Tutorial: Verwenden von Azure Cache for Redis als semantischen Cache
In diesem Tutorial verwenden Sie Azure Cache for Redis als semantischen Cache mit einem KI-basierten großen Sprachmodell (LLM). Sie verwenden Azure OpenAI Service, um LLM-Antworten für Abfragen zu generieren und diese Antworten mithilfe von Azure Cache for Redis zwischenzuspeichern, um schnellere Antworten bereitzustellen und Kosten zu senken.
Da Azure Cache for Redis integrierte Vektorsuchfunktionen bietet, können Sie auch semantisches Zwischenspeichern ausführen. Sie können zwischengespeicherte Antworten für identische Abfragen und auch für Abfragen zurückgeben, die eine ähnliche Bedeutung haben, auch wenn der Text nicht identisch ist.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen einer für semantisches Zwischenspeichern konfigurierten Azure Cache for Redis-Instanz
- Verwenden Sie LangChain oder andere beliebte Python-Bibliotheken.
- Verwenden Sie Azure OpenAI Service, um Text aus KI-Modellen zu generieren und Ergebnisse zwischenzuspeichern.
- Sehen Sie sich die Leistungsverbesserungen bei der Verwendung der Zwischenspeicherung mit LLMs an.
Wichtig
In diesem Tutorial wird das Erstellen einer Jupyter Notebook-Instanz erläutert. Sie können dieses Tutorial mit einer Python-Codedatei (.py) durchführen und ähnliche Ergebnisse erhalten. Sie müssen jedoch alle Codeblöcke in diesem Tutorial der .py-Datei hinzufügen und einmal ausführen, um Ergebnisse anzuzeigen. Mit anderen Worten: Jupyter Notebook-Instanzen stellen beim Ausführen von Zellen Zwischenergebnisse bereit, dieses Verhalten sollten Sie jedoch nicht beim Arbeiten in einer Python-Codedatei erwarten.
Wichtig
Wenn Sie das Tutorial stattdessen mithilfe einer fertigen Jupyter Notebook-Instanz ausführen möchten, laden Sie die Jupyter Notebook-Datei mit dem Namen semanticcache.ipynb herunter, und speichern Sie sie im neuen Ordner semanticcache.
Voraussetzungen
Azure-Abonnement: Kostenloses Azure-Konto
Zugriff auf Azure OpenAI im gewünschten Azure-Abonnement gewährt. Derzeit müssen Sie Zugriff auf Azure OpenAI beantragen. Sie können den Zugriff auf Azure OpenAI beantragen, indem Sie das Formular unter https://aka.ms/oai/access ausfüllen.
Jupyter Notebook-Instanzen (optional)
Eine Azure OpenAI-Ressource mit den bereitgestellten Modellen text-embedding-ada-002 (Version 2) und gpt-35-turbo-instruct. Diese Modelle sind derzeit nur in bestimmten Regionen verfügbar. Anweisungen zum Bereitstellen der Modelle finden Sie im Leitfaden zur Ressourcenbereitstellung.
Erstellen einer Azure Cache for Redis-Instanz
Befolgen Sie den Leitfaden unter Schnellstart: Erstellen einer Redis Cache-Instanz. Stellen Sie auf der Seite Erweitert sicher, dass Sie das Modul RediSearch hinzugefügt und die Clusterrichtlinie Enterprise ausgewählt haben. Alle anderen Einstellungen können den in der Schnellstartanleitung beschriebenen Standardeinstellung entsprechen.
Das Erstellen des Cache dauert einige Minuten. In der Zwischenzeit können Sie mit dem nächsten Schritt fortfahren.
Einrichten der Entwicklungsumgebung
Erstellen Sie auf Ihrem lokalen Computer einen Ordner namens semanticcache an dem Speicherort, an dem Sie Ihre Projekte normalerweise speichern.
Erstellen Sie eine neue Python-Datei (tutorial.py) oder eine Jupyter Notebook-Instanz (tutorial.ipynb) im Ordner.
Installieren Sie die erforderlichen Python-Pakete:
pip install openai langchain redis tiktoken
Erstellen von Azure OpenAI-Modellen
Stellen Sie sicher, dass Sie zwei Modelle in Ihrer Azure OpenAI-Ressource bereitgestellt haben:
Ein LLM, das Textantworten bereitstellt. Wir verwenden das Modell GPT-3.5-turbo-instruct für dieses Tutorial.
Ein Einbettungsmodell, das Abfragen in Vektoren konvertiert, damit sie mit früheren Abfragen verglichen werden können. Wir verwenden das Modell text-embedding-ada-002 (Version 2) für dieses Tutorial.
Ausführlichere Anweisungen finden Sie unter Bereitstellen eines Modells. Notieren Sie den Namen, den Sie für jede Modellimplementierung ausgewählt haben.
Importieren von Bibliotheken und Einrichten von Verbindungsinformationen
Für erfolgreiche Azure OpenAI-Aufrufe benötigen Sie einen Endpunkt und einen Schlüssel. Sie benötigen außerdem einen Endpunkt und einen Schlüssel, um eine Verbindung mit Azure Cache for Redis herzustellen.
Wechseln Sie im Azure-Portal zu Ihrer Azure OpenAI-Ressource.
Suchen Sie Endpunkt und Schlüssel im Abschnitt Ressourcenverwaltung der Azure OpenAI-Ressource. Kopieren Sie den Endpunkt und den Zugriffsschlüssel, da Sie beide für die Authentifizierung Ihrer API-Aufrufe benötigen. Ein Beispielendpunkt ist
https://docs-test-001.openai.azure.com. Sie könnenKEY1oderKEY2verwenden.Navigieren Sie im Azure-Portal zur Seite Übersicht Ihrer Azure Cache for Redis-Ressource. Kopieren Sie Ihren Endpunkt.
Suchen Sie im Abschnitt Einstellungen nach Zugriffsschlüssel. Kopieren Sie Ihren Zugriffsschlüssel. Sie können
PrimaryoderSecondaryverwenden.Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Aktualisieren Sie den Wert von
API_KEYundRESOURCE_ENDPOINTmit den Schlüssel- und Endpunktwerten aus Ihrer Azure OpenAI-Bereitstellung.Legen Sie
LLM_DEPLOYMENT_NAMEundEMBEDDINGS_DEPLOYMENT_NAMEauf den Namen Ihrer beiden Modelle fest, die in Azure OpenAI Service bereitgestellt sind.Aktualisieren Sie
REDIS_ENDPOINTundREDIS_PASSWORDmit dem Endpunkt- und dem Schlüsselwert aus der Azure Cache for Redis-Instanz.Wichtig
Es wird dringend empfohlen, Umgebungsvariablen oder einen Geheimnis-Manager wie Azure Key Vault zu verwenden, um den API-Schlüssel, den Endpunkt und den Bereitstellungsnamen zu übergeben. Diese Variablen werden hier der Einfachheit halber als Klartext festgelegt.
Führen Sie Codezelle 2 aus.
Initialisieren von KI-Modellen
Als Nächstes initialisieren Sie das LLM und das Einbettungsmodell.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Führen Sie Codezelle 3 aus.
Einrichten von Redis als semantischen Cache
Geben Sie als Nächstes Redis als semantischen Cache für Ihr LLM an.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Wichtig
Der Wert des Parameters
score_thresholdbestimmt, wie ähnlich zwei Abfragen sein müssen, um ein zwischengespeichertes Ergebnis zurückzugeben. Je niedriger die Zahl ist, desto ähnlicher müssen die Abfragen sein. Sie können mit diesem Wert spielen, um ihn für Ihre Anwendung zu optimieren.Führen Sie Codezelle 4 aus.
Abfragen und Abrufen von Antworten vom LLM
Fragen Sie schließlich das LLM ab, um eine KI-generierte Antwort zu erhalten. Wenn Sie eine Jupyter Notebook-Instanz verwenden, können Sie oben in der Zelle %%time hinzufügen, um die für die Ausführung des Codes aufgewendete Zeit auszugeben.
Fügen Sie einer neuen Codezelle den folgenden Code hinzu, und führen Sie ihn aus:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)Daraufhin sollte eine Ausgabe ähnlich der folgenden angezeigt werden:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sWall timegibt einen Wert von 2,67 Sekunden an. So lange hat es tatsächlich gedauert, das LLM abzufragen und eine Antwort durch das LLM zu generieren.Führen Sie Zelle 5 erneut aus. Sie sollten die gleiche Ausgabe sehen, aber mit einer kürzeren tatsächlichen Zeit:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msDie tatsächliche Zeit scheint um einen Faktor von fünf verkürzt zu sein – bis zu 575 Millisekunden.
Ändern Sie die Abfrage von
Please write a poem about cute kittensinWrite a poem about cute kittens, und führen Sie Zelle 5 erneut aus. Sie sollten genau die gleiche Ausgabe und eine kürzere tatsächliche Zeit als für die ursprüngliche Abfrage sehen. Obwohl sich die Abfrage geändert hat, blieb die semantische Bedeutung der Abfrage unverändert, sodass die gleiche zwischengespeicherte Ausgabe zurückgegeben wurde. Dies ist der Vorteil des semantischen Zwischenspeicherns.
Ändern des Schwellenwerts für die Ähnlichkeit
Versuchen Sie, eine ähnliche Abfrage mit einer anderen Bedeutung auszuführen, z. B.
Please write a poem about cute puppies. Beachten Sie, dass auch hier das zwischengespeicherte Ergebnis zurückgegeben wird. Die semantische Bedeutung des Wortspuppiesist nah genug an der des Wortskittens, sodass das zwischengespeicherte Ergebnis zurückgegeben wird.Der Schwellenwert für die Ähnlichkeit kann geändert werden, um zu bestimmen, wann der semantische Cache ein zwischengespeichertes Ergebnis zurückgeben soll und wann eine neue Ausgabe aus dem LLM zurückgegeben werden soll. Ändern Sie in Codezelle 4
score_thresholdvon0.05in0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Führen Sie die Abfrage
Please write a poem about cute puppiesdann erneut aus. Sie sollten eine neue Ausgabe erhalten, die sich auf Welpen bezieht:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sWahrscheinlich müssen Sie den Schwellenwert für die Ähnlichkeit basierend auf Ihrer Anwendung optimieren, um sicherzustellen, dass die richtige Empfindlichkeit verwendet wird, wenn Sie bestimmen, welche Abfragen zwischengespeichert werden sollen.
Bereinigen von Ressourcen
Wenn Sie die in diesem Artikel erstellten Ressourcen weiterhin verwenden möchten, behalten Sie die Ressourcengruppe bei.
Wenn Sie die Ressourcen nicht mehr benötigen, können Sie die erstellte Azure-Ressourcengruppe ansonsten löschen, um Kosten im Zusammenhang mit den Ressourcen zu vermeiden.
Warnung
Das Löschen einer Ressourcengruppe kann nicht rückgängig gemacht werden. Beim Löschen einer Ressourcengruppe werden alle darin enthaltenen Ressourcen unwiderruflich gelöscht. Achten Sie daher darauf, dass Sie nicht versehentlich die falsche Ressourcengruppe oder die falschen Ressourcen löschen. Falls Sie die Ressourcen in einer vorhandenen Ressourcengruppe erstellt haben, die Ressourcen enthält, die Sie behalten möchten, können Sie anstelle der Ressourcengruppe jede Ressource einzeln löschen.
Löschen einer Ressourcengruppe
Melden Sie sich beim Azure-Portal an, und wählen Sie anschließend Ressourcengruppen aus.
Wählen Sie die zu löschende Ressourcengruppe aus.
Wenn viele Ressourcengruppen vorhanden sind, verwenden Sie das Feld Nach einem beliebigen Feld filtern, und geben Sie den Namen der Ressourcengruppe ein, die Sie für diesen Artikel erstellt haben. Wählen Sie in der Liste der Suchergebnisse die Ressourcengruppe aus.
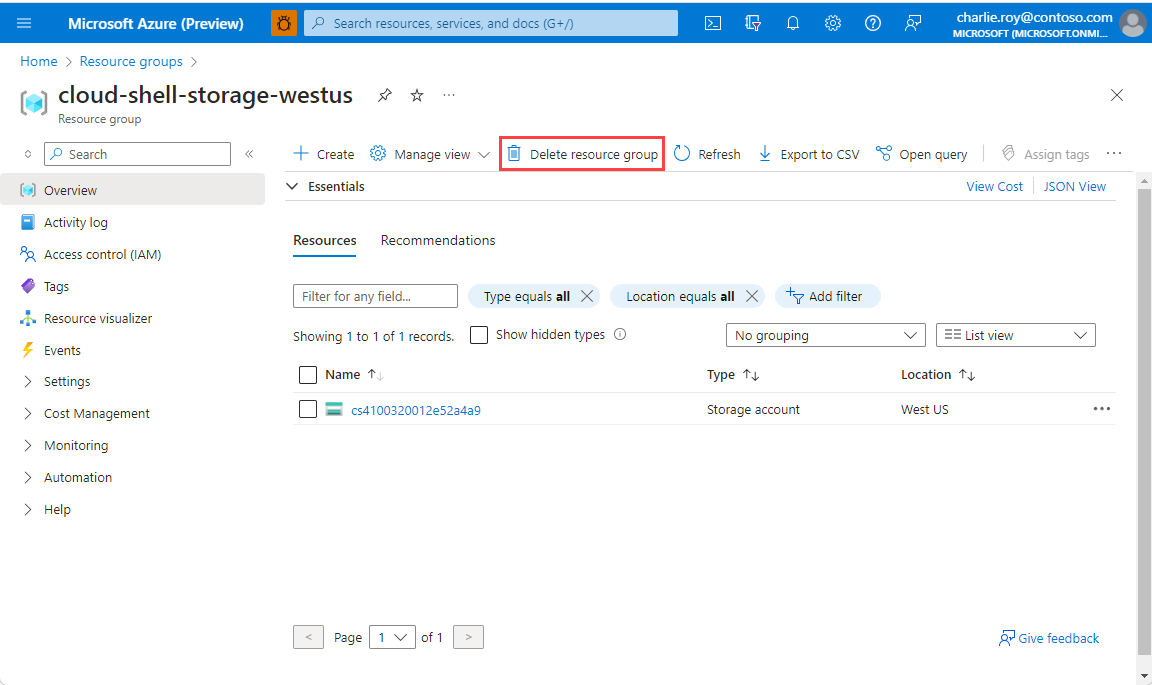
Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie im Bereich Ressourcengruppe löschen zur Bestätigung den Namen Ihrer Ressourcengruppe ein, und wählen Sie dann Löschen aus.
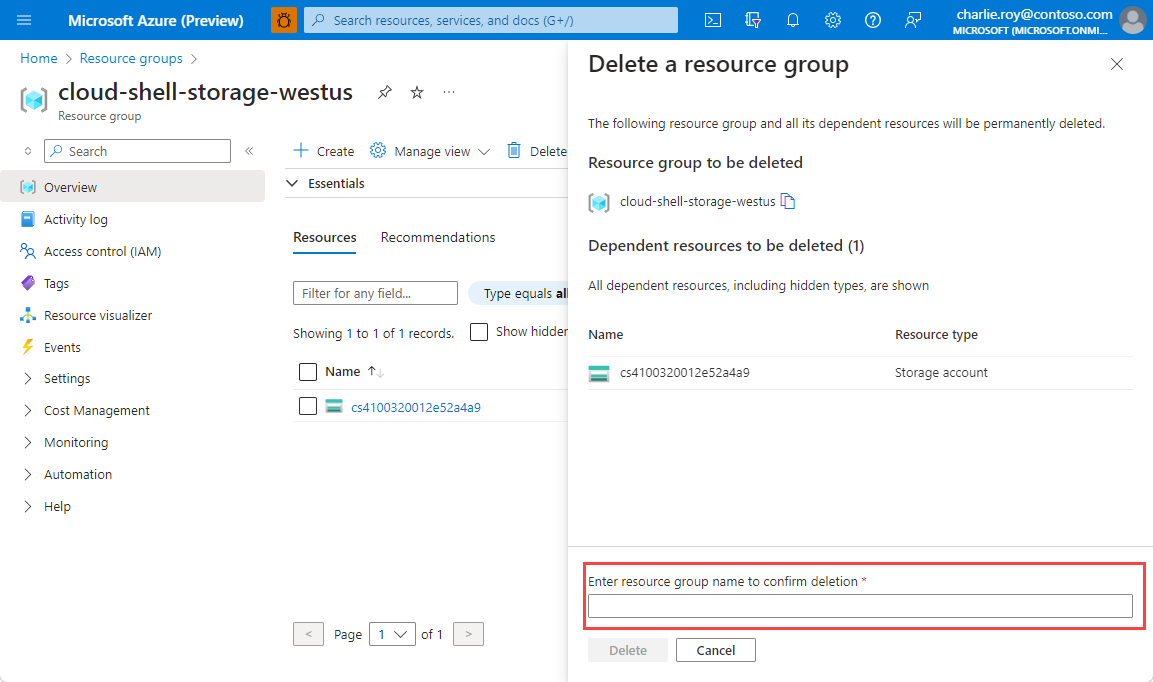
Innerhalb kurzer Zeit werden die Ressourcengruppe und alle darin enthaltenen Ressourcen gelöscht.
Zugehöriger Inhalt
- Weitere Informationen zu Azure Cache for Redis
- Weitere Informationen zu Azure Cache for Redis-Vektorsuchfunktionen finden Sie hier.
- Tutorial: Verwenden der Vektorähnlichkeitssuche in Azure Cache for Redis
- Erfahren Sie, wie Sie eine KI-gestützte App mit OpenAI und Redis erstellen.
- Erstellen einer Q&A-App mit semantischen Antworten