Verwendung von Azure Databricks im Rahmen von Analysen auf Cloudebene in Azure
Azure Databricks ist eine Datenanalyseplattform, die für die Microsoft Azure Cloud Services-Plattform optimiert ist. Azure Databricks bietet zwei Umgebungen für die Entwicklung datenintensiver Anwendungen:
Azure Databricks SQL, was das schnelle Ausführen von Ad-hoc-SQL-Abfragen für Ihren Data Lake ermöglicht.
Azure Databricks Data Science & Engineering (manchmal auch einfach „Arbeitsbereich“ genannt) ist eine auf Apache Spark basierende Analyseplattform. Sie ist in Azure integriert, um Folgendes zu ermöglichen: Einrichtung mit nur einem Klick, optimierte Workflows und einen interaktiven Arbeitsbereich für die Zusammenarbeit von Datentechnikern, Data Scientists und Machine Learning-Technikern.
Für Analysen auf Cloudebene konzentrieren wir uns auf Azure Databricks Data Science & Engineering.
Überblick
Für jede von Ihnen bereitgestellte Datenzielzone haben Sie die Möglichkeit, zwei freigegebene Arbeitsbereiche bereitzustellen. Eine für die datenagnostische Erfassung und eine andere für Analysen.
- Der Azure Databricks Engineering-Arbeitsbereich für die Erfassung und Verarbeitung stellt über Azure-Dienstprinzipale eine Verbindung mit Azure Data Lake her. Es wird von der datenagnostischen Erfassung aufgerufen.
- Der Azure Databricks Analyse-Arbeitsbereich kann für alle Data Scientists und Datenbetriebsteams bereitgestellt werden. Dieser Arbeitsbereich stellt mithilfe der Passthrough-Authentifizierung von Microsoft Entra eine Verbindung mit Azure Data Lake her. Sie geben den Azure Databricks Analytics- und Data Science-Arbeitsbereich in der gesamten Datenzielzone für alle Benutzer mit Zugriff auf den Arbeitsbereich frei.
Wenn Sie über einen automatisierten datenagnostischen Erfassungs-Engine verfügen, verwendet der Azure Databricks Engineering-Arbeitsbereich eine Azure Key Vault-Instanz, die in der Azure Metadatendienstressourcengruppe erstellt wurde, um Datenerfassungspipelines von roh in angereichert auszuführen.
Der Azure Databricks-Analyse-Arbeitsbereich muss über Clusterrichtlinien verfügen, die das Erstellen von Clustern mit hoher Parallelität erfordern. Dieser Clustertyp ermöglicht das Untersuchen von Data Lakes mithilfe von Microsoft Entra-Passthrough für Anmeldeinformationen. Weitere Informationen finden Sie unter Zugriffssteuerung und Data Lake-Konfigurationen in Azure Data Lake Storage.
Konfigurieren von Azure Databricks
Die Azure Databricks-Bereitstellung basiert teilweise auf Parametern über eine Azure Resource Manager-Vorlage und YAML-Skripten, erfordert aber auch einen manuellen Eingriff, um alle Arbeitsbereiche zu konfigurieren.
Alle Azure Databricks-Arbeitsbereiche sollten den Premium-Plan verwenden, der die folgenden erforderlichen Funktionen bietet:
- Optimierte automatische Computeskalierung
- Passthrough-Authentifizierung von Anmeldeinformationen von Microsoft Entra
- Bedingte Authentifizierung
- Rollenbasierte Zugriffssteuerung für Notebooks, Cluster, Aufträge und Tabellen
- Überwachungsprotokolle
Zur Ausrichtung an Analysen auf Cloudebene wird empfohlen, dass für alle Arbeitsbereiche die folgenden Standardbereitstellungsoptionen konfiguriert sind:
- Die Azure Databricks-Arbeitsbereiche werden mit einer externen Apache Hive Metastore-Instanz in der Datenzielzone verbunden.
- Konfigurieren Sie jeden Arbeitsbereich so, dass die Databricks-Diagnoseprotokollierung an Azure Log Analytics im databricks-monitoring-rg gesendet wird.
- Implementieren Sie Cluster-Richtlinien, um die Möglichkeit zur Erstellung von Clustern anhand einer Reihe von Regeln einzuschränken. Weitere Informationen finden Sie unter Verwalten von Cluster-Richtlinien.
- Definieren Sie mehrere Cluster-Richtlinien. Weisen Sie im Rahmen des Onboarding-Prozesses jeder Zielgruppe die Berechtigung zu, die vom Betriebsteam für Datenzielzonen verwendet werden soll. Standardmäßig wird die Berechtigung zum Erstellen von Clustern nur dem Betriebsteam erteilt. Verschiedenen Teams oder Gruppen wird die Berechtigung zum Verwenden von Cluster-Richtlinien erteilt.
- Verwenden Sie die Cluster-Richtlinien in Kombination mit Azure Databricks-Pools, um die Start- und Autoskalierungszeiten von Clustern zu reduzieren, indem Sie eine Reihe von sofort einsatzbereiten Instanzen im Leerlauf beibehalten. Weitere Informationen finden Sie unter Pools.
- Rufen Sie alle Azure Databricks Betriebsgeheimnisse, wie die SPN-Anmeldeinformationen und Verbindungszeichenfolgen, aus einer Azure Key Vault ab.
- Konfigurieren Sie eine separate Unternehmensanwendung pro Arbeitsbereich für die Verwendung mit SCIM (System für die domänenübergreifende Identitätsverwaltung). Der Link zum Azure Databricks-Arbeitsbereich, um den Zugriff und die Berechtigungen für jeden Arbeitsbereich zu steuern. Weitere Informationen finden Sie unter Bereitstellen von Benutzer*innen und Gruppen mit SCIM und Konfigurieren der SCIM-Bereitstellung für Microsoft Entra ID.
Warnung
Wenn Sie den Azure Databricks-Arbeitsbereich konfigurieren, um die Azure Databricks-SCIM-Schnittstelle zu verwenden, wirkt sich das auf Ihre Bereitstellung der Sicherheitskontrollen aus. Sie wechselt von einem automatisierten in einen manuellen Prozess und unterbricht alle CI/CD-Bereitstellungspipelines.
Die folgenden Zugriffssteuerungsoptionen werden für alle Databricks-Arbeitsbereiche festgelegt:
- Die Sichtbarkeitssteuerung für die Arbeitsbereiche: aktiviert (Standard: deaktiviert)
- Die Sichtbarkeitssteuerung für die Cluster: aktiviert (Standard: deaktiviert)
- Die Sichtbarkeitssteuerung für die Aufträge: aktiviert (Standard: deaktiviert)
Möglicherweise sollten Sie die folgenden Optionen für den Azure Databricks-Analyse-Arbeitsbereich aktivieren:
- Notebook-Export: deaktiviert (Standard: aktiviert)
- Funktionen der Notebook-Tabellenzwischenablage: deaktiviert (Standard: aktiviert)
- Tabellenzugriffssteuerung: aktiviert (Standard: deaktiviert)
- Bedingter Microsoft Entra-Zugriff
Bereitstellen von Azure Databricks
Wenn Sie die Azure Databricks-Arbeitsbereiche als Teil einer neuen Bereitstellung der Datenzielzone bereitstellen. Das folgende Bild zeigt einen Beispielworkflow für die Bereitstellung einer Azure Databricks-Umgebung bei Analysen auf Cloudebene.
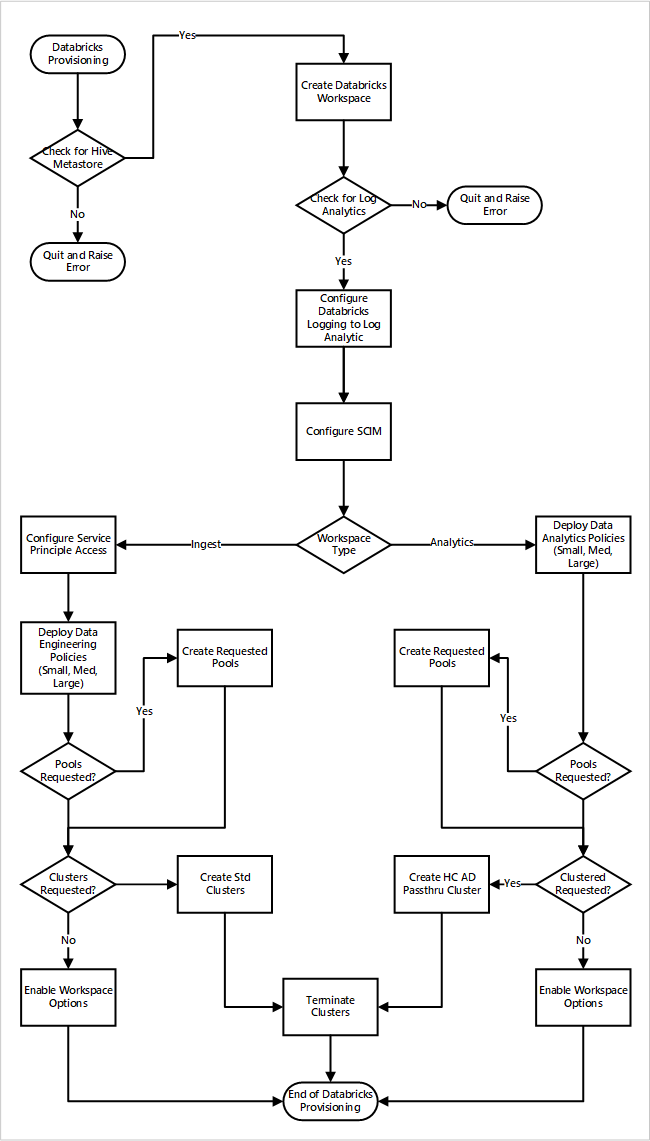
- Der Bereitstellungsprozess stellt zunächst sicher, dass eine Apache Hive Metastore-Instanz in der Datenzielzone vorhanden ist. Wenn der Apache Hive Metastore nicht gefunden wird, wird das Programm beendet und eine Fehlermeldung ausgegeben.
- Nach einer erfolgreichen Suche von Apache Hive Metastore wird ein Arbeitsbereich erstellt.
- Der Prozess überprüft auf einen Log Analytics-Arbeitsbereich in der Datenzielzone. Wenn der Log Analytics-Arbeitsbereich nicht gefunden wird, wird das Programm beendet und eine Fehlermeldung ausgegeben.
- Für jeden Arbeitsbereich wird eine Microsoft Entra-Anwendung erstellt und SCIM konfiguriert.
Für den Azure Databricks-Erfassungsarbeitsbereich:
- Der Prozess konfiguriert den Arbeitsbereich mit dem Zugriff auf den Dienstprinzipal.
- Die Datentechnikrichtlinien, die vom Betriebsteam für die Datenplattform definiert wurden, werden bereitgestellt.
- Wenn das Betriebsteam für Datenzielzonen Databricks-Pools oder -Cluster angefordert hat, können sie in den Bereitstellungsprozess integriert werden.
- Dies ermöglicht Arbeitsbereichsoptionen, die spezifisch für den Azure Databricks-Technik-Arbeitsbereich sind.
Für den Azure Databricks-Analysearbeitsbereich:
- Der Prozess stellt Datenanalyserichtlinien bereit, die vom Betriebsteam der Datenplattform definiert wurden.
- Wenn das Betriebsteam für Datenzielzonen Databricks-Pools oder -Cluster angefordert hat, können sie in den Bereitstellungsprozess integriert werden.
- Dies ermöglicht Arbeitsbereichsoptionen, die spezifisch für den Azure Databricks-Technik-Arbeitsbereich sind.
Externer Hive-Metastore
Bereitstellung in einem Azure Databricks-Arbeitsbereich:
- Ein neues globales Init-Skript konfiguriert Apache Hive Metastore-Einstellungen für alle Cluster. Dieses Skript wird von der neuenglobalen Init-Skript-API verwaltet.
Die neue API für globale Init-Skripte befindet sich in der öffentlichen Vorschau. Die öffentlichen Previewfunktionen in Azure Databricks sind für Produktionsumgebungen bereit und werden vom Supportteam unterstützt. Weitere Informationen finden Sie unter Azure Databricks-Vorschauversionen.
- Diese Lösung verwendet Azure Database for MySQL, um die Apache Hive-Metastore-Instanz zu speichern. Diese Datenbank wurde aufgrund ihrer Kosteneffizienz und ihrer hohen Kompatibilität mit Apache Hive ausgewählt.
Nächste Schritte
Analysen auf Cloudebene berücksichtigen die folgenden Leitlinien für die Integration von Azure Databricks: