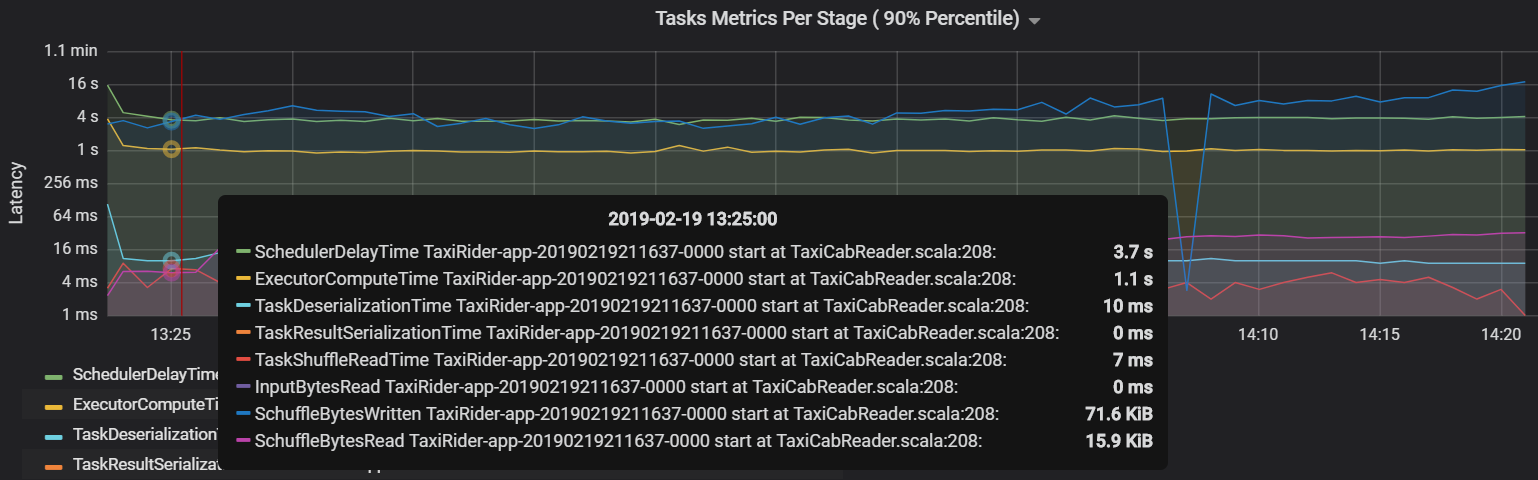
Eine weitere Aufgabenmetrik ist die Planerverzögerung, die misst, wie lange es dauert, eine Aufgabe zu planen. Im Idealfall sollte dieser Wert niedrig sein im Vergleich zur Executorcomputezeit – der Zeit, die tatsächlich zum Ausführen der Aufgabe aufgewendet wird.
Das folgende Diagramm zeigt eine Planerverzögerungszeit (3,7s), die die Executorcomputezeit (1,1s) überschreitet. Es wird also mehr Zeit für das Warten auf das Planen von Aufgaben aufgewendet als für die eigentliche Arbeit.
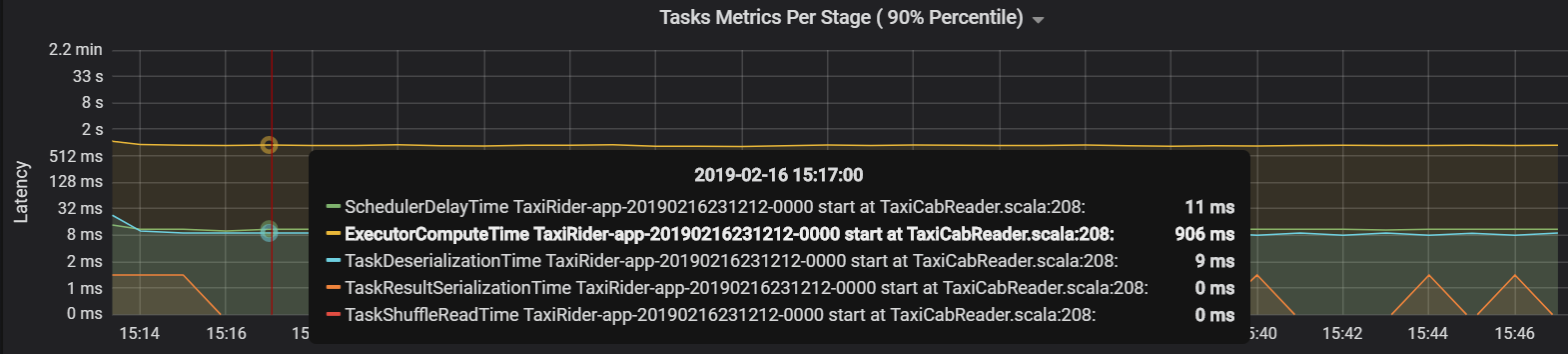
In diesem Fall wurde das Problem durch zu viele Partitionen verursacht, die einen beträchtlichen Mehraufwand erforderten. Die Reduzierung der Anzahl von Partitionen verringerte die Planerverzögerungszeit. Das folgende Diagramm zeigt, dass die meiste Zeit für das Ausführen der Aufgabe aufgewendet wird.
Streamingdurchsatz und Latenz
Der Streamingdurchsatz steht im direkten Zusammenhang mit strukturiertem Streaming. Zwei wichtige Metriken sind mit dem Streamingdurchsatz verknüpft: Eingabezeilen pro Sekunde und verarbeitete Zeilen pro Sekunde. Wenn die Zahl der Eingabezeilen pro Sekunde die Zahl der verarbeiteten Zeilen pro Sekunde überschreitet, bedeutet dies, dass das System zur Datenstromverarbeitung im Rückstand ist. Auch wenn die eingehenden Daten von Event Hubs oder Kafka stammen, sollte die Zahl der Eingabezeilen pro Sekunde mit der Datenerfassungsrate am Front-End Schritt halten.
Zwei Aufträge können einen ähnlichen Clusterdurchsatz, jedoch sehr unterschiedliche Streamingmetriken haben. Der folgende Screenshot zeigt zwei verschiedene Workloads. Sie sind im Hinblick auf den Clusterdurchsatz (Aufträge, Phasen und Aufgaben pro Minute) ähnlich. Aber der zweite verarbeitet 12.000 Zeilen/s gegenüber 4.000 Zeilen/s.
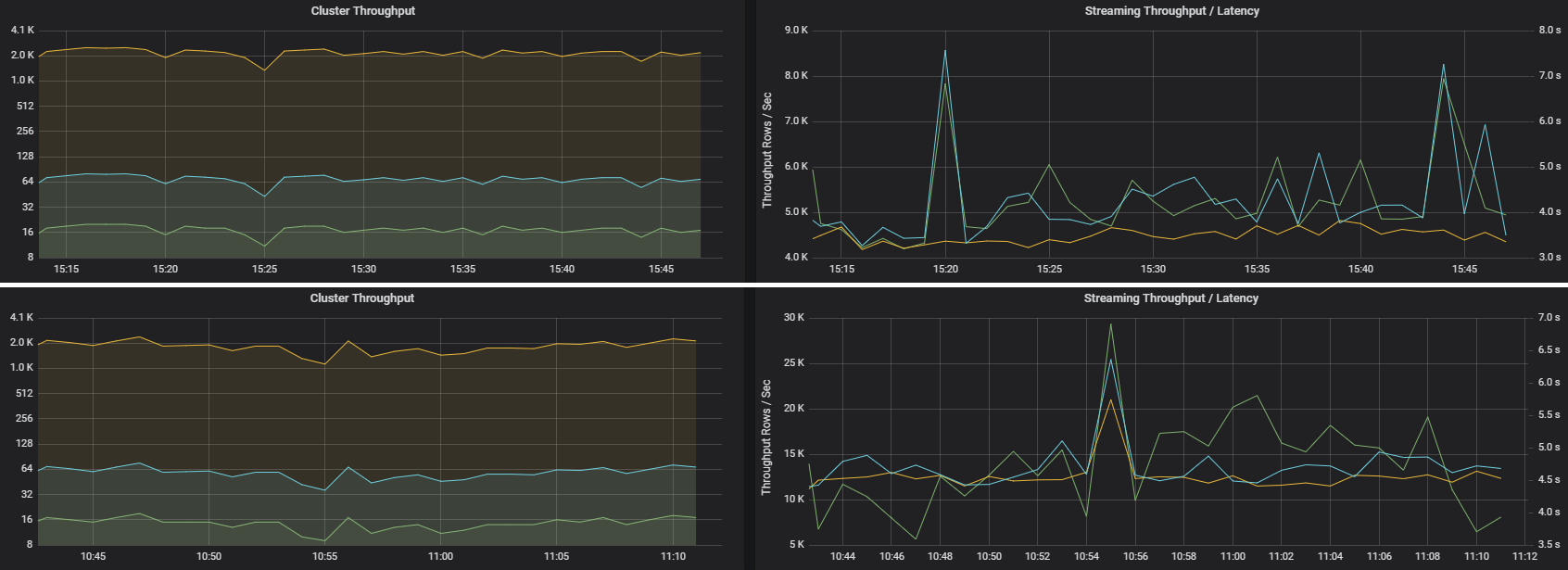
Der Streamingdurchsatz ist häufig eine bessere Geschäftsmetrik als der Clusterdurchsatz, da die Anzahl der verarbeiteten Datensätze gemessen wird.
Ressourcenverbrauch pro Executor
Diese Metriken helfen Ihnen, die Arbeit der einzelnen Executor zu verstehen.
Prozentuale Metriken messen, wie viel Zeit ein Executor für verschiedene Aktionen aufwendet, als Verhältnis der aufgewendeten Zeit zur gesamten Executorcomputezeit. Die Metriken sind:
- % Serialisierungszeit
- % Deserialisierungszeit
- % CPU-Executorzeit
- % JVM-Zeit
Diese Visualisierungen zeigen, wie viel jede dieser Metriken zur gesamten Executorverarbeitung beiträgt.
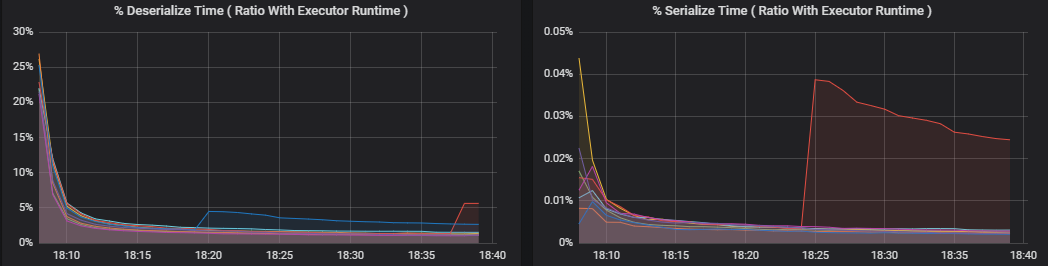
Shufflemetriken sind Metriken, die sich auf das Datenshuffling zwischen Executorn beziehen.
- Shuffle-E/A
- Shufflearbeitsspeicher
- Dateisystemnutzung
- Datenträgerauslastung
Häufige Leistungsengpässe
Zwei häufige Leistungsengpässe in Spark sind Aufgabennachzügler und eine nicht optimale Shufflepartitionszahl.
Aufgabennachzügler
Die Phasen in einem Auftrag werden nacheinander ausgeführt, wobei frühere Phasen spätere Phasen blockieren. Wenn eine Aufgabe eine Shufflepartition langsamer ausführt als andere Aufgaben, müssen alle Aufgaben im Cluster auf die langsame Aufgabe warten, bevor die Phase abgeschlossen werden kann. Dies kann aus folgenden Gründen geschehen:
Ein Host oder eine Gruppe von Hosts werden langsam ausgeführt. Symptome: Hohe Aufgaben-, Phasen- oder Auftragslatenz und niedriger Clusterdurchsatz. Die Summe der Aufgabenlatenzen pro Host wird nicht gleichmäßig verteilt. Der Ressourcenverbrauch wird jedoch gleichmäßig auf die Executor verteilt.
Aufgaben müssen eine aufwändige Aggregation (Datenschiefe) ausführen. Symptome: Hohe Aufgabenlatenz, hohe Phasenlatenz, hohe Auftragslatenz und niedriger Clusterdurchsatz, aber die Summe der Latenzen pro Host ist gleichmäßig verteilt. Der Ressourcenverbrauch wird gleichmäßig auf die Executor verteilt.
Wenn Partitionen nicht dieselbe Größe aufweisen, kann eine größere Partition eine unausgeglichene Aufgabenausführung (Partitionsschiefe) verursachen. Symptome: Der Executorressourcenverbrauch ist im Vergleich zu anderen im Cluster ausgeführten Executorn hoch. Alle auf diesem Executor ausgeführte Aufgaben werden langsam ausgeführt und halten die Phasenausführung in der Pipeline. Diese Phasen werden als Phasenbarrieren bezeichnet.
Nicht optimale Shufflepartitionszahl
Während einer Strukturiertes-Streaming-Abfrage ist die Zuweisung einer Aufgabe an einen Executor für den Cluster ein ressourcenintensiver Vorgang. Wenn die Größe der Shuffledaten nicht optimal ist, beeinträchtigt die Dauer der Verzögerung für eine Aufgabe Durchsatz und Latenz. Wenn zu wenige Partitionen vorhanden sind, werden die Kerne im Cluster nicht ausreichend ausgelastet, was zu Leistungseinbußen bei der Verarbeitung führen kann. Wenn andererseits zu viele Partitionen vorhanden sind, entsteht ein hoher Verwaltungsmehraufwand für eine kleine Anzahl von Aufgaben.
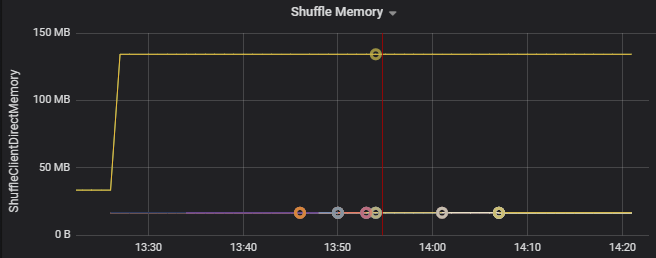
Verwenden Sie die Metriken zum Ressourcenverbrauch, um Partitionsschiefe und Fehlzuordnung von Executorn im Cluster zu beheben. Wenn eine Partition verzerrt ist, werden Executorressourcen im Vergleich zu anderen im Cluster ausgeführten Executorn erhöht.
Das folgende Diagramm zeigt beispielsweise, dass der für das Shuffling verwendete Arbeitsspeicher auf den ersten beiden Executorn 90-mal größer ist als auf den anderen Executorn:
Nächste Schritte
- Überwachen von Azure Databricks in einem Azure Log Analytics-Arbeitsbereich
- Lernpfad: Erstellen und Betreiben von Machine Learning-Lösungen mit Azure Databricks
- Dokumentation zu Azure Databricks
- Azure Monitor – Übersicht
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für