Tutorial: Konfigurieren von Verfügbarkeitsgruppen für SQL Server auf virtuellen RHEL-Computern in Azure
Gilt für: ![]() SQL Server auf Azure VM
SQL Server auf Azure VM
Hinweis
In diesem Tutorial wird SQL Server 2017 (14.x) mit RHEL 7.6 verwendet. Hochverfügbarkeit kann aber auch mit SQL Server 2019 (15.x) in RHEL 7 oder RHEL 8 konfiguriert werden. Die Befehle zum Konfigurieren des Pacemaker-Clusters und von Verfügbarkeitsgruppenressourcen haben sich in RHEL 8 geändert. Informationen zu den korrekten Befehlen finden Sie im Artikel Erstellen von Verfügbarkeitsgruppenressourcen sowie in den RHEL 8-Ressourcen.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen einer neuen Ressourcengruppe, einer Verfügbarkeitsgruppe und eines virtuellen Linux-Computers
- Aktivieren von Hochverfügbarkeit (High Availability, HA)
- Erstellen eines Pacemaker-Clusters
- Konfigurieren eines Fencing-Agents durch Erstellen eines STONITH-Geräts
- Installieren von SQL Server und „mssql-tools“ unter RHEL
- Konfigurieren einer SQL Server-Always On-Verfügbarkeitsgruppe
- Konfigurieren von Verfügbarkeitsgruppenressourcen im Pacemaker-Cluster
- Testen von Failover und Fencing-Agent
In diesem Tutorial wird die Azure CLI verwendet, um Ressourcen in Azure bereitzustellen.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Verwenden Sie die Bash-Umgebung in Azure Cloud Shell. Weitere Informationen finden Sie unter Schnellstart für Bash in Azure Cloud Shell.

Wenn Sie CLI-Referenzbefehle lieber lokal ausführen, installieren Sie die Azure CLI. Wenn Sie Windows oder macOS ausführen, sollten Sie die Azure CLI in einem Docker-Container ausführen. Weitere Informationen finden Sie unter Ausführen der Azure CLI in einem Docker-Container.
Wenn Sie eine lokale Installation verwenden, melden Sie sich mithilfe des Befehls az login bei der Azure CLI an. Führen Sie die in Ihrem Terminal angezeigten Schritte aus, um den Authentifizierungsprozess abzuschließen. Informationen zu anderen Anmeldeoptionen finden Sie unter Anmelden mit der Azure CLI.
Installieren Sie die Azure CLI-Erweiterung beim ersten Einsatz, wenn Sie dazu aufgefordert werden. Weitere Informationen zu Erweiterungen finden Sie unter Verwenden von Erweiterungen mit der Azure CLI.
Führen Sie az version aus, um die installierte Version und die abhängigen Bibliotheken zu ermitteln. Führen Sie az upgrade aus, um das Upgrade auf die aktuelle Version durchzuführen.
- Für diesen Artikel ist mindestens Version 2.0.30 der Azure CLI erforderlich. Bei Verwendung von Azure Cloud Shell ist die aktuelle Version bereits installiert.
Erstellen einer Ressourcengruppe
Sollten Sie über mehrere Abonnements verfügen, legen Sie das Abonnement fest, für das Sie diese Ressourcen bereitstellen möchten.
Verwenden Sie den folgenden Befehl, um eine Ressourcengruppe (<resourceGroupName>) in einer Region zu erstellen. Ersetzen Sie <resourceGroupName> durch einen Namen Ihrer Wahl. In diesem Tutorial wird East US 2 verwendet. Weitere Informationen finden Sie in dieser Schnellstartanleitung.
az group create --name <resourceGroupName> --location eastus2
Verfügbarkeitsgruppe erstellen
Im nächsten Schritt wird eine Verfügbarkeitsgruppe erstellt. Führen Sie in Azure Cloud Shell den folgenden Befehl aus, und ersetzen Sie dabei <resourceGroupName> durch den Namen Ihrer Ressourcengruppe. Wählen Sie einen Namen für <availabilitySetName> aus.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Die Ergebnisse des abgeschlossenen Befehls sollten wie folgt aussehen:
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Erstellen virtueller RHEL-Computer innerhalb der Verfügbarkeitsgruppe
Warnung
Wenn Sie sich für ein RHEL-Image mit nutzungsbasierter Bezahlung (Pay-As-You-Go, PAYG) entscheiden und Hochverfügbarkeit konfigurieren, müssen Sie Ihr Abonnement ggf. registrieren. Dies kann dazu führen, dass Sie zweimal für das Abonnement bezahlen, da Ihnen das Microsoft Azure-RHEL-Abonnement für den virtuellen Computer und ein Abonnement für Red Hat in Rechnung gestellt werden. Weitere Informationen finden Sie unter https://access.redhat.com/solutions/2458541.
Verwenden Sie beim Erstellen des virtuellen Azure-Computers ein RHEL-HA-Image, um eine doppelte Abrechnung zu vermeiden. Als RHEL-HA-Images angebotene Images sind PAYG-Images mit vorab aktiviertem HA-Repository.
Rufen Sie wie folgt eine Liste mit VM-Images ab, die RHEL mit Hochverfügbarkeit bieten:
az vm image list --all --offer "RHEL-HA"Die Ergebnisse sollten wie folgt aussehen:
[ { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.4", "urn": "RedHat:RHEL-HA:7.4:7.4.2019062021", "version": "7.4.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.5", "urn": "RedHat:RHEL-HA:7.5:7.5.2019062021", "version": "7.5.2019062021" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "7.6", "urn": "RedHat:RHEL-HA:7.6:7.6.2019062019", "version": "7.6.2019062019" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.0", "urn": "RedHat:RHEL-HA:8.0:8.0.2020021914", "version": "8.0.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "8.1", "urn": "RedHat:RHEL-HA:8.1:8.1.2020021914", "version": "8.1.2020021914" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "80-gen2", "urn": "RedHat:RHEL-HA:80-gen2:8.0.2020021915", "version": "8.0.2020021915" }, { "offer": "RHEL-HA", "publisher": "RedHat", "sku": "81_gen2", "urn": "RedHat:RHEL-HA:81_gen2:8.1.2020021915", "version": "8.1.2020021915" } ]Für dieses Tutorial wählen wir das Image
RedHat:RHEL-HA:7.6:7.6.2019062019für das RHEL 7-Beispiel undRedHat:RHEL-HA:8.1:8.1.2020021914für das RHEL 8-Beispiel aus.Sie können auch die Option wählen, bei der SQL Server 2019 (15.x) auf RHEL8-HA-Images vorinstalliert ist. Führen Sie zum Abrufen der Liste mit diesen Images den folgenden Befehl aus:
az vm image list --all --offer "sql2019-rhel8"Die Ergebnisse sollten wie folgt aussehen:
[ { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "enterprise", "urn": "MicrosoftSQLServer:sql2019-rhel8:enterprise:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "sqldev", "urn": "MicrosoftSQLServer:sql2019-rhel8:sqldev:15.0.200512", "version": "15.0.200512" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200317", "version": "15.0.200317" }, { "offer": "sql2019-rhel8", "publisher": "MicrosoftSQLServer", "sku": "standard", "urn": "MicrosoftSQLServer:sql2019-rhel8:standard:15.0.200512", "version": "15.0.200512" } ]Wenn Sie eines der oben aufgeführten Images verwenden, um die virtuellen Computer zu erstellen, ist SQL Server 2019 (15.x) vorinstalliert. Überspringen Sie den Abschnitt Installieren von SQL Server und „mssql-tools“ wie in diesem Artikel beschrieben.
Wichtig
Computernamen müssen weniger als 15 Zeichen umfassen, um die Verfügbarkeitsgruppe einrichten zu können. Der Benutzername darf keine Großbuchstaben enthalten, und Kennwörter müssen länger als 12 Zeichen sein.
Wir möchten in der Verfügbarkeitsgruppe drei virtuelle Computer erstellen. Ersetzen Sie diese Werte im folgenden Befehl:
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>: Ein Beispiel wäre etwa „Standard_D16_v3“.<username><adminPassword>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --image "RedHat:RHEL-HA:7.6:7.6.2019062019" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys done
Der obige Befehl erstellt die virtuellen Computer sowie ein standardmäßiges virtuelles Netzwerk für diese virtuellen Computer. Weitere Informationen zu den verschiedenen Konfigurationen finden Sie im Artikel zu „az vm create“.
Nach Abschluss des Befehls für die einzelnen virtuellen Computer sollten die Ergebnisse in etwa wie folgt aussehen:
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/<VM1>",
"location": "eastus2",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"publicIpAddress": "",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Wichtig
Durch das mit dem obigen Befehl erstellte Standardimage wird standardmäßig ein Betriebssystemdatenträger mit einer Kapazität von 32 GB erstellt. Bei dieser Standardinstallation besteht ggf. die Gefahr, dass der Speicherplatz nicht ausreicht. Daher können Sie dem obigen Befehl az vm create den folgenden Parameter hinzufügen, um beispielsweise einen Betriebssystemdatenträger mit 128 GB zu erstellen: --os-disk-size-gb 128.
Anschließend können Sie Logical Volume Manager (LVM) konfigurieren, um bei Bedarf die entsprechenden Ordnervolumes für Ihre Installation zu erweitern.
Testen der Verbindung mit den erstellten virtuellen Computern
Stellen Sie mithilfe des folgenden Befehls in Azure Cloud Shell eine Verbindung mit „VM1“ oder den anderen virtuellen Computern her. Sollten Sie die IP-Adressen Ihrer VMs nicht finden, lesen Sie diese Schnellstartanleitung zu Azure Cloud Shell.
ssh <username>@publicipaddress
Nach erfolgreicher Verbindungsherstellung sollte die folgende Ausgabe (Linux-Terminal) angezeigt werden:
[<username>@<VM1> ~]$
Geben Sie exit ein, um die SSH-Sitzung zu verlassen.
Aktivieren der Hochverfügbarkeit
Wichtig
Für diesen Teil des Tutorials benötigen Sie ein Abonnement für RHEL sowie das Add-On für Hochverfügbarkeit. Wenn Sie eines der im vorherigen Abschnitt empfohlenen Images verwenden, müssen Sie kein weiteres Abonnement registrieren.
Stellen Sie eine Verbindung mit den einzelnen VM-Knoten her, und gehen Sie wie im Anschluss beschrieben vor, um Hochverfügbarkeit zu aktivieren. Weitere Informationen finden Sie unter Aktivieren des Hochverfügbarkeitsabonnements für RHEL.
Tipp
Der Einfachheit halber empfiehlt es sich, gleichzeitig eine SSH-Sitzung mit jedem der virtuellen Computer zu öffnen, da im Rahmen des Artikels auf jedem virtuellen Computer die gleichen Befehle ausgeführt werden müssen.
Wenn Sie mehrere sudo-Befehle kopieren und einfügen und zur Eingabe eines Kennworts aufgefordert werden, werden die weiteren Befehle nicht ausgeführt. Führen Sie die Befehle jeweils separat aus.
Führen Sie auf jedem virtuellen Computer die folgenden Befehle aus, um die Pacemaker-Firewallports zu öffnen:
sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadAktualisieren und installieren Sie die Pacemaker-Pakete auf allen Knoten mithilfe der folgenden Befehle:
Hinweis
nmap wird im Rahmen dieses Befehlsblocks als Tool für die Suche nach verfügbaren IP-Adressen in Ihrem Netzwerk installiert. Sie müssen nmap zwar nicht installieren, es ist jedoch später in diesem Tutorial hilfreich.
sudo yum update -y sudo yum install -y pacemaker pcs fence-agents-all resource-agents fence-agents-azure-arm nmap sudo rebootLegen Sie das Kennwort für den Standardbenutzer fest, der beim Installieren von Pacemaker-Paketen erstellt wird. Verwenden Sie auf allen Knoten dasselbe Kennwort.
sudo passwd haclusterVerwenden Sie den folgenden Befehl, um die Hostdatei zu öffnen und die Hostnamensauflösung einzurichten. Weitere Informationen zum Konfigurieren der Hostdatei finden Sie unter Konfigurieren von SQL Server-Always On-Verfügbarkeitsgruppen für Hochverfügbarkeit unter Linux.
sudo vi /etc/hostsGeben Sie im vi-Editor
iein, um Text einzufügen, und fügen Sie in einer leeren Zeile die private IP-Adresse des entsprechenden virtuellen Computers hinzu. Fügen Sie nach der IP-Adresse ein Leerzeichen und den VM-Namen hinzu. Jede Zeile muss einen separaten Eintrag enthalten.<IP1> <VM1> <IP2> <VM2> <IP3> <VM3>Wichtig
Es empfiehlt sich, im vorherigen Beispiel Ihre private IP-Adresse zu verwenden. Mit der öffentlichen IP-Adresse ist diese Einrichtung nicht erfolgreich, und es wird davon abgeraten, den virtuellen Computer für externe Netzwerke verfügbar zu machen.
Drücken Sie zum Verlassen des vi-Editors ESC, und geben Sie anschließend den Befehl
:wqein, um die Datei zu schreiben und den Editor zu beenden.
Erstellen eines Pacemaker-Clusters
In diesem Abschnitt wird der pcsd-Dienst aktiviert und gestartet und anschließend der Cluster konfiguriert. Für SQL Server für Linux werden die Clusterressourcen nicht automatisch erstellt. Die Pacemaker-Ressourcen müssen manuell aktiviert und erstellt werden. Weitere Informationen finden Sie im Artikel Konfigurieren eines RHEL-FCI-Clusters (Failoverclusterinstanz) für SQL Server.
Aktivieren und starten Sie den pcsd-Dienst und Pacemaker.
Führen Sie die Befehle auf allen Knoten aus. Diese Befehle sorgen dafür, dass die Knoten dem Cluster nach dem Neustart erneut hinzugefügt werden können.
sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerEntfernen Sie alle vorhandenen Clusterkonfigurationen von allen Knoten. Führen Sie den folgenden Befehl aus:
sudo pcs cluster destroy sudo systemctl enable pacemakerFühren Sie auf dem primären Knoten die folgenden Befehle aus, um den Cluster einzurichten.
- Wenn Sie den Befehl
pcs cluster authzum Authentifizieren der Clusterknoten ausführen, werden Sie zur Eingabe eines Kennworts aufgefordert. Geben Sie das Kennwort für den zuvor erstellten Benutzer hacluster ein.
RHEL7
sudo pcs cluster auth <VM1> <VM2> <VM3> -u hacluster sudo pcs cluster setup --name az-hacluster <VM1> <VM2> <VM3> --token 30000 sudo pcs cluster start --all sudo pcs cluster enable --allRHEL8
Bei RHEL 8 müssen Sie die Knoten separat authentifizieren. Geben Sie den Benutzernamen und das Kennwort für hacluster manuell ein, wenn Sie dazu aufgefordert werden.
sudo pcs host auth <node1> <node2> <node3> sudo pcs cluster setup <clusterName> <node1> <node2> <node3> sudo pcs cluster start --all sudo pcs cluster enable --all- Wenn Sie den Befehl
Vergewissern Sie sich mithilfe des folgenden Befehls, dass alle Knoten online sind:
sudo pcs statusRHEL 7
Sind alle Knoten online, sieht die Ausgabe in etwa wie im folgenden Beispiel aus:
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Stack: corosync Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum Last updated: Fri Aug 23 18:27:57 2019 Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> 3 nodes configured 0 resources configured Online: [ <VM1> <VM2> <VM3> ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledRHEL 8
Cluster name: az-hacluster WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: <VM2> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum * Last updated: Fri Aug 23 18:27:57 2019 * Last change: Fri Aug 23 18:27:56 2019 by hacluster via crmd on <VM2> * 3 nodes configured * 0 resource instances configured Node List: * Online: [ <VM1> <VM2> <VM3> ] Full List of Resources: * No resources Daemon Status: * corosync: active/enabled * pacemaker: active/enabled * pcsd: active/enabledLegen Sie die erwarteten Stimmen im aktiven Cluster auf „3“ fest. Dieser Befehl betrifft nur den aktiven Cluster und hat keine Änderung der Konfigurationsdateien zur Folge.
Legen Sie mithilfe des folgenden Befehls auf allen Knoten die erwarteten Stimmen fest:
sudo pcs quorum expected-votes 3
Konfigurieren des Fencing-Agents
Zum Konfigurieren eines Fencing-Agents werden die folgenden Anweisungen für dieses Lernprogramm geändert. Weitere Informationen finden Sie unter Erstellen des STONITH-Geräts.
Überprüfen Sie die Version des Azure Fence-Agents, um sich zu vergewissern, dass sie aktualisiert wurde. Verwenden Sie den folgenden Befehl:
sudo yum info fence-agents-azure-arm
Die Ausgabe sollte in etwa wie im folgenden Beispiel aussehen:
Loaded plugins: langpacks, product-id, search-disabled-repos, subscription-manager
Installed Packages
Name : fence-agents-azure-arm
Arch : x86_64
Version : 4.2.1
Release : 11.el7_6.8
Size : 28 k
Repo : installed
From repo : rhel-ha-for-rhel-7-server-eus-rhui-rpms
Summary : Fence agent for Azure Resource Manager
URL : https://github.com/ClusterLabs/fence-agents
License : GPLv2+ and LGPLv2+
Description : The fence-agents-azure-arm package contains a fence agent for Azure instances.
Registrieren Sie eine neue App in Microsoft Entra ID
Führen Sie die folgenden Schritte aus, um eine neue Anwendung in der Microsoft Entra-ID (vormals Azure Active Directory) zu registrieren:
- Wechseln Sie zu https://portal.azure.com.
- Öffnen Sie den Bereich Microsoft Entra ID-Eigenschaften, und notieren Sie sich
Tenant ID. - Wählen Sie App-Registrierungen aus.
- Wählen Sie Neue Registrierung aus.
- Geben Sie einen Namen ein (beispielsweise
<resourceGroupName>-app). Klicken Sie unter Unterstützte Kontotypen auf Nur Konten in diesem Organisationsverzeichnis (nur Microsoft – einzelner Mandant). - Wählen Sie Web für Umleitungs-URI aus, geben Sie eine URL ein (z. B.
http://localhost), und wählen Sie Hinzufügen aus. Die Anmelde-URL kann eine beliebige gültige URL sein. Wählen Sie anschließend Registrieren aus. - Wählen Sie für Ihre neue App-Registrierung Zertifikate und Geheimnisse und dann Neuer geheimer Clientschlüssel aus.
- Geben Sie eine Beschreibung für einen neuen Schlüssel (geheimer Clientschlüssel) ein, und wählen Sie dann Hinzufügen aus.
- Notieren Sie sich den Wert des Geheimnisses. Dieser wird als Kennwort für den Dienstprinzipal verwendet.
- Wählen Sie Übersicht. Notieren Sie sich die Anwendungs-ID. Sie wird als Benutzername (Anmelde-ID in den folgenden Schritten) des Dienstprinzipals verwendet.
Erstellen einer benutzerdefinierten Rolle für den Fence-Agent
Befolgen Sie die Anleitungen im Tutorial Erstellen einer benutzerdefinierten Azure-Rolle mit der Azure CLI.
Ihre JSON-Datei sollte dem folgenden Beispiel ähneln:
- Ersetzen Sie
<username>durch einen Namen Ihrer Wahl. Dieser Schritt dient dazu, Duplikate bei der Erstellung der Rollendefinition zu vermeiden. - Ersetzen Sie
<subscriptionId>durch Ihre Azure-Abonnement-ID.
{
"Name": "Linux Fence Agent Role-<username>",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [
],
"AssignableScopes": [
"/subscriptions/<subscriptionId>"
]
}
Führen Sie den folgenden Befehl aus, um die Rolle hinzuzufügen:
- Ersetzen Sie
<filename>durch den Namen der Datei. - Falls Sie den Befehl nicht in dem Ordner ausführen, in dem die Datei gespeichert ist, schließen Sie den Ordnerpfad der Datei in den Befehl ein.
az role definition create --role-definition "<filename>.json"
Die folgende Ausgabe wird angezeigt:
{
"assignableScopes": [
"/subscriptions/<subscriptionId>"
],
"description": "Allows to power-off and start virtual machines",
"id": "/subscriptions/<subscriptionId>/providers/Microsoft.Authorization/roleDefinitions/<roleNameId>",
"name": "<roleNameId>",
"permissions": [
{
"actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"dataActions": [],
"notActions": [],
"notDataActions": []
}
],
"roleName": "Linux Fence Agent Role-<username>",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
Zuweisen der benutzerdefinierten Rolle zum Dienstprinzipal
Weisen Sie dem Dienstprinzipal die benutzerdefinierte Rolle Linux Fence Agent Role-<username> zu, die im letzten Schritt erstellt wurde. Verwenden Sie nicht mehr die Besitzerrolle.
- Besuchen Sie https://portal.azure.com.
- Öffnen Sie den Bereich Alle Ressourcen.
- Wählen Sie den virtuellen Computer des ersten Clusterknotens aus.
- Wählen Sie Zugriffssteuerung (IAM) aus.
- Auswählen von Rollenzuweisung hinzufügen
- Wählen Sie in der Liste Rolle die Rolle
Linux Fence Agent Role-<username>aus. - Geben Sie in der Liste Auswählen den Namen der Anwendung ein, die Sie zuvor erstellt haben, z. B.
<resourceGroupName>-app. - Wählen Sie Speichern aus.
- Wiederholen Sie diese Schritte für alle Clusterknoten.
Erstellen des STONITH-Geräts
Führen Sie die folgenden Befehle für den ersten Knoten aus:
- Ersetzen Sie
<ApplicationID>durch den ID-Wert aus Ihrer Anwendungsregistrierung. - Ersetzen Sie
<servicePrincipalPassword>durch den Wert aus dem geheimen Clientschlüssel. - Ersetzen Sie
<resourceGroupName>durch die Ressourcengruppe aus Ihrem für dieses Tutorial verwendeten Abonnement. - Ersetzen Sie
<tenantID>und<subscriptionId>aus Ihrem Azure-Abonnement.
sudo pcs property set stonith-timeout=900
sudo pcs stonith create rsc_st_azure fence_azure_arm login="<ApplicationID>" passwd="<servicePrincipalPassword>" resourceGroup="<resourceGroupName>" tenantId="<tenantID>" subscriptionId="<subscriptionId>" power_timeout=240 pcmk_reboot_timeout=900
Da wir der Firewall bereits eine Regel hinzugefügt haben, um den Hochverfügbarkeitsdienst zuzulassen (--add-service=high-availability), müssen die folgenden Firewallports nicht für alle Knoten geöffnet werden: 2224, 3121, 21064, 5405. Sollten allerdings Verbindungsprobleme im Zusammenhang mit der Hochverfügbarkeit auftreten, verwenden Sie den folgenden Befehl, um diese mit der Hochverfügbarkeit zusammenhängenden Ports zu öffnen.
Tipp
Sie können optional auch alle Ports in diesem Tutorial gleichzeitig hinzufügen, um etwas Zeit zu sparen. Die zu öffnenden Ports werden weiter unten in den entsprechenden Abschnitten erläutert. Wenn Sie alle Ports sofort hinzufügen möchten, fügen Sie auch gleich die folgenden Ports hinzu: 1433 und 5022.
sudo firewall-cmd --zone=public --add-port=2224/tcp --add-port=3121/tcp --add-port=21064/tcp --add-port=5405/tcp --permanent
sudo firewall-cmd --reload
Installieren von SQL Server und „mssql-tools“
Hinweis
Wenn Sie die VMs mit einer Vorinstallation von SQL Server 2019 (15.x) unter RHEL8-HA erstellt haben, können Sie die unten angegebenen Schritte für die Installation von SQL Server und „mssql-tools“ überspringen. Starten Sie in diesem Fall mit dem Abschnitt Konfigurieren einer Verfügbarkeitsgruppe, nachdem Sie das Systemadministratorkennwort auf allen VMs eingerichtet haben, indem Sie den Befehl sudo /opt/mssql/bin/mssql-conf set-sa-password für alle VMs ausgeführt haben.
In diesem Abschnitt werden SQL Server und „mssql-tools“ auf den virtuellen Computern installiert. Sie können eines der unten angegebenen Beispiele auswählen, um SQL Server 2017 (14.x) auf RHEL 7 oder SQL Server 2019 (15.x) auf RHEL 8 zu installieren. Führen Sie jede dieser Aktionen auf allen Knoten aus. Weitere Informationen finden Sie unter Schnellstart: Installieren von SQL Server und Erstellen einer Datenbank unter Red Hat.
Installieren von SQL Server auf den VMs
Die folgenden Befehle dienen zum Installieren von SQL Server:
RHEL 7 mit SQL Server 2017
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
RHEL 8 mit SQL Server 2019
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/8/mssql-server-2019.repo
sudo yum install -y mssql-server
sudo /opt/mssql/bin/mssql-conf setup
sudo yum install mssql-server-ha
Öffnen des Firewallports 1433 für Remoteverbindungen
Auf dem virtuellen Computer muss der Port 1433 geöffnet werden, um Remoteverbindungen zu ermöglichen. Verwenden Sie die folgenden Befehle, um den Port 1433 in der Firewall der einzelnen virtuellen Computer zu öffnen:
sudo firewall-cmd --zone=public --add-port=1433/tcp --permanent
sudo firewall-cmd --reload
Installieren von SQL Server-Befehlszeilentools
Die folgenden Befehle dienen zum Installieren der SQL Server-Befehlszeilentools. Weitere Informationen finden Sie unter Installieren der SQL Server-Befehlszeilentools.
RHEL 7
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/7/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
RHEL 8
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/8/prod.repo
sudo yum install -y mssql-tools unixODBC-devel
Hinweis
Fügen Sie Ihrer PATH-Umgebungsvariablen der Einfachheit halber „/opt/mssql-tools/bin/“ hinzu. Dadurch können Sie die Tools ausführen, ohne den vollständigen Pfad angeben zu müssen. Führen Sie die folgenden Befehle aus, um den Pfad (PATH) sowohl für Anmeldesitzungen als auch für interaktive Sitzungen oder Sitzungen ohne Anmeldung zu ändern: echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profileecho 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrcsource ~/.bashrc
Überprüfen des Status der SQL Server-Instanz
Nach Abschluss der Konfiguration können Sie den Status der SQL Server-Instanz überprüfen und sich vergewissern, dass sie ausgeführt wird:
systemctl status mssql-server --no-pager
Die folgende Ausgabe wird angezeigt.
● mssql-server.service - Microsoft SQL Server Database Engine
Loaded: loaded (/usr/lib/systemd/system/mssql-server.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2019-12-05 17:30:55 UTC; 20min ago
Docs: https://learn.microsoft.com/sql/linux
Main PID: 11612 (sqlservr)
CGroup: /system.slice/mssql-server.service
├─11612 /opt/mssql/bin/sqlservr
└─11640 /opt/mssql/bin/sqlservr
Konfigurieren einer Verfügbarkeitsgruppe
Führen Sie die folgenden Schritte aus, um eine SQL Server-Always On-Verfügbarkeitsgruppe für Ihre virtuellen Computer zu konfigurieren. Weitere Informationen finden Sie unter Konfigurieren von SQL Server-Always On-Verfügbarkeitsgruppen für Hochverfügbarkeit unter Linux.
Aktivieren von Always On-Verfügbarkeitsgruppen und Neustarten von mssql-server
Aktivieren Sie Always On-Verfügbarkeitsgruppen auf jedem Knoten, der eine SQL Server-Instanz hostet. Starten Sie dann „mssql-server“ neu. Führen Sie folgendes Skript aus:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Erstellen eines Zertifikats
Für den Endpunkt der Verfügbarkeitsgruppe wird aktuell keine AD-Authentifizierung unterstützt. Daher müssen wir für die Verschlüsselung des Endpunkts der Verfügbarkeitsgruppe ein Zertifikat verwenden.
Stellen Sie über SQL Server Management Studio (SSMS) oder sqlcmd eine Verbindung mit allen Knoten her. Führen Sie die folgenden Befehle aus, um eine AlwaysOn_health-Sitzung zu aktivieren und einen Hauptschlüssel zu erstellen:
Wichtig
Falls Sie eine Remoteverbindung mit Ihrer SQL Server-Instanz herstellen, muss der Port 1433 in der Firewall geöffnet sein. Außerdem müssen in Ihrer NSG für jeden virtuellen Computer eingehende Verbindungen am Port 1433 zugelassen werden. Weitere Informationen zum Erstellen einer Eingangssicherheitsregel finden Sie unter Erstellen einer Sicherheitsregel.
- Ersetzen Sie
<Master_Key_Password>durch Ihr eigenes Kennwort.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Master_Key_Password>';- Ersetzen Sie
Stellen Sie über SSMS oder sqlcmd eine Verbindung mit dem primären Replikat her. Die folgenden Befehle erstellen auf Ihrem primären SQL Server-Replikat ein Zertifikat unter
/var/opt/mssql/data/dbm_certificate.cerund einen privaten Schlüssel untervar/opt/mssql/data/dbm_certificate.pvk:- Ersetzen Sie
<Private_Key_Password>durch Ihr eigenes Kennwort.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<Private_Key_Password>' ); GO- Ersetzen Sie
Beenden Sie die sqlcmd-Sitzung mithilfe des Befehls exit, und kehren Sie zu Ihrer SSH-Sitzung zurück.
Kopieren des Zertifikats auf die sekundären Replikate und Erstellen der Zertifikate auf dem Server
Kopieren Sie die beiden erstellten Dateien auf allen Servern, von denen Verfügbarkeitsreplikate gehostet werden, an den gleichen Speicherort.
Führen Sie auf dem primären Server den folgenden
scp-Befehl aus, um das Zertifikat auf die Zielserver zu kopieren:- Ersetzen Sie
<username>und<VM2>durch den Benutzernamen bzw. den Namen der verwendeten Ziel-VM. - Führen Sie diesen Befehl für alle sekundären Replikate aus.
Hinweis
Sie müssen nicht
sudo -iausführen, um die Stammumgebung zu erhalten. Es reicht, wenn Sie wie zuvor in diesem Tutorial vor jedem Befehl den Befehlsudoausführen.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@<VM2>:/home/<username>- Ersetzen Sie
Führen Sie auf dem Zielserver den folgenden Befehl aus:
- Ersetzen Sie
<username>durch Ihren Benutzernamen. - Der Befehl
mvverschiebt die Dateien oder das Verzeichnis an einen anderen Ort. - Der Befehl
chowndient zum Ändern des Besitzers und der Gruppe von Dateien, Verzeichnissen oder Links. - Führen Sie diese Befehle für alle sekundären Replikate aus.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Ersetzen Sie
Mit dem folgenden Transact-SQL-Skript wird ein Zertifikat auf der Grundlage der Sicherung erstellt, die Sie auf dem primären SQL Server-Replikat erstellt haben. Aktualisieren Sie das Skript durch sichere Kennwörter. Das Entschlüsselungskennwort ist das gleiche Kennwort, das Sie im vorherigen Schritt zum Erstellen der PVK-Datei verwendet haben. Um das Zertifikat zu erstellen, führen Sie das folgende Skript unter Verwendung von sqlcmd oder SSMS auf allen sekundären Servern aus:
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<Private_Key_Password>' ); GO
Erstellen des Datenbankspiegelungs-Endpunkte auf allen Replikaten
Führen Sie das folgende Skript unter Verwendung von sqlcmd oder SSMS in allen SQL Server-Instanzen aus:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Erstellen der Verfügbarkeitsgruppe
Stellen Sie unter Verwendung von sqlcmd oder SSMS eine Verbindung mit der SQL Server-Instanz her, die das primäre Replikat hostet. Führen Sie den folgenden Befehl aus, um die Verfügbarkeitsgruppe zu erstellen:
- Ersetzen Sie
ag1durch den gewünschten Namen für die Verfügbarkeitsgruppe. - Ersetzen Sie die Werte
<VM1>,<VM2>und<VM3>durch die Namen der SQL Server-Instanzen, von denen die Replikate gehostet werden.
CREATE AVAILABILITY GROUP [ag1]
WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<VM1>'
WITH (
ENDPOINT_URL = N'tcp://<VM1>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM2>'
WITH (
ENDPOINT_URL = N'tcp://<VM2>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<VM3>'
WITH(
ENDPOINT_URL = N'tcp://<VM3>:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
GO
Erstellen einer SQL Server-Anmeldung für Pacemaker
Erstellen Sie in allen SQL Server-Instanzen eine SQL Server-Anmeldung für Pacemaker. Mit dem folgenden Transact-SQL-Skript wird eine Anmeldung erstellt.
- Ersetzen Sie
<password>durch Ihr eigenes komplexes Kennwort.
USE [master]
GO
CREATE LOGIN [pacemakerLogin] with PASSWORD= N'<password>';
GO
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin];
GO
Speichern Sie in allen SQL Server-Instanzen die für die SQL Server-Anmeldung verwendeten Anmeldeinformationen.
Erstellen Sie die Datei:
sudo vi /var/opt/mssql/secrets/passwdFügen Sie der Datei die folgenden Zeilen hinzu:
pacemakerLogin <password>Drücken Sie zum Verlassen des vi-Editors ESC, und geben Sie anschließend den Befehl
:wqein, um die Datei zu schreiben und den Editor zu beenden.Sorgen Sie dafür, dass die Datei nur mit root-Berechtigungen lesbar ist:
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Verknüpfen sekundärer Replikate mit der Verfügbarkeitsgruppe
Um die sekundären Replikate mit der Verfügbarkeitsgruppe verknüpfen zu können, muss der Port 5022 in der Firewall für alle Server geöffnet werden. Führen Sie in Ihrer SSH-Sitzung den folgenden Befehl aus:
sudo firewall-cmd --zone=public --add-port=5022/tcp --permanent sudo firewall-cmd --reloadFühren Sie auf Ihren sekundären Replikaten die folgenden Befehle aus, um die Replikate mit der Verfügbarkeitsgruppe zu verknüpfen:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOFühren Sie auf dem primären Replikat sowie auf jedem sekundären Replikat das folgende Transact-SQL-Skript aus:
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GONachdem die sekundären Replikate verknüpft wurden, können Sie sie im SSMS-Objekt-Explorer anzeigen, indem Sie den Knoten Hochverfügbarkeit mit Always On erweitern:
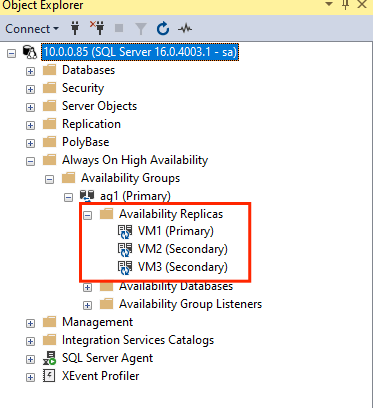
Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe
Wir gehen wie unter Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe beschrieben vor.
In diesem Schritt werden die folgenden Transact-SQL-Befehle verwendet. Führen Sie diese Befehle auf dem primären Replikat aus:
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery model
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Sicherstellen, dass die Datenbank auf den sekundären Servern erstellt wird
Führen Sie auf jedem sekundären SQL Server-Replikat die folgende Abfrage aus, um zu ermitteln, ob die Datenbank „db1“ erstellt wurde und sich im Zustand „SYNCHRONIZED“ (Synchronisiert) befindet:
SELECT * FROM sys.databases WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database', synchronization_state_desc FROM sys.dm_hadr_database_replica_states;
Wenn synchronization_state_desc für db1 den Zustand „SYNCHRONIZED“ (SYNCHRONISIERT) angibt, wurden die Replikate synchronisiert. Für die sekundären Replikate wird db1 im primären Replikat angezeigt.
Erstellen von Verfügbarkeitsgruppenressourcen im Pacemaker-Cluster
Wir gehen wie unter Erstellen der Verfügbarkeitsgruppenressourcen im Pacemaker-Cluster (nur „Extern“) beschrieben vor.
Hinweis
Vorurteilsfreie Kommunikation
In diesem Artikel wird der Begriff Slave (Sklave) verwendet, der in diesem Kontext von Microsoft als beleidigend eingestuft wird. Der Begriff wird in diesem Artikel verwendet, weil er derzeit in der Software verwendet wird. Sobald der Begriff aus der Software entfernt wird, wird er auch aus dem Artikel entfernt.
Erstellen der Verfügbarkeitsgruppen-Clusterressource
Verwenden Sie je nach Umgebung, die Sie oben ausgewählt haben, einen der folgenden Befehle, um die Ressource
ag_clusterin der Verfügbarkeitsgruppeag1zu erstellen.RHEL 7
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s master notify=trueRHEL 8
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s promotable notify=trueStellen Sie sicher, dass Ihre Ressourcen online sind, bevor Sie mit dem nächsten Befehl fortfahren:
sudo pcs resourceDie folgende Ausgabe wird angezeigt.
RHEL 7
[<username>@VM1 ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM1> ] Slaves: [ <VM2> <VM3> ]RHEL 8
[<username>@VM1 ~]$ sudo pcs resource * Clone Set: ag_cluster-clone [ag_cluster] (promotable): * ag_cluster (ocf::mssql:ag) : Slave VMrhel3 (Monitoring) * ag_cluster (ocf::mssql:ag) : Master VMrhel1 (Monitoring) * ag_cluster (ocf::mssql:ag) : Slave VMrhel2 (Monitoring)
Erstellen einer virtuellen IP-Ressource
Verwenden Sie eine verfügbare statische IP-Adresse aus Ihrem Netzwerk, um eine virtuelle IP-Ressource zu erstellen. Zur Ermittlung können Sie das Befehlstool
nmapverwenden.nmap -sP <IPRange> # For example: nmap -sP 10.0.0.* # The above will scan for all IP addresses that are already occupied in the 10.0.0.x space.Legen Sie die Eigenschaft stonith-enabled auf „false“ fest:
sudo pcs property set stonith-enabled=falseVerwenden Sie den folgenden Befehl, um die virtuelle IP-Ressource zu erstellen. Ersetzen Sie den Wert
<availableIP>durch eine ungenutzte IP-Adresse.sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=<availableIP>
Hinzufügen von Einschränkungen
Es muss eine Kollokationseinschränkung konfiguriert werden, um sicherzustellen, dass die IP-Adresse und die Verfügbarkeitsgruppenressource auf demselben Knoten ausgeführt werden. Führen Sie den folgenden Befehl aus:
RHEL 7
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=MasterRHEL 8
sudo pcs constraint colocation add virtualip with master ag_cluster-clone INFINITY with-rsc-role=MasterErstellen Sie eine Sortierungseinschränkung, um sicherzustellen, dass die Verfügbarkeitsgruppenressource vor der IP-Adresse ausgeführt wird. Obwohl die Kollokationseinschränkung eine Sortierungseinschränkung impliziert, erzwingt sie diese.
RHEL 7
sudo pcs constraint order promote ag_cluster-master then start virtualipRHEL 8
sudo pcs constraint order promote ag_cluster-clone then start virtualipFühren Sie den folgenden Befehl aus, um die Einschränkungen zu überprüfen:
sudo pcs constraint list --fullDie folgende Ausgabe wird angezeigt.
RHEL 7
Location Constraints: Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
Location Constraints: Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:
Reaktivieren von STONITH
Wir sind nun testbereit. Reaktivieren Sie STONITH im Cluster, indem Sie auf dem ersten Knoten den folgenden Befehl ausführen:
sudo pcs property set stonith-enabled=true
Überprüfen des Clusterstatus
Der Status Ihrer Clusterressourcen kann mithilfe des folgenden Befehls überprüft werden:
[<username>@VM1 ~]$ sudo pcs status
Cluster name: az-hacluster
Stack: corosync
Current DC: <VM3> (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum
Last updated: Sat Dec 7 00:18:38 2019
Last change: Sat Dec 7 00:18:02 2019 by root via cibadmin on VM1
3 nodes configured
5 resources configured
Online: [ <VM1> <VM2> <VM3> ]
Full list of resources:
Master/Slave Set: ag_cluster-master [ag_cluster]
Masters: [ <VM2> ]
Slaves: [ <VM1> <VM3> ]
virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
rsc_st_azure (stonith:fence_azure_arm): Started <VM1>
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Testfailover
Führen Sie ein Testfailover durch, um sich zu vergewissern, dass die bisherige Konfiguration erfolgreich war. Weitere Informationen finden Sie unter Failover der Always On-Verfügbarkeitsgruppe unter Linux.
Führen Sie den folgenden Befehl aus, um ein manuelles Failover des primären Replikats auf
<VM2>durchzuführen. Ersetzen Sie<VM2>durch Ihren Servernamen.RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --masterSie können auch eine zusätzliche Option angeben, damit die vorübergehende Einschränkung, die erstellt wird, um die Ressource auf einen gewünschten Knoten zu verschieben, automatisch deaktiviert wird und Sie die Schritte 2 und 3 in den folgenden Anweisungen nicht ausführen müssen.
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master lifetime=30SRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master lifetime=30SEine weitere Alternative zur Automatisierung der weiter unten angegebenen Schritte 2 und 3, durch die die vorübergehende Einschränkung direkt im Befehl für die Ressourcenverschiebung entfernt wird, besteht darin, mehrere Befehle in einer einzelnen Zeile zu kombinieren.
RHEL 7
sudo pcs resource move ag_cluster-master <VM2> --master && sleep 30 && pcs resource clear ag_cluster-masterRHEL 8
sudo pcs resource move ag_cluster-clone <VM2> --master && sleep 30 && pcs resource clear ag_cluster-cloneWenn Sie Ihre Einschränkungen erneut überprüfen, sehen Sie, dass aufgrund des manuellen Failovers eine weitere Einschränkung hinzugefügt wurde:
RHEL 7
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-master) Ordering Constraints: promote ag_cluster-master then start virtualip (kind:Mandatory) (id:order-ag_cluster-master-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-master (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-master-INFINITY) Ticket Constraints:RHEL 8
[<username>@VM1 ~]$ sudo pcs constraint list --full Location Constraints: Resource: ag_cluster-master Enabled on: VM2 (score:INFINITY) (role: Master) (id:cli-prefer-ag_cluster-clone) Ordering Constraints: promote ag_cluster-clone then start virtualip (kind:Mandatory) (id:order-ag_cluster-clone-virtualip-mandatory) Colocation Constraints: virtualip with ag_cluster-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-virtualip-ag_cluster-clone-INFINITY) Ticket Constraints:Entfernen Sie die Einschränkung mit der ID
cli-prefer-ag_cluster-mastermithilfe des folgenden Befehls:RHEL 7
sudo pcs constraint remove cli-prefer-ag_cluster-masterRHEL 8
sudo pcs constraint remove cli-prefer-ag_cluster-cloneÜberprüfen Sie Ihre Clusterressourcen mithilfe des Befehls
sudo pcs resource. Die primäre Instanz sollte nun<VM2>sein.[<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] ag_cluster (ocf::mssql:ag): FAILED <VM1> (Monitoring) Masters: [ <VM2> ] Slaves: [ <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2> [<username>@<VM1> ~]$ sudo pcs resource Master/Slave Set: ag_cluster-master [ag_cluster] Masters: [ <VM2> ] Slaves: [ <VM1> <VM3> ] virtualip (ocf::heartbeat:IPaddr2): Started <VM2>
Testen des Fencings
Die Umgrenzung kann durch Ausführen des folgenden Befehls getestet werden. Führen Sie den folgenden Befehl auf <VM1> für <VM3>aus.
sudo pcs stonith fence <VM3> --debug
Hinweis
Standardmäßig wird der Knoten durch die Aktion „fence“ offline und anschließend wieder online geschaltet. Wenn Sie den Knoten nur offline schalten möchten, verwenden Sie im Befehl die Option --off.
Die Ausgabe sollte wie folgt aussehen:
[<username>@<VM1> ~]$ sudo pcs stonith fence <VM3> --debug
Running: stonith_admin -B <VM3>
Return Value: 0
--Debug Output Start--
--Debug Output End--
Node: <VM3> fenced
Weitere Informationen zum Testen eines Fence-Geräts finden Sie in diesem Red Hat-Artikel.