Bewährte Azure Machine Learning-Methoden für die Unternehmenssicherheit
In diesem Artikel werden bewährte Sicherheitsmethoden für die Planung oder Verwaltung einer sicheren Azure Machine Learning-Bereitstellung beschrieben. Bewährte Methoden stammen aus der Erfahrung von Microsoft und Kunden mit Azure Machine Learning. In jeder Leitlinie werden das Verfahren und die Gründe dafür erläutert. Der Artikel stellt auch Links zu Anleitungen und Referenzdokumentation bereit.
Empfohlene Netzwerksicherheitsarchitektur (verwaltetes Netzwerk)
Bei der empfohlenen Netzwerksicherheitsarchitektur für maschinelles Lernen handelt es sich um ein verwaltetes virtuelles Netzwerk. Ein von Azure Machine Learning verwaltetes virtuelles Netzwerk sichert den Arbeitsbereich, die zugeordneten Azure-Ressourcen und alle verwalteten Rechenressourcen. Sie vereinfacht die Konfiguration und Verwaltung der Netzwerksicherheit, indem erforderliche Ausgaben vorkonfiguriert und automatisch verwaltete Ressourcen im Netzwerk erstellt werden. Sie können private Endpunkte verwenden, um Azure-Diensten den Zugriff auf das Netzwerk zu ermöglichen, und optional ausgehende Regeln definieren, damit das Netzwerk auf das Internet zugreifen kann.
Das verwaltete virtuelle Netzwerk verfügt über zwei Modi, für die es konfiguriert werden kann:
Ausgehendes Internet zulassen – Dieser Modus ermöglicht ausgehende Kommunikation mit Ressourcen, die sich im Internet befinden, z. B. die öffentlichen PyPi- oder Anaconda-Paketrepositorys.

Nur genehmigte ausgehende zulassen – Dieser Modus ermöglicht nur die minimale ausgehende Kommunikation, die für die Funktion des Arbeitsbereichs erforderlich ist. Dieser Modus wird für Arbeitsbereiche empfohlen, die vom Internet isoliert werden müssen. Oder wenn der ausgehende Zugriff nur für bestimmte Ressourcen über Dienstendpunkte, Diensttags oder vollqualifizierte Domänennamen zulässig ist.

Weitere Informationen finden Sie unter Verwalten virtueller Netzwerkisolation.
Empfohlene Netzwerksicherheitsarchitektur (Azure Virtual Network)
Wenn Sie aufgrund Ihrer Geschäftlichen Anforderungen kein verwaltetes virtuelles Netzwerk verwenden können, können Sie ein virtuelles Azure-Netzwerk mit den folgenden Subnetzen verwenden:
- Training: Enthält die für das Training verwendeten Computeressourcen, z. B. Machine Learning-Compute-Instanzen oder Computecluster.
- Bewertung: Enthält Computeressourcen für die Bewertung, z. B. Azure Kubernetes Service (AKS).
- Firewall: Enthält die Firewall (z. B. Azure Firewall), über die Datenverkehr aus dem bzw. in das öffentliche Internet zugelassen wird, z. B. Azure Firewall.
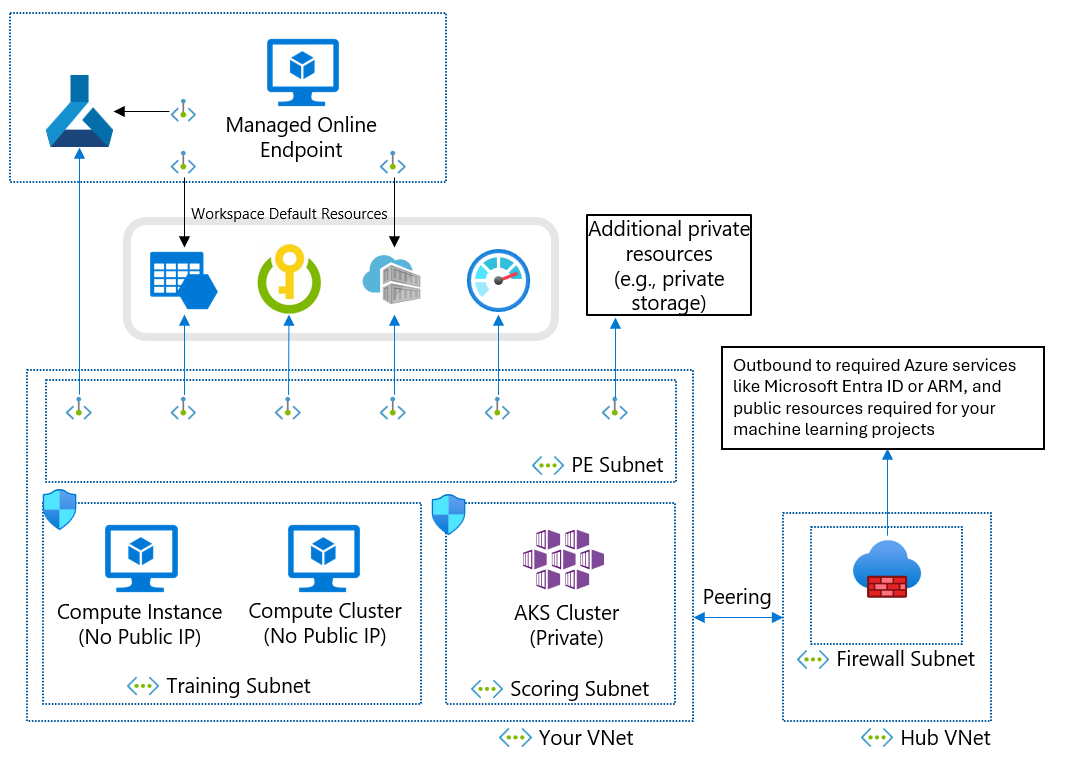
Das virtuelle Netzwerk enthält auch einen privaten Endpunkt für Ihren Machine Learning-Arbeitsbereich sowie die folgenden abhängigen Dienste:
- Azure Storage-Konto
- Azure-Schlüsseltresor
- Azure Container Registry
Ausgehende Kommunikation aus dem virtuellen Netzwerk muss die folgenden Microsoft-Dienste erreichen können:
- Machine Learning
- Microsoft Entra ID
- Azure Container Registry und bestimmte Registrierungen, die Microsoft verwaltet
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Remote-Clients verbinden sich über Azure ExpressRoute oder eine VPN-Verbindung (Virtual Private Network) mit dem virtuellen Netzwerk.
Aufbau des virtuellen Netzwerks und privater Endpunkte
Wenn Sie ein virtuelles Azure-Netzwerk, Subnetze und private Endpunkte entwerfen, sollten Sie die folgenden Anforderungen berücksichtigen:
Generell sollten Sie getrennte Subnetze für Training und Bewertung erstellen und das Trainingssubnetz für alle privaten Endpunkte verwenden.
Für IP-Adressierung benötigen Compute-Instanzen jeweils eine private IP-Adresse. Computecluster benötigen eine private IP-Adresse pro Knoten. Für AKS-Cluster sind viele private IP-Adressen erforderlich, wie unter Planen der IP-Adressierung für Ihren Cluster beschrieben. Ein separates Subnetz mindestens für AKS trägt dazu bei, IP-Adresserschöpfung zu verhindern.
Die Rechenressourcen in den Subnetzen für Training und Bewertung müssen auf das Speicherkonto, den Schlüsseltresor und die Containerregistrierung zugreifen. Erstellen Sie private Endpunkte für das Speicherkonto, den Schlüsseltresor und die Containerregistrierung.
Der Standardspeicher des Machine Learning-Arbeitsbereichs erfordert zwei private Endpunkte: einen für Azure Blob Storage und einen für Azure File Storage.
Wenn Sie Azure Machine Learning Studio verwenden, sollten sich der Arbeitsbereich und die privaten Speicherendpunkte im selben virtuellen Netzwerk befinden.
Wenn Sie mehrere Arbeitsbereiche nutzen, verwenden Sie für jeden Arbeitsbereich ein virtuelles Netzwerk, um eine explizite Netzwerkgrenze zwischen den Arbeitsbereichen zu schaffen.
Verwenden privater IP-Adressen
Private IP-Adressen sorgen dafür, dass möglichst wenige Ihrer Azure-Ressourcen über das Internet zugänglich sind. Machine Learning verwendet viele Azure-Ressourcen, und der private Endpunkt des Machine Learning-Arbeitsbereichs ist für eine private End-to-End-IP-Adresse nicht ausreichend. Die folgende Tabelle zeigt die wichtigsten Ressourcen, die von Machine Learning verwendet werden, sowie die Aktivierung der privaten IP-Adresse für die Ressourcen. Die Compute-Instanz und der Computecluster sind die einzigen Ressourcen, die nicht über das Feature für private IP-Adressen verfügen.
| Ressourcen | Private IP-Lösung | Dokumentation |
|---|---|---|
| Arbeitsbereich | Privater Endpunkt | Konfigurieren eines privaten Endpunkts für einen Azure Machine Learning-Arbeitsbereich |
| Registrierung | Privater Endpunkt | Netzwerkisolation mit Azure Machine Learning-Registrierungen |
| Zugeordnete Ressourcen | ||
| Storage | Privater Endpunkt | Schützen von Azure Storage-Konten mit Dienstendpunkten |
| Key Vault | Privater Endpunkt | Schützen von Azure Key Vault |
| Container Registry | Privater Endpunkt | Aktivieren von Azure Container Registry |
| Ressourcen für Training | ||
| Compute-Instanz | Private IP (keine öffentliche IP) | Schützen von Trainingsumgebungen |
| Computecluster | Private IP (keine öffentliche IP) | Schützen von Trainingsumgebungen |
| Hostingressourcen | ||
| Verwalteter Onlineendpunkt | Privater Endpunkt | Netzwerkisolation mit verwaltete Onlineendpunkten |
| Kubernetes-Onlineendpunkte | Privater Endpunkt | Azure Kubernetes Service-Onlineendpunkte sichern |
| Batchendpunkte | Private IP (geerbt vom Compute-Cluster) | Netzwerkisolation in Batchendpunkten |
Steuern des ein- und ausgehenden Datenverkehrs des virtuellen Netzwerks
Verwenden Sie eine Firewall oder Azure-Netzwerksicherheitsgruppe (NSG), um den ein- und ausgehenden Datenverkehr des virtuellen Netzwerks zu steuern. Weitere Informationen zu den Anforderungen für ein- und ausgehenden Netzwerkdatenverkehr finden Sie hier. Weitere Informationen darüber, wie Datenverkehr zwischen Komponenten fließt, finden Sie unter Fluss des Netzwerkdatenverkehrs in einem geschützten Arbeitsbereich.
Sicherstellen des Zugriffs auf Ihren Arbeitsbereich
Führen Sie die folgenden Schritte aus, um sicherzustellen, dass Ihr privater Endpunkt auf Ihren Machine Learning-Arbeitsbereich zugreifen kann:
Stellen Sie sicher, dass Sie über eine VPN-Verbindung, ExpressRoute oder eine Jumpbox-VM mit Azure Bastion-Zugriff auf Ihr virtuelles Netzwerk zugreifen können. Der öffentliche Benutzer kann nicht auf den Machine Learning-Arbeitsbereich mit dem privaten Endpunkt zugreifen, da der Zugriff darauf nur über Ihr virtuelles Netzwerk möglich ist. Weitere Informationen finden Sie im Artikel zum Schützen Ihres Arbeitsbereichs mit virtuellen Netzwerken.
Stellen Sie sicher, dass Sie die vollqualifizierten Domänennamen (FQDNs) des Arbeitsbereichs mit Ihrer privaten IP-Adresse auflösen können. Wenn Sie Ihren eigenen DNS-Server (Domain Name System) oder eine zentralisierte DNS-Infrastruktur verwenden, müssen Sie DNS-Weiterleitung konfigurieren. Weitere Informationen finden Sie unter Verwenden Ihres Arbeitsbereichs mit einem benutzerdefinierten DNS-Server.
Verwalten des Arbeitsbereichszugriffs
Bei der Definition von Identitäts- und Zugriffsverwaltungsteuerungen für Machine Learning können Sie Steuerungen, die den Zugriff auf Azure-Ressourcen definieren, von Steuerungen trennen, die den Zugriff auf Datenbestände verwalten. Überlegen Sie je nach Anwendungsfall, ob Sie Self-Service-, datenorientierte oder projektorientierte Identitäts- und Zugriffsverwaltung verwenden möchten.
Self-Service-Muster
Beim Self-Service-Muster können Data Scientists Arbeitsbereiche erstellen und verwalten. Dieses Muster eignet sich am besten für Proof-of-Concept-Situationen, die Flexibilität beim Ausprobieren verschiedener Konfigurationen erfordern. Der Nachteil besteht darin, dass Data Scientists das Fachwissen benötigen, um Azure-Ressourcen bereitstellen zu können. Dieser Ansatz ist weniger geeignet, wenn eine strenge Kontrolle, Ressourcennutzung, Prüfspuren und Datenzugriff erforderlich sind.
Definieren Sie Azure-Richtlinien, um Sicherheitskomponenten für die Ressourcenbereitstellung und -nutzung festzulegen, z. B. zulässige Clustergrößen und VM-Typen.
Erstellen Sie eine Ressourcengruppe für die Arbeitsbereiche und weisen Sie Datenwissenschaftlern eine Rolle als Mitwirkender in der Ressourcengruppe zu.
Data Scientists können dann Arbeitsbereiche erstellen und in der Ressourcengruppe Ressourcen auf Self-Service-Basis zuordnen.
Erstellen Sie für den Zugriff auf Datenspeicher benutzerseitig zugewiesene verwaltete Identitäten, und gewähren Sie den Identitäten Rollen mit Lesezugriff für den Speicher.
Wenn Data Scientists Computeressourcen erstellen, können diese die verwalteten Identitäten den Computeressourcen zuweisen, um Zugriff auf Daten zu erlangen.
Informationen zu bewährten Methoden finden Sie unter Authentifizierung für Analysen auf Cloudebene in Azure.
Datenorientiertes Muster
Beim datenorientierten Muster befindet sich der Arbeitsbereich nur im Besitz einzelner wissenschaftlicher Fachkräfte für Daten, die ggf. an mehreren Projekten arbeiten. Der Vorteil dieses Ansatzes besteht darin, dass die wissenschaftliche Fachkraft für Daten den Code bzw. die Trainingspipelines projektübergreifend wiederverwenden kann. Solange der Arbeitsbereich auf einen einzelnen Benutzer beschränkt ist, kann der Datenzugriff beim Überwachen von Speicherprotokollen zu diesem Benutzer zurückverfolgt werden.
Der Nachteil ist, dass der Datenzugriff nicht nach Projekten aufgeteilt oder eingeschränkt ist und dass jeder Benutzer, der dem Arbeitsbereich hinzugefügt wird, auf dieselben Assets zugreifen kann.
Erstellen Sie den Arbeitsbereich.
Erstellen Sie Computeressourcen mit aktivierten systemseitig zugewiesenen verwalteten Identitäten.
Wenn ein Data Scientist für ein bestimmtes Projekt Zugriff auf die Daten benötigt, sollten Sie der verwalteten Identität der Computeressource die Rolle für Lesezugriff auf die Daten gewähren.
Gewähren Sie der Compute-Managed-Identity Zugriff auf andere erforderliche Ressourcen, z. B. eine Container-Registry mit benutzerdefinierten Docker-Images für Schulungen.
Gewähren Sie auch der verwalteten Identität des Arbeitsbereichs die Rolle für Lesezugriff auf die Daten, um Datenvorschau zu ermöglichen.
Gewähren Sie dem Data Scientist Zugriff auf den Arbeitsbereich.
Der Data Scientist kann nun Datenspeicher erstellen, um den Zugriff auf die für Projekte erforderlichen Daten zu ermöglichen, und Trainingsläufe mit den Daten übermitteln.
Erstellen Sie optional eine Microsoft Entra-Sicherheitsgruppe, gewähren Sie ihr Lesezugriff auf Daten, und fügen Sie der Sicherheitsgruppe dann verwaltete Identitäten hinzu. Mit diesem Ansatz wird die Anzahl von direkten Rollenzuweisungen für Ressourcen reduziert, um zu vermeiden, dass das Abonnementlimit für Rollenzuweisungen erreicht wird.
Projektorientiertes Muster
Bei einem projektorientierten Muster wird ein Machine Learning-Arbeitsbereich für ein bestimmtes Projekt erstellt, und viele Data Scientists arbeiten in demselben Arbeitsbereich zusammen. Da der Datenzugriff auf ein bestimmtes Projekt beschränkt ist, ist der Ansatz gut für die Arbeit mit vertraulichen Daten geeignet. Außerdem ist es einfach, dem Projekt Data Scientists hinzuzufügen oder aus ihm zu entfernen.
Der Nachteil besteht bei diesem Ansatz darin, dass die projektübergreifende Freigabe von Ressourcen schwierig sein kann. Es ist auch schwierig, Datenzugriff auf bestimmte Benutzer während Überwachungen nachzuverfolgen.
Erstellen des Arbeitsbereichs
Identifizieren Sie die für das Projekt erforderlichen Datenspeicherinstanzen, erstellen Sie eine benutzerseitig zugewiesene verwaltete Identität, und gewähren Sie ihr die Lesezugriff auf den Speicher.
Gewähren Sie der verwalteten Identität des Arbeitsbereichs optional Zugriff auf den Datenspeicher, um Datenvorschau zu ermöglichen. Sie können diesen Zugriff für vertrauliche Daten auslassen, die nicht für eine Vorschau geeignet sind.
Erstellen Sie anonyme Datenspeicher für die Speicherressourcen.
Erstellen Sie Computeressourcen innerhalb des Arbeitsbereichs, und weisen Sie ihnen die verwaltete Identität zu.
Gewähren Sie der Compute-Managed-Identity Zugriff auf andere erforderliche Ressourcen, z. B. eine Container-Registry mit benutzerdefinierten Docker-Images für Schulungen.
Gewähren Sie Data Scientists, die am Projekt arbeiten, eine Rolle für den Arbeitsbereich.
Mithilfe der rollenbasierten Zugriffssteuerung (Role-Based Access Control, RBAC) von Azure können Sie Data Scientists daran hindern, neue Datenspeicher oder neue Computeressourcen mit anderen verwalteten Identitäten zu erstellen. Diese Vorgehensweise verhindert den Zugriff auf Daten, die nicht spezifisch für das Projekt sind.
Optional können Sie zur Vereinfachung der Verwaltung von Projektmitgliedschaften eine Microsoft Entra-Sicherheitsgruppe für Projektmitglieder erstellen und der Gruppe Zugriff auf den Arbeitsbereich gewähren.
Passthrough für Azure Data Lake Storage-Anmeldeinformationen
Sie können die Microsoft Entra-Benutzeridentität für den interaktiven Speicherzugriff über Machine Learning Studio verwenden. Data Lake Storage mit aktivierten hierarchischen Namespaces ermöglicht eine verbesserte Organisation von Datenressourcen für Speicherung und Zusammenarbeit. Mit dem hierarchischen Namespace von Data Lake Storage können Sie den Datenzugriff aufteilen, indem Sie verschiedenen Benutzern auf der Grundlage von ACLs (Zugriffssteuerungslisten) Zugriff auf verschiedene Ordner und Dateien gewähren. Beispielsweise können Sie nur einem Teil der Benutzer Zugriff auf vertrauliche Daten gewähren.
RBAC und benutzerdefinierte Rollen
Mit Azure RBAC können Sie verwalten, wer Zugriff auf Machine Learning-Ressourcen hat, und konfigurieren, wer Vorgänge durchführen kann. Sie können zum Beispiel nur bestimmten Benutzern die Rolle des Arbeitsbereichsadministrators zur Verwaltung von Computeressourcen zuweisen.
Der Zugriffsbereich kann sich je nach Umgebung unterscheiden. In einer Produktionsumgebung können Sie für Benutzer die Möglichkeit einschränken, Rückschlussendpunkte zu aktualisieren. Stattdessen können Sie diese Berechtigung einem autorisierten Dienstprinzipal erteilen.
In Machine Learning gibt es mehrere Standardrollen: „Besitzer“, „Mitwirkender“, „Leser“ und „Data Scientist“. Sie können auch eigene benutzerdefinierte Rollen erstellen, z. B. zum Erstellen von Berechtigungen, die Ihre Organisationsstruktur widerspiegeln. Weitere Informationen finden Sie unter Verwalten des Zugriffs auf einen Azure Machine Learning-Arbeitsbereich.
Es kann sein, dass sich die Zusammensetzung Ihres Teams im Laufe der Zeit ändert. Wenn Sie für jede Teamrolle und jeden Arbeitsbereich eine Microsoft Entra-Gruppe erstellen, können Sie der Microsoft Entra-Gruppe eine Azure RBAC-Rolle zuweisen und den Ressourcenzugriff und Benutzergruppen separat verwalten.
Benutzer- und Dienstprinzipale können Teil derselben Microsoft Entra-Gruppe sein. Wenn Sie beispielsweise eine benutzerseitig zugewiesene verwaltete Identität erstellen, die Azure Data Factory zum Auslösen einer Machine Learning-Pipeline verwendet, können Sie diese verwaltete Identität ggf. in eine Microsoft Entra-Gruppe vom Typ ML-Pipelines-Executor einfügen.
Zentrale Docker-Imageverwaltung
Bei Azure Machine Learning können Sie zusammengestellte Docker-Images zu Trainings- und Bereitstellungszwecken verwenden. Es kann jedoch sein, dass die Compliance-Anforderungen Ihres Unternehmens die Verwendung von Images aus einem privaten Repository vorschreiben, das Ihr Unternehmen verwaltet. Machine Learning kann ein zentrales Repository auf zwei Arten verwenden:
Verwenden Sie die Images aus einem zentralen Repository als Basisimages. Die Verwaltungsfunktion der Machine Learning-Umgebung installiert Pakete und erstellt eine Python-Umgebung, in der der Trainings- oder Rückschlusscode ausgeführt wird. Mit diesem Ansatz können Sie Paketabhängigkeiten einfach aktualisieren, ohne das Basis-Image zu verändern.
Verwenden Sie die Images unverändert ohne Einsatz der Machine Learning-Umgebungsverwaltung. Bei diesem Ansatz haben Sie eine bessere Kontrolle, aber Sie müssen die Python-Umgebung auch sorgfältig als Teil des Images erstellen. Sie müssen alle notwendigen Abhängigkeiten erfüllen, um den Code auszuführen, und jede neue Abhängigkeit erfordert eine Neuerstellung des Images.
Weitere Informationen finden Sie unter Verwalten von Umgebungen.
Datenverschlüsselung
Ruhende Machine Learning-Daten haben zwei Datenquellen:
Ihr Speicher enthält alle Ihre Daten, einschließlich der Trainings- und trainierten Modelldaten, mit Ausnahme der Metadaten. Sie sind für die Speicherverschlüsselung verantwortlich.
Azure Cosmos DB enthält Ihre Metadaten, einschließlich Informationen zum Ausführungsverlauf wie Experimentname und Datum und Uhrzeit der Experimentübermittlung. In en meisten Arbeitsbereich befindet sich Azure Cosmos DB in einem Microsoft-Abonnement und wird mit einem von Microsoft verwalteten Schlüssel verschlüsselt.
Wenn Sie Ihre Metadaten mit Ihrem eigenen Schlüssel verschlüsseln möchten, können Sie einen vom Kunden verwalteten Schlüsselarbeitsbereich verwenden. Der Nachteil hierbei ist, dass Sie in Ihrem Abonnement über eine Azure Cosmos DB-Instanz verfügen und die dafür anfallenden Kosten tragen müssen. Weitere Informationen finden Sie unter Datenverschlüsselung mit Azure Machine Learning.
Informationen dazu, wie bei Azure Machine Learning Daten während der Übertragung verschlüsselt werden, finden Sie unter Verschlüsselung während der Übertragung.
Überwachung
Wenn Sie Machine Learning-Ressourcen bereitstellen, richten Sie Protokollierungs- und Überwachungssteuerungen für Beobachtungszwecke ein. Die Beweggründe für die Beobachtung von Daten können je nach den Personen variieren, die die Daten untersuchen. Mögliche Szenarien:
Machine Learning-Experten oder Betriebsteams möchten die Integrität der Machine Learning-Pipeline überwachen. Diese Beobachter müssen Probleme bei der geplanten Ausführung oder Probleme mit der Datenqualität oder der erwarteten Trainingsleistung verstehen. Sie können Azure-Dashboards erstellen, die Azure Machine Learning-Daten überwachen oder ereignisgesteuerte Workflows erstellen.
Kapazitäts-Manager, Machine Learning-Spezialisten oder Betriebsteams möchten ggf. ein Dashboard erstellen, über das sie die Auslastung von Computeressourcen und Kontingenten verfolgen können. Beim Verwalten einer Bereitstellung mit mehreren Machine Learning-Arbeitsbereichen sollten Sie erwägen, ein zentrales Dashboard zu erstellen, um die Kontingentnutzung zu verstehen. Kontingente werden auf Abonnementebene verwaltet, daher ist eine umgebungsweite Ansicht wichtig, um Optimierungsmöglichkeiten zu verbessern.
IT- und Betriebsteams können Diagnoseprotokollierung einrichten, um den Ressourcenzugriff und Daten ändernde Ereignisse innerhalb des Arbeitsbereichs zu überwachen.
Erwägen Sie die Erstellung von Dashboards, über die die Integrität der Gesamtinfrastruktur für Azure Machine Learning und abhängige Ressourcen wie den Speicher überwacht werden können. Die Kombination von Azure Storage-Metriken mit Pipeline-Ausführungsdaten kann Ihnen beispielsweise dabei helfen, die Infrastruktur für eine bessere Leistung zu optimieren oder die Ursachen von Problemen zu ermitteln.
Azure erfasst und speichert Plattformmetriken und Aktivitätsprotokolle automatisch. Sie können die Daten mithilfe einer Diagnoseeinstellung an andere Speicherorte weiterleiten. Richten Sie die Diagnoseprotokollierung in einem zentralen Log Analytics-Arbeitsbereich ein, um die Beobachtung über mehrere Arbeitsbereichsinstanzen hinweg zu ermöglichen. Verwenden Sie Azure Policy, um Protokollierung für neue Machine Learning-Arbeitsbereiche automatisch in diesem zentralen Log Analytics-Arbeitsbereich einzurichten.
Azure Policy
Sie können die Verwendung von Sicherheitsfeatures für Arbeitsbereiche über Azure Policy erzwingen und überwachen. Empfehlungen umfassen Folgendes:
- Erzwingen der Verschlüsselung von kundenseitig verwalteten Schlüsseln.
- Erzwingen von Azure Private Link und privaten Endpunkten.
- Erzwingen von privaten DNS-Zonen.
- Deaktivieren von anderen Authentifizierungsarten als Azure AD-Authentifizierung, z. B. von Secure Shell (SSH).
Weitere Informationen finden Sie unter Integrierte Azure Policy-Richtliniendefinitionen für Azure Machine Learning.
Sie können auch benutzerdefinierte Richtliniendefinitionen verwenden, um die Sicherheit Ihres Arbeitsbereichs auf flexible Weise zu steuern.
Computecluster und -Instanzen
Die folgenden Überlegungen und Empfehlungen gelten für Machine Learning-Computecluster und -Instanzen.
Datenträgerverschlüsselung
Der Datenträger des Betriebssystems (OS) für eine Compute-Instanz oder einen Compute-Cluster-Knoten wird in Azure Storage gespeichert und mit von Microsoft verwalteten Schlüsseln verschlüsselt. Jeder Knoten verfügt hierbei zusätzlich über einen lokalen temporären Datenträger. Der temporäre Datenträger wird ebenfalls mit von Microsoft verwalteten Schlüsseln verschlüsselt, wenn der Arbeitsbereich mit dem hbi_workspace = True-Parameter erstellt wurde. Weitere Informationen finden Sie unter Datenverschlüsselung mit Azure Machine Learning.
Verwaltete Identität
Für Computecluster wird die Verwendung verwalteter Identitäten für die Authentifizierung bei Azure-Ressourcen unterstützt. Die Verwendung einer verwalteten Identität für den Cluster ermöglicht die Authentifizierung bei Ressourcen, ohne dass Sie Anmeldeinformationen in Ihrem Code bereitstellen müssen. Weitere Informationen finden Sie unter Erstellen eines Azure Machine Learning-Computeclusters.
Setupskript
Sie können ein Setup-Skript verwenden, um die Anpassung und Konfiguration von Recheninstanzen bei der Erstellung zu automatisieren. Als Administrator können Sie ein Anpassungsskript schreiben, das verwendet wird, wenn die einzelnen Compute-Instanzen in einem Arbeitsbereich erstellt werden. Sie können Azure Policy verwenden, um die Verwendung des Setup-Skripts zur Erstellung jeder Compute-Instanz zu erzwingen. Weitere Informationen finden Sie unter Erstellen und Verwalten einer Azure Machine Learning-Compute-Instanz.
Erstellen im Namen von
Wenn Sie nicht möchten, dass Datenwissenschaftler Rechenressourcen bereitstellen, können Sie in ihrem Namen Recheninstanzen erstellen und diese den Datenwissenschaftlern zuweisen. Weitere Informationen finden Sie unter Erstellen und Verwalten einer Azure Machine Learning-Compute-Instanz.
Für private Endpunkte aktivierte Arbeitsbereiche
Verwenden Sie Compute-Instanzen mit einem für private Endpunkte aktivierten Arbeitsbereich. Die Compute-Instanz lehnt den gesamten öffentlichen Zugriff von außerhalb des virtuellen Netzwerks ab. Mit dieser Konfiguration wird auch die Paketfilterung verhindert.
Azure Policy-Unterstützung
Wenn Sie ein virtuelles Azure-Netzwerk verwenden, können Sie mithilfe von Azure Policy sicherstellen, dass jeder Compute-Cluster oder jede Instanz in einem virtuellen Netzwerk erstellt wird, und das virtuelle Standardnetzwerk und das Subnetz festlegen. Die Richtlinie wird bei Verwendung eines verwalteten virtuellen Netzwerks nicht benötigt, da die Rechenressourcen automatisch im verwalteten virtuellen Netzwerk erstellt werden.
Sie können auch eine Richtlinie verwenden, um andere Authentifizierungsarten als Azure AD-Authentifizierung (z. B. SSH) zu deaktivieren.
Nächste Schritte
Hier erfahren Sie mehr über die Sicherheitskonfigurationen bei maschinellen Lernen:
- Sicherheit und Governance in Unternehmen für Azure Machine Learning
- Schützen von Azure Machine Learning-Arbeitsbereichsressourcen mit virtuellen Netzwerken (VNETs)
Erste Schritte bei der Bereitstellung mit Machine Learning-Vorlagen:
Hier finden Sie weitere Artikel zu architekturbezogenen Überlegungen zum Bereitstellen von maschinellem Lernen:
Erfahren Sie, wie sich Teamstruktur, Umgebung oder regionale Einschränkungen auf die Einrichtung des Arbeitsbereichs auswirken.
Erfahren Sie, wie Sie Computekosten und Budgets team- und benutzerübergreifend verwalten.
Erfahren Sie mehr über Machine Learning DevOps (MLOps), bei dem eine Kombination aus Personen, Prozessen und Technologien verwendet wird, um stabile, zuverlässige und automatisierte Lösungen für maschinelles Lernen bereitzustellen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für