Migrieren von relationalen Daten mit 1:n-Beziehungen zu einem Azure Cosmos DB for NoSQL-Konto
GILT FÜR: ![]() NoSQL
NoSQL
Zum Migrieren von einer relationalen Datenbank zu Azure Cosmos DB for NoSQL müssen möglicherweise zur Optimierung Änderungen am Datenmodell vorgenommen werden.
Eine gängige Transformation ist die Denormalisierung von Daten durch das Einbetten verwandter Unterelemente innerhalb eines JSON-Dokuments. In diesem Artikel werden einige Optionen dafür unter Verwendung von Azure Data Factory oder Azure Databricks aufgezeigt. Weitere Informationen zur Datenmodellierung für Azure Cosmos DB finden Sie unter Datenmodellierung in Azure Cosmos DB.
Beispielszenario
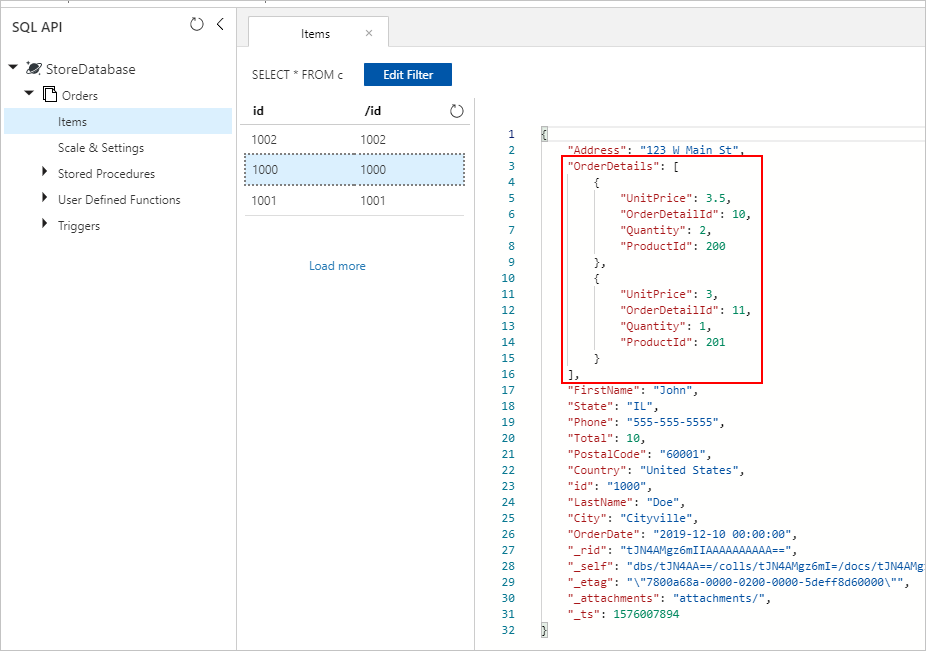
Angenommen unsere SQL-Datenbank enthält die beiden Tabellen „Orders“ und „OrderDetails“.
Wir möchten diese 1:n-Beziehung während der Migration zu einem JSON-Dokument kombinieren. Um ein einzelnes Dokument zu erstellen, erstellen Sie eine T-SQL-Abfrage mit FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
Die Ergebnisse dieser Abfrage enthalten Daten aus der Tabelle Orders:

Im Idealfall würden Sie in Azure Data Factory (ADF) eine einzige Kopieraktivität ausführen, um SQL-Daten als Quelle abzufragen und die Ausgabe direkt als ordnungsgemäße JSON-Objekte in die Azure Cosmos DB-Senke zu schreiben. Aktuell ist es nicht möglich, die erforderliche JSON-Transformation in einer Kopieraktivität auszuführen. Wenn wir versuchen, die Ergebnisse der obigen Abfrage in einen Azure Cosmos DB for NoSQL-Container zu kopieren, wird das Feld „OrderDetails“ als Zeichenfolgeneigenschaft des Dokuments und nicht das erwartete JSON-Array angezeigt.
Wir können diese aktuelle Einschränkung auf folgende Weise umgehen:
- Verwenden von Azure Data Factory mit zwei Kopieraktivitäten:
- Speichern JSON-formatierter Daten aus SQL in einer Textdatei an einem Blob-Zwischenspeicherort
- Laden Sie die Daten aus der JSON-Textdatei in einen Container in Azure Cosmos DB.
- Verwenden von Azure Databricks zum Lesen aus SQL und zum Schreiben in Azure Cosmos DB – Wir stellen hier zwei Optionen vor.
Nachfolgend werden diese Ansätze ausführlicher erörtert:
Azure Data Factory
„OrderDetails“ kann zwar nicht als JSON-Array in das Azure Cosmos DB-Zieldokument eingebettet werden, aber wir können das Problem mit zwei separaten Kopieraktivitäten umgehen.
Kopieraktivität Nummer 1: SqlJsonToBlobText
Für die Quelldaten verwenden wir eine SQL-Abfrage, um das Resultset als einzelne Spalte mit einem (den Auftrag darstellenden) JSON-Objekt pro Zeile mithilfe der SQL Server-Funktionen OPENJSON und FOR JSON PATH abzurufen:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
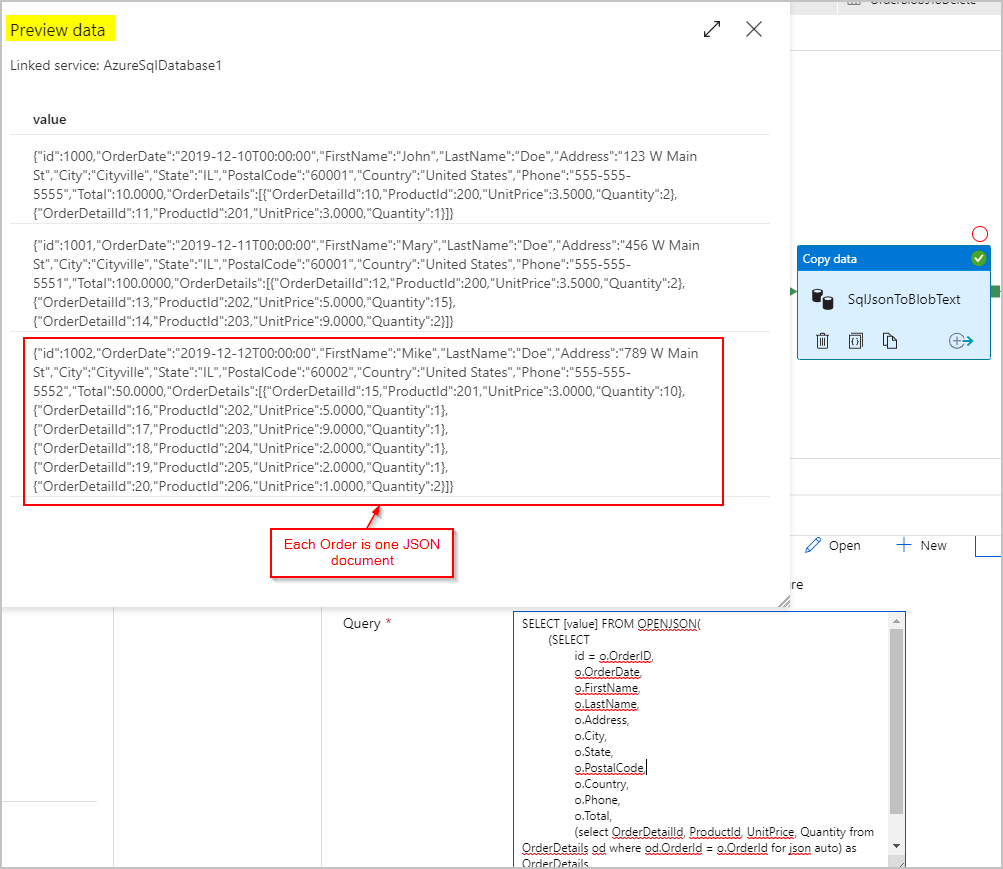
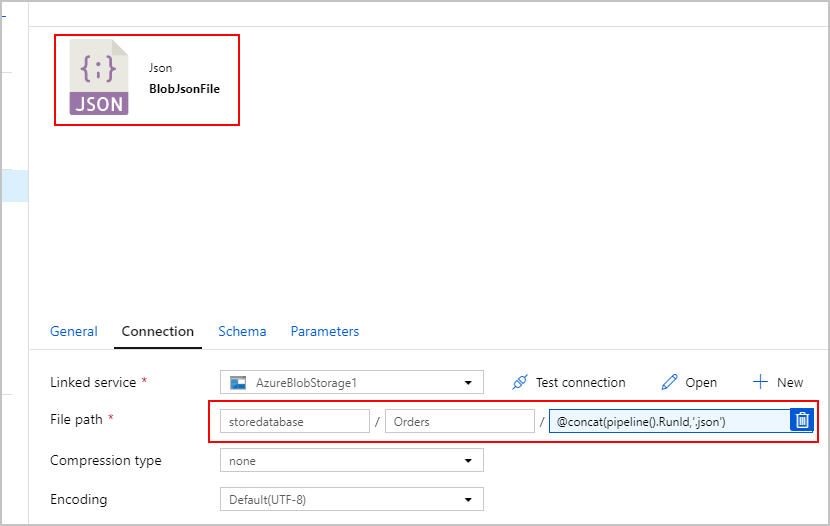
Für die Senke der SqlJsonToBlobText-Kopieraktivität wählen wir „Durch Trennzeichen getrennter Text“ und verweisen auf einen bestimmten Ordner in Azure Blob Storage. Diese Senke enthält einen dynamisch generierten eindeutigen Dateinamen (z. B @concat(pipeline().RunId,'.json').
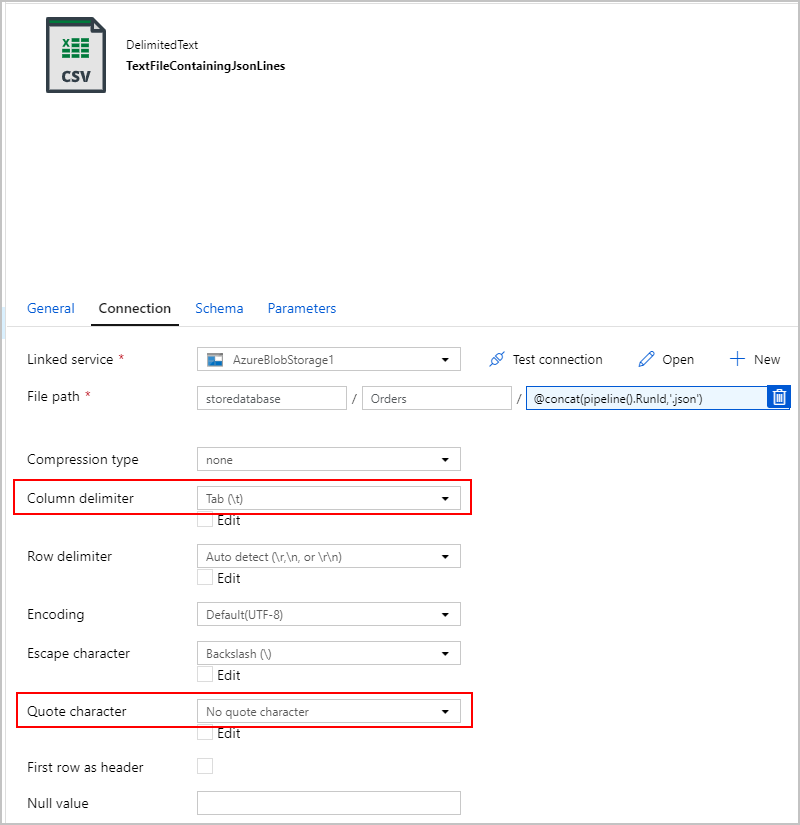
Dabei ist unsere Textdatei nicht wirklich „Durch Trennzeichen getrennt“, und wir möchten verhindern, dass sie unter Verwendung von Kommas in getrennte Spalten geparst wird. Außerdem möchten wir die doppelten Anführungszeichen (") beibehalten, das „Spaltentrennzeichen“ auf ein Tabstoppzeichen („\t“) oder ein anderes Zeichen festlegen, das in den Daten nicht vorkommt, und dann „Anführungszeichen“ auf „Kein Anführungszeichen“ setzen.
Kopieraktivität Nummer 2: BlobJsonToCosmos
Als Nächstes ändern wir die ADF-Pipeline, indem wir die zweite Kopieraktivität hinzufügen, die in Azure Blob Storage nach der Textdatei sucht, die von der ersten Aktivität erstellt wurde. Sie wird als „JSON“-Quelle verarbeitet und als ein Dokument pro in der Textdatei gefundener JSON-Zeile in die Azure Cosmos DB-Senke eingefügt.
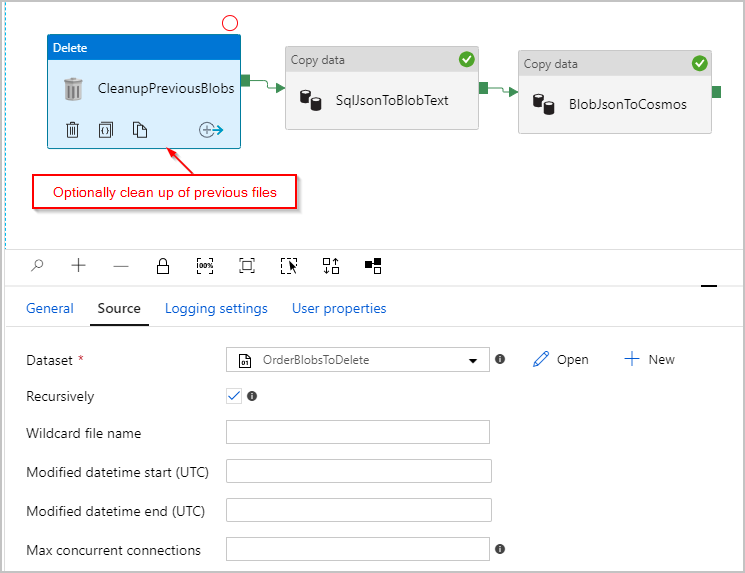
Optional fügen wir der Pipeline auch eine Aktivität „Löschen“ hinzu, sodass alle im Ordner „/Orders/“ verbliebenen vorherigen Dateien vor jeder Ausführung gelöscht werden. Unsere ADF-Pipeline sieht jetzt in etwa wie folgt aus:
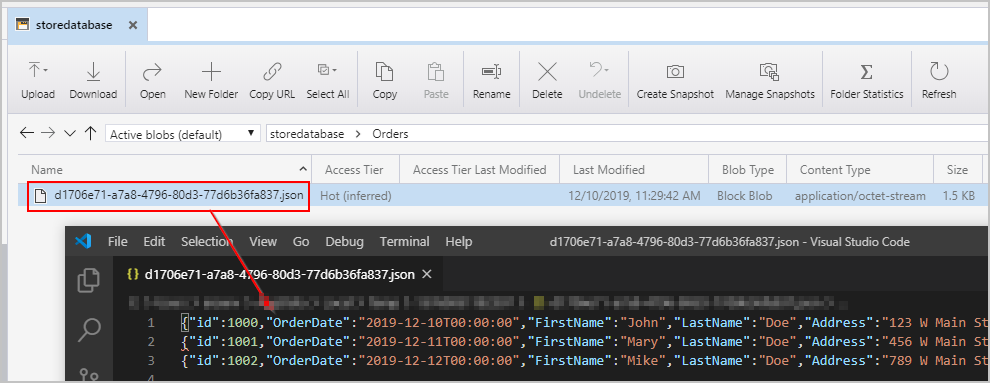
Nachdem wir die oben genannte Pipeline ausgelöst haben, wird in unserem Azure Blob Storage-Zwischenspeicherort eine Datei erstellt, die ein JSON-Objekt pro Zeile enthält:
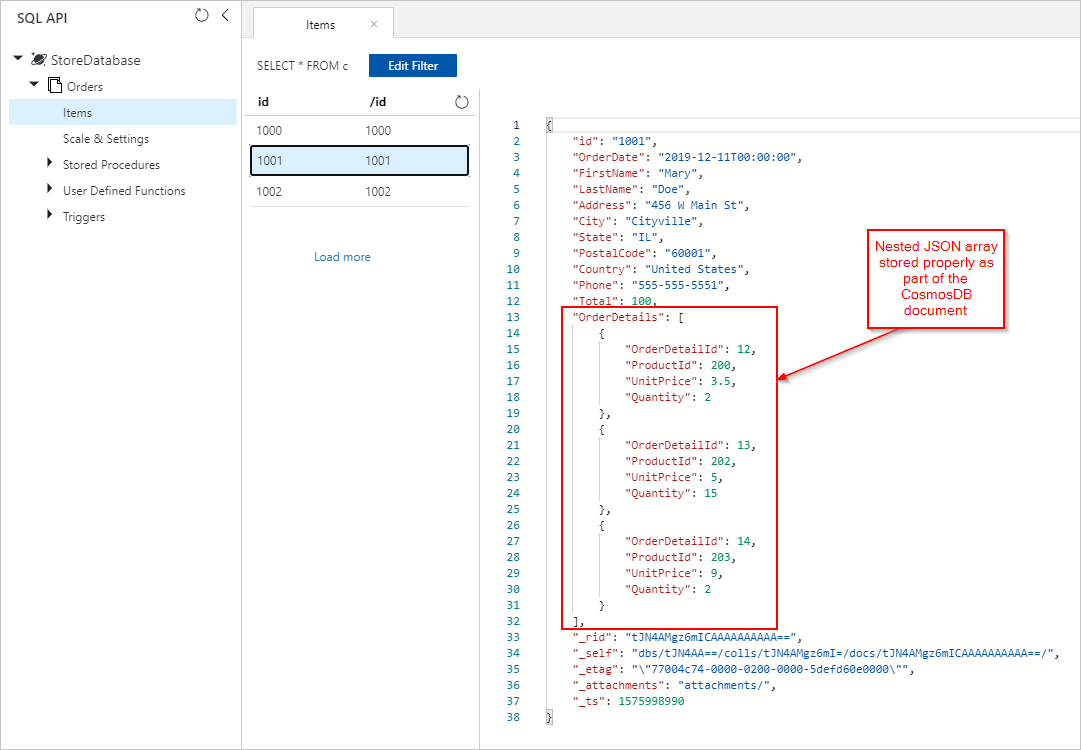
Außerdem werden Dokumente des Ordners „Orders“ mit ordnungsgemäß eingebetteten „OrderDetails“ in unsere Azure Cosmos DB-Sammlung eingefügt:
Azure Databricks
Wir können auch Spark in Azure Databricks verwenden, um die Daten aus unserer SQL-Datenbankquelle in das Azure Cosmos DB-Ziel zu kopieren, ohne die Text-/JSON-Zwischendateien in Azure Blob Storage zu erstellen.
Hinweis
Der Klarheit und Einfachheit halber enthalten die nachstehenden Codeschnipsel (explizit inline dargestellte) Dummy-Datenbankkennwörter. Sie sollten jedoch idealerweise Azure Databricks-Geheimnisse verwenden.
Zuerst erstellen wir die erforderlichen SQL-Connector- und Azure Cosmos DB-Connectorbibliotheken und fügen sie an unseren Azure Databricks-Cluster an. Starten Sie den Cluster neu, um sicherzustellen, dass die Bibliotheken geladen werden.

Als Nächstes stellen wir zwei Beispiele für Scala und Python vor.
Scala
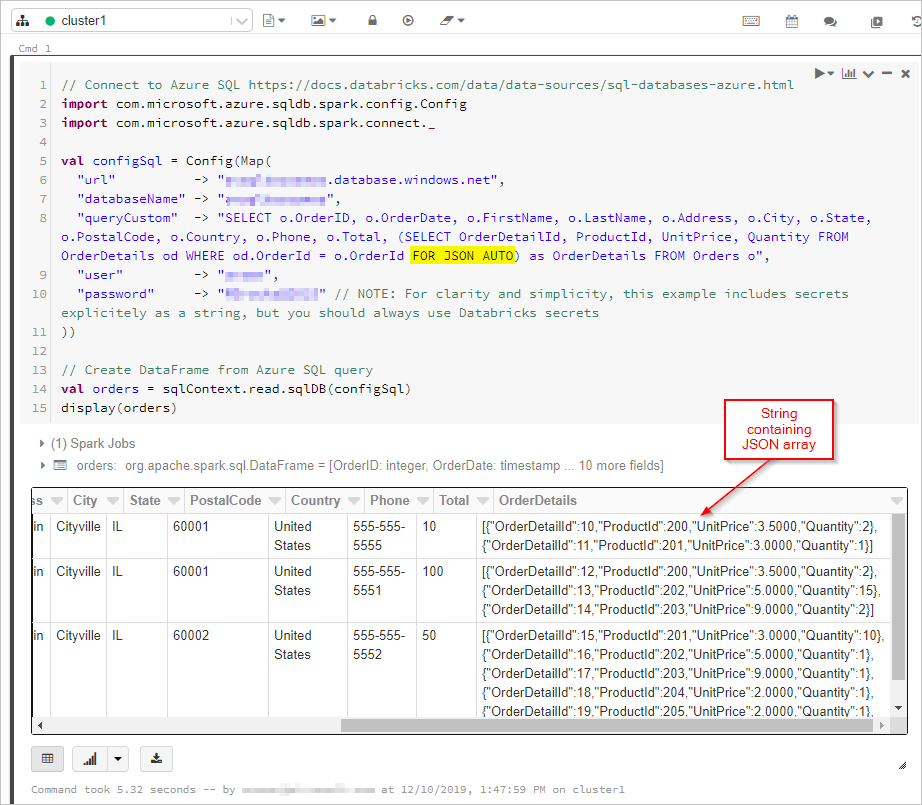
Hier rufen wir die Ergebnisse der SQL-Abfrage mit der „FOR JSON“-Ausgabe in einem Datenrahmen ab:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
Als Nächstes stellen wir eine Verbindung mit unserer Azure Cosmos DB-Datenbank und -Sammlung her:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
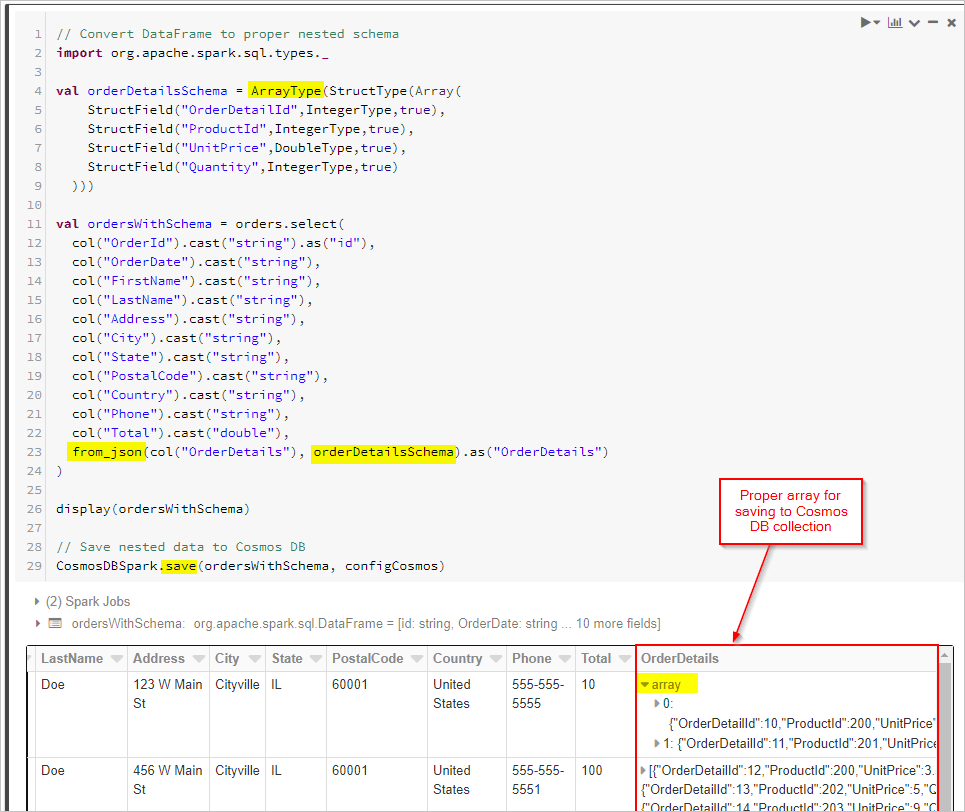
Zum Schluss definieren wir unser Schema und verwenden „from_json“, um den Datenrahmen vor dem Speichern in der Cosmos DB-Sammlung anzuwenden.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
Alternativ müssen Sie möglicherweise JSON-Transformationen in Spark ausführen, wenn FOR JSON oder ein vergleichbarer Vorgang von der Quelldatenbank nicht unterstützt wird. Alternativ können Sie parallele Vorgänge für ein umfangreiches Dataset verwenden. Hier stellen wir ein PySpark-Beispiel vor. Zuerst werden die Quell- und Zieldatenbankverbindungen in der ersten Zelle konfiguriert:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Anschließend fragen wir die Quelldatenbank (in diesem Fall SQL Server) nach allen „Orders“- und „OrderDetails“-Datensätzen ab, wobei die Ergebnisse in Spark-Datenrahmen ausgegeben werden. Wir erstellen auch eine Liste mit allen Auftrags-IDs und einen Threadpool für parallele Vorgänge:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Erstellen Sie dann eine Funktion zum Schreiben von Aufträgen in die „API für NoSQL“-Zielsammlung. Diese Funktion filtert alle „OrderDetails“ für die angegebene Auftrags-ID heraus, konvertiert sie in ein JSON-Array und fügt das Array in ein JSON-Dokument ein. Das JSON-Dokument wird dann in den API für NoSQL-Zielcontainer für diese Bestellung geschrieben:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Zum Schluss rufen wir die writeOrder-Python-Funktion mithilfe einer Zuordnungsfunktion für den Threadpool auf, die parallel ausgeführt wird und die zuvor erstellte Liste der Auftrags-IDs übergibt:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
Bei beiden Ansätzen sollten wir am Ende ordnungsgemäß gespeicherte eingebettete „OrderDetails“ in jedem „Order“-Dokument in der Azure Cosmos DB-Sammlung erhalten: