Modellieren und Partitionieren von Daten in Azure Cosmos DB anhand eines praktischen Beispiels
GILT FÜR: ![]() NoSQL
NoSQL
Dieser Artikel veranschaulicht auf Grundlage verschiedener Azure Cosmos DB-Konzepte wie Datenmodellierung, Partitionierung und bereitgestelltem Durchsatz die Erstellung eines Datenentwurfs anhand einer praktischen Übung.
Wenn Sie normalerweise mit relationalen Datenbanken arbeiten, haben Sie sich wahrscheinlich bestimmte Gewohnheiten und Vorstellungen im Hinblick auf das Entwerfen eines Datenmodells angeeignet. Die meisten dieser bewährten Methoden lassen sich aufgrund der spezifischen Einschränkungen, aber auch der einzigartigen Vorteile von Azure Cosmos DB, nicht gut umsetzen und können dazu führen, dass Sie sich für suboptimale Lösungen entscheiden. Dieser Artikel führt Sie Schritt für Schritt durch den gesamten Modellierungsprozess für einen realen Anwendungsfall in Azure Cosmos DB – von der Elementmodellierung bis hin zur Zusammenstellung der Entitäten und Containerpartitionierung.
Laden Sie Quellcode aus der Community herunter, oder sehen Sie ihn sich an, der die Konzepte aus diesem Artikel veranschaulicht.
Wichtig
Ein Community-Mitwirkender hat dieses Codebeispiel beigesteuert, und das Azure Cosmos DB-Team unterstützt seine Wartung nicht.
Szenario
In dieser Übung betrachten wir die Domäne einer Blogplattform, auf der Benutzer die Möglichkeit haben, Beiträge zu erstellen. Benutzer können diese Beiträge auch mit „Gefällt mir“ markieren und ihnen Kommentare hinzufügen.
Tipp
Einige Wörter sind hier kursiv hervorgehoben. Sie stellen die Art von „Dingen“ dar, die von unserem Modell bearbeitet werden sollen.
Weitere Anforderungen für unsere Spezifikation:
- Auf einer Startseite wird ein Feed der kürzlich erstellten Beiträge angezeigt.
- Wir können alle Beiträge für einen Benutzer, alle Kommentare für einen Beitrag und alle „Gefällt mir“-Markierungen für einen Beitrag abrufen.
- Beiträge werden mit dem Benutzernamen der Autoren sowie der Anzahl von Kommentaren und „Gefällt mir“-Markierungen zurückgegeben.
- Kommentare und „Gefällt mir“-Markierungen werden ebenfalls mit dem Benutzernamen des Benutzers, von denen sie erstellt wurden, zurückgegeben.
- Bei der Anzeige in Listenform muss für Beiträge nur eine gekürzte Zusammenfassung des Inhalts angezeigt werden.
Identifizieren der wichtigsten Zugriffsmuster
Zunächst strukturieren wir unsere anfängliche Spezifikation, indem wir die Zugriffsmuster der Lösung ermitteln. Beim Entwurf eines Datenmodells für Azure Cosmos DB ist es wichtig zu verstehen, welche Anforderungen unser Modell erfüllen muss, um sicherzustellen, dass es diese Anforderungen effizient erfüllt.
Um den Gesamtprozess leichter nachvollziehbar zu machen, kategorisieren wir diese verschiedenen Anfragen entweder als Befehle oder als Abfragen, wobei wir einige Vokabeln von CQRS übernehmen. In CQRTS sind Befehle Schreibanforderungen (d. h. Absichten zum Aktualisieren des Systems), und Abfragen sind schreibgeschützte Anforderungen.
Hier sehen Sie die Liste der Anforderungen, die unserer Plattform verfügbar macht:
- [C1] : Einen Benutzer erstellen/bearbeiten
- [Q1] : Einen Benutzer abrufen
- [C2] : Einen Beitrag erstellen/bearbeiten
- [Q2] : Einen Beitrag abrufen
- [Q3] : Beiträge eines Benutzers in Kurzform auflisten
- [C3] : Einen Kommentar erstellen
- [Q4] : Kommentare für einen Beitrag auflisten
- [C4] : Einen Beitrag mit „Gefällt mir“ markieren
- [Q5] : „Gefällt mir“-Markierungen eines Beitrags auflisten
- [Q6] : Die x neuesten Beiträge in Kurzform auflisten (Feed)
Zu diesem Zeitpunkt haben wir uns noch keine Gedanken darüber gemacht, was die einzelnen Entitäten (Benutzer, Beitrag usw.) im Einzelnen enthalten. Dieser Schritt gehört in der Regel zu den ersten, die beim Entwerfen für einen relationalen Speicher angegangen werden müssen. Wir beginnen mit diesem Schritt am Anfang, da wir herausfinden müssen, wie diese Entitäten in Bezug auf Tabellen, Spalten, Fremdschlüssel usw. übersetzt werden. Bei einer Dokumentdatenbank, die beim Schreiben kein Schema erzwingt, ist es wesentlich weniger problematisch.
Die Zugriffsmuster von Beginn an zu identifizieren, ist vor allem deswegen wichtig, weil diese Liste von Anforderungen unsere Testsammlung sein wird. Jedes Mal, wenn wir das Datenmodell durchlaufen, gehen wir jede der Anforderungen durch und überprüfen ihre Leistung und Skalierbarkeit. Wir berechnen die in den einzelnen Modellen verbrauchten Anforderungseinheiten und optimieren sie. Alle diese Modelle verwenden die Standardindizierungsrichtlinie, und Sie können sie überschreiben, indem Sie bestimmte Eigenschaften indizieren, was auch RU-Verbrauch und Latenz weiter verbessern kann.
Version 1: Die erste Version
Wir beginnen mit zwei Containern: users und posts.
Container „users“
In diesem Container werden nur Benutzerelemente gespeichert:
{
"id": "<user-id>",
"username": "<username>"
}
Wir partitionieren diesen Container nach id, was bedeutet, dass jede logische Partition innerhalb des Containers nur ein Element enthält.
Container „posts“
Dieser Container hostet Entitäten wie z. B. Beiträge, Kommentare und „Gefällt mir“-Markierungen:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Wir partitionieren diesen Container nach postId, was bedeutet, dass jede logische Partition innerhalb des Containers einen Beitrag, alle Kommentare zu diesem Beitrag und alle „Gefällt mir“-Markierungen des Beitrags enthält.
Wir haben für die in diesem Container gespeicherten Elemente eine type-Eigenschaft hinzugefügt, um zwischen den drei Typen von Entitäten zu unterscheiden, die der Container hostet.
Zudem haben wir uns aus den folgenden Gründen entschieden, auf zugehörige Daten zu verweisen, anstatt sie einzubetten (Details zu diesen Konzepten finden Sie in diesem Abschnitt):
- Es gibt keine Obergrenze für die Anzahl von Beiträgen, die ein Benutzer erstellen kann.
- Beiträge können beliebig lang sein.
- Es gibt keine Obergrenze für die Anzahl von Kommentaren und „Gefällt mir“-Markierungen eines Beitrags.
- Es soll möglich sein, einem Beitrag einen Kommentar hinzuzufügen oder ihn mit „Gefällt mir“ zu markieren, ohne den Beitrag selbst zu aktualisieren.
Wie gut funktioniert das Modell?
Der nächste Schritt besteht darin, die Leistung und Skalierbarkeit der ersten Version zu bewerten. Für jede der zuvor identifizierten Anforderungen messen wir die Wartezeit und die von der Anforderung verbrauchte Anzahl von Anforderungseinheiten (Request Unit, RU). Diese Messung wird für ein Dummydataset ausgeführt, das 100.000 Benutzer mit fünf bis 50 Beiträgen pro Benutzer und bis zu 25 Kommentare und 100 „Gefällt mir“-Markierungen pro Beitrag enthält.
[C1]: Einen Benutzer erstellen/bearbeiten
Diese Anforderung ist einfach zu implementieren, da lediglich ein Element im Container users erstellt oder aktualisiert wird. Die Anforderungen verteilen sich dank des Partitionsschlüssels id gut auf alle Partitionen.
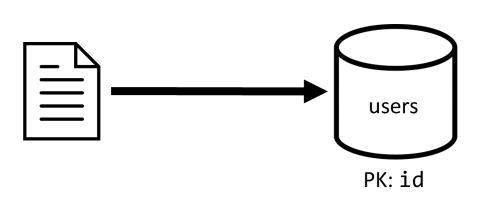
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1]: Einen Benutzer abrufen
Zum Abrufen eines Benutzers wird das entsprechende Element aus dem Container users gelesen.
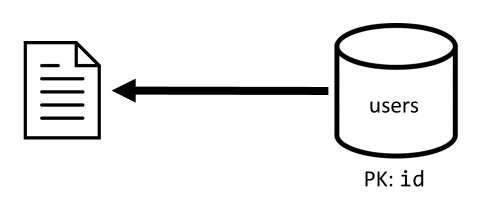
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2]: Einen Beitrag erstellen/bearbeiten
Ähnlich wie bei [C1] muss bei dieser Anforderung nur in den Container posts geschrieben werden.
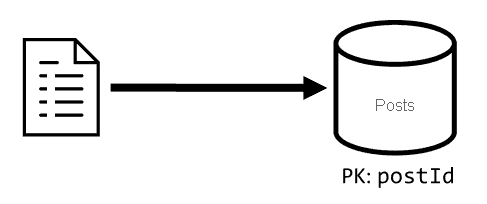
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2]: Einen Beitrag abrufen
Zunächst rufen wir das entsprechende Dokument aus dem Container posts ab. Aber das ist noch nicht genug, gemäß unserer Spezifikation müssen wir auch den Benutzernamen des Autors des Beitrags, die Anzahl der Kommentare und die Anzahl der „Gefällt mir“-Markierungen für den Beitrag aggregieren. Für die aufgeführten Aggregationen müssen 3 weitere SQL-Abfragen ausgegeben werden.
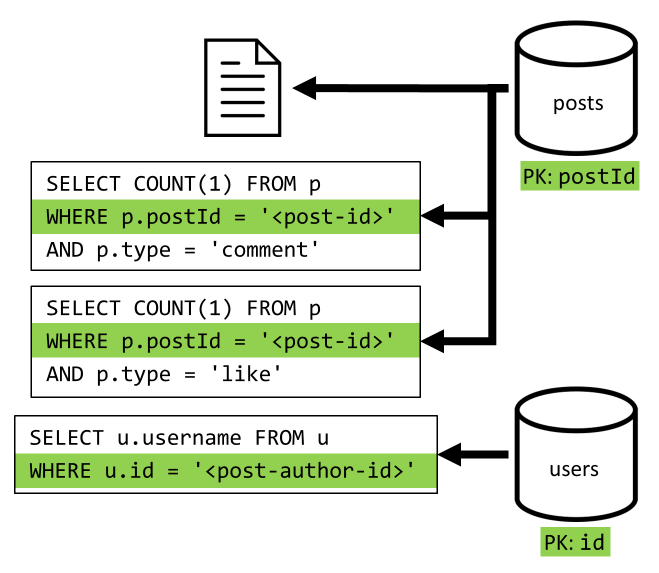
Jede der weiteren Abfragen filtert nach dem Partitionsschlüssel des jeweiligen Containers. Dies ist genau das erwünschte Verhalten, da wir die Leistung und Skalierbarkeit maximieren wollen. Im Endeffekt müssen jedoch zum Zurückgeben eines einzelnen Beitrags vier Vorgänge ausgeführt werden. Dies werden wir in einer der nächsten Iterationen verbessern.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3]: Beiträge eines Benutzers in Kurzform auflisten
Zunächst müssen wir die gewünschten Beiträge mit einer SQL-Abfrage abrufen, die die entsprechenden Beiträge für den jeweiligen Benutzer abruft. Wir müssen aber auch weitere Abfragen ausführen, um den Benutzernamen des Autors und die Anzahl von Kommentaren und „Gefällt mir“-Markierungen zu aggregieren.
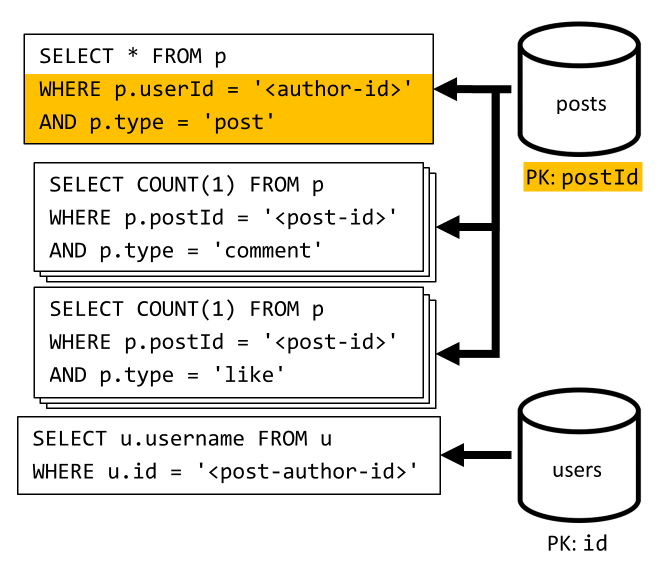
Diese Implementierung hat viele Nachteile:
- Die Abfragen zum Aggregieren der Anzahl von Kommentaren und „Gefällt mir“-Markierungen müssen für jeden von der ersten Abfrage zurückgegebenen Beitrag ausgeführt werden.
- Die Hauptabfrage filtert nicht nach dem Partitionsschlüssel des Containers
posts, was zu einer Auffächerung und einem Partitionsscan im Container führt.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3]: Einen Kommentar erstellen
Ein Kommentar wird erstellt, indem das entsprechende Element in den Container posts geschrieben wird.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
7 ms |
8.57 RU |
✅ |
[Q4]: Kommentare eines Beitrags auflisten
Wir beginnen mit einer Abfrage, die alle Kommentare für den jeweiligen Beitrag abruft. Zudem müssen wir auch hier die Benutzernamen separat für jeden Kommentar aggregieren.
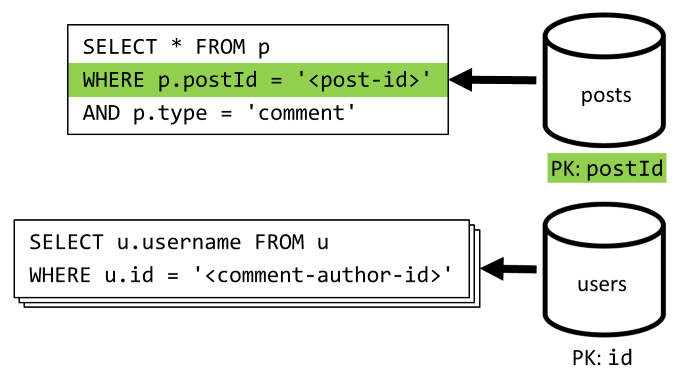
Obwohl die Hauptabfrage nach dem Partitionsschlüssel des Containers filtert, beeinträchtig das separate Aggregieren der Benutzernamen die Gesamtleistung. Dies werden wir später verbessern.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4]: Einen Beitrag mit „Gefällt mir“ markieren
Wie bei [C3] erstellen wir das entsprechende Element im Container posts.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
6 ms |
7.05 RU |
✅ |
[Q5]: „Gefällt mir“-Markierungen eines Beitrags auflisten
Wie bei [Q4] fragen wir die „Gefällt mir“-Markierungen für den Beitrag ab, und anschließend aggregieren wir die zugehörigen Benutzernamen.
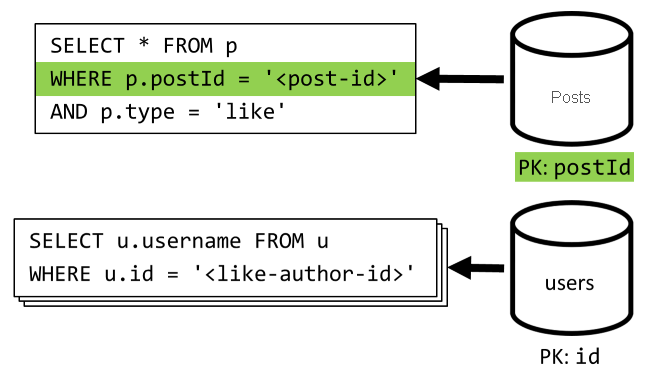
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6]: Die „x“ neuesten Beiträge in Kurzform auflisten (Feed)
Wir rufen die neuesten Beiträge ab, indem wir den Container posts absteigend nach Erstellungsdatum sortiert abfragen, und anschließend aggregieren wir die Benutzernamen sowie die Anzahl von Kommentaren und „Gefällt mir“-Markierungen für jeden der Beiträge.
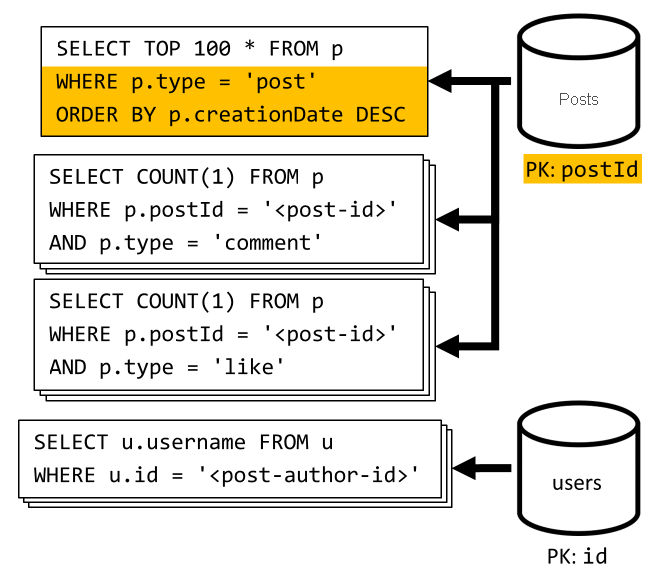
Auch hier filtert unsere erste Abfrage nicht nach dem Partitionsschlüssel des Containers posts, wodurch ein kostspieliges Fan-out ausgelöst wird. Dieses ist noch schwerwiegender, da wir auf ein viel größeres Resultsset zielen und die Ergebnisse mit einer ORDER BY-Klausel sortieren, wodurch es in Bezug auf die Anforderungseinheiten noch teurer wird.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
Überlegungen zur Leistung von Version 1
Wenn wir uns die Leistungsprobleme im vorherigen Abschnitt ansehen, können wir zwei primäre Arten von Problemen erkennen:
- Manche Anforderungen erfordern mehrere Abfragen, um alle Daten zu erfassen, die zurückgegeben werden müssen.
- Manche Abfragen filtern nicht nach dem Partitionsschlüssel der jeweiligen Container, was zu einer Auffächerung führt und die Skalierbarkeit beeinträchtigt.
Diese Probleme werden wir nun beheben. Beginnen wir mit dem ersten Problem.
Version 2: Verwenden der Denormalisierung zum Optimieren der Leseabfragen
Der Grund, warum wir einigen Fällen weitere Anforderungen ausstellen müssen, ist, dass die Ergebnisse der ersten Anforderung nicht alle Daten enthalten, die wir zurückgeben müssen. Die Denormalisierung von Daten löst diese Art von Problem im gesamten Dataset, wenn mit einem nicht relationalen Datenspeicher wie Azure Cosmos DB gearbeitet wird.
In unserem Beispiel ändern wir die Beitragselemente, indem wir den Benutzernamen des Beitragsautors, die Anzahl von Kommentaren und die Anzahl von „Gefällt mir“-Markierungen hinzufügen:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Außerdem ändern wir die Kommentar- und „Gefällt mir“-Markierungselemente, indem wir den Benutzernamen des Benutzers hinzufügen, von denen sie erstellt wurden:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Denormalisieren der Anzahl von Kommentaren und „Gefällt mir“-Markierungen
Wir möchten erreichen, dass bei jeder Hinzufügung eines Kommentars oder einer „Gefällt mir“-Markierung die Anzahl commentCount oder likeCount im zugehörigen Beitrag erhöht wird. Da postId unseren posts-Container partitioniert, befinden sich das neue Element (Kommentar oder „Gefällt mir“-Markierung) und der dazugehörige Beitrag in der gleichen logischen Partition. Wir können daher eine gespeicherte Prozedur zum Ausführen des Vorgangs verwenden.
Wenn Sie einen Kommentar ([C3]) erstellen, wird nicht einfach ein neues Element in den posts-Container eingefügt, sondern die folgende gespeicherte Prozedur für diesen Container aufgerufen:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Diese gespeicherte Prozedur akzeptiert die ID des Beitrags und den Text des neuen Kommentars als Parameter und führt anschließend die folgenden Aktionen aus:
- Abrufen des Beitrags
- Erhöhen der Anzahl von
commentCount - Ersetzen des Beitrags
- Hinzufügen des neuen Kommentars
Da gespeicherte Prozeduren als unteilbare Transaktionen ausgeführt werden, sind der Wert von commentCount und die tatsächliche Anzahl von Kommentaren immer synchron.
Beim Hinzufügen neuer „Gefällt mir“-Markierungen rufen wir eine ähnliche gespeicherte Prozedur auf, um likeCount zu erhöhen.
Denormalisieren von Benutzernamen
Benutzernamen erfordern eine andere Herangehensweise, da sich Benutzer nicht nur in unterschiedlichen Partitionen, sondern auch in einem anderen Container befinden. Wenn wir Daten partitions- und containerübergreifend denormalisieren müssen, können wir den Änderungsfeed des Quellcontainers verwenden.
In unserem Beispiel verwenden wir den Änderungsfeed des Containers users, um auf jede von Benutzern durchgeführte Aktualisierung des Benutzernamens zu reagieren. Wenn ein Benutzer seinen Benutzernamen aktualisiert, verteilen wir die Änderung, indem wir eine weitere gespeicherte Prozedur für den Container posts aufrufen:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Diese gespeicherte Prozedur akzeptiert die ID des Benutzers und seinen neuen Benutzernamen als Parameter und führt anschließend die folgenden Aktionen aus:
- Abrufen aller Elemente, die mit der
userIdübereinstimmen (Beiträge, Kommentare oder „Gefällt mir“-Markierungen) - Folgende Vorgänge für jedes dieser Elemente:
- Ersetzen von
userUsername - Ersetzen des Elements
- Ersetzen von
Wichtig
Dieser Vorgang ist kostspielig, da die gespeicherte Prozedur für jede Partition des Containers posts ausgeführt werden muss. Wir gehen davon aus, dass die meisten Benutzer bei der Registrierung einen geeigneten Benutzernamen auswählen, den sie niemals ändern, und diese Aktualisierung daher nur sehr selten ausgeführt wird.
Welche Leistungsverbesserungen bietet Version 2?
Lassen Sie uns über einige der Leistungssteigerungen von V2 sprechen.
[Q2]: Einen Beitrag abrufen
Da wir die Denormalisierung hinzugefügt haben, müssen wir zum Verarbeiten dieser Anforderung nur ein einziges Element abrufen.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
2 ms |
1 RU |
✅ |
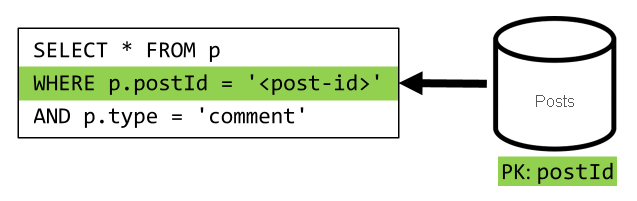
[Q4]: Kommentare eines Beitrags auflisten
Auch in diesem Fall können wir die zusätzlichen Anforderungen zum Abrufen der Benutzernamen weglassen und stattdessen eine einzige Abfrage verwenden, die nach dem Partitionsschlüssel filtert.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
4 ms |
7.72 RU |
✅ |
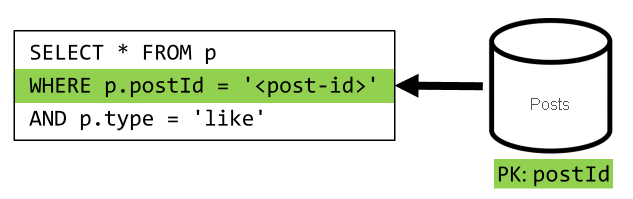
[Q5]: „Gefällt mir“-Markierungen eines Beitrags auflisten
Beim Auflisten der „Gefällt mir“-Markierungen haben wir die gleiche Situation.
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
4 ms |
8.92 RU |
✅ |
Version 3: Sicherstellen der Skalierbarkeit aller Anforderungen
Es gibt immer noch zwei Anforderungen, die wir nicht vollständig optimiert haben, wenn wir uns unsere Gesamtleistungsverbesserungen ansehen. Diese Anforderungen sind [Q3] und [Q6]. Dies sind die Anforderungen mit Abfragen, die nicht nach dem Partitionsschlüssel der Container filtern, auf die sie abzielen.
[Q3]: Beiträge eines Benutzers in Kurzform auflisten
Diese Anforderung profitiert bereits von den Verbesserungen, die wir zur Vermeidung weiterer Abfragen in Version 2 eingeführt haben.

Die verbleibende Abfrage filtert jedoch noch immer nicht nach dem Partitionsschlüssel des Containers posts.
Die Überlegungen zu dieser Situation sind einfach:
- Die Anforderung muss nach der
userIdfiltern, da wir alle Beiträge für einen bestimmten Benutzer abrufen wollen. - Die Leistung dieser Anforderung ist nicht gut, da sie für den Container
postsausgeführt wird, der nicht über eineuserId-Partitionierung verfügt. - Wir könnten das Leistungsproblem natürlich beheben, indem wir die Anforderung für einen Container ausführen, der mit
userIdpartitioniert ist. - Tatsächlich haben wir bereits einen solchen Container: den Container
users.
Wir fügen daher eine zweite Denormalisierungsebene hinzu, indem wir alle Posts im Container users duplizieren. Auf diese Weise erhalten wir effektiv eine Kopie unserer Beiträge, die lediglich nach einer anderen Dimension partitioniert ist. Die Beiträge können dadurch deutlich effizienter anhand ihrer userId abgerufen werden.
Der Container users enthält jetzt zwei Arten von Elementen:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
In diesem Beispiel:
- Wir haben ein
type-Feld im Benutzerelement hinzugefügt, um Benutzer von Beiträgen zu unterscheiden, - Außerdem haben wir ein
userId-Feld im Benutzerelement hinzugefügt, das mit dem Feldidredundant, aber erforderlich ist, da der Containerusersjetzt mituserIdpartitioniert ist (und nicht wie zuvor mitid)
Um diese Denormalisierung zu erreichen, verwenden wir wieder den Änderungsfeed. Dieses Mal reagieren wir auf den Änderungsfeed des Containers posts, um alle neuen oder aktualisierten Beiträge im Container users zu verteilen. Und da zum Auflisten von Beiträgen nicht der vollständige Inhalt zurückgegeben werden muss, können wir diese im Prozess abschneiden.
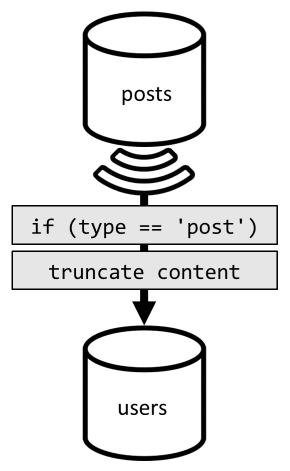
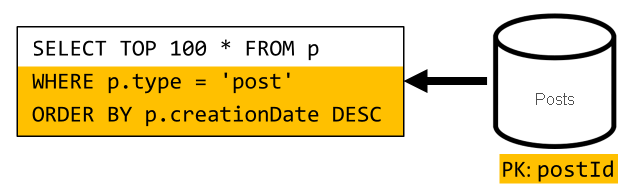
Jetzt können wir unsere Abfrage an den Container users weiterleiten und dabei nach dem Partitionsschlüssel des Containers filtern.

| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
4 ms |
6.46 RU |
✅ |
[Q6]: Die „x“ neuesten Beiträge in Kurzform auflisten (Feed)
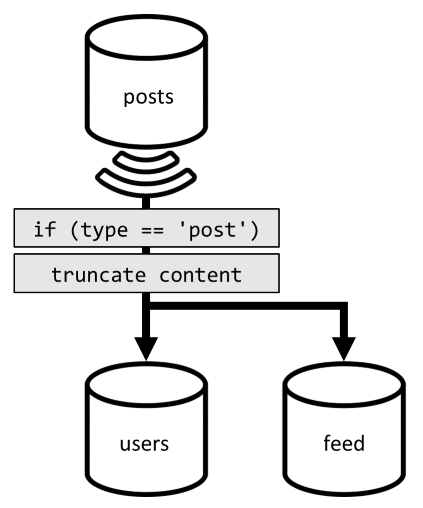
Hier haben wir es mit einer ähnlichen Situation zu tun: Auch nach dem Beseitigen der weiteren Abfragen durch das Hinzufügen der in Version 2 hinzugefügten Denormalisierung filtert die verbleibende Abfrage nicht nach dem Partitionsschlüssel des Containers:
Gemäß dem obigen Ansatz muss die Anforderung auf eine Partition beschränkt werden, um die Leistung und Skalierbarkeit der Anforderung zu maximieren. Das Treffen nur einer einzelnen Partition ist denkbar, da wir nur eine begrenzte Anzahl von Elementen zurückgeben müssen. Zum Auffüllen der Startseite unserer Blogplattform müssen wir nur die 100 neuesten Beiträge abrufen, ohne das gesamte Dataset zu paginieren.
Zum Optimieren dieser letzten Anforderung fügen wir unserem Entwurf daher einen dritten Container hinzu, der einzig zur Verarbeitung dieser Anforderung dient. Wir denormalisieren unsere Beiträge im neuen Container feed:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Das type-Feld partitioniert diesen Container, das immer post in unseren Elementen ist. Dadurch wird sichergestellt, dass sich alle Elemente in diesem Container in derselben Partition befinden.
Zum Erreichen der Denormalisierung müssen wir nur die Änderungsfeedpipeline verknüpfen, die wir zuvor hinzugefügt haben, um die Beiträge an den neuen Container zu verteilen. Wichtig ist hierbei, dass nur die 100 neuesten Beiträge gespeichert werden dürfen. Andernfalls kann der Inhalt des Containers die maximale Größe einer Partition überschreiten. Diese Einschränkung kann durch den Aufruf eines Post-Triggers bei jedem Hinzufügen eines Dokuments in den Container implementiert werden:
Hier sehen Sie den Text des nachgestellten Triggers, der die Auflistung abschneidet:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Im letzten Schritt müssen Sie die Abfrage an den neuen Container feed umleiten:
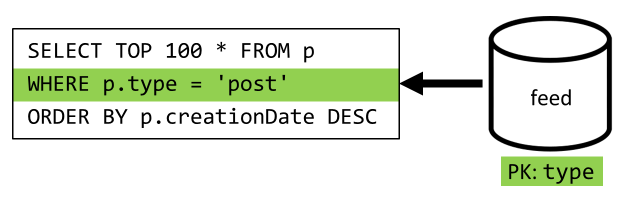
| Latenz | Verbrauchte RUs | Leistung |
|---|---|---|
9 ms |
16.97 RU |
✅ |
Zusammenfassung
Werfen wir nun einen Blick auf die Verbesserungen der Gesamtleistung und Skalierbarkeit, die wir in den verschiedenen Versionen unseres Entwurfs eingeführt haben.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Wir haben ein leseintensives Szenario optimiert
Möglicherweise haben Sie bemerkt, dass wir uns auf die Verbesserung der Leistung von Leseanforderungen (Abfragen) konzentriert und dafür Abstriche bei den Schreibanforderungen (Befehle) in Kauf genommen haben. In vielen Fällen lösen Schreibvorgänge jetzt eine nachfolgende Denormalisierung über Änderungsfeeds aus, wodurch diese Vorgänge rechenintensiver werden und ihre Materialisierung mehr Zeit in Anspruch nimmt.
Wir rechtfertigen diesen Fokus auf die Leseleistung damit, dass eine Blogplattform (wie die meisten sozialen Apps) leseintensiv ist. Eine leseintensive Arbeitsauslastung deutet darauf hin, dass die Anzahl der Leseanfragen in der Regel um Größenordnungen höher ist als die Anzahl der Schreibanfragen, die bedient werden müssen. Deshalb ist es sinnvoll, den Kostenaufwand für die Ausführung von Schreibanforderungen zu erhöhen, um im Gegenzug die Kosten von Leseanforderungen zu reduzieren und die Leistung dieser Anforderungen zu verbessern.
Sehen wir uns dazu die größte Optimierung an, die wir erzielt haben: Für [Q6] haben wir die Anzahl verbrauchter RUs von 2000 auf nur 17 RUs reduziert. Wir haben dies durch die Denormalisierung von Beiträgen erreicht, mit Kosten von etwa 10 RUs pro Element. Da wir deutlich mehr Feedanforderungen als Anforderungen zum Erstellen oder Aktualisieren von Beiträgen verarbeiten würden, sind diese Kosten für die Denormalisierung angesichts der Gesamteinsparungen vernachlässigbar.
Denormalisierung kann inkrementell angewendet werden.
Um die in diesem Artikel behandelten Verbesserungen der Skalierbarkeit zu erreichen, müssen Daten im Dataset denormalisiert und dupliziert werden. Anzumerken ist hierbei, dass diese Optimierungen nicht sofort umgesetzt werden müssen. Abfragen, die nach Partitionsschlüsseln filtern, haben für große Datenmengen eine bessere Leistung, aber partitionsübergreifende Abfragen können akzeptabel sein, wenn sie nur selten oder nur für eine begrenzte Menge an Daten aufgerufen werden. Wenn Sie nur einen Prototyp bauen, oder ein Produkt mit einer engen und kontrollierten Benutzerbasis starten, können Sie sich diese Verbesserungen wahrscheinlich für später aufheben. Es ist dann wichtig, die Leistung Ihres Modells zu überwachen, damit Sie entscheiden können, ob und wann die Verbesserungen vorgenommen werden sollen.
Im Änderungsfeed, den wir zum Verteilen der Aktualisierungen an andere Container verwenden, werden diese Aktualisierungen dauerhaft gespeichert. Dank dieser Persistenz können alle Aktualisierungen seit der Erstellung des Containers angefordert und das Bootstrapping der denormalisierten Ansichten als ein einmaliger Aufholvorgang durchgeführt werden, selbst dann, wenn in Ihrem System bereits viele Daten vorhanden sind.
Nächste Schritte
Nach dieser Einführung in die praktische Datenmodellierung und -partitionierung sollten Sie sich die folgenden Artikel ansehen, um die behandelten Konzepte zu wiederholen:
- Arbeiten mit Datenbanken, Containern und Elementen
- Partitioning in Azure Cosmos DB (Partitionierung in Azure Cosmos DB)
- Änderungsfeed in Azure Cosmos DB
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für