Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial wird eine Azure Data Factory-Instanz mit einer Pipeline erstellt, die Deltadaten basierend auf Informationen von Change Data Capture (CDC) aus der Azure SQL Managed Instance-Quelldatenbank in Azure Blob Storage lädt.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Vorbereiten des Quelldatenspeichers
- Erstellen einer Data Factory.
- Erstellen Sie verknüpfte Dienste.
- Erstellen von Quell- und Senkendatasets.
- Erstellen, Debuggen und Ausführen der Pipeline, um eine Überprüfung auf geänderte Daten durchzuführen
- Ändern von Daten in der Quelltabelle
- Abschließen, Ausführen und Überwachen der gesamten Pipeline für inkrementelles Kopieren
Übersicht
Die von Datenspeichern wie Azure SQL Managed Instance (MI) und SQL Server unterstützte Change Data Capture-Technologie kann zur Identifizierung geänderter Daten verwendet werden. In diesem Tutorial erfahren Sie, wie Sie Azure Data Factory zusammen mit Change Data Capture-Technologie für SQL verwenden, um Deltadaten inkrementell aus Azure SQL Managed Instance in Azure Blob Storage zu laden. Konkretere Informationen zur Change Data Capture-Technologie für SQL finden Sie unter Über Change Data Capture (SQL Server).
Kompletter Workflow
Hier finden Sie die typischen Schritte des End-to-End-Workflows für das inkrementelle Laden von Daten mithilfe der Change Data Capture-Technologie.
Hinweis
Die Change Data Capture-Technologie wird sowohl von Azure SQL Managed Instance als auch von SQL Server unterstützt. In diesem Tutorial wird Azure SQL Managed Instance als Quelldatenspeicher verwendet. Sie können auch eine lokale SQL Server-Instanz verwenden.
Allgemeine Lösung
In diesem Tutorial wird eine Pipeline für folgende Vorgänge erstellt:
- Erstellen einer Lookup-Aktivität, um die Anzahl geänderter Datensätze in der CDC-Tabelle der SQL-Datenbank zu ermitteln und an eine Aktivität vom Typ „If-Bedingung“ zu übergeben
- Erstellen einer If-Bedingung, um zu überprüfen, ob geänderte Datensätze vorhanden sind, und die Kopieraktivität aufzurufen, wenn dies der Fall ist
- Erstellen einer Kopieraktivität, um die eingefügten/aktualisierten/gelöschten Daten aus der CDC-Tabelle in Azure Blob Storage zu kopieren
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- azure SQL Managed Instance. Sie verwenden die Datenbank als den Quell-Datenspeicher. Falls Sie noch nicht über Azure SQL Managed Instance verfügen, erfahren Sie im Artikel Schnellstart: Erstellen einer verwalteten Azure SQL-Instanz, wie Sie eine solche Instanz erstellen.
- Azure Storage-Konto. Sie verwenden den Blob Storage als den Senken-Datenspeicher. Wenn Sie kein Azure Storage-Konto besitzen, finden Sie im Artikel Erstellen eines Speicherkontos Schritte zum Erstellen eines solchen Kontos. Erstellen Sie einen Container mit dem Namen raw.
Erstellen einer Datenquellentabelle in Azure SQL-Datenbank
Starten Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit Ihrem Azure SQL Managed Instance-Server her.
Klicken Sie im Server-Explorer mit der rechten Maustaste auf Ihre Datenbank, und wählen Sie Neue Abfrage.
Führen Sie den folgenden SQL-Befehl für Ihre Azure SQL Managed Instance-Datenbank aus, um eine Tabelle mit dem Namen
customersals Quelldatenspeicher zu erstellen:create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Führen Sie die folgende SQL-Abfrage aus, um den Mechanismus Change Data Capture für Ihre Datenbank und die Quelltabelle (customers) zu aktivieren:
Hinweis
- Ersetzen Sie „<your source schema name>“ durch das Schema Ihrer Azure SQL Managed Instance-Instanz, die die Tabelle „customers“ enthält.
- Change Data Capture ist nicht an den Transaktionen beteiligt, mit denen die überwachte Tabelle geändert wird. Stattdessen werden Einfüge-, Aktualisierungs- und Löschvorgänge in das Transaktionsprotokoll geschrieben. Damit die Datenmenge in Änderungstabellen nicht auf eine unüberschaubare Größe anwächst, müssen die Daten regelmäßig und systematisch gekürzt werden. Weitere Informationen finden Sie unter Aktivieren und Deaktivieren von Change Data Capture (SQL Server).
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Führen Sie den folgenden Befehl aus, um Daten in die Tabelle „customers“ einzufügen:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Hinweis
Änderungen, die vor der Change Data Capture-Aktivierung an der Tabelle vorgenommen wurden, werden nicht erfasst.
Erstellen einer Data Factory
Wenn Sie noch nicht über eine Data Factory verfügen, mit der Sie arbeiten können, führen Sie die im Artikel Schnellstart: Erstellen einer Data Factory im Azure-Portal aufgeführten Schritte aus, um eine Data Factory zu erstellen.
Erstellen von verknüpften Diensten
Um Ihre Datenspeicher und Compute Services mit der Data Factory zu verknüpfen, können Sie verknüpfte Dienste in einer Data Factory erstellen. In diesem Abschnitt werden Dienste erstellt, die mit Ihrem Azure Storage-Konto und mit Azure SQL Managed Instance verknüpft sind.
Erstellen des verknüpften Azure Storage-Diensts.
In diesem Schritt verknüpfen Sie Ihr Azure Storage-Konto mit der Data Factory.
Klicken Sie auf Verbindungen und dann auf + Neu.
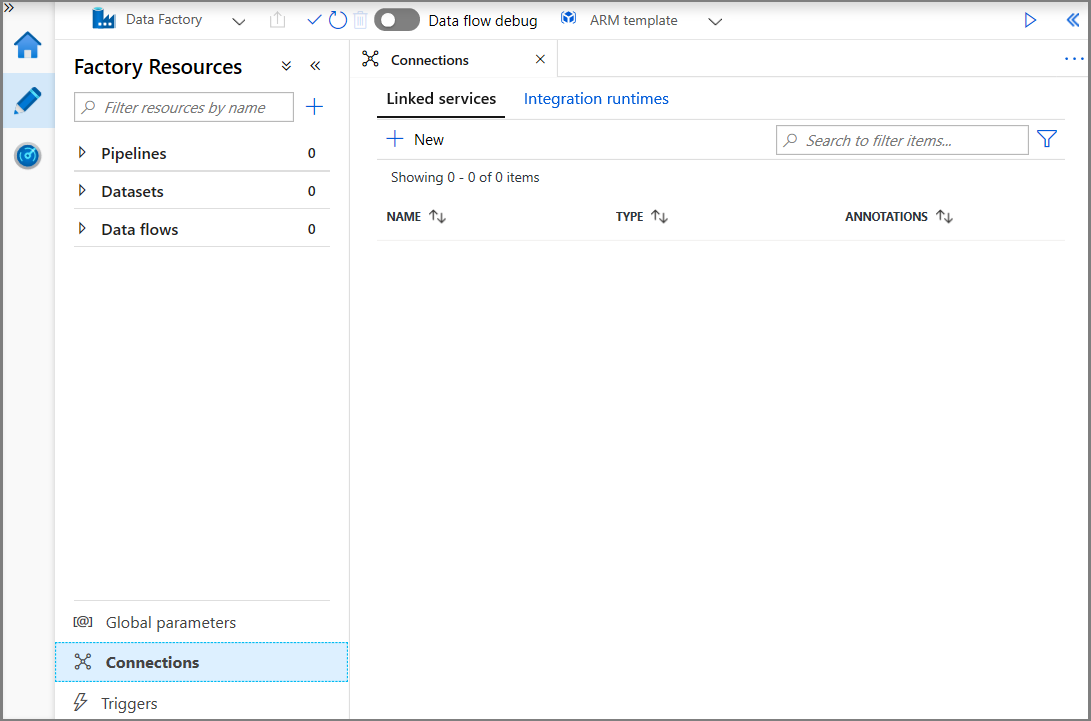
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Azure Blob Storage, und klicken Sie dann auf Weiter.
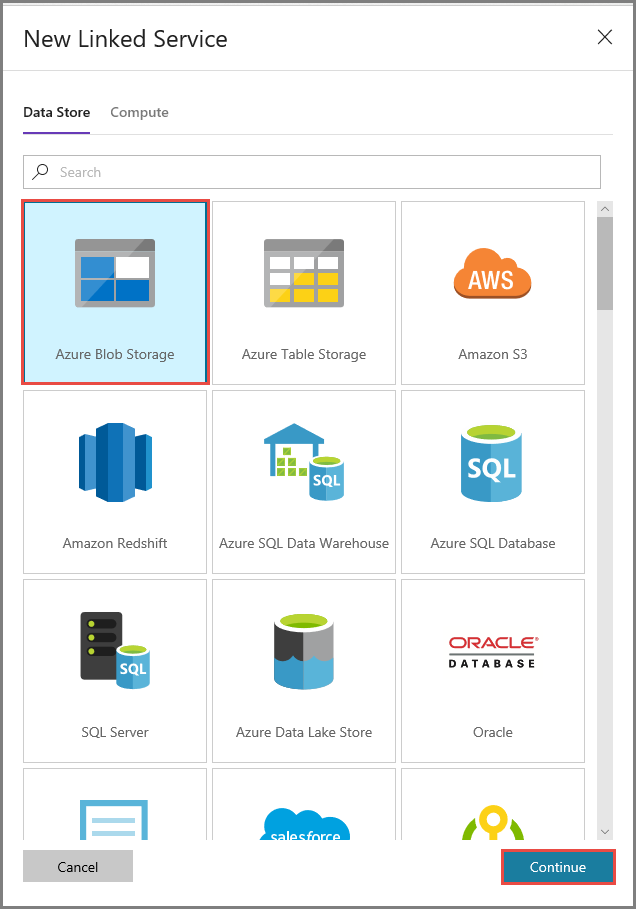
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
- Geben Sie unter Name die Zeichenfolge AzureStorageLinkedService ein.
- Wählen Sie unter Speicherkontoname Ihr Azure Storage-Konto aus.
- Klicken Sie auf Speichern.
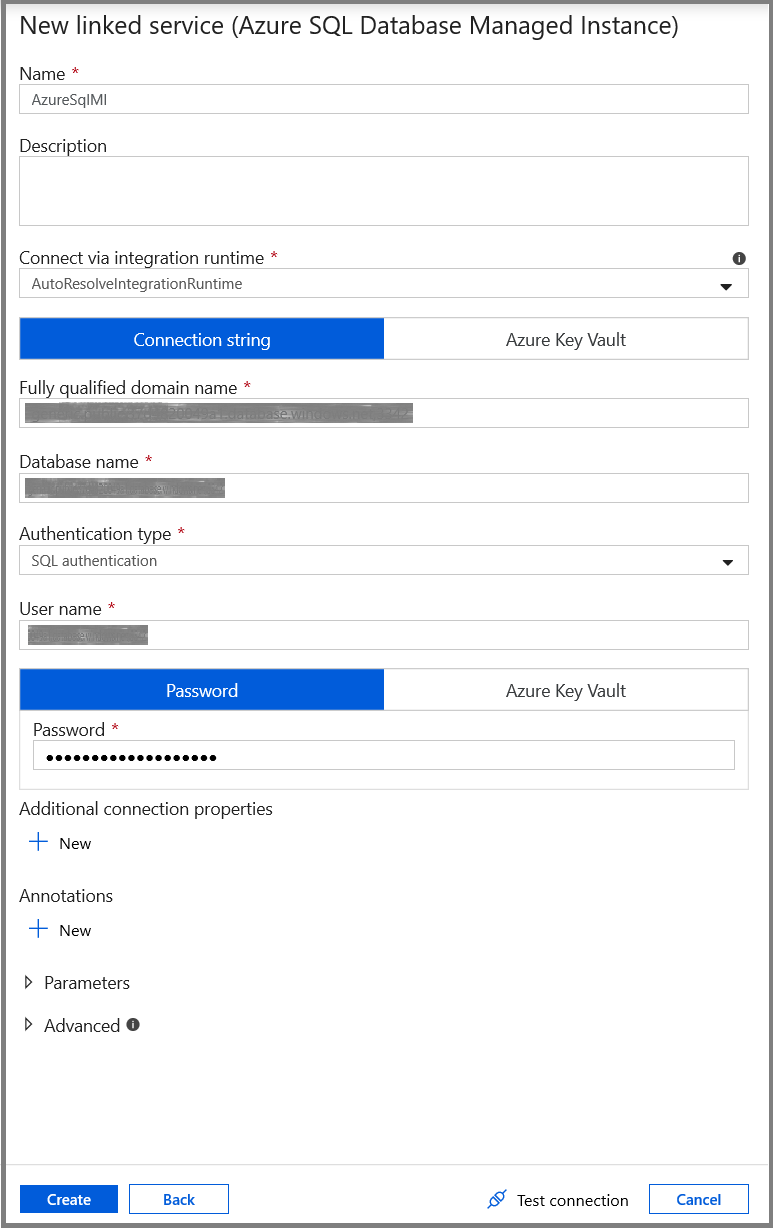
Erstellen eines mit der Azure SQL Managed Instance-Datenbank verknüpften Diensts
In diesem Schritt wird Ihre Azure SQL Managed Instance-Datenbank mit der Data Factory verknüpft.
Hinweis
Bei Verwendung von SQL Managed Instance finden Sie hier Informationen zum Zugriff über einen öffentlichen oder über einen privaten Endpunkt. Bei Verwendung eines privaten Endpunkts muss diese Pipeline unter Verwendung einer selbstgehosteten Integration Runtime ausgeführt werden. Gleiches gilt, wenn SQL Server lokal oder in einem VM- oder VNET-Szenario ausgeführt wird.
Klicken Sie auf Verbindungen und dann auf + Neu.
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Verwaltete Azure SQL-Datenbank-Instanz aus, und klicken Sie anschließend auf Weiter.
Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
- Geben Sie im Feld Name den Namen AzureSqlMI1 ein.
- Wählen Sie im Feld Servername Ihre SQL Server-Instanz aus.
- Wählen Sie im Feld Datenbankname Ihre SQL-Datenbank aus.
- Geben Sie im Feld Benutzername den Namen des Benutzers ein.
- Geben Sie im Feld Kennwort das Kennwort für den Benutzer ein.
- Klicken Sie auf Verbindung testen, um die Verbindung zu testen.
- Klicken Sie auf Speichern, um den verknüpften Dienst zu speichern.
Erstellen von Datasets
In diesem Schritt werden Datasets erstellt, um die Datenquelle und das Datenziel darzustellen.
Erstellen eines Datasets zum Darstellen von Quelldaten
In diesem Schritt erstellen Sie ein Dataset, das für die Quelldaten steht.
Klicken Sie in der Strukturansicht auf + (Pluszeichen) und dann auf Dataset.
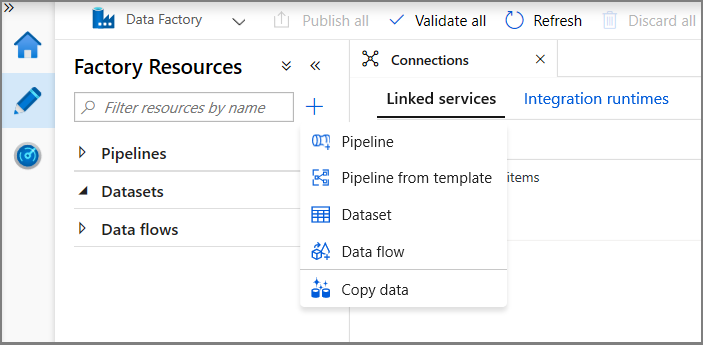
Wählen Sie Verwaltete Azure SQL-Datenbank-Instanz aus, und klicken Sie anschließend auf Weiter.
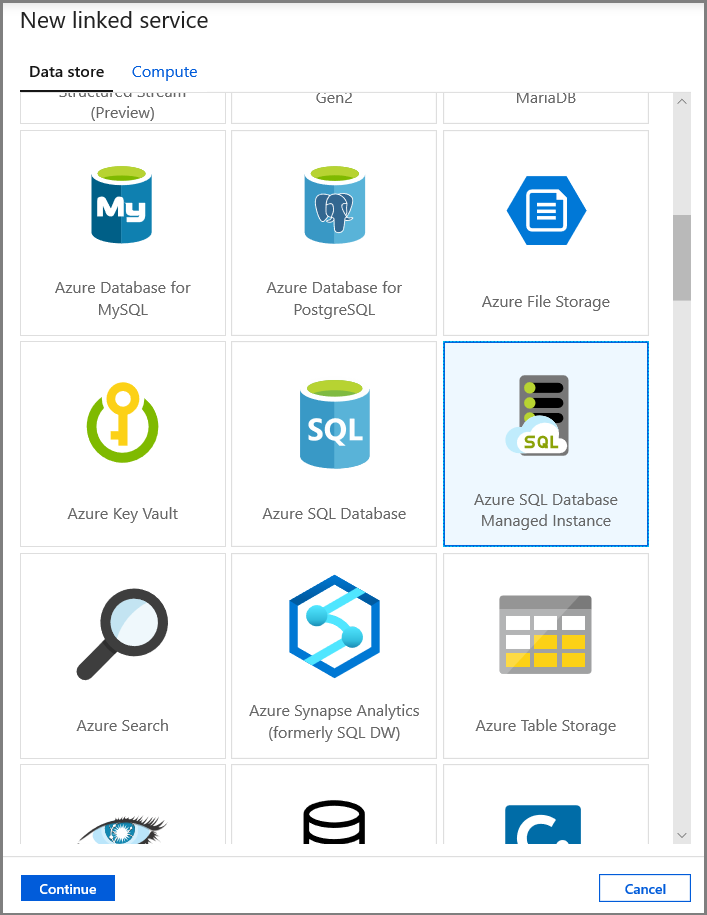
Legen Sie auf der Registerkarte Eigenschaften festlegen den Datasetnamen und die Verbindungsinformationen fest:
- Wählen Sie unter Verknüpfter Dienst die Option AzureSqlMI1 aus.
- Wählen Sie unter Tabellenname die Option [dbo].[dbo_customers_CT] aus. Hinweis: Diese Tabelle wurde automatisch erstellt, als CDC für die Tabelle „customers“ aktiviert wurde. Geänderte Daten werden nie direkt aus dieser Tabelle abgefragt, sondern über die Change Data Capture-Funktionen extrahiert.
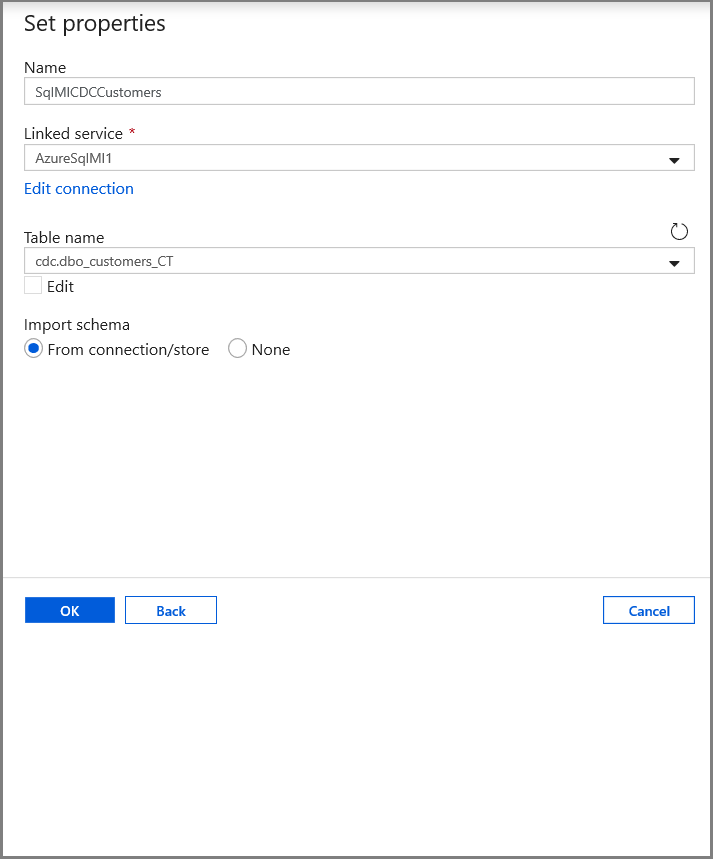
Erstellen Sie ein Dataset zum Darstellen von Daten, die in den Senkendatenspeicher kopiert werden.
In diesem Schritt erstellen Sie ein Dataset, das für die Daten steht, die aus dem Quelldatenspeicher kopiert werden. Den Data Lake-Container haben Sie im Rahmen der Vorbereitung in Ihrer Azure Blob Storage-Instanz erstellt. Erstellen Sie den Container, wenn er noch nicht vorhanden ist (oder) geben Sie den Namen eines bereits vorhandenen ein. In diesem Tutorial wird der Name der Ausgabedatei dynamisch unter Verwendung der (später konfigurierten) Auslösungszeit generiert.
Klicken Sie in der Strukturansicht auf + (Pluszeichen) und dann auf Dataset.
Wählen Sie Azure Blob Storage aus, und klicken Sie auf Weiter.
Wählen Sie DelimitedText aus, und klicken Sie auf Weiter.

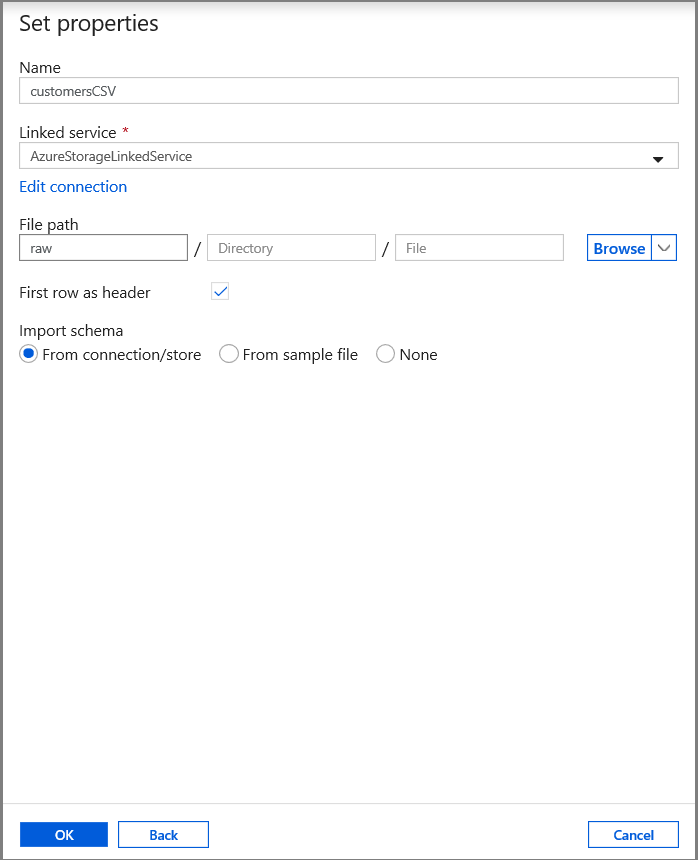
Legen Sie auf der Registerkarte Eigenschaften festlegen den Datasetnamen und die Verbindungsinformationen fest:
- Wählen Sie unter Verknüpfter Dienst die Option AzureStorageLinkedService.
- Geben Sie unter Dateipfad für Container die Zeichenfolge raw ein.
- Aktivieren Sie das Kontrollkästchen First row as header (Erste Zeile als Header).
- Klicken Sie auf OK.
Erstellen einer Pipeline zum Kopieren der geänderten Daten
In diesem Schritt wird eine Pipeline erstellt, die zunächst mithilfe einer Lookup-Aktivität überprüft, wie viele geänderte Datensätze in der Änderungstabelle vorhanden sind. Durch eine Aktivität vom Typ „If-Bedingung“ wird geprüft, ob die Anzahl geänderter Datensätze größer Null ist, und eine Kopieraktivität wird ausgeführt, um die eingefügten/aktualisierten/gelöschten Daten aus Azure SQL-Datenbank in Azure Blob Storage zu kopieren. Abschließend wird ein Trigger für ein rollierendes Fenster konfiguriert, und die Start- und Endzeiten werden als Parameter für den Start und das Ende des Fensters an die Aktivitäten übergeben.
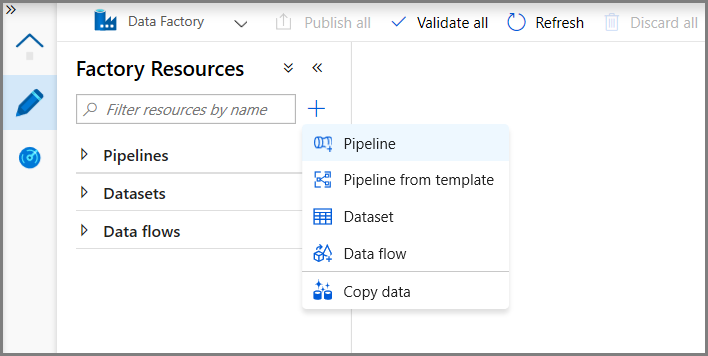
Wechseln Sie auf der Data Factory-Benutzeroberfläche zur Registerkarte Bearbeiten. Klicken Sie im Bereich auf der linken Seite auf + (Pluszeichen) und dann auf Pipeline.
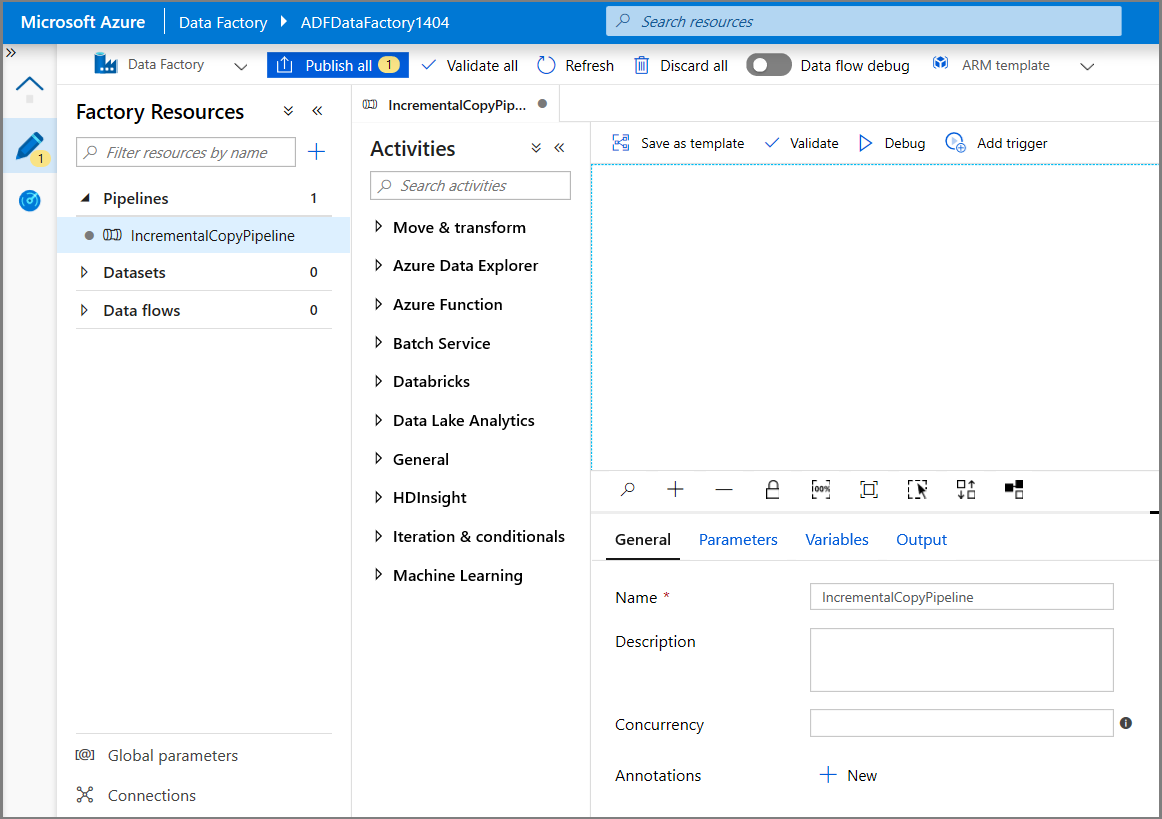
Eine neue Registerkarte zum Konfigurieren der Pipeline wird angezeigt. Außerdem wird die Pipeline in der Strukturansicht angezeigt. Ändern Sie im Eigenschaftenfenster den Namen der Pipeline in IncrementalCopyPipeline.
Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie die Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Legen Sie den Namen der Aktivität auf GetChangeCount fest. Durch diese Aktivität wird die Anzahl von Datensätzen in der Änderungstabelle für ein bestimmtes Zeitfenster abgerufen.
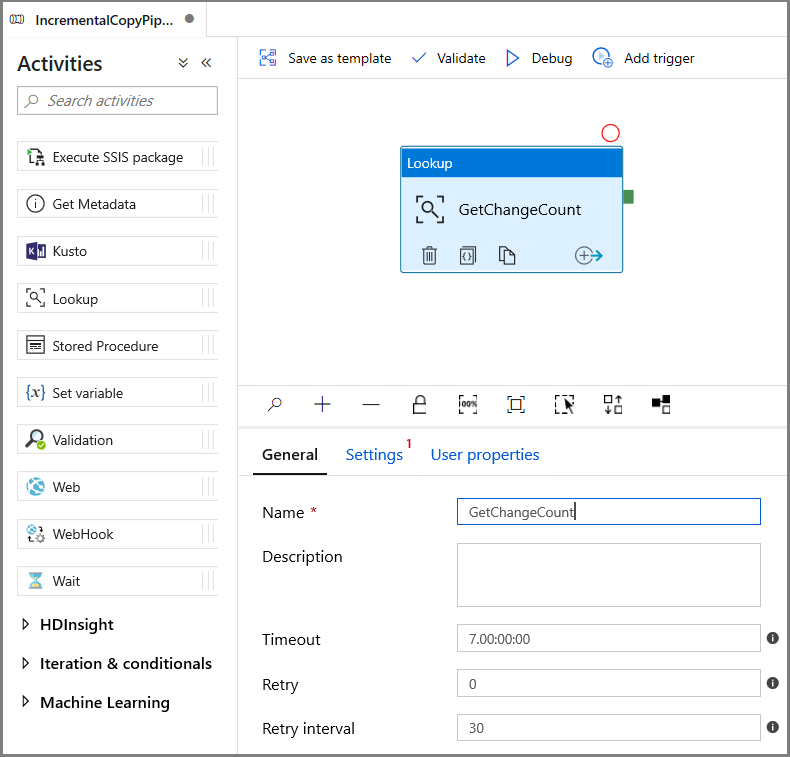
Wechseln Sie im Fenster Eigenschaften zu Einstellungen:
Geben Sie im Feld Source Dataset (Quelldataset) den Namen des SQL Managed Instance-Datasets an.
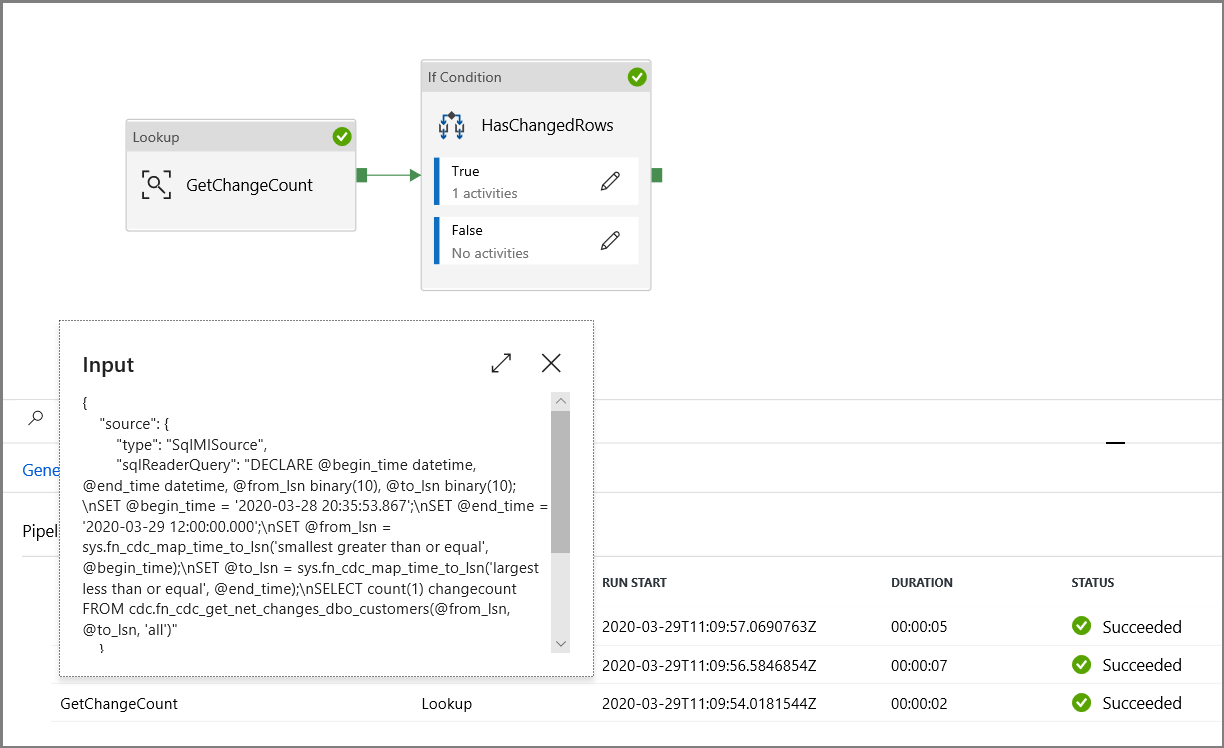
Wählen Sie die Option „Abfrage“ aus, und geben Sie Folgendes in das Abfragefeld ein:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Aktivieren Sie das Kontrollkästchen First row only (Nur erste Zeile).
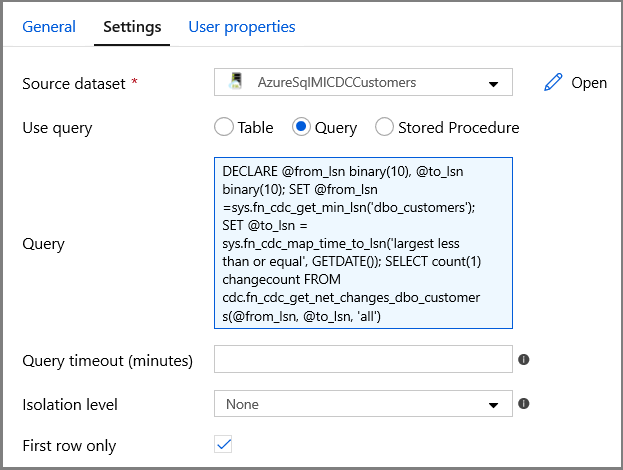
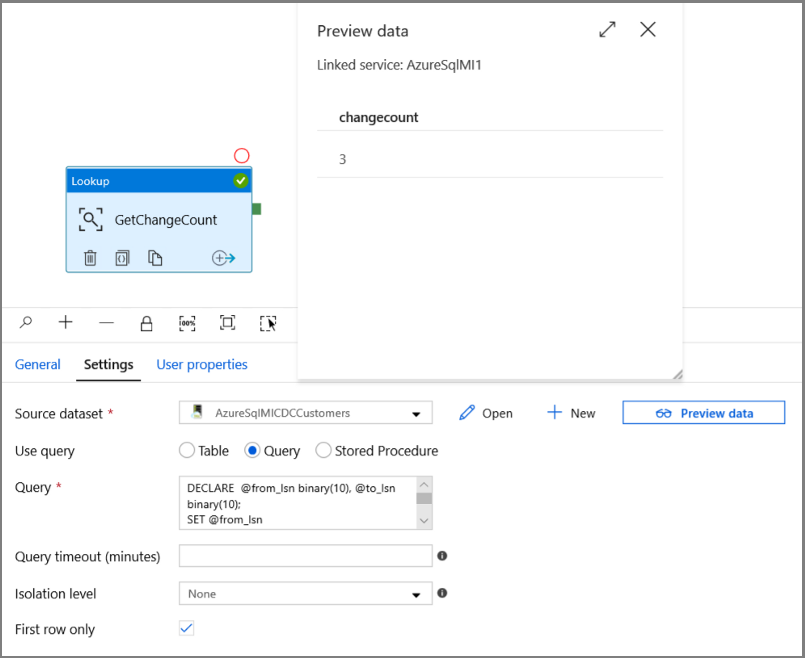
Klicken Sie auf die Schaltfläche Datenvorschau, um sich zu vergewissern, dass durch die Lookup-Aktivität eine gültige Ausgabe abgerufen wird.
Erweitern Sie in der Toolbox Aktivitäten die Option Iteration & Conditionals (Iteration und Bedingungen), und ziehen Sie die Aktivität If-Bedingung auf die Oberfläche des Pipeline-Designers. Legen Sie den Namen der Aktivität auf HasChangedRows fest.
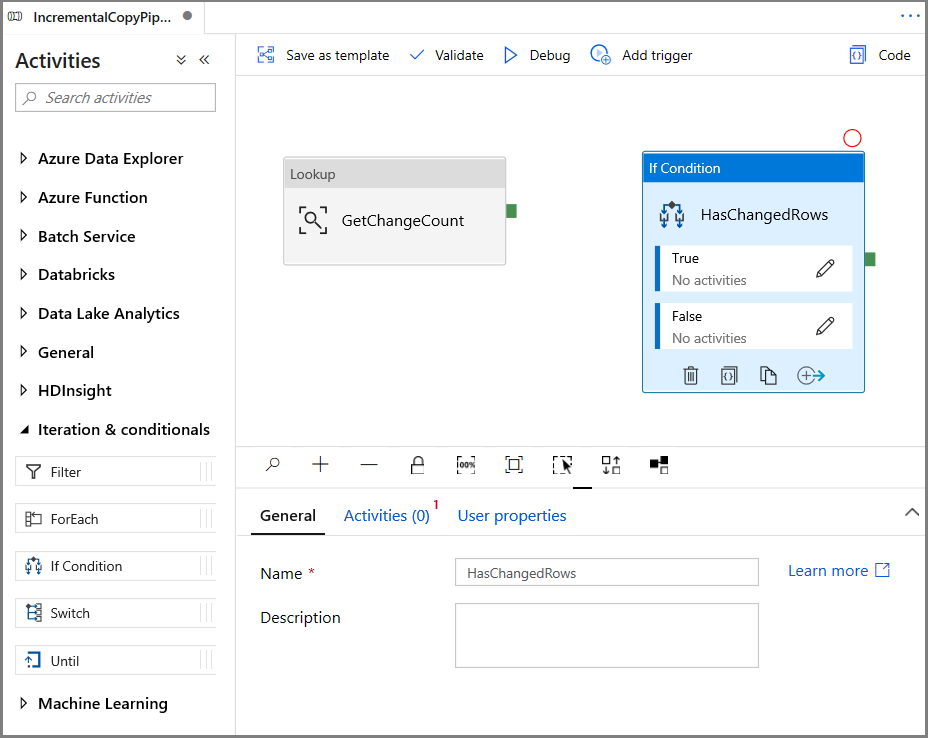
Wechseln Sie im Fenster Eigenschaften zu Aktivitäten:
- Geben Sie unter Ausdruck Folgendes ein:
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Klicken Sie auf das Stiftsymbol, um die True-Bedingung zu bearbeiten.
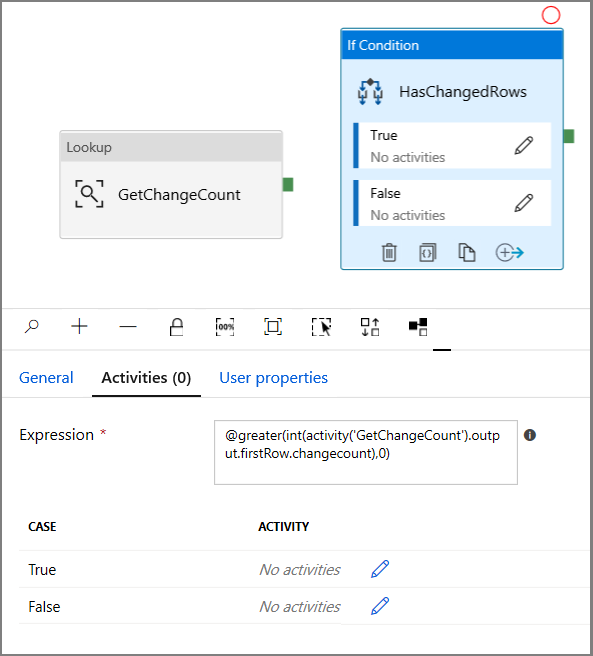
- Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie eine Aktivität vom Typ Warten auf die Oberfläche des Pipeline-Designers. Hierbei handelt es sich um eine temporäre Aktivität zum Debuggen der If-Bedingung; sie wird später in diesem Tutorial noch geändert.
- Klicken Sie auf der Breadcrumb-Leiste auf „IncrementalCopyPipeline“, um zur Hauptpipeline zurückzukehren.
Führen Sie die Pipeline im Modus Debuggen aus, um sich zu vergewissern, dass die Ausführung erfolgreich ist.
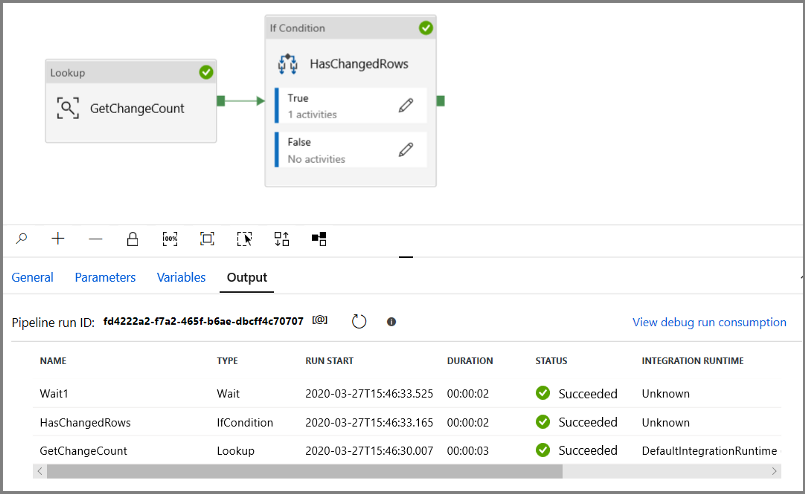
Kehren Sie als Nächstes zum Schritt für die True-Bedingung zurück, und löschen Sie die Aktivität Warten. Erweitern Sie in der Toolbox Aktivitäten die Option Move & transform (Verschieben und transformieren), und ziehen Sie eine Aktivität vom Typ Copy auf die Oberfläche des Pipeline-Designers. Legen Sie den Namen der Aktivität auf IncrementalCopyActivity fest.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Quelle, und führen Sie die folgenden Schritte aus:
Geben Sie im Feld Source Dataset (Quelldataset) den Namen des SQL Managed Instance-Datasets an.
Wählen Sie unter Abfrage verwenden die Option Abfrage.
Geben Sie unter Abfrage Folgendes ein:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
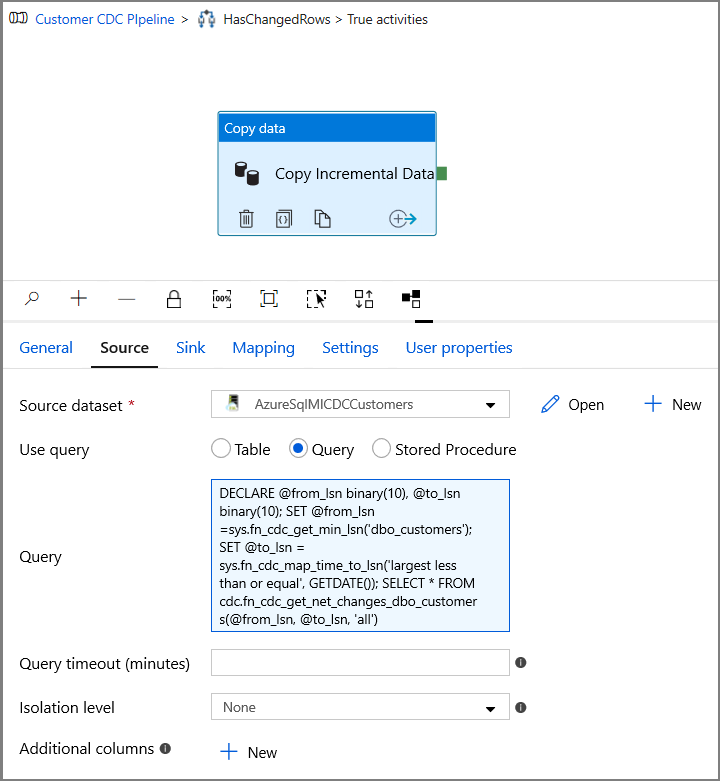
Klicken Sie auf die Vorschauoption, um sich zu vergewissern, dass die geänderten Zeilen durch die Abfrage korrekt zurückgegeben werden.
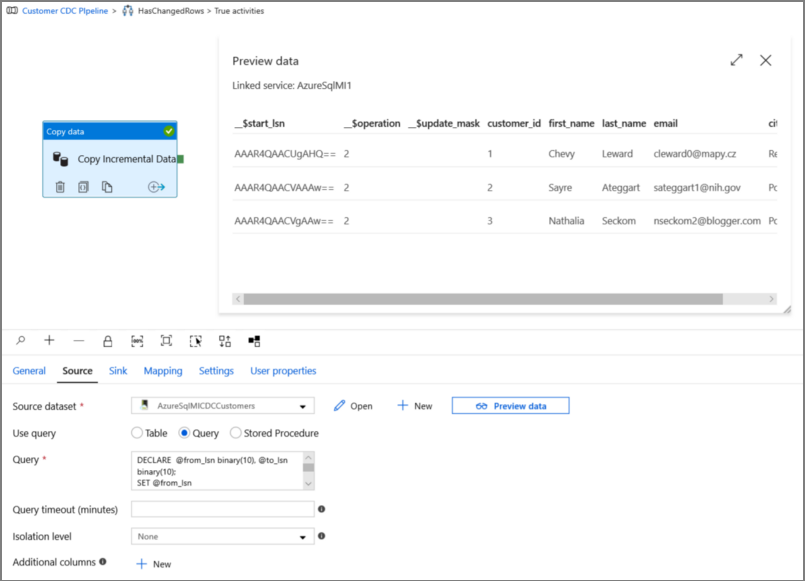
Wechseln Sie zur Registerkarte Senke, und geben Sie im Feld Sink Dataset (Senkendataset) das Azure Storage-Dataset an.

Kehren Sie zur Canvas der Hauptpipeline zurück, und verbinden Sie nacheinander die Aktivität Lookup mit der Aktivität If-Bedingung. Ziehen Sie die grüne Schaltfläche der Aktivität Lookup zur Aktivität If-Bedingung.
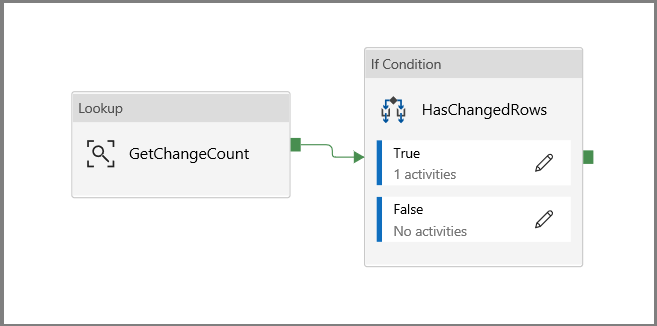
Klicken Sie in der Symbolleiste auf Überprüfen. Vergewissern Sie sich, dass keine Validierungsfehler vorliegen. Schließen Sie das Fenster Pipeline Validation Report (Pipelineüberprüfungsbericht), indem Sie auf >> klicken.
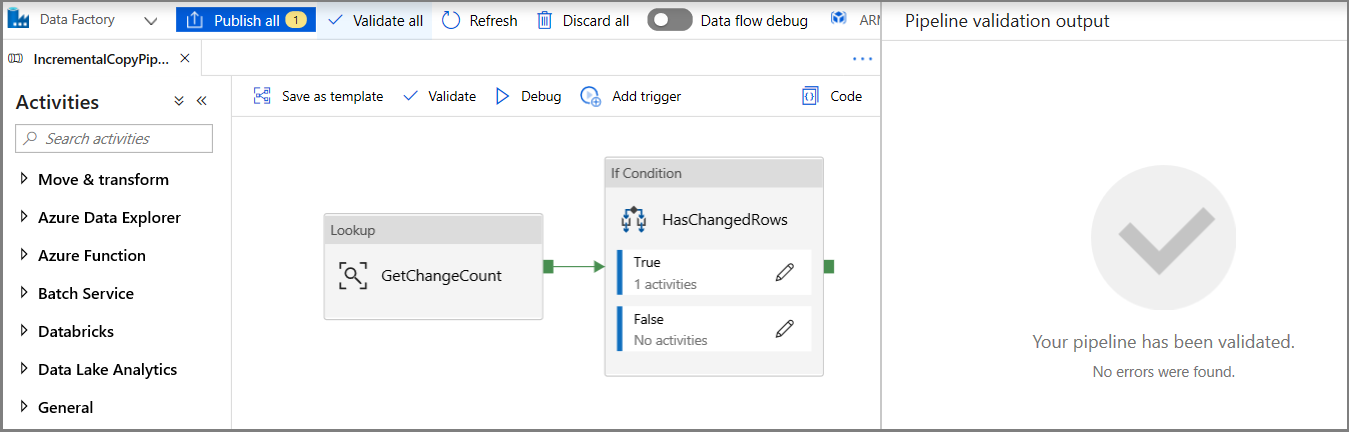
Klicken Sie auf „Debuggen“, um die Pipeline zu testen und sich zu vergewissern, dass am Speicherort eine Datei generiert wird.
Veröffentlichen Sie Entitäten (verknüpfte Dienste, Datasets und Pipelines) für den Data Factory-Dienst, indem Sie auf die Schaltfläche Alle veröffentlichen klicken. Warten Sie, bis die Meldung Veröffentlichung erfolgreich angezeigt wird.
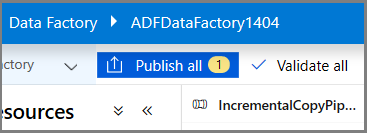
Konfigurieren des Triggers für ein rollierendes Fenster und der CDC-Fensterparameter
In diesem Schritt wird ein Trigger für ein rollierendes Fenster erstellt, um den Auftrag nach einem kurz getakteten Zeitplan auszuführen. Hierbei werden die Systemvariablen „WindowStart“ und „WindowEnd“ des Triggers für das rollierende Fenster als Parameter an die Pipeline übergeben, um sie in der CDC-Abfrage zu verwenden.
Navigieren Sie zur Registerkarte Parameter der Pipeline IncrementalCopyPipeline, und fügen Sie der Pipeline mithilfe der Schaltfläche + Neu zwei Parameter (triggerStartTime und triggerEndTime) hinzu, die die Start- und Endzeit des rollierenden Fensters darstellen. Fügen Sie zu Debuggingzwecken Standardwerte im Format JJJJ-MM-TT HH24:MI:SS.FFF hinzu. Achten Sie jedoch darauf, dass die Startzeit des Triggers (triggerStartTime) nicht vor der CDC-Aktivierung für die Tabelle liegt, da sonst ein Fehler auftritt.
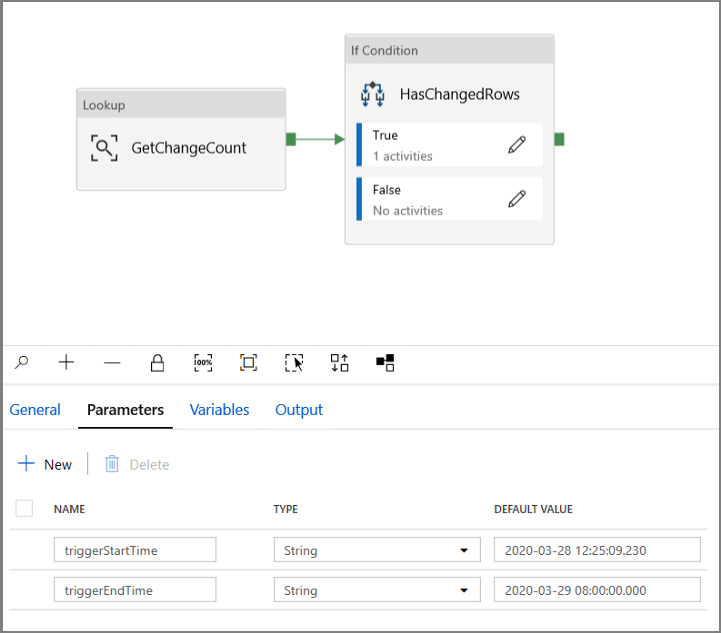
Klicken Sie auf die Registerkarte mit den Einstellungen der Aktivität Lookup, und konfigurieren Sie die Abfrage für die Verwendung des Start- und Endparameters. Kopieren Sie Folgendes in die Abfrage:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Navigieren Sie zur Aktivität Copy (im Fall „True“ der Aktivität If-Bedingung), und klicken Sie auf die Registerkarte Quelle. Kopieren Sie Folgendes in die Abfrage:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Klicken Sie auf die Registerkarte Senke der Aktivität Copy und anschließend auf Öffnen, um die Dataseteigenschaften zu bearbeiten. Klicken Sie auf die Registerkarte Parameter, und fügen Sie einen neuen Parameter namens triggerStart hinzu.
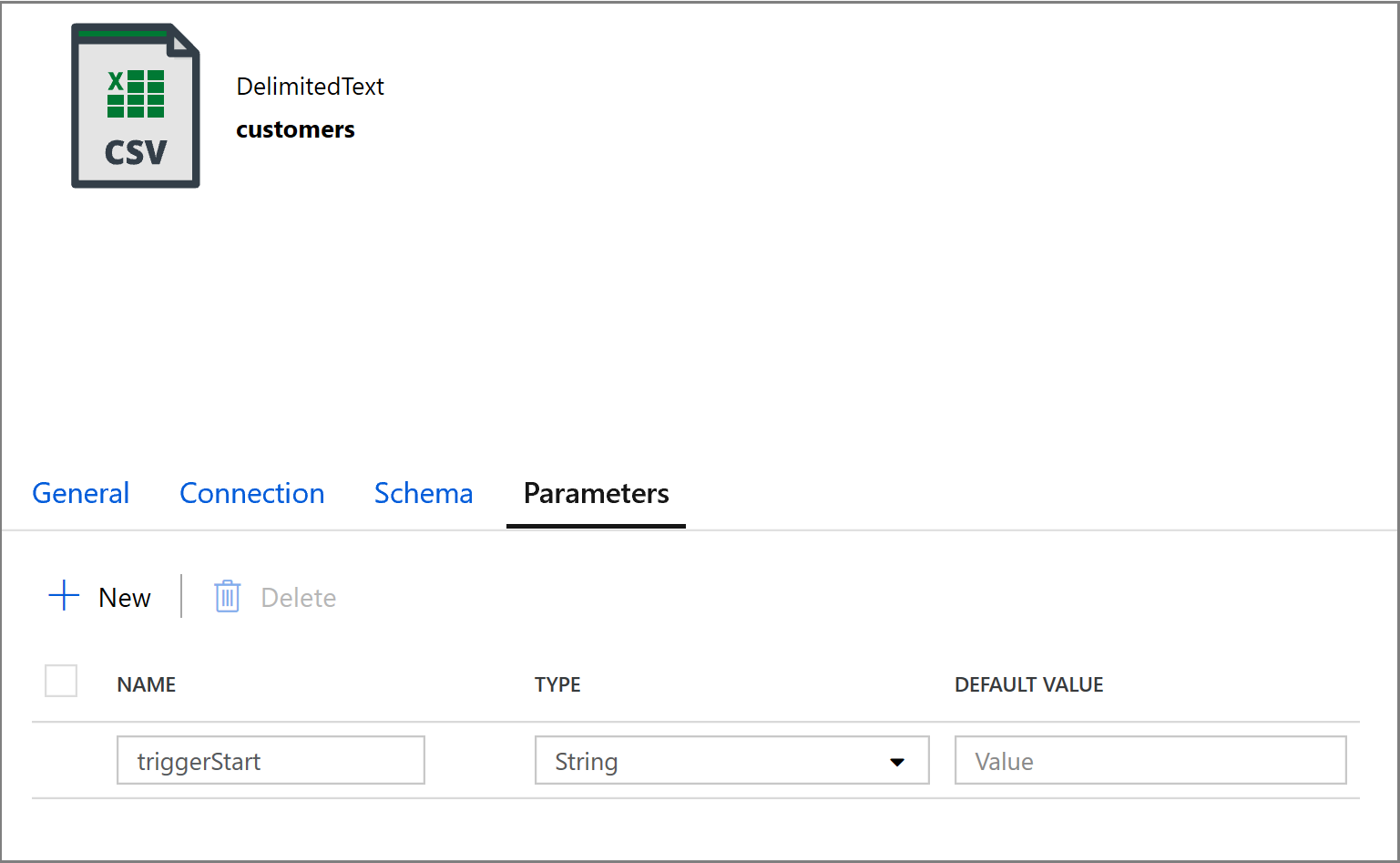
Konfigurieren Sie als Nächstes die Dataseteigenschaften, um die Daten mit datumsbasierten Partitionen in einem Unterverzeichnis von customers/incremental zu speichern.
Klicken Sie in den Dataseteigenschaften auf die Registerkarte Verbindung, und fügen Sie dynamische Inhalte für die Abschnitte Verzeichnis und Datei hinzu.
Geben Sie im Abschnitt Verzeichnis den folgenden Ausdruck ein, indem Sie unter dem Textfeld auf den Link für dynamischen Inhalt klicken:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Geben Sie im Abschnitt Datei den folgenden Ausdruck ein. Dadurch werden Dateinamen auf der Grundlage des Startdatums und der Startzeit des Triggers erstellt und mit dem Suffix „.csv“ versehen:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')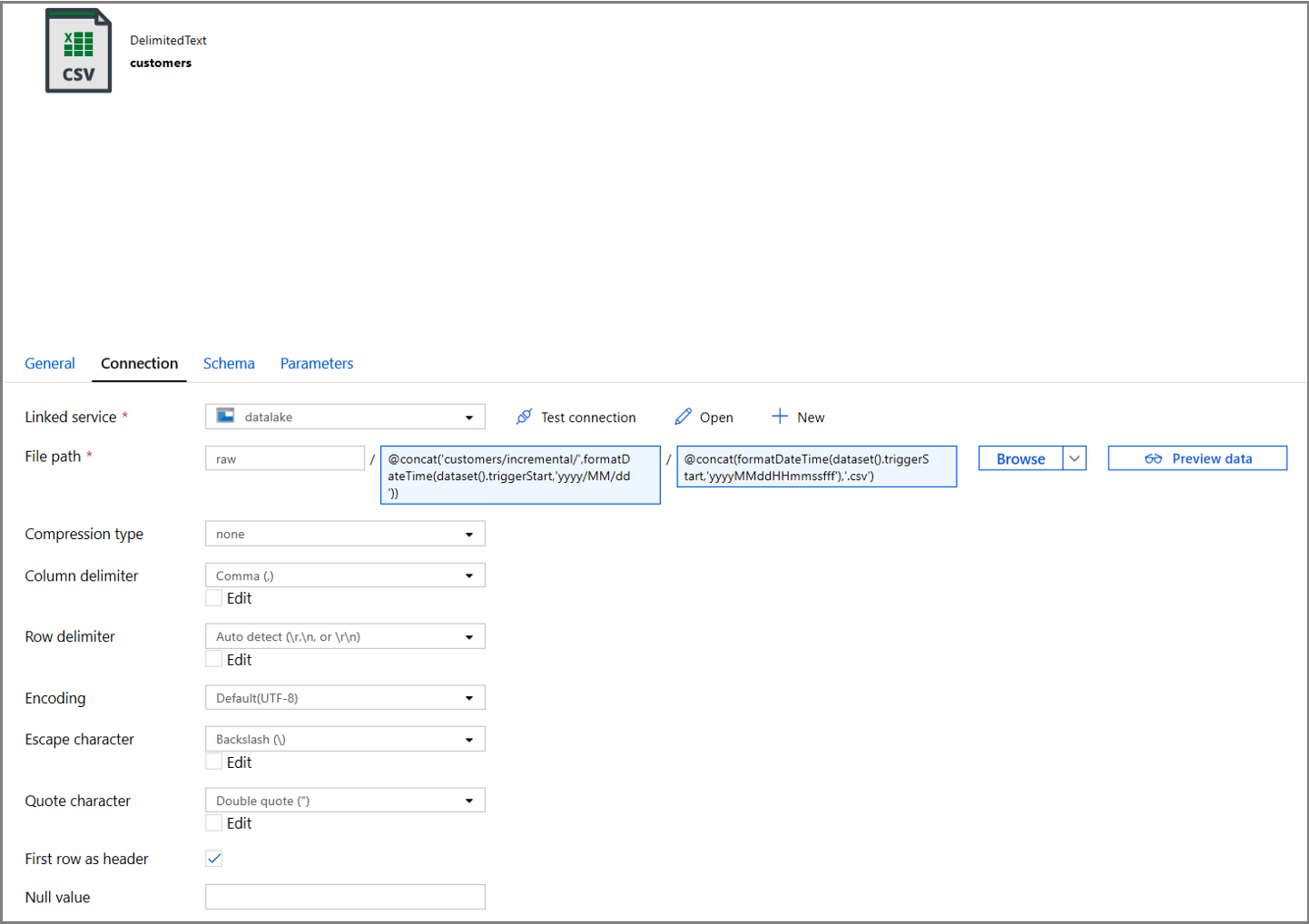
Klicken Sie auf die Registerkarte IncrementalCopyPipeline, um zu den Einstellungen für die Senke in der Aktivität Copy zurückzukehren.
Erweitern Sie die Dataseteigenschaften, und geben Sie im triggerStart-Parameterwert dynamischen Inhalt mit dem folgenden Ausdruck ein:
@pipeline().parameters.triggerStartTime
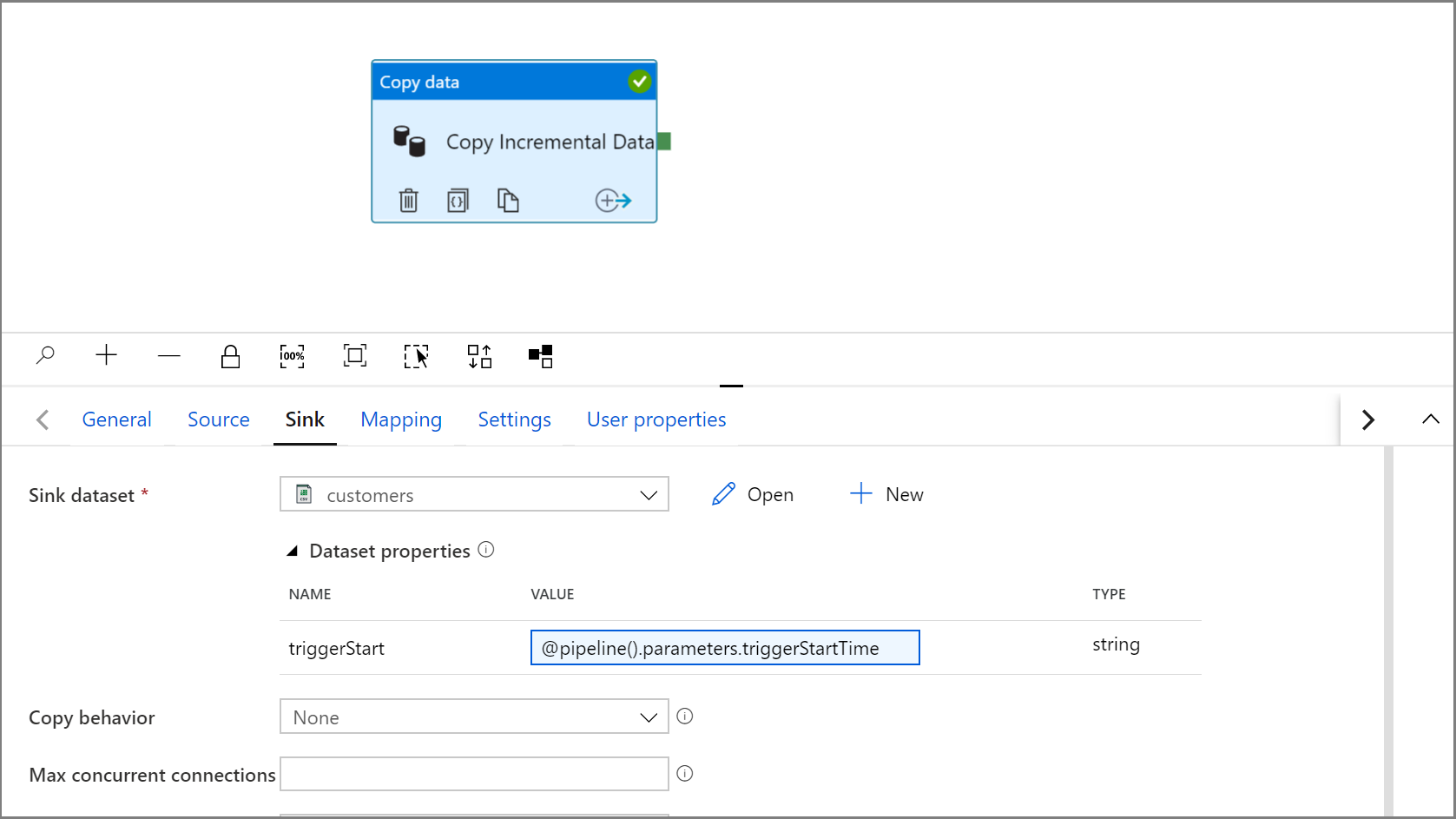
Klicken Sie auf „Debuggen“, um die Pipeline zu testen und sich zu vergewissern, dass die Ordnerstruktur und die Ausgabedatei erwartungsgemäß generiert werden. Laden Sie die Datei herunter, und öffnen Sie sie, um den Inhalt zu überprüfen.
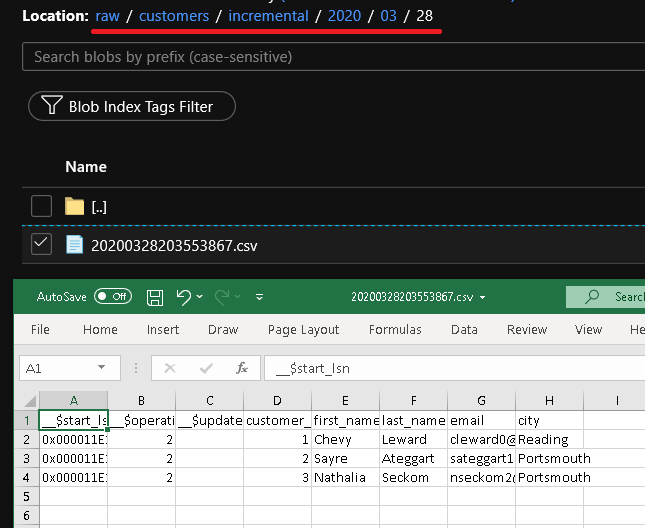
Vergewissern Sie sich, dass die Parameter in die Abfrage eingefügt werden, indem Sie die Eingabeparameter der Pipelineausführung überprüfen.
Veröffentlichen Sie Entitäten (verknüpfte Dienste, Datasets und Pipelines) für den Data Factory-Dienst, indem Sie auf die Schaltfläche Alle veröffentlichen klicken. Warten Sie, bis die Meldung Veröffentlichung erfolgreich angezeigt wird.
Konfigurieren Sie abschließend einen Trigger für ein rollierendes Fenster, um die Pipeline in regelmäßigen Abständen auszuführen, und legen Sie Parameter für Start- und Endzeit fest.
- Klicken Sie auf die Schaltfläche Trigger hinzufügen, und wählen Sie Neu/Bearbeiten aus.
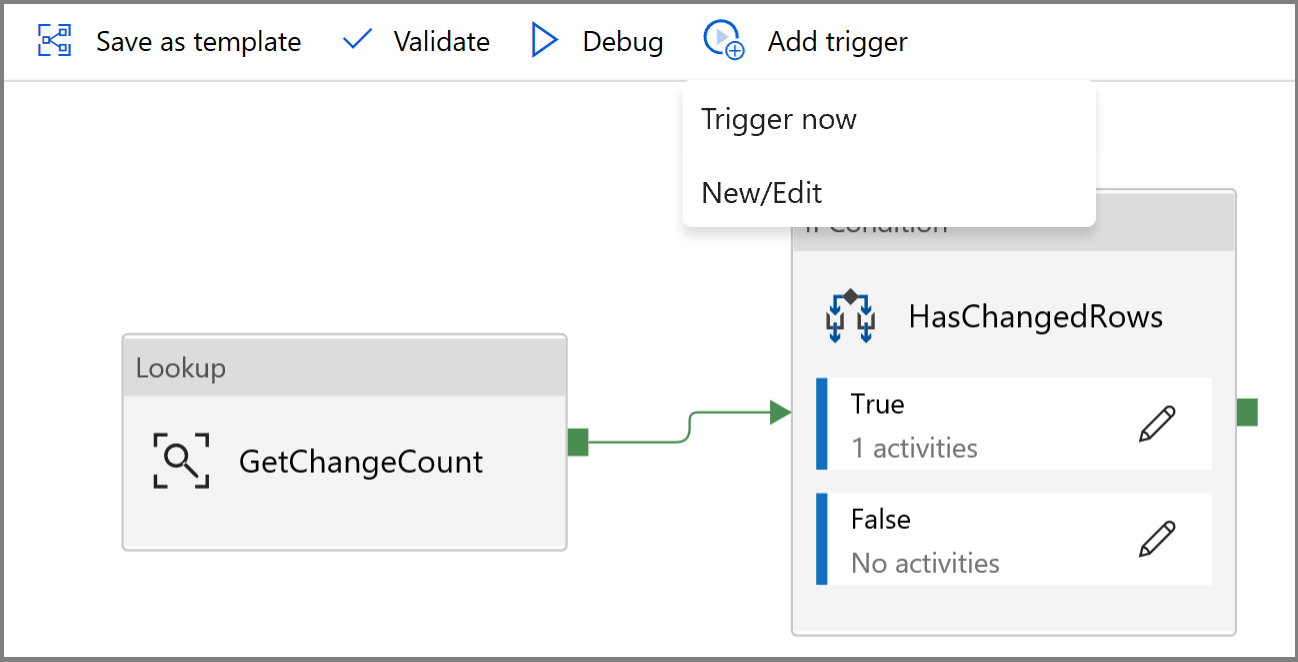
- Geben Sie einen Namen für den Trigger und eine Startzeit an, die der Endzeit des obigen Debugfensters entspricht.
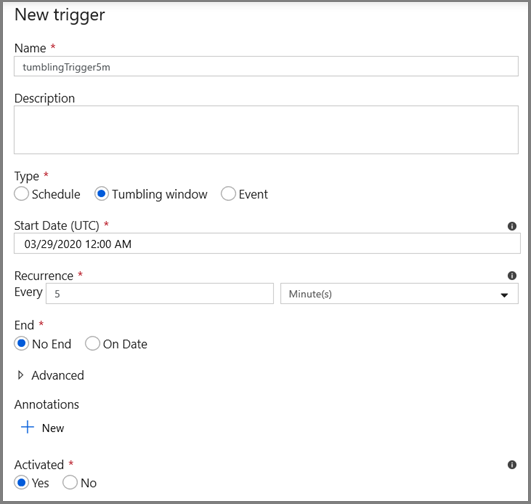
Geben Sie im nächsten Bildschirm die folgenden Werte für den Start- bzw. Endparameter an:
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')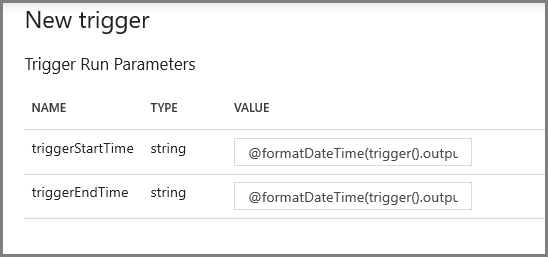
Hinweis
Der Trigger wird erst ausgeführt wird, nachdem er veröffentlicht wurde. Das erwartete Verhalten des rollierenden Fensters besteht außerdem in der Ausführung aller historischen Intervalle seit dem Startdatum bis zum aktuellen Zeitpunkt. Weitere Informationen zu Triggern für ein rollierendes Fenster finden Sie hier.
Nehmen Sie mithilfe von SQL Server Management Studio einige weitere Änderungen an der Kundentabelle vor, indem Sie den folgenden SQL-Code ausführen:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Klicken Sie auf die Schaltfläche Alle veröffentlichen. Warten Sie, bis die Meldung Veröffentlichung erfolgreich angezeigt wird.
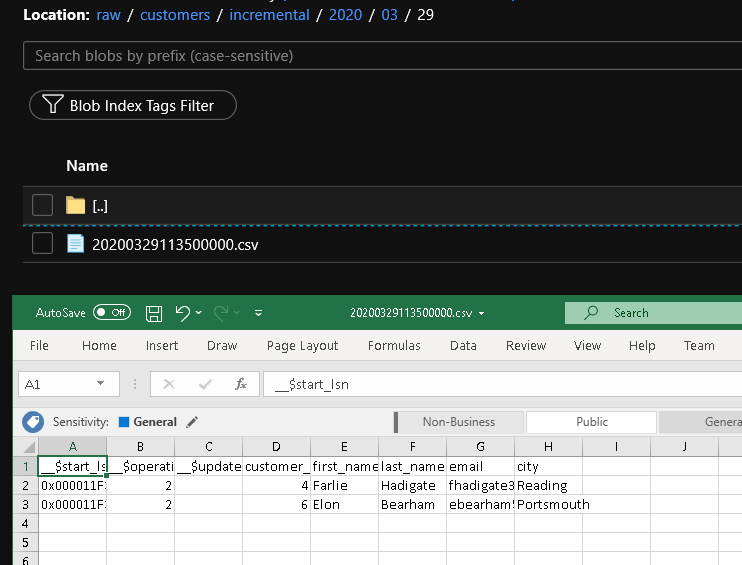
Nach ein paar Minuten wurde die Pipeline ausgelöst, und eine neue Datei wurde in Azure Storage geladen.
Überwachen der inkrementellen Kopierpipeline
Klicken Sie links auf die Registerkarte Überwachen. Die Pipelineausführung wird in der Liste mit ihrem Status angezeigt. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren. Zeigen Sie auf eine Stelle in der Nähe des Namens der Pipeline, um auf die Aktion „Erneut ausführen“ und auf den Verbrauchsbericht zuzugreifen.
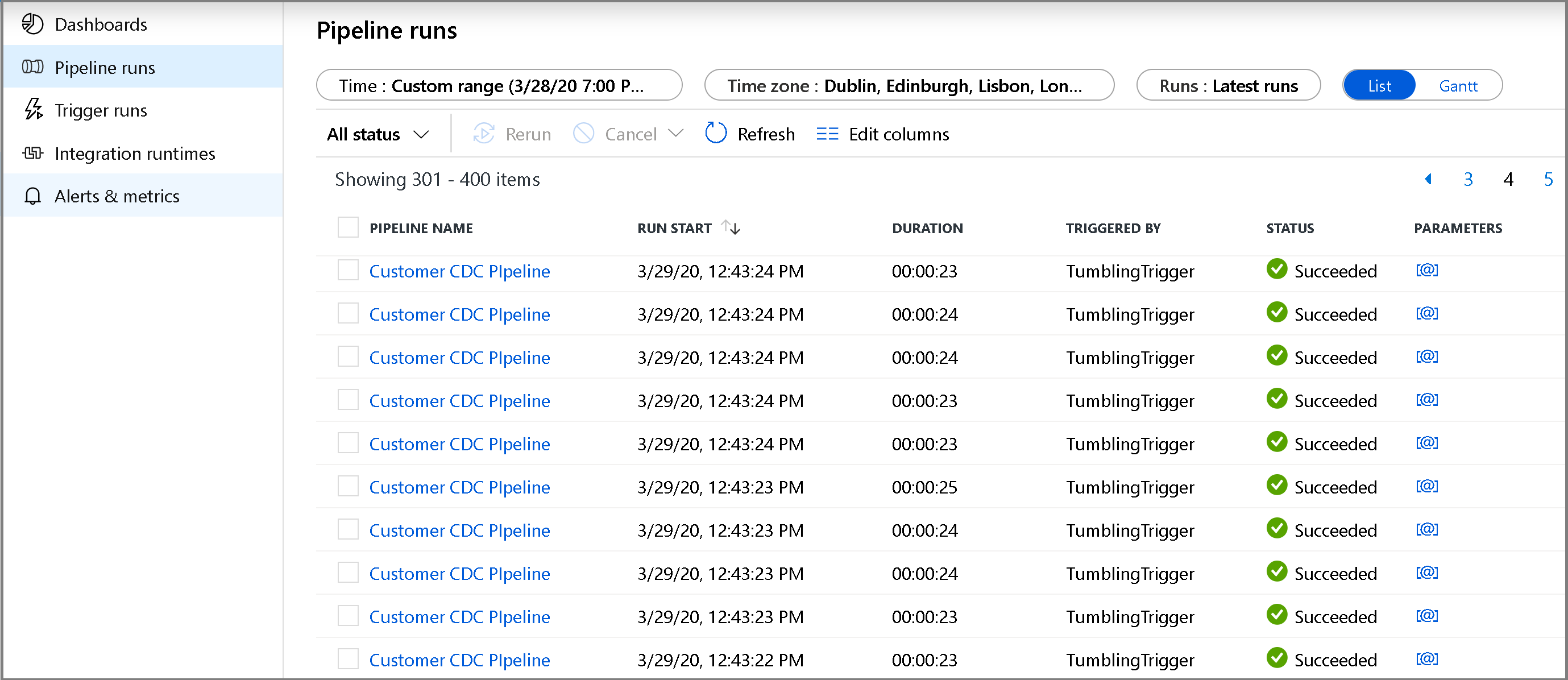
Klicken Sie auf den Namen der Pipeline, um mit der Pipelineausführung verknüpfte Aktivitätsausführungen anzuzeigen. Wurden geänderte Daten erkannt, stehen drei Aktivitäten zur Verfügung (unter anderem die Copy-Aktivität). Andernfalls enthält die Liste nur zwei Einträge. Klicken Sie im oberen Bereich auf den Link Alle Pipelines, um zur Ansicht mit den Pipelineausführungen zurückzukehren.
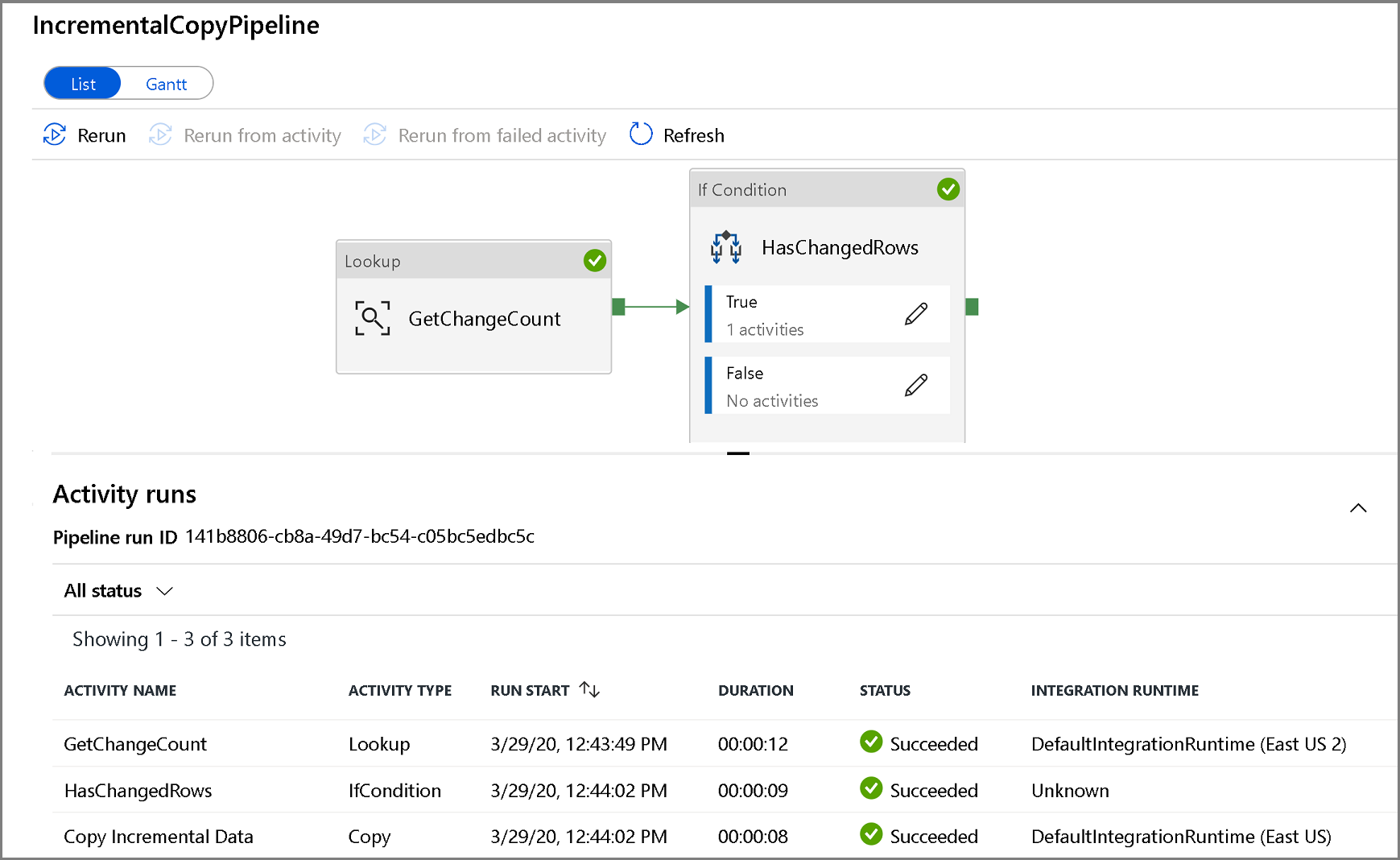
Überprüfen der Ergebnisse
Die zweite Datei ist im Ordner customers/incremental/YYYY/MM/DD des Containers raw enthalten.
Zugehöriger Inhalt
Im folgenden Tutorial erfahren Sie mehr über das Kopieren von neuen und geänderten Dateien nur auf Grundlage ihres LastModifiedDate-Werts: