Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verteilte Datenbanken, die sich auf Replikation für hohe Verfügbarkeit, niedrige Latenz oder beides verlassen, müssen Lesekonsistenz, Verfügbarkeit, Latenz und Durchsatz gemäß Definition des PACELC-Satzes ausgleichen. Die Linearisierbarkeit des starken Konsistenzmodells ist der Standard für die Datenprogrammierbarkeit. Die Schreibverzögerungen werden jedoch erhöht, da Daten über große Entfernungen replizieren und bestätigen müssen. Eine starke Konsistenz reduziert auch die Verfügbarkeit bei Fehlern, da Daten in jeder Region nicht replizieren und übernehmen können. Die spätere Konsistenz bietet eine höhere Verfügbarkeit und eine bessere Leistung, aber es ist schwieriger, Anwendungen zu programmieren, da Daten möglicherweise nicht in allen Regionen konsistent sind.
Die meisten verteilten NoSQL-Datenbanken auf dem Markt bieten heute nur eine starke und letztendliche Konsistenz. Azure Cosmos DB bietet fünf klar definierte Ebenen. Diese sind (von der stärksten bis zur schwächsten Ebene):
Weitere Informationen zur Standardkonsistenzebene finden Sie unter Konfigurieren der Standardkonsistenzebene oder unter Außerkraftsetzen der Standardkonsistenzebene.
Jede Stufe gleicht Verfügbarkeit und Leistung ab. Die folgende Abbildung zeigt die Konsistenzstufen als Spektrum.
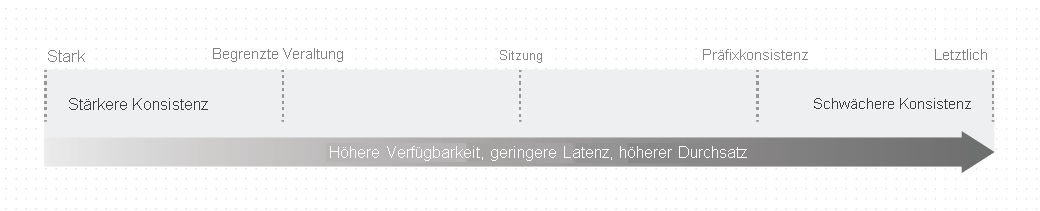
Konsistenzebenen und Azure Cosmos DB-APIs
Azure Cosmos DB unterstützt drahtprotokollkompatible APIs für beliebte Datenbanken, darunter MongoDB, Apache Cassandra, Apache Gremlin und Azure Table Storage. Für die API für Gremlin oder Table verwendet Azure Cosmos DB die auf dem Konto konfigurierte Standardkonsistenzstufe. Informationen zur Zuordnung von Konsistenzebenen finden Sie unter API für Cassandra-Konsistenzzuordnung bei Apache Cassandra und API für MongoDB-Konsistenzzuordnung bei MongoDB.
Umfang der Lesekonsistenz
Die Lesekonsistenz gilt für einen einzelnen Lesevorgang innerhalb einer logischen Partition. Ein Remoteclient, eine gespeicherte Prozedur oder ein Trigger kann den Lesevorgang ausgeben.
Konfigurieren der Standardkonsistenzebene
Konfigurieren Sie die Standardkonsistenzstufe für Ihr Azure Cosmos DB-Konto jederzeit. Die für Ihr Konto konfigurierte Standardkonsistenzebene gilt für alle Azure Cosmos DB-Datenbanken und -Container in diesem Konto. Bei allen in einem Container oder einer Datenbank ausgeführten Lesevorgängen und Abfragen wird standardmäßig die angegebene Konsistenzebene verwendet. Wenn Sie ihre Konsistenz auf Kontoebene ändern, stellen Sie Ihre Anwendungen erneut bereit, und nehmen Sie alle erforderlichen Codeänderungen vor, um diese Änderungen anzuwenden. Erfahren Sie mehr darüber, wie Sie die Standardkonsistenzstufe konfigurieren. Sie können auch die Standardkonsistenzstufe für eine bestimmte Anforderung außer Kraft setzen. Weitere Informationen finden Sie im Artikel über das Überschreiben der Standardkonsistenzstufe.
Tip
Das Überschreiben der Standardkonsistenzstufe gilt nur für Lesevorgänge im SDK-Client. Ein Konto, das standardmäßig für starke Konsistenz konfiguriert ist, schreibt und repliziert Daten weiterhin synchron in jede Region im Konto. Wenn die SDK-Clientinstanz oder -Anforderung diese Konsistenz mit Sitzungskonsistenz oder einer schwächeren Konsistenz außer Kraft setzt, werden Lesevorgänge unter Verwendung eines einzelnen Replikats ausgeführt. Weitere Informationen finden Sie unter Konsistenzstufen und Durchsatz.
Important
Erstellen Sie eine beliebige SDK-Instanz neu, nachdem Sie die Standardkonsistenzstufe geändert haben, indem Sie die Anwendung neu starten. In diesem Schritt wird sichergestellt, dass das SDK die neue Standardkonsistenzstufe verwendet.
Garantien in Zusammenhang mit Konsistenzebenen
Azure Cosmos DB garantiert, dass 100% von Leseanforderungen die Konsistenzgarantie für die gewählte Konsistenzstufe erfüllen. Die genauen Definitionen der fünf Konsistenzstufen in Azure Cosmos DB mithilfe der TLA - Temporal Logic of Actions - Spezifikationssprache werden im Azure/azure-cosmos-tla GitHub-Repo bereitgestellt.
In den folgenden Abschnitten wird die Semantik der fünf Konsistenzebenen beschrieben.
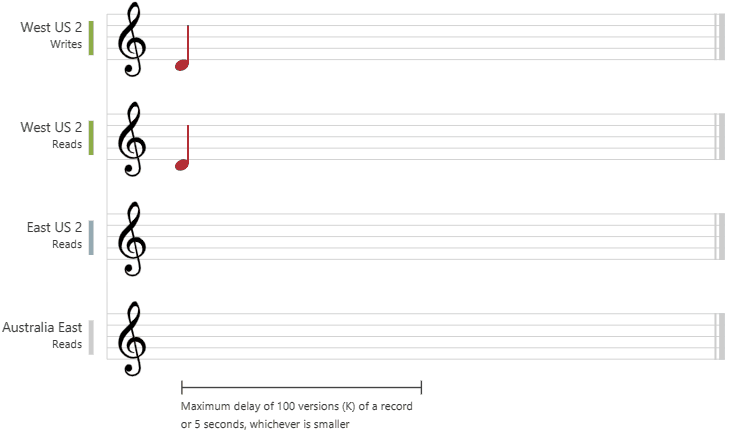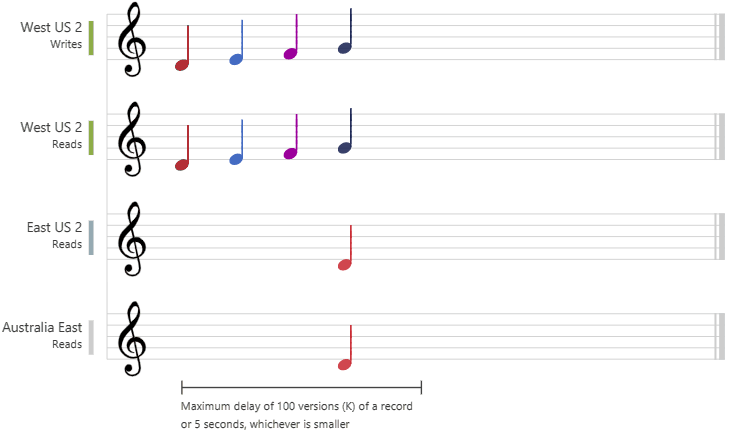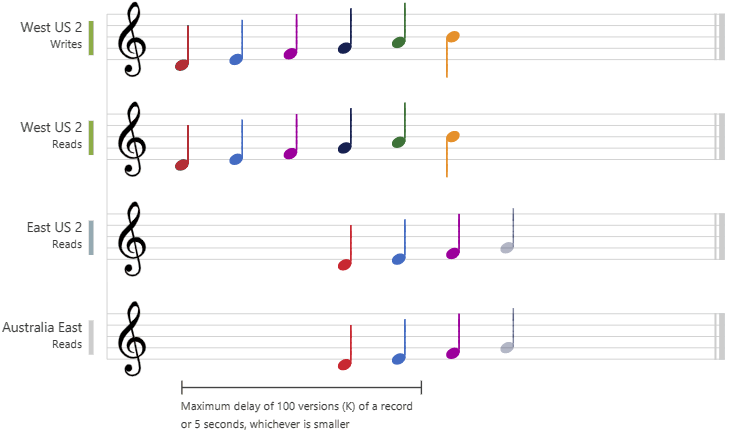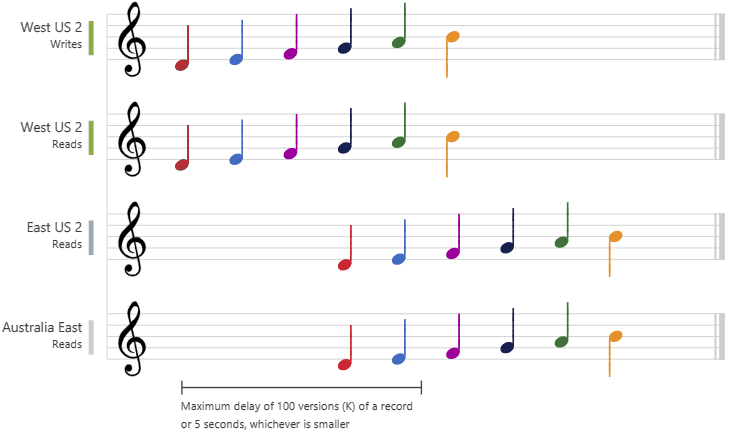
Starke Konsistenz
Starke Konsistenz bietet garantierte Linearisierbarkeit. Linearisierbarkeit bedeutet, Dass Anforderungen gleichzeitig bedient werden. Die Lesevorgänge geben garantiert die neueste festgeschriebene Version eines Elements zurück. Einem Client wird nie ein partieller Schreibvorgang bzw. ein Schreibvorgang, für den kein Commit ausgeführt wurde, angezeigt. Benutzer haben immer die Garantie, dass sie den neuesten Schreibvorgang lesen, für den ein Commit ausgeführt wurde.
Die folgende Grafik zeigt eine starke Übereinstimmung mit musikalischen Noten. Nachdem die Daten in die Region „USA, Westen 2“ geschrieben wurden, erhalten Sie beim Lesen der Daten aus anderen Regionen den neuesten Wert:

Dynamisches Quorum
Unter normalen Umständen gilt für ein Konto mit starker Konsistenz ein Schreibvorgang als zugesichert, wenn alle Regionen die Replikation des Datensatzes bestätigen. Wenn Ihr Konto über drei oder mehr Regionen verfügt, kann das System die Anzahl der Regionen verringern, die für ein Quorum erforderlich sind, wenn einige Regionen langsam oder nicht reagieren. Dies trägt dazu bei, eine starke Konsistenz zu gewährleisten, auch wenn einige Regionen Probleme haben. Zu diesem Zeitpunkt werden nicht reagierende Regionen aus dem Quorumsatz der Regionen entfernt, um eine starke Konsistenz zu gewährleisten. Sie werden nur dann wieder hinzugefügt, wenn sie mit anderen Regionen konsistent sind und wie erwartet ausgeführt werden. Die Anzahl der Regionen, die möglicherweise aus dem Quorumsatz entnommen werden können, hängt von der Gesamtzahl der Regionen ab. In einem Konto mit drei oder vier Regionen besteht die Mehrheit, je nach Fall, aus zwei oder drei Regionen, sodass nur eine Region entfernt werden kann. Bei einem Konto mit fünf Regionen ist die Mehrheit drei, sodass bis zu zwei nicht reagierende Regionen entfernt werden können. Diese Funktion wird als "dynamisches Quorum" bezeichnet und kann sowohl die Schreibverfügbarkeit als auch die Replikationslatenz für Konten mit drei oder mehr Regionen verbessern.
Note
Wenn Regionen aus dem Quorumsatz als Teil des dynamischen Quorums entfernt werden, können diese Regionen keine Lesevorgänge mehr bereitstellen, bis sie wieder dem Quorum hinzugefügt wurden.
Konsistenzebene „Begrenzte Veraltung“
Bei Einzelregion-Schreibkonten mit zwei oder mehr Regionen werden die Daten aus der primären Region auf alle sekundären (schreibgeschützten) Regionen repliziert. Bei Konten mit Schreibzugriff auf mehrere Regionen, wenn zwei oder mehr Regionen vorhanden sind, werden Daten aus der Region, in der sie ursprünglich geschrieben wurden, in alle anderen Schreibregionen repliziert. In beiden Szenarien kann es, obwohl nicht häufig, gelegentlich zu einer Replikationsverzögerung von einer Region zu einer anderen kommen.
Bei der begrenzten Veralterungskonsistenz ist die Datenverzögerung zwischen zwei beliebigen Regionen immer unter einem angegebenen Wert. Der Wert kann „K“ Versionen (Updates) eines Elements oder „T“ Zeitintervalle betragen (je nachdem, was zuerst erreicht wird). Wenn Sie also die begrenzte Veraltung auswählen, kann die maximale Veraltung der Daten in jeder Region auf zwei Arten konfiguriert werden:
- Die Anzahl der Versionen (K) des Elements
- Das Zeitintervall (T) kann hinter den Schreibvorgängen liegen.
Die begrenzte Veralterung ist in erster Linie von Vorteil für Schreibvorgänge in einer einzigen Region mit zwei oder mehr Regionen. Wenn die Datenverzögerung in einer Region (ermittelt pro physischer Partition) den konfigurierten Veraltungswert übersteigt, werden Schreibvorgänge für diese Partition gedrosselt, bis die Veraltung wieder innerhalb der konfigurierten Obergrenze liegt.
Für ein Konto mit einer einzelnen Region bietet die begrenzte Veraltung die gleichen Schreibkonsistenzgarantien wie Sitzungskonsistenz und letztliche Konsistenz. Bei Begrenzter Staleness werden Daten in einer lokalen Mehrheit der Replikate (drei von vier Replikaten) innerhalb der einzelnen Region repliziert.
Important
Bei der Konsistenzebene „Begrenzte Veraltung“ werden Veraltungsprüfungen nur regionsübergreifend und nicht innerhalb einer Region durchgeführt. Innerhalb einer bestimmten Region werden Daten unabhängig von der Konsistenzstufe immer auf eine lokale Mehrheit repliziert (drei Replikate in einer Gruppe von vier Replikaten).
Bei Verwendung der begrenzten Veraltung geben Lesevorgänge die neuesten in dieser Region verfügbaren Daten zurück, indem sie aus zwei verfügbaren Replikaten in dieser Region lesen. Da Schreibvorgänge innerhalb einer Region immer in einer lokalen Mehrheit (drei von vier Replikaten) repliziert werden, werden durch die Abfrage von zwei Replikaten die neuesten Daten zurückgegeben, die in dieser Region verfügbar sind.
Important
Bei der Konsistenz der gebundenen Stetigkeit zeigen Lesevorgänge aus einer nichtprimären Region möglicherweise nicht die aktuellsten Daten aus allen Regionen an. Sie geben jedoch immer die neuesten Daten zurück, die in dieser Region verfügbar sind, innerhalb des zulässigen Grenzwerts für veraltete Werte.
Die begrenzte Veraltung eignet sich am besten für global verteilte Anwendungen, die Konten mit Schreibzugriff auf eine einzelne Region mit zwei oder mehr Regionen verwenden und für die eine Konsistenzebene nahezu vom Typ „Stark“ zwischen Regionen gewünscht ist. Bei Konten mit Schreibzugriff auf mehrere Regionen mit zwei oder mehr Regionen sollten Anwendungsserver Lese- und Schreibvorgänge an dieselbe Region weiterleiten, in der auch die Anwendungsserver gehostet werden. Begrenzte Konsistenzverzögerung in einem Konto mit mehreren Schreibrechten ist ein Antimuster. Für diese Ebene wäre eine Abhängigkeit von der Replikationsverzögerung zwischen Regionen erforderlich, was keine Rolle spielen sollte, wenn Daten aus der gleichen Region gelesen werden, in die sie geschrieben wurden.
In der folgenden Grafik wird die Konsistenz der begrenzten Veraltung anhand von Musiknoten veranschaulicht. Nachdem die Daten in die Region „West US 2“ geschrieben wurden, wird der geschriebene Wert in den Regionen „East US 2“ und „Australia East“ basierend auf der konfigurierten maximalen Verzögerungszeit oder der maximalen Anzahl von Vorgängen gelesen.
Sitzungskonsistenz
Bei der Sitzungskonsistenz wird innerhalb einer einzelnen Clientsitzung garantiert, dass die Lesen-der-eigenen-Schreibvorgänge-Garantie und die Schreiben-folgt-Lesen-Garantie eingehalten werden. Diese Garantie setzt voraus, dass entweder eine einzelne "Writer"-Sitzung verwendet oder das Sitzungstoken zwischen mehreren Autoren geteilt wird.
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Nach jedem Schreibvorgang empfängt der Client ein aktualisiertes Sitzungstoken vom Server. Der Client zwischenspeichert die Token und sendet sie für Leseoperationen in einer angegebenen Region an den Server. Wenn das Replikat, für das der Lesevorgang ausgestellt wird, Daten für das angegebene Token (oder ein neueres Token) enthält, werden die angeforderten Daten zurückgegeben. Wenn das Replikat keine Daten für diese Sitzung enthält, wiederholt der Client die Anforderung für ein anderes Replikat in der Region. Bei Bedarf wiederholt der Client den Lesevorgang in weiteren verfügbaren Regionen, bis Daten für das angegebene Sitzungstoken abgerufen werden.
Important
In der Sitzungskonsistenz verwendet der Client ein Sitzungstoken, um sicherzustellen, dass er niemals Daten liest, die einer älteren Sitzung entsprechen. Wenn der Client ein altes Sitzungstoken verwendet, aber neuere Daten in der Datenbank verfügbar sind, gibt das System die neueste Version zurück. Auch bei einem veralteten Token erhalten Sie immer die neuesten Daten. Das Sitzungstoken wird als Mindestversionsbarriere verwendet, aber nicht als spezifische (möglicherweise historische) Version der Daten, die aus der Datenbank abgerufen werden sollen.
Sitzungstoken in Azure Cosmos DB sind partitionsgebunden, d. h. sie sind ausschließlich einer Partition zugeordnet. Um sicherzustellen, dass Sie Ihre Schreibvorgänge lesen können, verwenden Sie das Sitzungstoken, das zuletzt für die relevanten Elemente generiert wurde.
Wenn der Client keinen Schreibvorgang in einer physischen Partition initiiert hat, enthält der Cache des Clients kein Sitzungstoken, und Lesevorgänge in dieser physischen Partition verhalten sich wie Lesevorgänge mit letztlicher Konsistenz. Wenn der Client neu erstellt wird, wird auch der Sitzungstokencache neu erstellt. Auch hier verhalten sich Lesevorgänge wie bei der Eventual Consistency, bis der Cache der Sitzungstoken des Clients durch nachfolgende Schreibvorgänge neu aufgebaut wird.
Important
Wenn Sitzungstoken von einer Clientinstanz an eine andere übergeben werden, sollte der Inhalt des Tokens nicht geändert werden.
Sitzungskonsistenz ist die am häufigsten verwendete Konsistenzstufe für einzel- und global verteilte Anwendungen. Sie bietet Schreibwartezeiten, Verfügbarkeit und Lesedurchsatz, die mit der letztlichen Konsistenz vergleichbar sind. Darüber hinaus bietet Sitzungskonsistenz Konsistenzgarantien für Anwendungen, die für den Einsatz im Benutzerkontext geschrieben wurden. In der folgenden Grafik wird die Sitzungskonsistenz anhand von musikalischen Noten veranschaulicht. Für „USA, Westen 2“ (Schreiben) und „USA, Osten 2“ (Lesen) wird dieselbe Sitzung (Sitzung A) verwendet, sodass beide dieselben Daten zur selben Zeit lesen. Die Region „Australien, Osten“ dagegen verwendet „Sitzung B“ und empfängt Daten somit später, aber weiterhin in der Reihenfolge der Schreibvorgänge.

Präfixkonsistenz
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Bei einem konsistenten Präfix sind die Aktualisierungen, die als einzelne Dokumentschreibvorgänge durchgeführt werden, letztendlich konsistent.
Aktualisierungen, die als Batch innerhalb einer Transaktion vorgenommen wurden, werden in der Transaktion, in der sie festgeschrieben wurden, konsistent zurückgegeben. Schreibvorgänge innerhalb einer Transaktion mehrerer Dokumente sind immer zusammen sichtbar.
Angenommen, zwei Schreibvorgänge werden transaktional („Alles oder Nichts“-Vorgänge) für Dokument Doc1 gefolgt von Dokument Doc2 in den Transaktionen T1 und T2 ausgeführt. Wenn der Client ein Lesevorgang in einem Replikat durchführt, sieht der Benutzer entweder "Doc1 v1 und Doc2 v1" oder "Doc1 v2 und Doc2 v2" oder kein Dokument, wenn das Replikat verzögert wird, aber niemals "Doc1 v1 v1 und Doc2 v2" oder "Doc1 v2 und Doc2 v1" für denselben Lese- oder Abfragevorgang.
In der folgenden Grafik wird die Präfixkonsistenz anhand von Noten veranschaulicht. In allen Regionen beobachtet man niemals außerhalb der Reihenfolge liegende Schreibvorgänge bei einem Transaktionsbatch von Schreiboperationen:

Letztliche Konsistenz
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Bei letztlicher Konsistenz sendet der Client Leseanforderungen an ein beliebiges der vier Replikate in der angegebenen Region. Dieses Replikat kann verzögert werden und kann veraltete oder keine Daten zurückgeben.
Letztendlich ist die Konsistenz die schwächste Form der Konsistenz, da ein Client möglicherweise Werte liest, die älter sind als diese Werte, die er in der Vergangenheit gelesen hat. Eventuelle Konsistenz ist ideal, wenn die Anwendung keine Garantie der Reihenfolge erfordert. Beispiele sind die Anzahl der Retweets, Likes oder nicht geschachtelten Kommentare. In der folgenden Grafik wird die letztliche Konsistenz anhand von Noten veranschaulicht:

Konsistenzgarantien in der Praxis
In der Praxis erhalten Sie häufig stärkere Konsistenzgarantien. Die Konsistenzgarantien für einen Lesevorgang entsprechen der Aktualität und der Sortierung des Zustands der angeforderten Datenbank. Die Lesekonsistenz ist an die Sortierung und Verteilung der Schreib- und Aktualisierungsvorgänge gebunden.
Wenn keine Schreibvorgänge für die Datenbank vorhanden sind, kann ein Lesevorgang mit eventuellen, sitzungs- oder konsistenten Präfixkonsistenzebenen dieselben Ergebnisse wie ein Lesevorgang mit der starken Konsistenzstufe liefern.
Wenn Ihr Konto mit einer anderen Konsistenzstufe als der starken Konsistenz konfiguriert ist, können Sie die Wahrscheinlichkeit ermitteln, dass Ihre Clients möglicherweise starke und konsistente Lesevorgänge für Ihre Workloads erhalten. Ermitteln Sie diese Wahrscheinlichkeit, indem Sie die Probabilistically Bounded Staleness (PBS) -Metrik betrachten. Diese Metrik wird im Azure-Portal verfügbar gemacht. Weitere Informationen finden Sie unter Monitor Probabilistically Bounded Staleness (PBS)-Metrik.
Probabilistisch gebundene Veraltetkeit zeigt, wie letztendlich Ihre spätere Konsistenz ist. Diese Metrik bietet Einblicke in die Häufigkeit, in der Sie eine stärkere Konsistenz erhalten als die aktuell auf Ihrem Azure Cosmos DB-Konto konfigurierte Konsistenzstufe. Mit anderen Worten: Sie können die Wahrscheinlichkeit (gemessen in Millisekunden) sehen, konsistente Lesevorgänge für eine Kombination von Schreib- und Leseregionen zu erhalten.
Konsistenzebenen und Latenz
Die Leselatenzzeiten für sämtliche Konsistenzstufen sind garantiert unter 10 Millisekunden im 99. Quantil. Die durchschnittliche Leselatenz am 50. Quantil beträgt in der Regel 4 Millisekunden oder weniger.
Die Schreiblatenz für alle Konsistenzniveaus ist garantiert weniger als 10 Millisekunden im 99. Perzentil. Die durchschnittliche Schreiblatenz am 50. Perzentil beträgt üblicherweise 5 Millisekunden oder weniger. Azure Cosmos DB-Konten, die mehrere Regionen mit starker Konsistenz umfassen, sind eine Ausnahme dieser Garantie.
Schreiblatenz und starke Konsistenz
Für Azure Cosmos DB-Konten, die mit starker Konsistenz in mehreren Regionen konfiguriert sind, beträgt die Schreiblatenz das Zweifache der Roundtrip-Zeit (RTT) zwischen den beiden am weitesten entfernten Regionen plus 10 Millisekunden im 99. Perzentil. Hohe Netzwerk-RTT zwischen Regionen erhöht die Azure Cosmos DB-Anforderungslatenz, da starke Konsistenz einen Vorgang erst abschließt, nachdem sichergestellt wurde, dass der Vorgang in allen Regionen im Konto abgeschlossen ist.
Genaue RTT-Latenz hängt von der Geschwindigkeit des Lichtabstands und der Azure-Netzwerktopologie ab. Azure-Netzwerk bietet keine Latenz-Dienstgütevereinbarungen (SLAs) für die Round-Trip-Zeit (RTT) zwischen Azure-Regionen an, veröffentlicht aber Azure-Netzwerk-Roundtriplatenzstatistiken. Die Replikationslatenzzeiten für Ihr Azure Cosmos DB-Konto werden im Azure-Portal angezeigt. Verwenden Sie das Azure-Portal, indem Sie zum Abschnitt "Metriken" wechseln und die Option " Konsistenz " auswählen. Im Azure-Portal können Sie die Replikationswartezeiten zwischen verschiedenen Regionen überwachen, die Ihrem Azure Cosmos DB-Konto zugeordnet sind.
Important
Eine starke Konsistenz für Konten mit Regionen, die mehr als 5.000 Meilen (8.000 Kilometer) umfassen, wird standardmäßig aufgrund einer hohen Schreiblatenz blockiert. Wenden Sie sich an den Support, um diese Funktion zu aktivieren.
Konsistenzebenen und Durchsatz
Bei starkem und gebundenem Veraltungsgrad werden Lesevorgänge gegen zwei Replikas in einer Vier-Replika-Gruppe (Minderheitsquorum) durchgeführt, um Konsistenzgarantien sicherzustellen. Sitzungskonsistenz, konsistentes Präfix und letztendliche Konsistenz verwenden Einzelreplikat-Lesevorgänge. Der Lesedurchsatz für starke und begrenzte Staleheit ist bei derselben Anzahl von Anforderungseinheiten also nur halb so groß wie der der anderen Konsistenzstufen.
Bei einem bestimmten Schreibvorgangstyp, z. B. Einfügen, Ersetzen, Upsert oder Löschen, ist der Schreibdurchsatz für Anforderungseinheiten über alle Konsistenzstufen identisch. Für eine starke Konsistenz müssen Änderungen in jeder Region (globale Mehrheit) übernommen werden, während für alle anderen Konsistenzstufen die lokale Mehrheit (drei Replikate in einer Vier-Replikat-Gruppe) verwendet wird.
| Konsistenzstufe | Quorumlesevorgänge | Quorum-Schreibvorgänge |
|---|---|---|
| Stark | Lokale Minderheit | Globale Mehrheit |
| Begrenzte Veraltung | Lokale Minderheit | Lokale Mehrheit |
| Sitzung | Einzelnes Replikat (mit Sitzungstoken) | Lokale Mehrheit |
| Einheitliches Präfix | Einzelnes Replikat | Lokale Mehrheit |
| Letztliche Konsistenz | Einzelnes Replikat | Lokale Mehrheit |
Note
Die RU-Kosten für lokale Minderheitslesevorgänge sind doppelt so hoch wie bei schwächeren Konsistenzstufen, da Lesevorgänge aus zwei Replikaten durchgeführt werden, um die Konsistenzgarantien für die starke und die begrenzte Staleness-Konsistenz sicherzustellen.
Konsistenzebenen und Datendauerhaftigkeit
In einer global verteilten Datenbankumgebung wirkt sich die Konsistenzstufe während eines regionsweiten Ausfalls direkt auf die Datenbeständigkeit aus. Wenn Sie einen Geschäftskontinuitätsplan entwickeln, sollten Sie den maximalen Zeitraum der letzten Datenaktualisierungen verstehen, die die Anwendung während der Wiederherstellung von einem störenden Ereignis tolerieren kann. Der Zeitraum der Updates, die verloren gehen können, wird als Ziel des Wiederherstellungspunkts (Recovery Point Objective , RPO) bezeichnet.
Diese Tabelle zeigt die Beziehung zwischen Konsistenzmodellen und Datenbeständigkeit während eines regionsweiten Ausfalls.
| Regions | Replikationsmodus | Konsistenzebene | RPO |
|---|---|---|---|
| 1 | Eine oder mehrere Schreibregionen | Jede Konsistenzebene | < 240 Minuten |
| >1 | Eine Schreibregion | Sitzung, Präfixkonsistenz, Letztlich | < 15 Minuten |
| >1 | Eine Schreibregion | Begrenzte Veralterung | K & T |
| >1 | Eine Schreibregion | STARK (Strong) | 0 |
| >1 | Mehrere Schreibregionen | Sitzung, Präfixkonsistenz, Letztlich | < 15 Minuten |
| >1 | Mehrere Schreibregionen | Begrenzte Veralterung | K & T |
K = Die Anzahl der K-Versionen (Aktualisierungen) eines Elements.
T = Das Zeitintervall T seit der letzten Aktualisierung.
Bei einem Einzelregionenkonto beträgt der Mindestwert von K und T 10 Schreibvorgänge oder 5 Sekunden. Bei Konten mit mehreren Regionen beträgt der Mindestwert von K und T 100.000 Schreibvorgänge oder 300 Sekunden. Dieser Wert definiert das minimale Wiederherstellungsziel (RPO) für Daten bei Verwendung der Gebundenen Stetigkeit.
Hohe Konsistenz und mehrere Schreibregionen
Azure Cosmos DB-Konten mit mehreren Schreibbereichen können keine starke Konsistenz verwenden, da ein verteiltes System kein Wiederherstellungspunktziel (RPO) von Null und ein Wiederherstellungszeitziel (Recovery Time Objective, RTO) von Null bereitstellen kann. Darüber hinaus verbessert die starke Konsistenz mit mehreren Schreibbereichen die Schreiblatenz nicht, da Schreibvorgänge repliziert und für alle Regionen im Konto zugesichert werden müssen. Diese Einrichtung führt zu derselben Schreiblatenz wie ein Konto mit einem einzelnen Schreibbereich.
Weiterführende Lektüre
In folgenden Ressourcen erfahren Sie mehr über Konsistenzkonzepte:
- High-Level TLA⁺ Spezifikationen für die fünf Konsistenzstufen, die von Azure Cosmos DB angeboten werden
- Die Konsistenz replizierter Daten erklärt anhand von Baseball (Video) von Doug Terry
- Replizierte Datenkonsistenz erklärt anhand von Baseball (Whitepaper) von Doug Terry
- Sitzungsgarantien für schwach konsistente replizierte Daten
- Konsistenzkompromisse bei der Gestaltung moderner verteilter Datenbanksysteme: CAP ist nur ein Teil des Ganzen
- Probabilistische Gebundene Veraltetkeit (PBS) für praktische partielle Quorums
- Letztendlich konsistent - überarbeitet
Verwandte Inhalte
- Konfigurieren der Standardkonsistenzebene
- Außerkraftsetzen der Standardkonsistenzebene
- Erfahren Sie mehr über die Sla für Azure Cosmos DB.