Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure
Steuern Sie den Verbrauch der von einer Anwendungsinstanz, einem einzelnen Mandanten oder einem gesamten Dienst verwendeten Ressourcen. Dies kann es dem System ermöglichen, weiterhin zu funktionieren und die Ziele auf Serviceebene (Service Level Objectives, SLOs) zu erfüllen, auch wenn eine Zunahme der Nachfrage eine extreme Belastung für Ressourcen stellt.
Kontext und Problem
Die Belastung einer Cloud-Anwendung variiert in der Regel im Laufe der Zeit, je nach Anzahl der aktiven Nutzer oder der Art der von ihnen ausgeführten Aktivitäten. Dies ist beispielsweise während den Geschäftszeiten der Fall, in denen aller Wahrscheinlichkeit nach mehr Benutzer aktiv sind, oder am Ende eines jeden Monats, an dem das System rechenintensive Analysen durchführen muss. Zudem kann es zu plötzlichen und unvorhergesehenen Aktivitätsspitzen kommen. Wenn die Verarbeitungsanforderungen des Systems die Kapazität der verfügbaren Ressourcen überschreiten, tritt eine schlechte Leistung auf und kann sogar fehlschlagen. Wenn das System einen vereinbarten Servicelevel erfüllen muss, kann ein solcher Ausfall untragbar sein.
Es gibt viele Strategien für den Umgang mit unterschiedlicher Last in der Cloud, je nach den Geschäftszielen für die Anwendung. Eine Strategie besteht darin, die bereitgestellten Ressourcen zu einem beliebigen Zeitpunkt durch automatische Skalierung an die Benutzeranforderungen anzupassen. Hierdurch können nicht nur Benutzeranforderungen konsistent erfüllt werden, sondern es werden gleichzeitig laufende Kosten optimiert. Die automatische Skalierung kann zwar die Bereitstellung weiterer Ressourcen auslösen, doch erfolgt diese Bereitstellung nicht sofort. Steigt die Nachfrage schnell, kann es innerhalb eines bestimmten Zeitfensters zu einem Ressourcendefizit kommen.
Lösung
Eine alternative Strategie zur automatischen Skalierung besteht darin, die Nutzung von Ressourcen durch Anwendungen bis zu einem bestimmten Grenzwert zuzulassen und diese bei Erreichen dieses Grenzwerts dann zu drosseln. Das System sollte die Ressourcennutzung überwachen, damit es bei Überschreitung des Schwellenwerts Anforderungen von einem oder mehreren Benutzern drosseln kann. Auf diese Weise kann das System weiterhin funktionieren und alle ziele auf Serviceebene (SLOs) erfüllen, die vorhanden sind. Weitere Informationen zur Überwachung der Ressourcennutzung finden Sie unter Instrumentierungs- und Telemetrieleitfaden.
Das System kann mehrere Drosselungsstrategien implementieren, wie etwa Folgende:
Ablehnung von Anforderungen eines einzelnen Benutzers, der in einem bestimmten Zeitraum bereits mehr als n-mal pro Sekunde auf System-APIs zugegriffen hat. Hierfür muss das System den Ressourcenverbrauch für jeden Mandanten oder Benutzer, der eine Anwendung ausführt, messen. Weitere Informationen finden Sie im Leitfaden zur Dienstmessung.
Deaktivieren oder Beschränken der Funktionalität ausgewählter nicht wesentlicher Dienste, sodass wesentliche Dienste ungehindert mit ausreichenden Ressourcen ausgeführt werden können. Wenn die Anwendung beispielsweise Videoausgaben streamt, kann sie zu einer geringeren Auflösung wechseln.
Abschwächen des Aktivitätsvolumens durch einen Lastenausgleich (diese Vorgehensweise wird unter Muster „Warteschlangenbasierter Lastenausgleich“ näher beschrieben). In einer mandantenfähigen Umgebung führt dieser Ansatz zu einer Leistungsverringerung für jeden Mandanten. Wenn das System eine Kombination von Mandanten mit unterschiedlichen SLAs unterstützen muss, können die Aufgaben für Mandanten mit hoher Priorität sofort durchgeführt werden. Anfragen für andere Mandanten können zurückgehalten und bearbeitet werden, wenn der Anfragenrückstand nachgelassen hat. Könnte das Muster 'Prioritätswarteschlange' helfen, diesen Ansatz zu implementieren, so ebenso auch das Offenlegen verschiedener Endpunkte für die unterschiedlichen Dienstniveaus/Prioritäten.
Verschieben von Operationen, die für Anwendungen oder Mandanten mit geringerer Priorität ausgeführt werden. Diese Vorgänge können angehalten oder beschränkt werden, wobei eine Ausnahme erzeugt wird, um den Mandanten darüber zu informieren, dass das System ausgelastet ist und der Vorgang später erneut wiederholt werden sollte.
Lassen Sie bei der Integration von Drittanbieterdiensten, deren Verfügbarkeit möglicherweise unsicher ist oder die ggf. Fehler zurückgeben, Vorsicht walten. Verringern Sie die Anzahl gleichzeitig verarbeiteter Anforderungen, damit sich die Protokolle nicht unnötig mit Fehlern füllen. So vermeiden Sie auch Kosten durch unnötige erneute Verarbeitungsversuche für Anforderungen, die aufgrund dieses Drittanbieterdiensts nicht erfolgreich sind. Wenn Anforderungen erfolgreich verarbeitet werden, können Sie wieder zur regulären, nicht gedrosselten Anforderungsverarbeitung zurückkehren. Eine der Bibliotheken, die diese Funktion implementieren, ist NServiceBus.
Die Abbildung zeigt ein Flächendiagramm zum Ressourcenverbrauch (eine Kombination aus Speicher, CPU, Bandbreite und anderen Faktoren) im Zeitverlauf für Anwendungen, die auf alle drei Funktionen zurückgreifen. Ein Feature ist ein Funktionsbereich wie etwa eine Komponente, die eine bestimmte Gruppe von Aufgaben ausführt, ein Codeausschnitt, der eine komplexe Berechnung durchführt, oder ein Element, das einen Dienst bereitstellt (z.B. ein In-Memory-Cache). Diese Features sind mit den Buchstaben A, B und C gekennzeichnet.
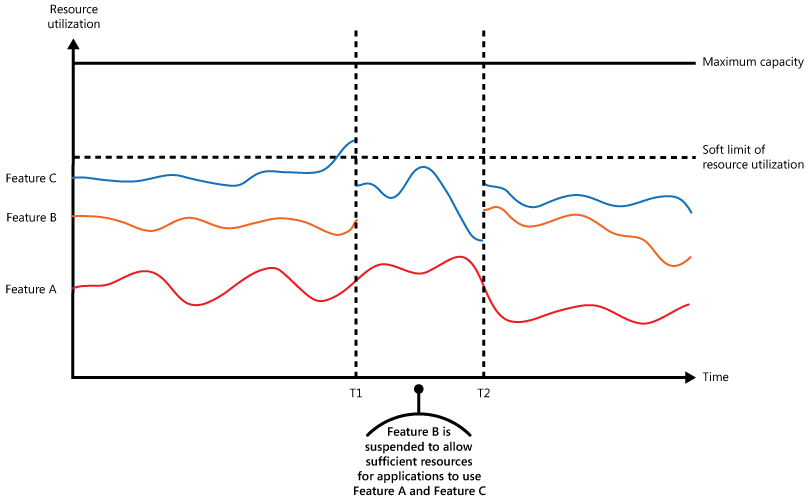
Der Bereich unmittelbar unter der Linie eines Features stellt die Ressourcen dar, die von Anwendungen beim Aufrufen dieses Features verwendet werden. Der Bereich unterhalb der Linie von Feature A beispielsweise stellt die Ressourcen dar, die von Anwendungen verwendet werden, die Feature A verwenden, während der Bereich zwischen den Linien von Feature A und Feature B die Ressourcen darstellt, die von Anwendungen verwendet werden, die Feature B aufrufen. Die aggregierten Bereiche der einzelnen Features stellen die gesamte Ressourcennutzung des Systems dar.
Die vorherige Abbildung zeigt die Auswirkungen des Aufschiebens von Operationen. Kurz vor der Zeit T1 erreichen die insgesamt für alle Anwendungen zugewiesenen Ressourcen, die diese Features verwenden, einen Schwellenwert. Dieser Schwellenwert stellt den Grenzwert für die Ressourcennutzung dar. An diesem Punkt besteht die Gefahr, dass Anwendungen die verfügbaren Ressourcen ausschöpfen. In diesem System ist Feature B weniger entscheidend als Feature A oder Feature C. Es wird daher vorübergehend deaktiviert, und die von diesem Feature verwendeten Ressourcen werden freigegeben. Im Zeitraum zwischen Zeitpunkt T1 und T2 werden die Anwendungen, die Feature A und Feature C verwenden, wie gewohnt ausgeführt. Letztendlich sinkt der Ressourcenverbrauch dieser beiden Features so weit, dass bei Zeitpunkt T2 genügend Kapazitäten für die erneute Aktivierung von Feature B vorhanden sind.
Die Vorgehensweisen zur automatischen Skalierung und Drosselung können auch kombiniert werden, um weiterhin die Reaktionsfähigkeit der Anwendungen und die Erfüllung der SLAs sicherzustellen. Wenn davon ausgegangen wird, dass die Nachfrage weiterhin hoch bleibt, stellt die Drosselung eine vorübergehende Lösung während der Erweiterung des Systems dar. Zu diesem Zeitpunkt kann die komplette Funktionalität des Systems wiederhergestellt werden.
Die folgende Abbildung zeigt ein Flächendiagramm zum gesamten Ressourcenverbrauch sämtlicher Anwendungen, die in einem bestimmten Zeitraum in einem System ausgeführt werden, und wie die Drosselung mit automatischer Skalierung kombiniert werden kann.
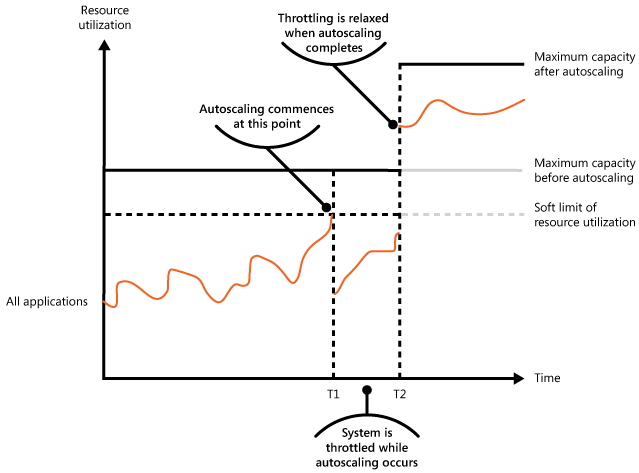
Bei Zeitpunkt T1 ist der Schwellenwert erreicht, der den weichen Grenzwert des Ressourcenverbrauchs angibt. An dieser Stelle kann das System mit der Aufskalierung beginnen. Wenn die neuen Ressourcen jedoch nicht schnell genug zur Verfügung stehen, werden die vorhandenen Ressourcen möglicherweise aufgebraucht, und das System könnte ausfallen. Um dies zu verhindern, wird das System wie zuvor beschrieben vorübergehend gedrosselt. Wenn die automatische Skalierung abgeschlossen ist und die zusätzlichen Ressourcen verfügbar sind, kann die Drosselung aufgehoben werden.
Probleme und Überlegungen
Bei der Entscheidung, wie dieses Muster implementiert werden soll, sind die folgenden Punkte zu beachten:
Die Drosselung einer Anwendung und die dafür gewählte Strategie ist eine Architekturentscheidung, die sich auf die gesamte Gestaltung eines Systems auswirkt. Bereits frühzeitig im Entwurfsprozess einer Anwendung sollte Throttling in Erwägung gezogen werden, da es schwierig ist, es hinzuzufügen, nachdem ein System implementiert wurde.
Eine Drosselung muss schnell erfolgen. Das System muss einen Aktivitätsanstieg erkennen und entsprechend darauf reagieren können. Das System muss außerdem in der Lage sein, zu seinem ursprünglichen Zustand zurückzukehren, sobald sich die Last verringert hat. Dies setzt voraus, dass die entsprechenden Leistungsdaten kontinuierlich erfasst und überwacht werden.
Wenn ein Dienst eine Benutzeranforderung vorübergehend ablehnen muss, sollte er einen spezifischen Fehlercode wie 429 („Zu viele Anforderungen“) und 503 („Server zu stark ausgelastet“) zurückgeben, damit die Clientanwendung verstehen kann, dass der Grund für die Ablehnung der Verarbeitung einer Anforderung eine Drosselung ist.
- HTTP 429 zeigt an, dass die aufrufende Anwendung zu viele Anforderungen in einem Zeitfenster gesendet hat und einen vordefinierten Grenzwert überschritten hat.
- HTTP 503 zeigt an, dass der Dienst nicht bereit ist, die Anforderung zu verarbeiten. Die häufigste Ursache ist, dass der Dienst vorübergehend mehr Lastspitzen als erwartet aufweist.
Die Clientanwendung wartet möglicherweise für einen gewissen Zeitraum, bis sie die Anforderung wiederholt. Ein Retry-After-HTTP-Header sollte eingeschlossen sein, um den Client bei der Auswahl der Wiederholungsstrategie zu unterstützen.
Die Drosselung kann als vorübergehende Maßnahme während der automatischen Skalierung eines Systems genutzt werden. In einigen Fällen ist es besser, eine Drosselung vorzunehmen, anstatt zu skalieren, wenn ein plötzlicher Anstieg der Aktivität eintritt und nicht von Dauer ist, da Skalierungen erheblich die laufenden Kosten erhöhen können.
Wenn während der automatischen Skalierung eines Systems eine Drosselung als vorübergehende Maßnahme verwendet wird und der Ressourcenbedarf sehr schnell ansteigt, kann das System möglicherweise nicht mehr funktionieren – selbst wenn es im gedrosselten Modus betrieben wird. Wenn dies nicht hinnehmbar ist, sollten Sie eventuell größere Kapazitätsreserven vorhalten und eine weitreichendere automatische Skalierung konfigurieren.
Normalisieren Sie die Ressourcenkosten für verschiedene Vorgänge, da diese im Allgemeinen nicht die gleichen Ausführungskosten verursachen. Beispielsweise können Drosselungsgrenzwerte für Lesevorgänge niedriger sein, für Schreibvorgänge aber höher. Wenn Sie die Kosten eines Vorgangs nicht berücksichtigen, kann dies dazu führen, dass die Kapazität erschöpft und ein potenzieller Angriffsvektor verfügbar gemacht wird.
Eine dynamische Änderung des Drosselungsverhaltens durch Konfigurationsänderungen zur Laufzeit wird als vorteilhaft betrachtet. Wenn ein System mit einer ungewöhnlichen Last konfrontiert ist, die die angewendete Konfiguration nicht bewältigen kann, müssen Drosselungsgrenzwerte möglicherweise erhöht oder verringert werden, um das System zu stabilisieren und mit dem aktuellen Datenverkehr Schritt zu halten. Teure, riskante und langsame Bereitstellungen sind an diesem Punkt nicht wünschenswert. Durch die Verwendung des Musters „Externer Konfigurationsspeicher“ wird die Drosselungskonfiguration externalisiert und kann ohne Bereitstellungen geändert und angewendet werden.
Wann Sie dieses Muster verwenden sollten
Verwenden Sie dieses Muster in folgenden Fällen:
Um sicherzustellen, dass ein System weiterhin die Service-Level-Ziele (SLOs) erfüllt.
Um zu verhindern, dass ein einzelner Mandant die von einer Anwendung bereitgestellten Ressourcen monopolisiert
Um Aktivitätsausbrüche zu bewältigen
Um die Kosten für ein System durch Beschränkung des maximalen Ressourcenbedarfs zu optimieren, der für die Aufrechterhaltung seiner Funktionsfähigkeit erforderlich ist
Um die Berechnungsverarbeitung mit geringem Wert in Zeiträumen mit hoher Kohlenstoffintensität im Energienetz zu reduzieren.
Workloadentwurf
Ein Architekt sollte bewerten, wie das Drosselungsmuster im Entwurf ihrer Arbeitsauslastung verwendet werden kann, um die Ziele und Prinzipien zu erfüllen, die in den Azure Well-Architected Framework-Säulen behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Sie legen die Grenzen so fest, dass eine Erschöpfung der Ressourcen, die zu Fehlfunktionen führen könnte, vermieden wird. Sie können dieses Muster auch als Kontrollmechanismus in einem Graceful-Degradation-Plan verwenden. - RE:07 Selbsterhaltung |
| Sicherheitsdesignentscheidungen tragen dazu bei, die Vertraulichkeit, Integrität und Verfügbarkeit der Daten und Systeme Ihrer Workload sicherzustellen. | Sie können die Grenzen so gestalten, dass eine Erschöpfung der Ressourcen, die durch einen automatischen Missbrauch des Systems entstehen könnte, verhindert wird. - SE:06 Netzwerksteuerungen - SE:08 Härtungsressourcen |
| Die Kostenoptimierung konzentriert sich darauf, die Rendite Ihrer Arbeitslast zu erhalten und zu verbessern. | Die erzwungenen Grenzen können in die Kostenmodellierung einfließen und sogar direkt mit dem Geschäftsmodell Ihrer Anwendung verknüpft werden. Sie setzen auch klare Obergrenzen für die Auslastung, die bei der Dimensionierung der Ressourcen berücksichtigt werden können. - CO:02 Kostenmodell - CO:12 Skalierungskosten |
| Die Leistungseffizienz unterstützt Ihre Workload dabei, Anforderungen effizient durch die Optimierung von Skalierung, Daten und Code zu erfüllen. | Wenn das System stark beansprucht wird, trägt dieses Muster dazu bei, Überlastungen zu vermeiden, die zu Leistungsengpässen führen können. Sie können damit auch proaktiv laute Nachbarschaftsszenarien vermeiden. - PE:02 Kapazitätsplanung - PE:05 Skalierung und Partitionierung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
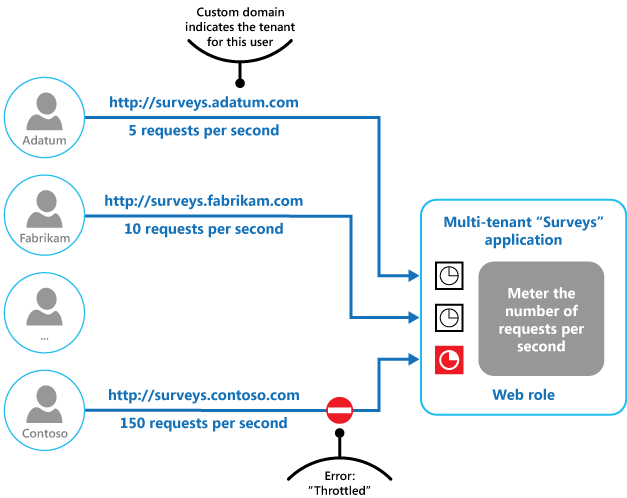
Die letzte Abbildung zeigt, wie die Drosselung in einem mandantenfähigen System umgesetzt werden kann. Benutzer der einzelnen Mandantenorganisationen greifen auf eine in der Cloud gehostete Anwendung zu, in der sie Umfragen ausfüllen und einreichen. Die Anwendung beinhaltet eine Instrumentierung, die die Geschwindigkeit überwacht, mit der diese Benutzer Anforderungen an die Anwendung senden.
Um zu verhindern, dass Benutzer eines Mandanten die Reaktionsfähigkeit und Verfügbarkeit der Anwendung für alle anderen Benutzer beeinträchtigen, wird die Anzahl der Anforderungen, die die Benutzer eines beliebigen Mandanten pro Sekunde senden können, begrenzt. Die Anwendung blockiert Anforderungen, die diesen Grenzwert überschreiten.
Nächste Schritte
Die folgenden Richtlinien sind unter Umständen beim Implementieren dieses Musters ebenfalls relevant:
- Instrumentations- und Telemetrieanleitungen. Die Drosselung hängt davon ab, Informationen darüber zu sammeln, wie stark ein Dienst genutzt wird. Dieser Leitfaden beschreibt, wie benutzerdefinierte Überwachungsinformationen generiert und erfasst werden.
- Leitfaden zur Dienstmessung: Beschreibt, wie man die Nutzung von Diensten misst, um zu verstehen, wie sie genutzt werden. Diese Informationen können als Entscheidungshilfe zur Auswahl einer Drosselungsmethode für einen Dienst dienen.
- Leitfaden für die automatische Skalierung. Die Drosselung kann als Übergangsmaßnahme während der automatischen Skalierung eines Systems verwendet werden oder um die Notwendigkeit der automatischen Skalierung eines Systems zu vermeiden. Dieser Leitfaden enthält Informationen über Strategien zur automatischen Skalierung.
Zugehörige Ressourcen
Die folgenden Muster sind unter Umständen bei der Implementierung dieses Musters ebenfalls relevant:
- Muster für Warteschlangen-basierten Lastenausgleich. Ein warteschlangenbasiertes Lastverteilungskonzept ist ein häufig verwendeter Mechanismus zur Implementierung der Drosselung. Eine Warteschlange kann als Puffer herangezogen werden, um die Geschwindigkeit auszugleichen, mit der die von einer Anwendung gesendeten Anforderungen an einen Dienst gesendet werden.
- Muster „Prioritätswarteschlange“: Ein System kann im Rahmen seiner Drosselungsstrategie Prioritätswarteschlangen einsetzen, um die Leistung von kritischen oder höherwertigen Anwendungen aufrechtzuerhalten und gleichzeitig die von weniger wichtigen Anwendungen zu reduzieren.
- Muster „Externer Konfigurationsspeicher“ Die Zentralisierung und Externalisierung der Drosselungsrichtlinien bietet die Möglichkeit, die Konfiguration zur Laufzeit zu ändern, ohne dass eine erneute Bereitstellung erforderlich ist. Dienste können Konfigurationsänderungen abonnieren, die die neue Konfiguration sofort anwenden, um ein System zu stabilisieren.