Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Tipp
Die entsprechende Transformation (Spalten auswählen) in Dataflow Gen2 finden Sie in einer Anleitung zu Dataflow Gen2 zum Zuordnen von Datenflussbenutzern.
Verwenden Sie die Auswahltransformation, um Spalten umzubenennen, zu löschen oder neu anzuordnen. Diese Transformation ändert keine Zeilendaten, sondern wählt aus, welche Spalten weiter unten weitergeleitet werden.
Bei einer Auswahltransformation können Benutzer feste Zuordnungen festlegen, Muster für regelbasierte Zuordnungen verwenden oder die automatische Zuordnung aktivieren. Feste und regelbasierte Zuordnungen können innerhalb der gleichen Auswahltransformation verwendet werden. Wenn eine Spalte nicht einer der definierten Zuordnungen entspricht ist, wird sie gelöscht.
Feste Zuordnung
Wenn in Ihrer Projektion weniger als 50 Spalten definiert sind, haben alle definierten Spalten standardmäßig eine feste Zuordnung. Eine feste Zuordnung verwendet eine definierte, eingehende Spalte und ordnet ihr einen genauen Namen zu.
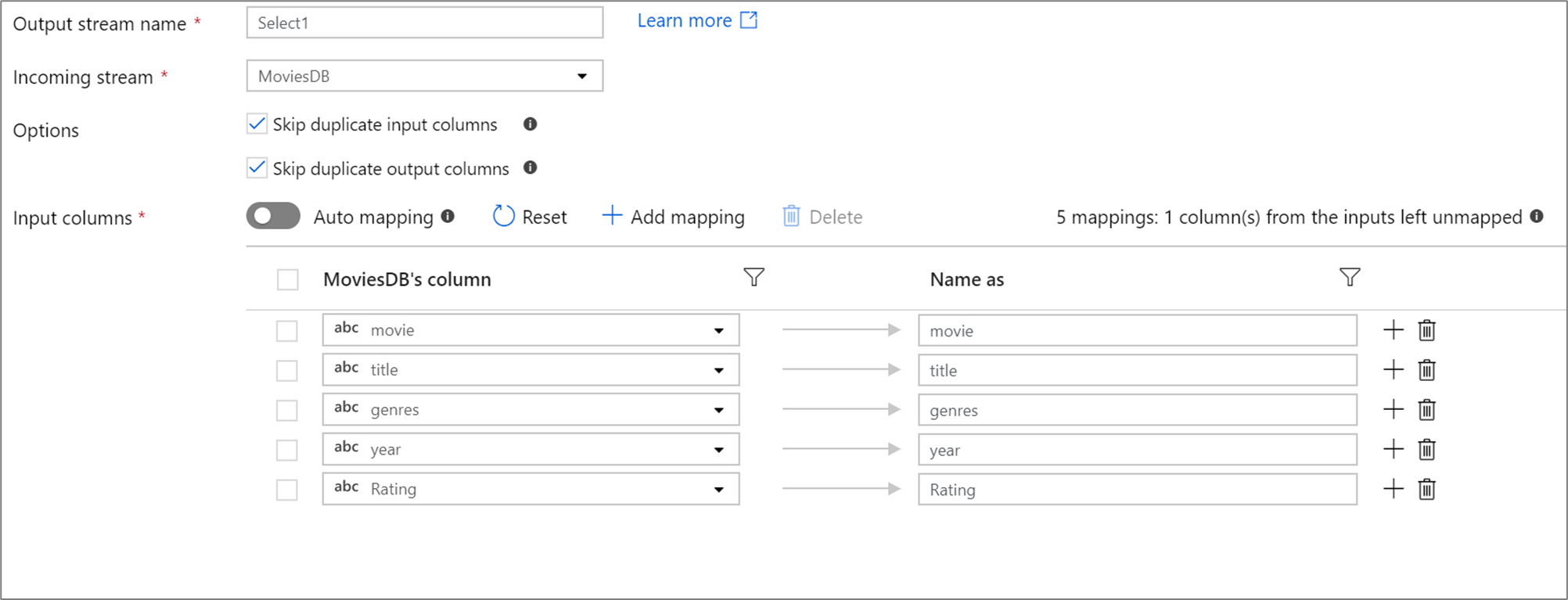
Hinweis
Sie können eine abweichende Spalte nicht mithilfe einer festen Zuordnung zuordnen oder umbenennen.
Zuordnen hierarchischer Spalten
Feste Zuordnungen können verwendet werden, um eine Unterspalte einer hierarchischen Spalte einer Spalte der obersten Ebene zuzuordnen. Wenn es eine festgelegte Hierarchie gibt, verwenden Sie das Dropdown-Menü der Spalte, um eine Unterspalte auszuwählen. Die Auswahltransformation erstellt eine neue Spalte mit dem Wert und Datentyp der Unterspalte.
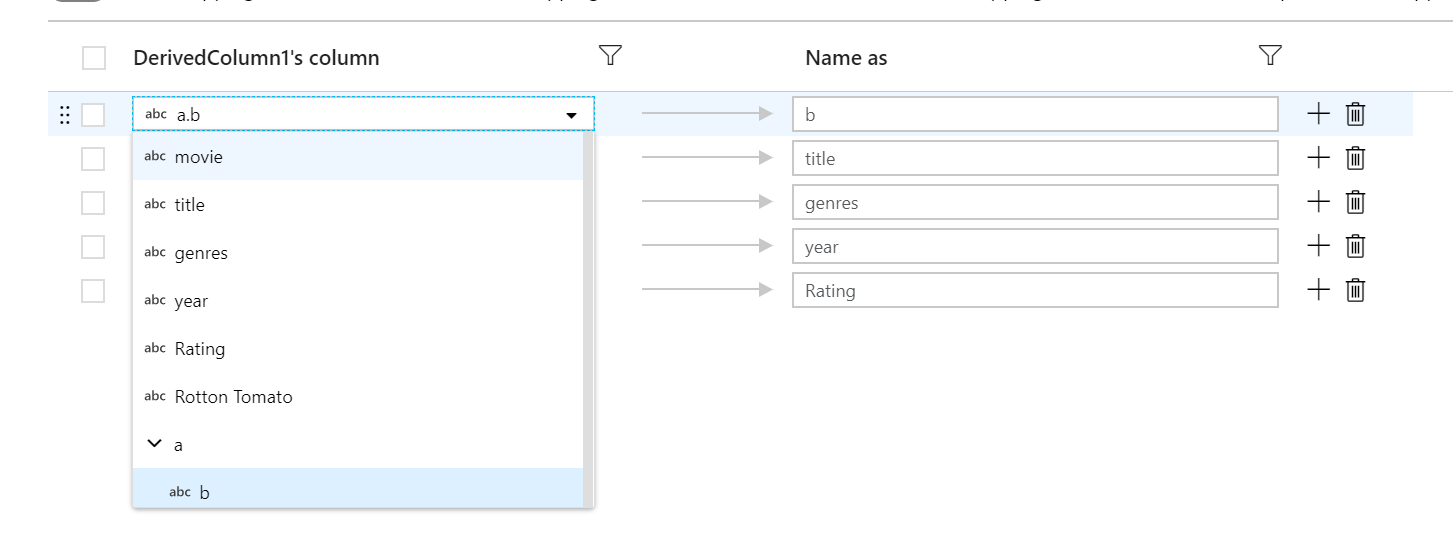
Regelbasierte Zuordnung
Wenn Sie viele Spalten auf einmal zuordnen oder abweichende Spalten nachgeschaltet weitergeben möchten, verwenden Sie die regelbasierte Zuordnung, um Ihre Zuordnungen mithilfe von Spaltenmustern zu definieren. Gleichen Sie basierend auf den Werten name, type, stream und position von Spalten ab. Es kann eine beliebige Kombination aus festen und regelbasierten Zuordnungen verwendet werden. Standardmäßig werden alle Projektionen mit mehr als 50 Spalten auf eine regelbasierte Zuordnung festgelegt, die einen Abgleich auf Übereinstimmung für jede Spalte vornimmt und den eingegebenen Namen ausgibt.
Klicken Sie zum Hinzufügen einer regelbasierten Zuordnung auf Zuordnung hinzufügen, und wählen Sie Rule-based mapping (Regelbasierte Zuordnung) aus.

Jede regelbasierte Zuordnung erfordert zwei Eingaben: die Bedingung, gemäß der der Abgleich auf Übereinstimmung erfolgen soll, und den Namen jeder zugeordneten Spalte. Beide Werte werden über den Ausdrucks-Generator eingegeben. Geben Sie im linken Ausdrucksfeld Ihre boolesche Übereinstimmungsbedingung ein. Geben Sie im rechten Ausdrucksfeld das Zuordnungsziel für die übereinstimmende Spalte an.

Verwenden Sie die $$-Syntax, um auf den eingegebenen Namen einer übereinstimmenden Spalte zu verweisen. Nehmen wir das obige Bild als Beispiel: Ein Benutzer wünscht einen Abgleich auf Übereinstimmung aller Zeichenfolgenspalten, deren Namen kürzer als sechs Zeichen sind. Wenn eine eingehende Spalte mittest benannt wurde, wird die Spalte durch den Ausdruck $$ + '_short' in test_short umbenannt. Wenn dies die einzige vorhandene Zuordnung ist, werden alle Spalten, die die Bedingung nicht erfüllen, aus den ausgegebenen Daten entfernt.
Muster stimmen sowohl mit abweichenden als auch definierten Spalten überein. Um zu prüfen, welche definierten Spalten von einer Regel zugeordnet werden, klicken Sie neben der Regel auf das Brillensymbol. Überprüfen Sie die Ausgabe mithilfe der Datenvorschau.
Zuordnung mit regulärem Ausdruck
Wenn Sie auf das nach unten zeigende Chevronsymbol klicken, können Sie eine RegEx-Zuordnungsbedingung angeben. Eine RegEx-Zuordnungsbedingung gleicht alle Spaltennamen ab, die der angegebenen RegEx-Bedingung entsprechen. Sie kann in Kombination mit standardmäßigen regelbasierten Zuordnungen verwendet werden.

Das obige Beispiel stimmt mit dem RegEx-Muster (r) oder einem beliebigen Spaltennamen überein, der den Kleinbuchstaben r enthält. Ähnlich wie bei der standardmäßigen regelbasierten Zuordnung werden alle übereinstimmenden Spalten von der Bedingung auf der rechten Seite mithilfe von $$-Syntax geändert.
Wenn es mehrere RegEx-Übereinstimmungen in Ihrem Spaltennamen gibt, können Sie mit $n auf bestimmte Übereinstimmungen verweisen, wobei sich „n“ auf die jeweilige Übereinstimmung bezieht. Beispielsweise bezieht sich „$2“ auf die zweite Übereinstimmung innerhalb eines Spaltennamens.
Regelbasierte Hierarchien
Wenn Ihre definierte Projektion eine Hierarchie hat, können Sie die regelbasierte Zuordnung verwenden, um die Unterspalten der Hierarchie zuzuordnen. Geben Sie eine Übereinstimmungsbedingung und die komplexe Spalte an, deren Unterspalten Sie zuordnen möchten. Jede übereinstimmende Unterspalte wird mithilfe der rechts angegebenen Regel „Name as“ (Benennen als) ausgegeben.
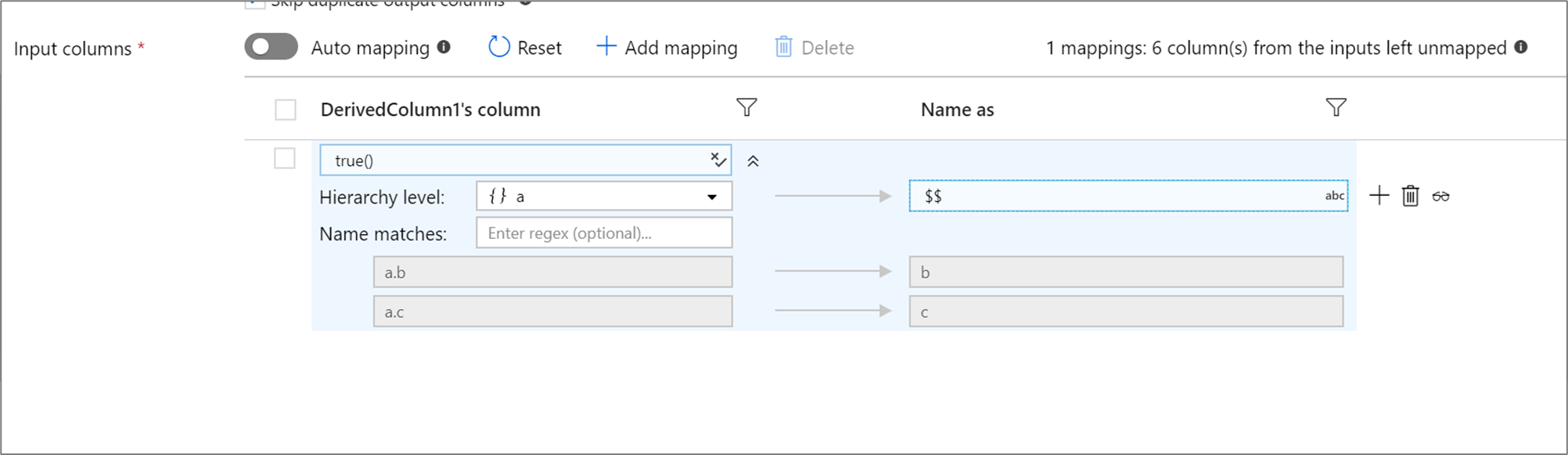
Das obige Beispiel stimmt mit allen Unterspalten der komplexen Spalte a überein.
a enthält die beiden Unterspalten b und c. Das Ausgabeschema weist die beiden Spalten b und c auf, da die Bedingung „Name as“ $$ ist.
Parametrisierung
Sie können Spaltennamen mithilfe einer regelbasierten Zuordnung parametrisieren. Verwenden Sie das Schlüsselwort name, um eingehende Spaltennamen mit einem Parameter auf Übereinstimmung abzugleichen. Wenn Sie beispielsweise den Datenflussparameter mycolumn haben, können Sie eine Regel erstellen, die allen Spaltennamen auf Übereinstimmung abgleicht, die gleich mycolumn sind. Sie können die übereinstimmende Spalte in eine hartcodierte Zeichenfolge wie z. B. „Geschäftsschlüssel“ umbenennen und explizit darauf verweisen. Bei diesem Beispiel ist die Übereinstimmungsbedingung name == $mycolumn und die Namensbedingung „Geschäftsschlüssel“.
Automatische Zuordnung
Beim Hinzufügen einer Auswahltransformation kann Auto mapping (Automatische Zuordnung) durch Umschalten des Schiebereglers für die automatische Zuordnung aktiviert werden. Bei der automatischen Zuordnung ordnet die Auswahltransformation alle eingehenden Spalten, mit Ausnahme von Duplikaten, mit dem ihrer Eingabe entsprechenden Namen zu. Dies schließt abweichende Spalten ein, was bedeutet, dass die Ausgabedaten Spalten enthalten können, die in Ihrem Schema nicht definiert sind. Weitere Informationen zu abweichenden Spalten finden Sie unter Schemaabweichung.
Bei aktivierter automatischer Zuordnung berücksichtigt die Auswahltransformation die Einstellungen für das Überspringen von Duplikaten und bietet einen neuen Alias für die vorhandenen Spalten. Aliasing ist nützlich, wenn mehrere Verknüpfungs- oder Nachschlagevorgänge für denselben Datenstrom und in Selbstverknüpfungsszenarien erfolgen.
Duplizierte Spalten
Standardmäßig löscht die Auswahltransformation duplizierte Spalten sowohl in der Eingabe- als auch in der Ausgabeprojektion. Duplizierte Eingabespalten stammen oft aus Verknüpfungs- und Nachschlagetransformationen, bei denen die Spaltennamen auf jeder Seite der Verknüpfung dupliziert werden. Duplizierte Ausgabespalten können auftreten, wenn Sie zwei verschiedene Eingabespalten demselben Namen zuordnen. Wählen Sie durch Umschalten des Kontrollkästchens, ob duplizierte Spalten gelöscht oder weitergegeben werden sollen.
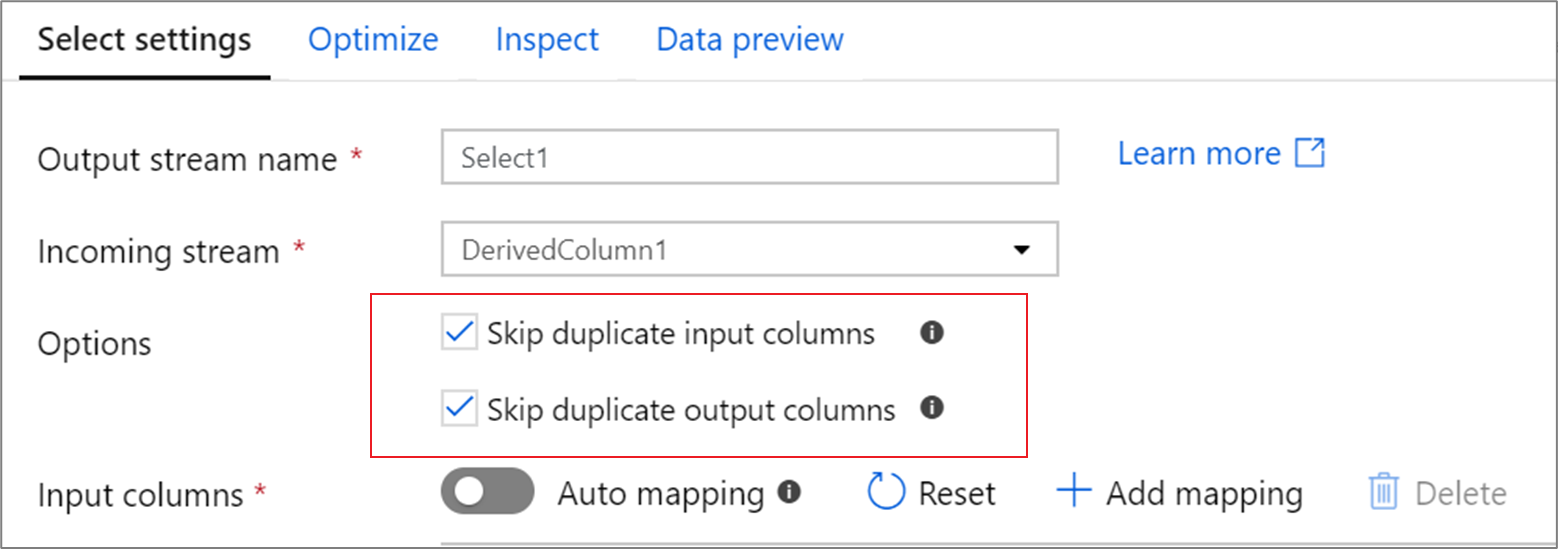
Anordnen von Spalten
Die Reihenfolge der Zuordnungen bestimmt die Reihenfolge der Ausgabespalten. Wenn eine Eingabespalte mehrfach zugeordnet wird, wird nur die erste Zuordnung berücksichtigt. Für jede duplizierte Spalte, die gelöscht wird, wird die erste Übereinstimmung beibehalten.
Datenflussskript
Syntax
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Beispiel
Es folgen ein Beispiel für ein Auswahlzuordnung und das zugehörige Datenflussskript:

DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Zugehöriger Inhalt
- Nachdem Sie die Option „Select“ (Auswählen) verwendet haben, um Spalten umzubenennen, neu anzuordnen und Aliase zuzuweisen, verwenden Sie die Sink-Transformation, um Ihre Daten in einem Datenspeicher zu speichern.