Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wir empfehlen diese bewährten Methoden für die Verwendung von Cloud-Skalierungsanalysen in Microsoft Azure zum Operationalisieren von Data Science-Projekten.
Entwickeln einer Vorlage
Entwickeln Sie eine Vorlage, die eine Reihe von Diensten für Ihre Data Science-Projekte gebündelt. Verwenden Sie eine Vorlage, die eine Reihe von Diensten bündelt, um Konsistenz in den Anwendungsfällen verschiedener Data Science-Teams zu gewährleisten. Es wird empfohlen, einen konsistenten Blueprint in Form eines Vorlagenrepositorys zu entwickeln. Sie können dieses Repository für verschiedene Data Science-Projekte in Ihrem Unternehmen verwenden, um die Bereitstellungszeiten zu verkürzen.
Richtlinien für Data Science-Vorlagen
Entwickeln Sie eine Data Science-Vorlage für Ihre Organisation mit den folgenden Richtlinien:
Entwickeln Sie eine Reihe von Infrastruktur-als-Code-Vorlagen (IaC), um einen Azure Machine Learning-Arbeitsbereich bereitzustellen. Schließen Sie Ressourcen wie einen Schlüsseltresor, ein Speicherkonto, eine Containerregistrierung und Application Insights ein.
Schließen Sie das Einrichten von Datenspeichern und Computezielen in diese Vorlagen ein, z. B. Computeinstanzen, Computecluster und Azure Databricks.
Best Practices für die Bereitstellung
Echtzeit
- Schließen Sie eine Azure Data Factory- oder Azure Synapse-Bereitstellung in Vorlagen und Azure AI-Dienste ein.
- Die Vorlagen sollten alle erforderlichen Tools bereitstellen, um die Data Science-Explorationsphase und die anfängliche Operationalisierung des Modells auszuführen.
Überlegungen für ein anfängliches Setup
In einigen Fällen benötigen Data Scientists in Ihrer Organisation möglicherweise eine Umgebung für eine schnelle analyse nach Bedarf. Diese Situation ist üblich, wenn ein Data Science-Projekt nicht formell eingerichtet ist. Beispielsweise fehlen vielleicht Projektmanager*innen ein Kostencode oder eine Kostenstelle für die interne Verrechnung in Azure, und diese Dinge fehlen, weil es dazu eine Genehmigung braucht. Benutzer in Ihrer Organisation oder Ihrem Team müssen möglicherweise auf eine Data Science-Umgebung zugreifen, um die Daten zu verstehen und möglicherweise die Machbarkeit eines Projekts auszuwerten. Außerdem erfordern einige Projekte aufgrund der geringen Anzahl von Datenprodukten möglicherweise keine vollständige Data Science-Umgebung.
In anderen Fällen kann ein vollständiges Data Science-Projekt erforderlich sein, vollständig mit einer dedizierten Umgebung, Projektmanagement, Kostencode und Kostenstelle. Vollständige Data Science-Projekte sind nützlich für mehrere Teammitglieder, die zusammenarbeiten, Ergebnisse teilen und Modelle operationalisieren müssen, nachdem die Explorationsphase erfolgreich war.
Der Setupprozess
Vorlagen sollten pro Projekt bereitgestellt werden, nachdem sie eingerichtet wurden. Jedes Projekt sollte mindestens zwei Instanzen erhalten, damit die Entwicklungs- und Produktionsumgebungen voneinander getrennt sind. In der Produktionsumgebung sollte keine einzelne Person Zugriff haben, und alles sollte über Pipelines für Continuous Integration oder fortlaufende Entwicklung und einen Dienstprinzipal bereitgestellt werden. Diese Prinzipien der Produktionsumgebung sind wichtig, da Azure Machine Learning kein differenziertes rollenbasiertes Zugriffssteuerungsmodell innerhalb eines Arbeitsbereichs bereitstellt. Sie können den Benutzerzugriff nicht auf eine bestimmte Gruppe von Experimenten, Endpunkten oder Pipelines beschränken.
Die gleichen Zugriffsrechte gelten in der Regel für verschiedene Arten von Artefakten. Es ist wichtig, die Entwicklung von der Produktion zu trennen, um das Löschen von Produktionspipelinen oder Endpunkten in einem Arbeitsbereich zu verhindern. Zusammen mit der Vorlage muss ein Prozess erstellt werden, um Datenproduktteams die Möglichkeit zu geben, neue Umgebungen anzufordern.
Es wird empfohlen, unterschiedliche KI-Dienste wie Azure AI-Dienste pro Projekt einzurichten. Durch das Einrichten verschiedener KI-Dienste projektweise erfolgen Bereitstellungen für jede Ressourcengruppe für Datenprodukte. Diese Richtlinie schafft eine klare Trennung vom Standpunkt des Datenzugriffs und verringert das Risiko eines nicht autorisierten Datenzugriffs durch die falschen Teams.
Streaming-Szenario
Für Echtzeit- und Streaming-Anwendungsfälle sollten Bereitstellungen auf einem verkleinerten Azure Kubernetes Service (AKS)getestet werden. Tests können in der Entwicklungsumgebung durchgeführt werden, um Kosten zu sparen, bevor Sie sie auf dem Produktions-AKS oder dem Azure App Service für Container bereitstellen. Sie sollten einfache Eingabe- und Ausgabetests durchführen, um sicherzustellen, dass die Dienste wie erwartet reagieren.
Als Nächstes können Sie Modelle für den gewünschten Dienst bereitstellen. Dieses Computeziel für die Bereitstellung ist das einzige, das allgemein verfügbar ist und für Produktionsworkloads in einem AKS-Cluster empfohlen wird. Dieser Schritt ist besonders notwendig, wenn Unterstützung für eine Grafikverarbeitungseinheit (GPU) oder ein feldprogrammierbares Gate-Array benötigt wird. Andere systemeigene Bereitstellungsoptionen, die diese Hardwareanforderungen unterstützen, sind derzeit in Azure Machine Learning nicht verfügbar.
Azure Machine Learning erfordert eine 1:1-Zuordnung zu AKS-Clustern. Jede neue Verbindung mit einem Azure Machine Learning-Arbeitsbereich bricht die vorherige Verbindung zwischen AKS und Azure Machine Learning auf. Nachdem diese Einschränkung behoben ist, haben wir empfohlen, zentrale AKS-Cluster als freigegebene Ressourcen bereitzustellen und sie an ihre jeweiligen Arbeitsbereiche anzufügen.
Eine weitere zentrale AKS-Instanz muss gehostet werden, wenn Stresstests durchgeführt werden sollen, bevor Sie ein Modell in die Produktionsumgebung von AKS verschieben. Die Testumgebung sollte dieselbe Computeressource wie die Produktionsumgebung bereitstellen, um sicherzustellen, dass die Ergebnisse der Produktionsumgebung so ähnlich wie möglich sind.
Batchszenario
Nicht alle Anwendungsfälle benötigen AKS-Clusterbereitstellungen. Ein Anwendungsfall benötigt keine AKS-Clusterbereitstellung, wenn große Datenmengen nur regelmäßig eine Bewertung benötigen oder auf einem Ereignis basieren. Beispielsweise können große Datenmengen darauf basieren, wann Daten in ein bestimmtes Speicherkonto fallen. Azure Machine Learning-Pipelines und Azure Machine Learning-Computecluster sollten während dieser Szenarien für die Bereitstellung verwendet werden. Diese Pipelines sollten in Data Factory orchestriert und ausgeführt werden.
Ermitteln der richtigen Computeressourcen
Bevor Sie ein Modell in Azure Machine Learning für eine AKS bereitstellen, muss der Benutzer die Ressourcen wie CPU, RAM und GPU angeben, die für das jeweilige Modell zugewiesen werden sollen. Das Definieren dieser Parameter kann ein komplexer und mühsamer Prozess sein. Sie müssen Stresstests mit verschiedenen Konfigurationen durchführen, um einen guten Satz von Parametern zu identifizieren. Sie können diesen Prozess mit der Funktion „Model Profiling“ in Azure Machine Learning vereinfachen. Dabei handelt es sich um einen langwierigen Auftrag, der verschiedene Kombinationen von Ressourcenzuweisungen testet. Es verwendet identifizierte Latenzzeiten und Round-Trip-Zeiten (RTT), um eine optimale Kombination zu empfehlen. Diese Informationen können die tatsächliche Modellbereitstellung auf AKS unterstützen.
Um Modelle in Azure Machine Learning sicher zu aktualisieren, sollten Teams die kontrollierte Rollout-Funktion (Vorschau) verwenden, um Ausfallzeiten zu minimieren und den REST-Endpunkt des Modells konsistent zu halten.
Bewährte Methoden und der Workflow für MLOps
Beispielcode in Data Science-Repositorys einschließen
Sie können Data Science-Projekte vereinfachen und beschleunigen, wenn Ihre Teams bestimmte Artefakte und bewährte Methoden haben. Es wird empfohlen, Artefakte zu erstellen, die alle Data Science-Teams während der Arbeit mit Azure Machine Learning und den jeweiligen Tools der Datenproduktumgebung verwenden können. Daten- und Machine Learning-Techniker sollten die Artefakte erstellen und bereitstellen.
Diese Artefakte sollten Folgendes umfassen:
Beispielnotizbücher, die zeigen, wie:
- Laden, Einbinden und Arbeiten mit Datenprodukten.
- Metriken und Parameter protokolliert.
- Trainingsaufträge an Computecluster übermittelt.
Artefakte, die für die Operationalisierung erforderlich sind:
- Beispiel für Azure Machine Learning-Pipelines
- Beispiel für Azure-Pipelines
- Weitere Skripts, die zum Ausführen von Pipelines erforderlich sind
Dokumentation
Verwenden von gut gestalteten Artefakten zum Operationalisieren von Pipelines
Artefakte können die Explorations- und Operationalisierungsphasen von Data Science-Projekten beschleunigen. Eine DevOps-Forkingstrategie kann dazu beitragen, diese Artefakte für alle Projekte zu skalieren. Da dieses Setup die Verwendung von Git fördert, können Benutzer und der gesamte Automatisierungsprozess von den bereitgestellten Artefakten profitieren.
Tipp
Azure Machine Learning-Beispielpipelinen sollten mit dem Python Software Developer Kit (SDK) oder basierend auf der YAML-Sprache erstellt werden. Die neue YAML-Oberfläche wird zukunftssicherer sein, da das Azure Machine Learning-Produktteam derzeit an einer neuen SDK- und Befehlszeilenschnittstelle (CLI) arbeitet. Das Azure Machine Learning-Produktteam ist zuversichtlich, dass YAML als Definitionssprache für alle Artefakte in Azure Machine Learning dient.
Beispielpipelines funktionieren für jedes Projekt nicht sofort, können aber als Basisplan verwendet werden. Sie können Beispielpipelines für Projekte anpassen. Eine Pipeline sollte die relevantesten Aspekte jedes Projekts enthalten. Beispielsweise kann eine Pipeline auf ein Computeziel verweisen, Datenprodukte referenzieren, Parameter definieren, Eingaben definieren und die Ausführungsschritte definieren. Derselbe Vorgang sollte für Azure-Pipelines erfolgen. Azure Pipelines sollte auch das Azure Machine Learning SDK oder CLI verwenden.
Pipelines sollten veranschaulichen, wie man:
- Stellen Sie innerhalb einer DevOps-Pipeline eine Verbindung zu einem Arbeitsbereich her.
- Überprüfen Sie, ob die erforderliche Berechnung verfügbar ist.
- Einen Auftrag übermittelt.
- Registrieren Sie und stellen Sie ein Modell bereit.
Artefakte sind nicht für alle Projekte immer geeignet und erfordern möglicherweise Anpassungen, aber eine Grundlage kann die Operationalisierung und Bereitstellung eines Projekts beschleunigen.
Struktur des MLOps-Repositorys
Möglicherweise haben Sie Situationen, in denen Benutzer den Überblick verlieren, wo sie Artefakte finden und speichern können. Um diese Situationen zu vermeiden, sollten Sie mehr Zeit für die Kommunikation anfordern und eine Ordnerstruktur auf oberster Ebene für das Standardrepository erstellen. Alle Projekte sollten der Ordnerstruktur folgen.
Hinweis
Die in diesem Abschnitt genannten Konzepte können in lokalen Umgebungen, sowie in Amazon Web Services, Palantir und Azure-Umgebungen verwendet werden.
Die vorgeschlagene Ordnerstruktur auf oberster Ebene für ein MLOps-Repository (Machine Learning Operations) wird im folgenden Diagramm veranschaulicht:
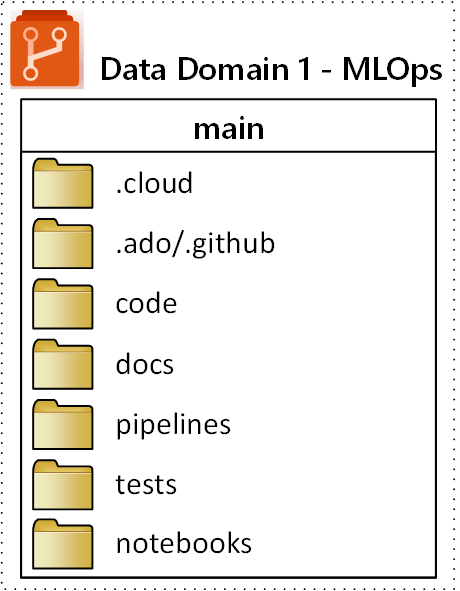
Die folgenden Zwecke gelten für jeden Ordner im Repository:
| Ordner | Zweck |
|---|---|
.cloud |
Speichern Sie cloudspezifischen Code und Artefakte in diesem Ordner. Zu den Artefakten gehören Konfigurationsdateien für den Azure Machine Learning-Arbeitsbereich, einschließlich Computezieldefinitionen, Aufträge, registrierte Modelle und Endpunkte. |
.ado/.github |
Speichern Sie Azure DevOps- oder GitHub-Artefakte wie YAML-Pipelines oder Codebesitzer in diesem Ordner. |
code |
Fügen Sie den tatsächlichen Code ein, der als Teil des Projekts in diesem Ordner entwickelt wurde. Dieser Ordner kann Python-Pakete und einige Skripts enthalten, die für die jeweiligen Schritte der Machine Learning-Pipeline verwendet werden. Es wird empfohlen, einzelne Schritte zu trennen, die in diesem Ordner ausgeführt werden müssen. Allgemeine Schritte sind Vorverarbeitung, Modellschulungund Modellregistrierung. Definieren Sie Abhängigkeiten wie Conda-Abhängigkeiten, Docker-Images oder andere für jeden Ordner. |
docs |
Verwenden Sie diesen Ordner zu Dokumentationszwecken. In diesem Ordner werden Markdown-Dateien und Bilder gespeichert, um das Projekt zu beschreiben. |
pipelines |
Speichern Sie Azure Machine Learning-Pipelinesdefinitionen in YAML oder Python in diesem Ordner. |
tests |
Schreiben Sie Komponenten- und Integrationstests, die ausgeführt werden müssen, um Fehler und Probleme frühzeitig während des Projekts in diesem Ordner zu ermitteln. |
notebooks |
Trennen Sie Jupyter-Notizbücher vom tatsächlichen Python-Projekt mit diesem Ordner. Innerhalb des Ordners sollte jede Person über einen Unterordner verfügen, um ihre Notebooks einzuchecken und Git-Merge-Konflikte zu verhindern. |