Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
In diesem Lernprogramm erstellen Sie eine Azure Data Factory mit einer Pipeline, die Deltadaten aus einer Tabelle in Azure SQL Database in Azure Blob Storage lädt.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Bereiten Sie den Datenspeicher vor, um den Wasserzeichenwert zu speichern.
- Erstellen einer Data Factory.
- Erstellen Sie verknüpfte Dienste.
- Erstellen Sie ein Quell-, Senken- und Grenzwertdataset.
- Erstellen einer Pipeline.
- Ausführen der Pipeline.
- Überwachen der Pipelineausführung.
- Überprüfen der Ergebnisse
- Hinzufügen von weiteren Daten zur Quelle
- Erneutes Ausführen der Pipeline
- Überwachen der zweiten Pipelineausführung
- Überprüfen der Ergebnisse der zweiten Ausführung
Übersicht
Allgemeines Lösungsdiagramm:

Hier sind die wesentlichen Schritte beim Erstellen dieser Lösung aufgeführt:
Wählen Sie die Wasserzeichen-Spalte aus Wählen Sie eine Spalte im Quelldatenspeicher aus, die verwendet werden kann, um die neuen oder aktualisierten Datensätze für jede Ausführung in Segmente aufzuteilen. Normalerweise steigen die Daten in dieser ausgewählten Spalte (z.B. Last_modify_time oder ID), wenn Zeilen erstellt oder aktualisiert werden. Der maximale Wert in dieser Spalte wird als Grenzwert verwendet.
Bereiten Sie einen Datenspeicher vor, um den Wasserzeichenwert zu speichern. In diesem Tutorial speichern Sie den Wasserzeichenwert in einer SQL-Datenbank.
Erstellen einer Pipeline mit dem folgenden Workflow:
Die Pipeline in dieser Lösung enthält die folgenden Aktivitäten:
- Erstellen Sie zwei Lookup-Aktivitäten. Verwenden Sie die erste Lookup-Aktivität, um den letzten Markierungswert abzurufen. Verwenden Sie die zweite Lookup-Aktivität, um den neuen Wasserzeichenwert abzurufen. Diese Wasserzeichenwerte werden an die Copy activity übergeben.
- Erstellen Sie eine Copy activity, die Zeilen aus dem Quelldatenspeicher kopiert, wobei der Wert der Wasserzeichenspalte größer als der alte Wasserzeichenwert und kleiner als der neue Wasserzeichenwert ist. Anschließend werden die Deltadaten aus dem Quelldatenspeicher als neue Datei in einen Blobspeicher kopiert.
- Erstellen Sie eine StoredProcedure-Aktivität, die den Grenzwert für die Pipeline aktualisiert, die nächstes Mal ausgeführt wird.
Wenn Sie nicht über ein Azure-Abonnement verfügen, erstellen Sie ein free Konto, bevor Sie beginnen.
Voraussetzungen
- Azure SQL Database. Sie verwenden die Datenbank als den Quelldatenspeicher. Wenn Sie keine Datenbank in Azure SQL Database haben, lesen Sie Erstellen einer Datenbank in Azure SQL-Datenbank, um die Schritte zum Erstellen einer Datenbank zu erfahren.
- Azure Storage. Sie verwenden den Blobspeicher als Senkendatenspeicher. Wenn Sie kein Speicherkonto besitzen, finden Sie unter Erstellen eines Speicherkontos Schritte zum Erstellen eines solchen Kontos. Erstellen Sie einen Container mit dem Namen „adftutorial“.
Erstellen einer Datenquelltabelle in Ihrer SQL-Datenbank
Öffnen Sie SQL Server Management Studio. Klicken Sie im Server-Explorer mit der rechten Maustaste auf die Datenbank, und wählen Sie Neue Abfrage.
Führen Sie den folgenden SQL-Befehl für Ihre SQL-Datenbank aus, um eine Tabelle mit dem Namen
data_source_tableals Quelldatenspeicher zu erstellen.create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');In diesem Tutorial verwenden Sie „LastModifytime“ als Wasserzeichenspalte. Die Daten im Quelldatenspeicher sind in der folgenden Tabelle dargestellt:
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Erstellen Sie eine weitere Tabelle in Ihrer SQL-Datenbank, um den High-Watermark-Wert zu speichern.
Führen Sie den folgenden SQL-Befehl für Ihre SQL-Datenbank aus, um eine Tabelle mit dem Namen
watermarktablezum Speichern des Grenzwerts zu erstellen:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Legen Sie den Standardwert für den hohen Grenzwert mit dem Tabellennamen des Quelldatenspeichers fest. In diesem Tutorial lautet der Tabellenname „data_source_table“.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Überprüfen Sie die Daten in der Tabelle
watermarktable.Select * from watermarktableAusgabe:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Erstellen einer gespeicherten Prozedur in Ihrer SQL-Datenbank
Führen Sie den folgenden Befehl zum Erstellen einer gespeicherten Prozedur in Ihrer SQL-Datenbank aus.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Erstellen einer Data Factory
Starten Sie Microsoft Edge oder Google Chrome Webbrowser. Derzeit wird data Factory UI nur in Microsoft Edge- und Google Chrome-Webbrowsern unterstützt.
Wählen Sie im oberen Menü die Option "Resource>Analytics>Data Factory erstellen" aus:
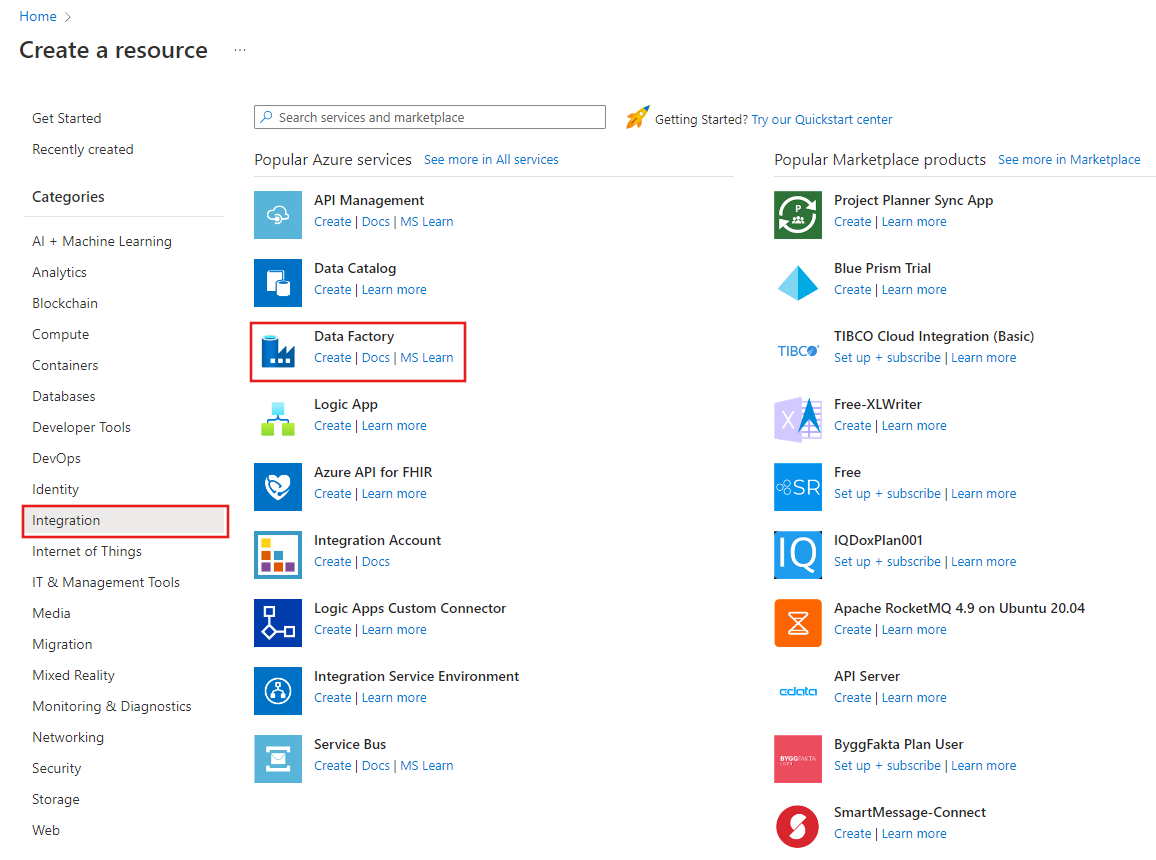
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFIncCopyTutorialDF ein.
Der Name des Azure Data Factory muss globally unique sein. Wenn ein rotes Ausrufezeichen mit dem folgenden Fehler angezeigt wird, können Sie den Namen der Data Factory ändern (z.B. in „
ADFIncCopyTutorialDF“) und dann versuchen, die Erstellung erneut durchzuführen. Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln. Der Data Factory-Name „ADFIncCopyTutorialDF“ ist nicht verfügbar.
Wählen Sie Ihr Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie für die Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie Use existing und wählen Sie eine vorhandene Ressourcengruppe aus der Dropdown-Liste aus.
Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwendung von Ressourcengruppen zum Verwalten ihrer Azure Ressourcen.
Wählen Sie V2 als Version aus.
Wählen Sie den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die datenspeicher (Azure Storage, Azure SQL Database, Azure SQL Managed Instance usw.) und computes (HDInsight usw.), die von data factory verwendet werden, können in anderen Regionen sein.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird die Seite Data Factory wie in der Abbildung angezeigt.

Wählen Sie Open im Open Azure Data Factory Studio Kachel aus, um die Azure Data Factory Benutzeroberfläche (UI) auf einer separaten Registerkarte zu starten.
Erstellen einer Pipeline
In diesem Tutorial erstellen Sie eine Pipeline mit zwei Lookup-Aktivitäten, einer Kopieraktivität und einer StoredProcedure-Aktivität, die in einer Pipeline verkettet sind.
Klicken Sie auf der Startseite der Data Factory Benutzeroberfläche auf die Kachel Orchestrieren.
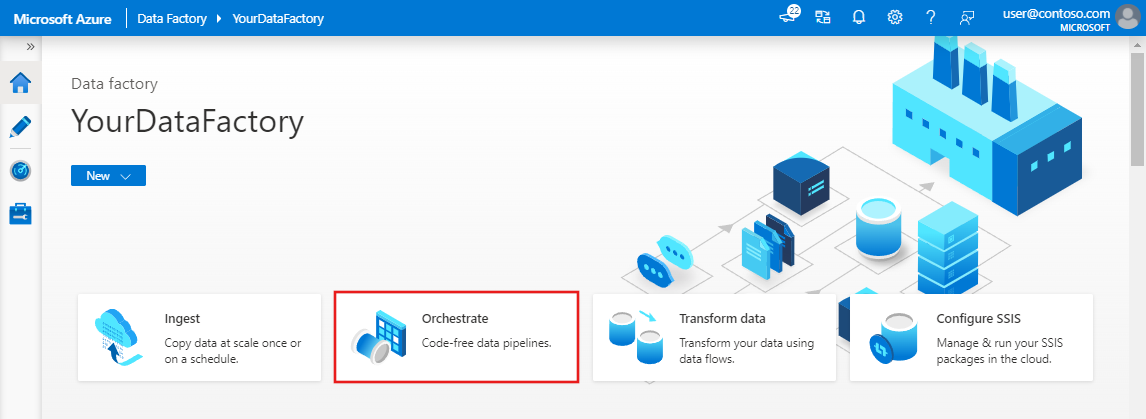
Geben Sie im Bereich „Allgemein“ unter Eigenschaften die Eigenschaft IncrementalCopyPipeline für Name an. Reduzieren Sie dann den Bereich, indem Sie in der oberen rechten Ecke auf das Symbol „Eigenschaften“ klicken.
Wir fügen die erste Lookup-Aktivität hinzu, um den alten Grenzwert abzurufen. Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie die Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Ändern Sie den Namen der Aktivität in LookupOldWaterMarkActivity.
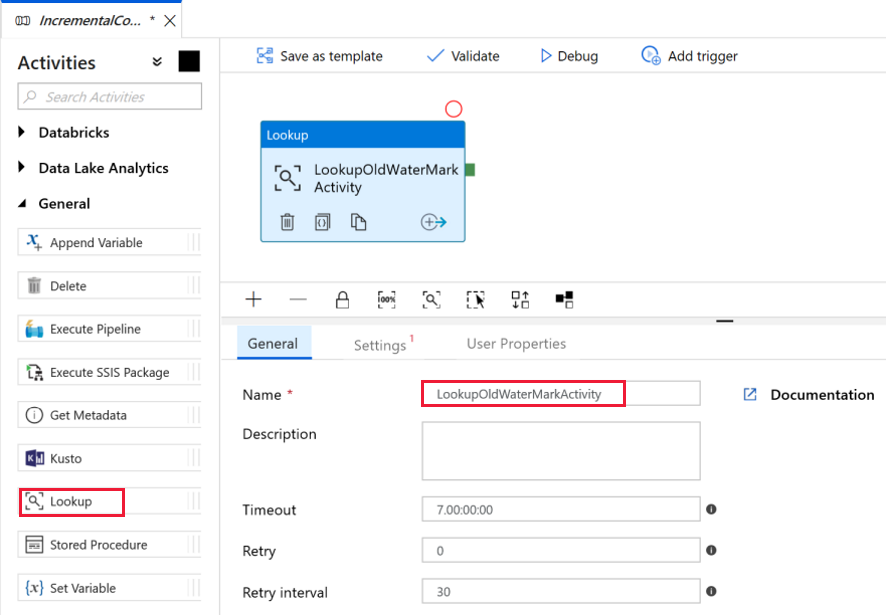
Wechseln Sie zur Registerkarte Einstellungen, und klicken Sie unter Source Dataset (Quelldataset) auf + Neu. In diesem Schritt erstellen Sie ein Dataset zur Darstellung von Daten in der Tabelle watermarktable. Diese Tabelle enthält das alte Wasserzeichen, das beim vorherigen Kopiervorgang verwendet wurde.
Wählen Sie im Fenster Neues DatasetAzure SQL Database aus, und klicken Sie auf Continue. Ein neues Fenster für den Datensatz wird geöffnet.
Geben Sie im Fenster Eigenschaften festlegen für das Dataset unter Name den Namen WatermarkDataset ein.
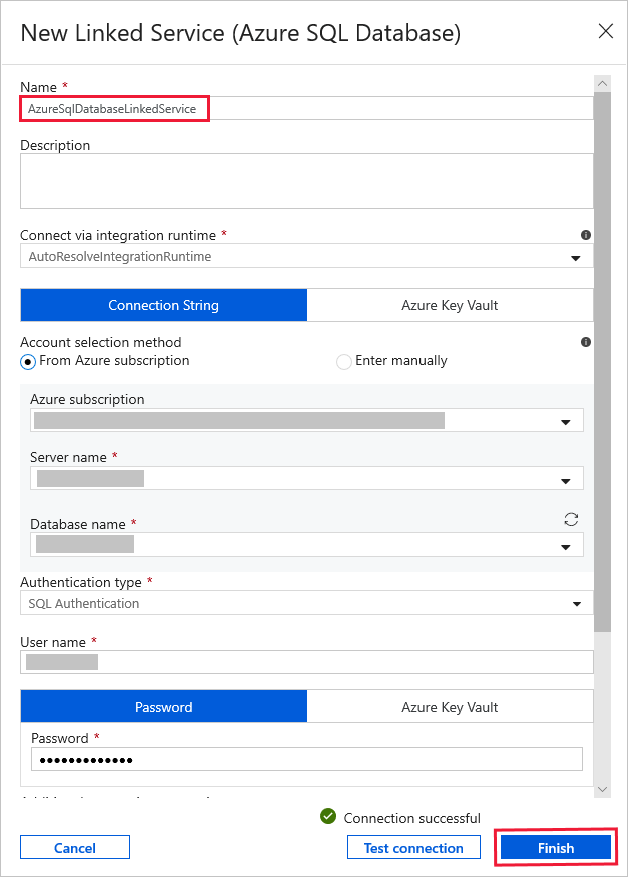
Wählen Sie unter Verknüpfter Dienst die Option Neu aus, und führen Sie dann die folgenden Schritte aus:
Geben Sie AzureSqlDatabaseLinkedService für Name ein.
Wählen Sie unter Servername Ihren Server aus.
Wählen Sie in der Dropdownliste den Datenbanknamen aus.
Geben Sie unter Benutzername Ihren Benutzernamen und unter Kennwort Ihr Kennwort ein.
Klicken Sie zum Testen der Verbindung mit Ihrer SQL-Datenbank auf Verbindung testen.
Klicken Sie auf Fertig stellen.
Vergewissern Sie sich, dass unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService ausgewählt ist.
Wählen Sie Fertig stellen aus.
Wählen Sie auf der Registerkarte Verbindung unter Tabelle die Option [dbo].[watermarktable] aus. Klicken Sie auf Datenvorschau, wenn Sie für die Daten der Tabelle eine Vorschau anzeigen möchten.
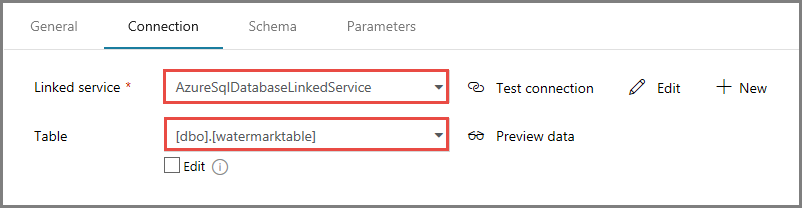
Wechseln Sie zum Pipeline-Editor, indem Sie oben auf die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite auf den Namen der Pipeline klicken. Vergewissern Sie sich im Eigenschaftenfenster für die Lookup-Aktivität, dass im Feld Source Dataset (Quelldataset) die Option WatermarkDataset ausgewählt ist.
Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie eine weitere Lookup-Aktivität auf die Oberfläche des Pipeline-Designers. Legen Sie den Namen im Eigenschaftenfenster auf der Registerkarte Allgemein auf LookupNewWaterMarkActivity fest. Mit dieser Lookup-Aktivität wird der neue Grenzwert aus der Tabelle mit den Quelldaten auf das Ziel kopiert.
Wechseln Sie im Eigenschaftenfenster für die zweite Lookup-Aktivität zur Registerkarte Einstellungen, und klicken Sie auf Neu. Sie erstellen ein Dataset zum Verweisen auf die Quelltabelle, die den neuen Grenzwert (maximaler Wert für LastModifyTime) enthält.
Wählen Sie im Fenster Neues DatasetAzure SQL Database aus, und klicken Sie auf Continue.
Geben Sie im Fenster Eigenschaften festlegen für NameSourceDataset ein. Wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService.
Wählen Sie [dbo].[data_source_table] als Tabelle. Zu einem späteren Zeitpunkt des Tutorials geben Sie eine Abfrage für dieses Dataset an. Die Abfrage hat Vorrang vor der Tabelle, die Sie in diesem Schritt angeben.
Wählen Sie Fertig stellen aus.
Wechseln Sie zum Pipeline-Editor, indem Sie oben auf die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite auf den Namen der Pipeline klicken. Vergewissern Sie sich im Eigenschaftenfenster für die Lookup-Aktivität, dass im Feld Source Dataset (Quelldataset) die Option SourceDataset ausgewählt ist.
Wählen Sie im Feld Abfrage verwenden die Option Abfrage, und geben Sie die folgende Abfrage ein: Sie wählen hierbei in der Tabelle data_source_table lediglich den höchsten Wert von LastModifytime aus. Stellen Sie sicher, dass Sie auch Nur erste Zeile mit einem Häkchen versehen haben.
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table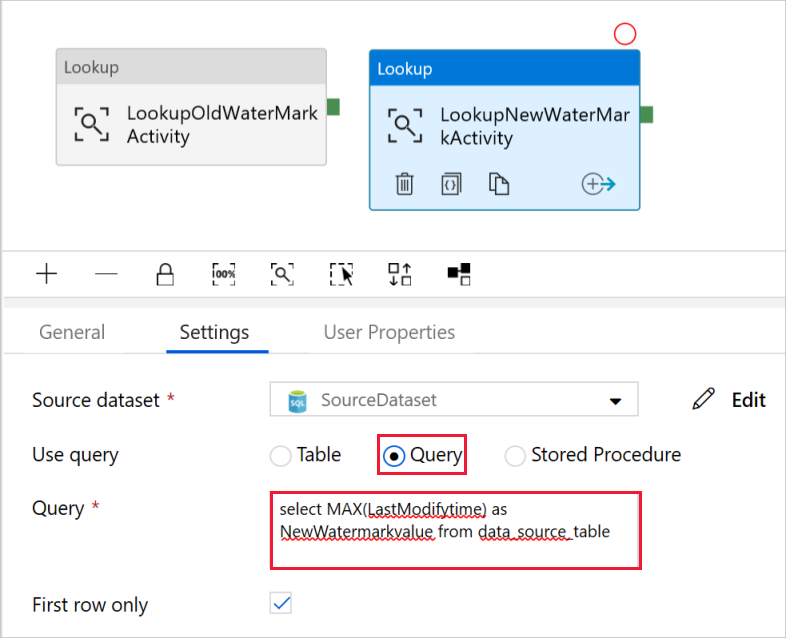
Erweitern Sie in der Toolbox Aktivitäten die Option Move & Transform (Verschieben und transformieren), ziehen Sie die Copy-Aktivität aus der Toolbox „Aktivitäten“, und legen Sie den Namen auf IncrementalCopyActivity fest.
Verbinden Sie beide Nachschlageaktivitäten mit der Kopieraktivität, indem Sie die grüne Schaltfläche, die an die Nachschlageaktivitäten angefügt ist, zur Kopieraktivität ziehen. Lassen Sie die Maustaste los, wenn sich die Rahmenfarbe der Kopieraktivität in Blau ändert.
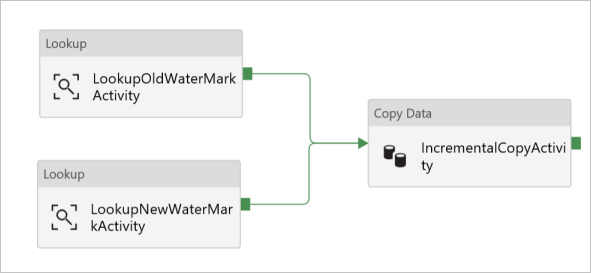
Wählen Sie die Copy activity aus, und bestätigen Sie, dass die Eigenschaften für die Aktivität im Fenster Properties angezeigt werden.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Quelle, und führen Sie die folgenden Schritte aus:
Wählen Sie SourceDataset für das Feld Source Dataset.
Wählen Sie Abfrage für das Feld Abfrage verwenden aus.
Geben Sie im Feld Abfrage die folgende SQL-Abfrage ein.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'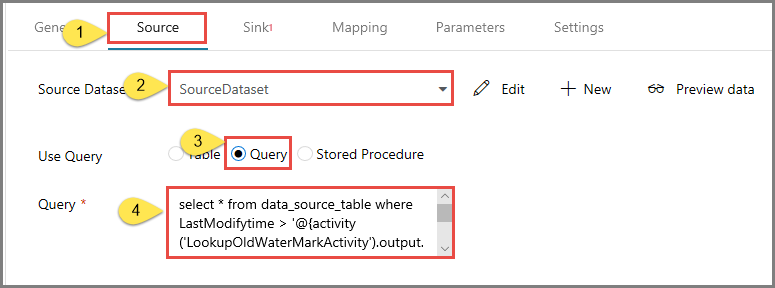
Wechseln Sie zur Registerkarte Senke, und klicken Sie für das Feld Sink Dataset auf + Neu.
In diesem Tutorial hat der Datenspeicher den Typ „Azure Blob Storage“. Wählen Sie daher Azure Blob Storage aus, und klicken Sie auf Continue im Fenster Neues Dataset.
Wählen Sie im Fenster Format auswählen den Formattyp Ihrer Daten aus, und klicken Sie dann auf Weiter.
Im Fenster Eigenschaften festlegen geben Sie für den NameSinkDataset ein. Wählen Sie unter Verknüpfter Dienst die Option + Neu aus. In diesem Schritt erstellen Sie eine Verbindung (verknüpfter Dienst) mit Ihrem Azure Blob Storage.
Führen Sie im Fenster Neuer verknüpfter Dienst (Azure Blob Storage) die folgenden Schritte aus:
- Geben Sie AzureStorageLinkedService für Name ein.
- Wählen Sie Ihr Azure-Speicherkonto für Storage-Kontoname aus.
- Testen Sie die Verbindung, und klicken Sie dann auf Fertig stellen.
Vergewissern Sie sich, dass im Fenster Eigenschaften festlegen unter Verknüpfter Dienst die Option AzureStorageLinkedService ausgewählt ist. Wählen Sie dann Fertig stellen aus.
Wechseln Sie zur Registerkarte Verbindung von „SinkDataset“, und führen Sie die folgenden Schritte aus:
- Geben Sie im Feld Dateipfad die Zeichenfolge adftutorial/incrementalcopy ein. adftutorial ist der Name des Blobcontainers, und incrementalcopy ist der Ordnername. In diesem Codeausschnitt wird davon ausgegangen, dass Sie einen Blobcontainer mit dem Namen „adftutorial“ in Ihrem Blobspeicher besitzen. Erstellen Sie den Container, wenn er noch nicht vorhanden ist, oder geben Sie den Namen eines bereits vorhandenen ein. Azure Data Factory erstellt automatisch den Ausgabeordner incrementalcopy wenn er nicht vorhanden ist. Sie können auch die Schaltfläche Durchsuchen für den Dateipfad verwenden, um zu einem Ordner in einem Blobcontainer zu navigieren.
- Wählen Sie für den Teil Datei des Felds Dateipfad die Option Dynamischen Inhalt hinzufügen [ALT+P] aus, und geben Sie dann
@CONCAT('Incremental-', pipeline().RunId, '.txt')in das geöffnete Fenster ein. Wählen Sie dann Fertig stellen aus. Der Dateiname wird durch den Ausdruck dynamisch generiert. Jede Pipelineausführung verfügt über eine eindeutige ID. Die Copy activity verwendet die Ausführungs-ID, um den Dateinamen zu generieren.
Wechseln Sie zum Pipeline-Editor, indem Sie oben auf die Registerkarte „Pipeline“ oder in der Strukturansicht auf der linken Seite auf den Namen der Pipeline klicken.
Erweitern Sie in der Toolbox Aktivitäten die Option Allgemein, und ziehen Sie die Stored Procedure-Aktivität aus der Toolbox Aktivitäten auf die Oberfläche des Pipeline-Designers. Verbinden Sie den grünen (Erfolg) Output der Copy-Aktivität mit der Stored Procedure-Aktivität.
Wählen Sie im Pipeline-Designer die Option Stored Procedure-Aktivität aus, und ändern Sie den Namen in StoredProceduretoWriteWatermarkActivity.
Wechseln Sie zur Registerkarte SQL-Konto, und wählen Sie unter Verknüpfter Dienst die Option AzureSqlDatabaseLinkedService aus.
Wechseln Sie zur Registerkarte Gespeicherte Prozedur, und führen Sie die folgenden Schritte aus:
Wählen Sie unter Name der gespeicherten Prozedur die Option usp_write_watermark.
Klicken Sie zum Angeben von Werten für die Parameter der gespeicherten Prozedur auf Import parameter (Importparameter), und geben Sie die folgenden Werte für die Parameter ein:
Name Typ Wert Letzte Änderungszeit Datum und Uhrzeit @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} Tabellenname Schnur @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 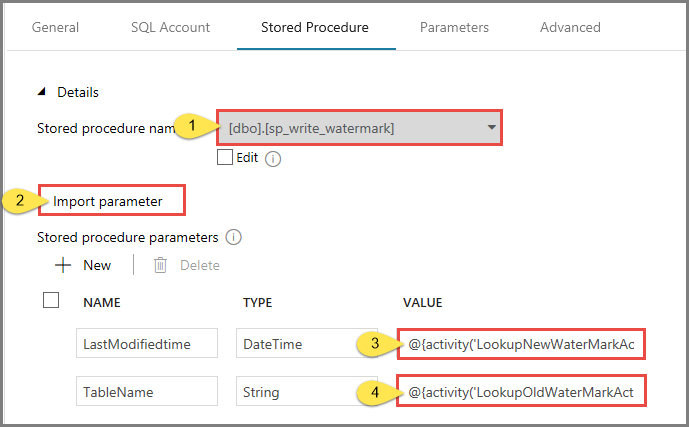
Klicken Sie zum Überprüfen der Pipelineeinstellungen in der Symbolleiste auf Überprüfen. Vergewissern Sie sich, dass keine Validierungsfehler vorliegen. Schließen Sie das Fenster Pipeline-Validierungsbericht, indem Sie auf >> klicken.
Veröffentlichen Sie Entitäten (verknüpfte Dienste, Datasets und Pipelines) im Azure Data Factory Dienst, indem Sie die Schaltfläche Publish All auswählen. Warten Sie, bis eine Meldung angezeigt wird, dass die Veröffentlichung erfolgreich war.
Auslösen einer Pipelineausführung
Klicken Sie auf der Symbolleiste auf Trigger hinzufügen und dann auf Jetzt auslösen.
Wählen Sie im Fenster Pipelineausführung die Option Fertig stellen aus.
Überwachen der Pipelineausführung
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. Dort wird der Status der Pipelineausführung angezeigt, der von einem manuellen Trigger ausgelöst wurde. Über die Links unter der Spalte PIPELINENAME können Sie Ausführungsdetails anzeigen und die Pipeline erneut ausführen.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie den Link unter der Spalte PIPELINENAME aus. Wenn Sie Details zu den Aktivitätsausführungen anzeigen möchten, wählen Sie unter der Spalte AKTIVITÄTSNAME den Link Details (das Brillensymbol) aus. Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.
Überprüfen der Ergebnisse
Stellen Sie mithilfe von Tools wie Azure Storage Explorer eine Verbindung mit Ihrem Azure Storage-Konto her. Vergewissern Sie sich, dass im Ordner incrementalcopy des Containers adftutorial eine Ausgabedatei erstellt wird.
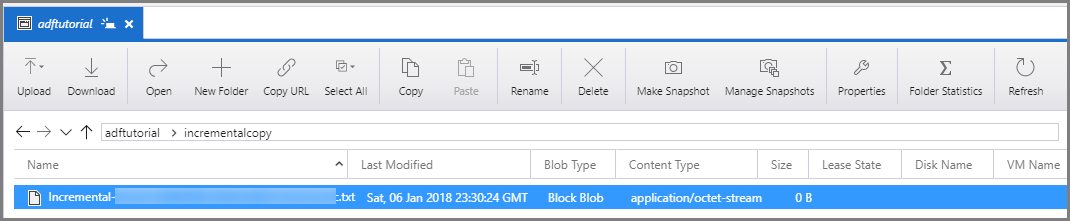
Wenn Sie die Ausgabedatei öffnen, können Sie sehen, dass alle Daten aus data_source_table in die Blobdatei kopiert werden.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Überprüfen Sie den aktuellen Wert aus
watermarktable. Sie bemerken, dass der Wasserzeichenwert aktualisiert wurde.Select * from watermarktableHier sehen Sie die Ausgabe:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Hinzufügen von weiteren Daten zur Quelle
Fügen Sie neue Daten in Ihre Datenbank (Datenquellenspeicher) ein.
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Die aktualisierten Daten in Ihrer Datenbank lauten:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Auslösen einer weiteren Pipelineausführung
Wechseln Sie zur Registerkarte Bearbeiten. Klicken Sie in der Strukturansicht auf die Pipeline, falls sie im Designer nicht geöffnet ist.
Klicken Sie auf der Symbolleiste auf Trigger hinzufügen und dann auf Jetzt auslösen.
Überwachen der zweiten Pipelineausführung
Wechseln Sie im linken Bereich zur Registerkarte Überwachen. Dort wird der Status der Pipelineausführung angezeigt, der von einem manuellen Trigger ausgelöst wurde. Über die Links unter der Spalte PIPELINENAME können Sie Aktivitätsdetails anzeigen und die Pipeline erneut ausführen.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie den Link unter der Spalte PIPELINENAME aus. Wenn Sie Details zu den Aktivitätsausführungen anzeigen möchten, wählen Sie unter der Spalte AKTIVITÄTSNAME den Link Details (das Brillensymbol) aus. Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren.
Überprüfen der zweiten Ausgabe
Im Blobspeicher sehen Sie, dass eine weitere Datei erstellt wurde. In diesem Tutorial ist der neue Dateiname
Incremental-<GUID>.txt. Wenn Sie diese Datei öffnen, sehen Sie zwei Zeilen mit Datensätzen.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Überprüfen Sie den aktuellen Wert aus
watermarktable. Sie sehen, dass der Wasserzeichenwert erneut aktualisiert wurde.Select * from watermarktableBeispielausgabe:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Zugehöriger Inhalt
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Bereiten Sie den Datenspeicher vor, um den Wasserzeichenwert zu speichern.
- Erstellen einer Data Factory.
- Erstellen Sie verknüpfte Dienste.
- Erstellen Sie ein Quell-, Senken- und Grenzwertdataset.
- Erstellen einer Pipeline.
- Ausführen der Pipeline.
- Überwachen der Pipelineausführung.
- Überprüfen der Ergebnisse
- Hinzufügen von weiteren Daten zur Quelle
- Erneutes Ausführen der Pipeline
- Überwachen der zweiten Pipelineausführung
- Überprüfen der Ergebnisse der zweiten Ausführung
In diesem Tutorial hat die Pipeline Daten aus einer einzelnen Tabelle in SQL-Datenbank in einen Blobspeicher kopiert. Wechseln Sie zum folgenden Tutorial, um zu erfahren, wie Sie Daten aus mehreren Tabellen in einer SQL Server-Datenbank in eine SQL-Datenbank kopieren.