Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Warnungen in Azure Monitor identifizieren proaktiv Probleme im Zusammenhang mit der Integrität und Leistung Ihrer Azure-Ressourcen. In diesem Artikel wird beschrieben, wie Sie eine Reihe empfohlener metrischer Warnungsregeln aktivieren und bearbeiten, die für Ihre Kubernetes-Cluster vordefiniert sind.
Aktivieren empfohlener Warnungsregeln
Verwenden Sie eine der folgenden Methoden, um die empfohlenen Warnungsregeln für Ihren Cluster zu aktivieren. Sie können sowohl Prometheus- als auch Plattformmetrik-Warnungsregeln für denselben Cluster aktivieren.
Hinweis
Empfohlene Warnungen für Arc-fähige Kubernetes-Cluster befinden sich in der Vorschauphase und unterstützen keine Plattformmetrik-Alarmregeln.
Mithilfe des Azure-Portals wird die Prometheus-Regelgruppe in derselben Region wie der Cluster erstellt.
Wählen Sie im Menü Warnungen für Ihren Cluster Empfehlungen einrichten aus.
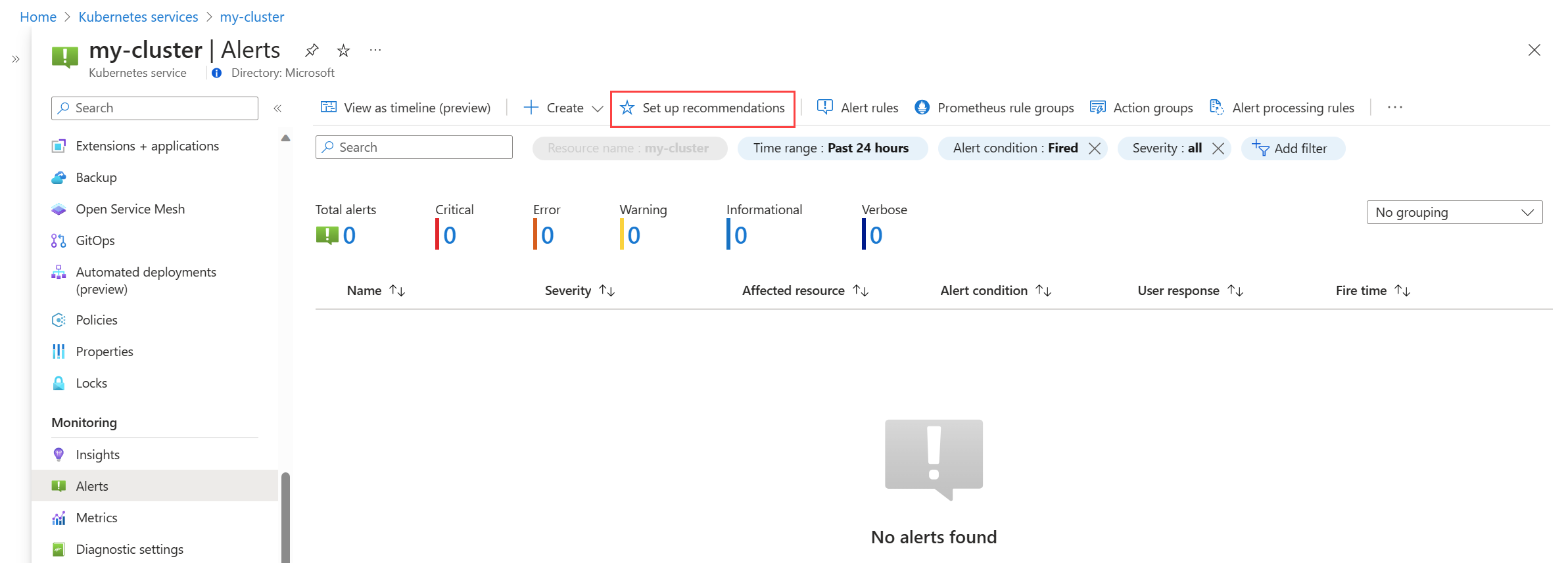
Die verfügbaren Prometheus- und Plattform-Warnungsregeln werden angezeigt, wobei die Prometheus-Regeln nach Pod-, Cluster- und Knotenebene geordnet sind. Aktivieren Sie eine Gruppe von Prometheus-Regeln, um diese Regelgruppe zu aktivieren. Erweitern Sie die Gruppe, um die einzelnen Regeln anzuzeigen. Sie können die Standardwerte beibehalten oder einzelne Regeln deaktivieren und deren Namen und Schweregrad bearbeiten.

Schalten Sie eine Plattformmetrikregel ein, um diese Regel zu aktivieren. Sie können die Regel erweitern, um die Details wie Name, Schweregrad und Schwellenwert zu ändern.
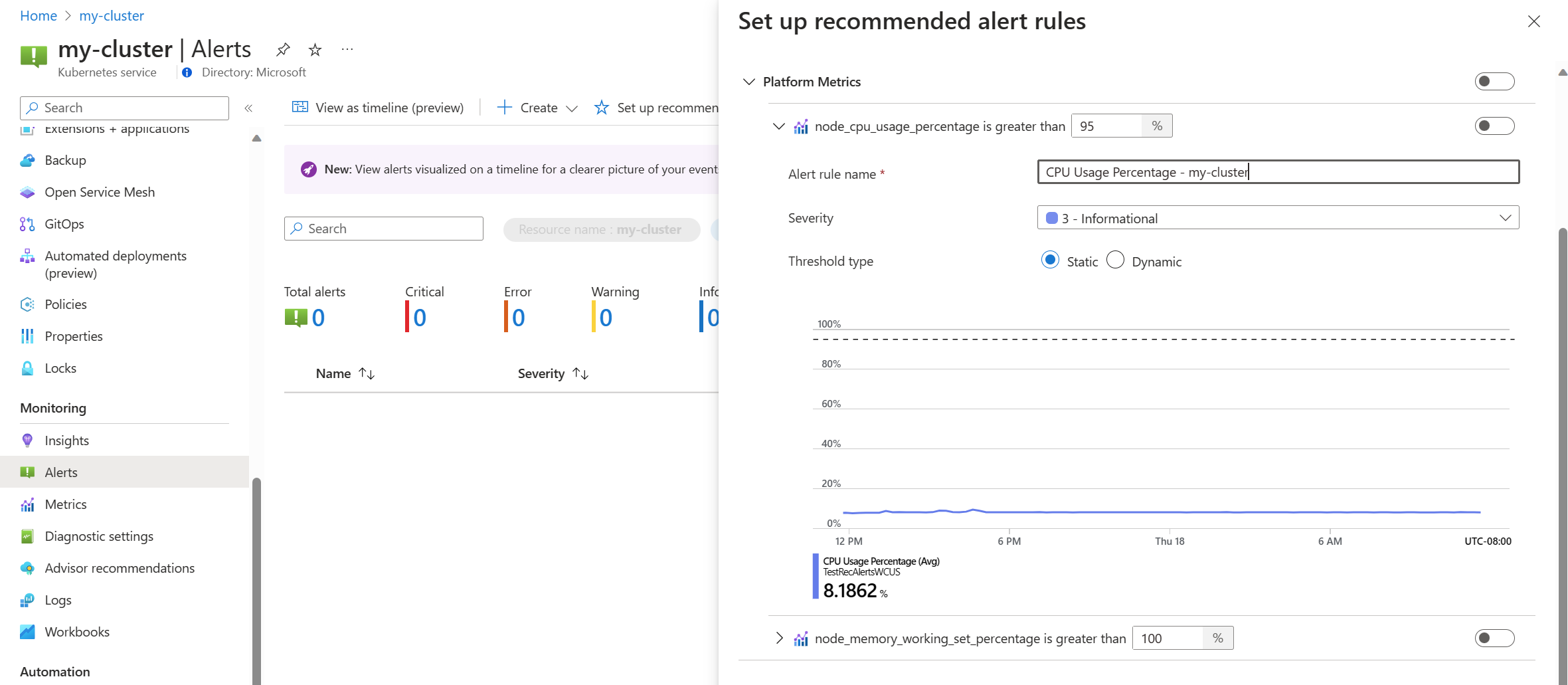
Wählen Sie entweder eine oder mehrere Benachrichtigungsmethoden aus, um eine neue Aktionsgruppe zu erstellen, oder wählen Sie eine vorhandene Aktionsgruppe mit den Benachrichtigungsdetails für diese Gruppe von Warnungsregeln aus.
Klicken Sie auf Speichern, um die Regelgruppe zu speichern.



Empfohlene Warnungsregeln bearbeiten
Nachdem die Regelgruppe erstellt wurde, können Sie nicht dieselbe Seite im Portal verwenden, um die Regeln zu bearbeiten. Für Prometheus-Metriken müssen Sie die Regelgruppe bearbeiten, um alle darin enthaltenen Regeln zu ändern, einschließlich der Aktivierung von noch nicht aktivierten Regeln. Für Plattformmetriken können Sie jede Warnungsregel bearbeiten.
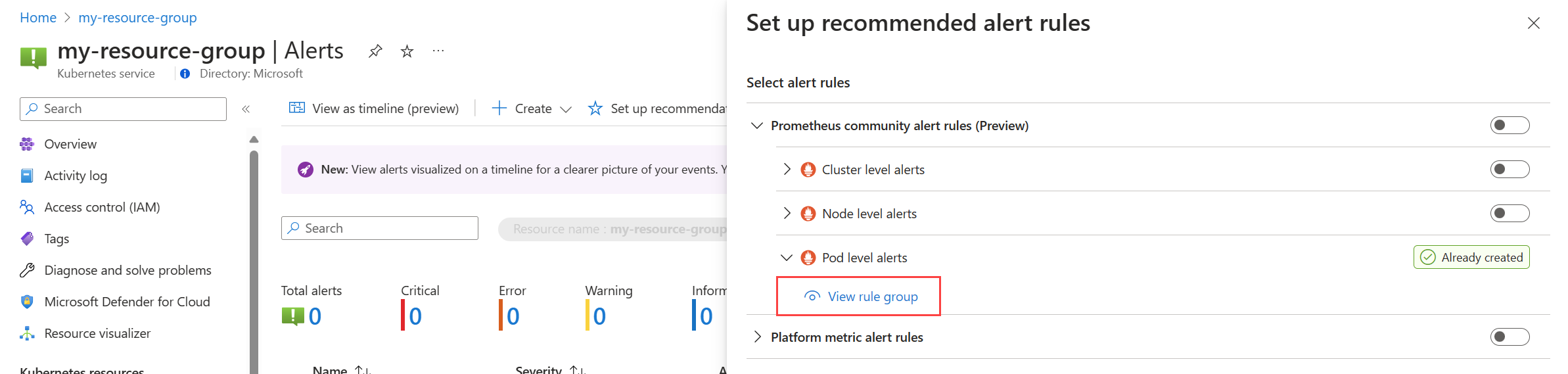
Wählen Sie im Menü Warnungen für Ihren Cluster Empfehlungen einrichten aus. Alle Regeln oder Regelgruppen, die bereits erstellt wurden, werden als Bereits erstellt bezeichnet.
Erweitern Sie die Regel- oder Regelgruppe. Klicken Sie auf Regelgruppe anzeigen für Prometheus und Warnungsregel anzeigen für Plattformmetriken.
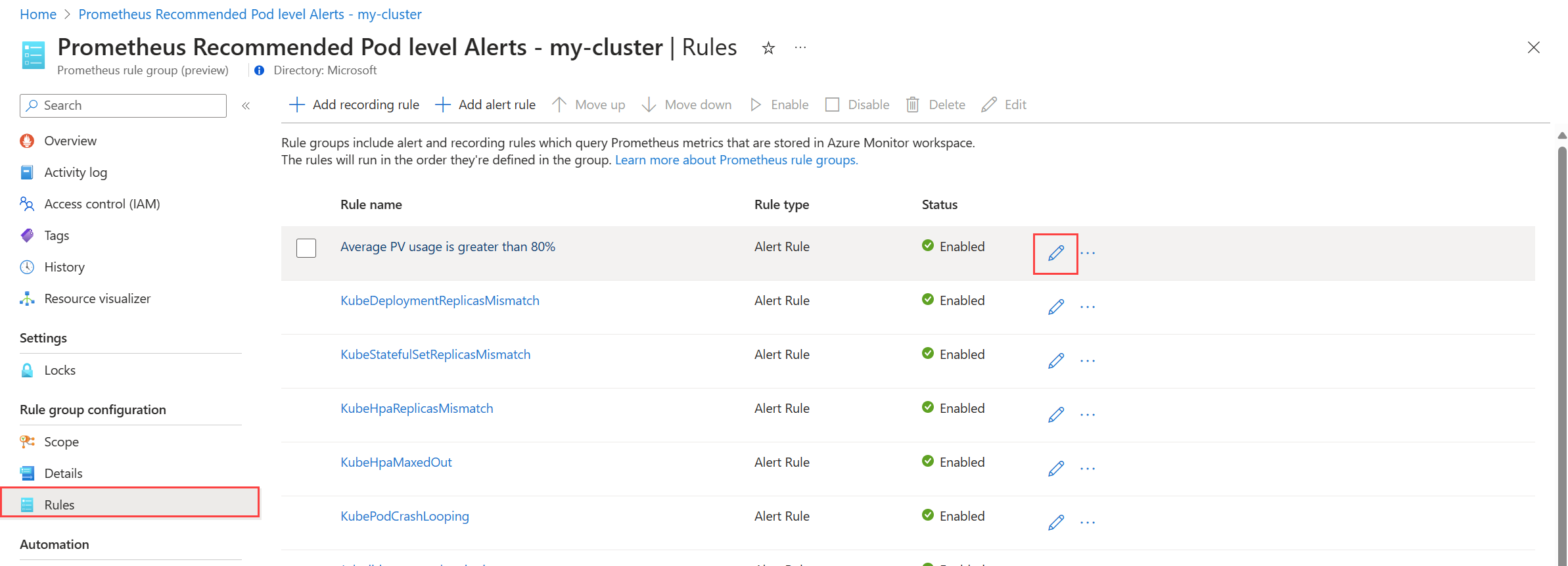
Für Prometheus-Regelgruppen:
wählen Sie Regeln aus, um die Warnungsregeln in der Gruppe anzuzeigen.
Klicken Sie auf das Symbol Bearbeiten neben einer Regel, die Sie ändern möchten. Verwenden Sie den Leitfaden unter Erstellen einer Warnungsregel, um die Regel zu ändern.
Wenn Sie die Bearbeitungsregeln in der Gruppe abgeschlossen haben, klicken Sie auf Speichern, um die Regelgruppe zu speichern.
Für Plattformmetriken:
Klicken Sie auf Bearbeiten, um die Details für die Warnungsregel zu öffnen. Verwenden Sie den Leitfaden unter Erstellen einer Warnungsregel, um die Regel zu ändern.




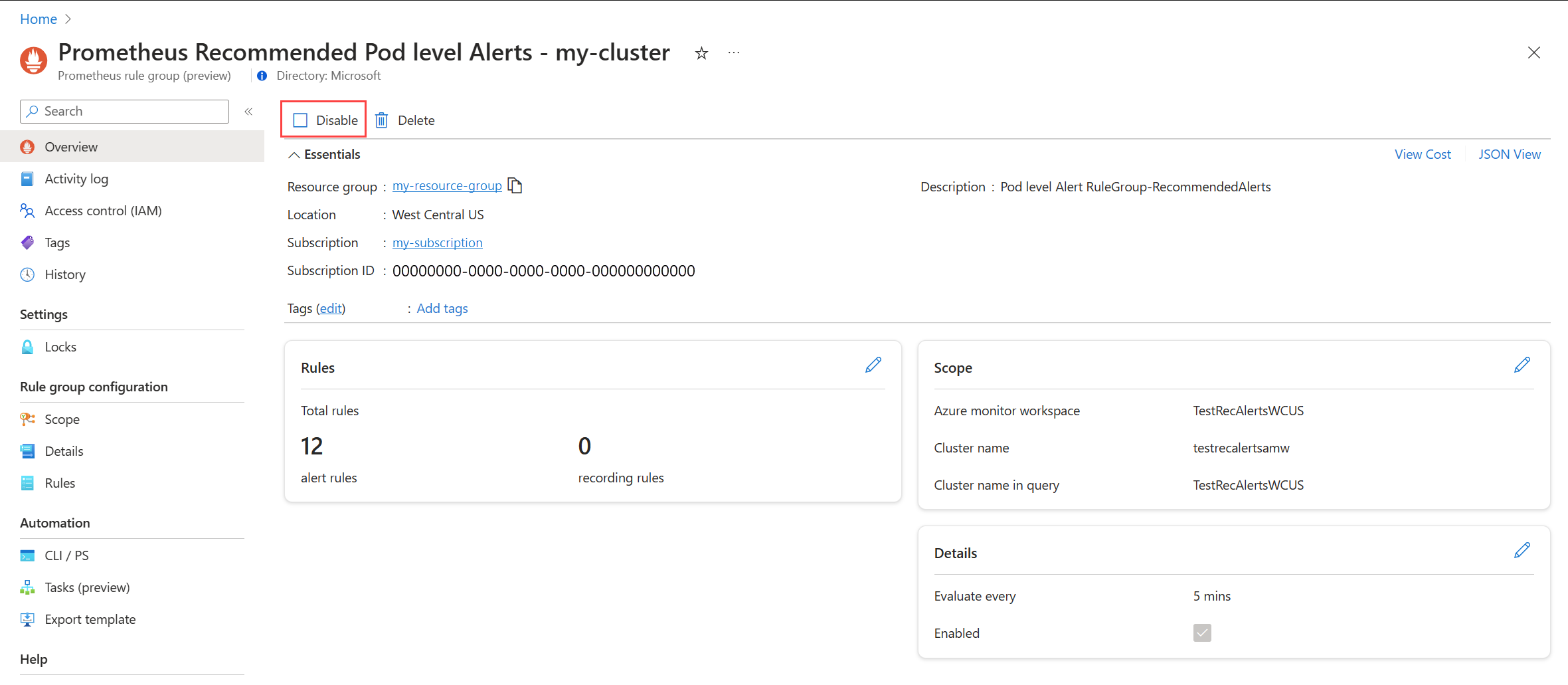
Alarmregelgruppe deaktivieren
Deaktivieren Sie die Regelgruppe, um den Empfang von Warnungen von den darin enthaltenen Regeln zu beenden.
Zeigen Sie die Prometheus-Warnungsregelgruppe oder plattformmetrische Warnungsregel an, wie in Empfohlene Warnungsregeln bearbeiten beschrieben.
Wählen Sie im Menü Übersicht die Option Deaktivieren aus.

Empfohlene Warnungsregeldetails
In den folgenden Tabellen sind die Details jeder empfohlenen Warnungsregel aufgeführt. Quellcode für jedes ist in GitHub zusammen mit Anleitungen zur Problembehandlung aus der Prometheus-Community verfügbar.
Prometheus Gemeinschafts-Alarmregeln
Warnungen auf Clusterebene
| Warnungsname | Beschreibung | Standardschwellenwert | Zeitrahmen (Minuten) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Das den Namespaces zugewiesene CPU-Ressourcenkontingent übersteigt die verfügbaren CPU-Ressourcen auf den Knoten des Clusters in den letzten 5 Minuten um mehr als 50 %. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Das den Namespaces zugewiesene Speicherressourcenkontingent übersteigt die verfügbaren Speicherressourcen auf den Knoten des Clusters in den letzten 5 Minuten um mehr als 50 %. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Ein oder mehrere Container innerhalb von Pods wurden in den letzten 5 Minuten aufgrund von OOM-Ereignissen (Out-of-Memory) beendet. | >0 | 5 |
| KubeClientErrors | Die Rate der Clientfehler (HTTP-Statuscodes beginnend mit 5xx) in Kubernetes-API-Anforderungen überschreitet 1 % der gesamten API-Anforderungsrate für die letzten 15 Minuten. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Der persistente Datenträger füllt sich und es wird erwartet, dass der verfügbare Speicherplatz bald erschöpft sein wird. Dies wird anhand des Verhältnisses von verfügbarem Speicherplatz, genutztem Speicherplatz und dem vorhergesagten linearen Trend des verfügbaren Speicherplatzes in den letzten 6 Stunden ermittelt. Diese Bedingungen werden in den letzten 60 Minuten ausgewertet. | Nicht verfügbar/Keine Angabe | 60 |
| KubePersistentVolumeInodesFillingUp | Weniger als 3 % der I-Knoten in einem persistenten Datenträger sind in den letzten 15 Minuten verfügbar. | <0.03 | 15 |
| Fehler bei KubePersistentVolume | Mindestens ein persistenter Datenträger befindet sich in einer fehlgeschlagenen oder ausstehenden Phase in den letzten 5 Minuten. | >0 | 5 |
| KubeContainerWaiting | Ein oder mehrere Container innerhalb von Kubernetes-Pods befinden sich seit 60 Minuten in einem Wartezustand. | >0 | 60 |
| KubeDaemonSetNotScheduled | Ein oder mehrere Pods sind auf keinem Knoten für die letzten 15 Minuten eingeplant. | >0 | 15 |
| KubeDaemonSetFehlgeplant | Ein oder mehrere Pods sind innerhalb des Clusters für die letzten 15 Minuten falsch eingeplant. | >0 | 15 |
| KubeQuotaAlmostFull | Die Auslastung der Kubernetes-Ressourcenkontingente liegt in den letzten 15 Minuten zwischen 90 % und 100 % der harten Grenzwerte. | >0.9 <1 | 15 |
Warnungen auf Knotenebene
| Warnungsname | Beschreibung | Standardschwellenwert | Zeitrahmen (Minuten) |
|---|---|---|---|
| Kube-Knoten nicht erreichbar | Ein Knoten war in den letzten 15 Minuten nicht erreichbar. | 1 | 15 |
| KubeNodeReadinessFlapping | Der Bereitschaftsstatus eines Knotens hat sich in den letzten 15 Minuten mehr als 2 Mal geändert. | 2 | 15 |
Warnungen auf Pod-Ebene
| Warnungsname | Beschreibung | Standardschwellenwert | Zeitrahmen (Minuten) |
|---|---|---|---|
| KubePVUsageHigh | Die durchschnittliche Verwendung persistenter Volumes (Datenträger, PVs) auf Pod beträgt in den letzten 15 Minuten mehr als 80 %. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Es besteht eine Diskrepanz zwischen der gewünschten Anzahl von Replikaten und der Anzahl der verfügbaren Replikate für die letzten 10 Minuten. | Nicht verfügbar/Keine Angabe | 10 |
| KubeStatefulSetReplicasMismatch | Die Anzahl der bereiten Replikate im StatefulSet stimmt nicht mit der Gesamtzahl der Replikate im StatefulSet für die letzten 15 Minuten überein. | Nicht verfügbar/Keine Angabe | 15 |
| KubeHpaReplicasMismatch | Die horizontale Pod-Autoscaler im Cluster hat nicht die gewünschte Anzahl von Replikaten in den letzten 15 Minuten abgeglichen. | Nicht verfügbar/Keine Angabe | 15 |
| KubeHpaMaxedOut | Der horizontale Pod Autoscaler (HPA) im Cluster wurde in den letzten 15 Minuten mit den maximalen Replikaten ausgeführt. | Nicht verfügbar/Keine Angabe | 15 |
| KubePodCrashLooping | Ein oder mehrere Pods befinden sich in einem CrashLoopBackOff-Zustand, bei dem der Pod nach dem Start kontinuierlich abstürzt und sich in den letzten 15 Minuten nicht erfolgreich erholen konnte. | >=1 | 15 |
| KubeJobStale | Mindestens eine Auftragsinstanz wurde in den letzten 6 Stunden nicht erfolgreich abgeschlossen. | >0 | 360 |
| KubePodContainerRestart | Ein oder mehrere Container innerhalb von Pods im Kubernetes-Cluster wurden innerhalb der letzten Stunde mindestens einmal neu gestartet. | >0 | 15 |
| KubePodReadyStateLow | Der Prozentsatz der Pods in einem bereiten Zustand fällt für alle Bereitstellungen oder Daemonsets im Kubernetes-Cluster in den letzten 5 Minuten unter 80 %. | <0.8 | 5 |
| KubePodFailedState | Ein oder mehrere Pods befinden sich seit 5 Minuten in einem fehlerhaften Zustand. | >0 | 5 |
| KubePodNotReadyByController | Mindestens ein Pod befindet sich nicht in einem bereiten Zustand (d. h. in der Phase „Ausstehend“ oder „Unbekannt“) in den letzten 15 Minuten. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | Die beobachtete Generierung eines Kubernetes StatefulSet stimmt nicht mit der Generierung seiner Metadaten für die letzten 15 Minuten überein. | Nicht verfügbar/Keine Angabe | 15 |
| Kube-Job fehlgeschlagen | Mindestens ein oder mehrere Kubernetes-Aufträge sind innerhalb der letzten 15 Minuten fehlgeschlagen. | >0 | 15 |
| KubeContainerAverageCPUHigh | Die durchschnittliche CPU-Auslastung pro Container überschreitet 95 % für die letzten 5 Minuten. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | Die durchschnittliche Speicherauslastung pro Container überschreitet 95 % für die letzten 5 Minuten. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Das 99. Perzentil der Startverzögerung des Pods überschreitet in den letzten 10 Minuten 60 Sekunden. | >60 | 10 |
Warnungsregeln für Plattformmetriken
| Warnungsname | Beschreibung | Standardschwellenwert | Zeitrahmen (Minuten) |
|---|---|---|---|
| Der CPU-Prozentsatz des Knotens ist größer als 95 % | Der CPU-Prozentsatz des Knotens ist für die letzten 5 Minuten größer als 95 %. | 95 | 5 |
| Der Prozentsatz des Arbeitssatzes für den Knotenspeicher ist größer als 100 % | Prozentualer Arbeitssatz für Arbeitsspeicher des Knotens ist für die letzten 5 Minuten größer als 100 %. | 100 | 5 |
Metriken für Legacy-Containereinblicke (Vorschau)
Metrikregeln in Container Insights wurden am 31. Mai 2024 eingestellt. Diese Regeln befanden sich in der öffentlichen Vorschau, wurden aber ohne allgemeine Verfügbarkeit zurückgezogen, da die in diesem Artikel beschriebenen neuen empfohlenen metrischen Warnungen jetzt verfügbar sind.
Wenn Sie diese Legacy-Warnungsregeln bereits aktiviert haben, sollten Sie diese deaktivieren und die neue Erfahrung aktivieren.
Deaktivieren von Metrikbenachrichtigungsregeln
- Wählen Sie im Menü Erkenntnisse für Ihren Cluster die Option Empfohlene Warnungen (Vorschau).
- Ändern Sie den Status für jede Warnregel in Deaktiviert.
Legacywarnungszuordnung
In der folgenden Tabelle werden die einzelnen Metrikwarnungen, die zum älteren System von Container Insights gehören, den entsprechenden empfohlenen Prometheus-Metrikwarnungen zugeordnet.
| Benutzerdefinierte empfohlene Metrikwarnung | Entsprechende empfohlene Metrikwarnung für Prometheus/Plattform | Bedingung |
|---|---|---|
| Anzahl abgeschlossener Aufträge | KubeJobStale (Warnungen auf Podebene) | Mindestens eine Auftragsinstanz wurde in den letzten 6 Stunden nicht erfolgreich abgeschlossen. |
| Container-CPU-Anteil in Prozent | KubeContainerAverageCPUHigh (Warnungen auf Podebene) | Die durchschnittliche CPU-Auslastung pro Container überschreitet 95 % für die letzten 5 Minuten. |
| Speicher für den Containerarbeitssatz in % | KubeContainerAverageMemoryHigh (Warnungen auf Podebene) | Die durchschnittliche Speicherauslastung pro Container überschreitet 95 % für die letzten 5 Minuten. |
| Anzahl fehlerhafter Pods | KubePodFailedState (Warnungen auf Podebene) | Ein oder mehrere Pods befinden sich seit 5 Minuten in einem fehlerhaften Zustand. |
| Knoten-CPU in % | CPU-Prozentsatz des Knotens ist größer als 95 % (Plattformmetrik) | Der CPU-Prozentsatz des Knotens ist für die letzten 5 Minuten größer als 95 %. |
| Auslastung von Knotendatenträgern in % | Nicht verfügbar/Keine Angabe | Durchschnittliche Datenträgerauslastung für einen Knoten ist größer als 80 % |
| Knotenstatus „NotReady“ | KubeNodeUnreachable (Warnungen auf Knotenebene) | Ein Knoten war in den letzten 15 Minuten nicht erreichbar. |
| Speicher für den Knotenarbeitssatz in % | Der Prozentsatz des Arbeitssatzes für den Knotenspeicher ist größer als 100 % | Prozentualer Arbeitssatz für Arbeitsspeicher des Knotens ist für die letzten 5 Minuten größer als 100 %. |
| Aufgrund von Arbeitsspeichermangel beendete Container | KubeContainerOOMKilledCount (Warnungen auf Clusterebene) | Ein oder mehrere Container innerhalb von Pods wurden in den letzten 5 Minuten aufgrund von OOM-Ereignissen (Out-of-Memory) beendet. |
| Nutzung des persistenten Volumes in % | KubePVUsageHigh (Warnungen auf Podebene) | Die durchschnittliche Verwendung persistenter Volumes (Datenträger, PVs) auf Pod beträgt in den letzten 15 Minuten mehr als 80 %. |
| Bereite Pods in % | KubePodReadyStateLow (Warnungen auf Podebene) | Der Prozentsatz der Pods in einem bereiten Zustand fällt für alle Bereitstellungen oder Daemonsets im Kubernetes-Cluster in den letzten 5 Minuten unter 80 %. |
| Anzahl der neu gestarteten Container | KubePodContainerRestart (Warnungen auf Podebene) | Ein oder mehrere Container innerhalb von Pods im Kubernetes-Cluster wurden innerhalb der letzten Stunde mindestens einmal neu gestartet. |
Zuordnung von Legacymetriken
In der folgenden Tabelle werden die einzelnen benutzerdefinierten Metriken der Legacy-Container-Insights den entsprechenden Prometheus-Metriken zugeordnet.
| Benutzerdefinierte Metrik | Entsprechende Prometheus-Metrik |
|---|---|
| CPU-Auslastung in Millicores | rate(container_cpu_usage_seconds_total[5m]) × 1.000 |
| CPU-Auslastungsprozentsatz | 100 × rate(container_cpu_usage_seconds_total{cluster="$cluster"}[5m]) |
| Cpu-Auslastung Zuteilbarer Prozentsatz | 100 × ( sum by (cluster) (node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster="$cluster"}) / sum by (cluster) (instance:node_num_cpu:sum{cluster="$cluster"}) ) |
| memoryRssByte | container_memory_rss{cluster="$cluster"} |
| memoryRssPercentage | 100 × (sum by (instance, cluster) (container_memory_rss{job="cadvisor", cluster="$cluster"}) / sum by (instance, cluster) (machine_memory_bytes{job="cadvisor", cluster="$cluster"})) |
| memoryRssAllocatablePercentage | 100 × (sum by (node, cluster) (container_memory_rss{cluster="$cluster"}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| memoryWorkingSetBytes | container_memory_working_set_bytes{cluster="$cluster"} |
| memoryWorkingSetPercentage | 100 × (sum by (node, cluster) (container_memory_working_set_bytes{cluster="$cluster"}) / sum by (node, cluster) (node_memory_MemTotal_bytes{cluster="$cluster"})) |
| Knotenanzahl | count(kube_node_status_condition{condition="Ready", status="true", cluster="$cluster"}) |
| Festplattenspeicheranteil genutzt | 100 × (node_filesystem_size_bytes{cluster="$cluster"} - node_filesystem_free_bytes{cluster="$cluster"}) / node_filesystem_size_bytes{cluster="$cluster"} |
| Pod-Anzahl | count(count by (pod, namespace, cluster) (kube_pod_info{cluster="$cluster"})) |
| abgeschlosseneAufträgeAnzahl | count(kube_job_status_succeeded{status="true", cluster="$cluster"} and time() - kube_job_status_start_time > 6 × 3.600) |
| AnzahlNeustartenderContainer | sum by(container, namespace, cluster) (rate(kube_pod_container_status_restarts_total{cluster="$cluster"}[5m])) |
| Anzahl der durch OOM getöteten Container | sum by(container, namespace, cluster) (kube_pod_container_status_terminated_reason{reason="OOMKilled", cluster="$cluster"}) |
| Pod-Bereit-Quote | 100 × (sum(kube_pod_status_phase{phase="Running", cluster="$cluster"}) by (namespace, cluster) / sum(kube_pod_status_phase{phase!="Succeeded", cluster="$cluster"}) by (namespace, cluster)) |
Nächste Schritte
- Erfahren Sie mehr über die verschiedenen Warnungsregeltypen in Azure Monitor.
- Erfahren Sie mehr über Warnungsregelgruppen im verwalteten Azure Monitor-Dienst für Prometheus.