Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Die JAR-Aktivität in Azure Databricks in einer Pipeline führt eine Spark JAR-Datei in Ihrem Azure Databricks-Cluster aus. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet. Azure Databricks ist eine verwaltete Plattform zum Ausführen von Apache Spark.
Das folgende Video enthält eine 11-minütige Einführung und Demonstration dieses Features:
Hinzufügen einer Jar-Aktivität für Azure Databricks zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine Jar-Aktivität für Azure Databricks in einer Pipeline zu verwenden:
Suchen Sie im Bereich für Pipeline-Aktivitäten nach Jar, und ziehen Sie eine Jar-Aktivität auf die Pipeline-Leinwand.
Wählen Sie die neue Jar-Aktivität auf dem Canvas aus, wenn sie noch nicht ausgewählt ist.
Wählen Sie die Registerkarte Azure Databricks aus, um einen neuen Azure Databricks verknüpften Dienst auszuwählen oder zu erstellen, der die Jar-Aktivität ausführt.

Wählen Sie die Registerkarte Settings aus, und geben Sie einen Klassennamen an, der für Azure Databricks ausgeführt werden soll, optionale Parameter, die an den Jar übergeben werden sollen, und Bibliotheken, die auf dem Cluster installiert werden sollen, um den Auftrag auszuführen.
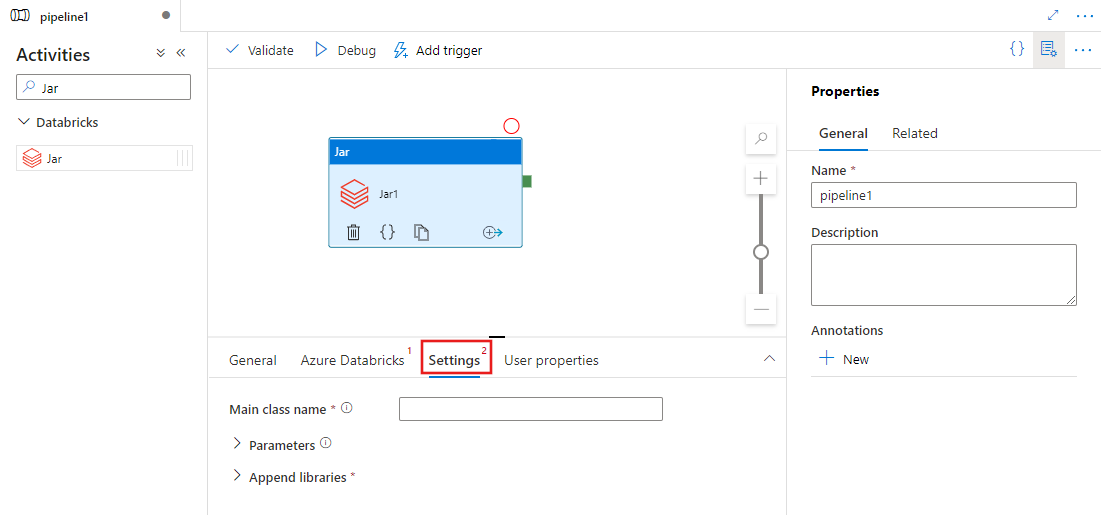
Definition der Databricks-JAR-Aktivität
Dies ist die JSON-Beispieldefinition der JAR-Aktivität in Databricks:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Eigenschaften der Databricks-JAR-Aktivität
Die folgende Tabelle beschreibt die JSON-Eigenschaften, die in der JSON-Definition verwendet werden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Name | Der Name der Aktivität in der Pipeline. | Ja |
| Beschreibung | Ein Text, der beschreibt, was mit der Aktivität ausgeführt wird. | Nein |
| Typ | Bei der Jar-Aktivität in Databricks lautet der Aktivitätstyp DatabricksSparkJar. | Ja |
| verknüpfterDienstname | Der Name des verknüpften Databricks-Diensts, in dem die JAR-Aktivität ausgeführt wird. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Verknüpfte Compute-Dienste. | Ja |
| mainClassName | Der vollständige Name der Klasse, die die auszuführende Hauptmethode enthält. Diese Klasse muss in einer JAR-Datei enthalten sein, die als Bibliothek bereitgestellt wird. Eine JAR-Datei kann mehrere Klassen enthalten. Jede der Klassen kann eine Main-Methode enthalten. | Ja |
| parameters | Parameter, die an die Hauptmethode übergeben werden. Diese Eigenschaft ist ein Array von Zeichenfolgen. | Nein |
| Bibliotheken | Eine Liste der Bibliotheken, die in dem Cluster installiert werden, der den Auftrag ausführen wird. Es kann ein Array vom Typ <Zeichenfolge, Objekt> sein. | Ja (mindestens eine mit der mainClassName-Methode) |
Hinweis
Bekanntes Problem: Wird derselbe interaktive Cluster zum Ausführen gleichzeitiger JAR in Databricks-Aktivitäten (ohne einen Clusterneustart) verwendet, kommt es zu einem bekannten Problem in Databricks, bei dem Parametern der ersten Aktivität auch von folgenden Aktivitäten verwendet werden. Dies führt zur Übergabe falscher Parameter an die nachfolgenden Aufträge. Um dieses Problem zu beheben, verwenden Sie stattdessen einen Auftragscluster.
Unterstützte Bibliotheken für Databricks-Aktivitäten
In der vorherigen Databricks-Aktivitätsdefinition haben Sie die folgenden Bibliothekstypen angegeben: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Weitere Informationen zu Bibliothekstypen finden Sie in der Databricks-Dokumentation.
Hochladen einer Bibliothek in Databricks
Sie können die Benutzeroberfläche des Arbeitsbereichs verwenden:
Verwenden der Benutzeroberfläche des Databricks-Arbeitsbereichs
Sie können den DBFS-Pfad der hinzugefügten Bibliothek über die Benutzeroberfläche mithilfe der Databricks-Befehlszeilenschnittstelle abrufen.
JAR-Bibliotheken werden beim Verwenden der Benutzeroberfläche in der Regel unter dbfs:/FileStore/jars gespeichert. Sie können alle über die Befehlszeilenschnittstelle auflisten: databricks fs ls dbfs:/FileStore/job-jars
Alternativ können Sie die Databricks-Befehlszeilenschnittstelle verwenden:
Folgen Sie Kopieren Sie die Bibliothek mit der Databricks-Befehlszeilenschnittstelle.
Verwenden Sie die Databricks-Befehlszeilenschnittstelle (Installationsschritte).
Zum Beispiel, um ein JAR auf dbfs zu kopieren:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar.
Zugehöriger Inhalt
Sehen Sie sich für eine elfminütige Einführung und Demonstration dieses Features das video an.