Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Azure Cosmos DB für PostgreSQL wird für neue Projekte nicht mehr unterstützt. Verwenden Sie diesen Dienst nicht für neue Projekte. Verwenden Sie stattdessen einen der folgenden beiden Dienste:
Verwenden Sie für hochskalige Szenarien eine verteilte Datenbanklösung mit Azure Cosmos DB für NoSQL, die ein 99,999%iges Verfügbarkeits-Service-Level-Agreement (SLA), eine sofortige Autoskalierung und ein automatisches regionenübergreifendes Failover bietet.
Verwenden Sie die Elastic Clusters-Funktion von Azure Database for PostgreSQL für geshartete PostgreSQL-Datenbanken mithilfe der Open-Source-Erweiterung Citus.
Die Auswahl der Verteilungsspalte für die einzelnen Tabellen ist eine der wichtigsten Entscheidungen bei der Modellierung, die Sie treffen. Azure Cosmos DB for PostgreSQL speichert Zeilen basierend auf dem Wert der zugehörigen Verteilungsspalte in Shards.
Durch die richtige Wahl werden verwandte Daten in denselben physischen Knoten gruppiert, was zu schnellen Abfragen führt und Unterstützung für alle SQL-Funktionen hinzufügt. Eine falsche Auswahl sorgt dafür, dass das System langsam ausgeführt wird.
Allgemeine Tipps
Im Folgenden finden Sie vier Kriterien für die Auswahl der idealen Verteilungsspalte für Ihre verteilten Tabellen.
Wählen Sie eine Spalte aus, die bei der Anwendungsworkload eine zentrale Rolle spielt.
Sie können sich diese Spalte als „Herz“, „Herzstück“ oder „natürliche Dimension“ für die Partitionierung von Daten vorstellen.
Beispiele:
-
device_idin einer IoT-Workload -
security_idfür eine Finanz-App, die Wertpapiere verfolgt -
user_idin einer Benutzeranalyse -
tenant_idbei einer SaaS-Anwendung mit mehreren Mandanten
-
Wählen Sie eine Spalte mit einer angemessenen Kardinalität und einer gleichmäßigen statistischen Verteilung aus.
Die Spalte sollte viele Werte enthalten sowie sorgfältig und gleichmäßig auf alle Shards verteilt werden.
Beispiele:
- Kardinalität über 1000
- Wählen Sie keine Spalte aus, die bei einem hohen Anteil von Zeilen denselben Wert aufweist (Datenschiefe).
- Bei einer SaaS-Workload, bei der ein Mandant viel größer als der Rest ist, kann das zu einer Datenschiefe führen. In diesem Fall können Sie die Mandantenisolation verwenden, um einen dedizierten Shard zum Verwalten des Mandanten zu erstellen.
Wählen Sie eine Spalte aus, von der Ihre vorhandenen Abfragen profitieren.
Wählen Sie für eine transaktionale oder operative Workload (bei der die meisten Abfragen nur wenige Millisekunden dauern) eine Spalte aus, die in
WHERE-Klauseln für mindestens 80 % der Abfragen als Filter angezeigt wird. Beispiel: Spaltedevice_idinSELECT * FROM events WHERE device_id=1.Wählen Sie für eine Analyseworkload (bei der die meisten Abfragen 1-2 Sekunden dauern) eine Spalte aus, die die Parallelisierung von Abfragen über Workerknoten hinweg ermöglicht. Beispiel: Eine Spalte, die häufig in GROUP BY-Klauseln auftritt oder über mehrere Werte gleichzeitig abgefragt wird.
Wählen Sie eine Spalte aus, die in den meisten großen Tabellen vorhanden ist.
Tabellen mit mehr als 50 GB sollten verteilt werden. Wenn Sie für alle dieselbe Verteilungsspalte auswählen, können Sie Daten für diese Spalte auf Workerknoten zusammenstellen. Diese Zusammenstellung sorgt für ein effizientes Ausführen von Joins und Rollups und das Erzwingen von Fremdschlüsseln.
Die anderen (kleineren) Tabellen können lokale Tabellen oder Verweistabellen sein. Wenn die kleinere Tabelle eine Verknüpfung (Join) mit verteilten Tabellen benötigt, richten Sie sie als Verweistabelle ein.
Beispiele für Anwendungsfälle
Sie haben nun allgemeine Kriterien für die Auswahl der Verteilungsspalte kennengelernt. Jetzt wird deren Anwendung auf häufige Anwendungsfälle veranschaulicht.
Mehrinstanzenfähige Apps
Die Architektur mit mehreren Mandanten verwendet eine Form der hierarchischen Datenbankmodellierung, um Abfragen auf Knoten im Cluster zu verteilen. Die Spitze der Datenhierarchie ist die Mandanten-ID, die in jeder Tabelle in einer Spalte gespeichert werden muss.
Azure Cosmos DB for PostgreSQL untersucht Abfragen, um die involvierte Mandanten-ID zu ermitteln, und sucht nach dem entsprechenden Tabellenshard. Die Abfrage wird an einen einzelnen Workerknoten weitergeleitet, der den Shard enthält. Die Ausführung einer Abfrage mit allen relevanten Daten auf demselben Knoten wird als Zusammenstellung bezeichnet.
Das folgende Diagramm veranschaulicht die Zusammenstellung im Datenmodell mit mehreren Mandanten. Es enthält zwei Tabellen, „Accounts“ und „Campaigns“, beide verteilt nach account_id. Die schattierten Felder stellen Shards dar. Grüne Shards werden zusammen auf einem Workerknoten gespeichert und blaue auf einem anderen Workerknoten. Beachten Sie, dass bei einer JOIN-Abfrage zwischen „Accounts“ und „Campaigns“ alle notwendigen Daten zusammen auf einem Knoten gespeichert werden, wenn beide Tabellen auf dieselbe account_id eingeschränkt sind.
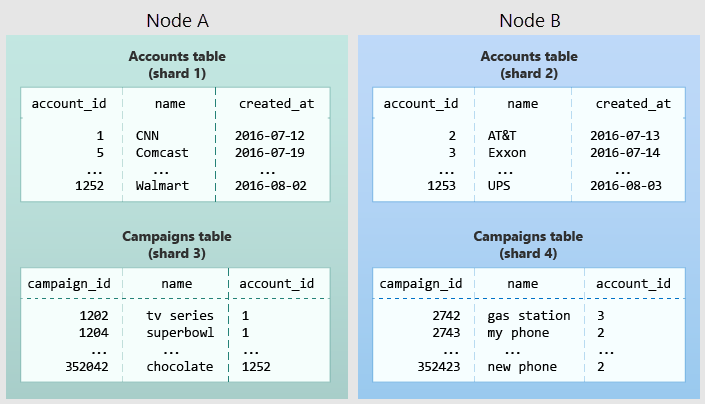
Um diesen Entwurf in Ihrem eigenen Schema anzuwenden, stellen Sie fest, was in Ihrer Anwendung einen Mandanten ausmacht. Zu den gängigen Instanzen gehören Unternehmen, Konto, Organisation oder Kunde. Der Name der Spalte lautet beispielsweise company_id oder customer_id. Untersuchen Sie die einzelnen Abfragen, und stellen Sie sich folgende Frage: Würde die Abfrage funktionieren, wenn alle beteiligten Tabellen durch zusätzliche WHERE-Klauseln auf Zeilen mit derselben Mandanten-ID eingeschränkt würden? Abfragen im mehrinstanzenfähigen Modell sind auf einen Mandanten beschränkt. Beispielsweise werden Abfragen für Verkäufe oder Inventar in einem bestimmten Speicher festgelegt.
Bewährte Methoden
- Verteilen Sie Tabellen nach einer gemeinsamen „tenant_id“-Spalte. In einer SaaS-Anwendung, in denen Mandanten Unternehmen darstellen, lautet die tenant_id wahrscheinlich „company_id“.
- Konvertieren Sie kleine mandantenübergreifende Tabellen in Verweistabellen. Wenn mehrere Mandanten eine kleine Tabelle mit Informationen gemeinsam nutzen, verteilen Sie sie als Verweistabelle.
- Schränken Sie alle Anwendungsabfragen ein, indem Sie sie nach „tenant_id“ filtern. Jede Abfrage muss Informationen für jeweils einen Mandanten anfordern.
Im Tutorial zur Verwendung mehrerer Mandanten finden Sie ein Beispiel für die Erstellung dieser Art von Anwendung.
Echtzeit-Apps
Die Architektur mit mehreren Mandanten führt eine hierarchische Struktur ein und verwendet die Zusammenstellung von Daten zum Weiterleiten von Abfragen pro Mandant. Im Gegensatz dazu sind Echtzeitarchitekturen von bestimmten Verteilungseigenschaften ihrer Daten abhängig, um eine hochgradige Parallelverarbeitung zu erreichen.
Wir verwenden „Entitäts-ID“ als Bezeichnung für Verteilungsspalten im Echtzeitmodell. Typische Entitäten sind Benutzer, Hosts oder Geräte.
Echtzeitabfragen fordern in der Regel numerische Aggregate an, die nach Datum oder nach Kategorie gruppiert sind. Azure Cosmos DB for PostgreSQL sendet diese Abfragen an die einzelnen Shards, um Teilergebnisse zu erhalten, und fasst die endgültige Antwort auf dem Koordinatorknoten zusammen. Abfragen werden am schnellsten ausgeführt, wenn so viele Knoten wie möglich einen Beitrag leisten und wenn kein einzelner Knoten eine unverhältnismäßig große Menge an Arbeit bewältigen muss.
Bewährte Methoden
- Wählen Sie eine Spalte mit hoher Kardinalität als Verteilungsspalte aus. Zum Vergleich: Ein Feld „Status“ mit den Werten "Neu", "Bezahlt" und "Geliefert" in einer Auftragstabelle ist als Verteilungsspalte eine ungünstige Wahl. Es kann nur diese wenigen Werte annehmen, wodurch die Anzahl von Shards zur Datenspeicherung und die Anzahl von Knoten zur Verarbeitung begrenzt werden. Außerdem empfiehlt es sich, unter den Spalten mit hoher Kardinalität diejenigen Spalten auszuwählen, die häufig in group-by-Klauseln oder als Joinschlüssel verwendet werden.
- Wählen Sie eine Spalte mit gleichmäßiger Verteilung. Wenn Sie eine Tabelle anhand einer Spalte verteilen, die eine Neigung zu bestimmten häufig verwendeten Werten aufweist, sammeln sich die Daten tendenziell in bestimmten Shards an. Die Knoten mit den betreffenden Shards müssen in diesem Fall mehr leisten als die anderen Knoten.
- Verteilen Sie Fakten- und Dimensionstabellen anhand ihrer gemeinsamen Spalten. Ihre Faktentabelle kann nur einen Verteilungsschlüssel aufweisen. Tabellen, die anhand eines anderen Schlüssels verknüpft werden, können nicht mit den Daten der Faktentabelle zusammengestellt werden. Wählen Sie eine Dimension basierend auf der Verknüpfungshäufigkeit und der Größe der verknüpften Zeilen aus.
- Ändern Sie einige Dimensionstabellen in Verweistabellen. Wenn eine Dimensionstabelle nicht mit den Daten der Faktentabelle zusammengestellt werden kann, können Sie die Abfrageleistung verbessern, indem Sie Kopien der Dimensionstabelle in Form einer Verweistabelle an alle Knoten verteilen.
Im Tutorial zum Echtzeitdashboard finden Sie ein Beispiel für die Erstellung dieser Art von Anwendung.
Zeitreihendaten
In einer Zeitreihenworkload fragen Anwendungen neueste Informationen ab und archivieren alte Informationen.
Der häufigste Fehler beim Modellieren von Zeitreiheninformationen in Azure Cosmos DB for PostgreSQL besteht darin, den Zeitstempel selbst als Verteilungsspalte zu verwenden. Eine Hashverteilung basierend auf der Zeit verteilt Zeiten scheinbar zufällig auf verschiedene Shards, statt Zeitbereiche in Shards zusammenzuhalten. Abfragen, die Zeitangaben beinhalten, verweisen im Allgemeinen auf Zeitbereiche, z.B. auf die neuesten Daten. Diese Art von Hashverteilung führt zu Netzwerkmehraufwand.
Bewährte Methoden
- Wählen Sie einen Zeitstempel nicht als Verteilungsspalte aus. Wählen Sie eine andere Verteilungsspalte aus. Verwenden Sie in einer App mit mehreren Mandanten die Mandanten-ID, oder verwenden Sie in einer Echtzeit-App die Entitäts-ID.
- Verwenden Sie stattdessen die PostgreSQL-Tabellenpartitionierung für die Zeit. Unterteilen Sie eine große Tabelle mit zeitlich strukturierten Daten mithilfe der Tabellenpartitionierung in mehrere geerbte Tabellen mit jeweils verschiedenen Zeiträumen. Durch die Verteilung einer mit Postgres partitionierten Tabelle werden Shards für die geerbten Tabellen erstellt.
Nächste Schritte
- Erfahren Sie, wie die Zusammenstellung zwischen verteilten Daten zu einer schnelleren Ausführung von Abfragen führt.
- Ermitteln Sie die Verteilungsspalte einer verteilten Tabelle und andere nützliche Diagnoseabfragen.