Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Volume-Sprache (vergleichbar mit Systemgebietsschemas auf Clientbetriebssystemen) auf einem Azure NetApp Files-Volume steuert die unterstützten Sprachen und Zeichensätze, wenn NFS- und SMB-Protokolleverwendet werden. Azure NetApp Files verwendet eine Standard-Volume-Sprache von C.UTF-8, die POSIX-kompatible UTF-8-Codierung für Zeichensätze bereitstellt. C.UTF-8 unterstützt nativ Zeichen mit einer Größe von 0-3 Byte, die eine Mehrheit der Weltsprachen auf der Basic Multilingual Plane (BMP) einschließt (einschließlich Japanisch, Deutsch und den meisten hebräischen und kyrillischen Zeichen). Weitere Informationen zu BMP finden Sie unter Unicode.
Zeichen außerhalb der BMP überschreiten manchmal die Größe von max. 3 Bytes, die von Azure NetApp Files unterstützt wird. Sie müssen daher Ersatzzeichenpaarlogikverwenden. Dabei werden mehrere Byte-Zeichensätze kombiniert, um neue Zeichen zu bilden. Emoji-Symbole fallen beispielsweise in diese Kategorie und werden in Azure NetApp Files in Szenarien unterstützt, in denen UTF-8 nicht erzwungen wird, z. B. bei Windows-Clients, die UTF-16-Codierung oder NFSv3 ohne Erzwingen von UTF-8 verwenden. NFSv4.x erzwingt UTF-8, was bedeutet, dass Ersatzzeichenpaare bei Verwendung von NFSv4.x nicht ordnungsgemäß angezeigt werden.
Nicht standardmäßige Codierung wie Shift-JIS- und weniger häufige CJK-Zeichen werden auch nicht ordnungsgemäß angezeigt, wenn UTF-8 in Azure NetApp Files erzwungen wird.
Tipp
Sie sollten Text mit UTF-8 übermitteln und empfangen, um zu vermeiden, dass Zeichen nicht ordnungsgemäß übersetzt werden können. Das kann zu Fehlern bei der Dateierstellung und -umbenennung oder beim Kopieren von Dateien führen.
Die Einstellungen zur Volume-Sprache können derzeit in Azure NetApp Files nicht geändert werden. Weitere Informationen finden Sie unter Protokollverhalten bei Sonderzeichensätzen.
Bewährte Methoden finden Sie unter bewährte Methoden für Zeichensätze.
Zeichencodierung in Azure NetApp Files NFS und SMB-Volumes
In einer Azure NetApp Files-Dateifreigabeumgebung werden Datei- und Ordnernamen lesbar durch eine Reihe von Zeichen dargestellt. Wie diese Zeichen angezeigt werden, hängt davon ab, wie der Client diese Zeichencodierung übermittelt und empfängt. Wenn ein Client beispielsweise veraltete ASCII (American Standard Code for Information Interchange)-Codierung beim Zugreifen auf das Azure NetApp Files-Volume übermittelt, können nur Zeichen angezeigt werden, die im ASCII-Format unterstützt werden.
Das japanische Zeichen für „Daten“ ist 資. Da dieses Zeichen nicht im ASCII-Format dargestellt werden kann, zeigt ein Client mit ASCII-Codierung ein „?“ anstelle von 資 an.
ASCII unterstützt nur 95 druckbare Zeichen, hauptsächlich die, die in der englischen Sprache zu finden sind. Jedes dieser Zeichen belegt 1 Byte, das als Teil der Gesamtlänge des Dateipfads auf einem Azure NetApp Files-Volume berechnet wird. Dies erschwert die Internationalisierung von Datasets, da eine Vielzahl möglicher Zeichen in Dateinamen nicht von ASCII nicht erkannt werden, z. B. Japanisch, Kyrillisch oder Emoji. Ein internationaler Standard (ISO/IEC 8859) wurde entwickelt,um die Unterstützung auf mehr internationale Zeichen auszuweiten, dieser hatte aber auch seine Einschränkungen. Die meisten modernen Clients verwenden Unicode für das Übermitteln und Empfangen von Zeichen.
Unicode
Aufgrund der Einschränkungen von ASCII- und ISO/IEC 8859-Codierungen wurde der Unicode-Standard eingerichtet, damit alle Geräte die Sprache der jeweiligen Heimatregion unterstützen.
- Unicode unterstützt mehr als eine Million Zeichensätze, indem sowohl die Anzahl der zulässigen Bytes pro Zeichen auf bis zu 4 Bytes als auch die Gesamtanzahl der in einem Dateipfad zulässigen Bytes erhöht wird, im Gegensatz zu älteren Codierungen wie ASCII.
- Unicode stellt die Abwärtskompatibilität sicher, indem die ersten 128 Zeichen für ASCII reserviert werden und die ersten 256 Codepunkte mit ISO/IEC 8859-Standards identisch sind.
- Im Unicode-Standard werden Zeichensätze in Ebenen unterteilt. Eine Ebene ist eine Gruppe von 65.536 Codepunkten. Insgesamt gibt es 17 Ebenen (Planes 0-16) im Unicode-Standard. Die Höchstanzahl 17 basiert auf den Einschränkungen von UTF-16.
- Plane 0 ist die Basic Multilingual Plane (BMP). Diese Ebene enthält die am häufigsten verwendeten Zeichen in mehreren Sprachen.
- Nur fünf der 17 Ebenen haben ihnen zugewiesene Zeichensätze (Stand: Unicode Version 15.1).
- Die Planes 1-17 werden als Supplementary Multilingual Planes (SMP) bezeichnet und enthalten seltener verwendete Zeichensätze, z. B. alte Schriftsysteme wie Keilschrift und Hieroglyphen sowie spezielle chinesische/japanische/koreanische-Zeichen (CJK).
- Weitere Informationen zur Anzeige von Zeichenlängen und Pfadlängen und zur Konfiguration einer an ein System übermittelten Codierung finden Sie unter Konvertieren von Dateien in verschiedene Codierungen.
Unicode verwendet Unicode Transformation Format als Standard. Die beiden Hauptformate sind UTF-8 und UTF-16.
Unicode-Ebenen
Unicode nutzt 17 Ebenen von 65.536 Zeichen (256 Codepunkte multipliziert mit 256 Feldern in der Ebene), wobei Plane 0 als Basic Multilingual Plane (BMP) dient. Diese Ebene enthält die am häufigsten verwendeten Zeichen in mehreren Sprachen. Da alle verwendeten Sprachen und Zeichensätze 65536 Zeichen überschreiten, werden mehr Ebenen benötigt, um weniger häufig verwendete Zeichensätze zu unterstützen.
Beispielsweise umfasst Ebene 1 (die Supplementary Multilingual Plane (SMP)) historische Schriften wie Keilschrift und ägyptische Hieroglyphen sowie Osage, Warang Citi, Adlam, Wancho und Toto. Plane 1 enthält auch einige Symbole und Emoticon-Zeichen.
Plane 2 – die Supplementary Ideographic Plane (SIP) – enthält die vereinheitlichten CJK-Ideogramme für Chinesisch, Japanisch und Koreanisch. Zeichen in Planes 1 und 2 sind im Allgemeinen 4 Byte groß.
Beispiel:
- Das Emoticon „grinsendes Gesicht mit großen Augen“ „😃“ in Plane 1 ist 4 Bytes groß.
- Die ägyptische Hieroglyphe „𓀀“ in Plane 1 ist 4 Bytes groß.
- Das Osage-Zeichen „𐒸“ in Plane 1 ist 4 Bytes groß.
- Das CJK-Zeichen „𫝁“ in Plane 2 ist 4 Bytes groß.
Da diese Zeichen alle >3 Bytes groß sind, können sie nur mit Ersatzzeichenpaaren ordnungsgemäß funktionieren. Azure NetApp Files unterstützt systemeigene Ersatzzeichenpaare, die Anzeige der Zeichen variiert jedoch je nach verwendetem Protokoll, Gebietsschema-Einstellungen des Clients und den Einstellungen der Remoteclient-Zugriffsanwendung.
UTF-8
UTF-8 verwendet 8-Bit-Codierung und kann bis zu 1.112.064 Codepunkte (oder Zeichen) aufweisen. UTF-8 ist die Standardcodierung für alle Sprachen in Linux-basierten Betriebssystemen. Da UTF-8 8 die 8-Bit-Codierung verwendet, beträgt die höchstmögliche ganze Zahl ohne Vorzeichen 255 (2^8 – 1). Das ist gleichzeitig auch die maximale Länge des Dateinamens für diese Codierung. UTF-8 wird auf über 98 % der Seiten im Internet verwendet, was es zum am meisten angenommenen Codierungsstandard macht. Die Web Hypertext Application Technology Working Group (WHATWG) nennt UTF-8 „die obligatorische Codierung für alle [Texte]“, und empfiehlt, dass Browseranwendungen aus Sicherheitsgründen UTF-16 nicht verwenden sollten.
Zeichen im UTF-8-Format belegen jeweils 1 bis 4 Bytes, aber fast alle Zeichen in allen Sprachen belegen zwischen 1 und 3 Bytes. Beispiel:
- Der lateinische Buchstabe „A“ belegt 1 Byte. (Eines der 128 reservierten ASCII-Zeichen)
- Das Copyright-Symbol „©“ belegt 2 Bytes.
- Das Zeichen „ä“ belegt 2 Bytes. (1 Byte für „a“ + 1 Byte für den Umlaut)
- Das japanische Kanji für Daten (資) belegt 3 Bytes.
- Das Emoji „grinsendes Gesicht“ (😃) belegt 4 Bytes.
Sprachgebietsschemas können entweder den Computerstandard UTF-8 (C.UTF-8) oder ein regionsspezifisches Formatverwenden, z. B. en_US. UTF-8, ja. UTF-8 usw. Sie sollten nach Möglichkeit die UTF-8-Codierung für Linux-Clients verwenden, wenn Sie auf Azure NetApp Files zugreifen. Ab OS X verwenden macOS-Clients auch UTF-8 für die Standardcodierung. Das sollte nicht geändert werden.
Windows-Clients verwenden UTF-16. In den meisten Fällen sollte diese Einstellung als Standard für das Betriebssystem-Gebietsschema belassen werden, aber neuere Clients bieten Betaunterstützung für UTF-8-Zeichen über ein Kontrollkästchen. Terminalclients in Windows können auch angepasst werden, um UTF-8 bei Bedarf in PowerShell oder CMD zu verwenden. Weitere Informationen finden Sie unter Dual-Protokollverhalten bei Sonderzeichensätzen.
UTF-16
UTF-16 verwendet 16-Bit-Codierung und kann alle 1.112.064-Codepunkte von Unicode codieren. Die Codierung für UTF-16 kann eine oder zwei 16-Bit-Codeeinheiten belegen, die jeweils 2 Bytes groß sind. Alle Zeichen in UTF-16 sind 2 oder 4 Bytes groß. Zeichen in UTF-16, die 4 Bytes belegen, nutzen Ersatzzeichenpaare. Dabei werden zwei separate 2-Byte-Zeichen kombiniert, um ein neues Zeichen zu erstellen. Diese ergänzenden Zeichen liegen außerhalb der Standard-BMP, und in einer der anderen mehrsprachigen Ebenen.
UTF-16 wird in Windows-Betriebssystemen und APIs, Java und JavaScript verwendet. Da die Abwärtskompatibilität mit ASCII-Formaten nicht gegeben ist, wurde UTF-16 im Web nie weithin akzeptiert. UTF-16 wird nur auf rund 0,002 % aller Seiten im Internet genutzt. Die Web Hypertext Application Technology Working Group (WHATWG) nennt UTF-8 „die obligatorische Codierung für alle Texte“, und empfiehlt, dass Anwendungen aus Browsersicherheitsgründen UTF-16 nicht verwenden sollten.
Azure NetApp Files unterstützt die meisten UTF-16 Zeichen, einschließlich Ersatzzeichenpaaren. In Fällen, in denen Zeichen nicht unterstützt werden, geben Windows-Clients den Fehler aus: „Der angegebene Dateiname ist ungültig oder zu lang“.
Zeichensatzbehandlung über Remoteclients
Remoteverbindungen mit Clients, die Azure NetApp Files-Volumes (z. B. SSH-Verbindungen mit Linux-Clients für den Zugriff auf NFS-Einbindungen) bereitstellen, können so konfiguriert werden, dass bestimmte Volume-Sprachen-Codierungen übermittelt und empfangen werden. Die an den Client über das Hilfsprogramm für Remoteverbindung übermittelte Sprachcodierung steuert, wie Zeichensätze erstellt und angezeigt werden. Daher kann eine Remoteverbindung, die eine andere Sprachcodierung verwendet als eine zweite Remoteverbindung – z. B. zwei verschiedene PuTTY-Fenster –, unterschiedliche Ergebnisse für Zeichen anzeigen, wenn Datei- und Ordnernamen im Azure NetApp Files-Volume aufgelistet werden. In den meisten Fällen entstehen dadurch keine Diskrepanzen (z. B. für lateinische/englische Zeichen), aber in den Fällen von Sonderzeichen wie Emojis können unterschiedliche Ergebnisse auftreten.
Beispielsweise zeigt die Verwendung einer UTF-8-Codierung für die Remoteverbindung vorhersehbare Ergebnisse für Zeichen in Azure NetApp Files-Volumes an, da C.UTF-8 die Volume-Sprache ist. Das japanische Zeichen für „Daten“ (資) wird je nach der vom Terminal gesendeten Codierung unterschiedlich angezeigt.
Zeichencodierung in PuTTY
Wenn ein PuTTY-Fenster UTF-8 verwendet (siehe Übersetzungseinstellungen von Windows), wird das Zeichen bei einem NFSv3-eingebundenes Volume in Azure NetApp Files ordnungsgemäß dargestellt:

Wenn das PuTTY-Fenster eine andere Codierung verwendet, z. B. ISO-8859-1:1998 (Lateinisch-1, Westeuropa), wird dasselbe Zeichen anders angezeigt, obwohl der Dateiname identisch ist.

PuTTY enthält standardmäßig keine CJK-Codierungen. Es gibt Patches, um diese Sprachsätze zu PuTTY hinzuzufügen.
Zeichencodierung in Bastion
Microsoft Azure empfiehlt die Verwendung von Bastion für die Remoteverbindung mit virtuellen Computern (VMs) in Azure. Bei Verwendung von Bastion wird die übermittelte und empfangene Sprachcodierung nicht in der Konfiguration verfügbar gemacht, sondern verwendet die standardmäßige UTF-8-Codierung. Daher sollten die meisten Zeichensätze, die in PuTTY mit UTF-8 zu sehen sind, auch in Bastion sichtbar sein, vorausgesetzt, die Zeichensätze werden im verwendeten Protokoll unterstützt.

Tipp
Andere SSH-Terminals können verwendet werden, z. B. TeraTerm. TeraTerm unterstützt standardmäßig einen größeren Bereich Zeichensätze, einschließlich CJK-Codierungen und nicht standardmäßiger Codierungen wie Shift-JIS.
Protokollverhalten bei Sonderzeichensätzen
Azure NetApp Files-Volumes verwenden UTF-8-Codierung und unterstützen nativ Zeichen, die 3 Bytes nicht überschreiten. Alle Zeichen im ASCII- und UTF-8-Satz werden ordnungsgemäß angezeigt, da sie in den Bereich von 1 bis 3 Bytes fallen. Beispiel:
- Der lateinische Buchstabe „A“ belegt 1 Byte (eines der 128 reservierten ASCII-Zeichen).
- Das Copyright-Symbol „©“ belegt 2 Bytes.
- Das Zeichen „ä" belegt 2 Bytes (1 Byte für „a“ und 1 Byte für den Umlaut).
- Das japanische Kanji für Daten (資) belegt 3 Bytes.
Azure NetApp Files unterstützen auch einige Zeichen, die mit Ersatzzeichenpaarlogik 3 Bytes überschreiten (z. B. Emoji), vorausgesetzt, die Clientcodierung und Protokollversion unterstützt sie. Weitere Informationen zum Protokollverhalten finden Sie unter:
SMB-Verhalten
In SMB-Volumes erstellt und verwaltet Azure NetApp Files zwei Namen für Dateien oder Verzeichnisse in jedem Verzeichnis, das Zugriff über einen SMB-Client hat: der ursprüngliche Name (Langform) und ein Name im 8.3-Format.
Dateinamen in SMB mit Azure NetApp Files
Wenn Datei- oder Verzeichnisnamen die zulässigen Zeichenbytes überschreiten oder nicht unterstützte Zeichen verwenden, generiert Azure NetApp Files wie folgt einen Namen im 8.3-Format:
- Der ursprüngliche Datei- oder Verzeichnisnamen wird trunkiert.
- Eine Tilde (~) und eine Zahl (1-5) werden an Datei- oder Verzeichnisnamen angehängt, die nach dem Trunkieren nicht mehr eindeutig sind. Wenn mehr als fünf Dateien mit nicht eindeutigen Namen vorhanden sind, erstellt Azure NetApp Files einen eindeutigen Namen ohne Bezug zum ursprünglichen Namen. Bei Dateien trunkiert Azure NetApp Files die Dateinamenerweiterung auf drei Zeichen.
Wenn beispielsweise ein NFS-Client eine Datei mit dem Namen specifications.htmlerstellt, erstellt Azure NetApp Files den Dateinamen specif~1.htm im 8.3-Format. Wenn dieser Name bereits vorhanden ist, verwendet Azure NetApp Files am Ende des Dateinamens eine andere Zahl. Wenn beispielsweise ein NFS-Client dann eine andere Datei namens specifications\_new.htmlerstellt, lautet der Name von specifications\_new.html im 8.3-Format specif~2.htm.
Sonderzeichen in SMB mit Azure NetApp Files
Bei Verwendung von SMB mit Azure NetApp Files-Volumes sind Zeichen (einschließlich Emoticons), die 3 Bytes überschreiten und in Datei- und Ordnernamen verwendet werden, aufgrund der Unterstützung von Ersatzzeichenpaaren zulässig. So erscheinen im Windows Explorer Zeichen außerhalb der BMP in einem Ordner, der von einem Windows-Client erstellt wurde, wenn Englisch mit der Standard-UTF-16-Codierung verwendet wird.
Hinweis
Die Standardschriftart in Windows Explorer ist Segoe UI. Schriftartänderungen können sich darauf auswirken, wie einige Zeichen auf Clients angezeigt werden.

Wie die Zeichen auf dem Client angezeigt werden, hängt von der Systemschriftart und den Sprach- und Gebietsschemaeinstellungen ab. Im Allgemeinen werden Zeichen, die auf der BMP liegen, über alle Protokolle hinweg unterstützt, unabhängig davon, ob die Codierung UTF-8 oder UTF-16 ist.
Wenn Sie CMD oder PowerShell verwenden, hängt die Zeichensatzanzeige von den Schriftarteinstellungen ab. Diese Hilfsprogramme haben standardmäßig nur eingeschränkte Schriftartoptionen. CMD verwendet Consolas als Standardschriftart.
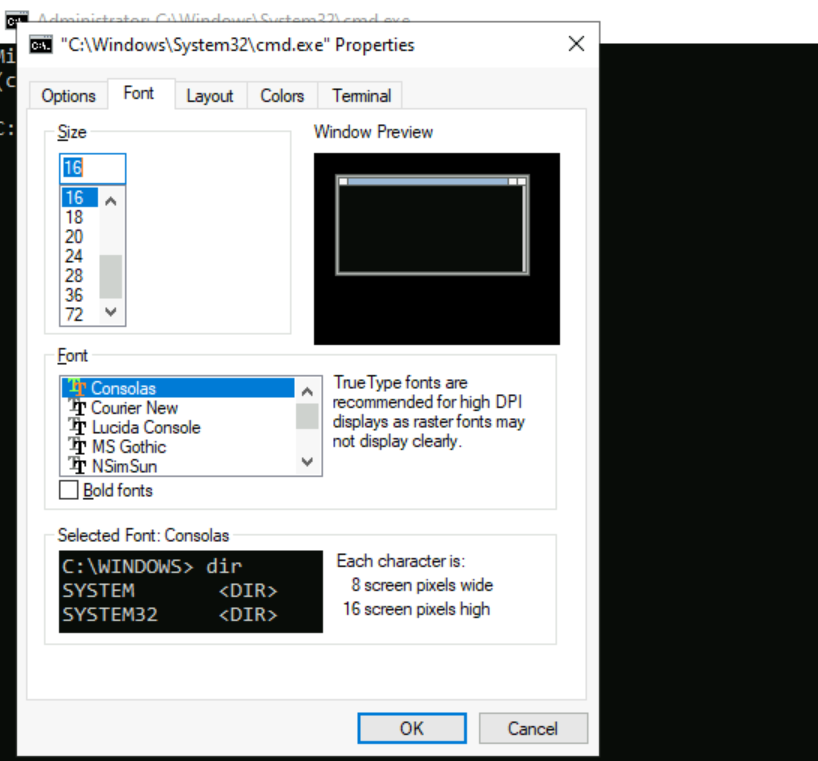
Dateinamen werden je nach Schriftart, die verwendet wird, möglicherweise nicht wie erwartet angezeigt, da einige Konsolen Segoe UI oder andere Schriftarten, die Sonderzeichen ordnungsgemäß anzeigen, nicht nativ unterstützen.
Dieses Problem kann auf Windows-Clients mithilfe PowerShell ISEbehoben werden, das eine erweiterte Schriftartunterstützung bietet. Wenn Sie z. B. PowerShell ISE auf Segoe UI festlegen, werden die Dateinamen mit unterstützten Zeichen richtig angezeigt.

PowerShell ISE ist jedoch für Skripting konzipiert, anstatt für das Verwalten von Freigaben. Neuere Windows-Versionen enthalten Windows Terminal, was die Steuerung von Schriftarten und Codierungswerten ermöglicht.
Hinweis
Verwenden Sie den Befehl chcp, um die Codierung für das Terminal anzuzeigen. Eine vollständige Liste der Codeseiten finden Sie unter Codeseitenbezeichner.

Wenn Dual-Protokolle (sowohl NFS als auch SMB) auf dem Volume aktiviert sind, kann das Verhalten abweichen. Weitere Informationen finden Sie unter Dual-Protokollverhalten bei Sonderzeichensätzen.
NFS-Verhalten
Wie NFS Sonderzeichen anzeigt, hängt von der verwendeten NFS-Version, den Gebietsschemaeinstellungen des Clients, installierten Schriftarten und den Einstellungen des verwendeten Remoteverbindungsclients ab. Beispielsweise fällt durch die Verwendung von Bastion für den Zugriff auf einen Ubuntu-Client die Zeichenanzeige anders als bei einem PuTTY-Client aus, der für ein anderes Gebietsschema auf derselben VM festgelegt ist. Die folgenden NFS-Beispiele basieren auf diesen Gebietsschemaeinstellungen für die Ubuntu-VM:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3-Verhalten
NFSv3 erzwingt keine UTF-Codierung für Dateien und Ordner. In den meisten Fällen sollten Sonderzeichensätze keine Probleme verursachen. Der verwendete Verbindungsclient kann jedoch beeinflussen, wie Zeichen übermittelt und empfangen werden. Beispielsweise kann die Verwendung von Unicode-Zeichen außerhalb der BMP für einen Ordnernamen im Azure-Verbindungsclient Bastion aufgrund der Clientcodierung zu unerwartetem Verhalten führen.
Im folgenden Screenshot kann Bastion die Werte nicht kopieren und in die CLI-Eingabeaufforderung außerhalb des Browsers einfügen, wenn ein Verzeichnis mit NFSv3 benannt wird. Beim Versuch, den Wert von NFSv3Bastion𓀀𫝁😃𐒸zu kopieren und einzufügen, werden die Sonderzeichen als Anführungszeichen in der Eingabe angezeigt.

Der Befehl „Kopieren/einfügen“ ist mit NFSv3 zulässig, die Zeichen werden jedoch als die entsprechenden numerischen Werte erstellt, was die Anzeige beeinträchtigt:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Diese Anzeige ist auf die Codierung zurückzuführen, die von Bastion zum Übermitteln von Textwerten beim Kopieren und Einfügen verwendet wird.
Wenn Sie PuTTY zum Erstellen eines Ordners mit denselben Zeichen mit NFSv3 verwenden, wird der Ordnername in Bastion anders angezeigt als nach dem Erstellen mit Bastion. Das Emoticon wird wie erwartet angezeigt (aufgrund der installierten Schriftarten und Gebietsschemaeinstellung), die anderen Zeichen (z. B. das „𐒸“ der Osage) werden jedoch nicht angezeigt.

In einem PuTTY-Fenster werden die Zeichen richtig angezeigt:

NFSv4.x-Verhalten
NFSv4.x erzwingt die UTF-8-Codierung in Datei- und Ordnernamen gemäß den RFC-8881 Internationalisierungsspezifikationen.
Wenn daher ein Sonderzeichen mit nicht UTF-8-Codierung gesendet wird, lässt NFSv4.x den Wert möglicherweise nicht zu.
In einigen Fällen kann ein Befehl mit Zeichen außerhalb der Basic Multilingual Plane (BMP) zulässig sein, aber der Wert wird möglicherweise nach der Erstellung nicht angezeigt.
Beispielsweise kann mit NFSv4.x erfolgreich ein Ordnername für mkdir vergeben werden, der die Zeichen „𓀀𫝁😃𐒸“ enthält (Zeichen in Supplementary Multilingual Planes (SMP) und der Supplementary Ideographic Plane (SIP)). Der Ordner wird beim Ausführen des Befehls ls nicht angezeigt.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Der Ordner ist im Volume vorhanden. Der Wechsel zu diesem ausgeblendeten Verzeichnisnamen funktioniert im PuTTY-Client, und eine Datei kann innerhalb dieses Verzeichnisses erstellt werden.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Ein stat-Befehl von PuTTY bestätigt außerdem, dass der Ordner vorhanden ist:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Obwohl der Ordner als vorhanden bestätigt wurde, funktionieren Wildcard-Befehle nicht, da der Client den Ordner in der Anzeige nicht „sehen“ kann.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 gibt einen Fehler an den Client aus, wenn ein Zeichen auftritt, das nicht auf UTF-8-Codierung basiert.
Wenn Sie beispielsweise Bastion verwenden, um auf dasselbe Verzeichnis zuzugreifen, das wir mit PuTTY mit NFSv4.1 erstellt haben, ist dies das Ergebnis:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL wird in RFC-8881 behandelt.
Da auf den Ordner über PuTTY zugegriffen werden kann (aufgrund der übermittelten und empfangenen Codierung), kann er kopiert werden, wenn der Name angegeben ist. Nachdem Sie diesen Ordner aus dem NFSv4.1 Azure NetApp Files-Volume in das NFSv3 Azure NetApp Files-Volume kopiert haben, wird der Ordnername angezeigt:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Derselbe NFS4ERR\_INVAL-Fehler kann auftreten, wenn eine Dateikonvertierung (mit `iconv``) in ein Nicht-UTF-8-Format versucht wird, z. B. Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Weitere Informationen finden Sie unter Konvertieren von Dateien in verschiedene Codierungen.
Dual-Protokollverhalten
Azure NetApp Files ermöglicht den Zugriff auf Volumes sowohl mit NFS als auch mit SMB über Dual-Protokollzugriff. Aufgrund der großen Unterschiede bei der von NFS (UTF-8) und SMB (UTF-16) verwendeten Sprachcodierung können Zeichensätze, Datei- und Ordnernamen sowie Pfadlängen über Protokolle hinweg sehr unterschiedliche Verhaltensweisen aufweisen.
Anzeigen von mit NFS erstellten Dateien und Ordnern in SMB
Wenn Azure NetApp Files für den Dual-Protokollzugriff (SMB und NFS) verwendet wird, kann ein von UTF-16 nicht unterstützter Zeichensatz in Dateinamen verwendet werden, die mit UTF-8 und NFS erstellt wurden. Wenn SMB dann auf eine Datei mit nicht unterstützten Zeichen zugreift, wird der Name in SMB anhand der 8.3-Konvention für Dateinamen-Kurzformenin SMB trunkiert.
Mit NFSv3 erstellte Dateien und SMB-Verhalten bei Zeichensätzen
NFSv3 erzwingt keine UTF-8-Codierung. Zeichen mit nicht standardmäßigen Sprachcodierungen (z. B. Shift-JIS) funktionieren bei Verwendung von NFSv3 mit Azure NetApp Files.
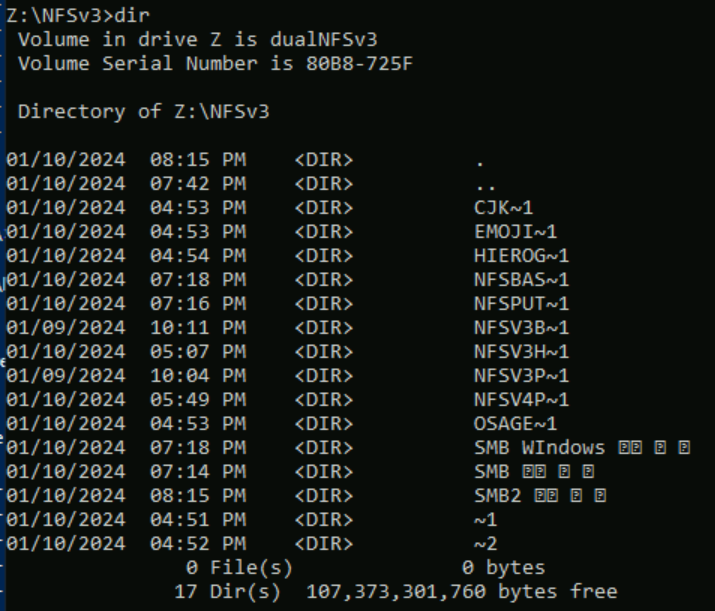
Im folgenden Beispiel wurden eine Reihe von Ordnernamen mit unterschiedlichen Zeichensätzen aus verschiedenen Ebenen in Unicode in einem Azure NetApp Files-Volume mit NFSv3 erstellt. In NFSv3 werden diese korrekt angezeigt.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Unter Windows SMB werden die Ordner mit Zeichen, die in der BMP enthalten sind, ordnungsgemäß angezeigt, aber Zeichen außerhalb dieser Ebene werden im 8.3-Namensformat angezeigt, da die UTF-8/UTF-16-Konvertierung für diese Zeichen nicht kompatibel ist.
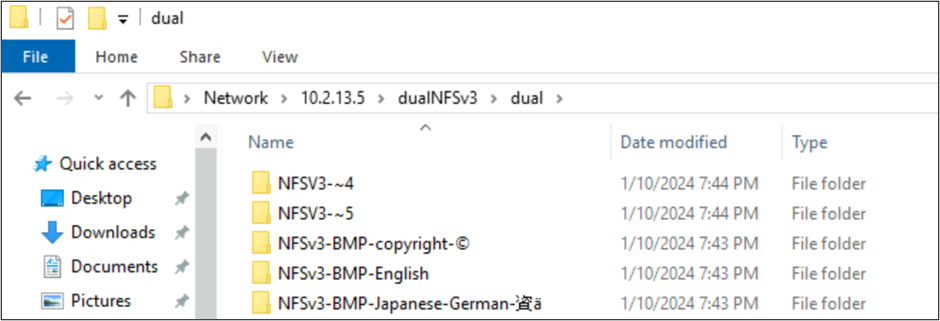
Mit NFSv4.1 erstellte Dateien und SMB-Verhalten bei Zeichensätzen
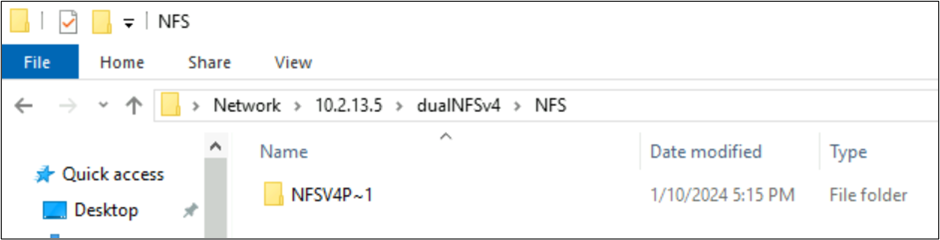
In den vorherigen Beispielen wurde ein Ordner mit dem Namen NFSv4 Putty 𓀀𫝁😃𐒸 auf einem Azure NetApp Files-Volume mit NFSv4.1 erstellt, konnte jedoch nicht mit NFSv4.1 angezeigt werden. Er kann jedoch mit SMB angezeigt werden. Der Name wird mit SMB aufgrund der im NFS-Client erstellten nicht unterstützten Zeichensätze und der inkompatiblen UTF-8/UTF-16-Konvertierung für Zeichen in verschiedenen Unicode-Ebenen auf ein unterstütztes 8.3-Format trunkiert.
Wenn ein Ordnername Standard-UTF-8-Zeichen verwendet, die in der BMP enthalten sind (z. B. englische oder andere Zeichen), übersetzt SMB die Namen ordnungsgemäß.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
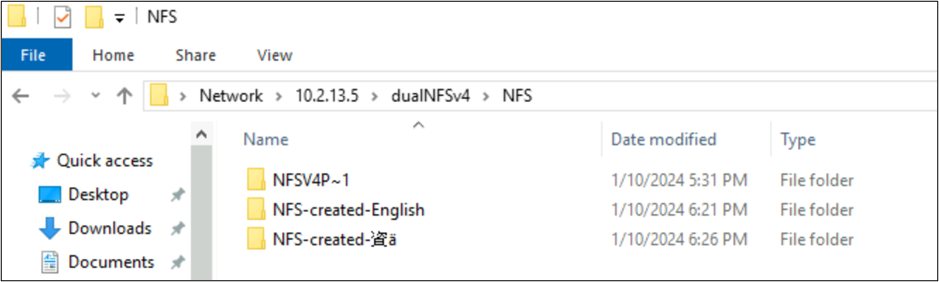
Mit NFS und SMB erstellte Dateien und Ordner
Windows-Clients sind der primäre Typ von Clients für den Zugriff auf SMB-Freigaben. Diese Clients verwenden standardmäßig UTF-16-Codierung. Unterstützung einiger UTF-8-codierte Zeichen in Windows ist mögliche, indem Sie sie in den Regionseinstellungen aktivieren:
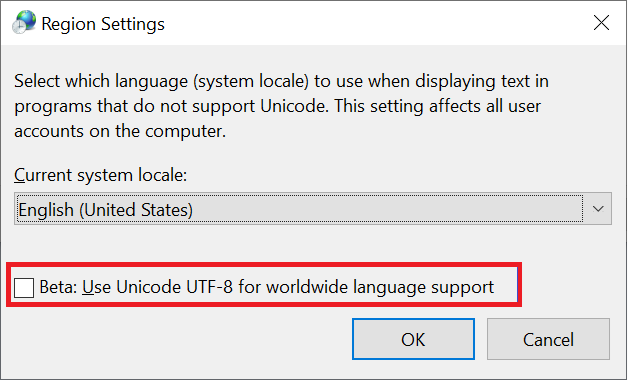
Wenn eine Datei oder ein Ordner über eine SMB-Freigabe in Azure NetApp Files erstellt wird, verwendet der Zeichensatz die UTF-16-Codierung. Daher können Clients, die UTF-8-Codierung verwenden – z. B. Linux-basierte NFS-Clients –, einige Zeichensätze möglicherweise nicht ordnungsgemäß übersetzen. Dies gilt insbesondere für Zeichensätze, die außerhalb der Basic Multilingual Plane (BMP) liegen.
Verhalten bei nicht unterstützten Zeichen
Wenn ein NFS-Client in diesen Szenarien auf eine Datei zugreift, die mit SMB mit nicht unterstützten Zeichen erstellt wurde, wird der Name als eine Reihe numerischer Werte angezeigt, die die Unicode-Werte der Zeichen darstellen.
Dieser Ordner wurde beispielsweise im Windows-Explorer mit Zeichen außerhalb der BMP erstellt.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
Mit NFSv3 wird der mit SMB erstellte Ordner angezeigt:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Mit NFSv4.1 wird der mit SMB erstellte Ordner so angezeigt:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Verhalten bei unterstützten Zeichen
Wenn die Zeichen auf der BMP liegen, gibt es keine Probleme zwischen den SMB- und NFS-Protokollen und deren Versionen.
Beispielsweise wird ein Ordnername, der mit SMB auf einem Azure NetApp Files-Volume erstellt wurde, und der Zeichen in der BMP in mehreren Sprachen (Englisch, Deutsch, Kyrillisch, Runen) enthält, in allen Protokollen und Versionen ordnungsgemäß angezeigt.
- Basis-Lateinisch „SMB“
- Griechisch „ͶΘΩ“
- Kyrillisch „ЁЄЊ“
- Runen „ᚠᚱᛯ“
- CJK-Ideogramme, Kompatibilität „豈滑虜“
So wird der Name mit SMB angezeigt:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
So wird der Name mit NFSv3 angezeigt:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
So wird der Name mit NFSv4.1 angezeigt:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Konvertieren von Dateien in verschiedene Codierungen
Datei- und Ordnernamen sind nicht die einzigen Teile von Dateisystemobjekten, die Sprachcodierungen verwenden. Dateiinhalte (z. B. Sonderzeichen in einer Textdatei) können ebenfalls eine Rolle spielen. Wenn beispielsweise versucht wird, eine Datei mit Sonderzeichen in einem inkompatiblen Format zu speichern, wird möglicherweise eine Fehlermeldung angezeigt. In diesem Fall kann eine Datei mit Katagana-Zeichen nicht in ANSI gespeichert werden, da diese Zeichen in dieser Codierung nicht vorhanden sind.
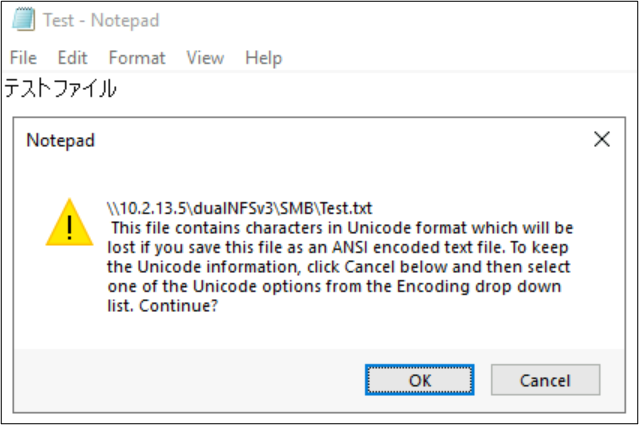
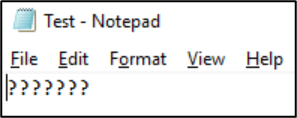
Sobald diese Datei in diesem Format gespeichert wurde, werden die Zeichen in Fragezeichen konvertiert:
Dateicodierungen können von NAS-Clients angezeigt werden. Auf Windows-Clients können Sie eine Anwendung wie Editor oder Notepad++ verwenden, um die Codierung einer Datei anzuzeigen. Wenn Windows-Subsystem für Linux (WSL) oder Git auf dem Client installiert sind, kann der Befehl file verwendet werden.
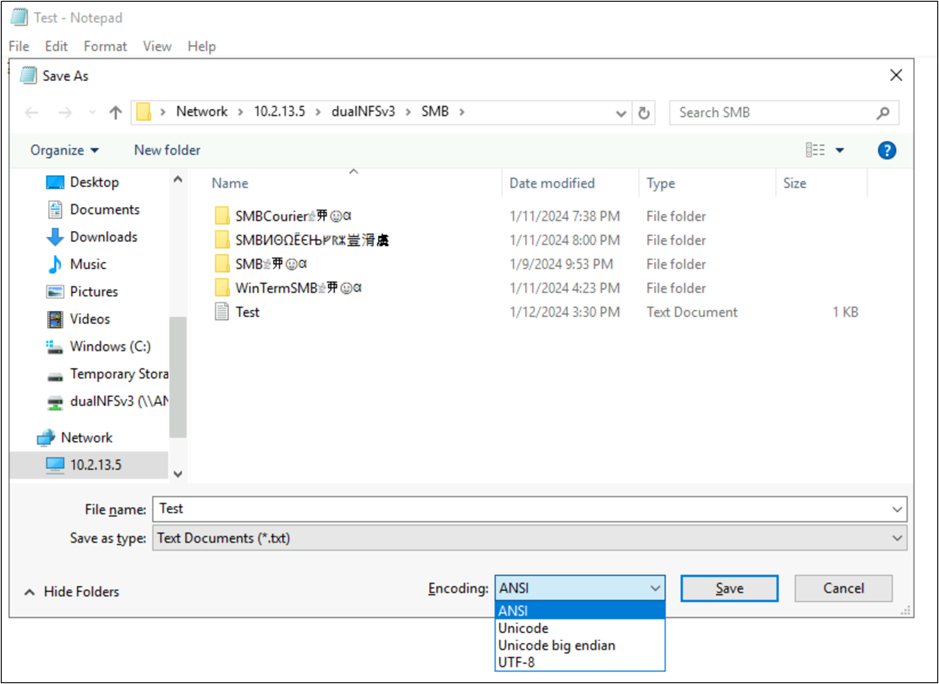
Mit diesen Anwendungen können Sie auch die Codierung der Datei ändern, indem Sie sie als verschiedene Codierungstypen speichern. Darüber hinaus kann PowerShell zum Konvertieren der Codierung für Dateien mit den cmdlets Get-Content und Set-Content verwendet werden.
Beispielsweise wird die Datei utf8-text.txt als UTF-8 codiert und enthält Zeichen außerhalb der BMP. Da UTF-8 verwendet wird, werden die Zeichen ordnungsgemäß angezeigt.
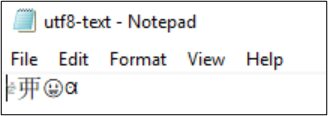
Wenn die Codierung in UTF-32 konvertiert wird, werden die Zeichen nicht ordnungsgemäß angezeigt.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
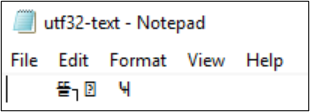
Get-Content kann auch zum Anzeigen der Dateiinhalte verwendet werden. Standardmäßig verwendet PowerShell UTF-16-Codierung (Codepage 437). Die Schriftartauswahl für die Konsole ist eingeschränkt. Dadurch kann eine UTF-8-formatierte Datei mit Sonderzeichen nicht ordnungsgemäß angezeigt werden:
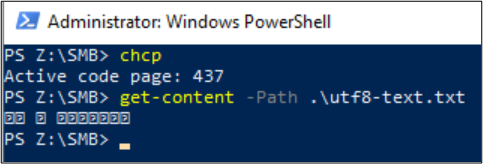
Linux-Clients können den Befehl file verwenden, um die Codierung der Datei anzuzeigen. Wenn eine Datei in Dual-Protokollumgebungen mit SMB erstellt wird, kann der Linux-Client mit NFS die Dateicodierung überprüfen.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Die Dateicodierungskonvertierung kann auf Linux-Clients mithilfe des Befehls iconv ausgeführt werden. Verwenden Sie iconv -l, um die Liste der unterstützten Codierungsformate anzuzeigen.
Beispielsweise kann eine UTF-8-codierte Datei in UTF-16 konvertiert werden.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Wenn der Zeichensatz für den Namen der Datei oder im Inhalt der Datei von der Zielcodierung nicht unterstützt wird, ist die Konvertierung nicht zulässig. Shift-JIS unterstützt z. B. die Zeichen im Inhalt der Datei nicht.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Wenn eine Datei Zeichen enthält, die von der Codierung unterstützt werden, wird die Konvertierung erfolgreich ausgeführt. Wenn die Datei die Katagana-Zeichen テストファイル enthält, kann sie mit NFS in Shift-JIS konvertiert werden. Da der hier verwendete NFS-Client aufgrund von Gebietsschemaeinstellungen kein Shift-JIS unterstützt, ist die Codierung „unknown-8bit“.
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Da Azure NetApp Files-Volumes nur UTF-8-kompatible Formatierung unterstützen, werden die Katagana-Zeichen in ein unlesbares Format konvertiert.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Bei Verwendung von NFSv4.x ist die Konvertierung auch zulässig, wenn nicht kompatible Zeichen innerhalb des Dateiinhalts vorhanden sind, obwohl NFSv4.x die UTF-8-Codierung erzwingt. In diesem Beispiel zeigt eine UTF-8-codierte Datei mit Katagana-Zeichen auf einem Azure NetApp Files-Volume die Dateiinhalte ordnungsgemäß an.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Sobald sie jedoch konvertiert wurde, werden die Zeichen in der Datei aufgrund der inkompatiblen Codierung nicht mehr ordnungsgemäß angezeigt.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Wenn der Name der Datei nicht unterstützte Zeichen für UTF-8 enthält, ist die Konvertierung mit NFSv3 erfolgreich, schlägt mit NSFv4.x jedoch aufgrund der UTF-8-Erzwingung der Protokollversion fehl.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Bewährte Methoden für Zeichensätze
Bei der Verwendung von Sonderzeichen oder Zeichen außerhalb der Standard-Basic Multilingual Plane (BMP) auf Azure NetApp Files-Volumes sollten einige bewährte Methoden berücksichtigt werden.
- Da Azure NetApp Files-Volumes UTF-8 als Volume-Sprache verwenden, sollte die Dateicodierung für NFS-Clients aus Konsistenzgründen auch UTF-8-Codierung verwenden.
- Zeichensätze in Dateinamen oder in Dateiinhalten sollten UTF-8-kompatibel sein, um die richtige Anzeige und Funktionalität zu ermöglichen.
- Da SMB UTF-16-Zeichencodierung verwendet, werden Zeichen außerhalb der BMP möglicherweise nicht ordnungsgemäß mit NFS in Dual-Protokoll-Volumes angezeigt. Verwenden Sie möglichst wenige Sonderzeichen in Dateiinhalten.
- Vermeiden Sie die Verwendung von Sonderzeichen außerhalb der BMP in Dateinamen, insbesondere bei Verwendung von NFSv4.1- oder Dual-Protokoll-Volumes.
- Bei Zeichensätzen, die nicht auf der BMP liegen, sollte die Anzeige der Zeichen in Azure NetApp Files mit UTF-8-Codierung möglich sein, wenn ein einzelnes Dateiprotokoll verwendet wird (nur SMB oder NFS). Dual-Protokoll-Volumes können diese Zeichensätze jedoch in den meisten Fällen nicht unterstützen.
- Nicht standardmäßige Codierung (z. B. Shift-JIS) wird auf Azure NetApp Files-Volumes nicht unterstützt.
- Ersatzzeichenpaare (z. B. für Emoji) werden auf Azure NetApp Files-Volumes unterstützt.