Verwalten von Budgets, Kosten und Kontingenten für Azure Machine Learning auf Unternehmensebene
Wenn Sie Computekosten verwalten, die durch Azure Machine Learning auf Unternehmensebene mit vielen Workloads, zahlreichen Teams und Benutzern entstehen, müssen sie zahlreiche Verwaltungs- und Optimierungsherausforderungen bewältigen.
In diesem Artikel werden bewährte Methoden zum Optimieren von Kosten, Verwalten von Budgets und Freigeben von Kontingenten für Azure Machine Learning dargestellt. Er spiegelt die Erfahrungen und Erkenntnisse wider, die sich aus der internen Arbeit mit Machine Learning-Teams bei Microsoft und während der Partnerschaft mit unseren Kunden ergeben haben. Sie lernen Folgendes:
- Optimieren von Computeressourcen, um Workloadanforderungen zu erfüllen
- Steuern der optimalen Nutzung des Budgets eines Teams
- Planen, Verwalten und Freigeben von Budgets, Kosten und Kontingenten auf Unternehmensniveau
Optimieren von Computeressourcen, um Workloadanforderungen zu erfüllen
Wenn Sie ein neues Machine Learning-Projekt starten, sind möglicherweise explorative Arbeiten erforderlich, um ein gutes Bild von den Computeanforderungen zu erhalten. Dieser Abschnitt enthält Empfehlungen dazu, wie Sie die richtige VM-SKU-Auswahl für Training, Rückschließen oder als Arbeitsstation bestimmen können.
Bestimmen der Computegröße für das Training
Die Hardwareanforderungen für Ihre Trainingsworkload können von Projekt zu Projekt variieren. Um diese Anforderungen zu erfüllen, bietet Azure Machine Learning Compute verschiedene Arten von VMs:
- Universell: Ausgewogenes Verhältnis zwischen CPU und Arbeitsspeicher
- Arbeitsspeicheroptimiert: Hohes Verhältnis von Arbeitsspeicher zu CPU
- Für Compute optimiert: Hohes Verhältnis von CPU zu Arbeitsspeicher
- Hochleistungs-Compute: Bereitstellung herausragender Leistung, Skalierbarkeit und Kosteneffizienz für verschiedene reale HPC-Workloads
- Instanzen mit GPUs: Spezielle virtuelle Computer als Ziel für aufwendiges Grafikrendering und Videobearbeitung sowie für Modelltraining und Rückschlüsse (ND) mit Deep Learning.
Möglicherweise kennen Sie Ihre Computeanforderungen noch nicht. In diesem Szenario wird empfohlen, mit einer der folgenden kostengünstigen Standardoptionen zu beginnen. Diese Optionen sind für schlanke Tests und für Trainingsworkloads gedacht.
| Typ | Größe des virtuellen Computers | Spezifikationen |
|---|---|---|
| CPU | Standard_DS3_v2 | 4 Kerne, 14 GB RAM, 28 GB Speicher |
| GPU | Standard_NC6 | 6 Kerne, 56 GB RAM, 380 GB Speicher, NVIDIA Tesla K80 GPU |
Um die beste VM-Größe für Ihr Szenario zu erhalten, müssen Sie eventuell ein wenig ausprobieren. Im Folgenden finden Sie einige zu berücksichtigende Aspekte.
- Wenn Sie eine CPU benötigen:
- Verwenden Sie einen speicheroptimierten virtuellen Computer, wenn Sie mit großen Datasets trainieren.
- Verwenden Sie einen computeoptimierten virtuellen Computer, wenn Sie in Echtzeit rückschließen oder andere latenzempfindliche Aufgaben ausführen.
- Verwenden Sie einen virtuellen Computer mit mehr Kernen und RAM, um die Trainingszeiten zu beschleunigen.
- Wenn Sie eine GPU benötigen, finden Sie Informationen zur Auswahl eines virtuellen Computers unter GPU-optimierte VM-Größen.
- Wenn Sie Trainings nicht verteilt ausführen, verwenden Sie VM-Größen mit mehreren GPUs.
- Wenn Sie Trainings verteilt auf mehreren Knoten ausführen, verwenden Sie GPUs mit NVLink-Verbindungen.
Während Sie den VM-Typ und die SKU auswählen, die am besten zu Ihrer Workload passen, bewerten Sie vergleichbare VM-SKUs als Kompromiss zwischen CPU- und GPU-Leistung und -Preisen. Unter dem Aspekt der Kostenverwaltung kann ein Auftrag auf mehreren SKUs recht gut ausgeführt werden.
Bestimmte GPUs wie die NC-Familie, insbesondere NC_Promo-SKUs, verfügen über ähnliche Funktionen wie andere GPUs, z. B. geringe Wartezeiten und die Möglichkeit, mehrere Computingworkloads parallel zu verwalten. Im Vergleich zu einigen anderen GPUs sind sie zu ermäßigten Preisen erhältlich. Die besonnene Auswahl von VM-SKUs gemäß der Workload kann am Ende erheblich Kosten sparen.
Ein Hinweis auf die Bedeutung der Auslastung ist, dass die Registrierung für eine größere Anzahl von GPUs nicht unbedingt mit schnelleren Ergebnissen einhergeht. Stellen Sie stattdessen sicher, dass die GPUs vollständig ausgelastet sind. Überprüfen Sie beispielsweise die Notwendigkeit von NVIDIA CUDA. Dies ist zwar möglicherweise für die GPU-Hochleistungsausführung erforderlich, doch Ihr Auftrag ist möglicherweise nicht davon abhängig.
Bestimmen der Computegröße für Rückschließen
Computeanforderungen für Rückschlussszenarien unterscheiden sich von Trainingsszenarien. Die verfügbaren Optionen unterscheiden sich je nachdem, ob Ihr Szenario Rückschließen im Batch offline oder Rückschließen in Echtzeit online erfordert.
Berücksichtigen Sie für Echtzeitrückschlussszenarien die folgenden Vorschläge:
- Verwenden Sie Profilerstellungsfunktionen für Ihr Modell mit Azure Machine Learning, um zu bestimmen, wie viel CPU und Arbeitsspeicher Sie dem Modell bei der Bereitstellung als Webdienst zuordnen müssen.
- Wenn Sie Echtzeitrückschlüsse durchführen, aber keine Hochverfügbarkeit benötigen, stellen Sie in Azure Container Instances (keine SKU-Auswahl) bereit.
- Wenn Sie Echtzeitrückschlüsse durchführen, aber Hochverfügbarkeit benötigen, stellen Sie in Azure Kubernetes Service bereit.
- Wenn Sie herkömmliche Machine Learning-Modelle verwenden und <10 Abfragen/s erhalten, beginnen Sie mit einer CPU-SKU. SKUs der F-Serie funktionieren häufig gut.
- Wenn Sie Deep Learning-Modelle verwenden und >10 Abfragen/s erhalten, probieren Sie eine NVIDIA GPU-SKU (NCasT4_v3 funktioniert häufig gut) mit Triton aus.
Berücksichtigen Sie für Batchrückschlussszenarien die folgenden Vorschläge:
- Wenn Sie Azure Machine Learning-Pipelines für Batchrückschlüsse verwenden, befolgen Sie die Anweisungen unter Bestimmen der Computegröße für das Training, um Ihre anfängliche VM-Größe zu wählen.
- Optimieren Sie Kosten und Leistung, indem Sie horizontal skalieren. Eine der wichtigsten Methoden zur Optimierung von Kosten und Leistung ist die Parallelisierung der Workload mithilfe eines Schritts zur parallelen Ausführung in Azure Machine Learning. Dieser Pipelineschritt ermöglicht es Ihnen, viele kleinere Knoten zu verwenden, um die Aufgabe parallel auszuführen, was wiederum die horizontale Skalierung ermöglicht. Für die Parallelisierung fällt jedoch ein Mehraufwand an. Abhängig von der Workload und dem Grad der Parallelität, der erreicht werden kann, stellt ein paralleler Ausführungsschritt eine Option dar oder nicht.
Bestimmen der Größe für die Compute-Instanz
Für die interaktive Entwicklung wird die Compute-Instanz von Azure Machine Learning empfohlen. Das Angebot für Compute-Instanzen (CI) bietet Computeressourcen mit einem einzelnen Knoten, die an einen einzelnen Benutzer gebunden sind und als Cloudarbeitsstation verwendet werden können.
Einige Organisationen erlauben keine Verwendung von Produktionsdaten auf lokalen Arbeitsstationen, besitzen erzwungene Einschränkungen für die Arbeitsstationsumgebung oder schränken die Installation von Paketen und Abhängigkeiten in der IT-Umgebung des Unternehmens ein. Eine Compute-Instanz kann als Arbeitsstation verwendet werden, um die Einschränkung zu überwinden. Sie bietet eine sichere Umgebung mit Zugriff auf Produktionsdaten und lässt sich auf Images ausführen, die mit beliebten Paketen und Tools für Data Science vorinstalliert werden.
Wenn die Compute-Instanz ausgeführt wird, werden dem Benutzer VM-Compute, Load Balancer Standard (einschließlich LB-/Ausgangsregeln und verarbeitete Daten), ein Betriebssystemdatenträger (verwalteter SSD Premium P10-Datenträger), ein temporärer Datenträger (der Typ des temporären Datenträgers hängt von der gewählten VM-Größe ab) und eine öffentliche IP-Adresse in Rechnung gestellt. Um Kosten zu sparen, empfehlen wir Benutzern Folgendes:
- Starten und beenden Sie die Compute-Instanz, wenn sie nicht verwendet wird.
- Arbeiten Sie mit einer Stichprobe Ihrer Daten auf einer Compute-Instanz, und skalieren Sie sie auf Computecluster hoch, um mit Ihrem vollständigen Dataset zu arbeiten.
- Übermitteln Sie Experimentieraufträge im lokalen Computezielmodus auf die Compute-Instanz, während Sie entwickeln oder testen, oder wenn Sie zur gemeinsam genutzten Computekapazität wechseln, wenn Sie Aufträge in vollem Umfang übermitteln. Beispielsweise viele Epochen, ein vollständiges Dataset und Hyperparametersuche.
Wenn Sie die Compute-Instanz beenden, erfolgt keine Abrechnung für VM-Computestunden, den temporären Datenträger und für Kosten der in der Load Balancer Standard-Instanz verarbeiteten Daten mehr. Beachten Sie, dass der Benutzer weiterhin für Betriebssystemdatenträger und die in Load Balancer Standard enthaltenen LB-/Ausgangsregeln bezahlt, auch wenn die Compute-Instanz beendet ist. Alle auf dem Betriebssystemdatenträger gespeicherten Daten werden durch Beenden und Neustarts beibehalten.
Optimieren der ausgewählten VM-Größe durch Überwachen der Computeauslastung
Sie können Informationen zu Ihrer Azure Machine Learning-Computenutzung und -auslastung über Azure Monitor anzeigen. Sie können Details zur Modellimplementierung und -registrierung, Kontingentdetails wie aktive und im Leerlauf befindliche Knoten, Ausführungsdetails wie abgebrochene und abgeschlossene Ausführungen sowie Computeauslastung für GPU- und CPU-Auslastung anzeigen.
Basierend auf den Erkenntnissen aus den Überwachungsdetails können Sie Ihre Ressourcennutzung im gesamten Team besser planen oder anpassen. Wenn Sie beispielsweise während der letzten Woche viele Knoten im Leerlauf bemerkt haben, können Sie mit den entsprechenden Arbeitsbereichsbesitzern zusammenarbeiten, um die Konfiguration des Computeclusters zu aktualisieren, um diese zusätzlichen Kosten zu vermeiden. Die Vorteile der Analyse der Auslastungsmuster können bei der Vorhersage von Kosten und Budgetverbesserungen helfen.
Sie können auf diese Metriken direkt im Azure-Portal zugreifen. Wechseln Sie zu Ihrem Azure Machine Learning-Arbeitsbereich, und wählen Sie im linken Bereich im Abschnitt „Überwachung“ die Option Metriken aus. Anschließend können Sie Details dazu auswählen, was Sie anzeigen möchten, z. B. Metriken, Aggregation und Zeitraum. Weitere Informationen finden Sie auf der Dokumentationsseite zum Überwachen von Azure Machine Learning.
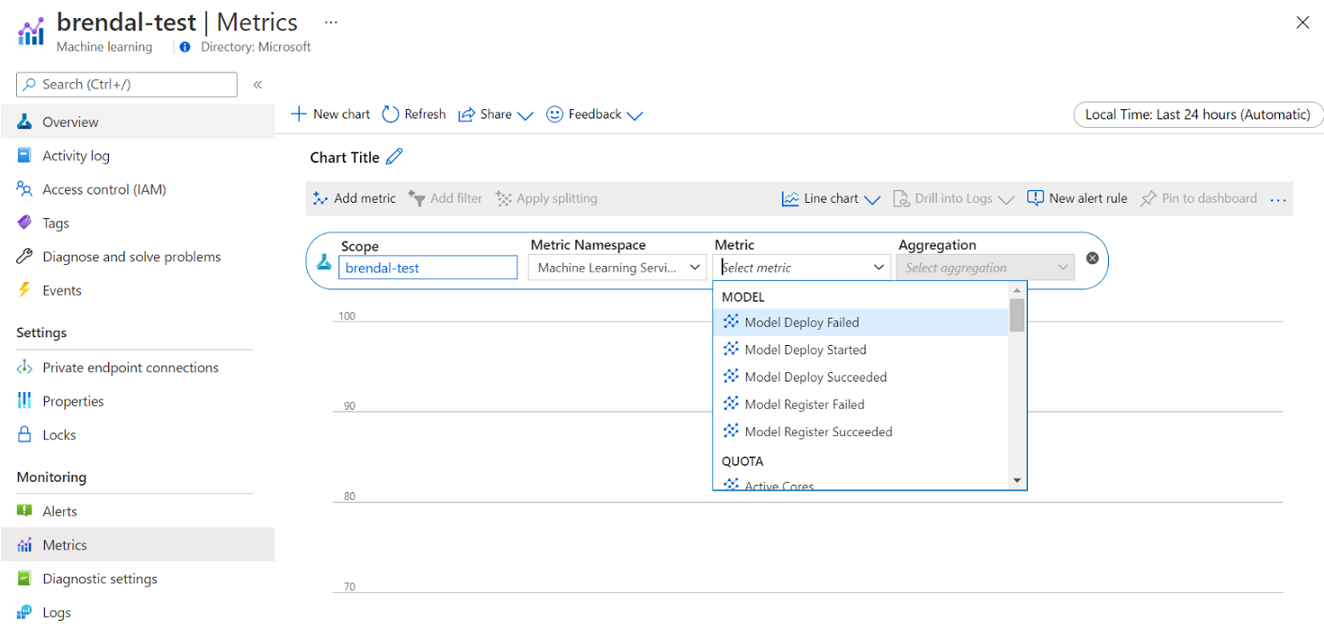
Wechseln zwischen lokalen Cloudcomputeressourcen, Cloudcomputeressourcen mit einem und mit mehreren Knoten während der Entwicklung
Während des gesamten Machine Learning-Lebenszyklus gibt es schwankende Compute- und Toolanforderungen. Um diese Anforderungen zu erfüllen, können Sie sich praktisch von jeder bevorzugten Arbeitsstationskonfiguration aus über eine SDK- oder CLI-Schnittstelle mit Azure Machine Learning verbinden.
Um Kosten zu sparen und produktiv zu arbeiten, wird Folgendes empfohlen:
- Klonen Sie Ihre Experimentcodebasis lokal mithilfe von Git, und übermitteln Sie Aufträge mithilfe des Azure Machine Learning-SDK oder der CLI an Cloudcomputeressourcen.
- Wenn Ihr Dataset groß ist, sollten Sie erwägen, eine Stichprobe Ihrer Daten auf Ihrer lokalen Arbeitsstation zu verwalten und gleichzeitig das vollständige Dataset im Cloudspeicher zu speichern.
- Parametrisieren Sie ihre Experimentcodebasis, sodass Sie Ihre Aufträge für die Ausführung mit einer variierenden Anzahl von Epochen oder Datasets unterschiedlicher Größe konfigurieren können.
- Hartcodieren Sie den Ordnerpfad Ihres Datasets nicht. Sie können dann dieselbe Codebasis problemlos mit unterschiedlichen Datasets und im lokalen und Cloudausführungskontext wiederverwenden.
- Bootstrappen Sie Ihre Experimentieraufträge im lokalen Computezielmodus, während Sie entwickeln oder testen, oder wenn Sie zu einer gemeinsam genutzten Computeclusterkapazität wechseln, wenn Sie Aufträge in vollem Umfang übermitteln.
- Wenn Ihr Dataset groß ist, arbeiten Sie mit einer Stichprobe der Daten auf Ihrer lokalen Arbeitsstation oder Compute-Instanzarbeitsstation, während Sie in Azure Machine Learning auf Cloudcomputeressourcen skalieren, um mit Ihrem vollständigen Dataset zu arbeiten.
- Wenn die Ausführung Ihrer Aufträge lange dauert, sollten Sie erwägen, Ihre Codebasis für verteiltes Training zu optimieren, um horizontales Aufskalieren zu ermöglichen.
- Entwerfen Sie Ihre verteilten Trainingsworkloads für Knotenelastizität, um eine flexible Verwendung von Compute mit einem oder mehreren Knoten zu ermöglichen und die Nutzung von Compute zu vereinfachen, die vorzeitig entfernt werden kann.
Kombinieren von Computetypen mithilfe von Azure Machine Learning-Pipelines
Wenn Sie Ihre Machine Learning-Workflows orchestrieren, können Sie eine Pipeline mit mehreren Schritten definieren. Jeder Schritt in der Pipeline kann auf einem eigenen Computetyp ausgeführt werden. Dadurch können Sie Leistung und Kosten so optimieren, dass sie schwankende Computeanforderungen im gesamten Machine Learning-Lebenszyklus erfüllen.
Steuern der optimalen Nutzung des Budgets eines Teams
Während Entscheidungen über die Budgetzuteilung außerhalb des Einflussbereichs eines einzelnen Teams liegen können, ist ein Team in der Regel befugt, das ihm zugeteilte Budget optimal nach seinen Bedürfnissen zu nutzen. Durch kluges Abwägen von Auftragspriorität gegenüber Leistung und Kosten kann ein Team eine höhere Clusterauslastung erreichen, die Gesamtkosten senken und mit demselben Budget eine größere Anzahl von Computestunden nutzen. Dies kann zu einer verbesserten Teamproduktivität führen.
Optimieren der Kosten gemeinsam genutzter Computeressourcen
Der Schlüssel zum Optimieren der Kosten gemeinsam genutzter Computeressourcen besteht darin, sicherzustellen, dass ihre gesamte Kapazität genutzt wird. Im Folgenden finden Sie einige Tipps zum Optimieren der Kosten für gemeinsam genutzte Ressourcen:
- Wenn Sie Compute-Instanzen verwenden, aktivieren Sie diese nur, wenn Sie Code ausführen müssen. Fahren Sie sie herunter, wenn sie nicht verwendet werden.
- Wenn Sie Computecluster verwenden, legen Sie die Mindestknotenanzahl auf 0 und die Knotenhöchstzahl auf einen Wert fest, der basierend auf Ihren Budgeteinschränkungen ausgewertet wird. Verwenden Sie den Azure-Preisrechner, um die Kosten für die vollständige Auslastung eines VM-Knotens Ihrer ausgewählten VM-SKU zu berechnen. Bei der automatischen Skalierung werden alle Computeknoten herunterskaliert, wenn sie von niemandem verwendet werden. Es erfolgt nur eine Hochskalierung auf die Anzahl der Knoten, für die Sie ein Budget haben. Sie können die automatische Skalierung konfigurieren, um alle Computeknoten herunterzuskalieren.
- Überwachen Sie beim Training von Modellen Ihre Ressourcenauslastungen wie CPU-Auslastung und GPU-Auslastung. Wenn die Ressourcen nicht vollständig ausgelastet sind, ändern Sie Ihren Code, um Ressourcen besser auszulasten, oder skalieren Sie sie auf kleinere oder kostengünstigere VM-Größen herunter.
- Bewerten Sie, ob Sie gemeinsam genutzte Computeressourcen für Ihr Team erstellen können, um Ineffizienzen beim Computing zu vermeiden, die durch Clusterskalierungsvorgänge verursacht werden.
- Optimieren Sie Timeoutrichtlinien für die automatische Skalierung von Computeclustern auf Grundlage von Nutzungsmetriken.
- Verwenden Sie Arbeitsbereichskontingente, um die Menge der Computeressourcen zu steuern, auf die einzelne Arbeitsbereiche Zugriff haben.
Einführen von Planungspriorität durch Erstellen von Clustern für mehrere VM-SKUs
Ein Team, das unter Kontingent- und Budgetbeschränkungen agiert, muss einen Kompromiss zwischen der rechtzeitigen Ausführung von Aufträgen und den Kosten finden, um sicherzustellen, dass wichtige Aufträge rechtzeitig ausgeführt werden und das Budget bestmöglich genutzt wird.
Um eine optimale Computeauslastung zu unterstützen, wird Teams empfohlen, Cluster verschiedener Größen mit niedriger Priorität und dedizierten VM-Prioritäten zu erstellen. Computeressourcen mit niedriger Priorität nutzen überschüssige Kapazität in Azure und gehen deshalb mit ermäßigten Preisen einher. Nachteilig ist allerdings, dass diese Computer jederzeit vorzeitig entfernt werden können, sobald eine Aufgabe mit höherer Priorität eingeht.
Mithilfe der Cluster unterschiedlicher Größe und Priorität kann ein Konzept der Planungspriorität eingeführt werden. Wenn beispielsweise experimentelle und Produktionsaufträge um dasselbe NC-GPU-Kontingent konkurrieren, hat ein Produktionsauftrag möglicherweise Vorrang bei der Ausführung gegenüber dem experimentellen Auftrag. Führen Sie in diesem Fall den Produktionsauftrag im dedizierten Computecluster und den experimentellen Auftrag im Computecluster mit niedriger Priorität aus. Wenn das Kontingent knapp wird, wird der experimentelle Auftrag zugunsten des Produktionsauftrags vorzeitig entfernt.
Erwägen Sie neben der VM-Priorität die Ausführung von Aufträgen auf verschiedenen VM-SKUs. Es kann sein, dass die Ausführung eines Auftrags auf einer VM-Instanz mit einer P40-GPU länger als bei einer V100-GPU dauert. Da V100-VM-Instanzen jedoch möglicherweise belegt sind oder das Kontingent vollständig ausgelastet ist, kann die Zeit bis zum Abschluss auf der P40 unter dem Aspekt des Auftragsdurchsatzes immer noch schneller sein. Unter dem Aspekt der Kostenverwaltung sollten Sie vielleicht auch die Ausführung von Aufträgen mit niedrigerer Priorität auf weniger leistungsfähigen und kostengünstigeren VM-Instanzen in Betracht ziehen.
Vorzeitiges Beenden einer Ausführung, wenn das Training nicht konvergiert
Wenn Sie kontinuierlich experimentieren, um ein Modell gegenüber seiner Baseline zu verbessern, können Sie verschiedene Experimentausführungen mit jeweils leicht unterschiedlichen Konfigurationen ausführen. Für eine Ausführung können Sie die Eingabedatasets optimieren. Bei einer weiteren Ausführung nehmen Sie vielleicht eine Hyperparameteränderung vor. Nicht alle Änderungen sind zwangläufig so effektiv wie die anderen. Sie erkennen frühzeitig, dass eine Änderung nicht die beabsichtigte Auswirkung auf die Qualität Ihres Modelltrainings hatte. Um zu ermitteln, ob das Training nicht konvergiert, überwachen Sie den Trainingsfortschritt während einer Ausführung. Beispielsweise durch Protokollieren von Leistungsmetriken nach jeder Trainingsepoche. Erwägen Sie die frühzeitige Beendigung des Auftrags, um Ressourcen und Budget für einen anderen Versuch freizugeben.
Planen, Verwalten und gemeinsames Nutzen von Budgets, Kosten und Kontingenten
Wenn ein Unternehmen die Anzahl seiner Machine Learning-Anwendungsfälle und -Teams erhöht, ist eine höhere Betriebsreife von IT und Finanzen sowie eine Koordination zwischen den einzelnen Machine Learning-Teams erforderlich, um einen effizienten Betrieb sicherzustellen. Kapazitäts- und Kontingentverwaltung auf Unternehmensniveau werden wichtig, um mit der Knappheit an Computeressourcen umzugehen und den Verwaltungsaufwand zu bewältigen.
In diesem Abschnitt werden bewährte Methoden für die Planung, Verwaltung und gemeinsame Nutzung von Budgets, Kosten und Kontingenten auf Unternehmensniveau erläutert. Er basiert auf Erkenntnissen aus der internen Verwaltung vieler GPU-Trainingsressourcen für Machine Learning bei Microsoft.
Grundlegendes zu Ressourcenausgaben mit Azure Machine Learning
Eine der größten Herausforderungen als Administrator bei der Planung von Computeanforderungen besteht darin, ganz neu zu beginnen, ohne historische Informationen für eine Baselineabschätzung zu besitzen. Aus praktischer Sicht beginnen die meisten Projekte im ersten Schritt mit einem kleinen Budget.
Um zu verstehen, wohin das Budget fließt, ist es entscheidend zu wissen, woher Azure Machine Learning-Kosten stammen können:
- Azure Machine Learning erhebt Gebühren nur für verwendete Compute-Infrastruktur und erhebt keinen zusätzlichen Aufschlag auf Computekosten.
- Wenn ein Azure Machine Learning-Arbeitsbereich erstellt wird, werden auch ein paar andere Ressourcen erstellt, um Azure Machine Learning zu ermöglichen: Key Vault, Application Insights, Azure Storage und Azure Container Registry. Diese Ressourcen werden in Azure Machine Learning verwendet, und Sie bezahlen für diese Ressourcen.
- Mit verwalteten Computeressourcen wie Trainingsclustern, Compute-Instanzen und verwalteten Rückschlussendpunkten gehen Kosten einher. Bei diesen verwalteten Computeressourcen müssen die folgenden Infrastrukturkosten berücksichtigt werden: virtuelle Computer, virtuelles Netzwerk, Lastenausgleich, Bandbreite und Speicher.
Nachverfolgen von Ausgabenmustern und Erstellen besserer Berichte mit Tagging
Es kommt häufig vor, dass Administratoren die Kosten für verschiedene Ressourcen in Azure Machine Learning nachverfolgen möchten. Tagging ist eine natürliche Lösung für dieses Problem und entspricht dem allgemeinen Ansatz, der von Azure und vielen anderen Cloud-Dienstanbietern verwendet wird. Durch die Unterstützung von Tags können Sie jetzt eine Kostenaufschlüsselung auf Computeebene anzeigen. Damit steht Ihnen eine detailliertere Ansicht zur Verfügung, die eine bessere Kostenüberwachung, eine verbesserte Berichterstellung und mehr Transparenz ermöglicht.
Das Tagging ermöglicht es Ihnen, Ihre Arbeitsbereiche und Computeressourcen (aus Azure Resource Manager-Vorlagen und Azure Machine Learning Studio) mit benutzerdefinierten Tags zu versehen, auf deren Grundlage Sie diese Ressourcen zur Beobachtung von Ausgabenmustern in Microsoft Cost Management weiter filtern können. Diese Funktion eignet sich optimal für Szenarien mit internen Rückbuchungen. Darüber hinaus können Tags nützlich sein, um Metadaten oder Details im Zusammenhang mit der Berechnung zu erfassen, z. B. ein Projekt, ein Team oder einen bestimmten Rechnungscode. Dies macht das Tagging sehr vorteilhaft, um zu messen, wie viel Geld Sie für verschiedene Ressourcen ausgeben, und somit tiefere Einblicke in Ihre Kosten und Ausgabenmuster über Teams oder Projekte hinweg zu gewinnen.
Es gibt auch vom System eingefügte Tags auf Computes, mit denen Sie auf der Seite „Kostenanalyse“ nach dem Tag „Computetyp“ filtern können, um eine Aufschlüsselung Ihrer Gesamtausgaben nach Compute anzuzeigen und zu bestimmen, welche Kategorie von Computeressourcen möglicherweise den Großteil Ihrer Kosten ausmacht. Dies ist besonders nützlich, um besseren Einblick in Ihre Trainings- und Rückschlusskostenmuster zu erhalten.
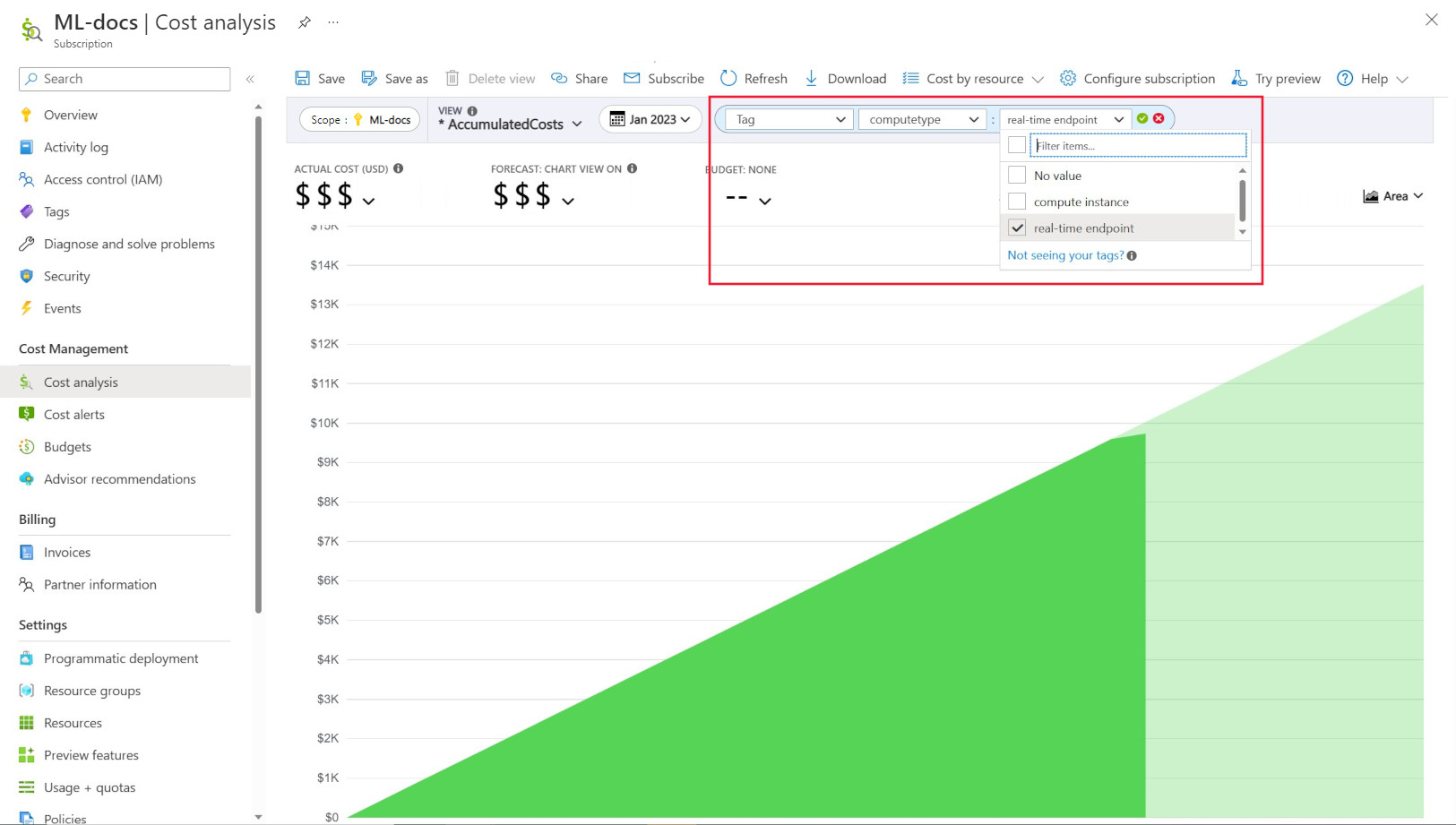
Steuern und Einschränken der Computenutzung durch Richtlinien
Wenn Sie eine Azure-Umgebung mit vielen Workloads verwalten, kann es eine Herausforderung sein, den Überblick über die Ressourcenausgaben zu behalten. Azure Policy kann Ihnen helfen, die Ressourcenausgaben zu kontrollieren und zu steuern, indem bestimmte Nutzungsmuster in der gesamten Azure-Umgebung eingeschränkt werden.
Insbesondere für Azure Machine Learning empfehlen wir, Richtlinien einzurichten, die nur die Verwendung bestimmter VM-SKUs zulassen. Richtlinien können dabei helfen, die Auswahl teurer VMs zu verhindern und zu kontrollieren. Richtlinien können auch verwendet werden, um die Verwendung von VM-SKUs mit niedriger Priorität zu erzwingen.
Zuordnen und Verwalten von Kontingenten auf Grundlage der Geschäftspriorität
Mit Azure können Sie Grenzwerte für die Kontingentzuordnung auf Abonnement- und Azure Machine Learning-Arbeitsbereichsebene festlegen. Die Einschränkung, wer Kontingente über die rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC) von Azure verwalten kann, kann dazu beitragen, die Ressourcenauslastung und Vorhersagbarkeit von Kosten sicherzustellen.
Die Verfügbarkeit des GPU-Kontingents kann in Ihren Abonnements knapp sein. Um eine hohe Kontingentauslastung über alle Workloads hinweg sicherzustellen, wird empfohlen, zu überwachen, ob das Kontingent workloadübergreifend optimal genutzt und zugewiesen wird.
Bei Microsoft wird in regelmäßigen Abständen ermittelt, ob GPU-Kontingente optimal genutzt und über alle Machine Learning-Teams hinweg optimal zugeordnet werden, indem Kapazitätsanforderungen in Bezug auf die Geschäftspriorität bewertet werden.
Vorzeitiges Committen von Kapazitäten
Wenn Sie eine gute Schätzung haben, welcher Computeumfang im nächsten Jahr oder in den nächsten paar Jahren anfallen wird, können Sie Azure Reserved VM Instances zu ermäßigten Kosten erwerben. Es können Laufdauern von einem oder drei Jahren gekauft werden. Da für Azure Reserved VM Instances ermäßigte Preise gelten, können Sie im Vergleich zu den Preisen für nutzungsbasierte Bezahlung erhebliche Kosteneinsparungen erzielen.
Azure Machine Learning unterstützt reservierte Compute-Instanzen. Nachlässe werden automatisch auf verwaltete Computeressourcen von Azure Machine Learning angewendet.
Verwalten der Datenaufbewahrung
Jedes Mal, wenn eine Machine Learning-Pipeline ausgeführt wird, können bei jedem Pipelineschritt zum Zwecke der Zwischenspeicherung und Wiederverwendung zwischengeschaltete Datasets generiert werden. Das Anwachsen der Daten als Ergebnis dieser Machine Learning-Pipelines kann zu einem Problem für eine Organisation werden, die viele Machine Learning-Experimente ausführt.
Datenanalysten verbringen ihre Zeit in der Regel nicht mit dem Bereinigen der generierten Zwischendatasets. Im Laufe der Zeit summiert sich die Menge der generierten Daten nicht unerheblich. Azure Storage bietet eine Möglichkeit, die Verwaltung des Datenlebenszyklus zu verbessern. Mithilfe der Azure Blob Storage-Lebenszyklusverwaltung können Sie allgemeine Richtlinien einrichten, um nicht verwendete Daten in kältere Speicherebenen (Cold Storage) zu verschieben und so Kosten zu sparen.
Überlegungen zur Optimierung von Infrastrukturkosten
Netzwerk
Azure-Netzwerkkosten entstehen durch die von Azure-Rechenzentren ausgehende Bandbreite. Alle eingehenden Daten in ein Azure-Rechenzentrum sind kostenlos. Der Schlüssel zur Reduzierung der Netzwerkkosten besteht in der Bereitstellung aller Ihrer Ressourcen in derselben Rechenzentrumsregion, wann immer dies möglich ist. Wenn Sie einen Azure Machine Learning-Arbeitsbereich und Computeressourcen in derselben Region bereitstellen können, in der Ihre Daten gespeichert sind, können Sie von geringeren Kosten und höherer Leistung profitieren.
Möglicherweise möchten Sie eine private Verbindung zwischen Ihrem lokalen Netzwerk und Ihrem Azure-Netzwerk herstellen, um so über eine Hybrid Cloud-Umgebung zu verfügen. ExpressRoute ermöglicht dies, aber angesichts der hohen Kosten für ExpressRoute kann es kostengünstiger sein, sich von einer Hybrid Cloud-Einrichtung zu verabschieden und alle Ressourcen in die Azure-Cloud zu verschieben.
Azure Container Registry
Für Azure Container Registry sind die bestimmenden Faktoren für die Kostenoptimierung unter anderem:
- Erforderlicher Durchsatz für Docker-Imagedownloads aus der Containerregistrierung in Azure Machine Learning
- Anforderungen an Unternehmenssicherheitsfunktionen, z. B. Azure Private Link
Für Produktionsszenarien, in denen hoher Durchsatz oder Unternehmenssicherheit erforderlich ist, wird die Premium-SKU von Azure Container Registry empfohlen.
Für Dev/Test-Szenarien, in denen Durchsatz und Sicherheit weniger kritisch sind, empfehlen wir entweder die Standard- oder die Premium-SKU.
Die Basic-SKU von Azure Container Registry wird für Azure Machine Learning nicht empfohlen. Sie wird wegen ihres niedrigen Durchsatzes und des geringen enthaltenen Speichers nicht empfohlen, der durch die relativ großen Docker-Images (>1 GB) von Azure Machine Learning schnell überschritten werden kann.
Berücksichtigen der Verfügbarkeit von Computingtypen bei der Auswahl von Azure-Regionen
Wenn Sie eine Region für Ihre Computeressourcen auswählen, bedenken Sie die Verfügbarkeit des Computekontingents. Beliebte und größere Regionen wie „USA, Osten“, „USA, Westen“ und „Europa, Westen“ verfügen im Vergleich zu einigen anderen Regionen mit strengeren Kapazitätseinschränkungen tendenziell über höhere Standardwerte und eine höhere Verfügbarkeit der meisten CPUs und GPUs.
Weitere Informationen
Nächste Schritte
Weitere Informationen zum Organisieren und Einrichten von Azure Machine Learning-Umgebungen finden Sie unter Organisieren und Einrichten von Azure Machine Learning-Umgebungen.
Informationen zu Best Practices für Machine Learning DevOps mit Azure Machine Learning finden Sie unter DevOps für maschinelles Lernen (MLOps) – ein Leitfaden.