Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie sich auf einen Azure regionalen Ausfall vorbereiten, indem Sie Ihre Azure Data Explorer Ressourcen, Verwaltung und Aufnahme in verschiedenen Azure Regionen replizieren. Der Artikel enthält ein Beispiel für die Datenaufnahme mit Azure Event Hubs. Außerdem wird die Kostenoptimierung für verschiedene Architekturkonfigurationen erläutert. Eine ausführlichere Betrachtung von Architekturaspekten und Wiederherstellungslösungen finden Sie in der Übersicht über die Geschäftskontinuität.
Vorbereiten auf einen regionalen Azure-Ausfall zum Schutz Ihrer Daten
Azure Data Explorer bietet keinen automatischen Schutz vor dem Ausfall einer gesamten Azure-Region. Eine solche Störung kann durch eine Naturkatastrophe (beispielsweise ein Erdbeben) verursacht werden. Wenn Sie eine Notfallwiederherstellungslösung benötigen, führen Sie die folgenden Schritte aus, um die Geschäftskontinuität sicherzustellen. In diesen Schritten replizieren Sie Ihre Cluster, Verwaltungsaktivitäten und die Datenaufnahme in zwei Azure gekoppelten Regionen.
- Erstellen Sie mindestens zwei unabhängige Cluster in zwei Azure-Regionspaaren.
- Replizieren Sie alle Verwaltungsaktivitäten wie etwa die Erstellung neuer Tabellen oder die Verwaltung von Benutzerrollen in jedem Cluster.
- Erfassen Sie Daten parallel in jedem Cluster.
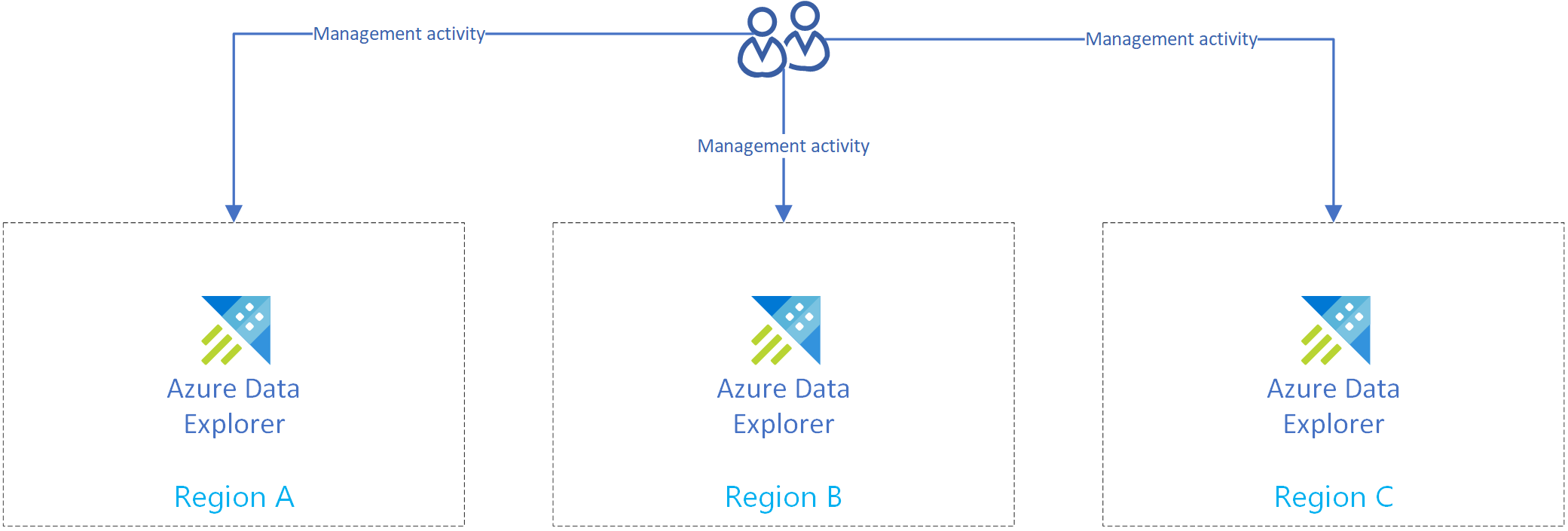
Erstellen mehrerer unabhängiger Cluster
Erstellen Sie mehrere Azure Data Explorer-Cluster in mehreren Regionen. Erstellen Sie mindestens zwei dieser Cluster in Azure gekoppelten Regionen.
Das folgende Diagramm zeigt drei Replikatcluster in drei verschiedenen Regionen.

Replizieren von Verwaltungsaktivitäten
Replizieren Sie Verwaltungsaktivitäten, sodass jedes Replikat dieselbe Clusterkonfiguration aufweist.
Erstellen Sie die gleichen Ressourcen für jedes Replikat:
- Datenbanken: Verwenden Sie das Azure-Portal oder eine der SDKs, um eine neue Datenbank zu erstellen.
- Tabellen
- Zuordnungen
- Richtlinien
Verwalten Sie die Authentifizierung und Autorisierung für jedes Replikat.
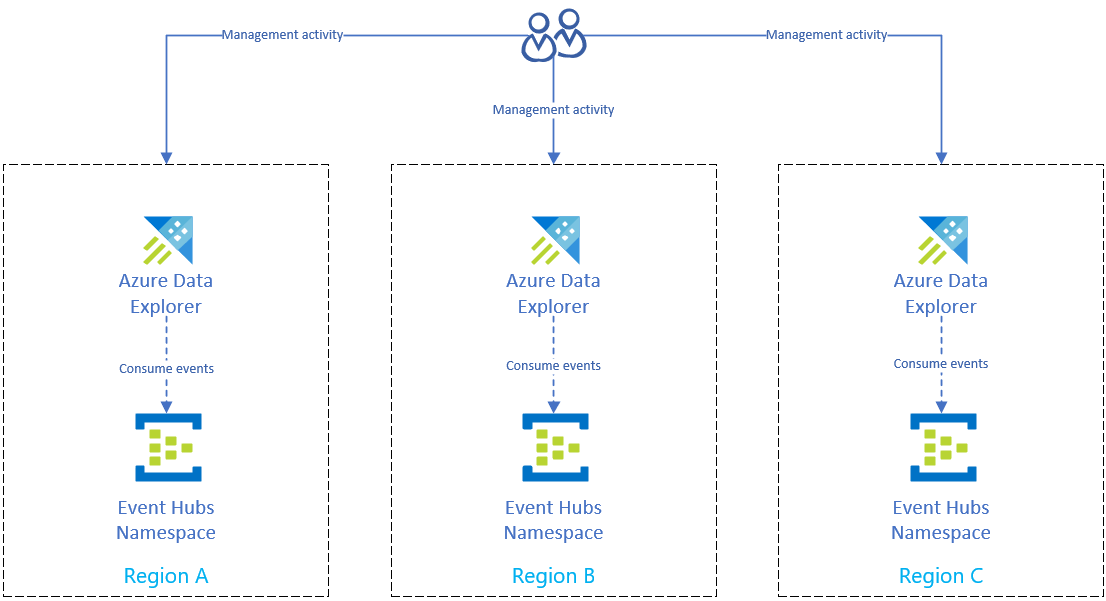
Notfallwiederherstellungslösung mit Event Hubs-Datenerfassung
Nachdem Sie Vorbereiten auf einen regionalen Azure-Ausfall zum Schutz Ihrer Daten abgeschlossen haben, speichert Azure Data Explorer Ihre Daten und Verwaltungsdaten über mehrere Regionen hinweg. Wenn ein Ausfall in einer Region vorhanden ist, können Azure Data Explorer die anderen Replikate verwenden.
Datenerfassung mit Event Hubs einrichten
Zum Erfassen von Daten aus Azure Event Hubs in den Azure Data Explorer-Clustern der einzelnen Regionen replizieren Sie zunächst Ihr Azure Event Hubs-Setup in jeder Region. Konfigurieren Sie dann das Azure Data Explorer-Replikat jeder Region so, dass Daten aus den entsprechenden Event Hubs erfasst werden.
Hinweis
Die Datenerfassung über Azure Event Hubs, IoT Hub oder Azure Storage ist zuverlässig. Wenn ein Cluster nicht rechtzeitig verfügbar ist, holt es dies später nach und fügt alle ausstehenden Nachrichten oder Blobs ein. Dieser Prozess basiert auf dem Setzen von Prüfpunkten.
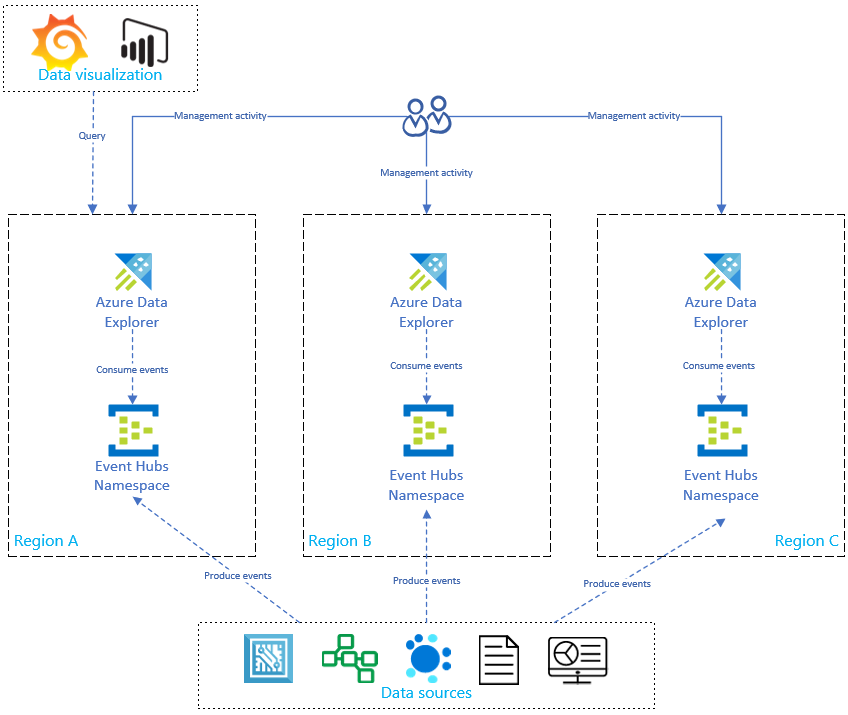
Dieses Diagramm zeigt, dass Ihre Datenquellen Ereignisse für Event Hubs in allen Regionen erzeugen, und jedes Azure Data Explorer Replikat verwendet diese Ereignisse. Datenvisualisierungskomponenten wie Power BI, Grafana oder SDK-gestützte Web-Apps können ein Replikat abfragen.
Optimieren der Kosten
Jetzt können Sie Ihre Replikate mithilfe einiger der folgenden Methoden optimieren:
- Erstellen Sie eine On-Demand-Datenwiederherstellungskonfiguration.
- Starten und Beenden der Replikate.
- Implementieren Sie einen hoch verfügbaren Anwendungsdienst.
- Optimieren Sie die Kosten in einer aktiven Konfiguration.
Erstellen einer Konfiguration mit bedarfsgesteuerter Datenwiederherstellung
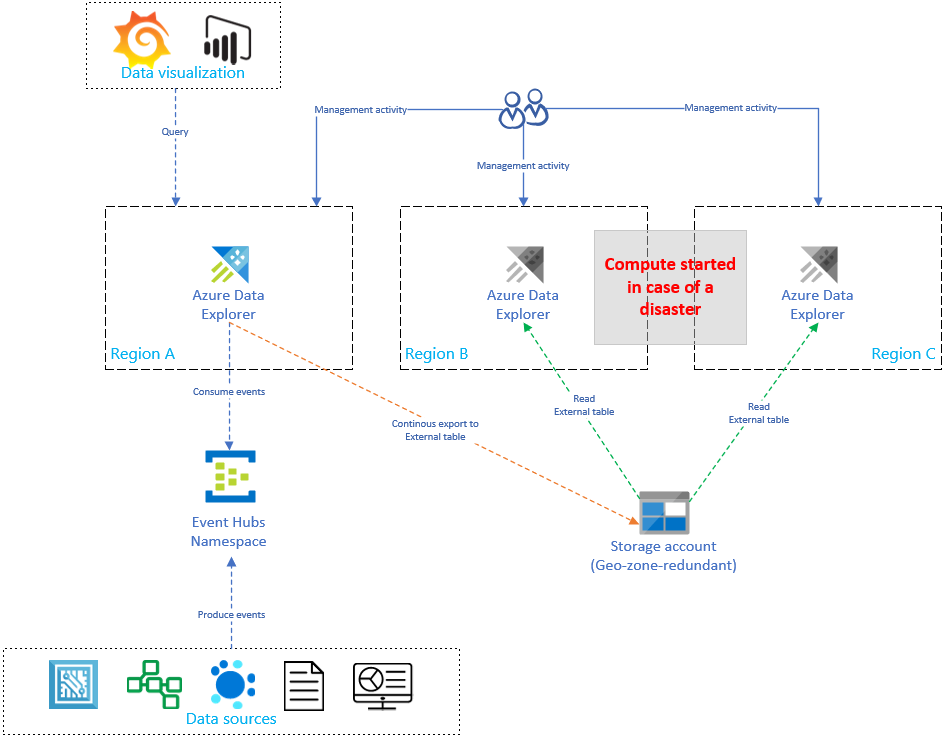
Das Replizieren und Aktualisieren des Azure Data Explorer Setups erhöht linear die Kosten, da die Anzahl der Replikate zunimmt. Um die Kosten zu optimieren, implementieren Sie eine Architekturvariante, die Zeit, Failover und Kosten ausgleicht. Eine On-Demand-Datenwiederherstellungskonfiguration optimiert die Kosten mithilfe passiver Azure Data Explorer Replikate. Diese Replikate werden nur aktiviert, wenn in der primären Region (beispielsweise in der Region A) ein Notfall vorliegt. Die Replikate in Den Regionen B und C müssen nicht 24/7 aktiv sein, wodurch die Kosten erheblich reduziert werden. Aber in den meisten Fällen übernehmen diese Replikate nicht die Verarbeitung, sondern der primäre Cluster. Weitere Informationen finden Sie unter Konfiguration mit bedarfsgesteuerter Datenwiederherstellung.
Im folgenden Diagramm erfasst nur ein Cluster Daten aus Event Hubs. Vom primären Cluster in der Region A werden alle Daten mittels kontinuierlichem Datenexport in ein Speicherkonto exportiert. Die sekundären Replikate greifen mithilfe externer Tabellen auf die Daten zu.
Starten und Beenden der Replikate
Starten und beenden Sie die sekundären Replikate mithilfe einer der folgenden Methoden:
Azure Data Explorer-Connector für Power Automate (Vorschauversion)
Schaltfläche Beenden auf der Registerkarte Übersicht des Azure-Portals. Weitere Informationen finden Sie unter Beenden und Neustarten des Clusters.
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>
Implementieren eines hochverfügbaren Anwendungsdiensts
Erstellen des Azure App Service-BCDR-Clients
In diesem Abschnitt erfahren Sie, wie Sie eine Instanz von Azure App Service erstellen, die eine Verbindung mit einem einzelnen primären und mehreren sekundären Azure Data Explorer-Clustern unterstützt. In der folgenden Abbildung sehen Sie das Azure App Service-Setup:
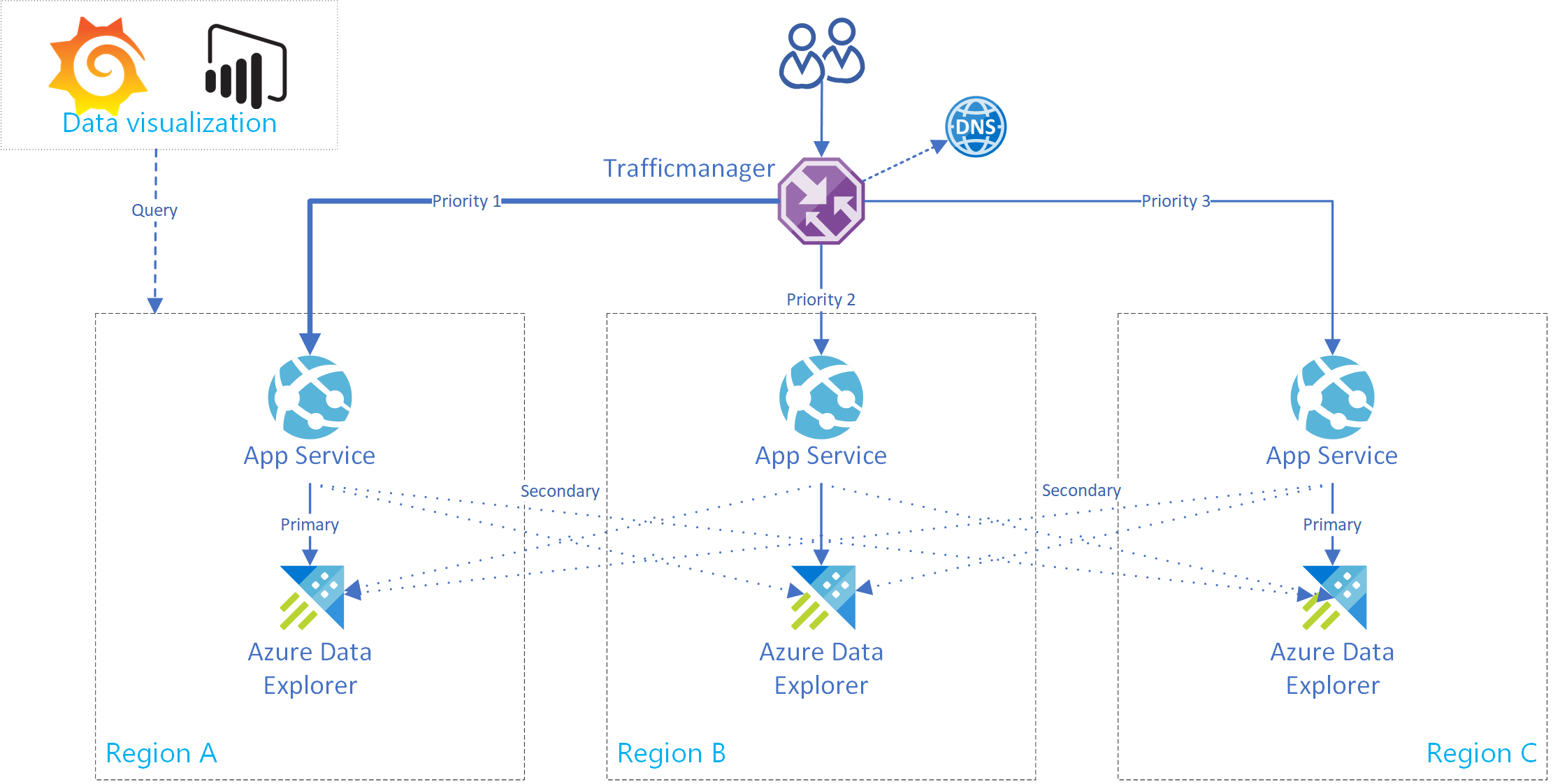
Tipp
Durch mehrere Verbindungen zwischen Replikaten im gleichen Dienst erhöht sich die Verfügbarkeit. Dieses Setup ist nicht nur bei regionalen Ausfällen hilfreich.
Verwenden Sie diese Codebausteine für einen App-Dienst. Verwenden Sie die AdxBcdrClient-Klasse , um einen Multiclusterclient zu implementieren. Jede Abfrage, die dieser Client ausführt, wird zuerst an den primären Cluster gesendet. Wenn ein Fehler auftritt, wird die Abfrage an sekundäre Replikate gesendet.
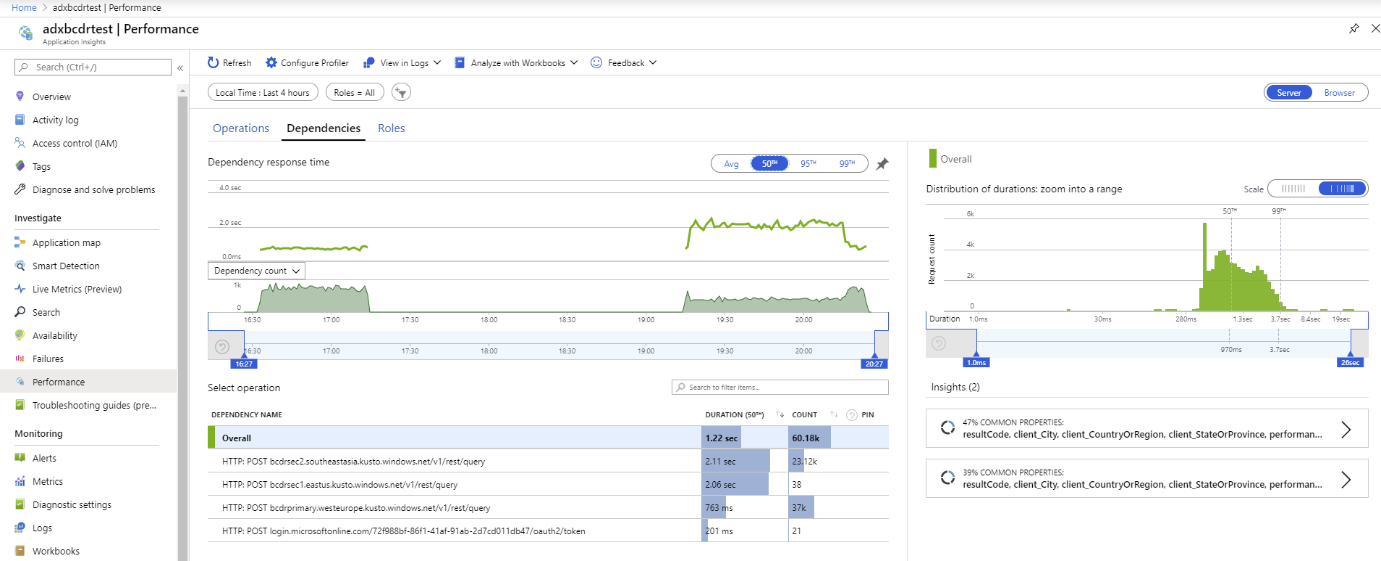
Verwenden Sie benutzerdefinierte Metriken für Anwendungserkenntnisse , um die Leistung und Anforderungsverteilung an primäre und sekundäre Cluster zu messen.
Testen des Azure App Service-BCDR-Clients
Der folgende Test verwendet mehrere Azure Data Explorer Replikate. Nach einem simulierten Ausfall von primären und sekundären Clustern verhält sich der BCDR-Client des App-Diensts wie beabsichtigt.
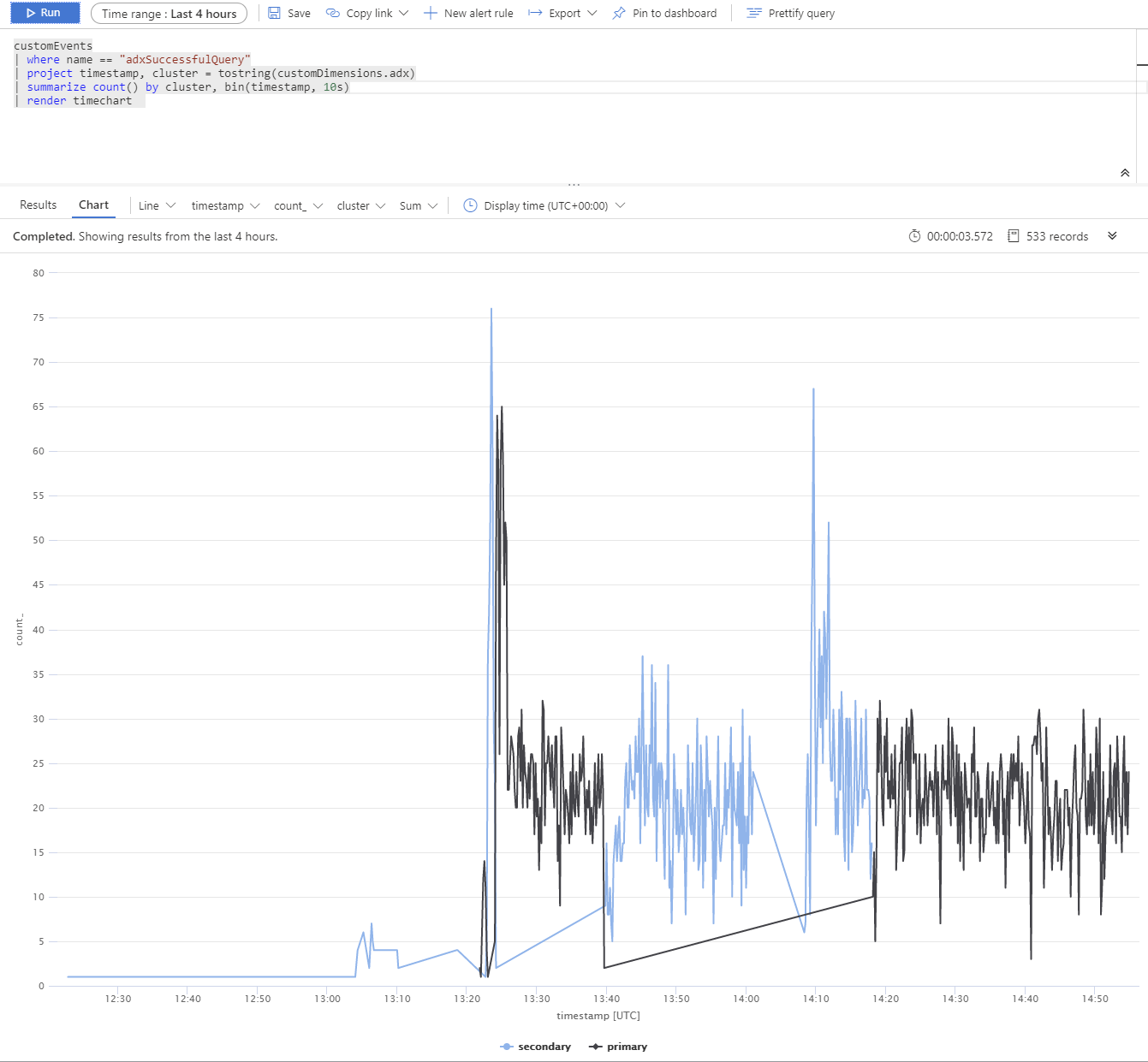
Die Azure Data Explorer-Cluster sind auf „Europa, Westen“ (2x D14v2, primär), „Asien, Südosten“ und „USA, Osten“ (2x D11v2) verteilt.
Hinweis
Langsamere Antwortzeiten sind auf unterschiedliche SKUs und weltweite Abfragen zurückzuführen.
Ausführen von dynamischem oder statischem Routing
Verwenden Sie Azure Traffic Manager Routingmethoden für dynamisches oder statisches Anforderungsrouting. Azure Traffic Manager ist ein DNS-basierter Datenverkehrsausgleich, den Sie zum Verteilen von App Service-Datenverkehr verwenden können. Dieser Datenverkehr wird für Dienste in Azure-Regionen auf der ganzen Welt optimiert. Gleichzeitig profitieren Sie von Hochverfügbarkeit und hoher Reaktionsfähigkeit.
Sie können auch Azure Front Door-basiertes Routing verwenden. Eine Gegenüberstellung dieser beiden Methoden finden Sie unter Lastenausgleich mit der Azure-Suite für die Anwendungsbereitstellung.
Kosten in einer Active-Active-Konfiguration optimieren
Bei Verwendung einer Aktiv/Aktiv-Konfiguration für die Notfallwiederherstellung steigen die Kosten linear an. Darin enthalten sind die Kosten für Knoten, Speicher und Markup sowie höhere Netzwerkkosten für die Bandbreite.
Verwenden Sie die optimierte Autoskalierung, um Kosten zu optimieren
Verwenden Sie das Feature Optimierte Autoskalierung, um die horizontale Skalierung für die sekundären Cluster zu konfigurieren. Dimensionieren Sie sekundäre Cluster so, dass sie die Erfassungslast bewältigen können. Wenn der primäre Cluster nicht erreichbar ist, erhalten sekundäre Cluster mehr Datenverkehr und skalierung entsprechend der Konfiguration.
In diesem Beispiel spart die optimierte Autoskalierung ungefähr 50% Kosten im Vergleich zur Verwendung desselben horizontalen und vertikalen Maßstabs für alle Replikate.