Schnellstart: Conversational Language Understanding
Verwenden Sie diesen Artikel, um mithilfe von Language Studio und der REST-API mit Conversational Language Understanding zu beginnen. Führen Sie diese Schritte aus, um ein Beispiel auszuprobieren.
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
Anmelden bei Language Studio
Wechseln Sie zu Language Studio, und melden Sie sich mit Ihrem Azure-Konto an.
Suchen Sie im angezeigten Fenster Sprachressource auswählen nach Ihrem Azure-Abonnement, und wählen Sie Ihre Sprachressource aus. Wenn keine Ressource vorhanden ist, können Sie eine neue erstellen.
Instanzdetails Erforderlicher Wert Azure-Abonnement Ihr Azure-Abonnement. Azure-Ressourcengruppe Der Name Ihrer Azure-Ressourcengruppe. Name der Azure-Ressource Der Name Ihrer Azure-Ressource. Standort Eine der unterstützten Regionen für Ihre Sprachressource. Beispiel: „USA, Westen 2“ Tarif Einer der gültigen Tarife für Ihre Sprachressource. Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst auszuprobieren. 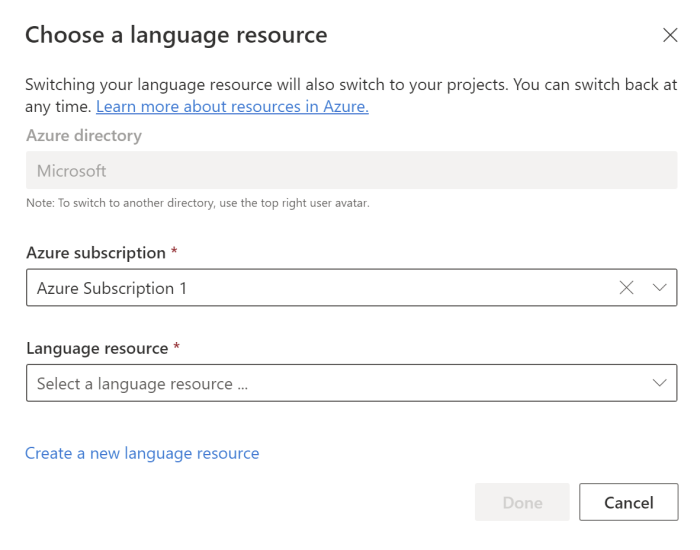

Erstellen eines Conversational Language Understanding-Projekts
Nachdem Sie eine Sprachressource ausgewählt haben, erstellen Sie ein Conversational Language Understanding-Projekt. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Für die Zwecke dieser Schnellstartanleitung können Sie dieses Beispielprojekt herunterladen und importieren. Dieses Projekt kann die beabsichtigten Befehle aus der Benutzereingabe vorhersagen, z. B. E-Mails lesen, E-Mails löschen und ein Dokument an eine E-Mail anfügen.
Suchen Sie in Language Studio den Abschnitt Understand questions and conversational language (Fragen und Unterhaltungssprache verstehen), und wählen Sie Conversational Language Understanding (Language Understanding für Unterhaltungen) aus.
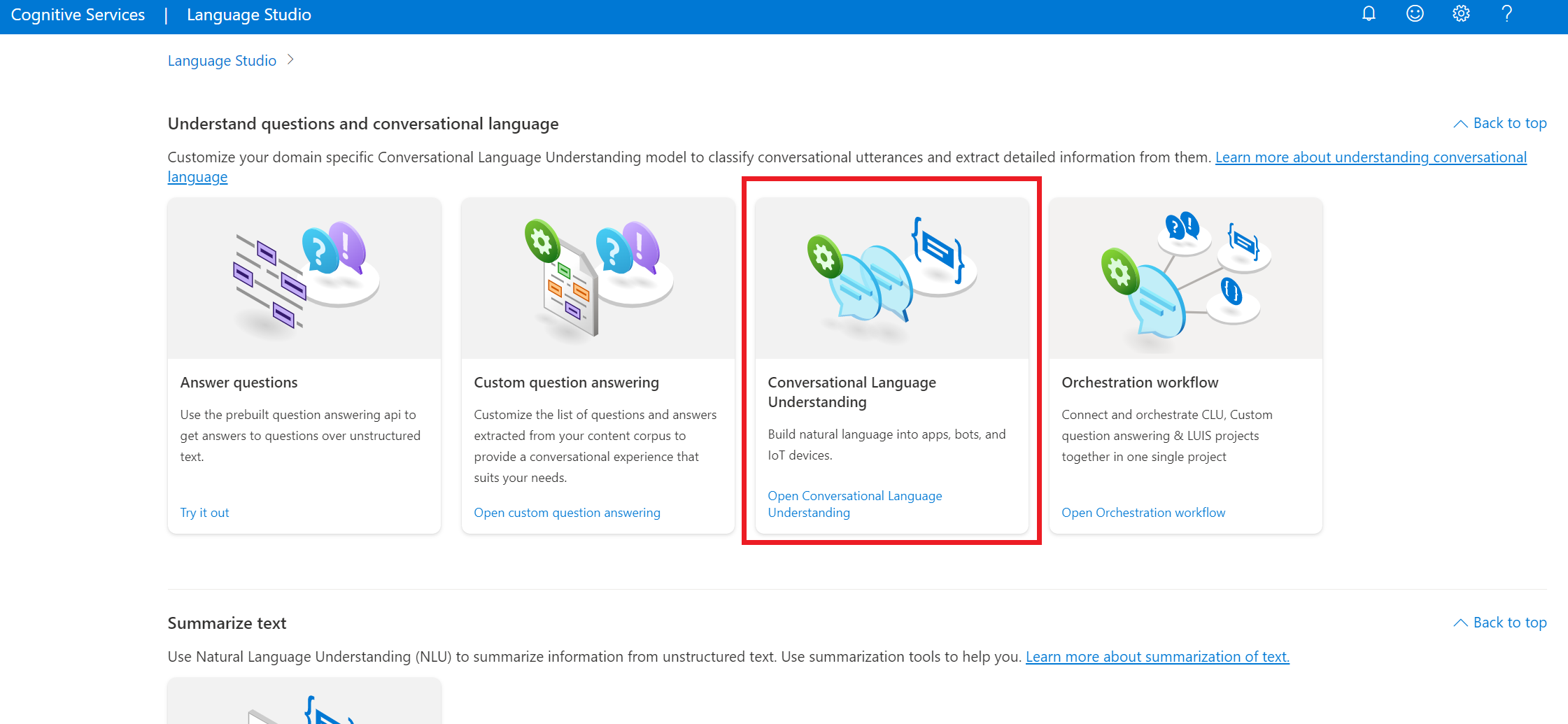
Dadurch gelangen Sie zur Seite Conversational Language Understanding-Projekte. Wählen Sie neben der Schaltfläche Neues Projekt erstellen die Option Importieren aus.
Laden Sie im angezeigten Fenster die JSON-Datei hoch, die Sie importieren möchten. Vergewissern Sie sich, dass Ihre Datei dem unterstützten JSON-Format entspricht.


Sobald der Upload abgeschlossen ist, landen Sie auf der Seite Schemadefinition. Für diese Schnellstartanleitung wurde das Schema bereits erstellt, und die Ausdrücke wurden bereits mit Absichten und Entitäten bezeichnet.
Trainieren Ihres Modells
Normalerweise sollten Sie nach dem Erstellen eines Projekts ein Schema erstellen und Äußerungen mit Bezeichnungen versehen. Für diese Schnellstartanleitung haben wir bereits ein fertiges Projekt mit erstelltem Schema und bezeichneten Äußerungen importiert.
Um ein Modell zu trainieren, müssen Sie einen Trainingsauftrag starten. Die Ausgabe eines erfolgreichen Trainingsauftrags ist Ihr trainiertes Modell.
So beginnen Sie das Training Ihres Modells über Language Studio:
Wählen Sie im Menü auf der linken Seite Modell testen aus.
Wählen Sie im oberen Menü Trainingsauftrag starten aus.
Wählen Sie Neues Modell trainieren aus, und geben Sie im Textfeld einen neuen Modellnamen ein. Um andernfalls ein vorhandenes Modell durch ein Modell zu ersetzen, das mit den neuen Daten trainiert wurde, wählen Sie Ein vorhandenes Modell überschreiben und dann ein vorhandenes Modell aus. Das Überschreiben eines trainierten Modells kann nicht rückgängig gemacht werden, wirkt sich jedoch erst auf Ihre bereitgestellten Modelle aus, wenn Sie das neue Modell bereitstellen.
Wählen Sie den Trainingsmodus aus. Sie können Standardtraining für schnelleres Training auswählen, dies ist aber nur für Englisch verfügbar. Alternativ können Sie Erweitertes Training auswählen, das für andere Sprachen und mehrsprachige Projekte unterstützt wird, dies bringt aber eine längere Trainingsdauer mit sich. Erfahren Sie mehr über Trainingsmodi.
Wählen Sie eine Methode zur Datenaufteilung aus. Sie können Automatically splitting the testing set from training data (Automatisches Abspalten des Testdatasets aus den Trainingsdaten) auswählen. Dabei teilt das System Ihre Äußerungen gemäß den angegebenen Prozentsätzen zwischen den Trainings- und Testdatasets auf. Alternativ können Sie Manuelle Aufteilung von Trainings- und Testdaten verwenden nutzen. Diese Option ist nur aktiviert, wenn Sie Ihrem Testdatensatz Äußerungen während des Bezeichnens von Äußerungen hinzugefügt haben.
Wählen Sie die Schaltfläche Train (Trainieren) aus.
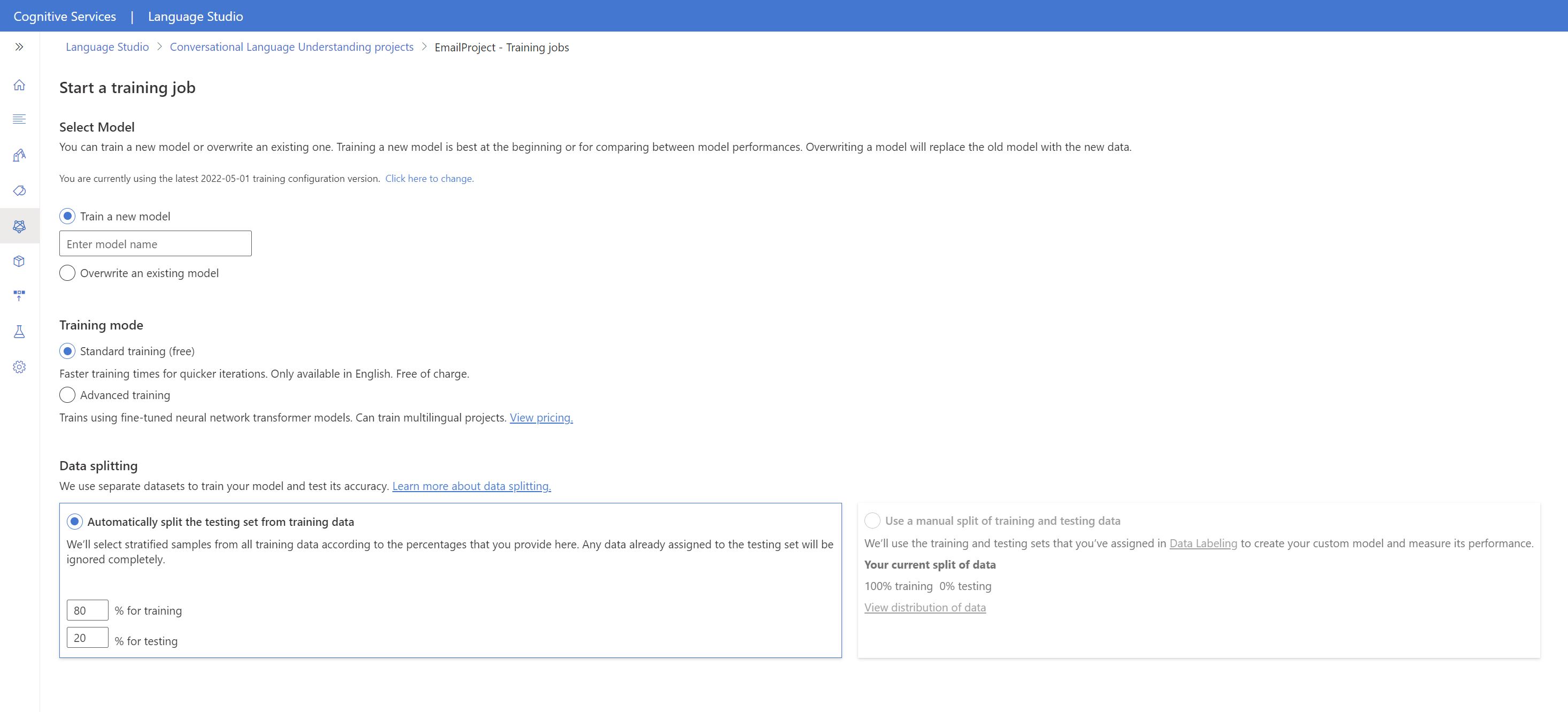
Wählen Sie in der Liste die ID des Trainingsauftrags aus. Ein Bereich wird angezeigt, in dem Sie den Trainingsfortschritt, den Auftragsstatus und andere Details für diesen Auftrag überprüfen können.
Hinweis
- Nur erfolgreich abgeschlossene Trainingsaufträge generieren Modelle.
- Je nach Anzahl der Äußerungen kann das Training wenige Minuten oder mehrere Stunden dauern.
- Es kann jeweils nur ein Trainingsauftrag ausgeführt werden. Sie können keinen anderen Trainingsauftrag innerhalb desselben Projekts starten, bis der laufende Auftrag abgeschlossen ist.
- Das maschinelle Lernen, das zum Trainieren von Modellen verwendet wird, wird regelmäßig aktualisiert. Um mit einer früheren Konfigurationsversion zu trainieren, wählen Sie die Option Hier zum ändern auswählen auf der Seite Trainingsauftrag starten aus und wählen Sie eine frühere Version aus.

Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren, oder Sie können die Vorhersage-API aufrufen.
So stellen Sie Ihr Modell über Language Studio bereit:
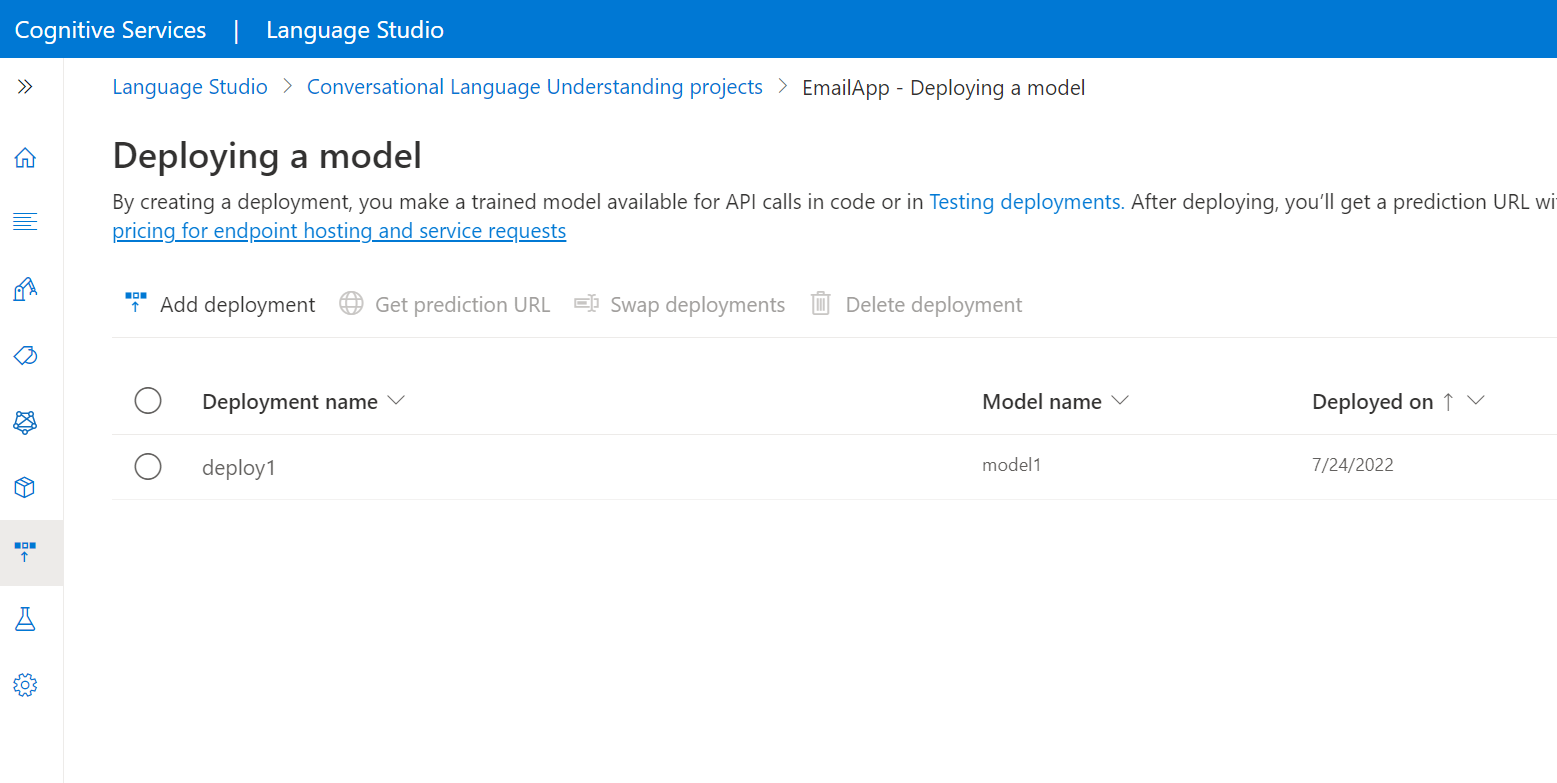
Wählen Sie im Menü auf der linken Seite Bereitstellen eines Modells aus.
Wählen Sie Bereitstellung hinzufügen aus, um den Assistenten zum Hinzufügen einer Bereitstellung zu starten.
Wählen Sie Neuen Bereitstellungsnamen erstellen aus, um eine neue Bereitstellung zu erstellen und ein trainiertes Modell aus der Dropdownliste unten zuzuweisen. Andernfalls können Sie einen vorhandenen Bereitstellungsnamen überschreiben auswählen, um effektiv das Modell zu ersetzen, das von einer vorhandenen Bereitstellung verwendet wird.
Hinweis
Das Überschreiben einer vorhandenen Bereitstellung erfordert keine Änderungen an Ihrem Aufruf der Vorhersage-API, aber die Ergebnisse, die Sie erhalten, basieren auf dem neu zugewiesenen Modell.
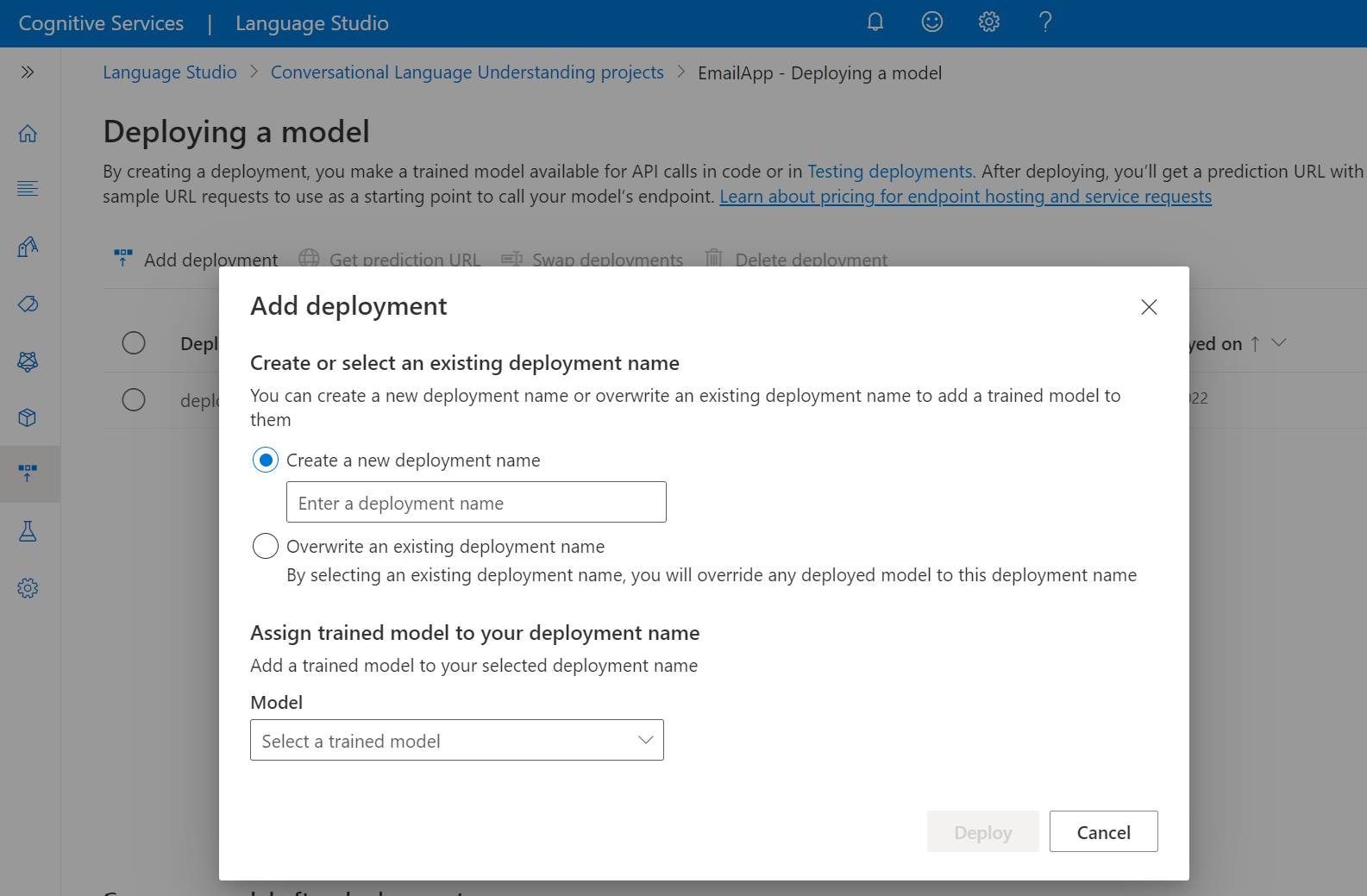
Wählen Sie in der Dropdownliste Modell ein trainiertes Modell aus.
Wählen Sie Bereitstellen aus, um die Bereitstellungsauftrag zu starten.
Nachdem die Bereitstellung ausgeführt wurde, wird ein Ablaufdatum neben dem Vorgang angezeigt. Der Bereitstellungsablauf ist dann, wenn Ihr bereitgestelltes Modell für die Vorhersage nicht verfügbar ist, was in der Regel zwölf Monate nach Ablauf einer Schulungskonfiguration der Fall ist.


Testen des bereitgestellten Modells
So testen Sie Ihre bereitgestellten Modelle über Language Studio
Wählen Sie Testbereitstellungen aus dem Menü auf der linken Seite aus.
Wählen Sie für mehrsprachige Projekte die Sprache der Äußerung, die Sie testen möchten, über das Dropdownmenü Textsprache auswählen aus.
Wählen Sie in der Dropdownliste Bereitstellungsname den Bereitstellungsnamen aus, der dem Modell entspricht, das Sie testen möchten. Sie können nur Modelle testen, die Bereitstellungen zugewiesen sind.
Geben Sie im Textfeld eine Äußerung ein, die getestet werden soll. Wenn Sie beispielsweise eine Anwendung für E-Mail-bezogene Äußerungen erstellt haben, könnten Sie Diese E-Mail löschen eingeben.
Wählen Sie oben auf der Seite Test ausführen aus.
Nach dem Ausführen des Tests sollten Sie die Antwort des Modells im Ergebnis sehen. Sie können die Ergebnisse in der Kartenansicht der Entitäten oder im JSON-Format anzeigen.
Bereinigen von Ressourcen
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie das Projekt mithilfe von Language Studio löschen. Wählen Sie im linken Navigationsmenü Projekte und das zu löschende Projekt aus und dann im oberen Menü Löschen.
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
Erstellen einer neuen Ressource im Azure-Portal
Melden Sie sich beim Azure-Portal an, um eine neue Azure KI Language-Ressource zu erstellen.
Wählen Sie Neue Ressource erstellen aus.
Suchen Sie im angezeigten Fenster nach Sprachdienst.
Klicken Sie auf Erstellen
Erstellen Sie eine Sprachressource mit den folgenden Details:
Instanzdetails Erforderlicher Wert Region Eine der unterstützten Regionen für Ihre Sprachressource. Name Erforderlicher Name für Ihre Language-Ressource Tarif Einer der unterstützten Tarife für Ihre Language-Ressource.
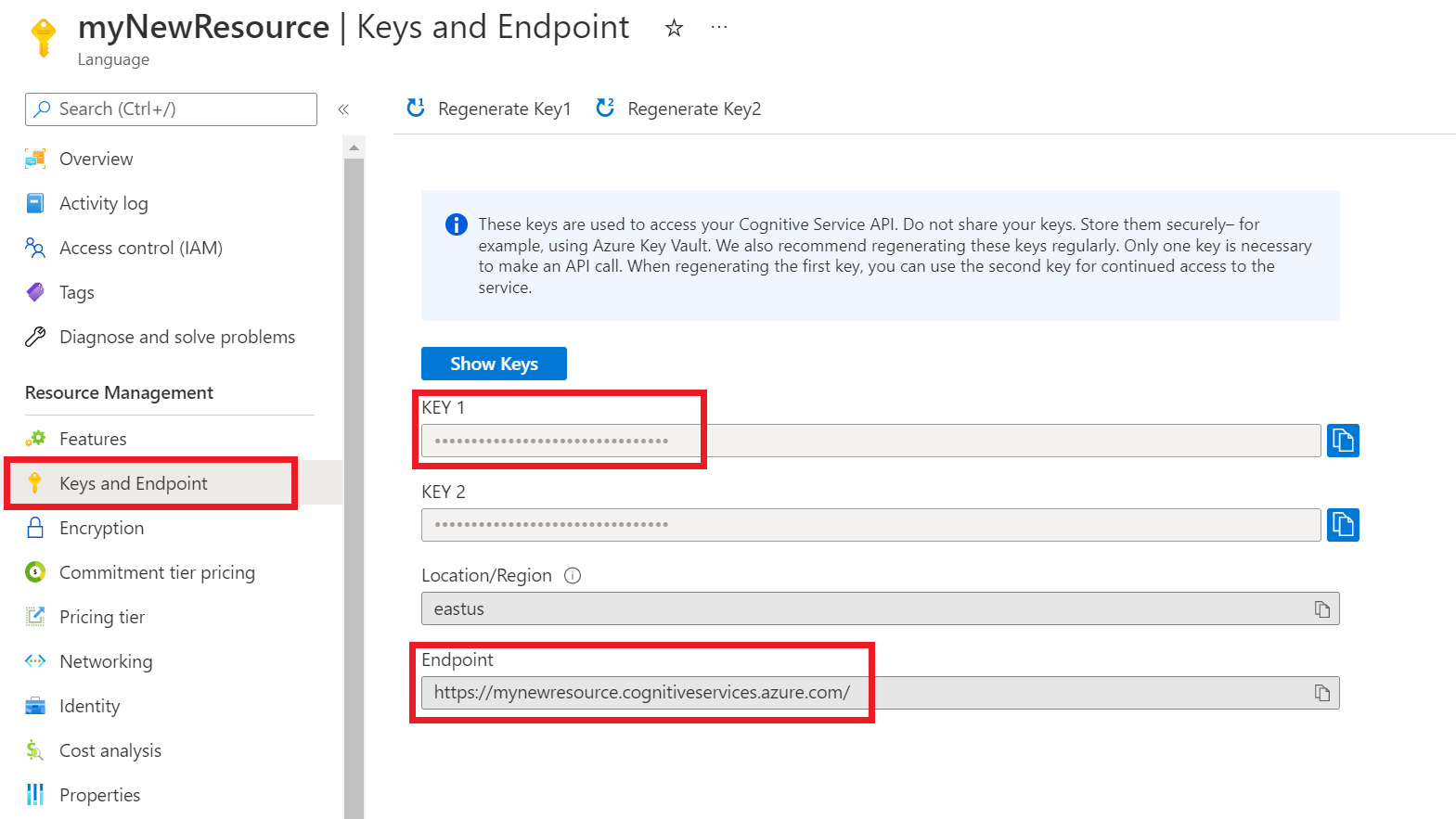
Abrufen Ihrer Ressourcenschlüssel und Endpunkte
Navigieren Sie im Azure-Portal zur Übersichtsseite Ihrer Ressource.
Wählen Sie im Menü auf der linken Seite Schlüssel und Endpunkt aus. Sie verwenden den Endpunkt und Schlüssel für die API-Anforderungen.

Importieren eines neuen CLU-Beispielprojekts
Nachdem Sie eine Sprachressource erstellt haben, erstellen Sie ein Conversational Language Understanding-Projekt. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Für die Zwecke dieser Schnellstartanleitung können Sie dieses Beispielprojekt herunterladen und es importieren. Dieses Projekt kann die beabsichtigten Befehle aus der Benutzereingabe vorhersagen, z. B. E-Mails lesen, E-Mails löschen und ein Dokument an eine E-Mail anfügen.
Auslösen des Importprojektauftrags
Übermitteln Sie eine POST-Anforderung mit den folgenden Angaben für URL, Header und JSON-Text, um Ihr Projekt zu importieren.
Anfrage-URL
Verwenden Sie zum Erstellen Ihrer API-Anforderung die folgende URL. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet, und er muss mit dem Projektnamen in der JSON-Datei übereinstimmen, die Sie importieren. | EmailAppDemo |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Body
Der JSON-Text, den Sie senden, ähnelt dem folgenden Beispiel. Weitere Informationen zum JSON-Objekt finden Sie in der Referenzdokumentation.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | EmailAppDemo |
language |
{LANGUAGE-CODE} |
Hierbei handelt es sich um eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendete Äußerung angibt. Wählen Sie bei einem mehrsprachigen Projekt den Sprachcode aus, der für die Mehrheit der Äußerungen verwendet wird. | en-us |
multilingual |
true |
Ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen, einschließlich Sprachen, die nicht in Ihren Trainingsdokumenten enthalten sind. | true |
dataset |
{DATASET} |
Informationen über die Aufteilung Ihrer Daten in einen Test- und einen Trainingssatz finden Sie unter Trainieren eines Modells. Mögliche Werte für dieses Feld sind Train und Test. |
Train |
Nach einer erfolgreichen Anforderung enthält die API-Antwort einen operation-location-Header mit einer URL, mit der Sie den Status des Importauftrags überprüfen können. Sie hat folgendes Format:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
Abrufen des Importauftragsstatus
Wenn Sie eine erfolgreiche Projektimportanforderung senden, ist die vollständige Anforderungs-URL zum Überprüfen des Importauftragsstatus (einschließlich Endpunkt, Projektname und Auftrags-ID) im operation-location-Header der Antwort enthalten.
Verwenden Sie die folgende GET-Anforderung, um den Status Ihres Importauftrags abzufragen. Sie können die URL verwenden, die Sie im vorherigen Schritt erhalten haben, oder die Platzhalterwerte durch Ihre eigenen Werte ersetzen.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Suchen Ihres Importauftragsstatus. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | BESCHREIBUNG | Wert |
|---|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. | {YOUR-PRIMARY-RESOURCE-KEY} |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt.
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
Beginnen mit dem Trainieren Ihres Modells
Normalerweise sollten Sie nach dem Erstellen eines Projekts ein Schema erstellen und Äußerungen kennzeichnen. Für diese Schnellstartanleitung haben wir bereits ein fertiges Projekt mit erstelltem Schema und gekennzeichneten Äußerungen importiert.
Erstellen Sie eine POST-Anforderung mit den folgenden Angaben für URL, Header und JSON-Text, um einen Trainingsauftrag zu übermitteln.
Anfrage-URL
Verwenden Sie zum Erstellen Ihrer API-Anforderung die folgende URL. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | EmailApp |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie das folgende Objekt in Ihrer Anforderung. Das Modell wird nach dem Wert benannt, den Sie für den modelLabel-Parameter verwenden, sobald das Training abgeschlossen ist.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Ihr Modellname. | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
Die Modellversion der Trainingskonfiguration. Standardmäßig wird die neueste Modellversion verwendet. | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
Der Trainingsmodus, der für das Training verwendet werden soll. Unterstützt werden die Modi Standardtraining, schnelleres Training, aber nur für Englisch verfügbar, und Fortgeschrittenes Training, das für andere Sprachen und mehrsprachige Projekte unterstützt wird, aber längere Trainingszeiten umfasst. Erfahren Sie mehr über Trainingsmodi. | standard |
kind |
percentage |
Aufteilungsmethoden Mögliche Werte sind percentage oder manual. Weitere Informationen finden Sie unter Trainieren eines Modells. |
percentage |
trainingSplitPercentage |
80 |
Prozentsatz der markierten Daten, die in den Trainingssatz einbezogen werden sollen. Der empfohlene Wert ist 80. |
80 |
testingSplitPercentage |
20 |
Prozentsatz der markierten Daten, die in den Testsatz einbezogen werden sollen. Der empfohlene Wert ist 20. |
20 |
Hinweis
trainingSplitPercentage und testingSplitPercentage sind nur erforderlich, wenn Kind auf percentage festgelegt ist, und die Summe beider Prozentsätze sollte 100 ergeben.
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202-Antwort, die angibt, dass sie erfolgreich war. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Sie können diese URL verwenden, um den Status des Trainingsauftrags abzurufen.
Abrufen des Trainingsauftragsstatus
Die Durchführung des Trainings kann einige Zeit in Anspruch nehmen – manchmal zwischen 10 und 30 Minuten. Sie können die folgende Anforderung verwenden, um den Status des Trainingsauftrags bis zum erfolgreichen Abschluss abzufragen.
Wenn Sie eine erfolgreiche Trainingsanforderung senden, ist die vollständige Anforderungs-URL zum Überprüfen des Auftragsstatus (einschließlich Endpunkt, Projektname und Auftrags-ID) im operation-location-Header der Antwort enthalten.
Verwenden Sie die folgende GET-Anforderung, um den Trainingsstatus Ihres Modells abzufragen. Ersetzen Sie die folgenden Platzhalter durch Ihre eigenen Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{YOUR-ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | EmailApp |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt.
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Schlüssel | Wert | Beispiel |
|---|---|---|
modelLabel |
Den Modellnamen | Model1 |
trainingConfigVersion |
Die Version der Trainingskonfiguration. Standardmäßig wird die neueste Version verwendet. | 2022-05-01 |
trainingMode |
Ihr ausgewählter Trainingsmodus. | standard |
startDateTime |
Die Zeitschulung wurde gestartet | 2022-04-14T10:23:04.2598544Z |
status |
Der Status des Trainingsauftrags. | running |
estimatedEndDateTime |
Geschätzter Abschlusszeitpunkt des Trainingsauftrags. | 2022-04-14T10:29:38.2598544Z |
jobId |
Ihre Trainingsauftrags-ID. | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Datum und Uhrzeit der Erstellung des Trainingsauftrags. | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Datum und Uhrzeit der letzten Aktualisierung des Trainingsauftrags. | 2022-04-14T10:23:45Z |
expirationDateTime |
Ablaufdatum und Uhrzeit des Trainingsauftrags | 2022-04-14T10:22:42Z |
Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails. In diesem Schnellstart stellen Sie ihr Modell einfach bereit und rufen die Vorhersage-API auf, um die Ergebnisse abzufragen.
Übermitteln des Bereitstellungsauftrags
Erstellen Sie eine PUT-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um mit der Bereitstellung eines CLU-Modells zu beginnen.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name für Ihre Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Der Modellname, der Ihrer Bereitstellung zugewiesen wird. Sie können nur Modelle zuweisen, für die das Training erfolgreich war. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myModel |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202-Antwort, die angibt, dass sie erfolgreich war. Extrahieren Sie in den Antwortheadern den operation-location-Wert. Er weist das folgende Format auf:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Sie können diese URL verwenden, um den Status des Bereitstellungsauftrags abzurufen.
Abrufen des Auftragsstatus der Bereitstellung
Wenn Sie eine erfolgreiche Bereitstellungsanforderung senden, ist die vollständige Anforderungs-URL zum Überprüfen des Auftragsstatus (einschließlich Endpunkt, Projektname und Auftrags-ID) im operation-location-Header der Antwort enthalten.
Verwenden Sie die folgende GET-Anforderung, um den Status Ihres Bereitstellungsauftrags abzurufen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name für Ihre Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Abfragemodell
Nachdem Ihr Modell bereitgestellt wurde, können Sie es verwenden, um Vorhersagen mithilfe der Vorhersage-API zu treffen.
Sobald die Bereitstellung erfolgreich war, können Sie Ihr bereitgestelltes Modell nach Vorhersagen abfragen.
Erstellen Sie mithilfe der folgenden URL, der Header und des JSON-Texts eine POST-Anforderung, um mit dem Testen eines Conversational Language Understanding-Modells zu beginnen.
Anfrage-URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
Die Äußerung, deren Absicht Sie voraussagen und deren Entitäten Sie extrahieren möchten. | "Read Matt's email |
projectName |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
Nachdem Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort für die Vorhersage:
Antworttext
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| Schlüssel | Beispielwert | BESCHREIBUNG |
|---|---|---|
| Abfrage | „Matts E-Mail lesen“ | Der Text, den Sie für die Abfrage übermittelt haben. |
| topIntent | „Lesen“ | Die vorhergesagte Absicht mit höchster Konfidenzbewertung. |
| Absichten | [] | Eine Liste aller Absichten, die für den Abfragetext vorhergesagt wurden, jede von ihnen mit einer Konfidenzbewertung. |
| entities | [] | Array mit der Liste der extrahierten Entitäten aus dem Abfragetext. |
API-Antwort für ein Konversationsprojekt
In einem Konversationsprojekt erhalten Sie Vorhersagen für Ihre Absichten und Entitäten, die in Ihrem Projekt vorhanden sind.
- Die Absichten und Entitäten enthalten eine Zuverlässigkeitsbewertung zwischen 0,0 und 1,0, die damit verbunden ist, wie sicher das Modell ist, ein bestimmtes Element in Ihrem Projekt vorhersagen zu können.
- Die Absicht mit der höchsten Bewertung ist in ihrem eigenen Parameter enthalten.
- In Ihrer Antwort werden nur vorhergesagte Entitäten angezeigt.
- Entitäten geben Folgendes an:
- Den Text der Entität, die extrahiert wurde
- Die Startposition, die durch einen Offsetwert gekennzeichnet ist
- Die Länge des Entitätstexts, der durch einen Längenwert bezeichnet wird
Bereinigen von Ressourcen
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie das Projekt mithilfe von APIs löschen.
Erstellen Sie mithilfe der folgenden URL, der Header und des JSON-Texts eine LÖSCH-Anforderung, um mit dem Löschen eines CLU-Projekts zu beginnen.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Dies ist die Version der von Ihnen aufgerufenen API. | 2023-04-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine Antwort vom Typ 202, die anzeigt, dass Ihr Projekt erfolgreich gelöscht wurde.