Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
Azure Cosmos DB arbeitet mit Partitionierung, um einzelne Container in einer Datenbank entsprechend den Leistungsanforderungen Ihrer Anwendung zu skalieren. Die Elemente werden in einem Container in eindeutige Teilgruppen unterteilt, die als logische Partitionen bezeichnet werden. Logische Partitionen werden basierend auf dem Wert des Partitionsschlüssels erstellt, die jedem Element in einem Container zugeordnet ist. Alle Elemente in einer logischen Partition haben denselben Partitionsschlüsselwert.
Angenommen, ein Container enthält Elemente. Jedes Element hat für die UserID-Eigenschaft einen eindeutigen Wert. Wenn UserID als Partitionsschlüssel für die Elemente in einem Container dient und es 1.000 eindeutige UserID-Werte gibt, werden für den Container 1.000 logische Partitionen erstellt.
Zusätzlich zu einem Partitionsschlüssel, der die logische Partition des Elements bestimmt, weist jedes Element in einem Container eine (innerhalb der logischen Partition eindeutige) Element-ID auf. Durch die Kombination des Partitionsschlüssels und der Element-ID wird der Index des Elements erstellt, der das Element eindeutig identifiziert. Die Auswahl eines Partitionsschlüssels ist eine wichtige Entscheidung, die sich auf die Leistung Ihrer Anwendung auswirkt.
In diesem Artikel wird die Beziehung zwischen logischen und physischen Partitionen erörtert. Außerdem werden bewährte Methoden für die Partitionierung erläutert. Und Sie erhalten eine detaillierte Übersicht über die Funktionsweise der horizontalen Skalierung in Azure Cosmos DB. Sie müssen diese internen Details nicht unbedingt verstehen, um Ihren Partitionsschlüssel auswählen zu können, aber wir haben sie angeführt, damit Sie Klarheit über die Funktionsweise von Azure Cosmos DB haben.
Logische Partitionen
Eine logische Partition besteht aus einer Gruppe von Elementen mit demselben Partitionsschlüssel. Beispielsweise enthalten alle Elemente in einem Container mit Daten über Nahrungsmittel eine foodGroup-Eigenschaft. Sie können foodGroup als Partitionsschlüssel für den Container verwenden. Elementgruppen mit bestimmten Werten für foodGroup, z.B. Beef Products, Baked Products und Sausages and Luncheon Meats, bilden eindeutige logische Partitionen.
Eine logische Partition definiert auch den Bereich für Datenbanktransaktionen. Sie können Elemente in einer logischen Partition mithilfe einer Transaktion mit Momentaufnahmeisolation aktualisieren. Wenn einem Container neue Elemente hinzugefügt werden, werden neue logische Partitionen transparent vom System erstellt. Sie müssen sich keine Gedanken über das Löschen einer logischen Partition machen, wenn die zugrunde liegenden Daten gelöscht werden.
Es besteht keine Beschränkung für die Anzahl logischer Partitionen in Ihrem Container. Jede logische Partition kann bis zu 20 GB Daten speichern. Durch eine sinnvolle Auswahl des Partitionsschlüssels ergeben sich viele mögliche Werte. Beispielsweise können in einem Container, in dem alle Elemente eine foodGroup-Eigenschaft aufweisen, die Daten innerhalb der logischen Partition Beef Products auf bis zu 20 GB anwachsen. Durch Auswählen eines Partitionsschlüssels mit einer Vielzahl möglicher Werte können Sie sicherstellen, dass der Container skaliert werden kann.
Sie können mithilfe von Azure Monitor-Warnungen überwachen, ob sich die Größe einer logischen Partition 20 GB annähert.
Physische Partitionen
Ein Container wird skaliert, indem Daten und Durchsatz auf physische Partitionen verteilt werden. Intern wird mindestens eine logische Partition einer einzelnen physischen Partition zugeordnet. Normalerweise verfügen kleinere Container über viele logische Partitionen, benötigen aber nur eine einzige physische Partition. Im Gegensatz zu logischen Partitionen sind physische Partitionen eine interne Implementierung des Systems und werden vollständig von Azure Cosmos DB verwaltet.
Die Anzahl der physischen Partitionen in Ihrem Container hängt von den folgenden Merkmalen ab:
Der Menge des bereitgestellten Durchsatzes (jede einzelne physische Partition kann einen Durchsatz von bis zu 10.000 Anforderungseinheiten pro Sekunde bereitstellen) Die Beschränkung auf 10.000 RU/s für physische Partitionen bedeutet, dass für logische Partitionen ebenfalls eine Begrenzung auf 10.000 RU/s besteht, da jede logische Partition nur einer physischen Partition zugeordnet ist.
Dem gesamten Datenspeicher (Auf jeder einzelnen physischen Partition können bis zu 50 GB Daten gespeichert werden.)
Hinweis
Physische Partitionen sind eine interne Implementierung des Systems, die vollständig von Azure Cosmos DB verwaltet werden. Sie müssen sich beim Entwickeln Ihrer Lösungen nicht auf physische Partitionen konzentrieren, da Sie diese nicht kontrollieren können. Konzentrieren Sie sich stattdessen auf die Partitionsschlüssel. Wenn Sie einen Partitionsschlüssel auswählen, der den verbrauchten Durchsatz gleichmäßig auf logische Partitionen verteilt, stellen Sie sicher, dass der Durchsatzverbrauch auf den physischen Partitionen ausgeglichen ist.
Es besteht keine Beschränkung für die Gesamtanzahl physischer Partitionen in Ihrem Container. Wenn der bereitgestellte Durchsatz oder die Datengröße zunimmt, erstellt Azure Cosmos DB automatisch neue physische Partitionen, indem die vorhandenen geteilt werden. Die Teilung physischer Partitionen hat keine Auswirkungen auf die Verfügbarkeit Ihrer Anwendung. Nach der Aufteilung einer physischen Partition bleiben alle Daten innerhalb einer einzelnen logischen Partition weiterhin auf derselben physischen Partition gespeichert. Bei der Aufteilung physischer Partitionen wird einfach eine neue Zuordnung der logischen Partitionen zu physischen Partitionen erstellt.
Der für einen Container bereitgestellte Durchsatz wird gleichmäßig auf physische Partitionen aufgeteilt. Ein Design mit Partitionsschlüsseln, bei dem Anforderungen nicht gleichmäßig verteilt werden, kann dazu führen, dass zu viele Anforderungen an eine kleine Teilmenge der Partitionen gerichtet werden, die "heiß" werden. Bei heißen Partitionen wird der bereitgestellte Durchsatz nicht effizient genutzt, sodass es zu einer geringeren Datenrate und höheren Kosten kommen kann.
Nehmen wir zum Beispiel einen Container, bei dem der Pfad /foodGroup als Partitionsschlüssel angegeben ist. Der Container kann eine beliebige Anzahl physischer Partitionen aufweisen, in diesem Beispiel wird jedoch davon ausgegangen, dass er über drei verfügt. Eine einzelne physische Partition kann mehrere Partitionsschlüssel enthalten. Die größte physische Partition könnte zum Beispiel die drei größten logischen Partitionen enthalten: Beef Products, Vegetable and Vegetable Products, und Soups, Sauces, and Gravies.
Wenn Sie einen Durchsatz von 18.000 Anforderungseinheiten pro Sekunde (RU/s) zuweisen, kann jede der drei physischen Partitionen 1/3 des insgesamt bereitgestellten Durchsatzes nutzen. Innerhalb der ausgewählten physischen Partition können die logischen Partitionsschlüssel Beef Products, Vegetable and Vegetable Products und Soups, Sauces, and Gravies die 6.000 bereitgestellten RU/s der physischen Partition gemeinsam nutzen. Weil der bereitgestellte Durchsatz gleichmäßig auf die physischen Partitionen Ihres Containers verteilt ist, müssen Sie unbedingt einen Partitionsschlüssel auswählen, der den verbrauchten Durchsatz gleichmäßig verteilt. Weitere Informationen finden Sie unter Auswählen eines Partitionsschlüssels.
Verwalten logischer Partitionen
Azure Cosmos DB verwaltet die Platzierung logischer Partitionen in physischen Partitionen transparent und automatisch, um die Anforderungen an Skalierbarkeit und Leistung des Containers effizient zu erfüllen. Wenn sich die Anforderungen einer Anwendung an Durchsatz und Speicher erhöhen, verschiebt Azure Cosmos DB logische Partitionen, um die Last automatisch auf eine größere Anzahl physischer Partitionen zu verteilen. Weitere Informationen zu physischen Partitionen finden Sie hier.
Azure Cosmos DB verwendet eine hashbasierte Partitionierung, um logische Partitionen auf physische Partitionen zu verteilen. Azure Cosmos DB erstellt für den Partitionsschlüsselwert eines Elements einen Hashwert. Das Hashergebnis bestimmt die logische Partition. Anschließendverteilt Azure Cosmos DB den Schlüsselbereich der Partitionsschlüsselhashes gleichmäßig auf die physischen Partitionen.
Transaktionen (in gespeicherten Prozeduren oder Triggern) sind nur für Elemente in einer einzelnen logischen Partition zulässig.
Replikatgruppen
Jede physische Partition besteht aus Replikatgruppen. Jedes Replikat hostet eine Instanz der Datenbank-Engine. Bei einer Replikatgruppe wird der Datenspeicher in der physischen Partition dauerhaft, hochverfügbar und konsistent. Jedes Replikat, aus dem die physische Partition besteht, erbt das Speicherkontingent der Partition. Alle Replikate einer physischen Partition unterstützen gemeinsam den Durchsatz, der der physischen Partition zugeordnet wurde. Replikatgruppen werden von Azure Cosmos DB automatisch verwaltet.
Normalerweise benötigen kleinere Container nur eine einzige physische Partition, sie verfügen jedoch trotzdem über mindestens vier Replikate.
Die folgende Abbildung zeigt, wie logische Partitionen physischen Partitionen zugeordnet werden, die global verteilt sind. Partitionssatz in der Abbildung bezieht sich auf eine Gruppe physischer Partitionen, die dieselben logischen Partitionsschlüssel in mehreren Regionen verwalten:
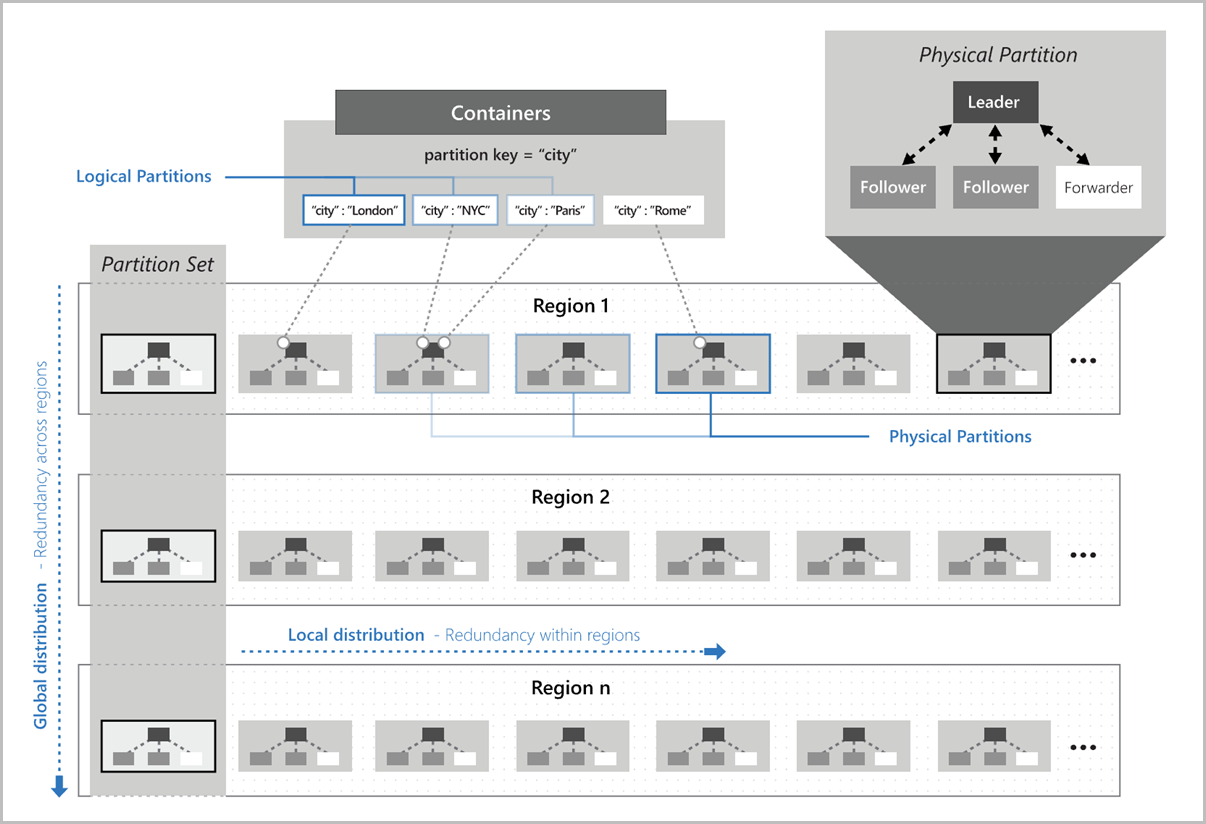
Auswählen eines Partitionsschlüssels
Ein Partitionsschlüssel besteht aus zwei Komponenten: dem Partitionsschlüsselpfad und dem Partitionsschlüsselwert. Beispiel: Wenn Sie bei dem Element { "userId" : "Andrew", "worksFor": "Microsoft" } „userId“ als Partitionsschlüssel auswählen, sind dies die beiden Partitionsschlüsselkomponenten:
Der Partitionsschlüsselpfad (Beispiel: "/userId"). Der Partitionsschlüsselpfad akzeptiert alphanumerische Zeichen und Unterstriche (_). Mithilfe der Standardpfadnotation (/) können Sie auch geschachtelte Objekte verwenden.
Der Partitionsschlüsselwert (Beispiel: "Andrew"). Der Partitionsschlüsselwert kann vom Typ „string“ oder „numeric“ sein.
Informationen zu den Beschränkungen im Hinblick auf Durchsatz, Speicher und Länge des Partitionsschlüssels finden Sie im Artikel Kontingente im Azure Cosmos DB-Dienst.
Die Auswahl Ihres Partitionsschlüssels ist eine einfache, aber wichtige Entwurfsentscheidung in Azure Cosmos DB. Nachdem Sie Ihren Partitionsschlüssel ausgewählt haben, ist es nicht möglich, ihn direkt zu ändern. Wenn Sie Ihren Partitionsschlüssel ändern müssen, sollten Sie Ihre Daten mit dem neuen gewünschten Partitionsschlüssel in einen neuen Container verschieben. (Containerkopieraufträge helfen bei diesem Prozess.)
Für alle Container sollte Ihr Partitionsschlüssel die folgenden Punkte erfüllen:
Er sollte einer Eigenschaft mit einem Wert entsprechen, der sich nicht ändert. Wenn eine Eigenschaft Ihr Partitionsschlüssel ist, können Sie den Wert dieser Eigenschaft nicht aktualisieren.
Sollte nur
String-Werte enthalten. Zahlen sollten idealerweise in denString-Datentyp konvertiert werden, wenn es möglich ist, dass sie außerhalb der Grenzen von Zahlen mit doppelter Genauigkeit gemäß IEEE 754 binary64 liegen. In der Json-Spezifikation sind Gründe dafür genannt, warum die Verwendung von Zahlen außerhalb dieser Grenze im Allgemeinen aufgrund wahrscheinlicher Interoperabilitätsprobleme nicht empfohlen wird. Diese Bedenken sind besonders für die Partitionsschlüsselspalte relevant, da diese unveränderlich ist und eine Datenmigration erfordert, damit sie später geändert werden kann.Er sollte eine hohe Kardinalität aufweisen. Anders ausgedrückt: Die Eigenschaft sollte über eine Vielzahl möglicher Werte verfügen.
Er sollte die zu verbrauchenden Anforderungseinheiten (Request Units, RUs) und die Datenspeicherung gleichmäßig auf alle logischen Partitionen verteilen. Durch diese Verteilung wird ein gleichmäßiger RU-Verbrauch und eine gleichmäßige Speicherverteilung auf Ihren physischen Partitionen sichergestellt.
Es sollten in der Regel Werte verwendet werden, die nicht größer als 2048 Bytes sind. Wenn keine großen Partitionsschlüssel aktiviert sind, sollten die Werte 101 Bytes nicht überschreiten. Weitere Informationen finden Sie unter Große Partitionsschlüssel.
Wenn Sie in Azure Cosmos DB ACID-Transaktionen mit mehreren Elementen benötigen, müssen Sie gespeicherte Prozeduren oder Trigger verwenden. Alle JavaScript-basierten gespeicherten Prozeduren und Trigger sind auf den Bereich einer einzelnen logischen Partition beschränkt.
Hinweis
Wenn Sie nur über eine physische Partition verfügen, ist der Wert des Partitionsschlüssels möglicherweise nicht relevant, da alle Abfragen auf dieselbe physische Partition abzielen.
Typen von Partitionsschlüsseln
| Partitionierungsstrategie | Verwendung | Vorteile | Nachteile |
|---|---|---|---|
| Regulärer Partitionsschlüssel (z. B. CustomerId, OrderId) | – Verwenden, wenn der Partitionsschlüssel eine hohe Kardinalität aufweist und mit Abfragemustern (z. B. Filtern nach CustomerId) übereinstimmt. – Geeignet für Workloads, bei denen Abfragen hauptsächlich auf die Daten eines einzelnen Kunden ausgerichtet sind (z. B. Abrufen aller Bestellungen eines Kunden). |
– Einfach zu verwalten. – Effiziente Abfragen, wenn das Zugriffsmuster mit dem Partitionsschlüssel übereinstimmt (z. B. Abfragen aller Bestellungen nach CustomerId). – Verhindert partitionsübergreifende Abfragen, wenn Zugriffsmuster konsistent sind. |
– Risiko von Heißen Partitionen, wenn einige Werte (z. B. einige Kunden mit hohem Datenverkehr) deutlich mehr Daten generieren als andere. – Kann den Grenzwert von 20 GB pro logischer Partition erreichen, wenn das Datenvolume für einen bestimmten Schlüssel schnell wächst. |
| Synthetischer Partitionsschlüssel (z. B. CustomerId + OrderDate) | – Wird verwendet, wenn kein einzelnes Feld sowohl über hohe Kardinalität verfügt als auch mit Abfragemustern übereinstimmt. – Gut für schreiblastige Workloads, bei denen Daten gleichmäßig über physische Partitionen verteilt werden müssen (z. B. viele Bestellungen, die am selben Datum getätigt wurden). |
– Hilft beim gleichmäßigen Verteilen von Daten über Partitionen, wodurch Heiße Partitionen reduziert werden (z. B. das Verteilen von Aufträgen durch CustomerId und OrderDate). – Verteilt Schreibvorgänge auf mehrere Partitionen, um den Durchsatz zu verbessern. |
– Abfragen, die nur nach einem Feld filtern (z. B. nur CustomerId), können zu partitionsübergreifenden Abfragen führen. – Partitionsübergreifende Abfragen können zu einer höheren RU-Auslastung (2-3 RU/s zusätzliche Gebühr für jede physische Partition, die existiert) und zu einer zusätzlichen Latenz führen. |
| Hierarchischer Partitionsschlüssel (HPK) (z. B. CustomerId/OrderId, StoreId/ProductId) | – Verwenden Sie diese Möglichkeit, wenn Sie eine Partitionierung mit mehreren Ebenen benötigen, um große Datensätze zu unterstützen. – Ideal, wenn Abfragen nach ersten und zweiten Ebenen der Hierarchie filtern. |
– Verhindert den Grenzwert von 20 GB, indem mehrere Partitionsebenen erstellt werden. – Effiziente Abfrage auf beiden Hierarchischen Ebenen (z. B. zuerst nach CustomerID, dann nach OrderID filtern). – Minimiert partitionsübergreifende Abfragen für Abfragen auf oberster Ebene (z. B. Abrufen aller Daten aus einer bestimmten Kunden-ID). |
– Erfordert eine sorgfältige Planung, um sicherzustellen, dass der Schlüssel auf oberster Ebene eine hohe Kardinalität aufweist und in den meisten Abfragen enthalten ist. – Komplexer zu verwalten als ein regulärer Partitionsschlüssel. – Wenn Abfragen nicht mit der Hierarchie übereinstimmen (z. B. nur nach OrderID filtern, wenn CustomerID die erste Ebene ist), kann die Abfrageleistung beeinträchtigt werden. |
Partitionsschlüssel für Container mit vielen Lesevorgängen
Bei den meisten Containern müssen Sie beim Auswählen eines Partitionsschlüssels nur die oben aufgeführten Kriterien beachten. Für große Container mit vielen Lesevorgängen sollten Sie jedoch einen Partitionsschlüssel auswählen, der häufig als Filter in Ihren Abfragen verwendet wird. Abfragen können effizient nur an die relevanten physischen Partitionen weitergeleitet werden, indem der Partitionsschlüssel in das Filterprädikat eingeschlossen wird.
Diese Eigenschaft kann eine gute Wahl für den Partitionsschlüssel darstellen, wenn es sich bei den meisten Anforderungen Ihrer Workload um Abfragen handelt und die meisten Abfragen einen Gleichheitsfilter für dieselbe Eigenschaft aufweisen. Wenn Sie z. B. häufig eine Abfrage ausführen, die nach UserID filtert, würde durch Auswählen von UserID als Partitionsschlüssel die Anzahl der partitionsübergreifenden Abfragen reduziert.
Wenn Sie jedoch über einen kleinen Container verfügen, sind wahrscheinlich nicht genügend physische Partitionen vorhanden, um sich Gedanken über die Leistung von partitionsübergreifenden Abfragen machen zu müssen. Die meisten kleinen Container in Azure Cosmos DB benötigen nur eine oder zwei physische Partitionen.
Wenn Ihr Container auf mehr als ein paar physische Partitionen anwachsen könnte, sollten Sie unbedingt einen Partitionsschlüssel auswählen, der die Anzahl von partitionsübergreifenden Abfragen minimiert. Ihr Container benötigt mehr als ein paar physische Partitionen, wenn einer der folgenden Punkte zutrifft:
Für Ihren Container werden über 30.000 Anforderungseinheiten bereitgestellt.
In Ihrem Container werden mehr als 100 GB Daten gespeichert.
Verwenden der Element-ID als Partitionsschlüssel
Hinweis
Dieser Abschnitt gilt in erster Linie für die API für NoSQL. Andere APIs, z. B. die API für Gremlin, unterstützen den eindeutigen Bezeichner nicht als Partitionsschlüssel.
Wenn Ihr Container über eine Eigenschaft mit einer Vielzahl möglicher Werte verfügt, stellt diese Eigenschaft wahrscheinlich eine gute Wahl für den Partitionsschlüssel dar. Ein mögliches Beispiel für eine solche Eigenschaft ist die Element-ID. Für kleine Container mit vielen Lesevorgängen oder für beliebig große Container mit vielen Schreibvorgängen stellt die Element-ID (/id) natürlich eine gute Wahl für den Partitionsschlüssel dar.
Die Systemeigenschaft Element-ID ist in jedem in Ihrem Container enthaltenen Element vorhanden. Möglicherweise verfügen Sie über weitere Eigenschaften, die eine logische ID Ihres Elements darstellen. In vielen Fällen sind diese IDs aus den gleichen Gründen wie bei der Element-ID ebenfalls eine gute Wahl für den Partitionsschlüssel.
Die Element-ID stellt aus den folgenden Gründen eine gute Wahl für den Partitionsschlüssel dar:
- Es ist eine Vielzahl möglicher Werte vorhanden (eine eindeutige Element-ID pro Element).
- Weil pro Element eine eindeutige Element-ID vorhanden ist, eignet sich die Element-ID hervorragend für die gleichmäßige Verteilung des RU-Verbrauchs und der Datenspeicherung.
- Sie können problemlos effiziente Punktlesevorgänge ausführen, weil Ihnen der Partitionsschlüssel eines Elements immer bekannt ist, wenn Sie die entsprechende Element-ID kennen.
Wenn Sie die Element-ID als Partitionsschlüssel auswählen, müssen Sie die folgenden Punkte berücksichtigen:
- Bei Verwendung der Element-ID als Partitionsschlüssel wird diese im gesamten Container zu einem eindeutigen Bezeichner. Sie können keine Elemente mit doppelten Element-IDs erstellen.
- Wenn Sie über einen Container mit vielen Lesevorgängen verfügen, der viele physische Partitionen umfasst, sind Abfragen effizienter, wenn ein Gleichheitsfilter mit der Element-ID verwendet wird.
- Sie können keine gespeicherten Prozeduren oder Trigger ausführen, die mehrere logische Partitionen zum Ziel haben.