Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Data Explorer ist ein schneller, vollständig verwalteter Datenanalysedienst. Es bietet Echtzeitanalysen für große Datenmengen, die aus vielen Quellen streamen, z. B. Anwendungen, Websites und IoT-Geräte.
Um Daten aus einer Datenbank in Oracle Server, Netezza, Teradata oder SQL Server in Azure Data Explorer zu kopieren, müssen Sie große Datenmengen aus mehreren Tabellen laden. In der Regel müssen die Daten in den einzelnen Tabellen partitioniert werden, um Zeilen mit mehreren Threads parallel aus einer einzelnen Tabelle laden zu können. In diesem Artikel wird eine Vorlage für diese Szenarios beschrieben.
Azure Data Factory-Vorlagen sind vordefinierte Data Factory-Pipelines. Diese Vorlagen können Ihnen helfen, schnell mit Data Factory zu beginnen und die Entwicklungszeit für Datenintegrationsprojekte zu reduzieren.
Sie erstellen die Vorlage zum Massenkopieren aus der Datenbank in Azure Data Explorer mithilfe von Lookup- und ForEach-Aktivitäten. Zum schnelleren Kopieren von Daten können Sie die Vorlage verwenden, um viele Pipelines pro Datenbank oder pro Tabelle zu erstellen.
Von Bedeutung
Achten Sie darauf, das Tool zu verwenden, das für die Datenmenge geeignet ist, die Sie kopieren möchten.
- Verwenden Sie die Vorlage " Massenkopie aus Datenbank in Azure Data Explorer ", um große Datenmengen aus Datenbanken wie SQL Server und Google BigQuery in Azure Data Explorer zu kopieren.
- Verwenden Sie das Data Factory Copy Data Tool , um einige Tabellen mit kleinen oder moderaten Datenmengen in Azure Data Explorer zu kopieren.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Datenbank. Erstellen Sie einen Cluster und eine Datenbank.
- Eine Datenfabrik. Erstellen Sie eine Datenfabrik.
- Eine Datenquelle.
Erstellen von ControlTableDataset
ControlTableDataset gibt an, welche Daten aus der Quelle in das Ziel in der Pipeline kopiert werden. Die Anzahl der Zeilen gibt die Gesamtanzahl der Pipelines an, die zum Kopieren der Daten erforderlich sind. Sie sollten ControlTableDataset als Teil der Quelldatenbank definieren.
Ein Beispiel für das SQL Server-Quelltabellenformat ist im folgenden Code dargestellt:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Die Codeelemente werden in der folgenden Tabelle beschrieben:
| Eigentum | BESCHREIBUNG | Beispiel |
|---|---|---|
| PartitionId | Der Kopierauftrag | 1 |
| SourceQuery | Die Abfrage, die angibt, welche Daten während der Pipelinelaufzeit kopiert werden | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | Der Name der Zieltabelle | MyAdxTable |
Wenn Ihr ControlTableDataset in einem anderen Format vorliegt, erstellen Sie ein vergleichbares ControlTableDataset für Ihr Format.
Verwenden der Vorlage zum Massenkopieren aus einer Datenbank in Azure Data Explorer
Wählen Sie im Bereich " Erste Schritte " die Option "Pipeline aus Vorlage erstellen" aus , um den Vorlagenkatalogbereich zu öffnen.
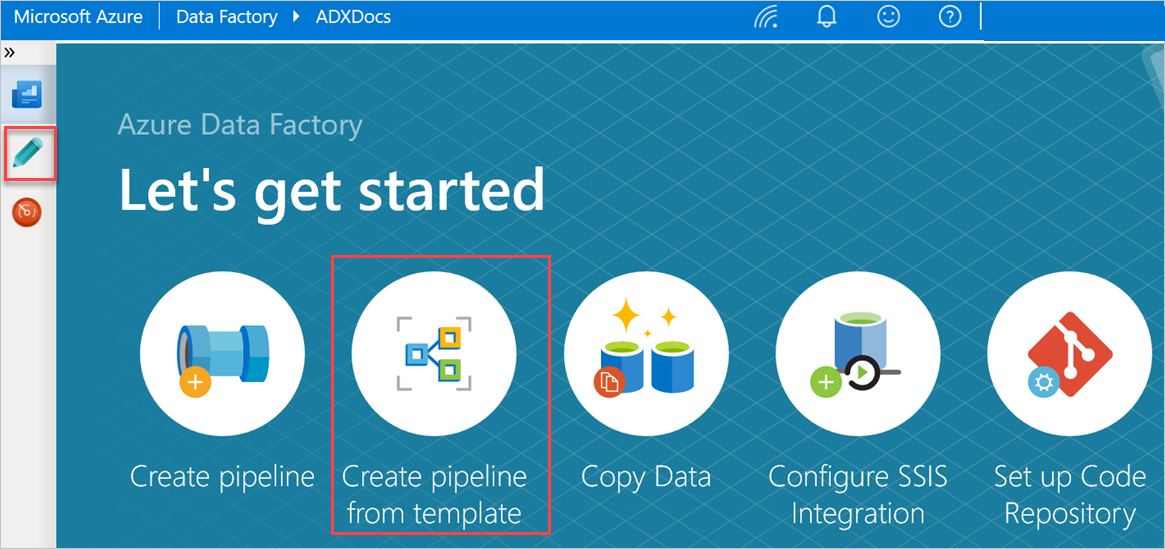
Wählen Sie die Vorlage "Massenkopie von Datenbank zu Azure Data Explorer" aus.
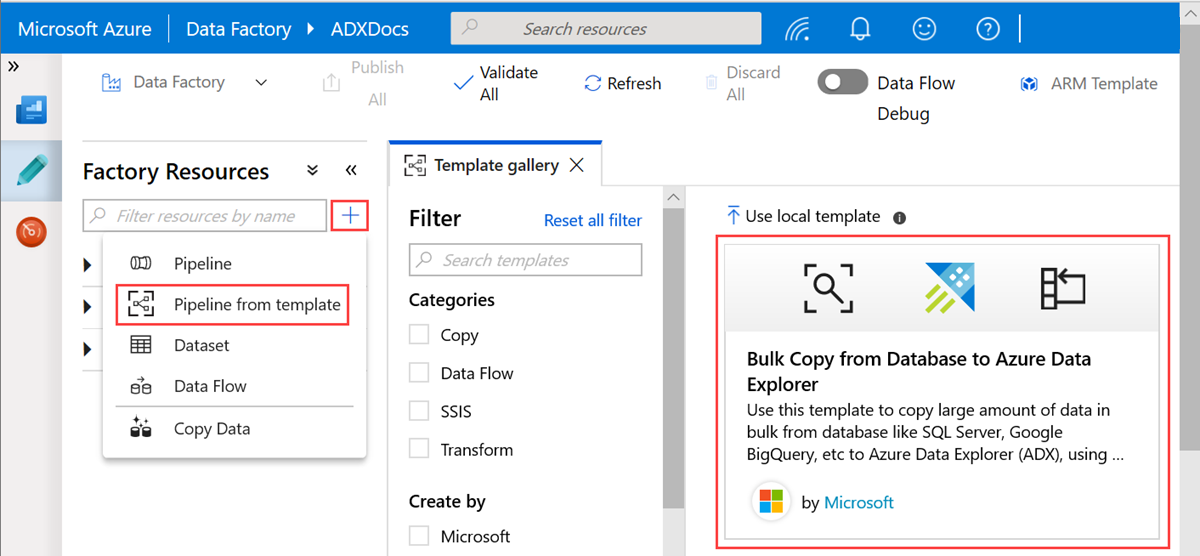
Geben Sie im Bereich "Massenkopie aus Datenbank in Azure Data Explorer" unter "Benutzereingaben" die Datensätze wie folgt an:
a) Wählen Sie in der Dropdownliste " ControlTableDataset " den verknüpften Dienst mit der Steuerelementtabelle aus, der angibt, welche Daten aus der Quelle in das Ziel kopiert werden und wo sie im Ziel platziert werden.
b. Wählen Sie in der Dropdownliste "SourceDataset " den verknüpften Dienst mit der Quelldatenbank aus.
Abschnitt c. Wählen Sie in der Dropdownliste "AzureDataExplorerTable " die Azure Data Explorer-Tabelle aus. Wenn das Dataset nicht vorhanden ist, erstellen Sie den verknüpften Azure-Daten-Explorer-Dienst , um das Dataset hinzuzufügen.
d. Wählen Sie Diese Vorlage verwenden aus.
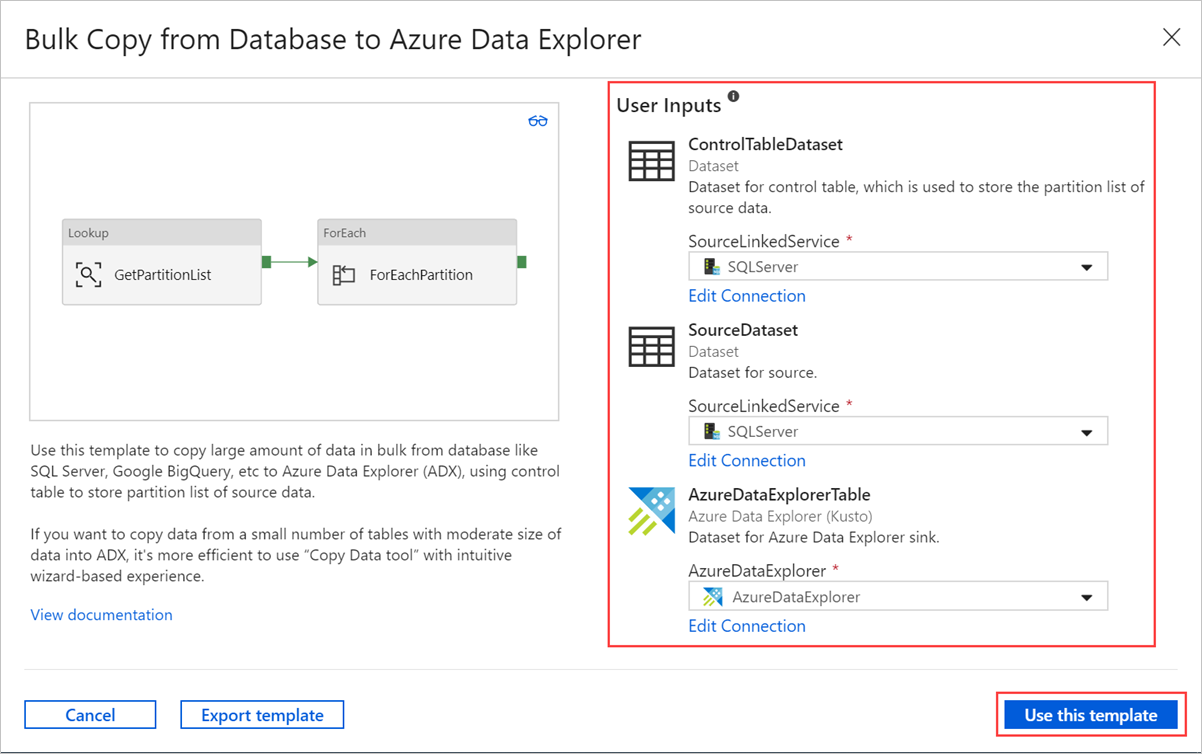
Wählen Sie einen Bereich in der Canvas außerhalb der Aktivitäten aus, um auf die Vorlagenpipeline zuzugreifen. Wählen Sie die Registerkarte "Parameter " aus, um die Parameter für die Tabelle einzugeben, einschließlich Name (Steuerelementtabellenname) und Standardwert (Spaltennamen).
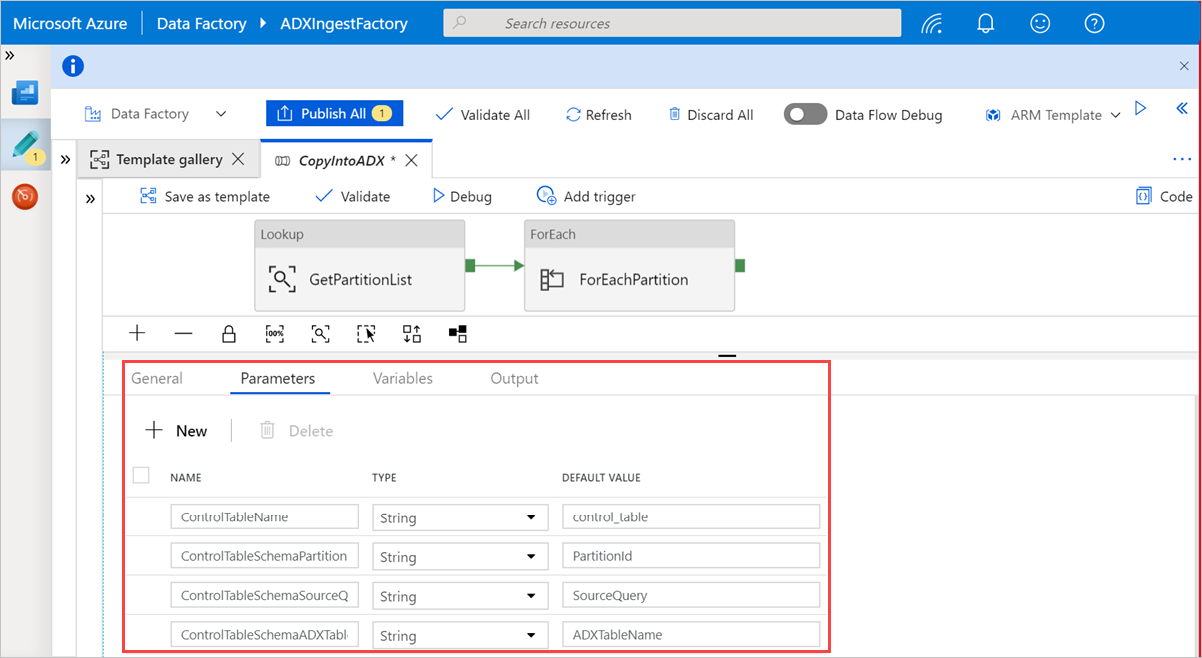
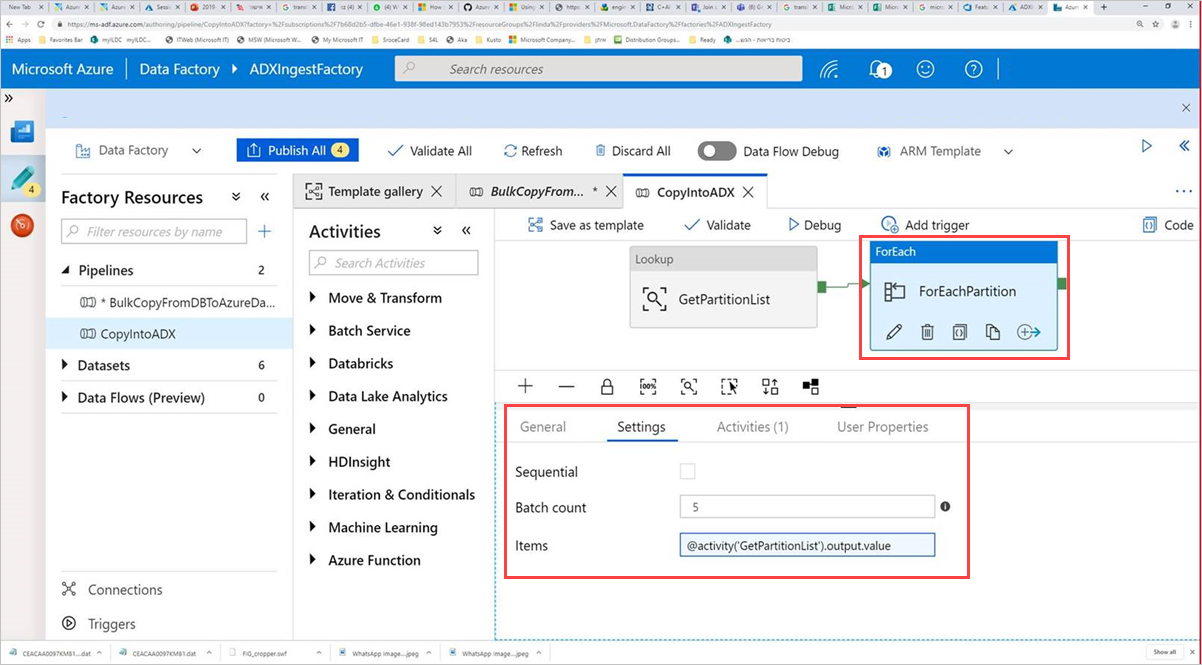
Wählen Sie unter Lookup die Option GetPartitionList aus, um die Standardeinstellungen anzuzeigen. Die Abfrage wird automatisch erstellt.
Wählen Sie die Befehlsaktivität ForEachPartition aus, wählen Sie die Registerkarte "Einstellungen " aus, und führen Sie dann die folgenden Aktionen aus:
a) Geben Sie im Feld "Batchanzahl " eine Zahl zwischen 1 und 50 ein. Diese Auswahl bestimmt die Anzahl der Pipelines, die parallel ausgeführt werden, bis die Anzahl der ControlTableDataset-Zeilen erreicht ist.
b. Um sicherzustellen, dass die Pipelinebatches parallel ausgeführt werden, aktivieren Sie nicht das Kontrollkästchen Sequenziell.
Tipp
Die bewährte Methode besteht darin, viele Pipelines parallel auszuführen, damit Ihre Daten schneller kopiert werden können. Um die Effizienz zu erhöhen, partitionieren Sie die Daten in der Quelltabelle, und weisen Sie je nach Datum und Tabelle eine Partition pro Pipeline zu.
Wählen Sie " Alle überprüfen" aus, um die Azure Data Factory-Pipeline zu überprüfen, und zeigen Sie dann das Ergebnis im Bereich "Pipelineüberprüfungsausgabe " an.
Validiere Vorlagenpipelines.
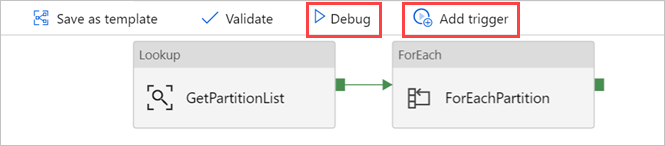
Wählen Sie bei Bedarf "Debuggen" und dann " Trigger hinzufügen " aus, um die Pipeline auszuführen.
Sie können jetzt die Vorlage verwenden, um große Datenmengen effizient aus Ihren Datenbanken und Tabellen zu kopieren.
Verwandte Inhalte
- Erfahren Sie mehr über den Azure Data Explorer-Connector für Azure Data Factory.
- Bearbeiten sie verknüpfte Dienste, Datasets und Pipelines in der Data Factory-Benutzeroberfläche.
- Abfragen von Daten in der Azure Data Explorer-Web-UI.