Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die automatisierte Bereitstellung ist ein Prozess zum schnellen Bereitstellen und Konfigurieren der Ressourcen, die Sie zum Ausführen eines Azure Data Explorer-Clusters benötigen. Sie ist ein wichtiger Bestandteil eines DevOps- oder DataOps-Workflows. Der Bereitstellungsprozess erfordert weder eine manuelle Konfiguration des Clusters noch einen Benutzereingriff und lässt sich ganz einfach einrichten.
Sie können die automatisierte Bereitstellung verwenden, um einen vorkonfigurierten Cluster mit Daten als Teil einer CI/CD-Pipeline (Continuous Integration and Continuous Delivery) bereitzustellen. Diese Vorgehensweise hat unter anderem folgende Vorteile:
- Definieren und Verwalten mehrerer Umgebungen
- Nachverfolgen von Bereitstellungen in der Quellcodeverwaltung
- Einfacheres Rollback auf frühere Versionen
- Erleichterung automatisierter Tests durch Bereitstellung dedizierter Testumgebungen
Dieser Artikel enthält eine Übersicht über die verschiedenen Mechanismen zum Automatisieren der Bereitstellung von Azure Data Explorer-Umgebungen, einschließlich Infrastruktur, Schemaentitäten und Datenerfassung. Außerdem finden Sie hier Verweise auf die verschiedenen Tools und Techniken, die zum Automatisieren des Bereitstellungsprozesses verwendet werden.

Bereitstellen der Infrastruktur
Die Infrastrukturbereitstellung betrifft die Bereitstellung von Azure-Ressourcen wie Clustern, Datenbanken und Datenverbindungen. Es gibt verschiedene Arten von Infrastrukturbereitstellungen:
- Bereitstellung über eine Azure Resource Manager-Vorlage (ARM)
- Terraform-Bereitstellung
- Imperative Bereitstellung
ARM-Vorlagen und Terraform-Skripts sind die beiden deklarativen Hauptverfahren für die Bereitstellung der Azure Data Explorer-Infrastruktur.
ARM-Vorlagenbereitstellung
ARM-Vorlagen sind JSON- oder Bicep-Dateien, die die Infrastruktur und Konfiguration einer Bereitstellung definieren. Sie können die Vorlagen zum Bereitstellen von Clustern, Datenbanken, Datenverbindungen und vieler anderer Infrastrukturkomponenten verwenden. Weitere Informationen finden Sie unter Erstellen eines Azure Data Explorer-Clusters und einer Datenbank mithilfe einer Azure Resource Manage-Vorlage.
Sie können ARM-Vorlagen außerdem verwenden, um Befehlsskripts bereitzustellen, mit denen Sie ein Datenbankschema erstellen und Richtlinien definieren können. Weitere Informationen finden Sie unter Konfigurieren einer Datenbank mithilfe eines Skripts für die Kusto-Abfragesprache.
Weitere Beispielvorlagen finden Sie auf der Website Azure-Schnellstartvorlagen.
Terraform-Bereitstellung
Terraform ist ein Open-Source-Infrastructure-as-Code-Softwaretool. Es bietet einen konsistenten CLI-Workflow zum Verwalten von Clouddiensten. Terraform schreibt Cloud-APIs in deklarativen Konfigurationsdateien fest.
Terraform bietet die gleichen Funktionen wie ARM-Vorlagen. Sie können Terraform zum Bereitstellen von Clustern, Datenbanken, Datenverbindungen und anderen Infrastrukturkomponenten verwenden.
Sie können Terraform außerdem verwenden, um Befehlsskripts bereitzustellen, mit denen Sie ein Datenbankschema erstellen und Richtlinien definieren können.
Imperative Bereitstellung
Die Infrastruktur kann auch imperativ mithilfe einer der unterstützten Plattformen bereitgestellt werden:
Bereitstellen von Schemaentitäten
Die Bereitstellung von Schemaentitäten betrifft die Bereitstellung von Tabellen, Funktionen, Richtlinien und Berechtigungen. Sie können Entitäten erstellen oder aktualisieren, indem Sie Skripts ausführen, die aus Verwaltungsbefehlen bestehen.
Für die Automatisierung der Bereitstellung von Schemaentitäten stehen folgende Methoden zur Verfügung:
- ARM-Vorlagen
- Terraform-Skripts
- Kusto-Befehlszeilenschnittstelle
- SDKs
- Werkzeuge
- Sync Kusto: Verwenden Sie dieses interaktive Entwicklertool, um das Datenbankschema oder das Verwaltungsbefehlsskript zu extrahieren. Anschließend können Sie das extrahierte Steuerungsbefehlsskript für die automatische Bereitstellung verwenden.
- Delta Kusto: Rufen Sie dieses Tool in einer CI/CD-Pipeline auf. Sie kann zwei Quellen vergleichen, z. B. das Datenbankschema oder das Verwaltungsbefehlsskript, und ein Delta-Verwaltungsbefehlsskript berechnen. Anschließend können Sie das extrahierte Steuerungsbefehlsskript für die automatische Bereitstellung verwenden.
- Azure DevOps-Aufgabe für Azure Data Explorer
Erfassen von Daten
Manchmal müssen in Ihrem Cluster möglicherweise Daten erfasst werden – beispielsweise, um Daten für die Durchführung von Tests zu erfassen oder eine Umgebung neu zu erstellen. Für die Datenerfassung stehen folgende Methoden zur Verfügung:
- SDKs
- LightIngest (CLI-Tool)
- Auslösen einer Azure Data Factory-Pipeline
Beispielbereitstellung mit einer CI/CD-Pipeline
Im folgenden Beispiel wird eine Azure DevOps-CI/CD-Pipeline verwendet, die Tools ausführt, um die Bereitstellung von Infrastruktur, Schemaentitäten und Daten zu automatisieren. Dies ist ein Beispiel für eine Pipeline, die einen bestimmten Satz Tools verwendet, Sie können jedoch andere Tools und Schritte verwenden. Beispielsweise kann es in einer Produktionsumgebung sinnvoll sein, eine Pipeline zu erstellen, die keine Daten erfasst. Darüber hinaus können Sie der Pipeline auch weitere Schritte hinzufügen – etwa das Ausführen automatisierter Tests für den erstellten Cluster.
Hier werden die folgenden Tools verwendet:
| Bereitstellungstyp | Tool | Aufgabe |
|---|---|---|
| Infrastruktur | ARM-Vorlagen | Erstellen eines Clusters und einer Datenbank |
| Schemaentitäten | Kusto-Befehlszeilenschnittstelle | Erstellen von Tabellen in der Datenbank |
| Daten | LightIngest | Erfassen von Daten in einer einzelnen Tabelle |

Verwenden Sie die folgenden Schritte, um eine Pipeline zu erstellen:
Schritt 1: Erstellen einer Dienstverbindung
Definieren Sie eine Dienstverbindung vom Typ Azure Resource Manager. Legen Sie als Ziel der Verbindung das Abonnement und die Ressourcengruppe fest, in denen Sie Ihren Cluster bereitstellen möchten. Ein Azure-Dienstprinzipal wird erstellt. Dieser wird zum Bereitstellen der ARM-Vorlage verwendet. Sie können den gleichen Prinzipal zum Bereitstellen der Schemaentitäten und zum Erfassen von Daten verwenden. Sie müssen die Anmeldeinformationen explizit an die Kusto CLI- und LightIngest-Tools übergeben.
Schritt 2: Erstellen einer Pipeline
Definieren Sie die Pipeline (deploy-environ), die Sie zum Bereitstellen des Clusters, zum Erstellen von Schemaentitäten und zum Erfassen von Daten verwenden.
Um die Pipeline verwenden zu können, müssen die folgenden Geheimnisvariablen erstellt werden:
| Variablenname | Beschreibung |
|---|---|
clusterName |
Der Name des Azure Data Explorer-Clusters. |
serviceConnection |
Der Name der Azure DevOps-Verbindung, die zum Bereitstellen der ARM-Vorlage verwendet wird. |
appId |
Die Client-ID des Dienstprinzipals, der für die Interaktion mit dem Cluster verwendet wird. |
appSecret |
Das Geheimnis des Dienstprinzipals. |
appTenantId |
Die Mieter-ID des Dienstherrn. |
location |
Die Azure-Region, in der Sie den Cluster bereitstellen. Beispiel: eastus. |
resources:
- repo: self
stages:
- stage: deploy_cluster
displayName: Deploy cluster
variables: []
clusterName: specifyClusterName
serviceConnection: specifyServiceConnection
appId: specifyAppId
appSecret: specifyAppSecret
appTenantId: specifyAppTenantId
location: specifyLocation
jobs:
- job: e2e_deploy
pool:
vmImage: windows-latest
variables: []
steps:
- bash: |
nuget install Microsoft.Azure.Kusto.Tools -Version 5.3.1
# Rename the folder (including the most recent version)
mv Microsoft.Azure.Kusto.Tools.* kusto.tools
displayName: Download required Kusto.Tools Nuget package
- task: AzureResourceManagerTemplateDeployment@3
displayName: Deploy Infrastructure
inputs:
deploymentScope: 'Resource Group'
# subscriptionId and resourceGroupName are specified in the serviceConnection
azureResourceManagerConnection: $(serviceConnection)
action: 'Create Or Update Resource Group'
location: $(location)
templateLocation: 'Linked artifact'
csmFile: deploy-infra.json
overrideParameters: "-clusterName $(clusterName)"
deploymentMode: 'Incremental'
- bash: |
# Define connection string to cluster's database, including service principal's credentials
connectionString="https://$(clusterName).$(location).kusto.windows.net/myDatabase;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
# Execute a KQL script against the database
kusto.tools/tools/Kusto.Cli $connectionString -script:MyDatabase.kql
displayName: Create Schema Entities
- bash: |
connectionString="https://ingest-$(CLUSTERNAME).$(location).kusto.windows.net/;Fed=true;AppClientId=$(appId);AppKey=$(appSecret);TenantId=$(appTenantId)"
kusto.tools/tools/LightIngest $connectionString -table:Customer -sourcePath:customers.csv -db:myDatabase -format:csv -ignoreFirst:true
displayName: Ingest Data
Schritt 3: Erstellen einer ARM-Vorlage zum Bereitstellen des Clusters
Definieren Sie die ARM-Vorlage (deploy-infra.json), die Sie verwenden, um den Cluster in Ihrem Abonnement und in Ihrer Ressourcengruppe bereitzustellen.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"clusterName": {
"type": "string",
"minLength": 5
}
},
"variables": {
},
"resources": [
{
"name": "[parameters('clusterName')]",
"type": "Microsoft.Kusto/clusters",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"sku": {
"name": "Dev(No SLA)_Standard_E2a_v4",
"tier": "Basic",
"capacity": 1
},
"resources": [
{
"name": "myDatabase",
"type": "databases",
"apiVersion": "2021-01-01",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Kusto/clusters', parameters('clusterName'))]"
],
"kind": "ReadWrite",
"properties": {
"softDeletePeriodInDays": 365,
"hotCachePeriodInDays": 31
}
}
]
}
]
}
Schritt 4: Erstellen eines KQL-Skripts zum Erstellen der Schemaentitäten
Definieren Sie das KQL-Skript (MyDatabase.kql), das Sie verwenden, um die Tabellen in den Datenbanken zu erstellen.
.create table Customer(CustomerName:string, CustomerAddress:string)
// Set the ingestion batching policy to trigger ingestion quickly
// This is to speedup reaction time for the sample
// Do not do this in production
.alter table Customer policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
.create table CustomerLogs(CustomerName:string, Log:string)
Schritt 5: Erstellen eines KQL-Skripts zum Erfassen von Daten
Erstellen Sie die zu erfassende CSV-Datendatei (customer.csv).
customerName,customerAddress
Contoso Ltd,Paris
Datum Corporation,Seattle
Fabrikam,NYC
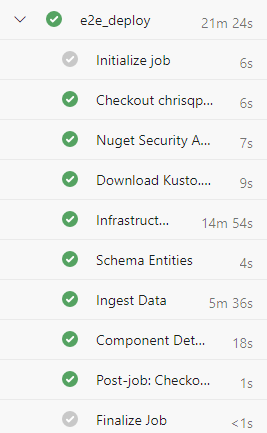
Sie erstellen den Cluster unter Verwendung der Anmeldeinformationen des Dienstprinzipals, die Sie in der Pipeline angegeben haben. Führen Sie die unter Verwalten der Berechtigungen für Datenbanken in Azure-Daten-Explorer beschriebenen Schritte aus, um Ihren Benutzern Berechtigungen zu erteilen.
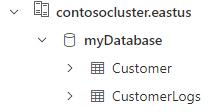
Sie können die Bereitstellung überprüfen, indem Sie eine Abfrage für die Tabelle Customer ausführen. Daraufhin sollten die drei Datensätze angezeigt werden, die aus der CSV-Datei importiert wurden.
Zugehöriger Inhalt
- Erstellen eines Azure Data Explorer-Clusters und einer Datenbank mithilfe einer Azure Resource Manager-Vorlage.
- Konfigurieren einer Datenbank mithilfe eines KQL-Skripts