Datenanwendungen (quellenorientiert)
Wenn Sie sich dafür entschieden haben, kein Datenagnostik-Modul für die einmalige Aufnahme von Daten aus betrieblichen Quellen zu implementieren, oder wenn Ihr Datenagnostik-Modul keine komplexen Verbindungen ermöglicht, sollten Sie eine Datenanwendung erstellen, die auf die Quelle ausgerichtet ist. Sie sollte dem gleichen Ablauf folgen wie ein Datenagnostik-Modul, das Daten aus externen Datenquellen aufnimmt.
Übersicht
Ihre Anwendungsressourcengruppe ist nur für die Datenaufnahme und -anreicherung aus externen Quellen, wie z. B. Telemetrie, Finanzen oder CRM, verantwortlich. Diese Ebene kann in Echtzeit, Batch und Micro-Batch ausgeführt werden.
In diesem Abschnitt wird die Infrastruktur erläutert, die für jede (quellenorientierte) Ressourcengruppe innerhalb der Datenzielzone bereitgestellt wird.
Tipp
Beim Data Mesh können Sie entweder eines pro Quelle oder eines pro Domäne bereitstellen. Die Grundsätze der Datenstandardisierung, der Datenqualität und der Datenherkunft müssen weiterhin beachtet werden. Datenplattform-Teams können Codeausschnitte entwickeln und diese zu diesem Zweck aufrufen.
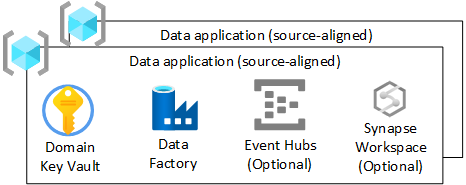
Für jede Datenanwendungs-Ressourcengruppe (quellenorientiert) in Ihrer Datenzielzone sollten Sie Folgendes erstellen:
- Einen Azure Key Vault
- Eine Azure Data Factory für die Ausführung entwickelter technischer Pipelines, die Daten von Rohdaten in angereicherte Daten umwandeln
- Ein Dienstprinzipal, der von der Datenanwendung (quellenorientiert) für die Bereitstellung von Ingest-Aufträgen in Azure Databricks verwendet wird (nur bei Verwendung von Azure Databricks)
Instanzen anderer Dienste wie Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics, und Azure Machine Learning können optional erstellt werden.
Hinweis
Sie müssen ein Spark-Modul wie Azure Synapse Spark oder Azure Databricks verwenden, um den Delta-Lake-Standard zu erzwingen.
Wenn Sie sich für die Verwendung von Azure Databricks entscheiden, empfehlen wir die Bereitstellung von Azure Data Factory anstelle von Azure Synapse Analytics Workspace, um die Oberfläche auf die erforderlichen Features zu beschränken.
Wenn Sie jedoch einen allumfassenden Entwicklungsbereich mit Pipelines und Spark benötigen, verwenden Sie Azure Synapse Analytics. Wenden Sie eine Richtlinie an, um nur die Verwendung von Spark und Pipelines zuzulassen, so dass Sie die Bildung von Silos in einem Azure Synapse SQL-Pool vermeiden.
Azure-Schlüsseltresor
Verwenden Sie die Azure Key Vault-Funktionalität, um Geheimnisse innerhalb von Azure zu speichern, wann immer dies möglich ist.
Jede Datenanwendung (quellenorientiert) Ressourcengruppe oder Datendomäne (wenn Mesh) verfügt über einen Azure Key Vault. Dadurch wird sichergestellt, dass der Verschlüsselungsschlüssel, das Geheimnis und die Zertifikatsableitung den Anforderungen Ihrer Umgebung entsprechen. Dies ermöglicht eine bessere Trennung der Verwaltungsaufgaben und verringert auch das Risiko, Schlüssel, Integrationen und Geheimnisse unterschiedlicher Klassifizierungen zu vermischen.
Alle Schlüssel, die sich auf Ihre Datenanwendung beziehen (quellenorientiert), sollten in Ihrem Azure Key Vault enthalten sein.
Wichtig
Schlüsseltresore für Datenanwendungen (quellenorientiert) sollten dem Least-Privilege-Modell folgen und sowohl Grenzen der Transaktionsskala als auch die gemeinsame Nutzung von Geheimnissen in verschiedenen Umgebungen vermeiden.
Azure Data Factory
Stellen Sie eine Azure Data Factory bereit, die es den Pipelines, die vom Datenanwendungsteam geschrieben wurden, ermöglicht, die Daten mithilfe der entwickelten Pipelines von Rohdaten in angereicherte Daten umzuwandeln. Verwenden Sie Zuordnungsdatenflüsse für Transformationen und nutzen Sie Azure Databricks (Ingest) Workspace oder Azure Synapse Spark für komplexe Transformationen.
Sie sollten Azure Data Factory mit der DevOps-Instanz Ihrer Datenanwendung (quellenorientiert) verbinden. Diese Verbindung ermöglicht CI/CD-Bereitstellungen.
Event Hubs
Wenn Ihre (quellenorientierte) Datenanwendung ein Daten-Streaming erfordert, können Sie nachgelagerte Event Hubs in Ihrer (quellenorientierten) Ressourcengruppe für Datenanwendungen bereitstellen.