Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Apache Kafka ist eine verteilte Streamingplattform zum Erstellen von zuverlässig Echtzeit-Streaming-Datenpipelines, mit denen Daten zwischen Systemen oder Anwendungen verschoben werden. Kafka Connect ist ein Tool zum skalierbaren und zuverlässigen Streamen von Daten zwischen Apache Kafka und anderen Datensystemen. Die Kusto-Kafka-Senke dient als Connector für Kafka und erfordert keine Verwendung von Code. Laden Sie die Sink-Connector-Jar-Datei vom Git-Repository oder vom Confluent-Connector-Hub herunter.
In diesem Artikel wird veranschaulicht, wie Sie Daten mit Kafka erfassen. Sie verwenden hierfür ein eigenständiges Docker-Setup, um die Einrichtung des Kafka-Clusters und Kafka-Connectorclusters zu vereinfachen.
Weitere Informationen finden Sie im Git-Repository und in den Versionsangaben zum Connector.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Einen Azure Data Explorer-Cluster und eine Datenbank mit den Standardrichtlinien für den Cache und die Aufbewahrung.
- Azure CLI.
- Docker und Docker Compose.
Microsoft Entra-Dienstprinzipal erstellen
Der Microsoft Entra-Dienstprinzipal kann über das Azure-Portal oder programmgesteuert (wie im folgenden Beispiel) erstellt werden.
Dieser Dienstprinzipal ist die Identität, die vom Connector zum Schreiben von Daten in Ihre Tabelle in Kusto genutzt wird. Sie gewähren diesem Dienstprinzipal Berechtigungen für den Zugriff auf Kusto-Ressourcen.
Melden Sie sich per Azure CLI an Ihrem Azure-Abonnement an. Führen Sie anschließend im Browser die Authentifizierung durch.
az loginWählen Sie das Abonnement aus, um den Prinzipal zu hosten. Dieser Schritt ist erforderlich, wenn Sie über mehrere Abonnements verfügen.
az account set --subscription YOUR_SUBSCRIPTION_GUIDErstellen Sie den Dienstprinzipal. In diesem Beispiel wird der Dienstprinzipal als
my-service-principalbezeichnet.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Kopieren Sie aus den zurückgegebenen JSON-Daten
appId,passwordundtenantfür die zukünftige Verwendung.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Sie haben Ihre Microsoft Entra-Anwendung und den Dienstprinzipal erstellt.
Erstellen einer Zieltabelle
Verwenden Sie den folgenden Befehl in Ihrer Abfrageumgebung, um die Tabelle
Stormszu erstellen:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Erstellen Sie mit dem folgenden Befehl die entsprechende Tabellenzuordnung
Storms_CSV_Mappingfür erfasste Daten:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Erstellen Sie eine Batchverarbeitungsrichtlinie auf der Tabelle für die konfigurierbare Warteschlangenlatenz der Erfassung.
Tipp
Die Richtlinie zur Batchverarbeitung ist eine Leistungsoptimierung mit drei Parametern. Die erste erfüllte Bedingung löst die Erfassung in der Tabelle aus.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Verwenden Sie den Dienstprinzipal aus Erstellen eines Microsoft Entra-Dienstprinzipals, um die Berechtigung zum Verwenden der Datenbank zu gewähren.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Führen Sie das Labor aus
Im folgenden Lab können Sie ausprobieren, wie Sie mit der Erstellung von Daten beginnen, den Kafka-Connector einrichten und diese Daten streamen. Dann können Sie die erfassten Daten anzeigen.
Klonen des Git-Repositorys
Klonen Sie das Git-Repository des Labs.
Erstellen Sie auf Ihrem Computer ein lokales Verzeichnis.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKlonen Sie das Repository.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Inhalt des geklonten Repositorys
Führen Sie den folgenden Befehl aus, um den Inhalt des geklonten Repositorys aufzulisten:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Das Ergebnis dieser Suche lautet wie folgt:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Überprüfen der Dateien im geklonten Repository
In den folgenden Abschnitten werden die wichtigen Teile der Dateien in der Dateistruktur erläutert.
adx-sink-config.json
Diese Datei enthält die Kusto-Sink-Eigenschaftendatei, in der Sie bestimmte Konfigurationsdetails aktualisieren:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Ersetzen Sie die Werte für die folgenden Attribute gemäß Ihrer Einrichtung: aad.auth.authority, aad.auth.appid, aad.auth.appkey, kusto.tables.topics.mapping (Datenbankname), kusto.ingestion.url und kusto.query.url.
Connector: Dockerfile
Diese Datei enthält die Befehle zum Generieren des Docker-Images für die Connectorinstanz. Sie enthält den Download des Connectors aus dem Releaseverzeichnis des Git-Repositorys.
Verzeichnis „Sturmereignisse-Erzeuger“
Dieses Verzeichnis enthält ein Go-Programm, mit dem die lokale Datei „StormEvents.csv“ gelesen wird und die Daten in einem Kafka-Thema veröffentlicht werden.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Starten der Container
Starten Sie die Container in einem Terminal:
docker-compose upDie Produceranwendung beginnt mit dem Senden von Ereignissen an das Thema
storm-events. Es sollten Protokolle angezeigt werden, die den folgenden Protokollen ähneln:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Führen Sie den folgenden Befehl in einem separaten Terminal aus, um die Protokolle zu überprüfen:
docker-compose logs -f | grep kusto-connect
Starten des Connectors
Verwenden Sie einen Kafka Connect-REST-Aufruf, um den Connector zu starten.
Starten Sie den Sink-Task in einem separaten Terminal, indem Sie folgenden Befehl ausführen:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsFühren Sie zum Überprüfen des Status den folgenden Befehl in einem separaten Terminal aus:
curl http://localhost:8083/connectors/storm/status
Der Connector beginnt, Datenaufnahmeprozesse in die Warteschlange zu stellen.
Hinweis
Erstellen Sie eine Problemmeldung, falls bei Ihnen Probleme mit dem Protokollconnector auftreten.
Verwaltete Identität
Standardmäßig verwendet der Kafka-Connector die Anwendungsmethode für die Authentifizierung während der Aufnahme. So authentifizieren Sie sich mithilfe der verwalteten Identität:
Weisen Sie Ihrem Cluster eine verwaltete Identität zu, und erteilen Sie Ihrem Speicherkonto Leseberechtigungen. Weitere Informationen finden Sie unter "Erfassen von Daten mithilfe der verwalteten Identitätsauthentifizierung".
Legen Sie in Ihrer adx-sink-config.json Datei
aad.auth.strategymanaged_identityund stellen Sie sicher, dassaad.auth.appidauf die ID des verwalteten Identitätsclients (Anwendung) gesetzt ist.Verwenden Sie ein Metadatendiensttoken für private Instanzen anstelle des Microsoft Entra-Dienstprinzipals.
Hinweis
Bei der Verwendung einer Managed Identity ruft der Connector automatisch appId und tenant aus dem Aufrufkontext ab, sodass Sie kein Passwort eingeben müssen.
Abfragen und Überprüfen von Daten
Bestätigen der Datenerfassung
Sobald die Daten in der
Storms-Tabelle angekommen sind, bestätigen Sie die Übertragung der Daten, indem Sie die Zeilenzahl überprüfen:Storms | countVergewissern Sie sich, dass der Erfassungsprozess keine Fehler aufweist:
.show ingestion failuresProbieren Sie einige Abfragen aus, nachdem Daten angezeigt werden.
Abfragen der Daten
Führen Sie die folgende Abfrage aus, um alle Datensätze anzuzeigen:
Storms | take 10Verwenden Sie
whereundproject, um die spezifischen Daten zu filtern:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdVerwenden Sie den Operator
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart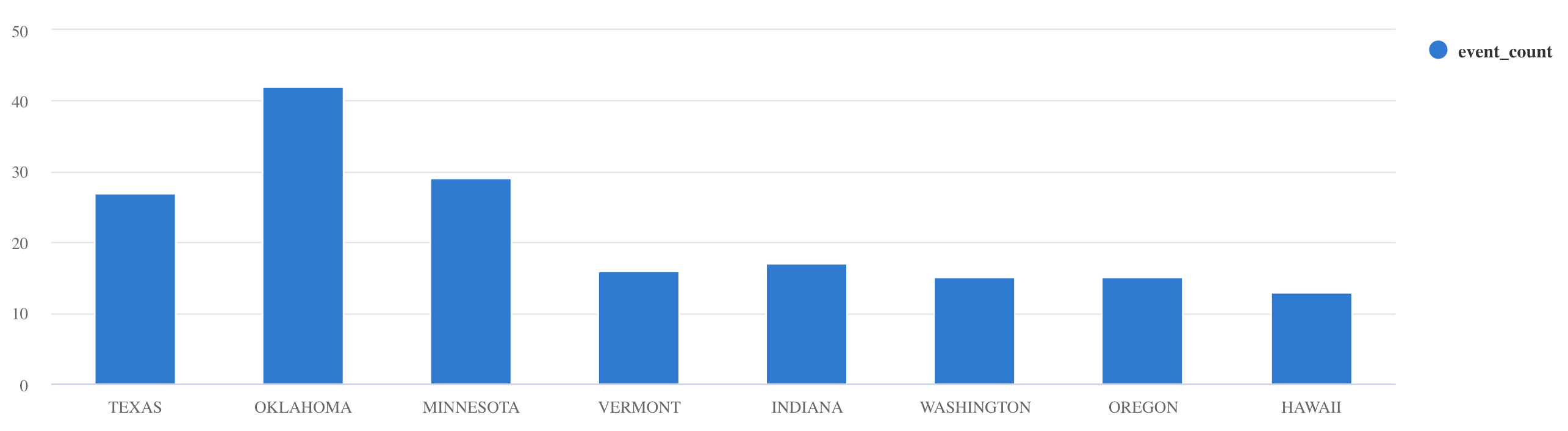
Weitere Abfragebeispiele und eine Anleitung finden Sie unter Schreiben von Abfragen in KQL und in der Dokumentation zur Kusto-Abfragesprache.
Zurücksetzen
Führen Sie zum Zurücksetzen die folgenden Schritte aus:
- Anhalten der Container (
docker-compose down -v) - Löschen (
drop table Storms) - Neuerstellen der Tabelle
Storms - Tabellenzuordnung neu erstellen
- Neustarten von Containern (
docker-compose up)
Bereinigen von Ressourcen
Um die Azure Data Explorer-Ressourcen zu löschen, verwenden Sie az kusto cluster delete (kusto extension) oder az kusto database delete (kusto extension):
az kusto cluster delete --name "<cluster name>" --resource-group "<resource group name>"
az kusto database delete --cluster-name "<cluster name>" --database-name "<database name>" --resource-group "<resource group name>"
Sie können Ihren Cluster und Ihre Datenbank auch über die Azure-Portal löschen. Weitere Informationen finden Sie unter Löschen eines Azure Data Explorer-Clusters und Löschen einer Datenbank im Azure-Daten-Explorer.
Optimierung des Kafka Sink-Connectors
Passen Sie den Kafka-Senke-Connector an, damit er mit der Batch-Policy für die Ingestion verwendet werden kann:
- Passen Sie das Größenlimit der Kafka-Senke
flush.size.bytesan, beginnend mit 1 MB, jeweils in Schritten von 10 MB oder 100 MB. - Bei Verwendung der Kafka-Senke werden die Daten zweimal aggregiert. Auf der Connector-Seite werden Daten gemäß den Flush-Einstellungen aggregiert, und auf der Dienst-Seite gemäß der Batch-Richtlinie. Wenn die Batchverarbeitungszeit zu kurz ist, so dass die Daten nicht sowohl vom Connector als auch vom Dienst aufgenommen werden können, muss die Batchverarbeitungszeit erhöht werden. Legen Sie die Batchverarbeitungsgröße auf 1 GB fest, und erhöhen oder verringern Sie sie bei Bedarf in Schritten von 100 MB. Wenn beispielsweise die Flush-Größe 1 MB und die Größe der Batching-Richtlinie 100 MB beträgt, aggregiert der Kafka-Sink-Connector die Daten zu einem 100-MB-Batch. Dieser Batch wird dann vom Dienst aufgenommen. Wenn die Batchverarbeitungsrichtlinienzeit 20 Sekunden beträgt und der Kafka-Senkenconnector in einem Zeitraum von 20 Sekunden 50 MB leert, erfasst der Dienst einen Batch mit 50 MB.
- Sie können skalieren, indem Sie Instanzen und Kafka-Partitionen hinzufügen. Erhöhen Sie
tasks.maxauf die Anzahl von Partitionen. Erstellen Sie eine Partition, wenn Sie über genügend Daten verfügen, um ein Blob mit der Größe der Einstellungflush.size.byteszu erstellen. Ist das Blob kleiner, wird der Batch bei Erreichen des Zeitlimits verarbeitet, sodass die Partition nicht genügend Durchsatz erhält. Eine große Anzahl von Partitionen bedeutet mehr Verarbeitungsaufwand.
Zugehöriger Inhalt
- Informieren Sie sich über die Big Data-Architektur.
- Informieren Sie sich über das Erfassen von Beispieldaten im JSON-Format in Azure Data Explorer.
- Erfahren Sie mehr über Kafka Labs: