Behandeln von Problemen mit der Leistung von Azure SQL-Datenbank und Azure SQL Managed Instance mithilfe von Intelligent Insights
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Diese Seite bietet Informationen zu Problemen mit der Leistung von Azure SQL-Datenbank und Azure SQL Managed Instance, die anhand des Ressourcenprotokolls von Intelligent Insights erkannt wurden. Metriken und Ressourcenprotokolle können an Azure Monitor-Protokolle, Azure Event Hubs, Azure Storage oder an eine Drittanbieterlösung für benutzerdefinierte DevOps-Warnungen und -Berichterstellungsfunktionen gestreamt werden.
Hinweis
Eine Kurzanleitung zur Behandlung von Problemen mit der Leistung unter Verwendung von Intelligent Insights finden Sie im Flussdiagramm Empfohlene Vorgehensweise bei der Problembehandlung in diesem Dokument.
Intelligent Insights ist eine Vorschaufunktion, die in den folgenden Regionen nicht verfügbar ist: „Europa, Westen“, „Europa, Norden“, „USA, Westen 1“ und „USA, Osten 1“.
Erkennbare Muster bei der Datenbankleistung
Intelligent Insights erkennt automatisch Leistungsprobleme auf Grundlage von Wartezeiten, Fehlern oder Timeouts bei der Abfrageausführung. Erkannte Leistungsmuster werden von Intelligent Insights an das Ressourcenprotokoll ausgegeben. Erkennbare Leistungsmuster sind in der folgenden Tabelle zusammengefasst.
| Erkennbare Leistungsmuster | Azure SQL-Datenbank | Azure SQL Managed Instance |
|---|---|---|
| Erreichen von Ressourcengrenzwerten | Die Nutzung der im überwachten Abonnement verfügbaren Ressourcen, Datenbankarbeitsthreads und Datenbankanmeldesitzungen hat Ressourcengrenzwerte erreicht. Dies wirkt sich auf die Leistung aus. | Die Nutzung von CPU-Ressourcen hat Ressourcengrenzwerte erreicht. Dies beeinträchtigt die Datenbankleistung. |
| Gestiegene Workload | Eine Zunahme der Workload oder fortlaufende Häufung von Workloads wurde in der Datenbank erkannt. Dies wirkt sich auf die Leistung aus. | Eine Zunahme der Workload wurde erkannt. Dies beeinträchtigt die Datenbankleistung. |
| Hohe Arbeitsspeicherauslastung | Worker, die Speicherzuweisungen angefordert haben, müssen statistisch gesehen lange auf Speicherbelegung warten. Dies gilt auch, wenn eine zunehmende Anzahl von Workern eine Speicherbelegung angefordert hat. Dies wirkt sich auf die Leistung aus. | Worker, die Speicherzuweisungen angefordert haben, warten statistisch gesehen lange auf Speicherbelegung. Dies beeinträchtigt die Datenbankleistung. |
| Sperren | Übermäßige Datenbanksperren wurden erkannt, die die Leistung beeinträchtigen. | Übermäßige Datenbanksperren wurden erkannt, welche die Datenbankleistung beeinträchtigen. |
| Erhöhter Wert für „Maximaler Grad an Parallelität“ | Die Option „Maximaler Grad an Parallelität“ (MAXDOP) wurde geändert, was sich auf die Effizienz der Ausführung von Abfragen auswirkt. Dies wirkt sich auf die Leistung aus. | Die Option „Maximaler Grad an Parallelität“ (MAXDOP) wurde geändert, was sich auf die Effizienz der Ausführung von Abfragen auswirkt. Dies wirkt sich auf die Leistung aus. |
| Seitenlatchkonflikt | Mehrere Threads versuchen gleichzeitig, auf dieselben Datenpufferseiten im Arbeitsspeicher zuzugreifen. Dies führt zu längeren Wartezeiten und verursacht einen Seitenlatchkonflikt. Dies wirkt sich auf die Leistung aus. | Mehrere Threads versuchen gleichzeitig, auf dieselben Datenpufferseiten im Arbeitsspeicher zuzugreifen. Dies führt zu längeren Wartezeiten und verursacht einen Seitenlatchkonflikt. Dies beeinträchtigt die Datenbankleistung. |
| Fehlender Index | Ein fehlender Index wurde erkannt, der die Leistung beeinträchtigt. | Ein fehlender Index wurde erkannt, wodurch die Datenbankleistung beeinträchtigt wird. |
| Neue Abfrage | Eine neue Abfrage wurde erkannt, die die allgemeine Leistung beeinträchtigt. | Eine neue Abfrage wurde erkannt, welche die allgemeine Datenbankleistung beeinträchtigt. |
| Statistik bei zunehmenden Wartezeiten | Zunehmende Datenbankwartezeiten wurden erkannt, die die Leistung beeinträchtigen. | Zunehmende Datenbankwartezeiten wurden erkannt, welche die Datenbankleistung beeinträchtigen. |
| TempDB-Konflikt | Mehrere Threads versuchen, auf die gleichen tempdb-Ressource zuzugreifen, wodurch ein Engpass verursacht wird. Dies wirkt sich auf die Leistung aus. |
Mehrere Threads versuchen, auf die gleichen tempdb-Ressource zuzugreifen, wodurch ein Engpass verursacht wird. Dies beeinträchtigt die Datenbankleistung. |
| Mangel an DTUs im Pool für elastische Datenbanken | Ein Mangel an verfügbaren eDTUs im Pool für elastische Datenbanken beeinträchtigt die Leistung. | Nicht verfügbar für Azure SQL Managed Instance, da dabei das Modell mit virtuellen Kernen verwendet wird. |
| Planregression | Ein neuer Plan oder eine Änderung bei der Workload in einem bestehenden Plan wurde erkannt. Dies wirkt sich auf die Leistung aus. | Ein neuer Plan oder eine Änderung bei der Workload in einem bestehenden Plan wurde erkannt. Dies beeinträchtigt die Datenbankleistung. |
| Änderung eines Werts der datenbankweit gültigen Konfiguration | Eine Konfigurationsänderung in der Datenbank wurde erkannt, wodurch die Datenbankleistung beeinträchtigt wird. | Eine Konfigurationsänderung in der Datenbank wurde erkannt, wodurch die Datenbankleistung beeinträchtigt wird. |
| Langsamer Client | Ein langsamer Anwendungsclient kann die Ausgabe der Datenbank nicht schnell genug nutzen. Dies wirkt sich auf die Leistung aus. | Ein langsamer Anwendungsclient kann die Ausgabe der Datenbank nicht schnell genug nutzen. Dies beeinträchtigt die Datenbankleistung. |
| Tarifdowngrade | Ein Tarifdowngrade hat die verfügbaren Ressourcen reduziert. Dies wirkt sich auf die Leistung aus. | Ein Tarifdowngrade hat die verfügbaren Ressourcen reduziert. Dies beeinträchtigt die Datenbankleistung. |
Tipp
Aktivieren Sie für die fortlaufende Optimierung von Datenbanken die automatische Optimierung. Dieses integrierte Feature überwacht Ihre Datenbank fortlaufend, optimiert automatisch Indizes und wendet Abfrageplankorrekturen an.
Im folgenden Abschnitt werden die erkennbaren Leistungsmuster genauer beschrieben.
Erreichen von Ressourcengrenzwerten
Was passiert?
Dieses erkennbare Leistungsmuster kombiniert Leistungsprobleme im Zusammenhang mit dem Erreichen geltender Ressourcen-, Worker- und Sitzungsgrenzwerte. Sobald dieses Leistungsproblem erkannt wird, gibt ein Beschreibungsfeld im Diagnoseprotokoll an, ob es mit Ressourcen-, Worker- oder Sitzungsgrenzwerten zusammenhängt.
Ressourcen in Azure SQL-Datenbank werden in der Regel als DTU- oder V-Kern-Ressourcen und Ressourcen in Azure SQL Managed Instance werden als V-Kern-Ressourcen bezeichnet. Das Muster des Erreichens von „Ressourcengrenzwerten“ wird erkannt, wenn eine aufgetretene Verschlechterung der Abfrageleistung durch Erreichen eines der gemessenen Ressourcengrenzwerte verursacht wird.
Die Ressourcengrenzwerte für Sitzungen beziehen sich auf die Anzahl der verfügbaren gleichzeitigen Anmeldungen bei der Datenbank. Dieses Leistungsmuster wird dann erkannt, wenn Anwendungen, die mit den Datenbanken verbunden sind, die Anzahl der verfügbaren gleichzeitigen Anmeldungen bei der Datenbank erreicht haben. Falls Anwendungen versuchen, mehr Sitzungen zu nutzen, als für eine Datenbank verfügbar sind, wird die Abfrageleistung beeinträchtigt.
Das Erreichen von Workergrenzwerten ist ein spezieller Fall des Erreichens von Ressourcengrenzwerten, da verfügbare Worker nicht in die DTU- oder V-Kern-Nutzung einbezogen werden. Das Erreichen der Workergrenzwerte einer Datenbank kann eine Erhöhung ressourcenspezifischer Wartezeiten und damit eine Verschlechterung der Abfrageleistung zur Folge haben.
Problembehandlung bei Ressourcenbeschränkungen
Das Diagnoseprotokoll gibt Abfragehashes von Abfragen aus, die sich auf die Leistung und den prozentualen Ressourcenverbrauch ausgewirkt haben. Sie können diese Informationen als Ausgangspunkt für die Optimierung der Workload Ihrer Datenbank verwenden. Insbesondere können Sie die Abfragen optimieren, die die Leistungsbeeinträchtigung beeinflussen, indem Sie Indizes hinzufügen. Alternativ können Sie Anwendungen mit einer ausgeglicheneren Workloadverteilung optimieren. Wenn Sie nicht in der Lage sind, Workloads zu reduzieren oder Optimierungen vorzunehmen, erhöhen Sie ggf. den Tarif Ihres Datenbankabonnements, damit Ihnen mehr Ressourcen zur Verfügung stehen.
Wenn Sie die geltenden Sitzungsgrenzwerte erreicht haben, können Sie Ihre Anwendungen optimieren, indem Sie die Anzahl der Anmeldungen bei der Datenbank reduzieren. Wenn Sie die Anzahl der Anmeldungen von Ihrer Anwendung bei der Datenbank nicht reduzieren können, erhöhen Sie ggf. den Tarif Ihres Datenbankabonnements. Sie können Ihre Datenbank auch teilen und sie für eine ausgeglichenere Verteilung Ihrer Workload in mehrere Datenbanken verschieben.
Weitere Vorschläge zum Behandeln von Problemen mit Sitzungsgrenzwerten finden Sie unter How to deal with the limits of maximum logins (Umgang mit den Grenzwerten für Anmeldungen). Informationen zu Grenzwerten auf dem Server und Abonnementebenen finden Sie unter Ressourcenverwaltung in Azure SQL-Datenbank.
Gestiegene Workload
Was passiert?
Dieses Leistungsmuster identifiziert Probleme, die durch eine Zunahme der Workload oder, in ihrer schwerwiegenderen Form, durch ein Aufstauen von Workloads verursacht werden.
Diese Erkennung erfolgt mithilfe einer Kombination mehrerer Metriken. Die gemessene Basismetrik ist das Erkennen eines Anstiegs der Workload im Vergleich mit der Baseline der vorherigen Workload. Die andere Form der Erkennung basiert auf der Messung einer großen Zunahme aktiver Arbeitsthreads, die groß genug ist, um die Abfrageleistung zu beeinträchtigen.
Eine strengere Form des Problems liegt womöglich vor, wenn sich die Workload ständig aufstaut, da die Datenbank nicht in der Lage ist, die Workload zu bewältigen. Das Ergebnis ist eine ständig wachsende Workload bzw. ein „Workloadstau“ genannter Zustand. Aufgrund dieser Bedingung verlängert sich der Zeitraum, in dem die Workload auf die Ausführung wartet. Diese Bedingung stellt eines der schwerwiegendsten Datenbankleistungsprobleme dar. Dieses Problem wird durch Überwachen des Anstiegs der Anzahl abgebrochener Arbeitsthreads erkannt.
Problembehandlung bei Workload-Wachstum
Das Diagnoseprotokoll gibt die Anzahl der Abfragen aus, deren Ausführung sich erhöht hat, sowie den Abfragehash der Abfrage mit dem größten Anteil an der Workloaderhöhung. Sie können diese Informationen als Ausgangspunkt für die Optimierung der Workload verwenden. Die Abfrage, die am meisten zur gestiegenen Workload beiträgt, ist besonders nützlich als Ihr Startpunkt.
Sie sollten auch eine gleichmäßigere Verteilung der Workloads auf die Datenbank in Betracht ziehen. Ziehen Sie es in Betracht, die Abfrage zu optimieren, die die Leistung beeinträchtigt, indem Sie Indizes hinzufügen. Sie können möglicherweise auch Ihre Workload auf mehrere Datenbanken verteilen. Wenn diese Lösungen nicht möglich sind, sollten Sie ggf. den Tarif Ihres Datenbankabonnements erhöhen, damit Sie über mehr Ressourcen verfügen.
Hohe Arbeitsspeicherauslastung
Was passiert?
Dieses Leistungsmuster ist ein Hinweis auf eine Verschlechterung der aktuellen Datenbankleistung aufgrund einer hohen Arbeitsspeicherauslastung oder, in seiner schwerwiegenderen Form, auf einen Arbeitsspeicherstau im Vergleich mit der Baseline der Leistung in den letzten sieben Tagen.
Eine hohe Arbeitsspeicherauslastung kennzeichnet eine Leistungsbedingung, bei der eine große Anzahl von Arbeitsthreads Speicherzuweisungen anfordern. Dieses hohe Volumen verursacht eine hohe Arbeitsspeicherbelegung, aufgrund der die Datenbank den Arbeitsspeicher nicht effizient allen Workern zuweisen kann, die diesen anfordern. Eine der häufigsten Ursachen für dieses Problem bezieht sich einerseits auf die Menge des verfügbaren Arbeitsspeichers für die Datenbank. Andererseits führt eine erhöhte Workload zur Erhöhung der Arbeitsthreads sowie der Arbeitsspeicherauslastung.
Eine schwerwiegendere Form der hohen Arbeitsspeicherauslastung wird als Arbeitsspeicherstau bezeichnet. Diese Bedingung gibt an, dass eine höhere Anzahl von Arbeitsthreads Arbeitsspeicherzuweisungen anfordern als Abfragen vorhanden sind, die den Speicher freigeben. Diese Anzahl von Arbeitsthreads, die Speicherzuweisungen anfordern, kann ebenfalls kontinuierlich ansteigen (sich aufstauen), da die Datenbank-Engine nicht in der Lage ist, Arbeitsspeicher effizient zuzuteilen, um den Bedarf zu erfüllen. Der Arbeitsspeicherstau stellt eines der schwerwiegendsten Datenbankleistungsprobleme dar.
Problembehandlung bei Speicherauslastung
Das Diagnoseprotokoll gibt die Speicherdetails des Arbeitsspeicherobjekts aus, wobei der Clerk (Arbeitsthread) als Hauptgrund für die hohe Arbeitsspeicherbelegung und die entsprechenden Zeitstempel markiert ist. Sie können diese Informationen als Grundlage für die Problembehandlung verwenden.
Sie können Abfragen im Zusammenhang mit den Clerks mit der höchsten Speicherbelegung optimieren oder entfernen. Sie können auch sicherstellen, dass Sie keine Daten abfragen, die Sie nicht verwenden möchten. Eine empfohlene Vorgehensweise ist, immer eine WHERE-Klausel in Ihren Abfragen anzugeben. Darüber hinaus empfiehlt es sich, nicht gruppierte Indizes zu erstellen, um die Daten zu suchen, anstatt sie zu durchsuchen.
Sie können auch die Workload reduzieren, indem Sie sie optimieren oder über mehrere Datenbanken verteilen. Sie können auch Ihre Workload auf mehrere Datenbanken verteilen. Falls dies nicht möglich ist, sollten Sie ggf. den Tarif Ihrer Datenbank erhöhen, um die der Datenbank zur Verfügung stehenden Arbeitsspeicherressourcen zu vergrößern.
Weitere Vorschläge zur Problembehandlung finden Sie unter Meditation über Speicherzuweisungen: Der mysteriöse SQL Server-Arbeitsspeicherconsumer mit vielen Namen. Weitere Informationen zu Fehlern im Zusammenhang mit unzureichendem Arbeitsspeicher in Azure SQL-Datenbank finden Sie unter Behandeln von Fehlern mit unzureichendem Arbeitsspeicher mit Azure SQL-Datenbanken.
Sperren
Was passiert?
Dieses Leistungsmuster deutet auf eine Verschlechterung der aktuellen Datenbankleistung hin, da im Vergleich zur Leistungsbaseline der letzten sieben Tage übermäßige Datenbanksperren festgestellt wurden.
In modernen Managementsystemen für relationale Datenbanken sind Sperren wesentlich für die Umsetzung von Multithreadsystemen. Bei diesen Systemen wird die Leistung maximiert, indem nach Möglichkeit mehrere gleichzeitige Workerprozesse und parallele Datenbanktransaktionen ausgeführt werden. Das Sperren bezieht sich in diesem Zusammenhang auf den integrierten Zugriffsmechanismus. Dabei kann nur ausschließlich eine Transaktion auf die benötigten Zeilen, Seiten, Tabellen und Dateien zugreifen, ohne in Konkurrenz zu anderen Transaktionen um Ressourcen zu treten. Wenn die Transaktion, die die Ressourcen für die Verwendung gesperrt hat, abgeschlossen ist, wird die Sperre für diese Ressourcen freigegeben. Daraufhin können andere Transaktionen auf die benötigen Ressourcen zugreifen. Weitere Informationen zu Sperren finden Sie unter Sperren in der Datenbank-Engine.
Wenn Transaktionen, die von der SQL-Engine ausgeführt werden, längere Zeit auf den Zugriff auf Ressourcen warten, die gesperrt sind, wird die Ausführungszeit der Workload verlangsamt.
Problembehandlung beim Sperren und Blockieren
Das Diagnoseprotokoll gibt Details zu Sperren aus, die Sie als Grundlage für die Problembehandlung verwenden können. Sie können die gemeldeten blockierenden Abfragen analysieren, die für die Verschlechterung der Sperrleistung verantwortlich sind, und diese entfernen. In einigen Fällen verspricht das Optimieren der blockierenden Abfragen Erfolg.
Die einfachste und sicherste Möglichkeit, das Problem zu beseitigen, besteht darin, Transaktionen kurz zu halten und den Sperrumfang der aufwändigsten Abfragen zu verkleinern. Sie können eine große Anzahl von Vorgängen in kleinere Vorgänge aufteilen. Eine bewährte Methode zum Verringern des Umfangs von Abfragesperren ist, die Abfrage so effizient wie möglich zu gestalten. Reduzieren Sie umfangreiche Scanvorgänge, da sie die Wahrscheinlichkeit von Deadlocks erhöhen und sich negativ auf die allgemeine Datenbankleistung auswirken. Für ermittelte Abfragen, die Sperren verursachen, können Sie neue Indizes erstellen oder Spalten zum vorhandenen Index hinzufügen, um Tabellenscans zu vermeiden.
Weitere Vorschläge finden Sie unter:
- Verstehen und Beheben von Problemen durch Blockierungen in Azure SQL-Datenbank
- Behebung von Blockierungsproblemen, die durch eine Sperrenausweitung in SQL Server verursacht werden
Erhöhter Wert für „Maximaler Grad an Parallelität“
Was passiert?
Dieses erkennbare Leistungsmuster deutet eine Bedingung an, bei der ein ausgewählter Abfrageausführungsplan übermäßig parallelisiert wurde. Der Abfrageoptimierer kann die Workloadleistung erhöhen, indem Abfragen parallel ausgeführt werden, um Vorgänge zu beschleunigen. In einigen Fällen verbringen parallele Worker, die eine Abfrage verarbeiten, mehr Zeit damit, aufeinander zu warten, um Ergebnisse zu synchronisieren und zusammenzuführen, als wenn dieselbe Abfrage mit weniger parallelen Workern oder sogar mitunter nur in einem einzigen Arbeitsthread ausgeführt würde.
Das Expertensystem analysiert die aktuelle Datenbankleistung im Vergleich mit dem Baselinezeitraum. Es bestimmt, ob eine zuvor ausgeführte Abfrage aufgrund der übermäßigen Parallelisierung des Ausführungsplan der Abfrage langsamer als vorher ausgeführt wird.
Die Serverkonfigurationsoption „MAXDOP“ dient zum Steuern, wie viele CPU-Kerne zum parallelen Ausführen derselben Abfrage verwendet werden können.
Problembehandlung bei Parallelität
Das Diagnoseprotokolls gibt Abfragehashes im Zusammenhang mit den Abfragen aus, deren Dauer sich aufgrund einer übermäßigen Parallelisierung erhöht hat. Das Protokoll gibt außerdem CXP-Wartezeiten aus. Dies ist die Zeit, die ein einzelner Organisator-/Koordinatorthread (Thread 0) auf das Beenden aller anderen Threads wartet, ehe die Ergebnisse zusammengeführt werden und der Vorgang fortgesetzt wird. Darüber hinaus gibt das Diagnoseprotokoll die Zeiten aus, die Abfragen mit schlechter Leistung insgesamt auf die Ausführung gewartet haben. Sie können diese Informationen als Grundlage für die Problembehandlung verwenden.
Optimieren oder vereinfachen Sie zunächst komplexe Abfragen. Eine bewährte Methode ist das Aufteilen langer Batchaufträge in kleinere Aufträge. Stellen Sie darüber hinaus sicher, dass Sie Indizes zur Unterstützung Ihrer Abfragen erstellt haben. Sie können auch manuell den maximalen Grad an Parallelität (MAXDOP) eine Abfrage erzwingen, die als eine Abfrage mit schlechter Leistung gekennzeichnet wurde. Um diesen Vorgang mithilfe von T-SQL zu konfigurieren, sehen Sie sich die Seite Konfigurieren der Serverkonfigurationsoption Max. Grad an Parallelität an.
Das Festlegen der Serverkonfigurationsoption „MAXDOP“ auf 0 (null) als Standardwert bedeutet, dass die Datenbank alle verfügbaren CPU-Kerne nutzt, um Threads zum Ausführen einer einzelnen Abfrage zu parallelisieren. Das Festlegen von MAXDOP auf 1 (eins) gibt an, dass nur ein Kern für eine einzelne Abfrageausführung verwendet werden kann. Das bedeutet, dass die Parallelität deaktiviert ist. Je nach vorliegendem Fall, den für die Datenbank verfügbaren Kernen und den Informationen im Diagnoseprotokoll können Sie die Option „MAXDOP“ auf die Anzahl von Kernen für die parallele Abfrageausführung festlegen, die das Problem in Ihrem Fall womöglich beheben.
Seitenlatchkonflikt
Was passiert?
Dieses Leistungsmuster zeigt die aktuelle Leistungsminderung der Datenbankworkload aufgrund eines Seitenlatchkonflikts im Vergleich zur Workloadbaseline der letzten sieben Tage.
Latches sind einfache Synchronisierungsmechanismen, die für die Aktivierung von Multithreading verwendet werden. Sie garantieren die Konsistenz von In-Memory-Strukturen, die Indizes, Datenseiten und andere interne Strukturen enthalten.
Es sind viele Arten von Latches verfügbar. Aus Gründen der Einfachheit werden Pufferlatches zum Schützen von In-Memory-Seiten im Pufferpool verwendet. E/A-Latches werden zum Schützen von Seiten verwendet, die noch nicht in den Pufferpool geladen wurden. Wenn im Pufferpool Daten auf eine Seite geschrieben oder von ihr gelesen werden, muss ein Arbeitsthread zuerst ein Pufferlatch für die Seite erhalten. Wenn ein Arbeitsthread versucht, auf eine Seite zuzugreifen, die im Pufferpool im Arbeitsspeicher noch nicht verfügbar ist, erfolgt eine E/A-Anforderung zum Laden der benötigten Informationen aus dem Speicher. Diese Abfolge von Ereignissen kennzeichnet eine eindringlichere Form der Leistungsbeeinträchtigung.
Ein Konflikt bei den Seitenlatches tritt auf, wenn mehrere Threads gleichzeitig versuchen, Latches für dieselbe Struktur im Arbeitsspeicher abzurufen, wodurch sich die Wartezeit bis zur Ausführung der Abfrage verlängert. Bei einem E/A-Seitenlatchkonflikt, wenn auf Daten im Speicher zugegriffen werden muss, ist diese Wartezeit noch länger. Dies kann die Arbeitsauslastung erheblich beeinträchtigen. Ein Seitenlatchkonflikt ist das gängigste Szenario von Threads, die aufeinander warten und auf mehreren CPU-Systemen um Ressourcen konkurrieren.
Problembehandlung bei Seitenlatchkonflikt
Das Diagnoseprotokoll gibt Details zum Seitenlatchkonflikt aus. Sie können diese Informationen als Grundlage für die Problembehandlung verwenden.
Da ein Seitenlatch ein interner Steuermechanismus ist, wird seine Verwendung automatisch bestimmt. Entscheidungen zu Anwendungen, wie z.B. der Schemaentwurf, können sich aufgrund des deterministischen Verhaltens von Latches auf das Verhalten von Seitenlatches auswirken.
Eine Methode zur Behandlung von Latchkonflikten ist das Ersetzen eines sequenziellen Indexschlüssels durch einen nicht sequenziellen Schlüssel, um Einfügevorgänge gleichmäßig auf einen Indexbereich zu verteilen. Typischerweise verteilt eine führende Spalte im Index die Workload proportional. Eine andere mögliche Methode ist die Tabellenpartitionierung. Das Erstellen eines Hashpartitionierungsschemas mit einer berechneten Spalte für eine partitionierte Tabelle ist eine gängige Methode zur Vermeidung übermäßiger Latchkonflikte. Im Fall von E/A-Seitenlatchkonflikten hilft das Einführen von Indizes, dieses Leistungsproblem zu beheben.
Weitere Informationen finden Sie unter Diagnose and resolve latch contention on SQL Server (Diagnostizieren und Beheben von Latchkonflikten in SQL Server) (PDF-Download).
Fehlender Index
Was passiert?
Dieses Leistungsmuster zeigt die aktuelle Leistungsminderung der Datenbankworkload aufgrund eines fehlenden Indexes im Vergleich zur Workloadbaseline der letzten sieben Tage.
Ein Index wird verwendet, um die Leistung von Abfragen zu beschleunigen. Er ermöglicht den schnellen Zugriff auf Tabellendaten bei gleichzeitiger Reduzierung der Anzahl von Datasetseiten, die besucht oder durchsucht werden müssen.
Bestimmte Abfragen, die eine Verschlechterung der Leistung verursacht haben, werden mithilfe dieser Erkennungsmethode bestimmt. Für sie wäre das Erstellen von Indizes für die Leistung von Vorteil.
Problembehandlung für teure Abfragen mit Indizes
Das Diagnoseprotokoll gibt Abfragehashes für die Abfragen aus, die sich negativ auf die Leistung der Workload auswirken. Sie können Indizes für diese Abfragen erstellen. Sie können auch diese Abfragen optimieren oder entfernen, wenn sie nicht erforderlich sind. Aus Leistungsgründen empfiehlt es sich unbedingt, das Abfragen nicht verwendeter Daten zu vermeiden.
Tipp
Wussten Sie, dass die integrierte intelligente Funktionen automatisch die leistungsfähigsten Indizes für Ihre Datenbanken verwalten?
Aktivieren Sie für fortlaufende Leistungsoptimierung die automatische Optimierung. Dieses einzigartige intelligente Feature überwacht Ihre Datenbank und optimiert automatisch Indizes für Ihre Datenbanken bzw. erstellt diese.
Neue Abfrage
Was passiert?
Dieses Leistungsmuster deutet an, dass eine neue Abfrage erkannt wurde, die im Vergleich mit der Leistungsbaseline der letzten sieben Tage eine schwache Leistung bietet und deshalb die Workload beeinträchtigt.
Das Schreiben einer leistungsfähigen Abfrage kann mitunter eine Herausforderung darstellen. Weitere Informationen zum Schreiben von Abfragen finden Sie unter Writing SQL queries (Schreiben von SQL-Abfragen). Um vorhandene Abfrageleistung zu optimieren, gehen Sie unter Optimieren von Abfragen.
Beheben von Problemen mit der Abfrageleistung
Das Diagnoseprotokoll gibt Informationen für bis zu zwei neuen Abfragen mit der höchsten CPU-Auslastung aus, einschließlich ihrer Abfragehashes. Da sich die erkannte Abfrage auf die Leistung Ihrer Workload auswirkt, können Sie Ihre Abfrage optimieren. Eine bewährte Methode besteht darin, nur Daten abzurufen, die Sie auch verwenden müssen. Es wird empfohlen, Abfragen mit einer WHERE-Klausel zu verwenden. Wir empfehlen auch, dass Sie komplexe Abfragen vereinfachen und sie in kleinere Abfragen aufteilen. Außerdem ist das Unterteilen großer Batchabfragen in kleinere Batchabfragen ebenso eine bewährte Methode. Das Einführen von Indizes für neue Abfragen ist in der Regel empfehlenswert, um dieses Leistungsproblem zu beseitigen.
Erwägen Sie den Einsatz der Statistik zur Abfrageleistung für Azure SQL-Datenbank.
Erhöhte Wartezeiten
Was passiert?
Dieses erkennbare Leistungsmuster deutet auf eine Verschlechterung der Workloadleistung dahingehend hin, dass im Vergleich mit einer Workloadbaseline der letzten sieben Tage Abfragen mit schlechter Leistung ausgemacht wurden.
In diesem Fall kann das System die Abfragen mit schwacher Leistung nicht in andere standardmäßige erkennbaren Leistungskategorien einstufen. Es hat jedoch eine Wartestatistik erkannt, die für die Regression verantwortlich ist. Aus diesem Grund werden diese als Abfragen mit Statistik bei zunehmenden Wartezeiten erkannt, wobei die für die Regression zuständige Wartestatistik ebenfalls verfügbar gemacht wird.
Problembehandlung bei Wartestatistiken
Das Diagnoseprotokoll gibt Details zu zunehmenden Wartezeiten und Abfragehashes der betroffenen Abfragen aus.
Da das System in diesem Fall nicht die Ursache für Abfragen mit schlechter Leistung bestimmen konnte, sind die Diagnoseinformationen ein geeigneter Ausgangspunkt für eine manuelle Problembehandlung. Sie können die Leistung dieser Abfragen optimieren. Es empfiehlt sich, nur Daten abzurufen, die Sie verwenden müssen, und komplexe Abfragen zu vereinfachen und in kleinere Abfragen zu unterteilen.
Weitere Informationen zum Optimieren der Leistung von Abfragen finden Sie unter Optimieren von Abfragen.
TempDB-Konflikt
Was passiert?
Dieses erkennbare Leistungsmuster ist ein Hinweis auf eine Datenbankleistungsbedingung mit einem Engpass bei Threads, die versuchen, auf tempdb-Ressourcen zuzugreifen. (Diese Bedingung ist nicht E/A-bedingt.) Das typische Szenario für dieses Leistungsproblem sind Hunderte gleichzeitiger Abfragen, die alle kleine tempdb-Tabellen erstellen, verwenden und dann löschen. Das System hat festgestellt, dass die Anzahl gleichzeitiger Abfragen unter Verwendung derselben tempdb-Tabellen im Vergleich mit der Leistungsbaseline der letzten sieben Tage statistisch so signifikant angestiegen ist, dass die Datenbankleistung darunter leidet.
Behandeln von Problemen mit tempdb-Inhalt
Das Diagnoseprotokoll gibt Details zum tempdb-Konflikt aus. Sie können diese Informationen als Startpunkt für die Problembehandlung verwenden. Es gibt zwei Dinge, mit denen Sie diese Art von Konflikt entschärfen und den Durchsatz der gesamten Workload erhöhen können: Sie können aufhören, die temporären Tabellen zu verwenden. Sie können auch speicheroptimierte Tabellen verwenden.
Weitere Informationen finden Sie unter Einführung in speicheroptimierte Tabellen.
Mangel an DTUs im Pool für elastische Datenbanken
Was passiert?
Dieses erkennbare Leistungsmuster zeigt eine aktuelle Leistungsminderung der Datenbankworkload im Vergleich zur Workloadbaseline der letzten sieben Tage. Der Grund dafür ist der Mangel an verfügbaren DTUs im Pool für elastische Datenbanken Ihres Abonnements.
Azure-Ressourcen für den Pool für elastische Datenbanken dienen als Pool verfügbarer Ressourcen, die zu Skalierungszwecken von mehreren Datenbanken gemeinsam genutzt werden. Wenn die verfügbaren eDTU-Ressourcen in Ihrem Pool elastischer Datenbanken nicht ausreichen, um alle Datenbanken im Pool zu unterstützen, wird das Problem „Mangel an DTUs im Pool für elastische Datenbanken“ vom System erkannt.
Fehlerbehebung bei DTU-Mangel im Pool für elastische Datenbanken
Das Diagnoseprotokoll gibt Informationen zum Pool für elastische Datenbanken aus, listet die Datenbanken mit dem höchsten DTU-Verbrauch auf und gibt einen Prozentwert der DTUs des Pools an, die von den Datenbanken mit dem höchsten Verbrauch verwendet werden.
Da sich diese Leistungsbedingung auf mehrere Datenbanken bezieht, die denselben Pool von eDTUs im Pool für elastische Datenbanken verwenden, konzentrieren sich die Schritte zur Problembehandlung auf die Datenbanken mit dem höchsten DTU-Verbrauch. Sie können die Workload der Datenbanken mit dem höchsten DTU-Verbrauch reduzieren, was das Optimieren der Abfragen mit dem höchsten Verbrauch dieser Datenbanken mit einschließt. Sie können auch sicherstellen, dass Sie keine Daten abfragen, die Sie nicht verwenden. Ein anderer Ansatz ist das Optimieren von Anwendungen, indem Sie die Datenbanken mit dem höchsten DTU-Verbrauch verwenden und die Workload auf mehrere Datenbanken umverteilen.
Wenn die Reduzierung und Optimierung der aktuellen Workload Ihrer Datenbanken mit dem höchsten DTU-Verbrauch nicht möglich ist, ziehen Sie es in Betracht, den Tarif für Ihren Pool für elastische Datenbanken zu erhöhen. Eine solche Heraufstufung führt zur Erhöhung der im Pool für elastische Datenbanken verfügbaren DTUs.
Planregression
Was passiert?
Dieses erkennbare Leistungsmuster deutet auf eine Bedingung hin, bei der die Datenbank einen suboptimalen Abfrageausführungsplan nutzt. Der suboptimale Plan verursacht in der Regel eine längere Abfrageausführung, was zu längeren Wartezeiten für die aktuelle und andere Abfragen führt.
Die Datenbank-Engine bestimmt den Abfrageausführungsplan mit den geringsten Kosten für eine Abfrageausführung. Wenn sich der Typ von Abfragen und Workloads ändert, sind die vorhandenen Pläne mitunter nicht mehr effizient, oder die Datenbank-Engine hat keine gute Bewertung vorgenommen. Als Korrekturmaßnahme können Abfrageausführungspläne manuell erzwungen werden.
Dieses erkennbare Leistungsmuster kombiniert drei Fälle von Planregression: neue Planregression, alte Planregression und geänderte Workload in vorhandenen Plänen. Die bestimmte Art der Planregression, die aufgetreten ist, wird in der Eigenschaft Details im Diagnoseprotokoll bereitgestellt.
Die Bedingung „Neue Planregression“ bezieht sich auf einen Zustand, in dem die Datenbank-Engine mit der Ausführung eines neuen Ausführungsplans beginnt, der nicht so effizient wie der alte Plan ist. Die Bedingung „Alte Planregression“ bezieht sich auf den Zustand, in dem die Datenbank-Engine von einem neuen, effizienteren Plan zu einem alten Plan wechselt, der nicht so effizient wie der neue Plan ist. Die Regression „Geänderte Workload in vorhandenen Plänen“ bezieht sich auf den Zustand, in dem die alten und neue Pläne sich laufend abwechseln, wobei die Waage mehr in Richtung des Plans mit der schlechten Leistung ausschlägt.
Weitere Informationen zu Planregressionen finden Sie unter Was ist Planregression in SQL Server?.
Problembehandlung bei Planregression
Das Diagnoseprotokoll gibt Abfragehashes, die ID des guten Plans, die ID des schlechten Plans und Abfrage-IDs zurück. Sie können diese Informationen als Grundlage für die Problembehandlung verwenden.
Sie können auch für Ihre spezifischen Abfragen, die Sie mithilfe der bereitgestellten Abfragehashes bestimmen können, analysieren, welcher Plan leistungsfähiger ist. Nachdem Sie den Plan bestimmt haben, der für Ihre Abfragen besser funktioniert, können Sie ihn manuell erzwingen.
Weitere Informationen finden Sie auf der Seite zum Thema wie SQL Server die Planregression verhindert.
Tipp
Wussten Sie, dass das integrierte intelligente Feature automatisch die leistungsfähigsten Abfrageausführungspläne für Ihre Datenbanken verwaltet?
Aktivieren Sie für fortlaufende Leistungsoptimierung die automatische Optimierung. Dieses integrierte intelligente Feature überwacht Ihre Datenbank fortlaufend und optimiert automatisch die leistungsfähigsten Abfrageausführungspläne für Ihre Datenbanken bzw. erstellt diese.
Änderung eines Werts der datenbankweit gültigen Konfiguration
Was passiert?
Dieses erkennbare Leistungsmuster ist ein Hinweis auf eine Bedingung dahingehend, dass eine Änderung an der datenbankweit gültigen Konfiguration erfolgt ist, die zu einem Leistungsverlust führt. Die Bedingung wurde im Vergleich mit dem Verhalten der Datenbankworkload in den letzten sieben Tagen bestimmt. Dieses Muster weist darauf hin, dass die letzte Änderung an der datenbankweit gültigen Konfiguration sich anscheinend nicht positiv auf die Leistung der Datenbank auswirkt.
Die Änderung der datenbankweit gültigen Konfiguration kann für jede einzelne Datenbank festgelegt werden. Diese Konfiguration wird fallweise verwendet, um die Leistung Ihrer Datenbank individuell zu optimieren. Die folgenden Optionen können für jede einzelne Datenbank konfiguriert werden: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES und CLEAR PROCEDURE_CACHE.
Fehlerbehebung bei datenbankweiten Konfigurationsänderungen
Das Diagnoseprotokoll gibt Änderungen an der datenbankweit gültigen Konfiguration aus, die vor Kurzem erfolgt sind und im Vergleich mit dem Workloadverhalten der vorherigen sieben Tage die Leistungsminderung verursacht haben. Sie können die Änderungen an der Konfiguration auf den vorherigen Wert zurücksetzen. Sie können auch die Werte einzeln optimieren, bis die gewünschte Leistungsstufe erreicht ist. Sie können auch Werte einer datenbankweit gültigen Konfiguration aus einer ähnlichen Datenbank mit zufriedenstellender Leistung kopieren. Wenn Sie die Leistungsprobleme nicht beheben können, stellen Sie die Standardwerte wieder her, und versuchen Sie, eine Optimierung ausgehend von dieser Baseline durchzuführen.
Weitere Informationen zum Optimieren der datenbankweit gültigen Konfiguration und zur T-SQL-Syntax zum Ändern der Konfiguration finden Sie unter ALTER DATABASE SCOPED CONFIGURATION (Transact-SQL).
Langsamer Client
Was passiert?
Dieses erkennbare Leistungsmuster gibt eine Bedingung an, bei der der mit der Datenbank arbeitende Client nicht in der Lage ist, die Ausgabe der Datenbank so schnell zu nutzen, wie die Datenbank die Ergebnisse sendet. Da die Datenbank Ergebnisse der ausgeführten Abfragen nicht in einem Puffer speichert, muss die Datenbank warten, bis der langsame Client die übermittelten Abfrageergebnisse verbraucht, bevor fortgefahren wird. Diese Bedingung ist möglicherweise auch auf ein langsames Netzwerk zurückzuführen, in dem die Ausgaben der Datenbank nicht schnell genug an den nutzenden Client übertragen werden können.
Diese Bedingung wird nur generiert, wenn im Vergleich mit dem Verhalten der Datenbankworkload in den letzten sieben Tagen eine Leistungsverschlechterung vorliegt. Dieses Leistungsproblem wird nur dann erkannt, wenn es zu einer statistisch signifikanten Leistungsminderung im Vergleich zum vorherigen Leistungsverhalten kommt.
Problembehandlung von clientseitigen Anwendungen
Dieses erkennbare Leistungsmuster gibt eine Bedingung auf Clientseite an. Es ist eine Problembehandlung der clientseitigen Anwendung oder des clientseitigen Netzwerks erforderlich. Das Diagnoseprotokoll gibt die Abfragehashes und längsten Wartezeiten bei der Nutzung der Ausgabe durch den Client in den letzten beiden Stunden zurück. Sie können diese Informationen als Grundlage für die Problembehandlung verwenden.
Sie können die Leistung Ihrer Anwendung für die Nutzung dieser Abfragen optimieren. Sie können auch mögliche Netzwerklatenzprobleme in Betracht ziehen. Da die Leistungsbeeinträchtigung auf der Veränderung der Leistungsbaseline der letzten sieben Tage basiert, können Sie untersuchen, ob die kürzlich durchgeführten Änderungen an der Anwendung oder am Netzwerk dieses Ereignis der Leistungsbeeinträchtigung verursacht haben.
Preisniveau-Downgrade
Was passiert?
Dieses erkennbare Leistungsmuster gibt eine Bedingung an, bei der der Tarif Ihres Datenbankabonnements herabgestuft wurde. Aufgrund der Reduzierung der für die Datenbank verfügbaren Ressourcen hat das System einen Abfall der aktuellen Datenbankleistung im Vergleich mit der Baseline der letzten sieben Tage erkannt.
Darüber hinaus kann eine Bedingung vorliegen, bei der innerhalb eines kurzen Zeitraums der Tarif Ihres Datenbankabonnements herabgestuft und auf einen höheren Tarif heraufgestuft wurde. Die Erkennung einer temporären Leistungsminderung wird im Abschnitt „Details“ des Diagnoseprotokolls als Tarifdowngrade und -upgrade ausgegeben.
Problembehandlung bei Preisstufen-Downgrades
Wenn Sie Ihren Tarif herabgestuft und Sie mit der Leistung zufrieden sind, müssen Sie nichts weiter tun. Wenn Sie Ihren Tarif gesenkt haben und mit der Leistung der Datenbank nicht zufrieden sind, verringern Sie die Workloads Ihrer Datenbank, oder stufen Sie den Tarif herauf.
Empfohlene Vorgehensweise bei der Problembehandlung
Befolgen Sie das Flussdiagramm für eine empfohlene Vorgehensweise bei der Behandlung von Leistungsproblemen mithilfe von Intelligent Insights.
Sie greifen auf Intelligent Insights über das Azure-Portal zu, indem Sie zu Azure SQL-Analyse navigieren. Versuchen Sie, eine eingehende Leistungswarnung zu finden, und wählen Sie sie aus. Ermitteln Sie auf der Seite „Erkennungen“ die Sachlage. Beachten Sie die bereitgestellte Fehlerursachenanalyse für das Problem, den Abfragetext, die Trends bei den Abfragezeiten und die Entwicklung von Incidents. Versuchen Sie, mithilfe der Empfehlung von Intelligent Insights das Leistungsproblem zu lösen.
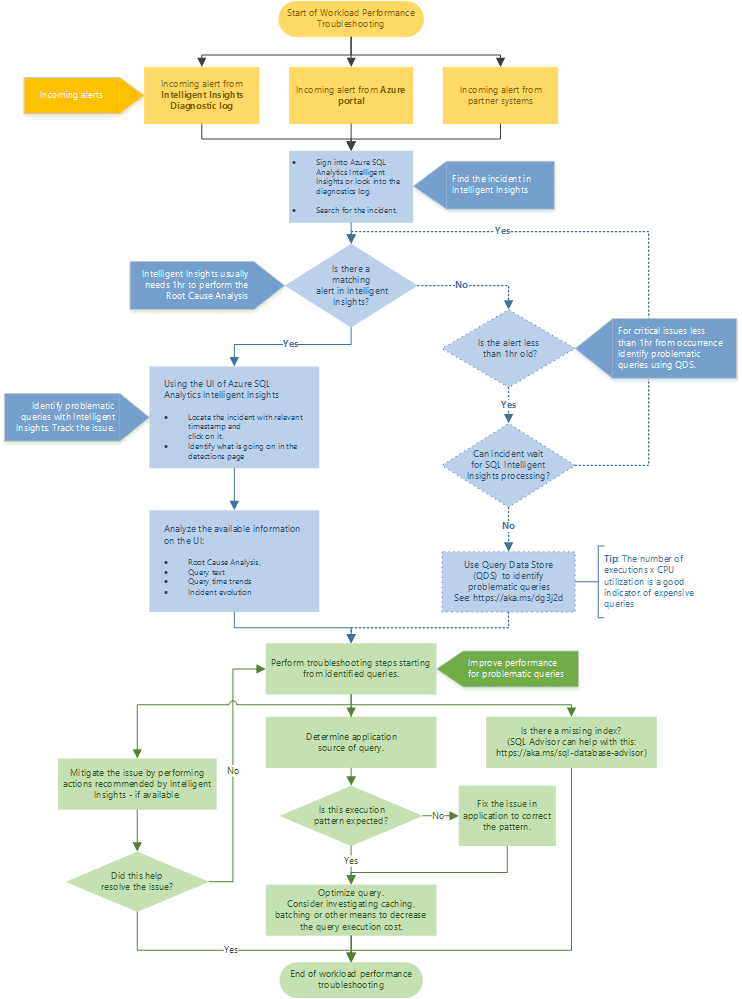
Tipp
Wählen Sie das Flussdiagramm aus, um eine PDF-Version herunterzuladen.
Intelligent Insights benötigt in der Regel eine Stunde für die Fehlerursachenanalyse eines Leistungsproblems. Wenn Sie Ihr Problem nicht in Intelligent Insights finden können, dies aber wichtig für Sie ist, verwenden Sie den Abfragespeicher, um manuell die Grundursache des Leistungsproblem zu identifizieren. (In der Regel sind diese Probleme weniger als eine Stunde alt.) Weitere Informationen finden Sie unter Leistungsüberwachung mit dem Abfragespeicher.
Zugehöriger Inhalt
- Intelligent Insights für die Überwachung und Problembehandlung der Datenbankleistung (Vorschau)
- Verwenden des Intelligent Insights-Diagnoseprotokolls für Leistungsprobleme bei Azure SQL-Datenbank und Azure SQL Managed Instance
- Azure SQL-Analysen
- Erfassen und Nutzen von Protokolldaten aus Ihren Azure-Ressourcen