Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Backup bietet ein integriertes Vor- und Postscript-Framework , um die Anwendungskonsistenz für Linux-VMs während der Sicherung sicherzustellen. Dieses Framework führt automatisch ein Präscript aus, um Anwendungen vor Datenträger-Momentaufnahmen zu deaktivieren, sowie ein Postscript, um Anwendungen nach dem Snapshot wieder in den normalen Betrieb zu versetzen.
Das Verwalten von benutzerdefinierten Vor- und Postscripts ist häufig komplex und zeitaufwändig. Um diesen Prozess zu vereinfachen, bietet Azure Backup einsatzbereite Pre-Skripte und Post-Skripte für beliebte Datenbanken, um anwendungskonsistente Snapshots mit minimalem Aufwand und Wartung zu ermöglichen.
Das folgende Diagramm veranschaulicht, wie Azure Backup erweiterte Vorskripte und Nachskripte verwendet, um anwendungskonsistente Momentaufnahmen für Linux-Datenbanken zu erzielen, was eine zuverlässige Sicherung und Wiederherstellung gewährleistet.
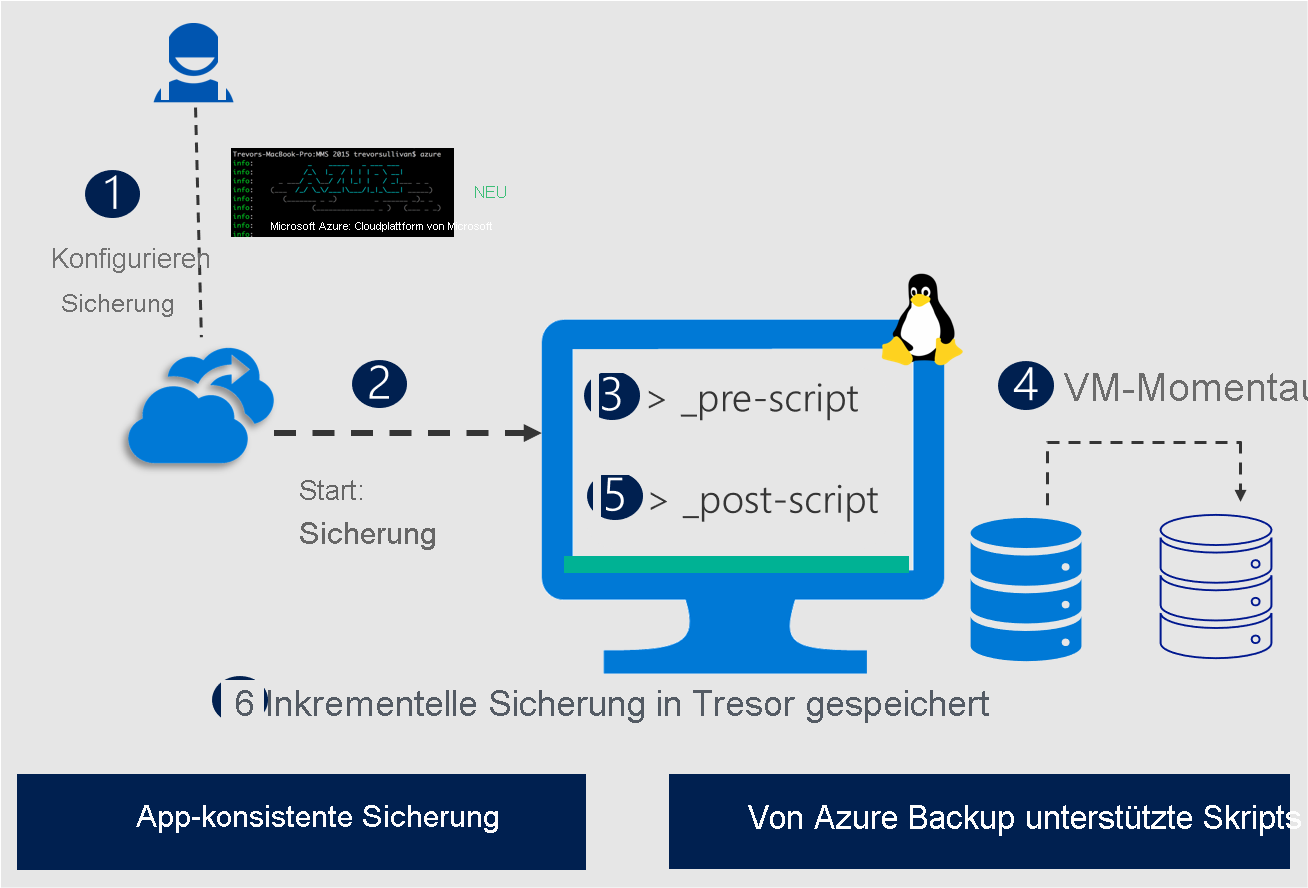
Wichtige Vorteile eines verbesserten Vorskript- und Postscript-Frameworks
Das neue erweiterte Präskript- und Postskript-Framework bietet die folgenden wesentlichen Vorteile:
- Diese Prä- und Postscripts werden zusammen mit der Sicherungserweiterung direkt in Azure-VMs installiert, sodass das Erstellen und Herunterladen von einem externen Speicherort entfällt.
- Die Definition und der Inhalt von Präscripts und Postscripts stehen auf GitHub zur Verfügung. Sie können Vorschläge und Änderungen über GitHub übermitteln, die priorisiert werden und der breiteren Community zugutekommen.
- Neue Prescripts und Postscripts für andere Datenbanken sind über GitHub verfügbar, die sortiert und bearbeitet werden, um der breiteren Community zu helfen.
- Der robuste Rahmen ist in der Lage, Szenarien wie Fehler bei der Ausführung von Skripten oder Abstürze zu bewältigen. In jedem Fall wird das Postscript automatisch ausgeführt, um alle im Präscript vorgenommenen Änderungen rückgängig zu machen.
- Das Framework bietet auch einen Messagingkanal für externe Tools, um Updates abzurufen und ihren eigenen Aktionsplan für jede Nachricht oder jedes Ereignis vorzubereiten.
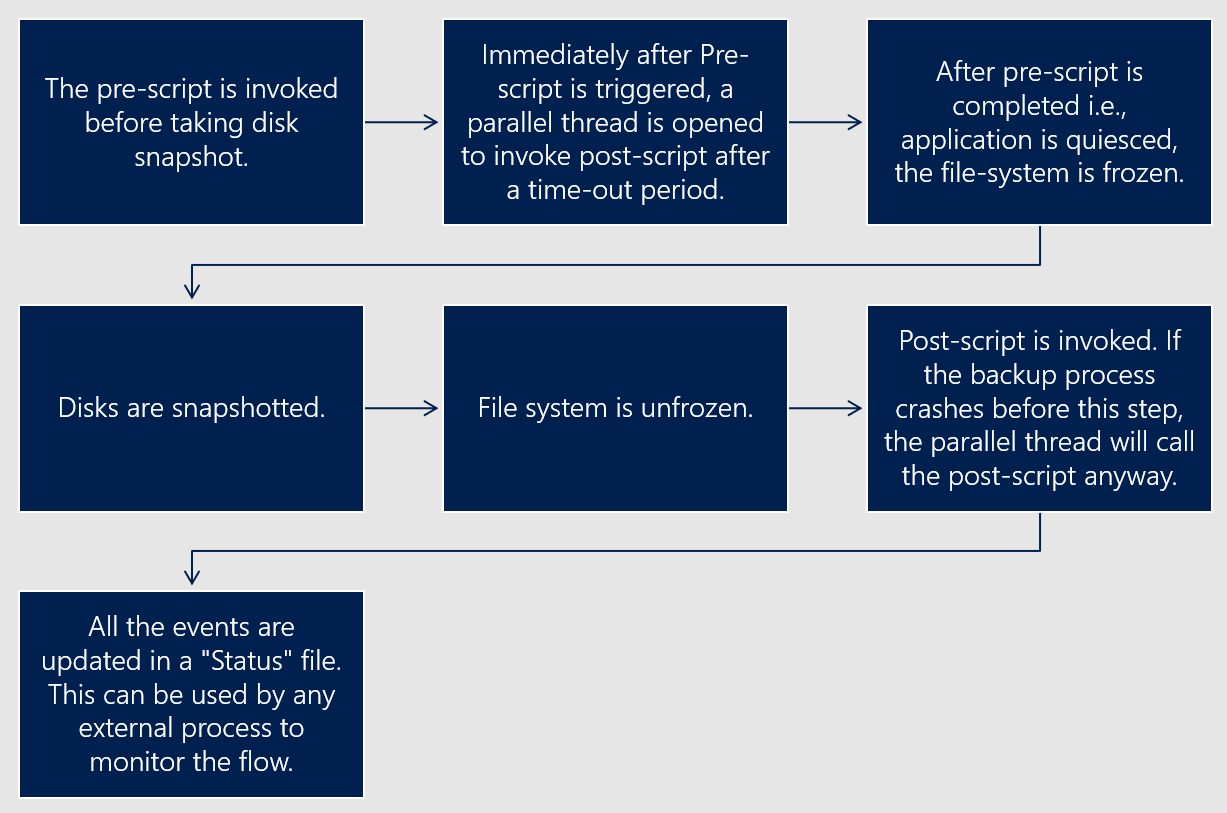
Lösungsfluss des erweiterten Präscript- und Postscript-Frameworks
Das folgende Diagramm veranschaulicht den Ablauf der Lösung des erweiterten Präscript- und Postscript-Frameworks für datenbankkonsistente Momentaufnahmen.
Unterstützungsmatrix
Die folgenden Datenbanken werden unter dem erweiterten Framework behandelt:
- Oracle (allgemein verfügbar):Siehe Supportmatrix für Azure VM-Sicherungen.
- MySQL (Vorschau).
Voraussetzungen
Sie müssen nur eine Konfigurationsdatei, workload.conf in /etc/azure, ändern, um Verbindungsdetails bereitzustellen. Auf diese Weise kann Azure Backup eine Verbindung mit der relevanten Anwendung herstellen und Prescripts und Postscripts ausführen. Die Konfigurationsdatei weist die folgenden Parameter auf:
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
In der folgenden Tabelle werden die Parameter beschrieben.
| Parameter | Obligatorisch. | Erklärung |
|---|---|---|
workload_name |
Ja | Enthält den Namen der Datenbank, für die Sie eine anwendungskonsensige Sicherung benötigen. Die derzeit unterstützten Werte sind oracle oder mysql. |
command_path/configuration_path |
Enthält einen Pfad zur Workload-Binärdatei. Dieses Feld ist nicht obligatorisch, wenn die Workload-Binärdatei als Pfadvariable festgelegt wird. | |
linux_user |
Ja | Enthält den Benutzernamen des Linux-Benutzers mit Zugriff auf die Anmeldung des Datenbankbenutzers. Wenn dieser Wert nicht festgelegt ist, wird root als Standardbenutzer verwendet. |
credString |
Bezeichnet die Zugangsdatenzeichenfolge zum Herstellen einer Verbindung mit der Datenbank. Enthält die gesamte Anmeldezeichenfolge. | |
ipc_folder |
Arbeitsauslastung kann nur in bestimmte Dateisystempfade geschrieben werden. Bitte geben Sie diesen Ordnerpfad an, damit das Skript die Zustände in den angegebenen Ordner schreiben kann. | |
timeout |
Ja | Maximale Zeitbegrenzung, für die sich die Datenbank in einem ruhen Zustand befindet. Der Standardwert ist 90 Sekunden. Legen Sie keinen Wert unter 60 Sekunden fest. |
Hinweis
Die JSON-Definition ist eine Vorlage, die Von Azure Backup an eine bestimmte Datenbank angepasst werden kann. Informationen zur Konfigurationsdatei für jede Datenbank finden Sie im Handbuch jeder Datenbank.
Die Gesamterfahrung zur Nutzung des erweiterten Präskript- und Postskript-Frameworks ist wie folgt:
- Vorbereiten der Datenbankumgebung.
- Bearbeiten Sie die Konfigurationsdatei.
- Starten Sie das VM-Backup.
- Stellen Sie VMs oder Datenträger oder Dateien nach Bedarf aus dem anwendungseinheitlichen Wiederherstellungspunkt wieder her.
Erstellen einer Datenbank-Backup-Strategie
Verwenden von Momentaufnahmen anstelle des Streamings
In der Regel verwenden Datenbankadministratoren in ihrer Sicherungsstrategie Streaming-Backups (z. B. vollständige, differenzielle oder inkrementelle Backups) und Protokolle. Die wichtigsten Punkte im Design sind:
- Leistung und Kosten: Eine tägliche vollständige Sicherung plus Protokolle ist die schnellste während der Wiederherstellung, erfordert jedoch erhebliche Kosten. Die Einbeziehung der differenziellen oder inkrementellen Streaming-Backup-Variante reduziert die Kosten, kann aber die Wiederherstellungsleistung beeinträchtigen. Snapshots bieten jedoch die beste Kombination aus Leistung und Kosten. Da Momentaufnahmen inhärent inkrementell sind, haben sie die geringste Auswirkung auf die Leistung während der Sicherung, werden schnell wiederhergestellt und sparen auch Kosten.
- Auswirkungen auf Datenbank oder Infrastruktur: Die Leistung einer Streamingsicherung hängt von den zugrunde liegenden Speicher-IOPS und der Netzwerkbandbreite ab, die verfügbar ist, wenn der Stream an einen Remotestandort ausgerichtet ist. Momentaufnahmen haben diese Abhängigkeit nicht, und die Nachfrage nach IOPS und Netzwerkbandbreite wird reduziert.
- Wiederverwendbarkeit: Die Befehle zum Auslösen verschiedener Streamingsicherungstypen sind für jede Datenbank unterschiedlich, sodass Skripts nicht einfach wiederverwendet werden können. Wenn Sie unterschiedliche Sicherungstypen verwenden, sollten Sie auch die Abhängigkeitskette auswerten, um den Lebenszyklus aufrechtzuerhalten. Bei Momentaufnahmen ist es einfach, Skripts zu schreiben, da keine Abhängigkeitskette vorhanden ist.
- Langfristige Aufbewahrung: Vollständige Sicherungen sind immer von Vorteil für die langfristige Aufbewahrung, da Sie sie unabhängig voneinander verschieben und wiederherstellen können. Für Betriebssicherungen mit kurzfristiger Aufbewahrung sind Momentaufnahmen günstig.
Eine tägliche Momentaufnahme plus Protokolle mit gelegentlicher vollständiger Sicherung für die langfristige Aufbewahrung ist die beste Sicherungsrichtlinie für Datenbanken.
Sicherungsstrategie
Das erweiterte Präscript- und Postscript-Framework basiert auf der Azure-VM-Backup-Technologie, die die Sicherung einmal täglich plant. Aus diesem Grund ist das Datenverlustfenster mit dem Wiederherstellungspunktziel (RPO) als 24 Stunden nicht für Produktionsdatenbanken geeignet. Ergänzt wird diese Lösung durch eine Log-Backup-Strategie, bei der die Log-Backups explizit gestreamt werden.
Netzwerkdateisystem (NFS) auf Azure Blob Storage und NFS auf AFS (Vorschau) erleichtern die einfache Einbindung von Volumes direkt auf Datenbank-VMs und die Verwendung von Datenbankclients für die Übertragung von Protokoll-Backups. Das Zeitfenster für den Datenverlust, d. h. das RPO, hängt von der Häufigkeit der Log-Backups ab. Außerdem müssen NFS-Ziele nicht sehr leistungsfähig sein. Möglicherweise müssen Sie kein reguläres Streaming (vollständig und inkrementell) für operative Sicherungen auslösen, nachdem Sie über datenbankkonsistente Momentaufnahmen verfügen.
Hinweis
Das erweiterte Präscript sorgt in der Regel dafür, dass alle Log-Transaktionen auf dem Weg zum Ziel der Log-Sicherung geleert werden, bevor die Datenbank für die Erstellung eines Snapshots stillgelegt wird. Daher sind die Momentaufnahmen während der Wiederherstellung datenbankkonsistent und zuverlässig.
Wiederherstellungsstrategie
Nachdem die konsistenten Datenbank-Snapshots erstellt und die Log-Backups auf ein NFS-Volume gestreamt sind, könnte die Wiederherstellungsstrategie der Datenbank die Wiederherstellungsfunktionalität von Azure VM-Backups nutzen. Die Möglichkeit von Protokollsicherungen wird auch mithilfe des Datenbankclients darauf angewendet. Die folgenden Optionen für die Wiederherstellungsstrategie sind:
- Erstellen Sie neue virtuelle Maschinen aus einem datenbankkonsistenten Wiederherstellungspunkt. Die VM sollte bereits mit dem Log-Mount-Punkt verbunden sein. Verwenden Sie Datenbank-Clients, um Wiederherstellungsbefehle für die Point-in-Time-Wiederherstellung auszuführen.
- Erstellen Sie Datenträger aus einem datenbankeinheitlichen Wiederherstellungspunkt, und fügen Sie sie an eine andere Ziel-VM an. Hängen Sie dann das Protokollziel ein und verwenden Sie Datenbank-Clients, um Wiederherstellungsbefehle für die Point-in-Time-Wiederherstellung auszuführen.
- Verwenden Sie eine Dateiwiederherstellungsoption, und generieren Sie ein Skript. Führen Sie das Skript auf der Ziel-VM aus und hängen Sie den Wiederherstellungspunkt als iSCSI-Datenträger an. Verwenden Sie dann Datenbank-Clients, um die datenbankspezifischen Validierungsfunktionen auf den angeschlossenen Festplatten auszuführen und die Sicherungsdaten zu validieren. Verwenden Sie außerdem Datenbankclients, um einige Tabellen oder Dateien zu exportieren oder wiederherzustellen, anstatt die gesamte Datenbank wiederherzustellen.
- Verwenden Sie die Funktion "Regionsübergreifende Wiederherstellung", um die vorherigen Aktionen aus sekundären gekoppelten Regionen während eines regionalen Notfalls auszuführen.
Zusammenfassung
Mit datenbankkonsistente Momentaufnahmen und Protokollen, die mithilfe einer benutzerdefinierten Lösung gesichert werden, können Sie eine Datenbanksicherungslösung erstellen, die leistungsfähig und kostengünstig ist. Diese Lösung verwendet die Vorteile der Azure VM-Sicherung und verwendet auch die Funktionen von Datenbankclients.